Linux内核深入理解全集
Linux 内核深入理解 - 绪论
任何计算机系统都包含一个名为操作系统的基本程序集合!在这个集合里最重要的程序被称为内核。当操作系统启动的时候内核会被装进RAM当中。
操作系统说来说去就是两个主要目标:他充当底层的物理部件好用的抽象,给予上层服务一个好的平台
- 与硬件部分进行交互,为包含在硬件平台上的所有底层可编程部件提供服务!
- 为运行在计算机系统上层的应用程序即所谓的用户程序提供一个执行环境!
为了保障安全。我们的操作系统引入了一组概念,也就是用户模式和特权模式。我们会在之后的博客中有所涉及:简单的讲:一些涉及到底层硬件访问的操作需要在特权模式下进行,反之则会在用户模式下进行!程序的运行有时会在两者之间进行频繁的切换,从而更好地完成程序所提供的服务。
多用户系统
多用户系统就是一台能够并发的执行和独立的执行分别属于两个或者多个用户的若干应用程序的计算机。
并发意味着几个应用程序同时处于活动状态执行自己应用进程所需要执行的任务,而并不需要考虑其它应用程序在做什么!
多用户操作系统必须包含以下几个特点
- 核实用户身份的认证机制
- 防止有错误的用户程序妨碍其它应用程序在系统中运行的保护机制
- 防止有恶意的用户程序干涉或者窥视其他用户的活动的保护机制
- 限制分配给每个用户的资源数的记账机制
于是我们会把用户进行分为用户组在多用户系统中每个用户在机器上都会有自己的私用空间!典型的它需要一些磁盘空间来存储文件!以及接受私人邮件信息等!这一些都需要分层的特权来实现一定的保护机制!
所有的用户都用一个唯一的数字来进行标识,也就是用户标识符!通常一个计算机系统只能够由有限个人来使用。当其中的某个用户开始一个工作session的时候,操作系统会要求输入一个登录口令。如果用户输入无效则会拒绝登录,从而保障用户的隐私。
进程
所有的操作系统都有一个基本的抽象:也就是进程!
进程可以定义为一个程序执行时的一个实例或者一个运行程序所使用的上下文。在传统的操作系统中:一个进程在地址空间中执行一个独立的指令序列,地址空间是允许引用的内存地址集合。
在多用户系统中必须实施一种执行环境:在这样的环境里,几个进程可以并发的活动,并能竞争系统资源。允许进程并发活动的系统叫多道程序系统或多处理系统。
作为一个单处理器系统上,只有一个进程能够占用CPU。这也就意味着实际上只有一条执行流,那么他们是如何实现一种感官上的并发呢?
这需要操作系统的进程是抢占式的!也就是说操作系统需要记录每个进程所占有的CPU时间,并且周期性地激活调度程序。以保证感官上的并发!Unix操作系统是一个具有抢占式进程的多处理操作系统。换而言之,Unix操作系统是一个抢占式的多道处理操作系统!
内核体系架构
大部分Unix内核是单块结构的!也就是说它们属于宏内核操作系统!每一个内核层都被集成到整个内核程序中,并且代表当前进程是在内核态下运行!相反微内核操作系统只需要内核有一个很小的函数:即通常包括几个同步原语,一个简单的调度程序,和IPC通信机制。运行在微内核上的几个系统进程实现宏内核操作系统实现的功能:如内存分配,设备驱动,系统调用处理等。
事实证明微内核操作系统的效率比较低,因为它需要花费大量的时间进行进程之间的通信。不过微内核操作系统比单核快内核有一定的理论优势,因为它强迫系统程序员采用模块化的方法来构建程序。所以Linux充分吸收了微内核操作系统的优点:提供了一个模块的机制!模块是这样的一个目标文件:它上面的代码可以在运行时链接到内核,或者从内核中解除链接。这种目标代码通常是由一组函数组成,从而来实现文件系统,驱动程序,或其他内核上层功能。
使用模块的主要优点有:
- 首先它保证了一种模块化的方法
- 其次它实现了一种平台无关性
- 接着它可以节省内存使用,当我们不再需要他的时候可以动态的进行解除,同样的在我们需要它的时候可以动态的进行加载
- 最后他无性能损失!
文件系统概述
Base
我们这样定义文件:
Unix文件是一个以字节序列组成的信息载体!
内核并不负责解释自己文件的内容!
文件或目录名由除/和空字符之外的任意ASCII字符序列组成!大多数文件系统对文件名的长度都会有所限制。(比如说我们的常见的Ext2是255,你不可以把文件名搞得太长!)
这个可以查看自己的ulimit值
与树的根相对应的目录被称为根目录,按照惯例它的名字是/
在同一目录中的文件名并不能相同,而在不同目录中的文件名则可以相同(因为可以通过连接不同的目录文件名从而唯一的标识这个文件)
Unix的每个进程都有一个工作目录(pwd,想你的shell怎么区分你当前在文件系统海洋的何处!)
当标识文件名时引用符号.和..:它们分别标识当前工作目录,和父目录。如果当前工作目录是根目录,那么这两个目录就是完全一致的!
硬链接和软链接
包含在文件目录的文件名就是一个文件的硬链接,或者简称链接。
在同一目录或不同的目录中同一个文件可以有好几个链接!因此对应几个文件名。
他有两方面的限制:首先他不允许用户给目录创建硬链接,因为这可能会把目录树变为环形图,从而就不可能通过名字来定位一个文件!
其次只有在同一文件系统中的文件才能创建链接!这带来比较大的限制!因为现在操作系统可能包含了多种文件系统!这些文件系统位于不同的磁盘和根目录或分区,用户也许无法知道它们的物理划分!
为了克服这些限制则引入了软链接,或者是符号链接。符号链接是短文件这些文件包含了另一个文件的任意路径名。路径名可以指向位于任意一个操作系统文件系统的任意文件或目录,甚至可以指向一个根本不存在的文件!
Unix文件类型
Unix文件类型可以是以下列的一种:
- 普通文件
- 目录
- 符号链接
- 面向块的设备文件
- 面向字符的设备文件
- 管道
- 命名管道
- 套接字
前三种文件类型是所有Unix文件系统的基本类型
文件描述符与索引节点
Unix对文件的内容和描述文件的信息给出了清楚的区分!除了设备文件和特殊文件系统外,每个文件都由字符序列组成!文件内容不包含任何克控制信息!如文件长度或者文件结束符。
我们使用索引节点在内核中表示文件,从而代表一大块文件数据进行管理!
文件也有访问权限和文件模式:文件的潜在用户有三种
- 作为文件所有者的
- 用户同组用户但是不包括所有者
- 所有剩下的用户
文件有三种访问类型:读,写与执行!
文件操作的系统调用
有open, read, write, close等,这里我们暂时不加讨论!(可以参考Linux系统编程手册学习!)
Unix内核简述
我们下面重点来讨论Unix内核,首先我们要说的是进程/内核模式:
如前所述CPU既可以运行在用户态,也可以运行在内核态。当一个程序在用户态下执行的时候,它并不能直接访问内核的数据结构和程序,然而当应用程序在内核态下运行时则不再会有这些限制。当应用程序有所请求内核服务时,内核才会把这个进程流陷入内核态。当完成任务时把进程送回用户态。进程是动态的实体,在系统内通常只有有限的生存期。创建,撤销,同步现有进程的任务都要委托给内核中的一组例程来完成!
内核本身不是一个进程,而是进程的管理者。除用户进程之外:Unix系统还包括几个所谓的内核进程的特权进程。它们具有以下特点:
- 它们以内核态运行在内核地址空间
- 他们不与用户直接交互,因此不需要终端设备!
- 他们通常在系统启动时创建然后一直处于活跃状态直到系统关闭
进程的实现
为了让内核管理进程所有的进程都需要用一个进程描述符进行抽象。当内核暂停一个进程的时候,就会把几个相关处理器寄存器的内容保存在进程描述符里,包括:
- 程序计数器和栈指针寄存器
- 通用寄存器
- 浮点寄存器
- 包括CPU状态信息的处理器控制器
- 用来跟踪进程对RAM访问的内存管理寄存器
当内核决定恢复一个进程的时候,他用进程描述符中合适的字段来装载CPU寄存器。因为程序计数器中所存的值指向下一条将要执行的指令,所以进程恐怕停止的地方恢复执行!
可重入内核
所有的Unix内核都是可重入的!
这意味着若干个进程可以同时在内核态下执行,当然在单处理器系统上只有一个进程在真正的执行!但是有许多进程可能在等待CPU或者某一个IO操作完成时在内核台下被阻塞!
提供可重入的一种方式就是编写函数,以便这些函数只能更改局部变量,而不更改全局数据结构。这样的函数叫做可重入函数!
如果一个硬件中断发生,可重入内核可以挂起正在执行的进程,即使这个进程处于内核态
在最简单的情况下CPU从第一条指令到最后一条指令顺序的执行内核控制路径。也就是表示内核处理系统调用异常或中断所执行的指令序列
然而当下述事情发生之一,CPU交错执行内核控制路径:
- 运行在用户态下的进程调用了一个系统调用,而相应的内核控制路径。正是这个请求没有办法立即得到满足,然后内核控制路径调用调度程序选择一个新的进程。进行调度完成后,进程切换。发生第一个内核控制路径还没有完成,而CPU又重新执行其他的内核控制路径。在这种情况下,两条控制路径代表两个不同的进程。
- 在执行当执行一个内核控制路径时,CPU检测到了一个异常:比如说访问了一个不在RAM中的页,那么第一个控制路径将会被挂起,而CPU开始执行合适的过程。比如说在这个例子中我们则是给那进程分配一个新页,并从磁盘中读取它的内容。当这个过程结束后第一个控制路径可以恢复执行,在这种情况下两个控制路径代表同一个进程在执行
- 当CPU在运行一个启用了中断的内核控制路径时,一个硬件中断发生。一个控制路径还没执行完,CPU马上开始执行另一个内核控制路径来处理这个中断。当这个中断处理程序终止时,第一个内核控制路径恢复。在这个情况下两条内核控制路径运行是同一进程的可执行上下文。所花费的系统CPU时间都算给了这个进程。然而中断处理程序无需代表这个进程运行
- 在支持抢占式调度的内核中,CPU正在运行。但是被一个更加高级的进程加入就绪队列。中断发生,调度开始。第一个内核控制路径并没有执行完。CPU代表高优先级进程又开始了另一个内核控制路径,只有把内核编译成支持抢占式调度后才有可能会出现这种情况!(你放心,咱们就是这个hhh)
进程地址空间
每个进程运行在它的私有地址空间!在用户态下运行的进程涉及到私有栈,数据区和代码区。
当在内核态运行时,进程访问内核的数据区,代码区。但是使用的是另外的私有栈。尽管看起来每个进程都在访问他们自己的私有栈,但是为了更好的进程间通信,有时进程之间也会共享部分地址空间!
Linux支持映射内存(mmap)系统调用,该系统调用将允许存放在块设备上的文件或信息映射到进程的部分地址空间。这为正常的读写传送数据方式提供了另一种选择
同步和临界区
实现可重入的内核需要利用同步机制,如果内核控制路径对某个内核数据结构进行操作被挂起时,那么其他内核控制路径就不应该对这个数据结构进行操作,否则会破坏一致性状态!
如何同步内核控制路径呢最彻底的办法就是使用非抢占式的内核(Weird huh?),其次就是禁止中断,再就是使用信号量自旋锁等内核机制来防止竞争条件!
在我们使用防止竞争条件的内核上锁机制时,需要避免死锁情况!在这里不予详细讨论!
信号与进程之间的通信
Unix信号提供了一种把系统事件报告给进程的一种机制。
有两种系统事件:
- 异步通告
- 同步错误或异常
如果进程并没有指定如何处理信号时,内核会按照信号的编号进行默认操作。有可能有以下五种默认操作:
终止进程
将执行上下文和进程地址空间的内容写入一个文件,并且终止进程
忽略信号
挂起进程
如果进程曾被暂停,则恢复它
进程管理
Unix在进程和它正在执行的程序之间做出了清晰的划分!fork和_exit这两个系统调用分别用来创建一个进程和终止,与exec类系统调用则是装入一个全新的程序!以及还有僵死进程。如果父进程丢失了跟踪子进程的情况,那么这个子进程就认为僵尸进程。内核会检查子进程是否终止。引入僵死进程的特殊状态是为了表示终止的进程。很多内核也实现了waitpid系统调用,让父进程可以显示的等待一个特殊的子进程。对于那些已经成为僵尸进程的进程,他们将会被一个以init的特殊系统进程收养进行清除!
内存管理
虚拟内存
所有新进的Unix系统都提供了一种有用的抽象:叫做虚拟内存!
它作为一种逻辑层处于应用程序的内在请求与硬件内存单元管理单元之间。虚拟内存有很多用途与优点,它可以让
- 若干进程并发执行
- 应用程序所需内存大于可用物理内存时也可以运行
- 程序集有部分代码装入内存时进程可以执行
- 允许每个进程访问可用物理内存的子集进程
- 可以共享库数据或程序或函数等一个单独内存映像
- 程序是可定位的!也就是说我们可以把程序放在物理内存中的任何地方
- 程序员可以编写与机器无关的代码!因为他们根本不需要关心物理内存的组织结构,也就是说他把物理内存进行了一层抽象
虚拟内存子系统的主要成分是虚拟地址空间进程所用的一组内存地址。不同于物理内存地址!
随机访问存储器的使用
随机访问存储器的使用分为两个部分:
一部分被专门用来存放内核映像,另一部分则由虚拟内存系统来进行处理:
- 用来满足内核对缓冲区描述服务及其它动态内核数据结构的请求
- 满足进程对一般性内存区的请求即对文件内存映射的请求
- 借助于高速缓存从磁盘或者其他缓冲设备获得较好的性能内存
内核分配器
它是一个子系统,试图满足系统中所有部分对内存的请求!其中一些请求可能来自内核其他子系统。他们需要一些内核使用的内存,还有一些请求则是来自用户程序的系统调用,以用来增加用户程序进程的地址空间!
一个好的内核内存分配器需要具有以下特点:
它必须快,实际上这是最重要的属性!因为它为所有的内核子系统所调用
必须把内存的浪费减到最少
必须努力减轻内存的碎片问题
必须能与其他内存管理子系统进行合作,以便借用和释放页框
现在已经提出了好几种内核内存分配器进程!这个可以查询其他资料!
进程的虚拟地址空间处理
进程的虚拟地址空间包括了进程可以引用的所有虚拟内存地址,内核通常用一组内存区描述符描述进程!虚拟地址空间内核分配给进程的虚拟地址空间主要有以下这几个部分:
- 组成程序的可执行代码
- 程序的初始化和未初始化的数据
- 初始程序栈
- 所需共享库的可执行代码和数据
- 堆
高速缓存
物理内存的一大优势就是用来磁盘和其它块设备的高速缓存!因为磁盘访问非常的慢,这与访问内存相比实在太长!因此磁盘通常是影响系统性能的一大瓶颈所在,最早的Unix系统中早就已经实现了一个策略就是对推迟写磁盘的时间,我们将在后续的实现中看看Linux是如何做到的!
内存寻址
引论,三个地址
下面来说说内存寻址!
程序员偶尔会引用内存地址作为访问内存单元的一种方式。我们有三种不同的地址:逻辑地址,线性地址,和物理地址
逻辑地址:指的是包含在机器语言指令中用来表示一个操作数或一条指令的地址!这种寻址方式在80X86著名的分段结构中表现得尤为具体,,它促使MSDOS程序员或Windows程序员把程序分成若干段(当然说的是汇编程序员hhh)。每一个逻辑地址都由一个段和偏移量组成!偏移量指明了从段开始的地方,到实际地址之间的距离
线性地址也被称为虚拟地址,是一个32位无符号整数(在32位平台上,自然的在64位平台上个就是64位无符号整数),可以用来表达高达4GB的地址!现行地址通常用16进制数字表示!
物理地址用来内存芯片及内存单元寻址。他们从与微处理器的地址引脚,发送到内存总线上的电信号。相对应物理地址由32位或36位无符号整数表示。内存控制单元通过一种分段单元的硬件电路把一个逻辑地址转换成一个线性地址,接着第二个称为分页单元的硬件电路把线性地址转换为一个物理地址!
硬件中的分段
从80286模型开始,英特尔微处理器以两种不同的方式执行地址转换这两种方式!分别被称为实模式和保护模式
段选择符和段寄存器一个逻辑地址有两个部分组成一个段标识符和一个段内相对地址的偏移量段标识符是一个16位长的字段也被称为段选择符为了快速方便地找到段选择符处理器提供一个叫做段寄存器的寄存器他的唯一目的是为了存放段选择符这些段寄存器被称为CS,SS,DS,ES,FS和GS。尽管只有六个段寄存器,但程序可以把同一个段的寄存器用作不同目的。方法是先把这个值保存在内存中,用完再恢复。其中有三者是有专门用途的。
CS(code segment):代码段寄存器!指向包含程序指令的段
SS(stack segmment):栈段寄存器!指向包含当前程序栈的段
DS(data segment):数据段寄存器!指向包含静态数据或者全局数据段!
CS寄存器还有一个重要的功能:它还有一个两位的字段用以指明CPU的当前特权级(Current Privilage Level)
值为零时代表最高优先级值!为三时表示最低优先级!Linux只用零级和三级,分别被称为内核态和用户态!
段描述符
每个段由八个字节的段描述符表示,他表示了一个段的特征!段描述符放在GDT或LDT中。通常只定义一个GDT而每个进程除了存放在GDP的段,以外如果还创建了附加的段,可以有自己的LDT。段序描述符字段由以下
| 标志 | 说明 |
|---|---|
| base | 表示段的首字节的线性地址 |
| G | 粒度标志!表示如果该位清零,则段大小以字节为单位。否则以4096字节的倍数。 |
| limit | 存放段中最后一个内存单元的偏移量,从而决定了段的长度。这就跟G扯上关系了: 如果既被置为零,则一个段的大小在1B到1MB之间变化,否则则在4KB到4GB之间变化 |
| S | 系统标志!如果它被清零则,这是一个系统段,存放着像LDT这种关键数据结构!否则它就是一个普通的代码段或数据段 |
| type | 描述了段的类型特征和它的存取权限 |
| DPL | 描述符特权级字段,用于限制这对这个段的存取!他表示为访问这个段要求的CPU最小优先级! |
| P | segment present标志!表示当前段并不在主存当中,Linux总是把这个标志设为一,因为他从不把整个段交换到磁盘上。 |
| D/B | 取决于是代码段还是数据段 |
| AVL | 系统使用但是已经被Linux所忽略 |
以下是Linux中被广泛使用的类型!
- 代码段描述符:表示这个段是一个代码段,它可以放在GDP或LDT中此时该描述符志S标志为一
- 数据段描述符:表示这个段描述了一个数据段,也可以被放在GDP或LDT中,S标志为1。栈段是通过一般的数据段所实现的!
- 任务状态的描述符:表示这个段的描述代表一个任务状态段,也就是TSS!这个段用来保存处理寄存器的内容
- 局部描述符表描述符:表示这个段描述符代表一个包含了LDT的段。他只会出现在GDT中!相应的type字段的值为2,S被置为零。
快速访问段描述符
我们回忆一下:逻辑地址是由一个16位段选择符和32位偏移量组成段寄存器!仅仅存放段选择符。为了加速逻辑地址到线性地址的转换,8086处理器提供了一种附加的非编程的寄存器:共六个可编程的段寄存器所使用。每一个非编程的寄存器含有八个字节的段描述符,由相应的段寄存器的段选择符来指定。每当一个段选择符被装入段寄存器时,相应的段描述符就从内存被装到对应的非编程CPU寄存器中!从那个时候起,针对那个段的逻辑地址转换就可以不用访问主存中的GDP或LDT。处理器只需要引用存放段描述符的CPU寄存器即可!仅当段寄存器的内容发生改变时,才会有必要访问GDP或LDT。这体现了一种缓存机制!
段选择符字段有三个字段名:
| 标识 | 说明 |
|---|---|
| index | 指定了放在GD T或LBT中的相应段描述符的一个入口 |
| TI | 指明断续描述符是在GDP中(TI = 0)还是在LDT中(TI = 1) |
| RPL | 请求者特权:即当相应的段选择符装入了CS寄存器中只是CPU当前的特权级!它还可以用来访问数据段时,有选择的削弱处理器的特权级分段单元。 |
分段单元
分段单元会执行以下操作:
- 它会检查段选择符的TI字段,以决定段描述符保存在哪一个描述符表中,TI字段指明段描述符市的GDP中还是在激活的LDT中
- 从段选择符的index字段中计算段描述符地址:index字段的值乘以八,这个结果与gdpr或ldtr寄存器中的内容相加。
- 把逻辑地址的偏移量与段描述符Base字段的值相加就会得到线性地址
Linux当中的分段是非常有限的!实际上分段和分页在某种程度上会显得有些多余,因为它们都可以划分进程的物理地址空间!分段可以给每一个进程分配以不同的线性空间,而分页则可以把同一线性地址空间映射到不同的物理内存。与分段相比,linux更青睐于使用分页方式:因为当所有进程使用相同的段寄存器值时,内存管理变得非常简单!也就是他们可以共享同样的一组线性地址!Linux的设计目标之一就是可以把它们移植到大多数流行的处理平台之下然而RISC体系结构对分段的支持非常有限!
Linux下的逻辑地址与线性地址是一致的:即逻辑地址的偏移量字段的值予以相应的线性地址的值总是一致的
Linux GDT
单处理器系统中只有一个GDT,而在多处理器系统中每个CPU对应一个GDT所。有的GDT都存放在cpu_gdt_table数组中:而所有GDP的地址和它们的大小(这个大小是初始化GDTR计算器使用)被存放在cpu_gdt_desp数组中!
每一个GDP的包含18个段分别指向下列的段:
- 用户态和内核态下的代码段和数数据段共四个任务状态段
- TSS,每个处理器有一个!
- 一个包含缺省局部描述符表的段,这个段是被所有进程共享的段!
- 三个局部线程存储段TLS,这种机制允许多线程应用程序使用最多三个局部与线程的数据段!
- 与高级电源管理相关的三个段
- 与支持即插即用功能的BIOS服务程序相关的五个段
- 被内核用来处理双重错误异常的特殊TSS段
Linux LDT
大多数Linux程序并不会使用局部描述符!然而在某些情况下进程仍然会需要创建自己的局部描述符表,比如说像Wine那样的程序
硬件中的分页
分页单元把线性地址转换为物理地址。其中一个关键的任务就是把请求的访问类型与线性地址的访问权限所相比较,如果这次访问是无效的,则会产生一个缺页异常!
为了效率,线性地址被分为固定长度为单位的组,称为页!页内不连续的线性地址会被映射到连续的物理地址当中去。这样内核可以指定一个页的物理地址和存取权限,而不用指定页所包含所有的线性地址的存取权限!我们通常遵循习惯使用习惯,让页来表示一组线性地址,包含这组地址中的数据。
分页单元把所有的分成固定长度的页框,有时也叫做物理页。每一个页框包含一个页,也就是说一个框的长度和一个页的长度是一致的。页框是主存的一部分,也就是存储区域。区分一个页和页框很重要,前者只是一个数据块,前者可以存放在任何页框和磁盘中。
把线性地址映射到物理地址的数据结构称为页表,页表存放在主存当中。并且启用分页单元之前就必须由内核对列表进行适当的初始化,从80386开始所有的值80X86处理器都会支持分页!它通过设置CR零寄存器的PG标志启用。当PG等于零时,线性地址就会被解释为物理地址。
32位线性地址经常会被分成三个域:
| directory目录 | table(页表) | offset偏移量 |
|---|---|---|
| 10 | 10 | 12 |
线性地址的转换分为两步走:每一步都基于一种转换表。第一种转换表被称为页目录表,第二种则是被称为页表。
使用这种二级模式的目的在于:减少每个进程页表所需要的RAM的数量!(自己想象如果给每一个信息地址的维护一个映射项的话这个页表将会有多么恐怖的大!)。页目录项和页表项有相同的结构!每项都包含下面的字段:
- present标志:如果被置为1,所指的页或页表它就在主存当中!如果该标志被置为零,则这一页并不在主存!当中如果执行一个地址转换所需的页表项或页目录项中的present被置为零,那么分页单元就会把该线性地址存放在控制寄存器CR2中,并产生14号异常缺页异常!操作系统会介入进行相应的处理。
- Field:包含页框物理地址最高二十位的字段!由于每一个页框有4kb标志的容量它的物理地址必须是4096的倍数,因此物理地址的最低12位总是零
- access:每当分页单元对应的页框进行寻址时,就会设置这个标志!当选中的页被交换出去,这个标志可以作系统所使用。分页单元从不会重置这个标志,而是必须由操作系统去做!
- read/write标志:含有页或页表的存取权限
- dirty标志:只用来列表项中每当对一个页框进行写操作时就会设置这个标识,当选中的页被交换出去,这个标志可以作系统所使用。分页单元从不会重置这个标志,而是必须由操作系统去做!
- user/supervisor标志:标志很有访问页或页表所需的特权级
- PCD和PWT标志:硬件控制硬件高速缓存处理页或页表的方式
- page size:只用于页目录项,如果被置为一则该目录页目录项指的是2mb或4mb的页框!
- global标识:只应用于页表项,这个标志是用来防止常用页从TLB高速缓存中刷新出去
PAE
常规分页机制32位地址线理论上可以寻址4GB的RAM地址空间。但是,大型的服务器需要大于4GB的RAM来同时运行数以千计的进程。
因此:Intel通过在处理器上把管脚数从32增加到36,以提高处理器的寻址能力,使其达到2^36=64GB,同时引入了一种新的分页机制PAE(Physical Address Extension,物理地址扩展)把32位线性地址转换为36位物理地址才能使用所增加的物理内存,通过设置CR4的第5位来开启对PAE的支持。引入PAE就是为了访问大于4GB的RAM,线性地址仍然是32位,而物理地址是36位。
把一个32位的虚拟地址分成4个部分:
- 0-11:页内偏移
- 12-20:页表(Page Table)
- 21-29:页表目录表(Page Table Directory)
- 30-31:页目录指针表(Page Directory Pointer Table)
硬件高速缓存
这是为了缓解微处理器的频率与访问RAM芯片的频率相差过大的矛盾所引入的!为了缩小CPU和RAM之间的速度不匹配,引入了硬件高速缓存内存机制:硬件高速缓存则是基于著名的局部性原理,该原理既适用于程序结构,也适用于数据结构!这表明由于程序的循环结构与相关数组可以组织成线性数组,最近最常用的相邻地址在最近的将来又被用到的可能性极大,因此引入小而快的内存来存放最近最常使用的代码和数据变得很有意义!
高速缓存又被细分为行的子集。在一种极端情况下高速缓存可以是直接映射的这是主存中的一个行,总是存放在高速缓存中完全相同的位置!在另一种极端情况下高速缓存是充分关联的,这意味着主存中的任意一个行,可以存放在高速缓存中的任意位置!
TLB
除了通用硬件高速缓存之外,还有一种转换后缓冲器或TLB的高速缓存用于加快线性地址转换
当线性地址第一次被使用时,通过慢速访问RAM中的页表,计算出相应的物理地址。同时物理地址被存放在一个TLB表象中,以便以后对同一个线性地址的引用时,得到快速的转换。
在多处理器系统中每个CPU都有自己的TLB这叫做CPU的本地TLB。与硬件高速缓存相反TLB的对应项不必同步,这是因为运行在现有CPU上可以使用同一个线性地址与不同的物理地址发生联系!
Linux中的分页
Linux从2.6开始使用四级分页:
- 页全局目录(Page Global Directory)
- 页上级目录(Page Upper Directory)
- 页中间目录(Page Middle Directory)
- 页表(Page Table)
页全局目录包含若干页上级目录的地址;
页上级目录又依次包含若干页中间目录的地址;
而页中间目录又包含若干页表的地址;
每一个页表项指向一个页框。
因此线性地址因此被分成五个部分,而每一部分的大小与具体的计算机体系结构有关。
页表类型定义pgd_t、pmd_t、pud_t和pte_t
Linux分别采用pgd_t、pmd_t、pud_t和pte_t四种数据结构来表示页全局目录项、页上级目录项、页中间目录项和页表项。这四种数据结构本质上都是无符号长整型unsigned long!
Linux为了更严格数据类型检查,将无符号长整型unsigned long分别封装成四种不同的页表项。如果不采用这种方法,那么一个无符号长整型数据可以传入任何一个与四种页表相关的函数或宏中,这将大大降低程序的健壮性。
pgprot_t是另一个64位(PAE激活时)或32位(PAE禁用时)的数据类型,它表示与一个单独表项相关的保护标志。
首先我们查看一下子这些类型是如何定义的
pteval_t,pmdval_t,pudval_t,pgdval_t
#ifndef __ASSEMBLY__
#include <linux/types.h>
/*
* These are used to make use of C type-checking..
*/
typedef unsigned long pteval_t;
typedef unsigned long pmdval_t;
typedef unsigned long pudval_t;
typedef unsigned long pgdval_t;
typedef unsigned long pgprotval_t;
typedef struct { pteval_t pte; } pte_t;
#endif /* !__ASSEMBLY__ */pgd_t、pmd_t、pud_t和pte_t
typedef struct { pgdval_t pgd; } pgd_t;
static inline pgd_t native_make_pgd(pgdval_t val)
{
return (pgd_t) { val };
}
static inline pgdval_t native_pgd_val(pgd_t pgd)
{
return pgd.pgd;
}
static inline pgdval_t pgd_flags(pgd_t pgd)
{
return native_pgd_val(pgd) & PTE_FLAGS_MASK;
}
#if CONFIG_PGTABLE_LEVELS > 3
typedef struct { pudval_t pud; } pud_t;
static inline pud_t native_make_pud(pmdval_t val)
{
return (pud_t) { val };
}
static inline pudval_t native_pud_val(pud_t pud)
{
return pud.pud;
}
#else
#include <asm-generic/pgtable-nopud.h>
static inline pudval_t native_pud_val(pud_t pud)
{
return native_pgd_val(pud.pgd);
}
#endif
#if CONFIG_PGTABLE_LEVELS > 2
typedef struct { pmdval_t pmd; } pmd_t;
static inline pmd_t native_make_pmd(pmdval_t val)
{
return (pmd_t) { val };
}
static inline pmdval_t native_pmd_val(pmd_t pmd)
{
return pmd.pmd;
}
#else
#include <asm-generic/pgtable-nopmd.h>
static inline pmdval_t native_pmd_val(pmd_t pmd)
{
return native_pgd_val(pmd.pud.pgd);
}
#endif
static inline pudval_t pud_pfn_mask(pud_t pud)
{
if (native_pud_val(pud) & _PAGE_PSE)
return PHYSICAL_PUD_PAGE_MASK;
else
return PTE_PFN_MASK;
}
static inline pudval_t pud_flags_mask(pud_t pud)
{
return ~pud_pfn_mask(pud);
}
static inline pudval_t pud_flags(pud_t pud)
{
return native_pud_val(pud) & pud_flags_mask(pud);
}
static inline pmdval_t pmd_pfn_mask(pmd_t pmd)
{
if (native_pmd_val(pmd) & _PAGE_PSE)
return PHYSICAL_PMD_PAGE_MASK;
else
return PTE_PFN_MASK;
}
static inline pmdval_t pmd_flags_mask(pmd_t pmd)
{
return ~pmd_pfn_mask(pmd);
}
static inline pmdval_t pmd_flags(pmd_t pmd)
{
return native_pmd_val(pmd) & pmd_flags_mask(pmd);
}
static inline pte_t native_make_pte(pteval_t val)
{
return (pte_t) { .pte = val };
}
static inline pteval_t native_pte_val(pte_t pte)
{
return pte.pte;
}
static inline pteval_t pte_flags(pte_t pte)
{
return native_pte_val(pte) & PTE_FLAGS_MASK;
}xxx_val和__xxx
五个类型转换宏(_ pte、_ pmd、_ pud、_ pgd和__ pgprot)把一个无符号整数转换成所需的类型。
另外的五个类型转换宏(pte_val,pmd_val, pud_val, pgd_val和pgprot_val)执行相反的转换,即把上面提到的四种特殊的类型转换成一个无符号整数。
#define pgd_val(x) native_pgd_val(x)
#define __pgd(x) native_make_pgd(x)
#ifndef __PAGETABLE_PUD_FOLDED
#define pud_val(x) native_pud_val(x)
#define __pud(x) native_make_pud(x)
#endif
#ifndef __PAGETABLE_PMD_FOLDED
#define pmd_val(x) native_pmd_val(x)
#define __pmd(x) native_make_pmd(x)
#endif
#define pte_val(x) native_pte_val(x)
#define __pte(x) native_make_pte(x) 这里需要区别指向页表项的指针和页表项所代表的数据。以pgd_t类型为例子,如果已知一个pgd_t类型的指针pgd,那么通过pgd_val(*pgd)即可获得该页表项(也就是一个无符号长整型数据),这里利用了面向对象的思想。
页表描述宏
参照arch/x86/include/asm/pgtable_64
linux中使用下列宏简化了页表处理,对于每一级页表都使用有以下三个关键描述宏:
| 宏字段 | 描述 |
|---|---|
| XXX_SHIFT | 指定Offset字段的位数 |
| XXX_SIZE | 页的大小 |
| XXX_MASK | 用以屏蔽Offset字段的所有位。 |
我们的四级页表,对应的宏分别由PAGE,PMD,PUD,PGDIR
| 宏字段前缀 | 描述 |
|---|---|
| PGDIR | 页全局目录(Page Global Directory) |
| PUD | 页上级目录(Page Upper Directory) |
| PMD | 页中间目录(Page Middle Directory) |
| PAGE | 页表(Page Table) |
PAGE宏–页表(Page Table)
| 字段 | 描述 |
|---|---|
| PAGE_SHIFT | 指定Offset字段的位数 |
| PAGE_SIZE | 页的大小 |
| PAGE_MASK | 用以屏蔽Offset字段的所有位。 |
定义如下,在/arch/x86/include/asm/page_types.h文件中
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))当用于80x86处理器时,PAGE_SHIFT返回的值为12。
由于页内所有地址都必须放在Offset字段, 因此80x86系统的页的大小PAGE_SIZE是2^12=4096字节。
PAGE_MASK宏产生的值为0xfffff000,用以屏蔽Offset字段的所有位。
PMD-Page Middle Directory (页目录)
| 字段 | 描述 |
|---|---|
| PMD_SHIFT | 指定线性地址的Offset和Table字段的总位数;换句话说,是页中间目录项可以映射的区域大小的对数 |
| PMD_SIZE | 用于计算由页中间目录的一个单独表项所映射的区域大小,也就是一个页表的大小 |
| PMD_MASK | 用于屏蔽Offset字段与Table字段的所有位 |
当PAE 被禁用时,PMD_SHIFT 产生的值为22(来自Offset 的12 位加上来自Table 的10 位),
PMD_SIZE 产生的值为222 或 4 MB,
PMD_MASK产生的值为 0xffc00000。
相反,当PAE被激活时,
PMD_SHIFT 产生的值为21 (来自Offset的12位加上来自Table的9位),
PMD_SIZE 产生的值为2^21 或2 MB
PMD_MASK产生的值为 0xffe00000。
大型页不使用最后一级页表,所以产生大型页尺寸的LARGE_PAGE_SIZE 宏等于PMD_SIZE(2PMD_SHIFT),而在大型页地址中用于屏蔽Offset字段和Table字段的所有位的LARGE_PAGE_MASK宏,就等于PMD_MASK。
PUD_SHIFT-页上级目录(Page Upper Directory)
| 字段 | 描述 |
|---|---|
| PUD_SHIFT | 确定页上级目录项能映射的区域大小的位数 |
| PUD_SIZE | 用于计算页全局目录中的一个单独表项所能映射的区域大小。 |
| PUD_MASK | 用于屏蔽Offset字段,Table字段,Middle Air字段和Upper Air字段的所有位 |
在80x86处理器上,PUD_SHIFT总是等价于PMD_SHIFT,而PUD_SIZE则等于4MB或2MB。
PGDIR_SHIFT-页全局目录(Page Global Directory)
| 字段 | 描述 |
|---|---|
| PGDIR_SHIFT | 确定页全局页目录项能映射的区域大小的位数 |
| PGDIR_SIZE | 用于计算页全局目录中一个单独表项所能映射区域的大小 |
| PGDIR_MASK | 用于屏蔽Offset, Table,Middle Air及Upper Air的所有位 |
当PAE 被禁止时,
PGDIR_SHIFT 产生的值为22(与PMD_SHIFT 和PUD_SHIFT 产生的值相同),
PGDIR_SIZE 产生的值为 222 或 4 MB,
PGDIR_MASK 产生的值为 0xffc00000。
相反,当PAE被激活时,
PGDIR_SHIFT 产生的值为30 (12 位Offset 加 9 位Table再加 9位 Middle Air),
PGDIR_SIZE 产生的值为230 或 1 GB
PGDIR_MASK产生的值为0xc0000000
PTRS_PER_PTE, PTRS_PER_PMD, PTRS_PER_PUD以及PTRS_PER_PGD
用于计算页表、页中间目录、页上级目录和页全局目录表中表项的个数。当PAE被禁止时,它们产生的值分别为1024,1,1和1024。当PAE被激活时,产生的值分别为512,512,1和4。
页表处理函数
内核还提供了许多宏和函数用于读或修改页表表项:
- 如果相应的表项值为0,那么,宏pte_none、pmd_none、pud_none和 pgd_none产生的值为1,否则产生的值为0。
- 宏pte_clear、pmd_clear、pud_clear和 pgd_clear清除相应页表的一个表项,由此禁止进程使用由该页表项映射的线性地址。ptep_get_and_clear( )函数清除一个页表项并返回前一个值。
- set_pte,set_pmd,set_pud和set_pgd向一个页表项中写入指定的值。set_pte_atomic与set_pte作用相同,但是当PAE被激活时它同样能保证64位的值能被原子地写入。
- 如果a和b两个页表项指向同一页并且指定相同访问优先级,pte_same(a,b)返回1,否则返回0。
- 如果页中间目录项指向一个大型页(2MB或4MB),pmd_large(e)返回1,否则返回0。
宏pmd_bad由函数使用并通过输入参数传递来检查页中间目录项。如果目录项指向一个不能使用的页表,也就是说,如果至少出现以下条件中的一个,则这个宏产生的值为1:
- 页不在主存中(Present标志被清除)。
- 页只允许读访问(Read/Write标志被清除)。
- Acessed或者Dirty位被清除(对于每个现有的页表,Linux总是
强制设置这些标志)。
pud_bad宏和pgd_bad宏总是产生0。没有定义pte_bad宏,因为页表项引用一个不在主存中的页,一个不可写的页或一个根本无法访问的页都是合法的。
如果一个页表项的Present标志或者Page Size标志等于1,则pte_present宏产生的值为1,否则为0。
前面讲过页表项的Page Size标志对微处理器的分页部件来讲没有意义,然而,对于当前在主存中却又没有读、写或执行权限的页,内核将其Present和Page Size分别标记为0和1。
这样,任何试图对此类页的访问都会引起一个缺页异常,因为页的Present标志被清0,而内核可以通过检查Page Size的值来检测到产生异常并不是因为缺页。
如果相应表项的Present标志等于1,也就是说,如果对应的页或页表被装载入主存,pmd_present宏产生的值为1。pud_present宏和pgd_present宏产生的值总是1。
查询页表项中任意一个标志的当前值
下表中列出的函数用来查询页表项中任意一个标志的当前值;除了pte_file()外,其他函数只有在pte_present返回1的时候,才能正常返回页表项中任意一个标志。
| 函数名称 | 说明 |
|---|---|
| pte_user( ) | 读 User/Supervisor 标志 |
| pte_read( ) | 读 User/Supervisor 标志(表示 80x86 处理器上的页不受读的保护) |
| pte_write( ) | 读 Read/Write 标志 |
| pte_exec( ) | 读 User/Supervisor 标志( 80x86 处理器上的页不受代码执行的保护) |
| pte_dirty( ) | 读 Dirty 标志 |
| pte_young( ) | 读 Accessed 标志 |
| pte_file( ) | 读 Dirty 标志(当 Present 标志被清除而 Dirty 标志被设置时,页属于一个非线性磁盘文件映射) |
2.3.2 设置页表项中各标志的值
下表列出的另一组函数用于设置页表项中各标志的值
| 函数名称 | 说明 |
|---|---|
| mk_pte_huge( ) | 设置页表项中的 Page Size 和 Present 标志 |
| pte_wrprotect( ) | 清除 Read/Write 标志 |
| pte_rdprotect( ) | 清除 User/Supervisor 标志 |
| pte_exprotect( ) | 清除 User/Supervisor 标志 |
| pte_mkwrite( ) | 设置 Read/Write 标志 |
| pte_mkread( ) | 设置 User/Supervisor 标志 |
| pte_mkexec( ) | 设置 User/Supervisor 标志 |
| pte_mkclean( ) | 清除 Dirty 标志 |
| pte_mkdirty( ) | 设置 Dirty 标志 |
| pte_mkold( ) | 清除 Accessed 标志(把此页标记为未访问) |
| pte_mkyoung( ) | 设置 Accessed 标志(把此页标记为访问过) |
| pte_modify(p,v) | 把页表项 p 的所有访问权限设置为指定的值 |
| ptep_set_wrprotect() | 与 pte_wrprotect( ) 类似,但作用于指向页表项的指针 |
| ptep_set_access_flags( ) | 如果 Dirty 标志被设置为 1 则将页的访问权设置为指定的值,并调用flush_tlb_page() 函数 |
| ptep_mkdirty() | 与 pte_mkdirty( ) 类似,但作用于指向页表项的指针。 |
| ptep_test_and_clear_dirty( ) | 与 pte_mkclean( ) 类似,但作用于指向页表项的指针并返回 Dirty 标志的旧值 |
| ptep_test_and_clear_young( ) | 与 pte_mkold( ) 类似,但作用于指向页表项的指针并返回 Accessed标志的旧值 |
宏函数-把一个页地址和一组保护标志组合成页表项,或者执行相反的操作
现在,我们来讨论下表中列出的宏,它们把一个页地址和一组保护标志组合成页表项,或者执行相反的操作,从一个页表项中提取出页地址。请注意这其中的一些宏对页的引用是通过 “页描述符”的线性地址,而不是通过该页本身的线性地址。
| 宏名称 | 说明 |
|---|---|
| pgd_index(addr) | 找到线性地址 addr 对应的的目录项在页全局目录中的索引(相对位置) |
| pgd_offset(mm, addr) | 接收内存描述符地址 mm 和线性地址 addr 作为参数。这个宏产生地址addr 在页全局目录中相应表项的线性地址;通过内存描述符 mm 内的一个指针可以找到这个页全局目录 |
| pgd_offset_k(addr) | 产生主内核页全局目录中的某个项的线性地址,该项对应于地址 addr |
| pgd_page(pgd) | 通过页全局目录项 pgd 产生页上级目录所在页框的页描述符地址。在两级或三级分页系统中,该宏等价于 pud_page() ,后者应用于页上级目录项 |
| pud_offset(pgd, addr) | 参数为指向页全局目录项的指针 pgd 和线性地址 addr 。这个宏产生页上级目录中目录项 addr 对应的线性地址。在两级或三级分页系统中,该宏产生 pgd ,即一个页全局目录项的地址 |
| pud_page(pud) | 通过页上级目录项 pud 产生相应的页中间目录的线性地址。在两级分页系统中,该宏等价于 pmd_page() ,后者应用于页中间目录项 |
| pmd_index(addr) | 产生线性地址 addr 在页中间目录中所对应目录项的索引(相对位置) |
| pmd_offset(pud, addr) | 接收指向页上级目录项的指针 pud 和线性地址 addr 作为参数。这个宏产生目录项 addr 在页中间目录中的偏移地址。在两级或三级分页系统中,它产生 pud ,即页全局目录项的地址 |
| pmd_page(pmd) | 通过页中间目录项 pmd 产生相应页表的页描述符地址。在两级或三级分页系统中, pmd 实际上是页全局目录中的一项 |
| mk_pte(p,prot) | 接收页描述符地址 p 和一组访问权限 prot 作为参数,并创建相应的页表项 |
| pte_index(addr) | 产生线性地址 addr 对应的表项在页表中的索引(相对位置) |
| pte_offset_kernel(dir,addr) | 线性地址 addr 在页中间目录 dir 中有一个对应的项,该宏就产生这个对应项,即页表的线性地址。另外,该宏只在主内核页表上使用 |
| pte_offset_map(dir, addr) | 接收指向一个页中间目录项的指针 dir 和线性地址 addr 作为参数,它产生与线性地址 addr 相对应的页表项的线性地址。如果页表被保存在高端存储器中,那么内核建立一个临时内核映射,并用 pte_unmap 对它进行释放。 pte_offset_map_nested 宏和 pte_unmap_nested 宏是相同的,但它们使用不同的临时内核映射 |
| pte_page( x ) | 返回页表项 x 所引用页的描述符地址 |
| pte_to_pgoff( pte ) | 从一个页表项的 pte 字段内容中提取出文件偏移量,这个偏移量对应着一个非线性文件内存映射所在的页 |
| pgoff_to_pte(offset ) | 为非线性文件内存映射所在的页创建对应页表项的内容 |
简化页表项的创建和撤消
下面我们罗列最后一组函数来简化页表项的创建和撤消。当使用两级页表时,创建或删除一个页中间目录项是不重要的。如本节前部分所述,页中间目录仅含有一个指向下属页表的目录项。所以,页中间目录项只是页全局目录中的一项而已。然而当处理页表时,创建一个页表项可能很复杂,因为包含页表项的那个页表可能就不存在。在这样的情况下,有必要分配一个新页框,把它填写为 0 ,并把这个表项加入。
如果 PAE 被激活,内核使用三级页表。当内核创建一个新的页全局目录时,同时也分配四个相应的页中间目录;只有当父页全局目录被释放时,这四个页中间目录才得以释放。当使用两级或三级分页时,页上级目录项总是被映射为页全局目录中的一个单独项。与以往一样,下表中列出的函数描述是针对 80x86 构架的。
| 函数名称 | 说明 |
|---|---|
| pgd_alloc( mm ) | 分配一个新的页全局目录。如果 PAE 被激活,它还分配三个对应用户态线性地址的子页中间目录。参数 mm( 内存描述符的地址 )在 80x86 构架上被忽略 |
| pgd_free( pgd) | 释放页全局目录中地址为 pgd 的项。如果 PAE 被激活,它还将释放用户态线性地址对应的三个页中间目录 |
| pud_alloc(mm, pgd, addr) | 在两级或三级分页系统下,这个函数什么也不做:它仅仅返回页全局目录项 pgd 的线性地址 |
| pud_free(x) | 在两级或三级分页系统下,这个宏什么也不做 |
| pmd_alloc(mm, pud, addr) | 定义这个函数以使普通三级分页系统可以为线性地址 addr 分配一个新的页中间目录。如果 PAE 未被激活,这个函数只是返回输入参数 pud 的值,也就是说,返回页全局目录中目录项的地址。如果 PAE 被激活,该函数返回线性地址 addr 对应的页中间目录项的线性地址。参数 mm 被忽略 |
| pmd_free(x) | 该函数什么也不做,因为页中间目录的分配和释放是随同它们的父全局目录一同进行的 |
| pte_alloc_map(mm, pmd, addr) | 接收页中间目录项的地址 pmd 和线性地址 addr 作为参数,并返回与 addr 对应的页表项的地址。如果页中间目录项为空,该函数通过调用函数 pte_alloc_one( ) 分配一个新页表。如果分配了一个新页表, addr 对应的项就被创建,同时 User/Supervisor 标志被设置为 1 。如果页表被保存在高端内存,则内核建立一个临时内核映射,并用 pte_unmap 对它进行释放 |
| pte_alloc_kernel(mm, pmd, addr) | 如果与地址 addr 相关的页中间目录项 pmd 为空,该函数分配一个新页表。然后返回与 addr 相关的页表项的线性地址。该函数仅被主内核页表使用 |
| pte_free(pte) | 释放与页描述符指针 pte 相关的页表 |
| pte_free_kernel(pte) | 等价于 pte_free( ) ,但由主内核页表使用 |
| clear_page_range(mmu, start,end) | 从线性地址 start 到 end 通过反复释放页表和清除页中间目录项来清除进程页表的内容 |
处理硬件高速缓存与TLB
void flush_tlb_all(void)最严格的刷新。在这个接口运行后,任何以前的页表修改都会对cpu可见。
这通常是在内核页表被改变时调用的,因为这种转换在本质上是“全局”的。
void flush_tlb_mm(struct mm_struct *mm)这个接口从TLB中刷新整个用户地址空间。在运行后,这个接口必须确保 以前对地址空间‘mm’的任何页表修改对cpu来说是可见的。也就是说,在 运行后,TLB中不会有‘mm’的页表项。
这个接口被用来处理整个地址空间的页表操作,比如在fork和exec过程 中发生的事情。
void flush_tlb_range(struct vm_area_struct *vma, unsigned long start, unsigned long end)这里我们要从TLB中刷新一个特定范围的(用户)虚拟地址转换。在运行后, 这个接口必须确保以前对‘start’到‘end-1’范围内的地址空间‘vma->vm_mm’ 的任何页表修改对cpu来说是可见的。也就是说,在运行后,TLB中不会有 ‘mm’的页表项用于‘start’到‘end-1’范围内的虚拟地址。
“vma”是用于该区域的备份存储。主要是用于munmap()类型的操作。
提供这个接口是希望端口能够找到一个合适的有效方法来从TLB中删除多 个页面大小的转换,而不是让内核为每个可能被修改的页表项调用 flush_tlb_page(见下文)。
void flush_tlb_page(struct vm_area_struct *vma, unsigned long addr)这一次我们需要从TLB中删除PAGE_SIZE大小的转换。‘vma’是Linux用来跟 踪进程的mmap区域的支持结构体,地址空间可以通过vma->vm_mm获得。另 外,可以通过测试(vma->vm_flags & VM_EXEC)来查看这个区域是否是 可执行的(因此在split-tlb类型的设置中可能在“指令TLB”中)。
在运行后,这个接口必须确保之前对用户虚拟地址“addr”的地址空间 “vma->vm_mm”的页表修改对cpu来说是可见的。也就是说,在运行后,TLB 中不会有虚拟地址‘addr’的‘vma->vm_mm’的页表项。
这主要是在故障处理时使用。
void update_mmu_cache(struct vm_area_struct *vma, unsigned long address, pte_t *ptep)在每个缺页异常结束时,这个程序被调用,以告诉体系结构特定的代码,在 软件页表中,在地址空间“vma->vm_mm”的虚拟地址“地址”处,现在存在 一个翻译。
可以用它所选择的任何方式使用这个信息来进行移植。例如,它可以使用这 个事件来为软件管理的TLB配置预装TLB转换。目前sparc64移植就是这么干 的。
接下来,我们有缓存刷新接口。一般来说,当Linux将现有的虚拟->物理映射 改变为新的值时,其顺序将是以下形式之一:
1) flush_cache_mm(mm);
change_all_page_tables_of(mm);
flush_tlb_mm(mm);
2) flush_cache_range(vma, start, end);
change_range_of_page_tables(mm, start, end);
flush_tlb_range(vma, start, end);
3) flush_cache_page(vma, addr, pfn);
set_pte(pte_pointer, new_pte_val);
flush_tlb_page(vma, addr); 缓存级别的刷新将永远是第一位的,因为这允许我们正确处理那些缓存严格, 且在虚拟地址被从缓存中刷新时要求一个虚拟地址的虚拟->物理转换存在的系统。 HyperSparc cpu就是这样一个具有这种属性的cpu。
下面的缓存刷新程序只需要在特定的cpu需要的范围内处理缓存刷新。大多数 情况下,这些程序必须为cpu实现,这些cpu有虚拟索引的缓存,当虚拟->物 理转换被改变或移除时:必须被刷新。因此,例如,IA32处理器的物理索引的物理标记的缓存没有必要实现这些接口,因为这些缓存是完全同步的,并且不依赖于翻译信息。
下面逐个列出这些程序:
void flush_cache_mm(struct mm_struct *mm)这个接口将整个用户地址空间从高速缓存中刷掉。也就是说,在运行后, 将没有与‘mm’相关的缓存行。
这个接口被用来处理整个地址空间的页表操作,比如在退出和执行过程 中发生的事情。
void flush_cache_dup_mm(struct mm_struct *mm)这个接口将整个用户地址空间从高速缓存中刷新掉。也就是说,在运行 后,将没有与‘mm’相关的缓存行。
这个接口被用来处理整个地址空间的页表操作,比如在fork过程中发生 的事情。
这个选项与flush_cache_mm分开,以允许对VIPT缓存进行一些优化。
void flush_cache_range(struct vm_area_struct *vma, unsigned long start, unsigned long end)在这里,我们要从缓存中刷新一个特定范围的(用户)虚拟地址。运行 后,在“start”到“end-1”范围内的虚拟地址的“vma->vm_mm”的缓存中 将没有页表项。
“vma”是被用于该区域的备份存储。主要是用于munmap()类型的操作。
提供这个接口是希望端口能够找到一个合适的有效方法来从缓存中删 除多个页面大小的区域, 而不是让内核为每个可能被修改的页表项调 用 flush_cache_page (见下文)。
void flush_cache_page(struct vm_area_struct *vma, unsigned long addr, unsigned long pfn)这一次我们需要从缓存中删除一个PAGE_SIZE大小的区域。“vma”是 Linux用来跟踪进程的mmap区域的支持结构体,地址空间可以通过 vma->vm_mm获得。另外,我们可以通过测试(vma->vm_flags & VM_EXEC)来查看这个区域是否是可执行的(因此在“Harvard”类 型的缓存布局中可能是在“指令缓存”中)。
“pfn”表示“addr”所对应的物理页框(通过PAGE_SHIFT左移这个 值来获得物理地址)。正是这个映射应该从缓存中删除。
在运行之后,对于虚拟地址‘addr’的‘vma->vm_mm’,在缓存中不会 有任何页表项,它被翻译成‘pfn’。
这主要是在故障处理过程中使用。
void flush_cache_kmaps(void)只有在平台使用高位内存的情况下才需要实现这个程序。它将在所有的 kmaps失效之前被调用。
运行后,内核虚拟地址范围PKMAP_ADDR(0)到PKMAP_ADDR(LAST_PKMAP) 的缓存中将没有页表项。
这个程序应该在asm/highmem.h中实现。
void flush_cache_vmap(unsigned long start, unsigned long end)void flush_cache_vunmap(unsigned long start, unsigned long end)在这里,在这两个接口中,我们从缓存中刷新一个特定范围的(内核) 虚拟地址。运行后,在“start”到“end-1”范围内的虚拟地址的内核地 址空间的缓存中不会有页表项。
这两个程序中的第一个是在vmap_range()安装了页表项之后调用的。 第二个是在vunmap_range()删除页表项之前调用的。
这是处理页表的一些API:
void copy_user_page(void *to, void *from, unsigned long addr, struct page *page)` `void clear_user_page(void *to, unsigned long addr, struct page *page)这两个程序在用户匿名或COW页中存储数据。它允许一个端口有效地 避免用户空间和内核之间的D-cache别名问题。
例如,一个端口可以在复制过程中把“from”和“to”暂时映射到内核 的虚拟地址上。这两个页面的虚拟地址的选择方式是,内核的加载/存 储指令发生在虚拟地址上,而这些虚拟地址与用户的页面映射是相同 的“颜色”。例如,Sparc64就使用这种技术。
“addr”参数告诉了用户最终要映射这个页面的虚拟地址,“page”参 数给出了一个指向目标页结构体的指针。
如果D-cache别名不是问题,这两个程序可以简单地直接调用 memcpy/memset而不做其他事情。
void flush_dcache_page(struct page *page)任何时候,当内核写到一个页面缓存页,或者内核要从一个页面缓存页中读出,并且这个页面的用户空间共享/可写映射可能存在时, 这个程序就会被调用。
这个程序只需要为有可能被映射到用户进程的地址空间的 页面缓存调用。因此,例如,处理页面缓存中vfs符号链 接的VFS层代码根本不需要调用这个接口。“内核写入页面缓存的页面”这句话的意思是,具体来说,内核执行存 储指令,在该页面的页面->虚拟映射处弄脏该页面的数据。在这里,通 过刷新的手段处理D-cache的别名是很重要的,以确保这些内核存储对 该页的用户空间映射是可见的。推论的情况也同样重要,如果有用户对这个文件有共享+可写的映射, 我们必须确保内核对这些页面的读取会看到用户所做的最新的存储。
如果D-cache别名不是一个问题,这个程序可以简单地定义为该架构上 的nop。在page->flags (PG_arch_1)中有一个位是“架构私有”。内核保证, 对于分页缓存的页面,当这样的页面第一次进入分页缓存时,它将清除这个位。这使得这些接口可以更有效地被实现。如果目前没有用户进程映射这个 页面,它允许我们“推迟”(也许是无限期)实际的刷新过程。请看 sparc64的flush_dcache_page和update_mmu_cache实现,以了解如 何做到这一点。
这个想法是,首先在flush_dcache_page()时,如果page->mapping->i_mmap 是一个空树,只需标记架构私有页标志位。之后,在update_mmu_cache() 中,会对这个标志位进行检查,如果设置了,就进行刷新,并清除标志位。通常很重要的是,如果你推迟刷新,实际的刷新发生在同一个 CPU上,因为它将cpu存储到页面上,使其变脏。同样,请看 sparc64关于如何处理这个问题的例子。
void flush_dcache_folio(struct folio *folio)该函数的调用情形与flush_dcache_page()相同。它允许架构针对刷新整个 folio页面进行优化,而不是一次刷新一页。
void copy_to_user_page(struct vm_area_struct *vma, struct page *page, unsigned long user_vaddr, void *dst, void *src, int len)` `void copy_from_user_page(struct vm_area_struct *vma, struct page *page, unsigned long user_vaddr, void *dst, void *src, int len)当内核需要复制任意的数据进出任意的用户页时(比如ptrace()),它将使 用这两个程序。
任何必要的缓存刷新或其他需要发生的一致性操作都应该在这里发生。如果 处理器的指令缓存没有对cpu存储进行窥探,那么你很可能需要为 copy_to_user_page()刷新指令缓存。
void flush_anon_page(struct vm_area_struct *vma, struct page *page, unsigned long vmaddr)当内核需要访问一个匿名页的内容时,它会调用这个函数(目前只有 get_user_pages())。注意:flush_dcache_page()故意对匿名页不起作 用。默认的实现是nop(对于所有相干的架构应该保持这样)。对于不一致性 的架构,它应该刷新vmaddr处的页面缓存。
void flush_icache_range(unsigned long start, unsigned long end)当内核存储到它将执行的地址中时(例如在加载模块时),这个函数被调用。
如果icache不对存储进行窥探,那么这个程序将需要对其进行刷新。
void flush_icache_page(struct vm_area_struct *vma, struct page *page)flush_icache_page的所有功能都可以在flush_dcache_page和update_mmu_cache 中实现。在未来,我们希望能够完全删除这个接口。
最后一类API是用于I/O到内核内特意设置的别名地址范围。这种别名是通过使用 vmap/vmalloc API设置的。由于内核I/O是通过物理页进行的,I/O子系统假定用户 映射和内核偏移映射是唯一的别名。这对vmap别名来说是不正确的,所以内核中任何 试图对vmap区域进行I/O的东西都必须手动管理一致性。它必须在做I/O之前刷新vmap 范围,并在I/O返回后使其失效。
void flush_kernel_vmap_range(void *vaddr, int size)刷新vmap区域中指定的虚拟地址范围的内核缓存。这是为了确保内核在vmap范围 内修改的任何数据对物理页是可见的。这个设计是为了使这个区域可以安全地执 行I/O。注意,这个API并 没有 刷新该区域的偏移映射别名。
void invalidate_kernel_vmap_range(void *vaddr, int size) invalidates在vmap区域的一个给定的虚拟地址范围的缓存,这可以防止处理器在物理页的I/O 发生时通过投机性地读取数据而使缓存变脏。这只对读入vmap区域的数据是必要的。
Reference
物理地址扩展(PAE)分页机制 - 冷烟花 - 博客园 (cnblogs。com)分页机制 常规分页机制32位地址线理论上可以寻址4GB的RAM地址空间%2C但是%2C大型的服务器需要大雨4GB的RAM来同时运行数以千计的进程%2C因此%2CIntel通过在处理器上把管脚数从32增加到36%2C以提高处理器的寻址能力%2C使其达到2^36%3D64GB%2C同时引入了一种新的分页机制PAE,(Physical Address Extension%2C物理地址扩展)把32位线性地址转换为36位物理地址才能使用所增加的物理内存%2C通过设置CR4的第5位来开启对PAE的支持。引入PAE就是为了访问大于4GB的RAM%2C线性地址仍然是32位%2C而物理地址是36位。)
PAE 分页模式详解 - jack。chen - 博客园 (cnblogs。com)
Linux分页机制之分页机制的实现详解—Linux内存管理(八) - yooooooo - 博客园 (cnblogs.com)
进程
下面开始讨论一个非常重要的抽象:这在我们前边已经提到过了的!也就是进程!
进程在使用中常有几个不同的含义,比如说在一般的操作系统教科书中给出了通用定义是:
进程是程序执行的一个实例
进程就像生命一般他们被产生,有或多或少的有效生命周期,,可以产生一个或者多个子进程,但是它们最终都会死亡!从内核观点上看进程的目的就是分配系统资源的一个实体
当一个进程创建时,它几乎与父进程相同。它接收父进程地址空间的一个逻辑拷贝,并开始执行父进程相同的代码!
Linux使用轻量级进程,对多线程应用程序提供了更好的支持。两个轻量级进程基本上可以共享一些资源诸如打开的文件,地址空间等。只要其中一个修改了共享资源,另一个就立即查看各种修改
进程描述符
为了管理进程,内核必须对每个进程所做的事情有清楚的描述!
首先我们要看的是进程的状态:顾名思义当我们查看源码时,进程描述符中的state字段就描述了进程当前的状态。它由一组标志组成。有以下几种可能的状态:
- 可运行状态(TASK_RUNNING):其进程要么在CPU上执行要么准备执行与
- 可中断的等待状态(TASK_INTERRUPTIBLE):进程被挂起直到某个条件为真,产生一个硬件中断,释放进程,正等待的系统资源或传递一个信号都是可以唤醒进程的条件
- 不可中断的等待状态(TASK_UNINTERRUPTIBLE):与可中断的等待状态类似,但是有一个例外:把信号传递到睡眠进程不能改变它的状态。这种状态很少用到,但在一些特定的情况下,也就是要求进程必须等待直到一个不能被中断的事件发生时,这种状态很有用!例如当进程打开一个设备文件,设备驱动程序开始探测相应的硬件设备时会用到这个状态,探测完成以前设备驱动程序是不可以被中断的!否则硬件设备会处于一种不可预知的状态!
- 暂停状态(TASK_STOPPED):进程的执行被暂停,当进程接收到这四个信号:SIGSTOP,SIGTSTP,SIGTTIN,SIGTTOU,进入暂停状态
- 跟踪状态(TASK_TRACED):进程的执行已经被调试程序暂停,当一个进程被另一个进程监控时,任何信号都可以把这个进程置于这个状态!
还有两个进程状态,是既可以存放在进程描述符当中,,也可以存放在退出状态字段当中!
- 僵死状态:进程的执行被终止,但是父进程并没有发布wait4或wait pid系统调用来返回有关死亡进程的信息
- 将死撤销状态:最终状态由于父进程发出了上面提到的两个系统调用,因而进程由系统进行删除。为了防止其他执行进程在同一进程上也执行wait类系统调用而把进程的状态由僵死状态设为僵死撤销状态!
标识一个进程
一般来说能被独立调度的每个进程上下文都必须有它自己的进程描述符!也就是pid。pid存放在进程描述符的pid字段中,它被顺序编号。内核使用一个pid_map_array位图来表示当前已经被分配的pid号和闲置的pid号。
进程描述符处理进程是动态实体,因此内核必须能够同时处理很多进程!并把进程描述符存放在动态内存中,而不是永久分配给内核的内存区!
标识当前进程是使用一个叫做thread_info的结构。进程最常用地址不是thread_info地址而是进程描述符的地址,为了获得当前CPU上运行形成的描述符指针内核需要调用current宏。该宏本质上等价于current thread info()->task
进程组织
Linux使用双向链表来管理进程!被称为进程链表。
task_running状态的进程列表,当内核寻找一个新进程在CPU上运行时,必须只考虑可以运行的。进程在Linux 2.6实现的运行队列与之前的实现有所不同,其目的是让调度程序能够在固定时间内选出最佳的可知运行进程!与队列中的可运行的进程数无关
进程之间的关系
程序创建的进程具有父子关系。如果一个进程创建多个子进程,则多个子进程之间又有兄弟关系。进程描述符中表示进程亲属关系的字段描述如下:
| 描述符 | 说明 |
|---|---|
| real parent | 指向创建了P的进程的描述符,如果P的进程不再存在就指向进程init进程描述符 |
| parent | P的当前父进程,它的值通常与real parent一致。但偶尔有所不同,比如说另一个进程发出监控P的Ptrace调用时。 |
| Children | 链表的头部链表中的所有元素都是P创建的子进程 |
| sibling | 指向兄弟进程链表中的下一个元素,或前一个元素的指针。这些兄弟进程的父进程都是P |
如何组织进程
运行队列链表把处于task running状态的所有进程组织在,一起不同的状态要求不同的处理!Linux选择下面的方式之一:
没有未处理task_stopped和exit_zombie或者是exit_dead状态的进程建立专门的链表。由于对处于暂停僵死,死亡状态进程的访问比较简单,或者通过pid或者通过特定父进程的子进程链表。所以不必对这三种状态进行分组
根据不同的特殊事件把处于task_interrupttable或task_uninterruptable状态的进程细分为许多类,每个类都对应一个特殊事件。
在这种情况下进程状态提供的信息满足不了快速检索进程的需要,所以需要另外引入进程列表!
等待队列
等待队列在内核中有很多用途!特别是在处理中断处理进程同步及定时(进程必须经常等待某些事情的发生——等待队列是由双向链表所实现的!关于具体操作可以参看相关的博客。
进程资源限制
每一个进程都有资源限制:
struct rlimit {
rlim_t rlim_cur; /* Soft limit */
rlim_t rlim_max; /* Hard limit (ceiling for rlim_cur) */
}; 这是常见的一些限制
- RLIMIT_AS
- 进程虚拟内存限制大小(字节数),即进程总的可用存储空间的最大长度
- yixie试图(brk()、sbrk()、mmap()、mremap()以及 shmat())超出这个限制会得到 ENOMEM 错误。
- 在实践中,程序中会超出这个限制的最常见的地方是在调用 malloc 包中的函数时,因为它们会使用 sbrk()和mmap()。当碰到这个限制时,栈增长操作也会失败,进而会出现下面 RLIMIT_STACK 限制中列出的情况。
- RLIMIT_CORE
- 核心文件大小(字节数),即core文件的最大字节数
- 当达到这个限制时,核心 dump 文件就不会再产生了
- 如果值为0标识阻止创建core文件
- 这种做法有时候是比较有用的,因为核心 dump 文件可能会变得非常大,而最终用户通常又不知道如何处理这些文件。
- 另一个禁用核心 dump文件的原因是安全性——防止程序占用的内存中的内容输出到磁盘上。
- 如果 RLIMIT_FSIZE限制值低于这个限制值,那么核心 dump 文件的最大大小会被限制为 RLIMIT_FSIZE 字节。
- RLIMIT_CPU
- 进程最多使用的 CPU 时间(包括系统模式和用户模式)。
- 当超过此软限制时,向该进程发送SIGXCPU信号(SIGXCPU 信号的默认动作是终止一个进程并输出一个核心 dump。此外,也可以捕获这个信号并将控制返回给主程序。)。
- 不同的 UNIX 实现对进程处理完 SIGXCPU 信号之后继续消耗 CPU 时间这种情况的处理方式不同。大多数会每隔固定时间间隔向进程发送一个 SIGXCPU 信号。
- 在达到软限制值之后,Linux 内核会在进程每消耗一秒钟的 CPU 时间后向其发送一个 SIGXCPU 信号。当进程持续执行直至达到硬 CPU 限制时,内核会向其发送一个 SIGKILL 信号,该信号总是会终止进程。
- RLIMIT_DATA
- 数据段的最大字节长度。这是初始化数据段、非初始化数据段、堆的总和
- 试图(sbrk()和 brk())访问这个限制之外的数据段会得到ENOMEM 的错误。
- 与 RLIMIT_AS 一样,程序中会超出这个限制的最常见的地方是在调用malloc 包中的函数时。
- RLIMIT_FSIZE
- 文件大小(字节数),即可以创建的文件的最大字节长度
- 当超过此软限制时,向该进程发送SIGXFSZ信号。并且系统调用(如 write()或truncate())会返回EFBIG错误。
- SIGXFSZ信号的默认动作是终止进程并产生一个核心dump。此外,也可以捕获这个信号并将控制返回给主程序。不管怎样,后续视图扩充该文件的操作都会得到同样的信号和错误。
- RLIMIT_MEMLOCK
- 一个进程最多能够将多少字节的虚拟内存锁进物理内存以防止内存被交换出去
- 这个限制会影响 mlock()和 mlockall()系统调用以及 mmap()和 shmctl()系统调用的加锁参数
- 如果在调用 mlockall()时指定了 MCL_FUTURE 标记,那么 RLIMIT_MEMLOCK 限制也会导致后续的 brk()、sbrk()、mmap()和 mremap()调用失败
- RLIMIT_MSGQUEUE
- 能够为调用进程的真实用户 ID 的 POSIX 消息队列分配的最大字节数。
- RLIMIT_MSGQUEUE 限制只会影响调用进程。这个用户下的其他进程不会受到影响,因为它们也会设置这个限制或继承这个限制。
- RLIMIT_NICE
- 规定了使用 sched_setscheduler()和 nice()能够为进程设置的最大 nice 值。
- 这个最大值是通过公式 20 – rlim_cur 计算得来的,其中 rlim_cur 是当前的 RLIMIT_NICE 软资源限制
- RLIMIT_NOFILE
- 一个进程能够分配的最大文件描述符数量加 1
- 试图(如 open()、pipe()、socket()、accept()、shm_open()、dup()、dup2()、fcntl(F_DUPFD)和 epoll_create())分配的文件描述符数量超出这个限制时会失败。
- 在大多数情况,失败的错误是 EMFILE
- 在 dup2(fd, newfd)调用中,失败的错误是 EBADF,
- 在 fcntl(fd, F_DUPFD, newfd)调用中当 newfd 大于或等于这个限制时,失败的错误是 EINVAL。
- 更改此限制将影响到sysconf函数在参数_SC_OPEN_MAX中返回的值
- 在 Linux 上可以通过使用 readdir()扫描/proc/PID/fd 目录下的内容来检查一个进程当前打开的文件描述符,这个目录包含了进程当前打开的每个文件描述符的符号链接。
- 从 2.6.25 的版本开始,这个限制由 Linux 特有的/proc/sys/fs/nr_open 文件定义。这个文件中的默认值是 1048576,超级用户可以修改这个值。试图将软或硬 RLIMIT_NOFILE 限制设置为一个大于最大值的值会产生 EPERM 错误。
- 还存在一个系统级别的限制,它规定了系统中所有进程能够打开的文件数量,通过 Linux 特有的/proc/sys/fs/file-max 文件能够获取和修改这个限制。
- 只有特权(CAP_SYS_ADMIN)进程才能够超出 file-max 的限制。
- 在非特权进程中,当系统调用碰到 file-max 限制时会返回 ENFILE 错误
- RLIMIT_NPROC
- 规定了调用进程的真实用户 ID 下最多能够创建的进程数量。
- 试图(fork()、vfork()和 clone())超出这个限制会得到 EAGAIN 错误
- RLIMIT_NPROC 限制只影响调用进程。这个用户下的其他进程不会受到影响,除非它们也设置或继承了这个限制。这个限制不适用于特权(CAP_SYS_ADMIN 和 CAP_SYS_RESOURCE)进程。
- Linux 还提供了系统层面的限制来规定所有用户能够创建的进程数量。在 Linux 2.4以及之后的版本中,可以使用 Linux 特有的/proc/sys/kernel/threads-max 文件来获取和修改这个限制
- 准确地说,RLIMIT_NPROC 资源限制和 threads-max 文件实际上限制的是所能创建的线程数量,而不是进程的数量
- 更改此限制将影响到sysconf函数在参数_SC_CHILD_MAX中返回的值
- 不存在一种统一的方法能够在不同系统中找出某个特定用户 ID 已经创建的进程数。
- RLIMIT_RSS
- 进程驻留集中的最大页面数,即当前位于物理内存中的虚拟内存页面总数。
- Linux 提供了这个限制,但当前并没有起任何作用
- 如果可用的物理存储器非常少,则内核将从进程处取同超过RSS的部分
- RLIMIT_RTPRIO
- 规定了使用 sched_ setscheduler()和 sched_setparam()能够为进程设置的最高实时优先级(自 Linux 2.6.12 起)
- RLIMIT_RTTIME
- 规定了一个进程在实时调度策略中不睡眠(即执行一个阻塞系统调用)的情况下最大能消耗的 CPU 秒数(微秒;自 Linux 2.6.25 起)
- 如果进程达到了软限制,那么内核会向进程发送一个 SIGXCPU 信号,之后进程每消耗一秒的 CPU 时间都会收到一个SIGXCPU 信号。在达到硬限制时,内核会向进程发送一个 SIGKILL 信号。
- RLIMIT_SBSIZE
- 在任一给定时刻,一个用户可以占用的套接字缓冲区的最大长度(字节)
- RLIMIT_SIGPENDING
- 一个进程可排队的信号最大数量制(Linux 特有的,自 Linux 2.6.8 起)
- 试图(sigqueue())超出这个限制会得到 EAGAIN错误。
- RLIMIT_SIGPENDING 只影响调用进程。这个用户下的其他进程不会受到影响,除非它们也设置或继承了这个限制 - RLIMIT_STACK
- 栈段的大小(字节数)
- 试图扩展栈大小以至于超出这个限制会导致内核向该进程发送一个 SIGSEGV 信号。
- 由于栈空间已经被用光了,因此捕获这个信号的唯一方式是建立另外一个备用的信号栈,
- RLIMIT_VMEN
- 这时RLIMIT_AS的同义词
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程!以恢复以前挂起的某个进程的执行。这种行为被称为进程切换,任务切换或者是上下文切换。
硬件上下文
尽管每个进程都可以拥有自己的地址空间,但所有的进程必须共享CPU的寄存器!因此在恢复一个进程的执行以前内核必须确保每个寄存器装入了挂起进程时的值。进程恢复至执行前必须装入寄存器的一组数据被称为硬件上下文
硬件上下文是进程可执行上下文的一个子集,因为可执行上下文包含进程执行时需要的所有信息。Linux 2.6使用软件执行线程切换:通过一组move指令逐步执行切换,这样能较好地控制所装入数据的合法性。尤其是这时检查ds和es段寄存器的值成为可能
任务状态段TSS用来存放硬件上下文,尽管Linux并不使用硬件上下文切换,但它强制为每个系统中每个不同的CPU创建一个TSS。这么做的理由有:当8086的一个CPU从用户态切换到内核态时它就从TSS中获取内核态堆栈的地址,当用户态进程试图通过IN或OUT指令访问一个io端口时,CPU需要访问存放在TSS中的io许可全位图,以检查该进程是否有访问端口的能力!
执行进程切换进程切换只能发生在精心定义的点:schedule函数。这里我们仅关心内核如何执行一个进程切换//从本质上来说每个进程切换有两步组成:
切换页全局目录已安装一个新的地址空间。
切换内核态堆栈和硬件上下文
因为硬件上下文提供了内核执行新进程所需要的所有信息,包括CPU的寄存器!
switch_to宏
进程切换的第二步由switch_to宏执行。它是内核中与硬件关系最密切的历程之一。首先该宏有三个参数它们是prev,next和last。在任何进程切换中涉及到三个进程而不是两个。因为假设内核正决定战役进程A而激活B,在schedule函数中Prev指向a的描述符而next指向B的描述符。一旦是a暂停,a的执行流就被冻结了。随后当内核再次想激活a时,又必须暂停另一个进程C!这通常不同于B(你想想B可能也被切换走了)于是就要用prev指向C,而next选项a来执行另一个switch to宏。当a恢复它的执行流时就会找到他原来的内核栈。于是prev局部变量还是指向a的描述符。next指向B的描述符。此时代表a的执行的内核就失去了对C的任何作用,但是事实表明这个引用对于完成进程切换还是很有用!
switch_to宏最后一个参数表示输出参数,它表示宏把进程C的描述地址写在了什么位置
下面来简述简述汇编语言是如何实现进程切换的:
- 在EAX和EDX寄存器中分别保存prev和next的值
movl prev, %eax
movl next, %edx把eflags和ebp寄存器的内容保存在prev内核栈中,必须保存他们的原因是编译器认为在switch to结束之前他们的值是保持不变的!
pushfl
pushl %ebp 把ESP的内容保存到prev指向的thread.esp中,使该字段指向prev内核栈的栈顶
movl %esp, 484(%eax) 把next指向thread.esp装入ESP,此时内核开始在next的内核栈上操作!因此这条指令实际上完成了从prev项next的切换
mov 484(%edx), %esp 把标记为一的地址存入prev->thread.eip。当被替换的进程重新执行时,进程执行被标记为一的那条指令。
movl $1f, 480(%eax) 宏把next thread.eip的值压入next的内核栈:
pushl 480(%edx) 跳到__switch_to()C函数,(这里就是主要完成硬件上下文切换,更新TSS,我们不讲)
jmp __switch_to 这里被进程B替换的进程A再次获得CPU。它执行一些保存eflags和ebp寄存器内容的指令,这里两条指令的第一条被标记为1
1:
popl %ebp
popfl 注意这些pop指令是如何引用prev进程的内核栈的!当进程调度程序选择prev作为进程,在CPU上运行时将执行这些指令!
拷贝寄存器的内容到switch_to宏的第三个参数last标识的内存区域中:
movl %eax, last创建进程
Unix操作系统仅仅依赖进程创建来满足用户的需求现代Unix内核引入了三种不同的机制来加快进程创建和减轻进程创建的开销写时复制技术允许父子进程读取相同的物理也只有两者中的有一个试图写一个物理页内核就把这个页拷贝到一个新的物理页并且把新的物理页分配给正在写的进程轻量级进程允许父子之间共享每进程之间的内河的很多数据结构比如说列表打开文件表和信号处理微fork系统调用创建的进程能共享其父进程的内存地址空间为了防止父进程重写子进程需要的数据需要阻塞父进程的执行一直到子进程退出或执行一个新的程序为止但是这个调用基本上不被提倡
在Linux在中,我们使用clone来创建轻量级的进程,这是一些常见的标志
CLONE_NEWNS:使新进程拥有一个新的、独立的挂载命名空间,可以隔离文件系统。
CLONE_NEWUTS:使新进程拥有一个新的、独立的 UTS 命名空间,可以隔离主机名和域名。
CLONE_NEWIPC:使新进程拥有一个新的、独立的 IPC 命名空间,可以隔离 System V IPC 和 POSIX 消息队列。
CLONE_NEWNET:使新进程拥有一个新的、独立的网络命名空间,可以隔离网络设备、协议栈和端口。
CLONE_NEWPID:使新进程拥有一个新的、独立的 PID 命名空间,可以隔离进程 ID。
CLONE_NEWUSER:使新进程拥有一个新的、独立的用户命名空间,可以隔离用户和组 ID。
CLONE_FILES:使新进程共享打开的文件描述符表,但不共享文件描述符的状态(例如文件偏移量)。
CLONE_FS:使新进程共享文件系统信息(例如当前工作目录和根目录)。
CLONE_VM:使新进程共享虚拟内存空间,即在进程之间共享代码和数据段。
CLONE_SIGHAND:使新进程共享信号处理程序。
CLONE_THREAD:使新进程成为调用进程的线程,与父进程共享进程 ID 和资源,但拥有独立的栈。do_fork
clone, fork, vfork底层:
它执行以下这些步骤
- 通过查找pidmap_array位图,为子进程分配新的PID
- 检查父进程的ptrace字段(current->ptrace):如果它的值不等于0,说明有另外一个进程正在跟踪父进程,因而,do_fork()检查debugger程序是否自己想跟踪子进程(独立于由父进程指定的CLONE_PTRACE标志的值)。在这种情况下,如果子进程不是内核线程(CLONE_UNTRACED标志被清0),那么do_fork()函数设置CLONE_PTRACE标志。
- 调用copy_process()复制进程描述符。如果所有必须的资源都是可用的,该函数返回刚创建的task_struct描述符的地址。这是创建过程的关键步骤,将在do_fork()之后描述它。
- 如果设置了CLONE_STOPPED标志,或者必须跟踪子进程,即在p->ptrace中设置了PT_PTRACED标志,那么子进程的状态被设置成TASK_STOPPED,并为子进程增加挂起的SIGSTOP信号。在另外一个进程(不妨假设是跟踪进程或是父进程)把子进程的状态恢复为TASK_RUNNING之前(通常是通过发送SIGCONT信号),子进程将一直保持TASK_STOPPED状态。
- 如果没有设置CLONE_STOPPED标志,则调用wake_up_new_task()函数以执行下述操作:
a.调整父进程和子进程的调度参数
b.如果子进程将和父进程运行在同一个CPU上(当内核创建一个新进程时父进程有可能会被转移到另一个CPU上执行),而且父进程和子进程不能共享同一组页表(CLONE_VM标志被清0),那么,就把子进程插入父进程运行队列,插入时让子进程恰好在父进程前面,因此而迫使子进程先于父进程运行。如果子进程刷新其地址空间,并在创建之后执行新程序,那么这种简单的处理会产生较好的性能。而如果我们让父进程先运行,那么写时复制机制将会执行一系列不必要的页面复制。
c.否则,如果子进程与父进程运行在不同的CPU上,或者父进程和子进程共享同一组页表(CLONE_VM标志被置位),就把子进程插入父进程运行队列的队尾。
- 如果CLONE_STOPPED标志被置位,则把子进程置为TASK_STOPPED状态。
- 如果父进程被跟踪,则把子进程的PID存入current的ptrace_message字段并调用ptrace_notify()。ptrace_notify()是当前进程停止运行,并向当前进程的父进程发送SIGCHLD信号。子进程的祖父进程是跟踪父进程的debugger进程。SIGCHLD信号通知debugger进程:current已经创建了一个子进程,可以通过查找current->ptrace_message字段获得子进程的PID。
- 如果设置了CLONE_VFORK标志,则把父进程插入等待队列,并挂起父进程直到子进程释放自己的内存地址空间(也就是说,直到子进程结束或执行新的程序)。
- 结束并返回子进程的PID。
欸,来看看中间的copy_process
- 定义返回值亦是
retval和新的进程描述符task_struct结构p。 - 标志合法性检查。对clone_flags所传递的标志组合进行合法性检查。当出现以下三种情况时,返回出错代号:
- CLONE_NEWNS和CLONE_FS同时被设置。前者标志表示子进程需要自己的命名空间,而后者标志则代表子进程共享父进程的根目录和当前工作目录,两者不可兼容。在传统的Unix系统中,整个系统只有一个已经安装的文件系统树。每个进程从系统的根文件系统开始,通过合法的路径可以访问任何文件。在2.6版本中的内核中,每个进程都可以拥有属于自己的已安装文件系统树,也被称为命名空间。通常大多数进程都共享init进程所使用的已安装文件系统树,只有在clone_flags中设置了CLONE_NEWNS标志时,才会为此新进程开辟一个新的命名空间。
- CLONE_THREAD被设置,但CLONE_SIGHAND未被设置。如果子进程和父进程属于同一个线程组(CLONE_THREAD被设置),那么子进程必须共享父进程的信号(CLONE_SIGHAND被设置)。
- CLONE_SIGHAND被设置,但CLONE_VM未被设置。如果子进程共享父进程的信号,那么必须同时共享父进程的内存描述符和所有的页表(CLONE_VM被设置)。
安全性检查。通过调用security_task_create()和后面的security_task_alloc()执行所有附加的安全性检查。询问 Linux Security Module (LSM) 看当前任务是否可以创建一个新任务。LSM是SELinux的核心。
复制进程描述符。通过dup_task_struct()为子进程分配一个内核栈、thread_info结构和task_struct结构。注意,这里将当前进程描述符指针作为参数传递到此函数中。首先,该函数分别定义了指向task_struct和thread_info结构体的指针。接着,prepare_to_copy为正式的分配进程描述符做一些准备工作。主要是将一些必要的寄存器的值保存到父进程的thread_info结构中。这些值会在稍后被复制到子进程的thread_info结构中。执行alloc_task_struct宏,该宏负责为子进程的进程描述符分配空间,将该片内存的首地址赋值给tsk,随后检查这片内存是否分配正确。执行alloc_thread_info宏,为子进程获取一块空闲的内存区,用来存放子进程的内核栈和thread_info结构,并将此会内存区的首地址赋值给ti变量,随后检查是否分配正确。
- 上面已经说明过orig是传进来的current宏,指向当前进程描述符的指针。arch_dup_task_struct直接将orig指向的当前进程描述符内容复制到当前里程描述符tsk。接着,用atomic_set将子进程描述符的使用计数器设置为2,表示该进程描述符正在被使用并且处于活动状态。最后返回指向刚刚创建的子进程描述符内存区的指针。
- 通过dup_task_struct可以看到,当这个函数成功操作之后,子进程和父进程的描述符中的内容是完全相同的。在稍后的copy_process代码中,我们将会看到子进程逐步与父进程区分开来。
- 一些初始化。通过诸如ftrace_graph_init_task,rt_mutex_init_task完成某些数据结构的初始化。调用copy_creds()复制证书(应该是复制权限及身份信息)。
- 检测系统中进程的总数量是否超过了max_threads所规定的进程最大数。
- 复制标志。通过copy_flags,将从do_fork()传递来的的clone_flags和pid分别赋值给子进程描述符中的对应字段。
- 初始化子进程描述符。初始化其中的各个字段,使得子进程和父进程逐渐区别出来。这部分工作包含初始化子进程中的children和sibling等队列头、初始化自旋锁和信号处理、初始化进程统计信息、初始化POSIX时钟、初始化调度相关的统计信息、初始化审计信息。它在copy_process函数中占据了相当长的一段的代码,不过考虑到task_struct结构本身的复杂性,也就不足为奇了。
- 调度器设置。调用sched_fork函数执行调度器相关的设置,为这个新进程分配CPU,使得子进程的进程状态为TASK_RUNNING。并禁止内核抢占。并且,为了不对其他进程的调度产生影响,此时子进程共享父进程的时间片。
- 复制进程的所有信息。根据clone_flags的具体取值来为子进程拷贝或共享父进程的某些数据结构。比如copy_semundo()、复制开放文件描述符(copy_files)、复制符号信息(copy_sighand 和 copy_signal)、复制进程内存(copy_mm)以及最终复制线程(copy_thread)。
- 复制线程。通过copy_threads()函数更新子进程的内核栈和寄存器中的值。在之前的dup_task_struct()中只是为子进程创建一个内核栈,至此才是真正的赋予它有意义的值。
- 当父进程发出clone系统调用时,内核会将那个时候CPU中寄存器的值保存在父进程的内核栈中。这里就是使用父进程内核栈中的值来更新子进程寄存器中的值。特别的,内核将子进程eax寄存器中的值强制赋值为0,这也就是为什么使用fork()时子进程返回值是0。而在do_fork函数中则返回的是子进程的pid,这一点在上述内容中我们已经有所分析。另外,子进程的对应的thread_info结构中的esp字段会被初始化为子进程内核栈的基址。
- 分配pid。用alloc_pid函数为这个新进程分配一个pid,Linux系统内的pid是循环使用的,采用位图方式来管理。简单的说,就是用每一位(bit)来标示该位所对应的pid是否被使用。分配完毕后,判断pid是否分配成功。成功则赋给p->pid。
- 更新属性和进程数量。根据clone_flags的值继续更新子进程的某些属性。将 nr_threads加一,表明新进程已经被加入到进程集合中。将total_forks加一,以记录被创建进程数量。
- 如果上述过程中某一步出现了错误,则通过goto语句跳到相应的错误代码处;如果成功执行完毕,则返回子进程的描述符p。
内核进程
所有进程的祖先是0进程,他在初始化阶段从无到有的创建一个进程。进程1是init进程!
撤销有一个进程
进程的终止有两个:exitt_group来终结一个进程组,exit系统调用终结摸一个线程
do_group_exit
这个函数用来杀死属于current进程组的所有进程!它接收进程终止代号作为参数
- 首先它检查退出进程的signal_group_exit标志是否不为零,如果不为零,说明内核已经开始为进程组执行退出的过程!在这种情况下就把存放在
current->signal->group->exit_code中的值当做退出码,然后跳到第四步 - 否则设置进程的signal group exit标志并把中指戴好存放在
current->signal->group->exit_code字段调用 - zap_other_threads函数杀死杀死current进程组的其他进程
- 调用do_exit函数,把进程的终止代号传递给他
do_exit函数
做这些事情:
- 把进程描述符的flag字段设置为PF_EXITING标志,以表示进程正在被删除。
- 如果需要,通过函数del_timer_sync()从动态定时器队列中删除进程描述符。
- 分别调用exit_mm()、exit_sem()、__exit_files()、__exit_fs()、exit_namespace()和exit_thread()函数从进程描述符中分离出与分页、信号量、文件系统、打开文件描述符、命名空间以及I/O权限位图相关的数据结构。如果没有其它进程共享这些数据结构,那么这些函数还删除所有这些数据结构中。
- 如果实现了被杀死进程的执行域和可执行格式的内核函数包含在内核模块中,则函数递减它们的使用计数器。
- 把进程描述符的exit_code字段设置成进程的终止代号,这个值要么是_exit()或exit_group()系统调用参数,要么是由内核提供的一个错误代码。
调用exit_notify()函数执行下面的操作:
- 更新父进程和子进程的亲属关系。如果同一线程组中有正在运行的进程,就让终止进程所创建的所有子进程都变成同一线程组中另外一个进程的子进程,否则让它们成为init的子进程
- 检查被终止进程其进程描述符的exit_signal字段是否不等于-1,并检查进程是否是其所属进程组的最后一个成员。在这种情况下,函数通过给正被终止进程的父进程发送一个信号,以通知父进程子进程死亡。
- 否则,也就是exit_signal字段等于-1,或者线程组中还有其它进程,那么只要进程正在被跟踪,就向父进程发送一个SIGCHLD信号。
- 如果进程描述符的exit_signal字段等于-1,而且进程没有被跟踪,就把进程描述符的exit_state字段置为EXIT_DEAD,然后调用release_task()回收进程的其它数据结构占用的内存,并递减进程描述符的使用计数器,以使进程描述符本身正好不会被释放。
- 否则,如果进程描述符的exit_signal字段不等于-1,或进程正在被跟踪,就把exit_state字段置为EXIT_ZOMBIE。
- 把进程描述符的flags字段设置为PF_DEAD标志。
调用schedule()函数选择一个新进程运行。调度程序忽略处于EXIT_ZOMBIE状态的进程,所以这种进程正好在schedule()中的宏switch_to被调用之后停止执行。
Reference
中断与异常
中断通常被定义为一个事件:让事件改变处理器执行的指令顺序这样的事件,与CPU芯片内外部硬件电路产生的电信号相对应!
中断通常分为同步中断与异步中断:
同步中断指的是当指令执行时,由CPU控制单元产生的。之所以称为同步,是因为只有在一条指令终止执行后,CPU才会发出中断!
异步中断是由其他硬件设备依照CPU时钟信号随机产生的
在英特尔微处理器手册中:也会把同步和异步中断分别称为异常和中断
中断则是由间隔定时器或者io设备产生的,举个例子你敲击键盘的时候,你的一次按键就会引发一个中断,希望操作系统介入进行处理!
另一方面异常是由程序的错误产生的,或者是由内核必须处理的异常条件产生的!比如说内核通过发送一个信号来处理异常,或者内核执行恢复异常所需要的步骤,比如说缺页,比如说对内核服务的一个请求
中断信号的作用
顾名思义,中断信号提供了一种特殊的方式来让处理器转而去运行正常控制流之外的代码。当一个中断信号到达的时候CPU必须停止它当前所做的事情,转而切换去处理这些终端。为了做到这一点就需要把内核态堆栈保存PC当前的值,并且把中断相关类型的的一个地址放进程序计数器中。这样才会跳转去执行处理中断的代码。
中断处理器内核执行的最敏感的任务之一,因为它必须要满足:
- 让内核正打算去完成别的事情的,由于中断随时都会到来,因此内核的目标就是:让中断尽可能的处理完尽可能把更多的更详细的处理向后推,所以中断响应分为两个部分:
- 关键而紧急的部分这一部分,内核立即执行。
- 其推迟的部分,则是内核随后执行。
- 因为中断随时会到来,所以内核可能正在处理其中一个中断的时候,另一个中断又发生了。应该尽可能地允许这种情况发生,因为这将会保持更多的io设备处于忙状态。因此中断处理程序必须编写成可以使相应的内核控制路径以嵌套的方式进行,执行到最后一个内核控制路径终止时,内核可以恢复被中断进程的执行,或者如果中断信号已导致了重新调度,内核可以切换到另外的进程。
- 尽管内核在处理前一个中断的时候,可以接受新的中断,但在内核代码区中仍然存在着一些临界区,在这些临界区中中断必须被禁止
中断和异常
英特尔文档把中断和异常又分为了以下几类:
- 中断:
又分出两类即:
| 类型 | 说明 |
|---|---|
| 可屏蔽中断 | IO设备发出的所有中断请求(Interruppt Request)都产生可屏蔽的中断,它处于两状态:屏蔽的和非屏蔽的,如果一个中断是被屏蔽的,那么控制单元会被它会忽略它 |
| 非可屏蔽中断 | 只有少数的几个危机事件是这样的,非屏蔽的中断总是由CPU辨认 |
异常:
异常分两类,处理器探测异常和编程异常。
处理器探测异常有三种
| 类型 | 说明 |
|---|---|
| 故障 | 通常可以被纠正,一旦纠正,程序就可以在不失连贯性的情况下,重新开始!保存在EIP中的值就是引起故障的指令地址,因此当异常处理程序终止时,那条指令会被重新执行 |
| 陷阱 | 在陷阱执行后,立即报告内核把控制权返回给程序后,就可以继续它的执行而不失去连贯性。保存在EIP中的值是一个随后要执行的指令地址,只有当没有必要重新执行已中止的指令时,才会触发陷阱。陷阱的主要目的是为了调试程序 |
| 异常终止 | 异常终止指的是发生了一个严重的错误及控制单元出现了问题,不能在EIP寄存器中保存引发了这个异常指令所在的确切位置。异常终止用的报告严重的错误,如硬件故障或系统表中无效的值或不一样的值。 |
编程异常:在编程者发出请求时发生是由int或int3指令触发的当into(检查溢出)和bound(检查地址出界)指令检查的条件不为真时,会引发编程异常控制单元!编程异常当作陷阱来处理,编程异常也被称为软中断,这样的异常常有两种的用途执行:系统调用以及给调试程序通报一个特定的事件。
IRQ与中断
每个能够发出中断请求的硬件设备系都有一条名为IRQ的输出线,所有现有的IRQ线都与一个名为可编程中断控制器的硬件电路的输入引脚相连,可编程中断控制器执行下列动作:
- 监视IRQ线检查产生的信号,如果有两条或两条以上的IRQ线上产生信号,选择引脚编号较小的IRQ线
- 如果一个引发信号出现在线上,那么它会把接收到的信发信号转换成对应的向量,把这个向量存放在中断控制器的一个io端口,从而允许CPU通过数据总线读取此向量。把引发信号发送到处理器的INTR引脚,也就是产生了一个中断
- 等待直到CPU通过把这个中断信号写进可编程中断控制器的io端口号,来确认它,当这种情况发生时,清理INTR线。然后继续监视。
异常
这里给出一些常见的异常:
| 异 常 一 览 表 | 向量号 | 异常名称 | 异常类型 | 出错代码 | 相关指令 |
|---|---|---|---|---|---|
| 0 | 除法出错 | 故障 | 无 | DIV,IDIV | |
| 1 | 调试异常 | 故障/陷阱 | 无 | 任何指令 | |
| 3 | 单字节INT3 | 陷阱 | 无 | INT 3 | |
| 4 | 溢出 | 陷阱 | 无 | INTO | |
| 5 | 边界检查 | 故障 | 无 | BOUNT | |
| 6 | 非法操作码 | 故障 | 无 | 非法指令编码或操作数 | |
| 7 | 设备不可用 | 故障 | 无 | 浮点指令或WAIT | |
| 8 | 双重故障 | 中止 | 有 | 任何指令 | |
| 9 | 协处理器段越界 | 中止 | 无 | 访问存储器的浮点指令 | |
| 0AH | 无效TSS异常 | 故障 | 有 | JMP、CALL、IRET或中断 | |
| 0BH | 段不存在 | 故障 | 有 | 装载段寄存器的指令 | |
| 0CH | 堆栈段异常 | 故障 | 有 | 装载SS寄存器的任何指令、对SS寻址的段访问的任何指令 | |
| 0DH | 通用保护异常 | 故障 | 有 | 任何特权指令、任何访问存储器的指令 | |
| 0EH | 页异常 | 故障 | 有 | 任何访问存储器的指令 | |
| 10H | 协处理器出错 | 故障 | 无 | 浮点指令或WAIT | |
| 11H—0FFH | 软中断 | 陷阱 | 无 | INT n |
中断向量表
中断描述符表IDT是一个系统表,它与每一个中断或者异常向量相联系
每一个向量在表中都有相应的中断或异常处理程序的入口地址,内核在允许中断发生前,必须适当初始化IDT
下图为IDT的结构表示图:
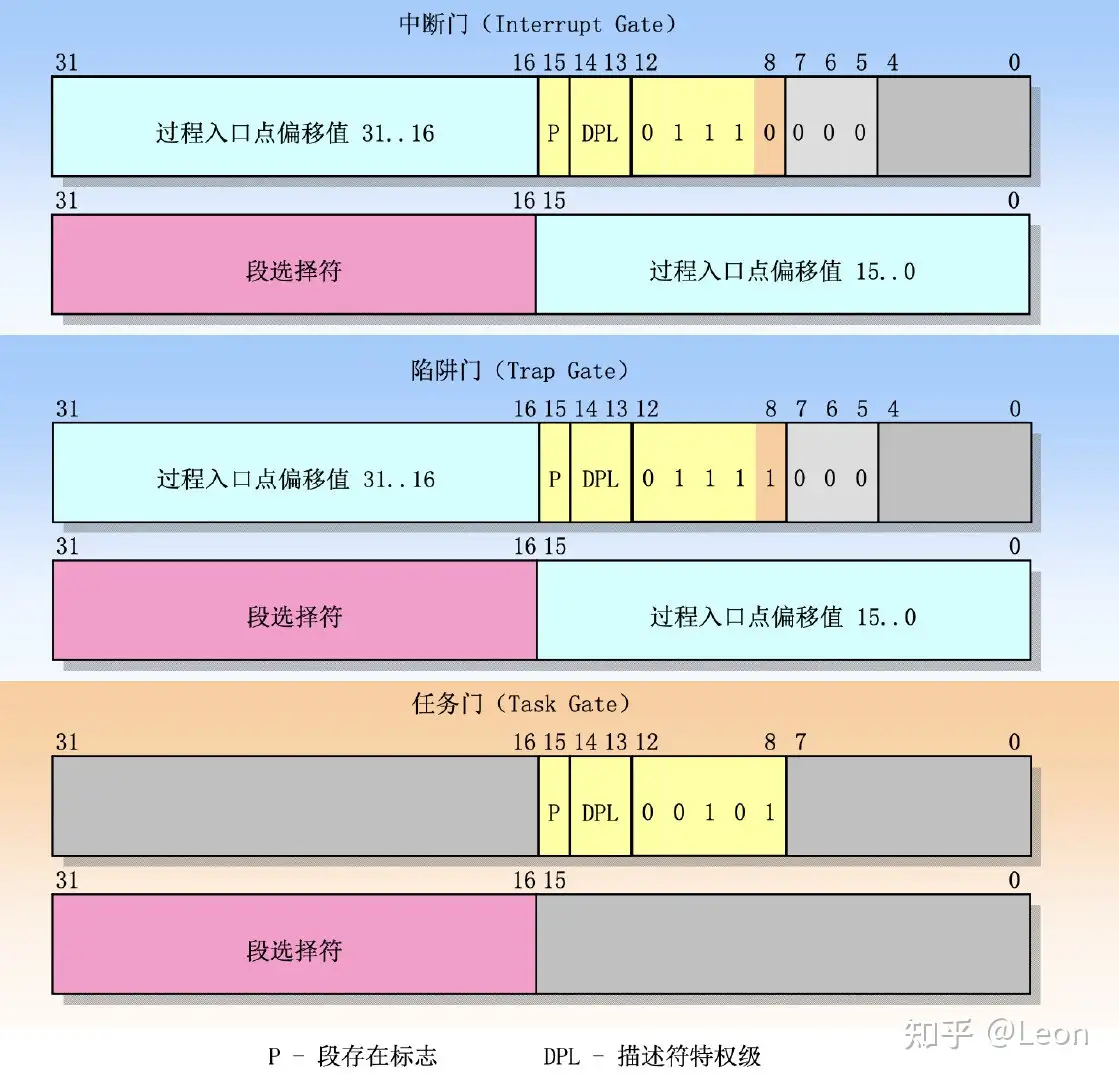
这些描述符是:
- 任务门
Task Gate:当中断信号发生时,必须取代当前进程的那个进程的TSS选择符,存放在任务门中 - 中断门
Interrupt Gate:包含段选择符和中断或异常处理程序的段内偏移量,当控制权转移到应适当的段时,处理器清IF标志,从而关闭即将会发生的可屏蔽中断。 - 陷阱门
Trap Gate:与中断门相似只是控制权传递到一个适当的段时处理器不修改IF标志Linux使用中断门处理中断应用陷阱门处理异常
硬件处理
现在描述CPU控制单元是如何处理中断和异常的!
我们现在假定内核已经被初始化,因此CPU将会在保护模式下运行。
当执行了一条指令后,CS和EIP这对寄存器将会包含下一条将要执行的指令的逻辑地址。在处理那条指令之前控制单元会检查在运行前一条指令是否已经发生一个中断或者异常,如果发生了,那么它将会:
确定与中断或异常关联的向量(看一眼是哪个异常)
读由寄存器指向的
IDT表中的i项(肘!IDT表爆破)从
gdpr寄存器中获取GDP的基地址,并在GDP中查找,以读取IDT表项的选择符所标识的段描述符。这个描述符指定中断或异常处理程序所在段的基地址(看看这个程序在哪里)确信中断事由授权的中断发生源发出的,首先将当前特权级CPL与段描述符的描述符特权级DPL的相比较:如果CPL小于DPL了就会产生一个
general protection异常,因为中断处理程序的特权不能低于引起中断的程序的特权!对于编程异常则需要做进一步的安全检查:比较CPL了与处于IDT中的门描述符的DPL了,如果DPL小于CPL了那么就产生一个general protection,这最后一个检查可以避免用户应用程序访问特殊的陷阱门和中断门(配不配处理这个异常)检查是否发生了特权级变化:也就是说CPL是否不同于所选择的段描述符的DPL,如果是,控制单元必须开始使用与新的特权级相关的栈,通过执行以下步骤来做到这一点:
- 读TR寄存器以访问运行进程的TSS段
- 用于新特权级相关的栈段和栈指针的正确值装载SS和ESP寄存器这些值,可以在TSS中找到在新的段中
- 保存SS和ESP以前的值,这些值定义了与旧特训级相关的栈的逻辑地址。
如果故障已经发生,用引起异常的指令地址装载CS和EIP寄存器,从而使得这条指令能够再次被执行!
在栈中保存eflags,cs,EIP等内容,如果引用异常产生了一个硬件出错码,把它保存到栈中,装在CS和EIP寄存器其值分别为IDT表中第I项门描述服务的段选择符和偏移量字段,这些值给出了中断或者异常处理的第一条指令的逻辑地址!
控制单元所执行的最后一步就是跳转到这些异常处理程序,换句话说处理完中断信号后控制单元所执行的指令,就是被选中处理程序的第一条指令!
当中断或处理结束后和异常被处理结束后相应的处理程序必须参与生一条iret指令,他把控制权转交给被中断的进程。这将会迫使控制单元:
- 用保存在栈中的值装在CS或eflags寄存器,如果一个硬件出错码曾经被压入栈中,并且在EIP内容的上面,那么执行Iret指令前必须弹出这个硬件错误码(准备回家)
- 检查处理程序的CPL是否等于CS中的最低两位的值如果是iret终止执行,否则执行下一步。(看看特权级够不够)
- 从栈中装载SS和ESP寄存器因此返回到与特权级相关的栈(也就是恢复栈)
- 检查DS ES FS 以及 GS段寄存器的内容,如果其中一个寄存器包含选择符是一个段描述符,并且其的DPL值小于CPL了,那么我们会清理相应的段寄存器控制单元,这么做是为了防止用户态的程序利用内核以前所用的段寄存器,如果不清理这些寄存器,那么一些怀有恶意的用户态程序就有可能利用他们来访问内核地址。(安全处理,安全恢复环境)
中断和异常处理程序的嵌套执行
每个中断或异常都会引起一个内核控制路径,或者说当前的进程在内核态执行单独的指令序列。
内核控制路径可以任意嵌套!一个中断处理程序可以被另一个中断处理程序所中断,因此这样就引起了内核控制路径的嵌套执行。允许内核控制路径嵌套执行必须要付出相应的代价,也就是中断处理程序必须永不阻塞换,中断处理程序在运行期间是不能够发生进程切换。
基于以下两个主要原因,Linux交错执行内核控制路径:
- 为了提高可编程中断控制器和设备控制中器的吞吐量。假定设备控制器在一条线上产生了一条信号,pic把这个信号转换成一个外部中断,然后pic和控制设备器保持阻塞一直到pic从内核CPU处接收一条应答信息!由于内核控制路径的交错执行内核即使正在处理前一个中断也能够发送应答。
- 为了实现一种没有优先级的中断模型,每个C中断处理程序都可以被另一个中断处理程序所延缓,因此在硬件设备之间没必要预定义优先级,这简化了内核代码,也提高了内核的可移植性!
初始化IDT
Linux在基于Intel给出的三种门之外,还更加细分了他们:
中断门(interrupt gate):用户态的进程不能访问的一个lntel中断门(门的DPL字段为0)。所有的Linux中 断处理程序都通过中断门激活,并全部限制在内核态。
系统门(syslem gate):用户态的进程可以访问的一个Intel陷阱门(门的DPL字段为到.通过系统门来激 活三个Linux异常处理程序,它们的向量是4,5及128,因此,在用户态下.可以 发布into、 bound及int $Ox80三条汇编语言指令。
系统中断门(system interrupt gate):能够被用户态进程访问的Intel中断门(门的DPL字段为3). 与向量3相关的异常 处理程序是由系统中断门激活的,因此,在用户态可以使用汇编语言指令int3.
陷阱门(Irapgate):用户态的进程不能访问的一个Inte)陷阱门(f]的DPL字段为0). 大部分Linux异 常处理程序都通过陷阱门来激活.
任务门(task gate):不能被用户态进程访问的Intel任务门(门的DPL字段为0).Linux对”Doublefault” 异常的处理程序是由任务门激活的.
IDT会被初始化两次。第一次是在BIOS程序中,此时CPU还工作在实模式下。一旦Linux启动,IDT会被搬运到RAM的受保护区域并被第二次初始化,因为Linux不会使用任何BIOS程序。
IDT结构被存储在idt_table表中,包含256项。idt_descr变量存储IDT的大小和它的地址,在系统的初始化阶段,内核用来设置idtr寄存器,专用汇编指令是lidt。
内核初始化的时候,汇编函数setup_idt()用相同的中断门填充idt_table表的所有项,都指向ignore_int()中断处理函数:
setup_idt:
lea ignore_int, %edx
movl $(__KERNEL_CS << 16), %eax
movw %dx, %ax /* = 0x0010 = cs */
movw $0x8e00, %dx /* 中断门,DPL=0 */
lea idt_table, %edi /* 加载idt表的地址到寄存器edi中 */
mov $256, %ecx
rp_sidt:
movl %eax, (%edi) /* 设置中断处理函数 */
movl %edx, 4(%edi) /* 设置段描述符 */
addl $8, %edi /* 跳转到IDT表的下一项 */
dec %ecx /* 自减 */
jne rp_sidt
ret中断处理函数ignore_int(),也是一个汇编语言编写的函数,相当于一个null函数,它执行:
- 保存一些寄存器到堆栈中。
- 调用printk()函数打印
Unknown interrupt系统消息`。 - 从堆栈中恢复寄存器的内容。
- 执行iret指令回到调用处。
正常情况下,此时的中断处理函数ignore_int()是不应该被执行的。如果在console或者log日志中出现Unknown interrupt的消息,说明发生硬件错误或者内核错误。
完成这次IDT表的初始化之后,内核还会进行第二次初始化,用真正的trap或中断处理函数代替刚才的null函数。一旦这两步初始化都完成,IDT表就包含具体的中断、陷阱和系统门,用以控制每个中断请求。
中断处理
这里讨论三种中断类型:
IO中断,时钟中断。和处理器间中断io
中断处理程序必须足够灵活地给多个设备同时提供服务,比如说在PCI总线的体系架构中几个设备可以共享一个IRQ线,这也就意味着仅仅中断向量是并不能说明所有问题的!中断处理程序的灵活性是以两种不同的方式实现的:
IRQ共享
中断处理程序执行多个中断服务例程,每个中断服务例程是一个与单独设备相关的函数,因此不可能预先知道哪个特定的设备产生,因此每个IRQ,也就是中断服务例程,都会被执行验证它的设备是否需要关注,如果是,当设备产生中断时则需要执行相关的所有操作
IRQ动态分配
一条线可能在最后的时刻才会与一个设备驱动程序相关联,这样,即使几个硬件设备并不共享线,同一个向量也可以在这几个设备在不同时刻中使用。当一个中断发生时,并不是所有的操作都具有急迫性,,因此Linux会把紧随中断要执行的操作分为三类:
紧急的:这样的操作比如说对pic应答中断,对pic或设备控制器中编程重修改,由设备和处理器同时访问的数据结构这样的操作都可以很快的被执行,他们是紧急的,因为他们必须要尽快的执行紧急操作!要在一个中断处理程序内立即执行,而且是在禁止可屏蔽中断的情况下
非紧急的:这样的操作比如说修改那些只有处理器才会访问的数据结构,这样的操作必须也很快完成,因此它们由中断处理程序立即执行,但它们是在开中断的情况下执行的
非紧急可延迟的:比如说把缓冲区的内容拷贝到进程的地址空间中,这样的操作可能被延迟较长的时间间隔,而不会影响内核的操作!
不管引起中断的电路类型如何所有的io中断处理程序都执行四个基本的操作:
- 在内核态堆栈中保存的值与寄存器的内容
- 为正在给线服务的pic发送个应答,这将允许pic进一步发出中断
- 执行共享这个IRQ的所有设备都中断服务例程
- 跳到ret_from_intr的地址后终止
为一个IRQ可配置设备选择一条线,有三种方式:
- 设置一些硬件跳线跳接器
- 安装设备时执行一个实用程序,这样的程序可以让用户选择一个可用的RQ号或者探测系统自身以确定一个可用的IRQ号
- 在系统启动时执行一个硬件协议,外设宣布他们准备使用哪些中断线,然后协商一个最终的值以尽可能减少冲突,该过程一旦完成,每个中断处理程序都会通过访问设备的某个IO端口函数来读取所分配的IRQ
数据结构
对于每一个外设的IRQ都用 struct irq_desc 来描述,我们称之中断描述符(struct irq_desc)。linux kernel中会有一个数据结构保存了关于所有IRQ的中断描述符信息,我们称之中断描述符DB(上图中红色框图内)。当发生中断后,首先获取触发中断的HW interupt ID,然后通过irq domain翻译成IRQ number,然后通过IRQ number就可以获取对应的中断描述符
中断描述符
通用中断处理模块可以用一个线性的table来管理一个个的外部中断,这个表的每个元素就是一个irq描述符,在kernel中定义如下:
struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
[0 ... NR_IRQS-1] = {
.handle_irq = handle_bad_irq,
.depth = 1,
.lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),
}
}; 系统中每一个连接外设的中断线(irq request line)用一个中断描述符来描述,每一个外设的 interrupt request line 分配一个中断号(irq number),系统中有多少个中断线(或者叫做中断源)就有多少个中断描述符(struct irq_desc)。NR_IRQS定义了该硬件平台IRQ的最大数目。
struct irq_desc {
struct irq_data irq_data;
unsigned int __percpu *kstat_irqs;------IRQ的统计信息
irq_flow_handler_t handle_irq;--------流控函数
struct irqaction *action; -----------处理函数
unsigned int status_use_accessors;-----中断描述符的状态,参考IRQ_xxxx
unsigned int core_internal_state__do_not_mess_with_it;
unsigned int depth;----------描述嵌套深度的信息
unsigned int wake_depth;--------电源管理中的wake up source相关
unsigned int irq_count;
unsigned long last_unhandled;
unsigned int irqs_unhandled;
raw_spinlock_t lock;
struct cpumask *percpu_enabled;
#ifdef CONFIG_SMP
const struct cpumask *affinity_hint;----和irq affinity相关,后续单独文档描述
struct irq_affinity_notify *affinity_notify;
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_var_t pending_mask;
#endif
#endif
unsigned long threads_oneshot;
atomic_t threads_active;
wait_queue_head_t wait_for_threads;
#ifdef CONFIG_PROC_FS
struct proc_dir_entry *dir;--------该IRQ对应的proc接口
#endif
int parent_irq;
struct module *owner;
const char *name;
} ____cacheline_internodealigned_in_smp响应函数 irqaction
在 irq_desc 中,struct irqaction action,主要是用来存用户注册的中断处理函数,一个中断可以有多个处理函数 ,当一个中断有多个处理函数,说明这个是共享中断。所谓*共享中断就是一个中断的来源有很多,这些来源共享同一个引脚。所以在irq_desc结构体中的action成员是个链表,以action为表头,若是一个以上的链表就是共享中断
struct irqaction {
irq_handler_t handler; //等于用户注册的中断处理函数,中断发生时就会运行这个中断处理函数
unsigned long flags; //中断标志,注册时设置,比如上升沿中断,下降沿中断等
cpumask_t mask; //中断掩码
const char *name; //中断名称,产生中断的硬件的名字
void *dev_id; //设备id
struct irqaction *next; //指向下一个成员
int irq; //中断号,
struct proc_dir_entry *dir; //指向IRQn相关的/proc/irq/
};中断数据 irq_data
中断描述符中应该会包括底层irq chip相关的数据结构,linux kernel中把这些数据组织在一起,形成struct irq_data,具体代码如下:
struct irq_data {
u32 mask;----------TODO
unsigned int irq;--------IRQ number
unsigned long hwirq;-------HW interrupt ID
unsigned int node;-------NUMA node index
unsigned int state_use_accessors;--------底层状态,参考IRQD_xxxx
struct irq_chip *chip;----------该中断描述符对应的irq chip数据结构
struct irq_domain *domain;--------该中断描述符对应的irq domain数据结构
void *handler_data;--------和外设specific handler相关的私有数据
void *chip_data;---------和中断控制器相关的私有数据
struct msi_desc *msi_desc;
cpumask_var_t affinity;-------和irq affinity相关
};操作合集 irq_chip
struct irq_chip {
const char *name;
unsigned int (*irq_startup)(struct irq_data *data);-------------初始化中断
void (*irq_shutdown)(struct irq_data *data);----------------结束中断
void (*irq_enable)(struct irq_data *data);------------------使能中断
void (*irq_disable)(struct irq_data *data);-----------------关闭中断
void (*irq_ack)(struct irq_data *data);---------------------应答中断
void (*irq_mask)(struct irq_data *data);--------------------屏蔽中断
void (*irq_mask_ack)(struct irq_data *data);----------------应答并屏蔽中断
void (*irq_unmask)(struct irq_data *data);------------------解除中断屏蔽
void (*irq_eoi)(struct irq_data *data);---------------------发送EOI信号,表示硬件中断处理已经完成。
int (*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);--------绑定中断到某个CPU
int (*irq_retrigger)(struct irq_data *data);----------------重新发送中断到CPU
int (*irq_set_type)(struct irq_data *data, unsigned int flow_type);----------------------------设置触发类型
int (*irq_set_wake)(struct irq_data *data, unsigned int on);-----------------------------------使能/关闭中断在电源管理中的唤醒功能。
void (*irq_bus_lock)(struct irq_data *data);
void (*irq_bus_sync_unlock)(struct irq_data *data);
void (*irq_cpu_online)(struct irq_data *data);
void (*irq_cpu_offline)(struct irq_data *data);
void (*irq_suspend)(struct irq_data *data);
void (*irq_resume)(struct irq_data *data);
void (*irq_pm_shutdown)(struct irq_data *data);
...
unsigned long flags;
}软中断,Tasklet和Work Queue
由内核执行的几个任务之间有一些不是紧急的,他们可以被延缓一段时间!把可延迟的中断从中断处理程序中抽出来,有利于使得内核保持较短的响应时间,所以我们现在使用以下面的这些结构,来把这样的非紧急的中断处理函数抽象出来!下面列出还在使用三个的机制:
软中断(softirq):内核2.3引入,是最基本、最优先的软中断处理形式,为了避免名字冲突,本文中将这种子类型的软中断叫softirq。
tasklet:其底层使用softirq机制实现,提供了一种用户方便使用的软中方式,为软中断提供了很好的扩展性。(封装了soft_irq)
work queue:前两种软中断执行时是禁止抢占的(softirq的ksoftirq除外),对于用户进程不友好。如果在softirq执行时间过长,会继续推后到work queue中执行,work queue执行处于进程上下文,其可被抢占,也可以被调度,如果软中断需要执行睡眠、阻塞,直接选择work queue。
软中断
前已注册的软中断有10种,定义为一个全局数组:
static struct softirq_action softirq_vec[NR_SOFTIRQS];
enum {
HI_SOFTIRQ = 0, /* 优先级高的tasklets */
TIMER_SOFTIRQ, /* 定时器的下半部 */
NET_TX_SOFTIRQ, /* 发送网络数据包 */
NET_RX_SOFTIRQ, /* 接收网络数据包 */
BLOCK_SOFTIRQ, /* BLOCK装置 */
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, /* 正常优先级的tasklets */
SCHED_SOFTIRQ, /* 调度程序 */
HRTIMER_SOFTIRQ, /* 高分辨率定时器 */
RCU_SOFTIRQ, /* RCU锁定 */
NR_SOFTIRQS /* 10 */
};(2)注册软中断处理函数
/**
* @nr: 软中断的索引号
* @action: 软中断的处理函数
*/
void open_softirq(int nr, void (*action) (struct softirq_action *))
{
softirq_vec[nr].action = action;
}例如:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);(3)触发软中断
调用raise_softirq()来触发软中断。
void raise_softirq(unsigned int nr)
{
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
/* This function must run with irqs disabled */
inline void rasie_softirq_irqsoff(unsigned int nr)
{
__raise_softirq_irqoff(nr);
/* If we're in an interrupt or softirq, we're done
* (this also catches softirq-disabled code). We will
* actually run the softirq once we return from the irq
* or softirq.
* Otherwise we wake up ksoftirqd to make sure we
* schedule the softirq soon.
*/
if (! in_interrupt()) /* 如果不处于硬中断或软中断 */
wakeup_softirqd(void); /* 唤醒ksoftirqd/n进程 */
}Percpu变量irq_cpustat_t中的__softirq_pending是等待处理的软中断的位图,通过设置此变量即可告诉内核该执行哪些软中断。
static inline void __rasie_softirq_irqoff(unsigned int nr)
{
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
typedef struct {
unsigned int __softirq_pending;
unsigned int __nmi_count; /* arch dependent */
} irq_cpustat_t;
irq_cpustat_t irq_stat[];
#define __IRQ_STAT(cpu, member) (irq_stat[cpu].member)
#define or_softirq_pending(x) percpu_or(irq_stat.__softirq_pending, (x))
#define local_softirq_pending() percpu_read(irq_stat.__softirq_pending)唤醒ksoftirqd内核线程处理软中断。
static void wakeup_softirqd(void)
{
/* Interrupts are disabled: no need to stop preemption */
struct task_struct *tsk = __get_cpu_var(ksoftirqd);
if (tsk && tsk->state != TASK_RUNNING)
wake_up_process(tsk);
}在下列地方,待处理的软中断会被检查和执行:
a. 从一个硬件中断代码处返回时
b. 在ksoftirqd内核线程中
c. 在那些显示检查和执行待处理的软中断的代码中,如网络子系统中
而不管是用什么方法唤起,软中断都要在do_softirq()中执行。如果有待处理的软中断,do_softirq()会循环遍历每一个,调用它们的相应的处理程序。
在中断处理程序中触发软中断是最常见的形式。中断处理程序执行硬件设备的相关操作,然后触发相应的软中断,最后退出。内核在执行完中断处理程序以后,马上就会调用do_softirq(),于是软中断开始执行中断处理程序完成剩余的任务。
下面来看下do_softirq()的具体实现。
asmlinkage void do_softirq(void)
{
__u32 pending;
unsigned long flags;
/* 如果当前已处于硬中断或软中断中,直接返回 */
if (in_interrupt())
return;
local_irq_save(flags);
pending = local_softirq_pending();
if (pending) /* 如果有激活的软中断 */
__do_softirq(); /* 处理函数 */
local_irq_restore(flags);
}/* We restart softirq processing MAX_SOFTIRQ_RESTART times,
* and we fall back to softirqd after that.
* This number has been established via experimentation.
* The two things to balance is latency against fairness - we want
* to handle softirqs as soon as possible, but they should not be
* able to lock up the box.
*/
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
/* 本函数能重复触发执行的次数,防止占用过多的cpu时间 */
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
pending = local_softirq_pending(); /* 激活的软中断位图 */
account_system_vtime(current);
/* 本地禁止当前的软中断 */
__local_bh_disable((unsigned long)__builtin_return_address(0), SOFTIRQ_OFFSET);
lockdep_softirq_enter(); /* current->softirq_context++ */
cpu = smp_processor_id(); /* 当前cpu编号 */
restart:
/* Reset the pending bitmask before enabling irqs */
set_softirq_pending(0); /* 重置位图 */
local_irq_enable();
h = softirq_vec;
do {
if (pending & 1) {
unsigned int vec_nr = h - softirq_vec; /* 软中断索引 */
int prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(vec_nr);
trace_softirq_entry(vec_nr);
h->action(h); /* 调用软中断的处理函数 */
trace_softirq_exit(vec_nr);
if (unlikely(prev_count != preempt_count())) {
printk(KERN_ERR "huh, entered softirq %u %s %p" "with preempt_count %08x,"
"exited with %08x?\n", vec_nr, softirq_to_name[vec_nr], h->action, prev_count,
preempt_count());
}
rcu_bh_qs(cpu);
}
h++;
pending >>= 1;
} while(pending);
local_irq_disable();
pending = local_softirq_pending();
if (pending & --max_restart) /* 重复触发 */
goto restart;
/* 如果重复触发了10次了,接下来唤醒ksoftirqd/n内核线程来处理 */
if (pending)
wakeup_softirqd();
lockdep_softirq_exit();
account_system_vtime(current);
__local_bh_enable(SOFTIRQ_OFFSET);
}(4)ksoftirqd内核线程
内核不会立即处理重新触发的软中断。当大量软中断出现的时候,内核会唤醒一组内核线程来处理。这些线程的优先级最低(nice值为19),这能避免它们跟其它重要的任务抢夺资源。但它们最终肯定会被执行,所以这个折中的方案能够保证在软中断很多时用户程序不会因为得不到处理时间而处于饥饿状态,同时也保证过量的软中断最终会得到处理。
每个处理器都有一个这样的线程,名字为ksoftirqd/n,n为处理器的编号。
static int run_ksoftirqd(void *__bind_cpu)
{
set_current_state(TASK_INTERRUPTIBLE);
current->flags |= PF_KSOFTIRQD; /* I am ksoftirqd */
while(! kthread_should_stop()) {
preempt_disable();
if (! local_softirq_pending()) { /* 如果没有要处理的软中断 */
preempt_enable_no_resched();
schedule();
preempt_disable():
}
__set_current_state(TASK_RUNNING);
while(local_softirq_pending()) {
/* Preempt disable stops cpu going offline.
* If already offline, we'll be on wrong CPU: don't process.
*/
if (cpu_is_offline(long)__bind_cpu))/* 被要求释放cpu */
goto wait_to_die;
do_softirq(); /* 软中断的统一处理函数 */
preempt_enable_no_resched();
cond_resched();
preempt_disable();
rcu_note_context_switch((long)__bind_cpu);
}
preempt_enable();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
wait_to_die:
preempt_enable();
/* Wait for kthread_stop */
set_current_state(TASK_INTERRUPTIBLE);
while(! kthread_should_stop()) {
schedule();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
}Tasklet API
动态初始化函数:
void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)t: struct tasklet_struct结构指针func:小任务函数data:传递给工作函数的实际参数
静态初始化:静态初始化DECLARE_TASKLET(name, func, data),定义一个名字为 name 的结构变量 ,并且使用 func,data对结构进行初始化,这个宏定义的 tasklet 是可调度的。静态初始化DECLARE_TASKLET_DISABLED(name, func, data)和DECLARE_TASKLET(name, func, data),不同是它开始不能被调度。必须先把 count 设置为0,才可以调度
name:struct tasklet_struct的名字
func:tasklet函数指针
data:传递给func函数的参数激活/取消激活 tasklet
void tasklet_disable(struct tasklet_struct *t) // 把 count 设置为1
void tasklet_enable (struct tasklet_struct *t) // 把count 设置为0调度函数
void tasklet_schedule (struct tasklet_struct *t)调度某个指定的tasklet小任务,调用后tasklet关联的函数会执行.一旦执行,则会在适当时候去执行 tasklet_struct 绑定的函数。对同一个 struct tasklet_struct 连续调度多次,效果等同一次(前提条件:当前一次调用,绑定函数还没有执行)。
5)kill掉函数(取消任务)
tasklet_kill(struct tasklet_struct *t);6) tasklet和普通工作队列区别:
它所绑定的函数不能休眠
它的响应速度高于普通工作队列。
tasklet 微线程的编程步骤:
taskle 内核机制实现过程是非常复杂的,但是对于驱动开发者来说,重点是掌握如果使用内核已经给我们实现好的tasklet机制。tasklet编程其实只有简单的几步,下面我们总结一下tasklet机制的编程步骤。
1. 定义tasklet 工作函数
2. 定义tasklet 结构变量
定义分有静态定义和动态定义两种方式:
// 动态定义:
struct tasklet_struct my_tasklet;
// 静态定义:
DECLARE_TASKLET(my_tasklet, my_tasklet_function, data);3. 初始化tasklet结构,绑定工作函数
如果上一步是采用静态定义,则这一步不用再做,跳过。如果是采用动态定义tasklet,则使用tasklet_init()函数进行初始化以及绑定。
tasklet_init(&my_tasklet, my_tasklet_function, data)4. 在适当的地方调度工作函数
tasklet一般是用于处理中断的下半部的,所以一般在中断的上半部调度tasklet工作函数。
tasklet_schedule(&my_tasklet);5. 销毁tasklet工作任务
在确定不再使用tasklet时,应该在适当的地方调用tasklet_kill()函数销毁tasklet任务,释放资源,这个适当的地方一般的tasklet初始化地方是相反的,比如,如果是在模块初始化函数初始化了tasklet,则相应地是在模块卸载函数调用tasklet_kill函数来销毁tasklet任务。
tasklet_kill(&my_tasklet);从中断和异常返回
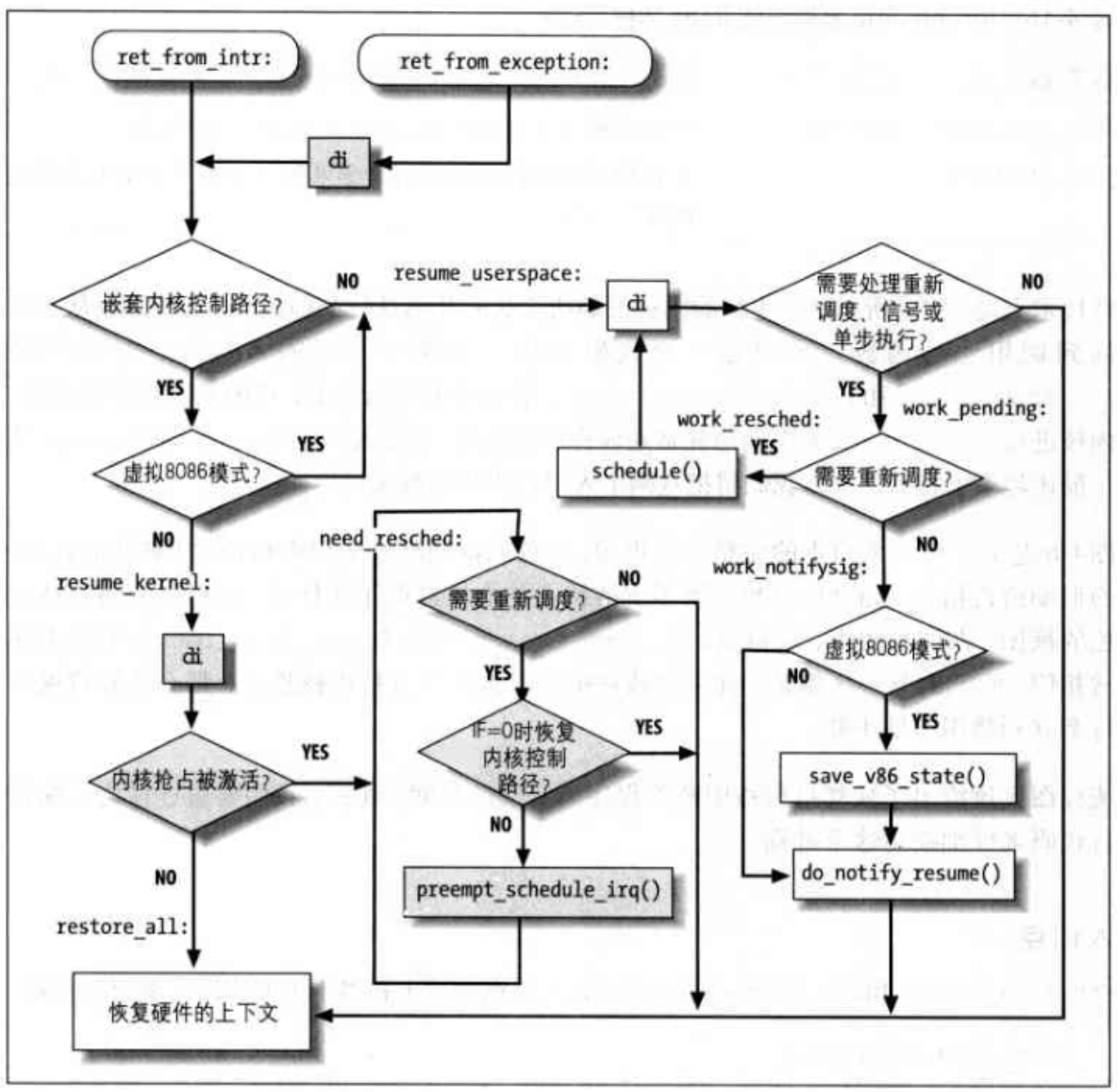
我们用《深入理解Linux内核》的一张大图来收尾。
我们的ret_from_intr和ret_from_exception本质上等价于:
入口点
ret_from_exception:
cli // 只有从异常返回时才使用 cli,禁用本地中断
ret_from_intr:
movl $-8192, %ebp // 将当前 thread_info 描述符的地址装载到 ebp 寄存器
andl %esp, %ebp
movl 0x30(%esp), %eax
movb 0x2c(%esp), %al
// 根据发生中断或异常压入栈中的 cs 和 eflags 寄存器的值,
// 确定中断的程序在中断时是否运行在用户态
testl $0x0002003, %eax
jnz resume_userspace
jpm resume_kernel恢复内核控制路径
rusume_kernel:
cli
cmpl $0, 0x14(%ebp) // 如果 thread_info 描述符的 preempt_count 字段为0(运行内核抢占)
jz need_resched // 跳到 need_resched
restore_all: // 否则,被中断的程序重新开始执行
popl %ebx
popl %ecx
popl %edx
popl %esi
popl %edi
popl %ebp
popl %eax
popl %ds
popl %es
addl $4, %esp
iret // 结束控制检查内核抢占
need_resched:
movl 0x8(%ebp), %ecx
testb $(1<<TIF_NEED_RESCHED), %cl // 如果 current->thread_info 的 flags 字段中的 TIF_NEED_RESCHED == 0,没有需要切换的进程
jz restore_all // 因此跳到 restore_all
testl $0x00000200, 0x30(%ebp) // 如果正在被恢复的内核控制路径是在禁用本地 CPU 的情况下运行
jz restore_all // 也跳到 restore_all,否则进程切换可能回破坏内核数据结构
call preempt_schedule_irq // 进程切换,设置 preempt_count 字段的 PREEMPT_ACTIVE 标志,大内核锁计数器暂时设置为 -1,调用 schedule()
jmp need_resched 恢复用户态程序
resume_userspace:
cli // 禁用本地中断
movl 0x8(%ebp), %ecx
// 检测 current->thread_info 的 flags 字段,
// 如果只设置了 TIF_SYSCALL_TRACE,TIF_SYSCALL_AUDIT 或 TIF_SINGLESTEP 标志,
// 跳到 restore_all
andl $0x0000ff6e, %ecx
je restore_all
jmp work_pending检测重调度标志
work_pending:
testb $(1<<TIF_NEED_RESCHED), %cl
jz work_notifysig
work_resched:
call schedule // 如果进程切换请求被挂起,选择另外 一个进程运行
cli
jmp resume_userspace // 当前面的进程要恢复时处理挂起信号、虚拟 8086 模式和单步执行
work_notifysig:
movl %esp, %eax
testl $0x00020000, 0x30(%esp)
je 1f
// 如果用户态程序 eflags 寄存器的 VM 控制标志被设置
work_notifysig_v86:
pushl %ecx
call save_v86_state // 在用户态地址空间建立虚拟8086模式的数据结构
popl %ecx
movl %eax, %esp
1:
xorl %edx, %edx
call do_notify_resume // 处理挂起信号和单步执行
jmp restore_all // 恢复被中断的程序Reference
Linux内核19-中断描述符表IDT的初始化-腾讯云开发者社区-腾讯云 (tencent.com)
Linux内核硬中断 / 软中断的原理和实现-腾讯云开发者社区-腾讯云 (tencent.com)
linux内核之tasklet使用_tasklet 改绑定-CSDN博客
深入理解 Linux 内核—-中断和异常_ret_from_exception-CSDN博客中断与异常
中断通常被定义为一个事件:让事件改变处理器执行的指令顺序这样的事件,与CPU芯片内外部硬件电路产生的电信号相对应!
中断通常分为同步中断与异步中断:
同步中断指的是当指令执行时,由CPU控制单元产生的。之所以称为同步,是因为只有在一条指令终止执行后,CPU才会发出中断!
异步中断是由其他硬件设备依照CPU时钟信号随机产生的
在英特尔微处理器手册中:也会把同步和异步中断分别称为异常和中断
中断则是由间隔定时器或者io设备产生的,举个例子你敲击键盘的时候,你的一次按键就会引发一个中断,希望操作系统介入进行处理!
另一方面异常是由程序的错误产生的,或者是由内核必须处理的异常条件产生的!比如说内核通过发送一个信号来处理异常,或者内核执行恢复异常所需要的步骤,比如说缺页,比如说对内核服务的一个请求
中断信号的作用
顾名思义,中断信号提供了一种特殊的方式来让处理器转而去运行正常控制流之外的代码。当一个中断信号到达的时候CPU必须停止它当前所做的事情,转而切换去处理这些终端。为了做到这一点就需要把内核态堆栈保存PC当前的值,并且把中断相关类型的的一个地址放进程序计数器中。这样才会跳转去执行处理中断的代码。
中断处理器内核执行的最敏感的任务之一,因为它必须要满足:
- 让内核正打算去完成别的事情的,由于中断随时都会到来,因此内核的目标就是:让中断尽可能的处理完尽可能把更多的更详细的处理向后推,所以中断响应分为两个部分:
- 关键而紧急的部分这一部分,内核立即执行。
- 其推迟的部分,则是内核随后执行。
- 因为中断随时会到来,所以内核可能正在处理其中一个中断的时候,另一个中断又发生了。应该尽可能地允许这种情况发生,因为这将会保持更多的io设备处于忙状态。因此中断处理程序必须编写成可以使相应的内核控制路径以嵌套的方式进行,执行到最后一个内核控制路径终止时,内核可以恢复被中断进程的执行,或者如果中断信号已导致了重新调度,内核可以切换到另外的进程。
- 尽管内核在处理前一个中断的时候,可以接受新的中断,但在内核代码区中仍然存在着一些临界区,在这些临界区中中断必须被禁止
中断和异常
英特尔文档把中断和异常又分为了以下几类:
- 中断:
又分出两类即:
类型 说明 可屏蔽中断 IO设备发出的所有中断请求(Interruppt Request)都产生可屏蔽的中断,它处于两状态:屏蔽的和非屏蔽的,如果一个中断是被屏蔽的,那么控制单元会被它会忽略它 非可屏蔽中断 只有少数的几个危机事件是这样的,非屏蔽的中断总是由CPU辨认 异常:
异常分两类,处理器探测异常和编程异常。
处理器探测异常有三种
类型 说明 故障 通常可以被纠正,一旦纠正,程序就可以在不失连贯性的情况下,重新开始!保存在EIP中的值就是引起故障的指令地址,因此当异常处理程序终止时,那条指令会被重新执行 陷阱 在陷阱执行后,立即报告内核把控制权返回给程序后,就可以继续它的执行而不失去连贯性。保存在EIP中的值是一个随后要执行的指令地址,只有当没有必要重新执行已中止的指令时,才会触发陷阱。陷阱的主要目的是为了调试程序 异常终止 异常终止指的是发生了一个严重的错误及控制单元出现了问题,不能在EIP寄存器中保存引发了这个异常指令所在的确切位置。异常终止用的报告严重的错误,如硬件故障或系统表中无效的值或不一样的值。 编程异常:在编程者发出请求时发生是由int或int3指令触发的当into(检查溢出)和bound(检查地址出界)指令检查的条件不为真时,会引发编程异常控制单元!编程异常当作陷阱来处理,编程异常也被称为软中断,这样的异常常有两种的用途执行:系统调用以及给调试程序通报一个特定的事件。
IRQ与中断
每个能够发出中断请求的硬件设备系都有一条名为IRQ的输出线,所有现有的IRQ线都与一个名为可编程中断控制器的硬件电路的输入引脚相连,可编程中断控制器执行下列动作:
- 监视IRQ线检查产生的信号,如果有两条或两条以上的IRQ线上产生信号,选择引脚编号较小的IRQ线
- 如果一个引发信号出现在线上,那么它会把接收到的信发信号转换成对应的向量,把这个向量存放在中断控制器的一个io端口,从而允许CPU通过数据总线读取此向量。把引发信号发送到处理器的INTR引脚,也就是产生了一个中断
- 等待直到CPU通过把这个中断信号写进可编程中断控制器的io端口号,来确认它,当这种情况发生时,清理INTR线。然后继续监视。
异常
这里给出一些常见的异常:
异 常 一 览 表 向量号 异常名称 异常类型 出错代码 相关指令 0 除法出错 故障 无 DIV,IDIV 1 调试异常 故障/陷阱 无 任何指令 3 单字节INT3 陷阱 无 INT 3 4 溢出 陷阱 无 INTO 5 边界检查 故障 无 BOUNT 6 非法操作码 故障 无 非法指令编码或操作数 7 设备不可用 故障 无 浮点指令或WAIT 8 双重故障 中止 有 任何指令 9 协处理器段越界 中止 无 访问存储器的浮点指令 0AH 无效TSS异常 故障 有 JMP、CALL、IRET或中断 0BH 段不存在 故障 有 装载段寄存器的指令 0CH 堆栈段异常 故障 有 装载SS寄存器的任何指令、对SS寻址的段访问的任何指令 0DH 通用保护异常 故障 有 任何特权指令、任何访问存储器的指令 0EH 页异常 故障 有 任何访问存储器的指令 10H 协处理器出错 故障 无 浮点指令或WAIT 11H—0FFH 软中断 陷阱 无 INT n 中断向量表
中断描述符表IDT是一个系统表,它与每一个中断或者异常向量相联系
每一个向量在表中都有相应的中断或异常处理程序的入口地址,内核在允许中断发生前,必须适当初始化IDT
下图为IDT的结构表示图:
这些描述符是:
- 任务门
Task Gate:当中断信号发生时,必须取代当前进程的那个进程的TSS选择符,存放在任务门中- 中断门
Interrupt Gate:包含段选择符和中断或异常处理程序的段内偏移量,当控制权转移到应适当的段时,处理器清IF标志,从而关闭即将会发生的可屏蔽中断。- 陷阱门
Trap Gate:与中断门相似只是控制权传递到一个适当的段时处理器不修改IF标志Linux使用中断门处理中断应用陷阱门处理异常硬件处理
现在描述CPU控制单元是如何处理中断和异常的!
我们现在假定内核已经被初始化,因此CPU将会在保护模式下运行。
当执行了一条指令后,CS和EIP这对寄存器将会包含下一条将要执行的指令的逻辑地址。在处理那条指令之前控制单元会检查在运行前一条指令是否已经发生一个中断或者异常,如果发生了,那么它将会:
确定与中断或异常关联的向量(看一眼是哪个异常)
读由寄存器指向的
IDT表中的i项(肘!IDT表爆破)从
gdpr寄存器中获取GDP的基地址,并在GDP中查找,以读取IDT表项的选择符所标识的段描述符。这个描述符指定中断或异常处理程序所在段的基地址(看看这个程序在哪里)确信中断事由授权的中断发生源发出的,首先将当前特权级CPL与段描述符的描述符特权级DPL的相比较:如果CPL小于DPL了就会产生一个
general protection异常,因为中断处理程序的特权不能低于引起中断的程序的特权!对于编程异常则需要做进一步的安全检查:比较CPL了与处于IDT中的门描述符的DPL了,如果DPL小于CPL了那么就产生一个general protection,这最后一个检查可以避免用户应用程序访问特殊的陷阱门和中断门(配不配处理这个异常)检查是否发生了特权级变化:也就是说CPL是否不同于所选择的段描述符的DPL,如果是,控制单元必须开始使用与新的特权级相关的栈,通过执行以下步骤来做到这一点:
- 读TR寄存器以访问运行进程的TSS段
- 用于新特权级相关的栈段和栈指针的正确值装载SS和ESP寄存器这些值,可以在TSS中找到在新的段中
- 保存SS和ESP以前的值,这些值定义了与旧特训级相关的栈的逻辑地址。
如果故障已经发生,用引起异常的指令地址装载CS和EIP寄存器,从而使得这条指令能够再次被执行!
在栈中保存eflags,cs,EIP等内容,如果引用异常产生了一个硬件出错码,把它保存到栈中,装在CS和EIP寄存器其值分别为IDT表中第I项门描述服务的段选择符和偏移量字段,这些值给出了中断或者异常处理的第一条指令的逻辑地址!
控制单元所执行的最后一步就是跳转到这些异常处理程序,换句话说处理完中断信号后控制单元所执行的指令,就是被选中处理程序的第一条指令!
当中断或处理结束后和异常被处理结束后相应的处理程序必须参与生一条iret指令,他把控制权转交给被中断的进程。这将会迫使控制单元:
- 用保存在栈中的值装在CS或eflags寄存器,如果一个硬件出错码曾经被压入栈中,并且在EIP内容的上面,那么执行Iret指令前必须弹出这个硬件错误码(准备回家)
- 检查处理程序的CPL是否等于CS中的最低两位的值如果是iret终止执行,否则执行下一步。(看看特权级够不够)
- 从栈中装载SS和ESP寄存器因此返回到与特权级相关的栈(也就是恢复栈)
- 检查DS ES FS 以及 GS段寄存器的内容,如果其中一个寄存器包含选择符是一个段描述符,并且其的DPL值小于CPL了,那么我们会清理相应的段寄存器控制单元,这么做是为了防止用户态的程序利用内核以前所用的段寄存器,如果不清理这些寄存器,那么一些怀有恶意的用户态程序就有可能利用他们来访问内核地址。(安全处理,安全恢复环境)
中断和异常处理程序的嵌套执行
每个中断或异常都会引起一个内核控制路径,或者说当前的进程在内核态执行单独的指令序列。
内核控制路径可以任意嵌套!一个中断处理程序可以被另一个中断处理程序所中断,因此这样就引起了内核控制路径的嵌套执行。允许内核控制路径嵌套执行必须要付出相应的代价,也就是中断处理程序必须永不阻塞换,中断处理程序在运行期间是不能够发生进程切换。
基于以下两个主要原因,Linux交错执行内核控制路径:
- 为了提高可编程中断控制器和设备控制中器的吞吐量。假定设备控制器在一条线上产生了一条信号,pic把这个信号转换成一个外部中断,然后pic和控制设备器保持阻塞一直到pic从内核CPU处接收一条应答信息!由于内核控制路径的交错执行内核即使正在处理前一个中断也能够发送应答。
- 为了实现一种没有优先级的中断模型,每个C中断处理程序都可以被另一个中断处理程序所延缓,因此在硬件设备之间没必要预定义优先级,这简化了内核代码,也提高了内核的可移植性!
初始化IDT
Linux在基于Intel给出的三种门之外,还更加细分了他们:
中断门(interrupt gate):用户态的进程不能访问的一个lntel中断门(门的DPL字段为0)。所有的Linux中 断处理程序都通过中断门激活,并全部限制在内核态。
系统门(syslem gate):用户态的进程可以访问的一个Intel陷阱门(门的DPL字段为到.通过系统门来激 活三个Linux异常处理程序,它们的向量是4,5及128,因此,在用户态下.可以 发布into、 bound及int $Ox80三条汇编语言指令。
系统中断门(system interrupt gate):能够被用户态进程访问的Intel中断门(门的DPL字段为3). 与向量3相关的异常 处理程序是由系统中断门激活的,因此,在用户态可以使用汇编语言指令int3.
陷阱门(Irapgate):用户态的进程不能访问的一个Inte)陷阱门(f]的DPL字段为0). 大部分Linux异 常处理程序都通过陷阱门来激活.
任务门(task gate):不能被用户态进程访问的Intel任务门(门的DPL字段为0).Linux对”Doublefault” 异常的处理程序是由任务门激活的.
IDT会被初始化两次。第一次是在BIOS程序中,此时CPU还工作在实模式下。一旦Linux启动,IDT会被搬运到RAM的受保护区域并被第二次初始化,因为Linux不会使用任何BIOS程序。
IDT结构被存储在idt_table表中,包含256项。idt_descr变量存储IDT的大小和它的地址,在系统的初始化阶段,内核用来设置idtr寄存器,专用汇编指令是lidt。
内核初始化的时候,汇编函数setup_idt()用相同的中断门填充idt_table表的所有项,都指向ignore_int()中断处理函数:
>setup_idt: lea ignore_int, %edx movl $(__KERNEL_CS << 16), %eax movw %dx, %ax /* = 0x0010 = cs */ movw $0x8e00, %dx /* 中断门,DPL=0 */ lea idt_table, %edi /* 加载idt表的地址到寄存器edi中 */ mov $256, %ecx >rp_sidt: movl %eax, (%edi) /* 设置中断处理函数 */ movl %edx, 4(%edi) /* 设置段描述符 */ addl $8, %edi /* 跳转到IDT表的下一项 */ dec %ecx /* 自减 */ jne rp_sidt ret中断处理函数
ignore_int(),也是一个汇编语言编写的函数,相当于一个null函数,它执行:
- 保存一些寄存器到堆栈中。
- 调用printk()函数打印
Unknown interrupt系统消息`。- 从堆栈中恢复寄存器的内容。
- 执行iret指令回到调用处。
正常情况下,此时的中断处理函数ignore_int()是不应该被执行的。如果在console或者log日志中出现
Unknown interrupt的消息,说明发生硬件错误或者内核错误。 完成这次IDT表的初始化之后,内核还会进行第二次初始化,用真正的trap或中断处理函数代替刚才的null函数。一旦这两步初始化都完成,IDT表就包含具体的中断、陷阱和系统门,用以控制每个中断请求。
中断处理
这里讨论三种中断类型:
IO中断,时钟中断。和处理器间中断io
中断处理程序必须足够灵活地给多个设备同时提供服务,比如说在PCI总线的体系架构中几个设备可以共享一个IRQ线,这也就意味着仅仅中断向量是并不能说明所有问题的!中断处理程序的灵活性是以两种不同的方式实现的:
IRQ共享
中断处理程序执行多个中断服务例程,每个中断服务例程是一个与单独设备相关的函数,因此不可能预先知道哪个特定的设备产生,因此每个IRQ,也就是中断服务例程,都会被执行验证它的设备是否需要关注,如果是,当设备产生中断时则需要执行相关的所有操作
IRQ动态分配
一条线可能在最后的时刻才会与一个设备驱动程序相关联,这样,即使几个硬件设备并不共享线,同一个向量也可以在这几个设备在不同时刻中使用。当一个中断发生时,并不是所有的操作都具有急迫性,,因此Linux会把紧随中断要执行的操作分为三类:
紧急的:这样的操作比如说对pic应答中断,对pic或设备控制器中编程重修改,由设备和处理器同时访问的数据结构这样的操作都可以很快的被执行,他们是紧急的,因为他们必须要尽快的执行紧急操作!要在一个中断处理程序内立即执行,而且是在禁止可屏蔽中断的情况下
非紧急的:这样的操作比如说修改那些只有处理器才会访问的数据结构,这样的操作必须也很快完成,因此它们由中断处理程序立即执行,但它们是在开中断的情况下执行的
非紧急可延迟的:比如说把缓冲区的内容拷贝到进程的地址空间中,这样的操作可能被延迟较长的时间间隔,而不会影响内核的操作!
不管引起中断的电路类型如何所有的io中断处理程序都执行四个基本的操作:
- 在内核态堆栈中保存的值与寄存器的内容
- 为正在给线服务的pic发送个应答,这将允许pic进一步发出中断
- 执行共享这个IRQ的所有设备都中断服务例程
- 跳到ret_from_intr的地址后终止
为一个IRQ可配置设备选择一条线,有三种方式:
- 设置一些硬件跳线跳接器
- 安装设备时执行一个实用程序,这样的程序可以让用户选择一个可用的RQ号或者探测系统自身以确定一个可用的IRQ号
- 在系统启动时执行一个硬件协议,外设宣布他们准备使用哪些中断线,然后协商一个最终的值以尽可能减少冲突,该过程一旦完成,每个中断处理程序都会通过访问设备的某个IO端口函数来读取所分配的IRQ
数据结构
对于每一个外设的IRQ都用 struct irq_desc 来描述,我们称之中断描述符(struct irq_desc)。linux kernel中会有一个数据结构保存了关于所有IRQ的中断描述符信息,我们称之中断描述符DB(上图中红色框图内)。当发生中断后,首先获取触发中断的HW interupt ID,然后通过irq domain翻译成IRQ number,然后通过IRQ number就可以获取对应的中断描述符
中断描述符
通用中断处理模块可以用一个线性的table来管理一个个的外部中断,这个表的每个元素就是一个irq描述符,在kernel中定义如下:
>struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = { [0 ... NR_IRQS-1] = { .handle_irq = handle_bad_irq, .depth = 1, .lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock), } >}; 系统中每一个连接外设的中断线(irq request line)用一个中断描述符来描述,每一个外设的 interrupt request line 分配一个中断号(irq number),系统中有多少个中断线(或者叫做中断源)就有多少个中断描述符(struct irq_desc)。NR_IRQS定义了该硬件平台IRQ的最大数目。
>struct irq_desc { struct irq_data irq_data; unsigned int __percpu *kstat_irqs;------IRQ的统计信息 irq_flow_handler_t handle_irq;--------流控函数 struct irqaction *action; -----------处理函数 unsigned int status_use_accessors;-----中断描述符的状态,参考IRQ_xxxx unsigned int core_internal_state__do_not_mess_with_it; unsigned int depth;----------描述嵌套深度的信息 unsigned int wake_depth;--------电源管理中的wake up source相关 unsigned int irq_count; unsigned long last_unhandled; unsigned int irqs_unhandled; raw_spinlock_t lock; struct cpumask *percpu_enabled; >#ifdef CONFIG_SMP const struct cpumask *affinity_hint;----和irq affinity相关,后续单独文档描述 struct irq_affinity_notify *affinity_notify; >#ifdef CONFIG_GENERIC_PENDING_IRQ cpumask_var_t pending_mask; >#endif >#endif unsigned long threads_oneshot; atomic_t threads_active; wait_queue_head_t wait_for_threads; >#ifdef CONFIG_PROC_FS struct proc_dir_entry *dir;--------该IRQ对应的proc接口 >#endif int parent_irq; struct module *owner; const char *name; >} ____cacheline_internodealigned_in_smp响应函数 irqaction
在 irq_desc 中,struct irqaction action,主要是用来存用户注册的中断处理函数,一个中断可以有多个处理函数 ,当一个中断有多个处理函数,说明这个是共享中断。所谓*共享中断就是一个中断的来源有很多,这些来源共享同一个引脚。所以在irq_desc结构体中的action成员是个链表,以action为表头,若是一个以上的链表就是共享中断
>struct irqaction { irq_handler_t handler; //等于用户注册的中断处理函数,中断发生时就会运行这个中断处理函数 unsigned long flags; //中断标志,注册时设置,比如上升沿中断,下降沿中断等 cpumask_t mask; //中断掩码 const char *name; //中断名称,产生中断的硬件的名字 void *dev_id; //设备id struct irqaction *next; //指向下一个成员 int irq; //中断号, struct proc_dir_entry *dir; //指向IRQn相关的/proc/irq/ >};中断数据 irq_data
中断描述符中应该会包括底层irq chip相关的数据结构,linux kernel中把这些数据组织在一起,形成struct irq_data,具体代码如下:
>struct irq_data { u32 mask;----------TODO unsigned int irq;--------IRQ number unsigned long hwirq;-------HW interrupt ID unsigned int node;-------NUMA node index unsigned int state_use_accessors;--------底层状态,参考IRQD_xxxx struct irq_chip *chip;----------该中断描述符对应的irq chip数据结构 struct irq_domain *domain;--------该中断描述符对应的irq domain数据结构 void *handler_data;--------和外设specific handler相关的私有数据 void *chip_data;---------和中断控制器相关的私有数据 struct msi_desc *msi_desc; cpumask_var_t affinity;-------和irq affinity相关 >};操作合集 irq_chip
>struct irq_chip { const char *name; unsigned int (*irq_startup)(struct irq_data *data);-------------初始化中断 void (*irq_shutdown)(struct irq_data *data);----------------结束中断 void (*irq_enable)(struct irq_data *data);------------------使能中断 void (*irq_disable)(struct irq_data *data);-----------------关闭中断 void (*irq_ack)(struct irq_data *data);---------------------应答中断 void (*irq_mask)(struct irq_data *data);--------------------屏蔽中断 void (*irq_mask_ack)(struct irq_data *data);----------------应答并屏蔽中断 void (*irq_unmask)(struct irq_data *data);------------------解除中断屏蔽 void (*irq_eoi)(struct irq_data *data);---------------------发送EOI信号,表示硬件中断处理已经完成。 int (*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);--------绑定中断到某个CPU int (*irq_retrigger)(struct irq_data *data);----------------重新发送中断到CPU int (*irq_set_type)(struct irq_data *data, unsigned int flow_type);----------------------------设置触发类型 int (*irq_set_wake)(struct irq_data *data, unsigned int on);-----------------------------------使能/关闭中断在电源管理中的唤醒功能。 void (*irq_bus_lock)(struct irq_data *data); void (*irq_bus_sync_unlock)(struct irq_data *data); void (*irq_cpu_online)(struct irq_data *data); void (*irq_cpu_offline)(struct irq_data *data); void (*irq_suspend)(struct irq_data *data); void (*irq_resume)(struct irq_data *data); void (*irq_pm_shutdown)(struct irq_data *data); >... unsigned long flags; >}软中断,
Tasklet和Work Queue 由内核执行的几个任务之间有一些不是紧急的,他们可以被延缓一段时间!把可延迟的中断从中断处理程序中抽出来,有利于使得内核保持较短的响应时间,所以我们现在使用以下面的这些结构,来把这样的非紧急的中断处理函数抽象出来!下面列出还在使用三个的机制:
软中断(softirq):内核2.3引入,是最基本、最优先的软中断处理形式,为了避免名字冲突,本文中将这种子类型的软中断叫softirq。
tasklet:其底层使用softirq机制实现,提供了一种用户方便使用的软中方式,为软中断提供了很好的扩展性。(封装了soft_irq)
work queue:前两种软中断执行时是禁止抢占的(softirq的ksoftirq除外),对于用户进程不友好。如果在softirq执行时间过长,会继续推后到work queue中执行,work queue执行处于进程上下文,其可被抢占,也可以被调度,如果软中断需要执行睡眠、阻塞,直接选择work queue。
软中断
前已注册的软中断有10种,定义为一个全局数组:
>static struct softirq_action softirq_vec[NR_SOFTIRQS]; >enum { HI_SOFTIRQ = 0, /* 优先级高的tasklets */ TIMER_SOFTIRQ, /* 定时器的下半部 */ NET_TX_SOFTIRQ, /* 发送网络数据包 */ NET_RX_SOFTIRQ, /* 接收网络数据包 */ BLOCK_SOFTIRQ, /* BLOCK装置 */ BLOCK_IOPOLL_SOFTIRQ, TASKLET_SOFTIRQ, /* 正常优先级的tasklets */ SCHED_SOFTIRQ, /* 调度程序 */ HRTIMER_SOFTIRQ, /* 高分辨率定时器 */ RCU_SOFTIRQ, /* RCU锁定 */ NR_SOFTIRQS /* 10 */ >};(2)注册软中断处理函数
>/** >* @nr: 软中断的索引号 >* @action: 软中断的处理函数 >*/ >void open_softirq(int nr, void (*action) (struct softirq_action *)) >{ softirq_vec[nr].action = action; >}例如:
>open_softirq(NET_TX_SOFTIRQ, net_tx_action); >open_softirq(NET_RX_SOFTIRQ, net_rx_action);(3)触发软中断
调用raise_softirq()来触发软中断。
>void raise_softirq(unsigned int nr) >{ unsigned long flags; local_irq_save(flags); raise_softirq_irqoff(nr); local_irq_restore(flags); >} >/* This function must run with irqs disabled */ >inline void rasie_softirq_irqsoff(unsigned int nr) >{ __raise_softirq_irqoff(nr); /* If we're in an interrupt or softirq, we're done * (this also catches softirq-disabled code). We will * actually run the softirq once we return from the irq * or softirq. * Otherwise we wake up ksoftirqd to make sure we * schedule the softirq soon. */ if (! in_interrupt()) /* 如果不处于硬中断或软中断 */ wakeup_softirqd(void); /* 唤醒ksoftirqd/n进程 */ >}Percpu变量irq_cpustat_t中的__softirq_pending是等待处理的软中断的位图,通过设置此变量即可告诉内核该执行哪些软中断。
>static inline void __rasie_softirq_irqoff(unsigned int nr) >{ trace_softirq_raise(nr); or_softirq_pending(1UL << nr); >} >typedef struct { unsigned int __softirq_pending; unsigned int __nmi_count; /* arch dependent */ >} irq_cpustat_t; >irq_cpustat_t irq_stat[]; >#define __IRQ_STAT(cpu, member) (irq_stat[cpu].member) >#define or_softirq_pending(x) percpu_or(irq_stat.__softirq_pending, (x)) >#define local_softirq_pending() percpu_read(irq_stat.__softirq_pending)唤醒ksoftirqd内核线程处理软中断。
>static void wakeup_softirqd(void) >{ /* Interrupts are disabled: no need to stop preemption */ struct task_struct *tsk = __get_cpu_var(ksoftirqd); if (tsk && tsk->state != TASK_RUNNING) wake_up_process(tsk); >}在下列地方,待处理的软中断会被检查和执行:
a. 从一个硬件中断代码处返回时
b. 在ksoftirqd内核线程中
c. 在那些显示检查和执行待处理的软中断的代码中,如网络子系统中
而不管是用什么方法唤起,软中断都要在do_softirq()中执行。如果有待处理的软中断,do_softirq()会循环遍历每一个,调用它们的相应的处理程序。
在中断处理程序中触发软中断是最常见的形式。中断处理程序执行硬件设备的相关操作,然后触发相应的软中断,最后退出。内核在执行完中断处理程序以后,马上就会调用do_softirq(),于是软中断开始执行中断处理程序完成剩余的任务。
下面来看下do_softirq()的具体实现。
>asmlinkage void do_softirq(void) >{ __u32 pending; unsigned long flags; /* 如果当前已处于硬中断或软中断中,直接返回 */ if (in_interrupt()) return; local_irq_save(flags); pending = local_softirq_pending(); if (pending) /* 如果有激活的软中断 */ __do_softirq(); /* 处理函数 */ local_irq_restore(flags); >}>/* We restart softirq processing MAX_SOFTIRQ_RESTART times, >* and we fall back to softirqd after that. >* This number has been established via experimentation. >* The two things to balance is latency against fairness - we want >* to handle softirqs as soon as possible, but they should not be >* able to lock up the box. >*/ >asmlinkage void __do_softirq(void) >{ struct softirq_action *h; __u32 pending; /* 本函数能重复触发执行的次数,防止占用过多的cpu时间 */ int max_restart = MAX_SOFTIRQ_RESTART; int cpu; pending = local_softirq_pending(); /* 激活的软中断位图 */ account_system_vtime(current); /* 本地禁止当前的软中断 */ __local_bh_disable((unsigned long)__builtin_return_address(0), SOFTIRQ_OFFSET); lockdep_softirq_enter(); /* current->softirq_context++ */ cpu = smp_processor_id(); /* 当前cpu编号 */ >restart: /* Reset the pending bitmask before enabling irqs */ set_softirq_pending(0); /* 重置位图 */ local_irq_enable(); h = softirq_vec; do { if (pending & 1) { unsigned int vec_nr = h - softirq_vec; /* 软中断索引 */ int prev_count = preempt_count(); kstat_incr_softirqs_this_cpu(vec_nr); trace_softirq_entry(vec_nr); h->action(h); /* 调用软中断的处理函数 */ trace_softirq_exit(vec_nr); if (unlikely(prev_count != preempt_count())) { printk(KERN_ERR "huh, entered softirq %u %s %p" "with preempt_count %08x," "exited with %08x?\n", vec_nr, softirq_to_name[vec_nr], h->action, prev_count, preempt_count()); } rcu_bh_qs(cpu); } h++; pending >>= 1; } while(pending); local_irq_disable(); pending = local_softirq_pending(); if (pending & --max_restart) /* 重复触发 */ goto restart; /* 如果重复触发了10次了,接下来唤醒ksoftirqd/n内核线程来处理 */ if (pending) wakeup_softirqd(); lockdep_softirq_exit(); account_system_vtime(current); __local_bh_enable(SOFTIRQ_OFFSET); >}(4)ksoftirqd内核线程
内核不会立即处理重新触发的软中断。当大量软中断出现的时候,内核会唤醒一组内核线程来处理。这些线程的优先级最低(nice值为19),这能避免它们跟其它重要的任务抢夺资源。但它们最终肯定会被执行,所以这个折中的方案能够保证在软中断很多时用户程序不会因为得不到处理时间而处于饥饿状态,同时也保证过量的软中断最终会得到处理。
每个处理器都有一个这样的线程,名字为ksoftirqd/n,n为处理器的编号。
>static int run_ksoftirqd(void *__bind_cpu) >{ set_current_state(TASK_INTERRUPTIBLE); current->flags |= PF_KSOFTIRQD; /* I am ksoftirqd */ while(! kthread_should_stop()) { preempt_disable(); if (! local_softirq_pending()) { /* 如果没有要处理的软中断 */ preempt_enable_no_resched(); schedule(); preempt_disable(): } __set_current_state(TASK_RUNNING); while(local_softirq_pending()) { /* Preempt disable stops cpu going offline. * If already offline, we'll be on wrong CPU: don't process. */ if (cpu_is_offline(long)__bind_cpu))/* 被要求释放cpu */ goto wait_to_die; do_softirq(); /* 软中断的统一处理函数 */ preempt_enable_no_resched(); cond_resched(); preempt_disable(); rcu_note_context_switch((long)__bind_cpu); } preempt_enable(); set_current_state(TASK_INTERRUPTIBLE); } __set_current_state(TASK_RUNNING); return 0; >wait_to_die: preempt_enable(); /* Wait for kthread_stop */ set_current_state(TASK_INTERRUPTIBLE); while(! kthread_should_stop()) { schedule(); set_current_state(TASK_INTERRUPTIBLE); } __set_current_state(TASK_RUNNING); return 0; >}Tasklet API
动态初始化函数:
>void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)
t: struct tasklet_struct结构指针func:小任务函数data:传递给工作函数的实际参数静态初始化:静态初始化DECLARE_TASKLET(name, func, data),定义一个名字为 name 的结构变量 ,并且使用 func,data对结构进行初始化,这个宏定义的 tasklet 是可调度的。静态初始化DECLARE_TASKLET_DISABLED(name, func, data)和DECLARE_TASKLET(name, func, data),不同是它开始不能被调度。必须先把 count 设置为0,才可以调度
>name:struct tasklet_struct的名字 >func:tasklet函数指针 >data:传递给func函数的参数激活/取消激活 tasklet
>void tasklet_disable(struct tasklet_struct *t) // 把 count 设置为1 >void tasklet_enable (struct tasklet_struct *t) // 把count 设置为0调度函数
>void tasklet_schedule (struct tasklet_struct *t)调度某个指定的tasklet小任务,调用后tasklet关联的函数会执行.一旦执行,则会在适当时候去执行 tasklet_struct 绑定的函数。对同一个 struct tasklet_struct 连续调度多次,效果等同一次(前提条件:当前一次调用,绑定函数还没有执行)。
5)kill掉函数(取消任务)
>tasklet_kill(struct tasklet_struct *t);6) tasklet和普通工作队列区别:
它所绑定的函数不能休眠
它的响应速度高于普通工作队列。
tasklet 微线程的编程步骤:
taskle 内核机制实现过程是非常复杂的,但是对于驱动开发者来说,重点是掌握如果使用内核已经给我们实现好的tasklet机制。tasklet编程其实只有简单的几步,下面我们总结一下tasklet机制的编程步骤。
1. 定义tasklet 工作函数
2. 定义tasklet 结构变量
定义分有静态定义和动态定义两种方式:
>// 动态定义: >struct tasklet_struct my_tasklet; >// 静态定义: >DECLARE_TASKLET(my_tasklet, my_tasklet_function, data);3. 初始化tasklet结构,绑定工作函数
如果上一步是采用静态定义,则这一步不用再做,跳过。如果是采用动态定义tasklet,则使用tasklet_init()函数进行初始化以及绑定。
>tasklet_init(&my_tasklet, my_tasklet_function, data)4. 在适当的地方调度工作函数
tasklet一般是用于处理中断的下半部的,所以一般在中断的上半部调度tasklet工作函数。
>tasklet_schedule(&my_tasklet);5. 销毁tasklet工作任务
在确定不再使用tasklet时,应该在适当的地方调用tasklet_kill()函数销毁tasklet任务,释放资源,这个适当的地方一般的tasklet初始化地方是相反的,比如,如果是在模块初始化函数初始化了tasklet,则相应地是在模块卸载函数调用tasklet_kill函数来销毁tasklet任务。
>tasklet_kill(&my_tasklet);从中断和异常返回
我们用《深入理解Linux内核》的一张大图来收尾。
我们的ret_from_intr和ret_from_exception本质上等价于:
入口点
>ret_from_exception: cli // 只有从异常返回时才使用 cli,禁用本地中断 >ret_from_intr: movl $-8192, %ebp // 将当前 thread_info 描述符的地址装载到 ebp 寄存器 andl %esp, %ebp movl 0x30(%esp), %eax movb 0x2c(%esp), %al // 根据发生中断或异常压入栈中的 cs 和 eflags 寄存器的值, // 确定中断的程序在中断时是否运行在用户态 testl $0x0002003, %eax jnz resume_userspace jpm resume_kernel恢复内核控制路径
>rusume_kernel: cli cmpl $0, 0x14(%ebp) // 如果 thread_info 描述符的 preempt_count 字段为0(运行内核抢占) jz need_resched // 跳到 need_resched >restore_all: // 否则,被中断的程序重新开始执行 popl %ebx popl %ecx popl %edx popl %esi popl %edi popl %ebp popl %eax popl %ds popl %es addl $4, %esp iret // 结束控制检查内核抢占
>need_resched: movl 0x8(%ebp), %ecx testb $(1<<TIF_NEED_RESCHED), %cl // 如果 current->thread_info 的 flags 字段中的 TIF_NEED_RESCHED == 0,没有需要切换的进程 jz restore_all // 因此跳到 restore_all testl $0x00000200, 0x30(%ebp) // 如果正在被恢复的内核控制路径是在禁用本地 CPU 的情况下运行 jz restore_all // 也跳到 restore_all,否则进程切换可能回破坏内核数据结构 call preempt_schedule_irq // 进程切换,设置 preempt_count 字段的 PREEMPT_ACTIVE 标志,大内核锁计数器暂时设置为 -1,调用 schedule() jmp need_resched恢复用户态程序
>resume_userspace: cli // 禁用本地中断 movl 0x8(%ebp), %ecx // 检测 current->thread_info 的 flags 字段, // 如果只设置了 TIF_SYSCALL_TRACE,TIF_SYSCALL_AUDIT 或 TIF_SINGLESTEP 标志, // 跳到 restore_all andl $0x0000ff6e, %ecx je restore_all jmp work_pending检测重调度标志
>work_pending: testb $(1<<TIF_NEED_RESCHED), %cl jz work_notifysig >work_resched: call schedule // 如果进程切换请求被挂起,选择另外 一个进程运行 cli jmp resume_userspace // 当前面的进程要恢复时处理挂起信号、虚拟 8086 模式和单步执行
>work_notifysig: movl %esp, %eax testl $0x00020000, 0x30(%esp) je 1f >// 如果用户态程序 eflags 寄存器的 VM 控制标志被设置 >work_notifysig_v86: pushl %ecx call save_v86_state // 在用户态地址空间建立虚拟8086模式的数据结构 popl %ecx movl %eax, %esp >1: xorl %edx, %edx call do_notify_resume // 处理挂起信号和单步执行 jmp restore_all // 恢复被中断的程序Reference
Linux内核19-中断描述符表IDT的初始化-腾讯云开发者社区-腾讯云 (tencent.com)
Linux内核硬中断 / 软中断的原理和实现-腾讯云开发者社区-腾讯云 (tencent.com)
内核同步
嗯,我们下面来聊聊内核同步的话题,内核同步是为了解决内核异步抢占而产生的。
内核抢占
在Linux中内核抢占比较复杂:
- 无论在抢占内核还是在非抢占内核,,运行在内核态的程序都可以自动放弃CPU,比如说:其原因可能是竞争,由于等待资源,而不得不进入睡眠状态。往往把这种状态称为计划性进程切换,但是抢占式内核在响应引起进程切换的异步事件,例如说唤醒高优先级进程的中断处理程序的方式上,与非抢占的内核是有差别的。我们把这种进程切换称之为强制性的进程切换
- 所有的进程切换都由宏:switch_to来完成,在抢占式的内核和非抢占式的内核中,当进程的执行完某一些具有内核功能的线程,而且调度程序被调度后,就会发生进程切换!不过在非抢占内核中,当前进程是不可能被替换!除非他打算换到用户态上去!
因此抢占式内核的主要特点:是一个在内核态运行的进程可能在执行内核函数期间被另一个进程取代!
在Linux中当被current thread info宏所引用的thread_info描述符的preempt_count字段大于零时,就会禁止内核抢占他!
在如下任何一种情况发生时,取值都大于零:
- 内核正在执行内中断服务例程
- 可延迟函数被禁止
- 通过把抢占计数器设置为正数而显示的禁用内核抢占
上面的原则告诉我们只有当内核正在执行异常处理程序,而且内核抢占没有被显式地禁用的时候,才会抢占内核
那么什么时候同步是必须的呢:我们之前就有提到过刚计算的结果依赖于两个或两个以上的交叉内核控制路径的嵌套方式时,才有可能会引起竞争!(说白了就是两个执行流撞在一起,有多个进程同时执行同一段代码),临界区是一段代码,在其他的内核控制路径能够进入临界区前,进入临界区的内核控制路径必须全部执行完!这段临界区的代码交叉内核控制路径使内核开发的工作者变得复杂,他们必须小心地识别出异常处理程序,中断处理程序,可延迟函数和内核进程中的临界区。一旦临界区被确定,就必须对其采取一定的保护措施
那么什么时候同步是不必要的呢:
- 所有中断处理程序响应来自pic的中断并且禁用了IRQ线,此外在中断处理程序的结束之前不允许产生相同的中断事件!
- 中断处理程序,软中断,tasklet既不可以被抢占也不可能被阻塞,所以他们不可能长时间的处于挂起状态!即使在最坏的情况下它们的执行也只是有轻微的延迟,因为在其执行的过程中可能会发生其他中断执行!
- 中断处理的内核控制路径不能被执行可延迟函数,或系统调用服务例程的内核控制路径所中断
- 软中断和tasklet不能在一个给定的CPU上交错执行
- 同一个tasklet不可能同时在几个CPU上执行!
以上的每一种设计选择都可以看作是一种约束,下面是一些可能简化了的例子
- 已中断处理程序和tasklet不必编写成可重入的函数
- 仅被软中断和task light访问的每CPU变量并不需要同步
- 仅被一种tasklet访问的数据结构是不需要同步的
同步原语
下面来看看同步原语,内核中使用的同步技术
| 技术 | 说明 | 适用范围 |
|---|---|---|
| 每CPU变量 | 在CPU中复制数据结构 | 所有CPU |
| 原子操作 | 对一个计数器原子的读修改写的指令 | 所有CPU |
| 内存屏障 | 避免指令重新排序 | 本地CPU或者所有CPU |
| 自旋锁 | 加锁时忙等待 | 所有CPU |
| 信号量 | 加锁是阻塞等待(睡眠) | 所有CPU |
| 顺序锁 | 基于访问计数器的锁 | 所有CPU |
| 本地中断的禁止 | 禁止单个CPU上的中断处理 | 本地CPU |
| 本地软中断的禁止 | 禁止单个CPU上的可延迟函数处理 | 本地CPU |
| RCU | 通过指针而不是锁来访问共享数据结构 | 所有CPU |
per-CPU变量
最好的同步技术就是把不需要同步的内核放在首位正如我们将要看到事实上每一种显示的同步原语都会有不容忽视的性能开销最简单也是最重要的同步技术包括把内核变量声明为每CPU变量每CPU变量主要是数据结构的数组系统的每个CPU都对应数组的一个元素一个CPU不应该访问其他CPU对应的数组元素另外它可以随意读或修改他们自己的元素而不必担心竞争条件因为这是他唯一有资格这么做的CPU但是这也意味着每CPU变量基本上只能在特殊情况下才能够使用也就是当他确定这个系统上的CPU上的数据的逻辑上是独立的此外在单处理器和多处理器系统中内核抢占都可能会使每cpu变量产生竞争条件总的原则是内核控制路径应该禁用抢占的情况下去访问每cpu变量
API
为每个CPU定义一个变量的拷贝的宏定义在文件include/linux/percpu-defs.h中,如下:
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")若我们使用DEFINE_PER_CPU(int, per_cpu_n)为每个CPU定义变量,其展开宏如下。
__attribute__((section(".data..percpu"))) int per_cpu_n
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) __typeof__(type) name
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec)))
#define PER_CPU_BASE_SECTION ".data..percpu"在链接过程中,所有通过DEFINE_PER_CPU宏定义的变量都将链接到一起。在操作系统启动时,Linux 将为该段分配一段内存。 查看编译出的内核镜像可找到.data..percpu段
# readelf -S vmlinux
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[21] .data..percpu PROGBITS 0000000000000000 01000000
000000000001d000 0000000000000000 WA 0 0 4096per CPU 变量的访问通过宏get_cpu_var完成 。Linux内核是可抢占的,并且在访问访问 per cpu变量时我们需要知道当前代码运行在哪个CPU核上。 因此,在访问每个cpu变量时,应当不允许抢占当前代码并将其移至另一个CPU。例如,若在获取到 CPU id 为 1 后,该任务被抢占而移动到了 CPU 2上继续运行,这时访问的将仍然是 CPU 1的per cpu 变量。因此,在 get_cpu_var 宏中,首先要调用preempt_disable()函数禁止任务抢占。
// in include/linux/percpu-defs.h
#define get_cpu_var(var) \
(*({ \
preempt_disable(); \
this_cpu_ptr(&var); \
}))我比较好奇的是 this_cpu_ptr是如何实现的。内核如何将该变量对应到属于该CPU的 per CPU 变量内存呢?
在初始化时,内核会使用一个数组__per_cpu_offset[cpu]记录每个CPU静态per cpu 变量的偏移地址。在ARM64架构下, OS 启动时将 per cpu 偏移地址写入到 TPDIR_EL1 和 TPDIR_EL2 寄存器中。
void __init setup_per_cpu_areas(void)
{
unsigned long delta;
unsigned int cpu;
...
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu)
__per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
}
/* arch/arm64/include/asm/percpu.h */
static inline void set_my_cpu_offset(unsigned long off)
{
asm volatile(ALTERNATIVE("msr tpidr_el1, %0",
"msr tpidr_el2, %0",
ARM64_HAS_VIRT_HOST_EXTN)
:: "r" (off) : "memory");
}this_cpu_ptr的宏展开如下:即相当于 percpu 变量指针 ptr 加上__my_cpu_offset。
#define arch_raw_cpu_ptr(ptr) SHIFT_PERCPU_PTR(ptr, __my_cpu_offset)
#define raw_cpu_ptr(ptr) \
({ \
__verify_pcpu_ptr(ptr); \
arch_raw_cpu_ptr(ptr); \
})
#define this_cpu_ptr(ptr) raw_cpu_ptr(ptr)__my_cpu_offset宏即是从当前cpu的tpidr_el1、tpidr_el2寄存器中取出此前设置的__per_cpu_offset[cpu]值,实现如下:
static inline unsigned long __my_cpu_offset(void)
{
unsigned long off;
/*
* We want to allow caching the value, so avoid using volatile and
* instead use a fake stack read to hazard against barrier().
*/
asm(ALTERNATIVE("mrs %0, tpidr_el1",
"mrs %0, tpidr_el2",
ARM64_HAS_VIRT_HOST_EXTN)
: "=r" (off) :
"Q" (*(const unsigned long *)current_stack_pointer));
return off;
}有时会需要指定某个 CPU 获取其某个 per cpu 变量的地址,通过宏per_cpu_ptr实现,源码如下:
#define SHIFT_PERCPU_PTR(__p, __offset) \
RELOC_HIDE((typeof(*(__p)) __kernel __force *)(__p), (__offset))
#define per_cpu_ptr(ptr, cpu) \
({ \
__verify_pcpu_ptr(ptr); \
SHIFT_PERCPU_PTR((ptr), per_cpu_offset((cpu))); \
})user,kernel,safe,force等定义在
compiler_type.h头文件中。看到两个很奇怪的现象,一个是只有在CHECKER宏打开的情况下,他们的定义才会被实现,否则他们的定义是空的。第二个是它们的attribute的定义,并不是gcc支持的属性。那到底是哪里使用到了呢?原来linux的作者们自己开发了一套编译期代码检查的工具Sparse,可以用于在编译阶段快速发现代码中隐含的问题。[1]
- address_space 定义了指针能指向的内存的类型,0代表kernel space,1代表user space,2代表设备地址空间,3代表cpu局部的内存空间
- safe 表示变量可以为空
- force 表示变量可以强制类型转换
Per CPU 变量的应用
记录每个CPU 的 id 是 per CPU 变量的应用之一。
那么有了 Per CPU变量之后,如何获得当前执行代码的CPU 编号? 内核函数smp_processor_id()用来获取当前 CPU 的 id 。
CPU id 的存储依赖于 per CPU 变量(DEFINE_PER_CPU宏用来定义 cpu_number 变量)。
// 每个CPU的cpuid是放置在cpu_number这个percpu变量中
DEFINE_PER_CPU(int, cpu_number);在内核初始化时,smp_prepare_cpus()函数执行per_cpu(cpu_number, cpu) = cpu;设定每个核的编号。
// in /arch/arm64/kernel/smp.c
void __init smp_prepare_cpus(unsigned int max_cpus)
{
const struct cpu_operations *ops;
int err;
unsigned int cpu;
unsigned int this_cpu;
init_cpu_topology();
this_cpu = smp_processor_id();
for_each_possible_cpu(cpu) {
// 设置 CPU id
per_cpu(cpu_number, cpu) = cpu;
// 确定在哪个核上执行的,若是本身则跳过。
if (cpu == smp_processor_id())
continue;
ops = get_cpu_ops(cpu);
if (!ops)
continue;
err = ops->cpu_prepare(cpu);
if (err)
continue;
set_cpu_present(cpu, true);
numa_store_cpu_info(cpu);
}
}smp_processer_id ()函数(定义在 include/linux/smp.h)展开如下。
# define smp_processor_id() __smp_processor_id()
#define __smp_processor_id(x) raw_smp_processor_id(x)raw_smp_processor_id与处理器架构相关(下例为ARM64)的实现如下,raw_cpu_ptr 获取到 cpu_number 的地址,在解引用得到 cpu id。
#define raw_smp_processor_id() (*raw_cpu_ptr(&cpu_number))per CPU 变量在多文件下的用法
声明一个 per cpu 变量并在另一个文件中引用,以获取当前 task_struct 为例(x86下 current 宏的实现)。
定义方式如下:
DEFINE_PER_CPU(struct task_struct *, current_task) ____cacheline_aligned =
&init_task;
EXPORT_PER_CPU_SYMBOL(current_task);在另一个文件中引用方式如下:
DECLARE_PER_CPU(struct task_struct *, current_task);
static __always_inline struct task_struct *get_current(void)
{
return this_cpu_read_stable(current_task);
}
#define current get_current()原子操作
若干汇编语言指令是具有RCU类型的,也就是说他们访问存储器单元两次!第一次读原值,第二次写新值
避免由于RCU指令引起的竞争条件的容易的办法,就是确保这样的操作在芯片级就是原子性的!
任何一个这样的操作都必须单个指令进行执行中间,是不允许中断的且避免其他的CPU访问统一存储器单元。这些很小的原子操作可以建立在其他更灵活的机制的基础之上创建临界区
让我们根据这样的分类来回顾一下8086的指令:
进行零次或一次对齐内存访问的汇编指令是原子的
如果在读操作之后写操作之前没有其他处理器占用内存总线,那么在从内存中读取数据,更新数据并且把更新后的数据写回内存中的这些RCU汇编语言指令是原子的!当然在单处理器系统中永远不会发生内存总线窃取的情况
操作码前缀是lock字节(0xf0)的汇编语言指令,即使在多处理器系统中,也是原子的!当控制单元检测到这个前缀时,就会锁定内存总线直到这条指令完成为止,因此在加速的指令执行时其他处理器是不能够访问这个内存单元的!
操作码前缀是reg字节(0xf2, 0xf3)的汇编语言指令不是原子的!这条指令强行让控制单元多次重复相同的指令控制单元,在执行新的循环之前要检查挂起的中断!
API
| API | 含义 |
|---|---|
| ATOMIC_INIT(int i) | 定义原子变量的时候对其初始化。 |
| int atomic_read(atomic_t *v) | 读取 v 的值,并且返回。 |
| void atomic_set(atomic_t *v, int i) | 向 v 写入 i 值。 |
| void atomic_add(int i, atomic_t *v) | 给 v 加上 i 值。 |
| void atomic_sub(int i, atomic_t *v) | 从 v 减去 i 值。 |
| void atomic_inc(atomic_t *v) | 给 v 加 1,也就是自增。 |
| void atomic_dec(atomic_t *v) | 从 v 减 1,也就是自减 |
| int atomic_dec_return(atomic_t *v) | 从 v 减 1,并且返回 v 的值。 |
| int atomic_inc_return(atomic_t *v) | 给 v 加 1,并且返回 v 的值。 |
| int atomic_sub_and_test(int i, atomic_t *v) | 从 v 减 i,如果结果为 0 就返回真,否则返回假 |
| int atomic_dec_and_test(atomic_t *v) | 从 v 减 1,如果结果为 0 就返回真,否则返回假 |
| int atomic_inc_and_test(atomic_t *v) | 给 v 加 1,如果结果为 0 就返回真,否则返回假 |
| int atomic_add_negative(int i, atomic_t *v) | 给 v 加 i,如果结果为负就返回真,否则返回假 |
相应的也提供了 64 位原子变量的操作 API 函数,这里我们就不详细讲解了,和表 中的 API 函数有用法一样,只是将“atomic_”前缀换为“atomic64_”,将 int 换为 long long。如果使用的是 64 位的 SOC,那么就要使用 64 位的原子操作函数。
优化和内存屏障
当使用边缘优化的编译器时,它会重排汇编指令从而达到以最优,此外现代CPU通常会并行地执行若干条指令且可能重新安排内存访问这种重新排序可以极大地加速程序的执行然而当处理同步时则必须避免指令重新排序优化屏障源于保证编译程序不会混淆放在原语操作之前的汇编语言指令和放在原语操作之后的汇编语言这些汇编语言指令在C中都有对应的语句在Linux中优化屏障就是barrier宏,它展开为:
asm volitile("":::"memory"); 指令ASM告诉编译程序要插入汇编语言片段,volatile关键字禁止编译器把ASM指令与程序中的其他指令重新组合!memory关键字强制编译器假定RAM中的所有内存单元已经被汇编语言指令修改,因此编译器不能使用存放在CPU寄存器中的内存单元的值来优化ASM指令前的代码
注意优化屏障并不保证不使当前CPU把汇编语言指令混在一起执行,这是内存屏障的工作!
内存屏障源于保证在原语之后的操作开始之前,原语之前的操作已经完成。因此内存屏障类似于防火墙,让任何汇编语句指令都不能通过!在以下这些汇编指令在8086处理中是串行的!因为他们起到了内存屏障的作用:
对IO端口进行操作的所有指令
有lock前缀的所有指令
写控制寄存器系统寄存器或调试寄存器的所有指令
在奔腾4微处理器中引入的汇编指令lfence, sfence, mfence
关于内存屏障的汇编指令少数专门的汇编语言指令
Linux使用六个内存屏障原语,如下表所示:
| 内存屏障的宏定义 | 功能说明 |
|---|---|
| mb() | 适用于多处理器和单处理器的内存屏障。 |
| rmb() | 适用于多处理器和单处理器的读内存屏障。 |
| wmb() | 适用于多处理器和单处理器的写内存屏障。 |
| smp_mb() | 适用于多处理器的内存屏障。 |
| smp_rmb() | 适用于多处理器的读内存屏障。 |
| smp_wmb() | 适用于多处理器的写内存屏障。 |
自旋锁
这是一种广泛使用的锁,关于锁,可以认为是对访问公共资源的一种限制。如果内核控制路径希望访问资源,就必须获取钥匙来打开这个锁!当且只当资源空闲时,也就是没有任何进程来访问这段资源的时候,它才能成功,然后持有这个锁!其他进程想要在这个进程处理。这个数据结构的时候必须等待这个进程处理完毕,释放掉这个锁之后,其他进程才能够接着访问这个数据结构!
严肃的版本:
自旋锁是用来在多处理器环境中工作的一种特殊的锁,如果内核控制路径发现自旋锁是开着的!那么获取锁,并且继续执行,相反,则会在周围旋转反复执行一条紧凑的循环指令,直到锁被释放!
自旋锁的循环指令表示忙等待,即使等待的内核控制路径是无事可做的。它也会在CPU上保持运行,不过自旋锁通常非常方便。因为很多内核资源只锁一毫秒的时间片段,所以说释放CPU和随后又获得CPU是不会消耗多少时间的!
这里有更加详细的自旋锁的文章,可以参看:
[Linux中的spinlock机制一] - CAS和ticket spinlock - 知乎 (zhihu.com)]
自旋锁 API 函数
最基本的自旋锁 API 函数如下表 所示:
| API | 描述 |
|---|---|
| DEFINE_SPINLOCK(spinlock_t lock) | 定义并初始化一个自选变量。 |
| int spin_lock_init(spinlock_t *lock) | 初始化自旋锁。 |
| void spin_lock(spinlock_t *lock) | 获取指定的自旋锁,也叫做加锁。 |
| void spin_unlock(spinlock_t *lock) | 释放指定的自旋锁。 |
| int spin_trylock(spinlock_t *lock) | 尝试获取指定的自旋锁,如果没有获取到就返回 0 |
| int spin_is_locked(spinlock_t *lock) | 检查指定的自旋锁是否被获取,如果没有被获取就返回非 0,否则返回 0 |
读写锁
读写自旋锁的引入是为了增加内核的并发能力,因为我们思考:只要没有内核控制路径对希望上锁的数据结构进行修改,我们就没有必要对这个数据结构进行上锁。只有当我们想要对这个结构进行写操作的时候那么我们才会对这个资源进行上锁。
API
与 spinlock 一样,Read/Write spinlock 有如下的 APIs:
| 接口API描述 | Read/Write Spinlock API |
|---|---|
| 定义rw spin lock并初始化 | DEFINE_RWLOCK |
| 动态初始化rw spin lock | rwlock_init |
| 获取指定的rw spin lock | read_lock write_lock |
| 获取指定的rw spin lock同时disable本CPU中断 | read_lock_irq write_lock_irq |
| 保存本CPU当前的irq状态,disable本CPU中断并获取指定的rw spin lock | read_lock_irqsave write_lock_irqsave |
| 获取指定的rw spin lock同时disable本CPU的bottom half | read_lock_bh write_lock_bh |
| 释放指定的spin lock | read_unlock write_unlock |
| 释放指定的rw spin lock同时enable本CPU中断 | read_unlock_irq write_unlock_irq |
| 释放指定的rw spin lock同时恢复本CPU的中断状态 | read_unlock_irqrestore write_unlock_irqrestore |
| 获取指定的rw spin lock同时enable本CPU的bottom half | read_unlock_bh write_unlock_bh |
| 尝试去获取rw spin lock,如果失败,不会spin,而是返回非零值 | read_trylock write_trylock |
RCU
RCU就是Read, Copy, Update机制,这是为了保护在多数情况下被多个CPU读的数据结构,而设计的一种同步技术!它允许多个读者和写者并发执行,而且它是不会使用锁的。就是说它不使用被所有CPU共享的锁或计数器
在这一点上与读写自旋锁与顺序锁相比,它具有更大的优势!它的关键思想在于限制RCP的范围:
- RCU只会保护被动态分配,并通过指针引用的数据结构
- 在被RCU保护的临界区中任何内核控制路径都不能睡眠
信号量
它本质上就是一个更加高级的锁,一个允许最大若干进程访问资源的锁。
Linux有两个信号量:内核信号量和IPC信号量,我们现在只关心前者
API
| 函数定义 | 功能说明 |
|---|---|
| sema_init(struct semaphore *sem, int val) | 初始化信号量,将信号量计数器值设置val。 |
| down(struct semaphore *sem) | 获取信号量,不建议使用此函数,因为是 UNINTERRUPTABLE 的睡眠。 |
| down_interruptible(struct semaphore *sem) | 可被中断地获取信号量,如果睡眠被信号中断,返回错误-EINTR。 |
| down_killable (struct semaphore *sem) | 可被杀死地获取信号量。如果睡眠被致命信号中断,返回错误-EINTR。 |
| down_trylock(struct semaphore *sem) | 尝试原子地获取信号量,如果成功获取,返回0,不能获取,返回1。 |
| down_timeout(struct semaphore *sem, long jiffies) | 在指定的时间jiffies内获取信号量,若超时未获取,返回错误-ETIME。 |
| up(struct semaphore *sem) | 释放信号量sem。 |
注意:down_interruptible 接口,在获取不到信号量的时候,该任务会进入 INTERRUPTABLE 的睡眠,但是 down() 接口会导致进入 UNINTERRUPTABLE 的睡眠,down 用的较少。
1. 信号量的结构:
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};信号量用结构semaphore描述,它在自旋锁的基础上改进而成,它包括一个自旋锁、信号量计数器和一个等待队列。用户程序只能调用信号量API函数,而不能直接访问信号量结构。
2. 初始化函数sema_init
#define __SEMAPHORE_INITIALIZER(name, n) \
{ \
.lock = __RAW_SPIN_LOCK_UNLOCKED((name).lock), \
.count = n, \
.wait_list = LIST_HEAD_INIT((name).wait_list), \
}
static inline void sema_init(struct semaphore *sem, int val)
{
static struct lock_class_key __key;
*sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val);
lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0);
}初始化了信号量中的 spinlock 结构,count 计数器和初始化链表。
3. 可中断获取信号量函数down_interruptible
static noinline int __sched __down_interruptible(struct semaphore *sem)
{
return __down_common(sem, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
int down_interruptible(struct semaphore *sem)
{
unsigned long flags;
int result = 0;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_interruptible(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
return result;
}down_interruptible 进入后,获取信号量获取成功,进入临界区,否则进入 down_interruptible->down_common
static inline int __sched __down_common(struct semaphore *sem, long state,
long timeout)
{
struct semaphore_waiter waiter;
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = current;
waiter.up = false;
for (;;) {
if (signal_pending_state(state, current))
goto interrupted;
if (unlikely(timeout <= 0))
goto timed_out;
__set_current_state(state);
raw_spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
raw_spin_lock_irq(&sem->lock);
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
}加入到等待队列,将状态设置成为 TASK_INTERRUPTIBLE , 并设置了调度的 Timeout : MAX_SCHEDULE_TIMEOUT
在调用了 schedule_timeout,使得进程进入了睡眠状态。
4. 释放信号量函数 up
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}如果等待队列为空,没有睡眠的进程期望获取这个信号量,则直接 count++,否则调用 __up:
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);
}static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);
}取出队列中的元素,进行唤醒操作。
Reference
Linux—原子操作(介绍及其操作函数集)_原子操作函数-CSDN博客
一文读懂优化屏障和内存屏障 - 知乎 (zhihu.com)
定时测量
为了准备讨论稍后的进程调度等相关内容(这是因为很多计算机的活动高度依赖定时器),我们需要首先讨论一下定时驱动。这通常对用户并不可见!为了进行这些跟定时高强度相关的操作程序,必须能从每个文件中检索到文件的最后访问时间及时间戳,因此这些的时间标记是必须由定时测量来完成的。
Linux内核必须完成主要两种定时测量:
- 保存当前的时间和日期以便能通过
time(),ftime()和gettimeofday()系统调用把它们返回给用户程序,也可以由内核本身把当前时间作为文件和网络包的时间戳维持 - 定时器这种机制能够告诉内核或用户程序某一时间间隔已经过去了
定时测量是由基于固定频率振荡器和计数器的几个硬件电路完成的。
时钟和定时器电路
实时时钟
所有的PC都包含一个叫做实时时钟的时钟,它是独立于CPU和其他芯片的。即使当PC被切断电源,RTC还在工作。因为它靠一个小电池或蓄电池工作,CMOS RAM和RTC被集成在一个芯片上,RTC能在IRQ8上发出周期性的中断,频率在二到8192赫兹之间,也可以对RTC进行编程使得RTC达到某个特定的值时,激活IRQ。也就是作为一个闹钟来工作。Linux只用R TC来获取时间和日期,不过通过对/dev/rtc设备文件进行操作也允许进程对RTC进行编程,内核通过0X70和0X71 IO端口访问RTC时间戳。
计数器
所有的8086微处理器都包括一条clk输入引线,它接受外部振荡器的时钟信号。从奔腾开始,8086微处理器都会包含一个计数器,它在每个时钟信号到来时加一。该计数器是利用64位的时间戳计数器寄存器来实现的。可以通过汇编语言指令读这个寄存器,当使用这个寄存器时,内核必须考虑到时钟信号的频率,例如如果时钟节拍的频率是1G赫兹,那么时钟抽计数器每纳秒增加一次!
可编程间隔定数
定时器除了实时时钟和时间戳计数器,IBM兼容PC还包含了的三种类型的时间测量设备,叫做可编程间隔计数器。它类似于微波炉的闹钟,即让用户意识到烹饪的时间已经过了!不过他的工作方式是发出一个特殊的中断,即时钟中断来通知内核又一个时间间隔过去了。与闹钟的另一个区别是PIT永远以内核确定的固定频率不停地发出中断
CPU本地定时器
还有一种测量设备是CPU本地定时器,它能够产生单步中断或周期性中断的设备,有点儿像刚刚所说的可编程间隔定时器。不过还是有几点区别:
- 首先它是32位的而,pic计数器是16位的。因此可以对本地定时器编程来产生很低频率的中断
- 本地APIC定时器只发送给自己的处理器,而PIT产生一个全局性中断。系统中的任意一个中CPU都可以对其进行处理
- APIC定时器是基于总线时钟信号的每隔1,2,4,8,16,32,64,128总线时钟信号到来时,对该定时器进行递减,就可以实现编程的目的!相反PIT有自己的内部时钟振荡器,可以更加灵活的编程
高精度事件定时器HPET
提供了许多可以被内核应用的应聘时器这种新定时器芯片,主要由八个32位或64位的独立计时器。每个计时器都由它们的时钟信号所驱动,可以通过映射到内存空间的寄存器来对HPET芯片进行编程
ACPI电源管理定时器
它是另一种时钟设备,包含在几乎所有基于ACPI的主板上,它的时钟信号拥有大约为3.58兆赫兹的固定频率。该设备实际上是一个简单的计数器,它在每个时钟节拍到来时增加一次。为了读取计数器的当前值,需要访问io端口!其io端口的地址由BIOS在初始化阶段进行确定!
Linux计时体系
Linux必须与之执行与定时相关的操作,例如
- 内核可以周期性地更新自系统启动以来所经过的时间!
- 更新时间和日期确定当前进程在每个CPU上已运行了多久时间,如果已经超过了分配给他的时间,那么就抢占他!
- 更新资源使用统计数检查
每个软定时器Linux的计时体系结构是一组与时间流相关的内核结构与函数
计时体系结构的数据结构
定时器对象
为了使用统一的方式管理定时器资源:我们使用timer_opts来抽象:
| 字段名 | 说明 |
|---|---|
| name | 标识定时器源的一个字符串 |
| mark_offset | 记录上一个节拍的准确时间,由时钟中断处理程序调用 |
| get_offset | 返回自上一个节拍开始所经过的时间 |
| monotonic_clock | 返回自内核初始化开始所经过的纳秒数 |
| delay | 等待指定数目的循环 |
mark_offset由时钟中断处理程序调用,以适当的数据结构记录每个节拍到来时的准确时间。get_offset用已记录的值来计算自上一次时钟中断以来经过的时间(以us为单位)。cur_timer存放了某个定时器对象的地址,该定时器是系统可利用的定时器资源中”最好的”。
下表显示了优先权的排序表:
| 定时器对象名称 | 说明 | 定时插补 | 延迟 |
|---|---|---|---|
| timer_hpet | 高精度事件定时器 | HPET | HPET |
| timer_pmtmr | ACPI电源管理定时器 | ACPI PMT | TSC |
| timer_tsc | 时间戳计数器 | TSC | TSC |
| timer_pit | 可编程间隔定时器 | PIT | 紧致循环 |
| timer_none | 普通虚拟定时器资源 | 紧致循环 |
jiffies变量
记录自系统启动以来产生的节拍总数。由于使用了time_after,time_after_eq,time_before,time_before_eq,内核很好的处理了jiffies变量的溢出。
jiffies被初始化为0xfffb6c20,它是一个32位有符号值,等于-300000。因此,计数器将会在系统启动后的5分钟内处于溢出状态。使那些不对jiffies做溢出检测的有缺陷代码在开发阶段被及时发现。(这个技巧是为了迫使内核程序员编写程序时考虑jifffies的溢出)80x86中,jiffies通过连接器被换算成一个64位计数器的低32位,这个64位计数器称作jiffies_64。
unsigned long long get_jiffies_64(void)
{
unsigned long seq;
unsigned long long ret;
do{
seq = read_seqbegin(&xtime_lock);
ret = jiffies_64;
} while(read_seqretry(&xtime_lock, seq));
return ret;
}在临界区增加jiffies_64值时必须用write_seqlock(&time_lock)和write_sequnlock(&xtime_lock)进行保护。
xtime变量
xtime作为一个extern的timespec的全局变量,存放当前时间和日期。
struct timespec
{
__kernel_time_t tv_sec; /* 秒数 */
long tv_nsec; /* 纳秒数,1纳秒(ns)=1e-9秒(s) */
};
extern struct timespec xtime;
tv_sec:存放自1970.1.1午夜以来经过的秒数tv_nesc:存放自上一秒开始经过的纳秒数
通常每个节拍更新一次。
单处理器系统上的计时体系结构
单处理器系统上,所有与定时有关的活动都是由IRQ线0上的可编程间隔定时器产生的中断触发的。Linux中,某些活动都尽可能在中断产生后立即执行,其余活动延迟。
初始化阶段
内核初始化期间,time_init函数被调用来建立计时体系结构,通常执行如下:
- 初始化xtime。用get_cmos_time从实时时钟上读取自1970年1月1日午夜以来经过的秒数。设置xtime的tv_nsec,
- 初始化wall_to_monotonic。它存放将被加到xtime上的秒数和纳秒数,以此来获得单向的时间流。外部时钟的闰秒和同步都可能突发低改变xtime的tv_sec和tv_nsec,使得它们不再是单向递增。
- 如内核支持HPET,将调hpet_enable来确认ACPI固件是否探测到该芯片并将它的寄存器映射到内存地址空间中。如结果是肯定,则hpet_enable将对HPET的第一个定时器编程使其以每秒1000次的频率引发IRQ0处的中断。否则,内核将使用PIT:该芯片已经被init_IRQ编程,使得它以每秒1000次的频率引发IRQ0处的中断。
- 调select_timer来挑选系统中可利用的最好的定时器资源,并设置cur_timer变量指向该定时器资源对应的定时器对象的地址。
- 调setup_irq(0, &irq0)来创建与IRQ0相应的中断门,IRQ0引脚线连接着系统时钟中断源(PIT或HPET)。irq0被静态定义如下:
struct irqaction irq0 = {
timer_interrupt,
SA_INTERRUPT,
0, "timer", NULL, NULL
}; 从现在起,timer_interrupt函数会在每个节拍到来时被调用,而中断被禁止,因为IRQ0主描述符的状态字段中SA_INTERRUPT被置位。
时钟中断处理程序
这里我们需要关注的就是timer_interrupt,他是PIT或HPET的中断服务例程
在xtime_lock顺序锁上产生一个write_seqlock
执行cur_timer的mark_offset。
- cur_timer指向timer_hpet对象,这种情况下,HPET芯片作为时钟中断源。make_offset检查自上一节拍以来是否丢失时钟中断,相应地更新jiffies_64。记录HPET周期计数器当前值。
- cur_timer指向timer_pmtmr:PIT芯片作为时钟中断源,但内核用APIC电源管理定时器以更高的分辨率来测量时间。make_offset检查自上一个节拍以来是否丢失时钟中断,如丢失,则更新jiffies_64。它记录APIC电源管理定时计数器当前值。
- cur_timer指向timer_tsc对象:PIT芯片作为时钟中断源,但是内核用时间戳计数器以更高的分辨率来测量时间。make_offset检查自上一个节拍以来是否丢失时钟中断,如丢失,则更新jiffies_64。它记录TSC计数器当前值。
- cur_timer指向timer_pit:PIT芯片作为时钟中断源,除此之外没别的定时器电路。mark_offset啥也不做。
- 调do_timer_interrupt
- 使jiffies_64增1.
- 调update_times更新系统日期和时间。
- 调update_process_times
- 调profile_tick
- 如使用外部时钟来同步系统时钟,则每隔660s调一次set_rtc_mmss来调整实时时钟。
调write_sequnlock释放xtime_lock顺序锁
返回值1,报告中断已经被有效地处理了。
多处理器系统上的计时体系结构
多处理器系统可依赖两种不同的时钟中断源:可编程间隔定时器,高精度事件定时器,CPU本地定时器产生的中断。Linux2.6中,PIT或HPET产生的全局时钟中断触发不涉及具体CPU的活动,如,处理软定时器,保持系统时间的更新。一个CPU本地时钟中断触发涉及本地CPU的计时活动,如,监视当前进程的运行时间,更新资源使用统计数
初始化阶段
全局时钟中断处理程序由time_init初始化。Linux内核为本地时钟中断保留第239号中断向量。在内核初始化阶段,函数apic_intr_init根据第239号向量和低级中断处理程序apic_timer_interrupt的地址设置IDT的中断门。每个APIC必须被告知多久产生一次本地时钟中断。calibrate_APIC_clock通过正在启动的CPU的本地APIC来计算一个节拍内收到了多少个总线时钟信号。然后这个确切的值被用来对本地所有APIC编程,由此在每个节拍产生一次本地时钟中断。这是由setup_APIC_timer完成的。
所有本地APIC定时器都是同步的,因为它们都基于公共总线时钟信号。意味着用于引导CPU的calibrate_APIC_clock计算出来的值对系统中的其他CPU同样有效
全局时钟中断处理程序
SMP版本的timer_interrupt与UP版本的该处理程序在几个地方有差异:
- timer_interrupt调do_timer_interrupt向I/O APIC芯片的一个端口写入,以应答定时器的中断请求。
- update_process_times不被调用,因为该函数执行与特定CPU相关的一个操作。
- profile_tick不被调用,因为该函数执行与特定CPU相关的操作。
本地时钟中断处理程序
该处理程序执行系统中与特定CPU相关的计时活动,即监管内核代码并检测当前进程在特定CPU上已经运行了多长时间。apic_timer_interrupt等价于:
apic_timer_interrupt:
pushl $(239-256)
SAVE_ALL
movl %esp, %eax
call smp_apic_timer_interrupt
jmp ret_from_intr被称作smp_apic_timer_interrupt的高级中断处理函数执行如下步骤:
- 获得CPU逻辑号
- 使irq_stat数组第n项的apic_timer_irqs字段加1
- 应答本地APIC上的中断
- 调irq_enter
- 调smp_local_timer_interrupt
- 调irq_exit
smp_local_timer_interrupt执行每个CPU的计时活动。事实上,它执行下面的主要步骤:
- 调profile_tick
- 调update_process_times检查当前进程运行的时间并更新一些本地CPU统计数。系统管理员通过写入/proc/profile可修改内核代码监管器的抽样频率。为实现修改,内核改变本地时钟中断产生的频率。smp_local_timer_interrupt保持每个节拍精确调用update_process_times一次。
更新时间和日期
用户程序从xtime变量中获得当前时间和日期。内核必须周期性地更新该变量,才能使它的值保持相当的精确。
void update_times(void)
{
unsigned long ticks;
ticks = jiffies - wall_jiffies;
if(ticks){
wall_jiffies += ticks;
update_wall_time(ticks);
}
calc_load(ticks);
} 对丢失的定时器中断的检查在cur_timer的mark_offset中完成。update_wall_time连续调update_wall_time_one_tick ticks次,每次调用都给xtime.tv_nsec加上1000000。如xtime.tv_nsec大于999999999,则update_wall_time更新xtime的tv_sec。
更新系统统计数
内核在与定时相关的其他任务中必须周期性地收集若干数据用于:
- 检查运行进程的CPU资源限制
- 更新与本地CPU工作负载有关的统计数
- 计算平均系统负载
- 监管内核代码
更新本地CPU统计数
使用的是update_process_times,这是流程:
- 检查当前进程运行了多长时间。时钟中断发生时,根据当前进程运行在用户态还是内核态,选择调account_user_time还是account_system_time
1.1. 更新当前进程描述符的utime或stime。在进程描述符中提供两个被称作cutime和cstime的附加字段,分别来统计子进程在用户态和内核态下所经过的CPU节拍数。
1.2. 检查是否已达到总的CPU时限。如是, 向current进程发SIGXCPU和SIGKILL。
1.3. 调account_it_virt和account_it_prof来检查进程定时器
1.4. 更新一些内核统计数 - 调raise_softirq来激活本地CPU上的TIMER_SOFTIRQ任务队列
- 如必须回收一些老版本的,受RCU保护的数据结构,则检查本地CPU是否经历了静止状态并调tasklet_schedule来激活本地CPU的rcu_tasklet任务队列。
- 调scheduler_tick,函数使当前进程的时间片计数器减1,并检查计数器是否已减到0。
记录系统负载
任何Unix内核都要记录系统进行了多少CPU活动。这些统计数据由各种管理实用程序来使用。用户输入uptime后可看到一些统计数据:如相对于最后1分钟,5分钟,15分钟的平均负载。单处理器系统上,值0意味着没活跃的进程。值1意味着一个单独的进程100%占有CPU。值大于1说明几个运行着的进程共享CPU。
监管内核代码
Linux包含一个被称作readprofiler的最低要求的代码监管器,Linux开发者用其发现内核在内核态什么地方花费时间。
监管器基于非常简单的蒙特卡洛算法:每次时钟中断发生时,内核确定该中断是否发生在内核态。如是,内核从堆栈取回中断发生前eip的值,并用这个值揭示中断发生前内核在做什么。采样数据积聚在”热点”上。
profile_tick为代码监管器采集数据。为激活代码监管器,Linux内核启动时必须传递”profile=N”,这里2^N标识要监管的代码段大小。采集的数据可从/proc/profile读取。可通过修改这个文件来重置计数器。多处理器系统上,修改此文件还可改变抽样频率。
内核开发者用readprofile命令。Linux 2.6内核还包括另一个监管器,oprofile。使用oprofile时,profile_tick调timer_notify收集数据。
检查非屏蔽中断监视器
多处理器系统上,Linux为内核开发者提供另一种功能:看门狗系统。这对于探测引起系统冻结的内核bug可能有用,启动内核时传递nmi_watchdog
看门狗基于本地和I/O APIC一个特性:它们能在每个CPU上产生周期性的NMI中断。
一旦每个时钟节拍到来,所有的CPU,都开始执行NMI中断处理程序;该中断处理程序又调用do_nmi。这个函数获得CPU的逻辑号n,检查irq_stat数组第n项的apic_timer_flags。如工作正常,则第n项的必定不同于前一个NMI中断中读出的值。CPU正常运行时,第n项的apic_timer_irq被本地时钟中断处理程序增加。当NMI中断处理程序检测到一个CPU冻结时,把引起恐慌的信息记录在日志文件, 转储该CPU寄存器的内容和内核栈的内容,最后杀死当前进程。
软定时器和延迟函数
Linux考虑两种类型的定时器:动态定时器,间隔定时器第一种类型由内核使用,间隔定时器可以由进程在用户态创建。对定时器函数的检查总是由可延迟函数进行,内核不能确保定时器函数正好在定时到期时开始执行,只能保证在适当的时间执行它们。对必须严格遵守定时时间的实时应用而言,定时器并不适合。
动态定时器
struct timer_list{
struct list_head entry;
unsigned long expires;
spinlock_t lock;
unsigned long magic;
void (*function)(unsigned long);
unsigned long data;
tvec_base_t *base;
};为了创建并激活一个动态定时器,内核必须:
- 如需要,创建一个新的timer_list
- 调init_timer(&t)
- 把定时器到期时激活函数地址存入function,设置data。
- 尚未插入链表时,赋值expires,调add_timer(&t)插入链表
- 已经插入链表时,调mod_timer更新expires。
一旦定时器到期,内核就自动把元素t从它的链表中删除。有时进程应用del_timer,del_timer_sync,del_singleshot_timer_sync显式从定时器链表删除一个定时器。LInux 2.6中,定时器函数总会在第一个执行add_timer或稍后执行mod_timer的那个CPU上运行。
动态定时器与竞争条件
一种凭经验做法是释放资源前停止定时器。
...
del_timer(&t);
X_Release_Resources();
... 多处理器系统上,这段代码是不安全的。因为调del_timer时,定时器函数可能已在其他CPU上运行了。为避免这种竞争条件,内核提供了del_timer_sync:从链表删除定时器,检查定时器函数是否还在CPU上运行,如是,等待运行结束。如内核开发者知道定时器函数从不重新激活定时器,就能使用更简单更快速的del_singleshot_timer_sync来使定时器无效,并等待直到定时器函数结束。
也存在其他种类的竞争条件:如,修改已激活定时器expires正确方法是调mod_timer,而非删除再创建。后一种途径中,要修改同一定时器expires的两个内核控制路径可能交错在一起。定时器函数在SMP上的安全实现是通过每个timer_list对象包含的lock达到:内核访问动态定时器链表时,需禁止中断,获取自旋锁。
动态定时器的数据结构
把expires值划分成不同的大小,并允许动态定时器从大expires值的链表到小expires值的链表进行有效的过滤。多处理器系统中活动的动态定时器集合被分配到各个不同的CPU中。
动态定时器的主要数据结构是一个叫tvec_bases的每CPU变量:它包含NR_CPUS个元素,系统中每个CPU各有一个。每个元素是一个tvec_base_t的结构:
typedef struct tvec_t_base_s{
spinlock_t lock;
unsigned long timer_jiffies;
struct timer_list* running_timer;
tvec_root_t tv1;
tvec_t tv2;
tvec_t tv3;
tvec_t tv4;
tvec_t tv5;
} tvec_base_t; tvec_root_t包含一个vec数组,数组由256个list_head元素组成。结构包含了在紧接着到来的255个节拍内将要到期的所有动态定时器。字段tv2,tv3,tv4结构都是tvec_t,该类型有一个数组vec(包含64个list_head)。这些链表包含在紧接着到来的214-1,220-1,2^26-1个节拍内将到期的所有动态定时器。字段tv5,vec数组最后一项是一个大expires字段值的动态定时器链表。timer_jiffies表示需检查的动态定时器的最早到时时间。多处理器系统中,running_timer指向由本地CPU当前正在处理的动态定时器的timer_list结构。
动态定时器处理
Linux 2.6中该活动由可延迟函数执行。即由TIMER_SOFTIRQ软中断执行。run_timer_softirq是与TIMER_SOFTIRQ软中断请求相关的可延迟函数。它实质上执行如下操作:
把与本地CPU相关的tvec_base_t地址存放到base
获得base->lock并禁止本地中断
开始执行一个while,当base->timer_jiffies大于jiffies时终止每次循环中:
计算base->tv1中索引,索引保存着下一次要处理的定时器index = base->timer_jiffies & 255
如索引值为0:调cascade来过滤动态定时器
使base->timer_jiffies值加1
对base->tv1.vec[index]链表上的每一个定时器,执行它对应的定时器函数。特别是,链表上每个timer_list元素t实质上执行:
- 将t从base->tv1的链表上删除
- 多处理器系统中,将base->running_timer设置为&t
- 设置t.base为NULL
- 释放base->lock,允许本地中断
- 传递t.data为参数,执行定时器函数t.function
- 获得base->lock,禁止本地中断
- 如链表中还有其他定时器,继续处理
链表上所有定时器已经被处理。继续执行最外层while循环的下一次循环。
最外层的while循环结束。base->running_timer=NULL
释放base->lock自旋锁,允许本地中断。
调用每个动态定时器函数前,激活中断并释放自旋锁。这保证了动态定时器的数据结构不被交错执行的内核控制路径所破坏。
动态定时器应用:nanosleep系统调用
current->state = TASK_INTERRUPTIBLE;
remaining = schedule_timeout(timespec_to_jiffies(&t)+1);内核使用动态定时器来实现进程的延时。
struct timer_list timer;
unsigned long expire = timeout + jiffies;
init_timer(&timer);
timer.expires = expire;
timer.data = (unsigned long)current;
timer.function = process_timeout;
add_timer(&timer);
schedule();
del_singleshot_timer_sync(&timer);
timeout = expire - jiffies;
return (timeout < 0 ? 0 : timeout);返回值0表示延时到期。timeout表示如进程因某些其他原因被唤醒,到延迟到期时还剩余的节拍数。延迟到期时,执行
void process_timeout(unsigned long __data)
{
wake_up_process((task_t*)__data);
}延迟函数
由于动态定时器通常有很大的设置开销和一个相当大的最小等待时间(1ms),所以设备驱动器使用它会很不方便。这时,内核使用udelay,ndelay:前者接收一个微妙级的时间间隔,后者接收纳秒级。
void udelay(unsigned long usecs)
{
unsigned long loops;
loops = (usecs*HZ*current_cpu_data.loops_per_jiffy)/1000000;
cur_timer->delay(loops);
}
void ndelay(unsigned long nsecs)
{
unsigned long loops;
loops = (nsecs*HZ*current_cpu_data.loops_per_jiffy)/1000000000;
cur_timer->delay(loops);
} 两个函数都依赖于cur_timer的delay,它接收”loops”中的时间间隔作为参数。不过每次”loops”精确的持续时间取决于cur_timer涉及的定时器对象。
- 如cur_timer指向timer_hpet,timer_pmtmr和timer_tsc,则一次”loop”对应一个CPU循环–也就是两个连续CPU时钟信号间的时间间隔
- 如cur_timer指向timer_none或timer_pit,则一次”loop”对应于一条紧凑指令循环在一次单独的循环中所花费的时间。
初始化阶段,select_timer设置好cur_timer后,内核通过calibrate_delay决定一个节拍里有多少次”loop”。值保存在current_cpu_data.loops_per_jiffy中,这样udelay,ndelay能根据它来把微妙和纳秒转换成”loops”。
如可利用HPET或TSC硬件电路,则cur_timer->dalay使用它们来获取精确的时间测量。否则,该方法执行一个紧凑指令循环的loops次循环。
与定时测量相关的系统调用
time和gettimeofday系统调用
time:返回从1970年1月1日午夜开始所走过的秒数gettimeofday:返回从1970年1月1日午夜开始所走过的秒数及前一秒内走过的微妙数,值存放在数据结构timeval中。
另一个被广泛使用的函数ftime不再作为一个系统调用来执行,它返回从1970年1月1日午夜开始所走过的秒数与前1秒内所走过的毫秒数。这是使用do_gettimeofday更新这些函数所需要的资源:
为读操作获取xtime_lock
调cur_timer的get_offset来确定自上次时钟中断走过的微妙数
- 如cur_timer指向timer_hpet,将HPET计数器的当前值与上一次时钟中断处理程序执行时在同一个计数器中保存的值比较。
- 如cur_timer指向timer_pmtmr,将ACPI PMT计数器的当前值与上一次时钟中断处理程序执行时在同一个计数器里保存的值比较。
- 如cur_timer指向timer_tsc,将时间戳计数器的当前值与上一次时钟中断处理程序执行时在同一个TSC里保存的值比较
- 如cur_timer指向timer_pit,读取PIT计数器的当前值来计算自上一次PIT时钟中断以来走过的微妙数。
如某定时器中断丢失,该函数为usec加上相应的延迟:usec += (jiffies - wall_jiffies) * 1000;
为usec加上前1秒内走过的微妙数usec += (xtime.tv_nsec / 1000);
将xtime的内容复制到系统调用参数tv指定的用户空间缓冲区中,并给微妙字段的值加上usec:tv->tv_sec = xtime->tv_sec;tv->tv_usec = usec;
在xtime_lock顺序锁上调read_seqretry,且如另一条内核控制路径同时为写操作而获得了xtime_lock,跳回1
检查tv_usec字段是否溢出,如必要调整
while(tv->tv_usec >= 1000000){
tv->tv_usec -= 1000000;
tv->tv_sec++;
}拥有root权限的用户态下的进程可用stime,settimeofday来修改系统当前日期和时间。
settimer和alarm
Linux允许用户态的进程激活一种叫间隔定时器的特殊定时器。这种定时器引起的Unix信号被周期性地发送到进程。间隔定时器:
- 发送信号所必须的频率,或如只需产生一个信号,则频率为空。
- 在下一个信号被产生以前所剩余的时间settimer:
ITIMER_REAL
真正过去的时间;进程接收SIGALRM
ITIMER_VIRTUAL
进程在用户态下花费的时间;进程接收SIGVTALRM
ITIMER_PROF
进程既在用户态下又在内核态下花费的时间;进程接收SIGPROF为能实现每种策略,进程描述符要包含3对字段:
- it_real_incr和it_real_value
- it_virt_incr和it_virt_value
- it_prof_incr和it_prof_value
每对中第一个字段存放着两个信号之间以节拍为单位的间隔;另一个字段存放着定时器当前值。ITIMER_REAL利用动态定时器实现。每个进程描述符包含一个real_timer的动态定时器对象。
ITIMER_VIRTUAL和ITIMER_PROF,只有当进程运行时,它们才能被更新。update_process_times在单处理器上由PIT时钟中断处理程序调用;多处理器上由本地时钟中断处理程序调用。
进程调度
我们这里,准备讨论一下进程调度这个话题,这是对进程那一章节的继续补充!
调度策略
Linux的调度基于分时技术!多个进程以时间多路复用的方式进行运行。因为CPU的时间被分成了片分配给每个进程。当然单处理器在任何给定时刻只能运行一个进程,如果当前进程的时间片或时限到期时,进程没有运行完毕,那么进程切换就可以!
发生分时机依赖于定时中断,因此对进程是透明的,不需要在程序中插入额外的代码来进行切换。
在Linux中进程的优先级是动态进行分配的,调度程序跟踪器进程正在做什么,动态的调整它们的优先级!传统上把进程分为io受限或CPU受限,前者频繁的使用io设备,并且花费等很多时间等待io操作完成。后者则需要大量的CPU时间的数值计算这样的应用程序。
另一种则把进程分为三类:
- 交互式进程:这类进程经常与用户进行交互,因此需要花很多时间等待键盘和鼠标操作
- 批处理进程:这些进程不必与用户进行一种交互,经常在后台进行运行。这样的进程不必很快响应,因此经常受到调度程序的慢怠
- 实时进程:这些进程有很强的调度需求,这样的进程绝不会被低优先级的进程阻塞。他们应该有一个很短的响应时间。
一些API:
| 系统调用 | 说明 |
|---|---|
| nice | 改变一个普通进程的静态优先级 |
| getpriority | 获得一组普通进程的最大静态优先级 |
| setpriority | 设置一组普通进程的静态优先级 |
| sched_getscheduler | 获得一个进程的调度策略 |
| sched_setscheduler | 设置一个进程的调度策略和实时优先级 |
| sched_getparam | 获得一个进程的实时优先级 |
| sched_setparam | 设置一个进程的实时优先级 |
| sched_yield | 自愿放弃处理器而不阻塞 |
| sched_get_priority_min | 获得一种策略的最小实时优先级 |
| sched_get_priority_max | 获得一种策略的最大实时优先级 |
| sched_rr_get_interval | 获得时间片轮转策略的时间片值 |
| sched_setaffinity | 设置进程的CPU亲和力掩码 |
| sched_getaffinity | 获得进程的CPU亲和力掩码 |
进程抢占
Linux的进程是抢占式的,如果进程进入task running状态,内核检查它的动态优先级是否大于当前正在运行的进程的优先级!如果是,进程切换发生。
时间片的选择应该如何
时间片的长短对系统性能很关键,不可太长也不可太短,如果太短,由进程切换引起的系统额外开销会变得很高;如果太长,系统看起来的响应非常的差。所以对时间片大小的选择始终是一种折中 。
调度算法
每次进程切换时,内核扫描可运行进程链表,计算进程的优先级,再选择”最佳”进程来运行。在固定的时间内(与可运行的进程数量无关)选中要运行的进程。很好处理了与处理器数量的比例关系,每个CPU都拥有自己的可运行进程队列。新算法较好解决了区分交互式进程,批处理进程的问题。每个Linux进程总是按下面的调度类型被调度:
SCHED_FIFO:当调度程序把CPU分配给进程时候,它把该进程描述符保留在运行队列链表的当前位置。如没其他可运行的更高优先级实时进程,进程就继续用CPU。想用多久用多久。SCHED_RR:时间片轮转的实时进程。调度程序把CPU分配给进程时候,把该进程的描述符放在运行队列链表的末尾。保证对所有具有相同优先级的SCHED_RR实时进程公平地分配CPU时间。SCHED_NORMAL:普通的分时进程。(默认的)
普通进程的调度
每个普通进程有它自己的静态优先级,调度程序使用静态优先级来估价系统中这个进程和其他普通进程间调度的程度。内核用100(高)到139(低)的数表示普通进程的静态优先级。值越大静态优先级越低。新进程总是继承其父进程的静态优先级。通过把某些"nice"值传递给系统调用nice和setpriority,用户可改变自己拥有的进程的静态优先级。
基本时间片
静态优先级本质上决定了进程的基本时间片,即进程用完了以前的时间片时,系统分配给进程的时间片长度。静态优先级和基本时间片的关系用下列公式确定:
基本时间片(ms):
若静态优先级 < 120,(140 - 静态优先级) * 20
若静态优先级 >= 120,(140 - 静态优先级) * 5
| 说明 | 静态优先级 | nice值 | 基本时间片 | 交互式@值 | 睡眠时间极限值 |
|---|---|---|---|---|---|
| 最高静态优先级 | 100 | -20 | 800ms | -3 | 299ms |
| 高静态优先级 | 110 | -10 | 600ms | -1 | 499ms |
| 缺省静态优先级 | 120 | 0 | 100ms | +2 | 799ms |
| 低静态优先级 | 130 | +10 | 50ms | +4 | 999ms |
| 最低静态优先级 | 139 | +19 | 5ms | +6 | 1199ms |
动态优先级和平均睡眠时间
普通进程除了静态优先级,还有动态优先级,其值的范围是100(高)~139(低)。动态优先级是调度程序在选择新进程来运行时候使用的数。它与静态优先级的关系用下面的经验公式表示:
动态优先级=max(100, min(静态优先级 - bonus + 5, 139))
bonus是范围0~10的值,值小于5表示降低动态优先级以示惩罚,值大于5表示增加动态优先级以示奖赏。bonus值依赖于进程过去的情况,更准确些,与进程的平均睡眠时间相关。粗略讲,平均睡眠时间是进程在睡眠状态所消耗的平均纳秒数。如,在TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE状态所计算出的平均睡眠时间是不同的。且,进程在运行过程中平均睡眠时间递减,平均睡眠时间永远不会大于1s。
| 平均睡眠时间 | bonus | 粒度 |
|---|---|---|
| [0,100ms) | 0 | 5120 |
| [100ms,200ms) | 1 | 2560 |
| [200ms,300ms) | 2 | 1280 |
| [300ms,400ms) | 3 | 640 |
| [400ms,500ms) | 4 | 320 |
| [500ms,600ms) | 5 | 160 |
| [600ms,700ms) | 6 | 80 |
| [700ms,800ms) | 7 | 40 |
| [800ms,900ms) | 8 | 20 |
| [900ms,1000ms) | 9 | 10 |
| 1s | 10 | 10 |
平均睡眠时间也被调度程序用来确定一个给定进程是交互式进程,还是批处理进程。对于交互式进程的计算方式是:动态优先级 <= 3 * 静态优先级 / 4 + 28或 bonus - 5 >= 静态优先级 / 4 - 28
总结:
- 优先级越高获得的时间片越大
- 睡眠时间越长,动态优先级在静态优先级基础上越高(值越小)。
活动与过期进程
当然,我们想到即使是不具有较高静态优先级的普通进程获得较大的CPU时间片,也不应该使得静态优先级较低的进程无法运行!(活动队列一直被高优先级的进程抢占!)为了避免进程饥饿,当一个进程用完它的时间片时,它应该被还没有用完时间片的低优先级进程取代!
为了实现这种机制调度程序分了两个不相交的可运行进程的集合:
- 活动进程:这些进程还没有用完他们的时间片因此引起他们的运行运行
- 过期进程:这些可运行进程已经完它们的时间片,因此禁止被运行直到所有活动进程都过期
实时进程的调度
每个实时进程都与一个实时优先级相关!实时优先级是一个从1到99的值!调用程序总是让优先级高的进程运行,换句话说实时进程运行的过程中禁止低优先级进程的运行!与普通进程相反,实时进程总是可以被当成活动进程!
如果几个可运行的实时进程具有相同的优先级那么调度,进程选择第一个出现在本地CPU的运行队列的相应的列表的进程!与进程只有在以下列这些事情发生的时候实时进程才会被另外一个进程取代:
- 进程被另一个具有较高优先级对实时进程抢占
- 实时进程执行了阻塞操作并且进入了睡眠进程
- 停止或者被杀死进程
- 通过系统调用sched_yield自愿放弃CPU
- 进程正是基于时间片轮转的实时进程,而且用完了它的时间片
调度程序所使用的数据结构
数据结构runqueue
系统中的每个CPU都有它自己的运行队列,所有的runqueue结构存放在runqueues每CPU变量中。宏this_rq产生本地CPU运行队列的地址,宏cpu_rq(n)产生索引为n的CPU的运行队列的地址。
| 类型 | 名称 | 说明 |
|---|---|---|
| spinlock_t | lock | 保护进程链表的自旋锁 |
| unsigned long | nr_running | 运行队列链表中可运行进程的数量 |
| unsigned long | cpu_load | 基于运行队列中进程的平均数量的CPU负载因子 |
| unsigned long | nr_switches | CPU执行进程切换的次数 |
| unsigned long | nr_uninterruptible | 先前在运行队列链表,现在睡眠在TASK_UNINTERRUPTIBLE状态的进程的数量 |
| unsigned long | expired_timestamp | 过期队列中最老的进程被插入队列的时间 |
| unsigned long long | timestamp_last_tick | 最近一次定时器中断的时间戳的值 |
| task_t* | curr | 当前正运行进程的描述符指针 |
| task_t* | idle | 当前CPU上swapper进程的描述符指针 |
| struct mm_struct* | prev_mm | 进程切换期间用来存放被替换进程的内存描述符地址 |
| prio_array_t* | active | 指向活动进程链表的指针 |
| prio_array_t* | expired | 指向过期进程链表的指针 |
| prio_array_t[2] | arrays | 活动进程和过期进程的两个集合 |
| int | best_expired_prio | 过期进程中静态优先级最高的进程 |
| atomic_t | nr_iowait | 先前在运行队列链表中,现在正等待磁盘I/O操作结束的进程的数量 |
| struct sched_domain* | sd | 指向当前CPU的基本调度域 |
| int | active_balance | 如要把一些进程从本地运行队列迁移到另外的运行队列,就设置 |
| int | push_cpu | 未使用 |
| task_t* | migration_thread | 迁移内核线程的进程描述符指针 |
| struct list_head | migration_queue | 从运行队列中被删除的进程的链表 |
系统中每个可运行进程属于且只属于一个运行队列。只要可运行进程保持在同一个运行队列中,它就只可能在拥有该运行队列的CPU上执行。可运行进程会从一个运行队列迁移到另一个运行队列。
运行队列的arrays字段是一个包含两个prio_array_t结构的数组。每个数据结构都表示一个可运行进程的集合,并包括140个双向链表头(每个链表对应一个可能的进程优先级),一个优先级位图,一个集合中所包含的进程数量的计数器。
arrays中两个数据结构的作用会发生周期性的变化:活动进程突然变成过期进程,过期进程变成活动进程。调度程序简单地交换运行队列的active和expired字段的内容以完成变化。
进程描述符
| 类型 | 名称 | 说明 |
|---|---|---|
| unsigned long | thread_info->flags | 存放TIF_NEED_RESCHED,如必须调调度程序,则设置 |
| unsigned int | thread_info->cpu | 可运行进程所在运行队列的CPU逻辑号 |
| unsigned long | state | 进程的当前状态 |
| int | prio | 进程的动态优先级 |
| int | static_prio | 进程的静态优先级 |
| struct list_head | run_list | 指向进程所属的运行队列链表中的下一个和前一个元素。链表节点。 |
| prio_array_t* | array | 指向包含进程的运行队列的集合prio_array_t |
| unsigned long | sleep_avg | 进程的平均睡眠时间 |
| unsigned long long | timestamp | 进程最近插入运行队列时间,或涉及本进程的最近一次进程切换的时间 |
| unsigned long long | last_ran | 最近一次替换本进程的进程切换时间 |
| int | activated | 进程被唤醒时使用的条件代码 |
| unsigned long | policy | 进程的调度类型(SCHED_NORMAL,SCHED_RR,SCHED_FIFO) |
| cpumask_t | cpus_allowed | 能执行进程的CPU的位掩码 |
| unsigned int | time_slice | 在进程的时间片中还剩余的时钟节拍数 |
| unsigned int | first_time_slice | 如进程肯定不会用完其时间片,就设置 |
| unsigned long | rt_priority | 进程的实时优先级 |
进程被创建时
p->time_slice = (current->time_slice+1)>>1;
current->time_slice>>=1;父进程剩余的节拍数被划分成两等份。一份给父进程,一份给子进程。子进程在首个时间片内终止或执行新程序,剩余时间奖励给父进程。
调度程序所使用的函数
scheduler_tick:维持最新的time_slice计数器try_to_wake_up:唤醒睡眠进程recalc_task_prio更新进程的动态优先级schedule选择要被执行的新进程load_balance:维持多处理器系统中运行队列的平衡
scheduler_tick
每次时钟节拍到来时,scheduler_tick:
把转换为纳秒的
TSC当前值存入本地运行队列的timestamp_last_tick。这个时间戳是从sched_clock获得的。检查当前进程是否是本地
CPU的swapper进程。如是,如本地运行队列除了
swapper外,还包括一个可运行的进程,就设置当前进程的TIF_NEED_RESCHED。如内核支持超线程技术,则只要一个逻辑CPU运行队列中的所有进程 都有比 另一个逻辑CPU上已经在执行的进程 有低得多的优先级(两个逻辑CPU对应同一个物理CPU),前一逻辑CPU就可能空闲。超线程下,将2个进程安排在两个不同物理cpu,相比在同一物理cpu的多个逻辑cpu可以更好并发,然后跳到第七步!检查
current->array是否指向本地运行队列的活动链表。如不是,设置TIF_NEED_RESCHED。跳到7获得
this_rq()->lock递减当前进程的时间片计数器。检查是否已用完时间片。由于进程的调度类型不同,这一步操作也有很大差别。稍后讨论。
释放
this_rq()->lock调
rebalance_tick。保证不同CPU的运行队列包含数量基本相同的可运行进程。
更新实时进程的时间片
如当前进程是FIFO的实时进程,scheduler_tick什么也不做。维持当前进程的最新时间片计数器没意义。如current表示基于时间片轮转的实时进程,scheduler_tick就递减它的时间片计数器并检查时间片是否被用完
if(current->policy == SCHED_RR && !--current->time_slice)
{
current->time_slice = task_timeslice(current);
current->first_time_slice = 0;
set_tsk_need_resched(current);
list_del(¤t->run_list);
list_add_tail(¤t->run_list, this_rq()->active->queue+current->prio);
}如函数确定时间片用完了,就执行操作以抢占当前进程。
- 调
task_timeslice重填进程的时间片计数器 scheduler_tick调set_tsk_need_resched设置TIF_NEED_RESCHED- 把进程描述符移到与当前进程优先级相应的运行队列活动链表尾部。
更新普通进程的时间片
如当前进程是普通进程,scheduler_tick:
递减
current->time_slice如时间片用完
调
dequeue_task从可运行进程的this_rq()->active集合中删除current指向的进程调
set_tsk_need_resched设置TIF_NEED_RESCHED更新
current指向的进程的动态优先级,current->prio = effective_prio(current);重填进程的时间片
current->time_slice = task_timeslice(current); current->first_time_slice = 0;如果本地运行队列的
expired_timestamp等于0,就把当前时钟节拍值赋给expired_timestamp把当前进程插入活动进程集合或过期进程集合
if(!TASK_INTERACTIVE(current) || EXPIRED_STARVING(this_rq()) { enqueue_task(current, this_rq()->expired); if(current->static_prio < this_rq()->best_expired_prio) this_rq()->best_expired_prio = current->static_prio; } else enqueue_task(current, this_rq()->active);宏
EXPIRED_STARVING检查运行队列中的第一个过期进程的等待时间是否已经超过1000个时钟节拍乘以运行队列中可运行进程数加1。如是,产生1。如当前进程的静态优先级大于一个过期进程的静态优先级。也产生1。
如时间片没用完。检查当前进程的剩余时间片是否太长。
>if(TASK_INTERACTIVE(p) && !((task_timeslice(p)-p->time_slice % TIMESLICE_GRANULARITY(p)) && (p->time_slice >= TIMESLICE_GRANULARITY(p)) && (p->array == rq->active)) >{ list_del(¤t->run_list); list_add_tail(¤t->run_list, this_rq()->active->queue+current->prio); set_tsk_need_resched(p); >}
基本上,具有高静态优先级的交互式进程,其时间片被分成大小为TIMESLICE_GRANULARITY的几个片段,每次用完一个片段,就重新调度一次。以便时间片太长下,其他活动进程有机会得到执行。
try_to_wake_up
把进程状态置为TASK_RUNNING,把进程插入本地CPU的运行队列来唤醒睡眠或停止的进程。参数:
- 被唤醒进程的描述符指针
- 可被唤醒的进程状态掩码
- 一个标志,用来禁止被唤醒的进程抢占本地
CPU上正运行的进程
操作:
调
task_rq_lock禁用本地中断。获得最后执行进程的cpu所拥有的运行队列rq锁。检查进程状态
p->state是否属于被当作参数传递给函数的状态掩码。如不是,跳到9。如
p->array不等于NULL。跳到8在多处理器系统中,函数检查要被唤醒的进程是否应该从最近运行的
CPU的运行队列迁移到另外一个CPU的运行队列。实际上,函数根据一些启发式规则选择一个目标运行队列。
- 如系统中某些
CPU空闲,就选择空闲CPU的运行队列。按优先选择当前正执行进程的CPU和本地CPU这种顺序。- 如先前执行进程的CPU
的工作量远小于本地CPU的工作量,就选择先前的运行队列作为目标- 如进程最近被执行过,就选择老的运行队列作为目标(可能仍用这个进程的数据填充硬件高速缓存)
- 如把进程移到本地
CPU以缓解CPU之间的不平衡,目标就是本地运行队列此时,已经确定了目标
CPU和对应的目标运行队列rq。如进程处于
TASK_UNINTERRUPTIBLE,递减目标运行队列的nr_uninterruptible,把进程描述符的p->activated置为-1。调
active_task
调
sched_clock获取以纳秒为单位的当前时间戳。如目标CPU不是本地CPU,就补偿本地时钟中断的偏差。从而得到准确的目标cpu上的时间戳。>now=(sched_clock()-this_rq()->timestamp_last_tick)+rq->timestamp_last_tick;调
recalc_task_prio,把进程描述符的指针和上一步计算出的时间戳传递给它。重新计算平均睡眠时间,动态优先级。调整
p->activated,以便反映从中断唤醒,从非中断唤醒,不可中断睡眠进程唤醒。据
6.1.算出的时间戳设置p->timestamp把进程描述符插入活动进程集合
enqueue_task(p, rq->active); rq->nr_running++;. 如目标
CPU不是本地CPU,或没设置sync。就检查可运行的新进程的动态优先级是否比rq运行队列中当前进程动态优先级高。如是,就让目标cpu及时发生新的调度。把进程的
p->state置为TASK_RUNNING调
task_rq_unlock打开rq运行队列的锁并打开本地中断返回
1或0
recalc_task_prio
更新进程的平均睡眠时间,动态优先级.接收进程描述符指针p,和由sched_clock计算出的当前时间戳。操作:
把
min(now - p->timestamp,1 0 9 10^9109)的结果赋给局部变量sleep_time。这样计算出来的是进程的睡眠时间。p->timestamp包含导致进程进入睡眠状态的进程切换的时间戳。sleep_time中存放的是从进程最后一次执行开始,进程消耗在睡眠状态的纳秒数。睡眠时间长时,sleep_time就等于1s如
sleep_time不大于0,跳到8。若进程不是内核线程,进程不是从
TASK_UNINTERRUPTIBLE被唤醒,进程连续睡眠的时间超过给定的睡眠时间极限。都满足,函数把p->sleep_avg设置为相当于900个时钟节拍的值。(用最大平均睡眠时间减去一个标准进程的基本时间片长度获得一个经验值)跳8。睡眠时间极限,进程静态优先级。这些经验规则的目的是保证已经睡眠了很长时间的进程,获得一个预先确定且足够长的平均睡眠时间,以使这些进程能尽快获得服务。
执行
CURRENT_BONUS计算进程原来的平均睡眠时间的bonus值。如(10 - bonus)大于0,函数用这个值与sleep_time相乘。因为要把sleep_time加到进程的平均睡眠时间上,所以当前平均睡眠时间越短,它增加的就越快。如进程处于
TASK_UNINTERRUPTIBLE且不是内核线程,执行下述:- 检查平均睡眠时间
p->sleep_avg是否大于或等于进程的睡眠时间极限。如是,把局部变量sleep_time重新置为0,因此不用调整平均睡眠时间,跳6。 - 如
sleep_time+p->sleep_avg的和大于或等于睡眠时间极限,就把p->sleep_avg置为睡眠时间极限并把sleep_time置为0。通过对进程平均睡眠时间的轻微限制,函数不会对睡眠时间很长的批处理进程给予过多奖赏。
- 检查平均睡眠时间
把
sleep_time加到进程的平均睡眠时间上。检查
p->sleep_avg是否超过1000个时钟节拍(以纳秒为单位),如是,函数就把它减到1000个时钟节拍(以纳秒为单位)。更新进程的动态优先级:
p->prio=effective_prio(p);函数依据p的静态优先级,sleep_avg按前面介绍的规则计算动态优先级。
schedule
从运行队列的链表找到一个进程,随后将CPU分配给这个进程。schedule可由几个内核控制路径调用,可采取直接调用或延迟调用的方式。
从使用角度介绍schedule使用场景–直接调用
如current进程因不能获得必须的资源而要立刻被阻塞,就直接调调度程序。此时,要阻塞进程的内核路径按下述步骤:
- 把
current进程插入适当的等待队列 - 把
current进程状态改为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE - 调
schedule - 检查资源是否可用。如不可用就跳到
2。 - 一旦资源可用,就从等待队列中删除
current。
从使用角度介绍schedule使用场景–延迟调用
也可把current进程的TIF_NEED_RESCHED标志设置为1,而以延迟方式调用调度程序。
由于总是在恢复用户态进程的执行前检查这个标志的值,所以schedule将在不久后的某个时间被明确地调用。
以下是延迟调用调度程序的典型例子:
- 当
current进程用完了它的CPU时间片时,由schedule_tick完成schedule的延迟调用。 - 当一个被唤醒进程的优先级比当前进程的优先级高,由
try_to_wake_up完成schedule的延迟调用 - 当发出系统调用
sched_setscheduler时。
进程切换之前schedule所执行的操作
schedule任务之一是用另外一个进程来替换当前正执行的进程。
该函数的关键结果是设置一个叫next的变量,使它指向被选中的进程,该进程将取代current进程。如系统中没优先级高于current进程的可运行进程,则最终next与current相等,不发生任何进程切换。
need_resched:
preempt_disable();
prev = current;
rq = thi_rq();下一步,schedule要保证prev不占用大内核锁
if(prev->lock_depth >= 0)
up(&kernel_sem); 注意,schedule不改变lock_depth;进程切换会自动释放和重新获取大内核锁。调sched_clock以读取TSC,将它的值换成纳秒。获得的时间戳存放在局部变量now。schedule计算prev所用的CPU时间片长度:
now = sched_clock();
run_time = now - prev->timestamp;
if(run_time > 1000000000)
run_time = 1000000000;通常使用限制在1s的时间。run_time的值用来限制进程对CPU的使用。不过,鼓励进程有较长的平均睡眠时间:
run_time /= (CURRENT_BONUS(prev) ? : 1);记住,CURRENT_BONUS返回0~10之间的值,它与进程的平均睡眠时间是成比例的。这样 平均睡眠时间越长,有效的run_time就越小。开始寻找可运行进程前,schedule需关掉本地中断,并获得所要保护的运行队列的自旋锁。
spin_lock_irq(&rq->lock);prev可能是一个正被终止的进程。为确认这个事实,schedule检查PF_DEAD标志:
if(prev->flags & PF_DEAD)
prev->state = EXIT_DEAD;schedule检查prev的状态。
// 进程状态不是可运行&允许内核抢占
if(prev->state != TASK_RUNNING && !(preempt_count() & PREEMPT_ACTIVE))
{
// 进程状态是可中断休眠&存在待处理信号
if(prev->state == TASK_INTERRUPTIBLE && signal_pending(prev))
prev->state = TASK_RUNNING;// 恢复进程状态为可运行
else
{
if(prev->state == TASK_UNINTERRUPTIBLE)
rq->nr_uninterruptible++;
// 将进程从其所在的进程链表移除。这样进程被移除在调度目标考虑范围外。
deactive_task(prev, rq);
}
} 现在schedule检查运行队列中剩余的可运行进程数。如有可运行的进程,schedule就调dependent_sleeper。绝大多数情况下,该函数立即返回0。但,如内核支持超线程技术,函数检查要被选中执行的进程,其优先级是否比已经在相同物理CPU的某个逻辑CPU上运行的兄弟进程的优先级低;这种特殊情况下,schedule拒绝选中低优先级进程,执行swapper。这样是为了避免低优先级进程抢占同一物理cpu内的共享资源。
if(rq->nr_running)
{
if(dependent_sleeper(smp_processor_id(), rq))
{
next = rq_idle;
goto switch_tasks;
}
}如运行队列中没可运行的进程存在,就调idle_balance。从另外一个运行队列迁移一些可运行进程到本地运行队列中。idle_balance与load_balance类似。
if(!rq->nr_running)
{
idle_balance(smp_processor_id(), rq);
if(!rq->nr_running){
next = rq_idle;
rq->expired_timestamp = 0;
wake_sleeping_dependent(smp_processor_id(), rq);
if(!rq->nr_running)
goto switch_tasks;
}
}如idle_balance没成功把进程迁移到本地运行队列, wake_sleeping_dependent是检查兄弟进程正在运行空闲进程,且存在可运行进程下,设置其调度标志。在单处理器系统,或把进程迁移到本地运行队列的种种努力都失败情况下,函数选择swapper作为next并继续执行下一步骤。
// 走到这里,是可以继续在运行队列中选择目标进程
array = rq->active;
if(!array->nr_active)
{
// 交换活动队列,过期队列
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = 140;
}schedule搜索活动进程集合位掩码的第一个非0位。当对应的优先级链表不为空时,就把位掩码相应位置1。第一个非0位的下标对应包含最佳运行进程的链表。
idx = sched_find_first_bit(array->bitmap);
next = list_entry(array->queue[idx].next, task_t, run_list);函数sched_find_first_bit基于bsfl汇编语言指令的,它返回32位字中被设置为1的最低位的位下标。局部变量next现在存放将取代prev的进程描述符指针。schedule检查next->activated,该字段的编码值表示进程在被唤醒时的状态。
| 值 | 说明 |
|---|---|
| 0 | 进程处于TASK_RUNNING |
| 1 | 进程处于TASK_INTERRUPTIBLE或TASK_STOPPED,且正被系统服务例程或内核线程唤醒 |
| 2 | 进程处于TASK_INTERRUPTIBLE或TASK_STOPPED,且正被中断处理程序或可延迟函数唤醒 |
| -1 | 进程处于TASK_UNINTERRUPTIBLE且正被唤醒 |
如next是一个普通进程,且正从TASK_INTERRUPTIBLE或TASK_STOPPED被唤醒,调度程序就把自从进程插入运行队列开始所经过的纳秒数加到进程的平均睡眠时间中。即进程的睡眠时间被增加了,以包含进程在运行队列中等待CPU所消耗的时间。
if(next->prio >= 100 && next->activated > 0)
{
unsigned long long delta = now - next->timestamp;
if(next->activated == 1)
delta = (delta * 38) / 128;
array = next->array;
dequeue_task(next, task);
recalc_task_prio(next, next->timestamp + delta);// 内部会用参数2 - 参数1的timestamp字段计算平均睡眠时间
}
enqueue_task(next, array);调度程序把被中断处理程序和可延迟函数所唤醒的进程与被系统调用服务例程和内核线程所唤醒的进程区分开来。前一种,调度程序增加全部运行队列等待时间。后一种,它只增加等待时间的部分。交互式进程更可能被异步事件而不是同步事件唤醒。
schedule完成进程切换时操作
到这里已经完成了目标进程的选择。
switch_tasks:
prefetch(next);prefetch提示CPU控制单元把next的进程描述符第一部分字段的内容装入硬件高速缓存。替代prev之前,调度程序应完成一些管理工作
clear_tsk_need_resched(prev);
rcu_qsctr_inc(prev->thread_info->cpu);clear_tsk_need_resched清除prev的TIF_NEED_RESCHED标志。函数记录CPU正在经历静止状态。schedule还必须基于进程所使用的CPU时间片减少prev的平均睡眠时间
prev->sleep_avg -= run_time;
if((long)prev->sleep_avg <= 0)
prev->sleep_avg = 0;
// 记录进程失去cpu的时间点
// 这样,便能在后续用于记录睡眠了多长时间
prev->timestamp = prev->last_ran = now;prev和next很可能是同一个进程:如在当前运行队列中没优先级较高或相等的其他活动进程时,会发生这种情况。
if(prev == next)
{
spin_unlock_irq(&rq->lock);
goto finish_schedule;
}prev和next是不同的进程,进程切换发生。
// 目标进程记录开始获得cpu的时间。这样后续就可用来统计运行时间。
next->timestamp = now;
rq->nr_switches++;
rq->curr = next;
prev = context_switch(rq, prev, next);context_switch
context_switch建立next的地址空间,进程描述符的active_mm指向进程所使用的内存描述符,mm指向进程所拥有的内存描述符。
内核线程没自己的地址空间,且它的mm置为NULL。context_switch确保,如next是一个内核线程,使用prev的地址空间。
// 表明next是一个内核线程
if(!next->mm)
{
// 保持之前active_mm
next->active_mm == prev->active_mm;
atomic_inc(&prev->active_mm->mm_count);
// 进入懒惰TLB
enter_lazy_tlb(prev->active_mm, next);
}如果next是内核线程,schedule把进程设置为懒惰TLB模式。如next是一个普通进程,context_switch用next的地址空间替换prev的。
// 表明next是一个普通进程
if(next->mm)
switch_mm(prev->active_mm, next->mm, next);// 完成页表切换如prev是内核线程或正退出的进程,context_switch就把指向prev内存描述符的指针保存到运行队列的prev_mm,重新设置prev->active_mm:
// 之前是内核线程
if(!prev->mm)
{
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}现在,context_switch终于可调switch_to执行prev和next之间的进程切换了。
// 设置寄存器,栈,执行流程切换
switch_to(prev, next, prev);
// 表示被换出进程恢复执行
return prev;进程切换后schedule所执行的操作
稍后调度程序又选择prev执行时由prev执行。然而,那个时刻,prev局部变量并不指向我们开始描述schedule时所替换出去的原来那个进程,而是指向prev被调度时由prev替换出的原来那个进程。
barrier();
finish_task_switch(prev);finish_task_switch函数:
mm = this_rq()->prev->mm;
this_rq()->prev_mm = NULL;
prev_task_flags = prev->flags;
spin_unlock_irq(&this_rq()->lock);
if(mm)
mmdrop(mm);
if(prev_task_flags & PF_DEAD)
put_task_struct(prev);如prev是一个内核线程,则运行队列的prev_mm字段存放借给prev的内存描述符的地址。mmdrop减少内存描述符的使用计数器;如计数器等于0,函数还需释放与页表相关的所有描述符和虚拟存储区。finish_task_switch函数还要释放运行队列的自旋锁并打开本地中断。检查prev是否是一个正在从系统中被删除的僵死任务。如是,就调put_task_struct以释放进程描述符引用计数器,并撤销所有其余对该进程的引用。
finish_schedule:
prev = current;
if(prev->lock_depth >= 0)
__reacquire_kernel_lock();
preempt_enable_no_resched();
if(test_bit(TIF_NEED_RESCHED, ¤t_thread_info()->flags))
goto need_resched;
return;schedule在需要时重新获得大内核锁,重新启用内核抢占。并检查是否一些其他的进程已设置了当前进程的TIF_NEED_RESCHED。如是,整个schedule重新执行。如否,结束
多处理器系统中运行队列的平衡
(1). 标准的多处理器体系结构
这些机器所共有的RAM芯片集被所有CPU共享
(2). 超线程
当前线程在访问内存的间隙,处理器可使用它的机器周期去执行另一个线程。一个物理CPU包含多个逻辑CPU。
(3). NUMA
把CPU和RAM以本地”节点”为单位分组。通常一个节点包括一个CPU和几个RAM芯片。
内存仲裁器(一个使系统中的CPU以串行方式访问RAM的专用电路)是典型的多处理器系统的性能瓶颈。
在NUMA体系结构中,当CPU访问与它同在一个节点中的”本地”RAM芯片时,几乎没有竞争,因此访问通常很快。
另一方面,访问其所属节点外的”远程”RAM芯片就非常慢。
这些基本的多处理器系统类型经常被组合使用。如,内核把一个包括两个不同超线程CPU的主板看作四个逻辑CPU。schedule从本地CPU的运行队列挑选新进程运行。一个指定的CPU只能执行其相应的运行队列中的可运行进程。一个可运行进程总是存放在某一个运行队列中:任何一个可运行进程都不可能同时出现在两个或多个运行队列。
某些情况下,把可运行进程限制在一个指定的CPU上可能引起严重的性能损失。如考虑频繁使用CPU的大量批处理进程:如它们绝大多数都在同一个运行队列中,则系统中的一个CPU将会超负荷。而其他一些CPU几乎处于空闲状态。故,内核周期性地检查运行队列的工作量是否平衡,并在需要的时候,把一些进程从一个运行队列迁移到另一个运行队列。但为了从多处理系统获得最佳性能,负载平衡算法应考虑系统中CPU的拓扑结构。从内核2.6.7开始,Linux提出一种基于”调度域”概念的复杂的运行队列平衡算法。有了调度域概念,使得这种算法很容易适应各种已有的多处理器体系结构。
调度域
调度域实际上是一个CPU集合,它们的工作量应由内核保持平衡。一般,调度域采取分层的组织形式:最上层的调度域(通常包括系统中的所有CPU)包括多个子调度域,每个子调度域包括一个CPU子集。正是调度域的这种分层结构,使工作量的平衡能以如下有效方式来实现。
每个调度域被依次划分成一个或多个组,每个组代表调度域的一个CPU子集。工作量的平衡总是在调度域的组之间来完成。只有在调度域的某个组的总工作量远远低于同一个调度域的另一个组的工作量时,才把进程从一个CPU迁移到另一个CPU。
(1). 2-CPU的SMP
基本域(0级):
有两个组,每组一个CPU
(2). 2-CPU,有超线程的SMP
一级域:
有两个组,每组一个物理CPU
基本域(0级):
有两个组,每组一个逻辑CPU
(3). 8-CPU的NUMA(每个节点有四个CPU)
一级域:
有两个组,每组一个节点
基本域(0级):
有四个组,每组1个CPU
每个调度域由一个sched_domain表示。调度域中的每个组由sched_group表示。每个sched_domain包括一个groups字段,它指向组描述符链表中的第一个元素。此外,sched_domain结构的parent指向父调度域的描述符。系统中所有物理CPU的sched_domain都存放在每CPU变量phys_domains中。
如内核不支持超线程技术,这些域就在域层次结构的最底层,运行队列描述符的sd字段指向它们,即它们是基本调度域。相反,如内核支持超线程技术,则底层调度域存放在每CPU变量cpu_domains中。
rebalance_tick
为保持系统中运行队列的平衡,每经过一次时钟节拍,scheduler_tick就调用rebalance_tick。它接收参数有:本地CPU的下标this_cpu,本地运行队列的地址this_rq,一个标志idle,该标志可取下面值:
(1). SCHED_IDLECPU当前空闲,即current是swapped进程
(2). NOT_IDLECPU当前不空闲,即current不是swapper进程
rebalance_tick先确定运行队列中的进程数,更新运行队列的平均工作量,为完成此工作。函数要访问运行队列描述符的nr_running和cpu_load。最后,rebalance_tick开始在所有调度域上的循环,其路径是从基本域(本地运行队列描述符的sd字段所引用的域)到最上层的域。每次循环中,函数确定是否已到调用函数load_balance的时间,从而在调度域上执行重新平衡的操作。
由存放在sched_domain描述符中的参数和idle值决定调用load_balance的频率。如idle等于SCHED_IDLE,则运行队列为空。rebalance_tick就以很高的频率调load_balance。大概每一到两个节拍处理一次对应于逻辑和物理CPU的调度域。如idle等于NOT_IDLE,rebalance_tick就以很低的频率调度load_balance。大概每10ms处理一次逻辑CPU对应的调度域,每100ms处理一次物理CPU对应的调度域。
load_balance
检查是否调度域处于严重的不平衡状态。它检查是否可通过把最繁忙的组中的一些进程迁移到本地CPU的运行队列来减轻不平衡的状况。如是,函数尝试实现这个迁移。它接收四个参数:
(1). this_cpu
本地CPU的下标
(2). this_rq
本地运行队列的描述符的地址
(3). sd
指向被检查的调度域的描述符
(4). idle
取值为SCHED_IDLE(本地CPU空闲)或NOT_IDLE
函数执行下面的操作:
(1). 获得this_rq->lock
(2). 调find_busiest_group分析调度域中各组的工作量。
函数返回最繁忙组的sched_group描述符的地址,假设这个组不包括本地CPU,此时,函数还返回为了恢复平衡而被迁移到本地运行队列的进程数。另一方面,如最繁忙的组包括本地CPU或所有组本来就是平衡的,函数返回NULL。
(3). 如find_busiest_group在调度域中没找到既不包括本地CPU又非常繁忙的组,就释放this_rq->lock,调整调度域描述符的参数,以延迟本地CPU下一次对load_balance的调度,函数终止。
(4). 调find_busiest_queue以查找2中找到的组中最繁忙的CPU,函数返回相应运行队列的描述符地址busiest。
(5). 获取另一自旋锁,即busiest->lock。为避免死锁,先释放this_rq->lock,通过增加CPU下标获得这两个锁
(6). 调move_tasks,尝试从最繁忙运行队列中把一些进程迁移到本地运行队列this_rq
(7). 如move_tasks没成功。则调度域还是不平衡。把busiest->active_balance置为1,唤醒migration内核线程,它的描述符存在busiest->migration_thread。
Migration顺着调度域的链搜索-从最繁忙运行队列的基本域到最上层域,寻找空闲CPU。如找到,该内核线程就调move_tasks把一个进程迁移到空闲运行队列。
(8). 释放busiest->lock和this_rq->lock
(9). 结束。
move_tasks
把进程从源运行队列迁移到本地运行队列。接收6个参数:
(1). this_rq
(2). this_cpu
(3). busiest
(4). max_nr_move
(5). sd
(6). idle
函数先分析busiest运行队列的过期进程,从优先级高的进程开始,扫描完所有过期进程后,扫描busiest运行队列的活动进程。对所有的候选进程调can_migrate_task。如下列条件都满足,则can_migrate_task返回1:
(1). 进程当前没在远程CPU上执行
(2). 本地CPU包含在进程描述符的cpus_allowed位掩码
(3). 至少满足下列条件之一
(3.1). 本地CPU空闲。如内核支持超线程,则所有本地物理芯片中的逻辑CPU必须空闲。
(3.2). 内核在平衡调度域时因反复进行进程迁移都不成功陷入困境。
(3.3). 被迁移的进程不是”高速缓存命中”的(最近不曾在远程CPU上执行,可设想远程CPU上的硬件高速缓存中没该进程的数据)
如can_migrate_task返回1,move_tasks调pull_task把候选进程迁移到本地运行队列。pull_tasks执行dequeue_task从远程队列删除进程,执行enqueue_task把进程插入本地运行队列。如刚被迁移的进程比当前进程拥有更高的动态优先级,就调resched_task抢占本地CPU的当前进程。
与调度相关的系统调用
nice
允许进程改变它们的基本优先级,负增加下,调capable核实进程是否有CAP_SYS_NICE。且,函数调security_task_setnice安全钩。
getpriority和setpriority
nice只影响调用它的进程,getpriority和setpriority作用于给定组中所有进程的基本优先级。getpriority返回20减去组中所有进程之中最低nice字段的值;setpriority把给定组中所有进程的基本优先级都设置为一个给定的值。内核对这两个系统调用的实现是通过sys_getpriority和sys_setpriority完成的。which :指定进程组的值。
a.
PRIO_PROCESS
根据进程的ID选择进程
b.PRIO_PGRP
根据组ID选择进程
c.PRIO_USER
根据用户ID选择进程
d.who
用pid,pgrp或uid字段的值(取决于which的值)选择进程。
如who是0,把它的值置为current进程相应字段的值。
e.niceval
新的基本优先级值。取值范围在`-20~+19
sched_getaffinity和sched_setaffinity
返回和设置CPU进程亲和力掩码、即允许执行进程的CPU的位掩码。该掩码放在进程描述符的cpus_allowed字段。
与实时进程相关的系统调用
进程为了修改任何进程的描述符的rt_priority和policy,必须具有CAP_SYS_NICE权能。
| 调用 | 说明 |
|---|---|
sched_getscheduler |
查询由pid所表示的进程当前所用的调度策略。如pid等于0,将检索调用进程的策略。如成功,这个系统调用为进程返回策略:SCHED_FIFO,SCHED_RR或SCHED_NORMAL。相应的sys_sched_getscheduler调find_task_by_pid,后一函数确定给pid所对应的进程描述符,并返回其policy字段值。 |
sched_setscheduler |
既设置调度策略,也设置由pid所表示进程的相关参数。如pid等于0,调用进程的调度程序参数将被设置。相应的sys_sched_setscheduler简单地调do_sched_setscheduler。后者检查由policy指定的调度策略和由参数param->sched_priority指定的新优先级是否有效。还检查进程是否有CAP_SYS_NICE。或进程的拥有者是否有超级用户权限。如每个条件都满足,就把进程从它的运行队列中删除;更新进程的静态优先级,实时优先级,动态优先级;把进程插回到运行队列;在需要的情况下,调 resched_task抢占运行队列的当前进程。 |
sched_getparam |
系统调用sched_getparam为pid所表示的进程检索调度参数,如果pid是0,则current进程的参数被检索!正如所期望的,相应的sys_sched_getparam()服务例程找到与pid相关的进程描述指针,把它的rt_priority字段放在了字类型为sched_param的局部变量中,并且调用copy to user把它拷贝到进程地址空间由param参数指定的地址 |
sched_setparam |
这个系统调用类似于sched_setscheduler,它与后者的不同在于不让调用者设置policy字段的值!相应的sys_sched_set_prama服务例程几乎与do_sched_setscheduler相同的参数调用 |
sched_yield |
允许进程在不被挂起的情况下自愿放弃CPU,进程仍处于TASK_RUNNING,但调度程序把它放在运行队列的过期进程集合中,或放在运行队列链表的末尾。随后调schedule。这种方式下,有相同动态优先级的其他进程将有机会运行。 |
sched_get_priority_min |
current是实时进程,则sys_sched_get_priority_min返回1。否则,返回0;如current是实时进程,则sys_sched_get_priority_max返回99,否则,返回0; |
sched_get_priority_max |
current是实时进程,则sys_sched_get_priority_min返回1。否则,返回0;如current是实时进程,则sys_sched_get_priority_max返回99,否则,返回0; |
sched_rr_get_interval |
把参数pid表示的实时进程的轮转时间片写入用户态地址空间的一个结构中。 |
Reference
内存管理
RAM中,剩下的自由部分被称为动态内存!因为这不仅是内进程所需要的宝贵资源,也是内核执行本身所需要的宝贵资源!实际上整个系统的性能都高度取决于如何有效的管理动态内存!因此内存管理是操作系统中非常重要的话题之一!
页框管理
Intel的Pentinum处理器可采用两种不同的页框大小:4KB,4MB(如PAE被激活,则为2MB)。Linux采用4KB页框大小作为标准的内存分配单元。
- 由分页单元引发的缺页异常很容易得到解释,或由于请求的页存在但不允许进程对其访问,或由于请求的页不存在。第二种情况下,内存分配器必须找到一个4KB的空闲页框,并将其分配给进程。
- 虽然
4KB,4MB都是磁盘块大小的倍数,但绝大多数情况下,当主存和磁盘之间传输小块数据时更高效。
页描述符
内核必须记录每个页框当前的状态。内核必须能区分哪些页框包含的是属于进程的页,哪些页框包含的是内核代码或内核数据。类似地,内核还必须能确定动态内存中的页框是否空闲。页框的状态信息保存在一个类型为page的页描述符中,其中的字段如表所示:
| 类型 | 名字 | 说明 |
|---|---|---|
| unsigned long | flags | 一组标志。对页框所在的管理区进行编号。 |
| atomic_t | _count | 页框的引用计数器 |
| atomic_t | _mapcount | 页框中的页表项数量(没有则为-1) |
| unsigned long | private | 可用于正使用页的内核成分 |
| struct address_space* | mapping | 当页被插入页高速缓存时使用。或当页属于匿名区时使用。 |
| unsigned long | index | 作为不同的含义被几种内核成分使用。 |
| struct list_head | lru | 包含页的最近最少使用双向链表的指针 |
所有的页描述符存放在mem_map数组中。mem_map所需要的空间略小于整个RAM的1%。
virt_to_page(addr)宏产生线性地址addr对应的页描述符地址。pfn_to_page(pfn)宏产生与页框号pfn对应的页描述符地址。
上述转换可行是因为内核知道页描述符数组起始线性地址,通过线性地址得到物理地址,通过物理地址得到页框在数组索引。进而定位到页描述符地址。
让我们较详细地描述以下两个字段:
_count:页的引用计数器。如字段为-1,则相应页框空闲,并可被分配给任一进程或内核本身。如该字段值大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放一些内核数据结构。page_count返回__count加1后的值,即该页的使用者的数目。flags:包含多达32个用来描述页框状态的标志。对每个PG_xyz标志,内核都定义了操纵其值的一些宏。通常,PageXyz宏返回标志的值,SetPageXyz和ClearPageXyz宏分别设置和清除相应的位。
下表正是常见的页框状态的标签:可以一览:
| 标志名 | 含义 |
|---|---|
| PG_locked | 页被锁住。如,在磁盘I/O操作中涉及的页 |
| PG_error | 在传输页时发生I/O错误 |
| PG_referenced | 刚刚访问过的页 |
| PG_uptodate | 在完成读操作后置位,除非发生磁盘I/O错误 |
| PG_dirty | 页已经被修改 |
| PG_lru | 页在活动或非活动页链表中 |
| PG_active | 页在活动页链表中 |
| PG_highmem | 页框属于ZONE_HIGHMEM管理区 |
| PG_checked | 由一些文件系统使用的标志 |
| PG_arch_1 | 在80x86体系结构上没有使用 |
| PG_reserved | 页框留给内核代码或没有使用 |
| PG_private | 页描述符的private字段存放了有意义的数据 |
| PG_writeback | 正使用writeback方法将页写到磁盘上 |
| PG_nosave | 系统挂起、唤醒时使用 |
| PG_compound | 通过扩展分页机制处理页框 |
| PG_swapcache | 页属于对换高速缓存 |
| PG_mappedtodisk | 页框中的所有数据对应于磁盘上分配的块 |
| PG_reclaim | 为回收内存对页已经做了写入磁盘的标记 |
| PG_nosave_free | 系统挂起、恢复时使用 |
UMA和NUMA
习惯上,认为计算机内存是一种均匀,共享的资源。在忽略硬件高速缓存作用的情况下,期望不管内存单元处于何处,CPU处于何处,CPU对内存单元的访问都需相同的时间(UMA)。可惜,这些假设在某些体系结构上并不总是成立。如,对某些多处理器Alpha或MIPS计算机,就不成立。Linux2.6支持非一致内存访问模型,在这种模型中,给定CPU对不同内存单元的访问时间可能不一样。系统的物理内存被划分为几个节点(node)。节点既封装了内存资源,也封装了CPU资源。在一个单独的节点内,任一给定CPU访问页面所需的时间都是相同的。然而, 对不同CPU,这个时间可能就不同。这就是NUMA的特性!
对每个CPU而言,内核都试图把耗时节点的访问次数减到最少,这就要小心地选择CPU最常引用的内核数据结构的存放位置。每个节点中的物理内存又可分为几个管理区。每个节点都有一个类型为pg_data_t的描述符。
| 类型 | 名字 | 说明 |
|---|---|---|
| struct zone[] | node_zones | 节点中管理区描述符的数组 |
| struct zonelist[] | node_zonelists | 页分配器使用的zonelist数据结构的数组 |
| int | nr_zones | 节点中管理区的个数 |
| struct page* | node_mem_map | 节点中页描述符的数组 |
| struct bootmem_data* | bdata | 用在内核初始化阶段 |
| unsigned long | node_start_pfn | 节点中第一个页框的下标 |
| unsigned long | node_present_pages | 内存节点的大小,不包含洞(以页框为单位) |
| unsigned long | node_spanned_pages | 节点的大小,包括洞(以页框为单位) |
| int | node_id | 节点标识符 |
| pg_data_t* | pgdat_next | 节点内存链表中的下一项 |
| wait_queue_head_t | kswapd_wait | kswapd页换出守护进程使用的等待队列 |
| struct task_struct* | kswapd | 指针指向kswapd内核线程的进程描述符 |
| int | kswapd_max_order | kswapd将要创建的空闲块大小取对数的值 |
同样,我们只关注80x86。IBM兼容PC使用一致内存访问模型,因此,并不真正需要NUMA的支持。然而,即使NUMA的支持没有编译进内核,Linux还是使用节点。不过,这是一个单独的节点,它包含了系统中所有的物理内存。此时,pgdat_list指向一个链表,此链表是由一个元素组成的。这个元素就是节点0描述符,它被存放在config_page_data。在80x86结构中,把物理内存分组在一个单独的节点中可能显得没用处;但这种方式有助于内核代码的处理具有可移植性。
内存管理区
在一个理想的计算机体系结构中,一个页框就是一个内存存储单元,可用于任何事情:存放内核数据和用户数据,缓冲磁盘数据等等。任何种类的数据页都可存放在任何页框中。但实际的计算机体系结构有硬件的制约,这限制了页框可使用的方式。尤其是,Linux内核必须处理80x86体系结构的两种硬件约束:
ISA总线的直接内存存取(DMA)处理器有一个严格的限制:它们只能对RAM的前16MB寻址、- 在具有大容量
RAM的现代32位计算机中,CPU不能直接访问所有的物理内存,因为线性地址空间太小。
为应对这两种限制,Linux2.6把每个内存节点的物理内存划分为三个管理区。在80x86UMA体系结构中的管理区为:
ZONE_DMA:包含低于16MB的内存页框ZONE_NORMAL:包含高于16MB且低于896MB的内存页框ZONE_HIGHMEM:包含从896MB开始高于896MB的内存页框
ZONE_DMA区包含的页框可由老式基于ISA的设备通过DMA使用。ZONE_DMA和ZONE_NORMAL区包含内存的”常规”页框,通过把它们直接映射到线性地址空间的第4个GB,内核就可直接进行访问。相反,ZONE_HIGHMEM区包含的内存页不能由内核直接访问,尽管它们页线性地映射到了线性地址空间的第4个GB。在64位体系结构上,ZONE_HIGHMEM区总是空的。
每个内存管理区都有自己的描述符。
| 类型 | 名称 | 说明 |
|---|---|---|
| unsigned long | free_pages | 管理区中空闲页的数目 |
| unsigned long | pages_min | 管理区中保留页的数目 |
| unsigned long | pages_low | 回收页框使用的下界;同时也被管理区分配器作为阀值使用 |
| unsigned long | pages_high | 回收页框使用的上届;同时也被管理区分配器作为阀值使用 |
| unsigned long[] | lowmem_reserve | 指明在处理内存不足的临界情况下每个管理区必须保留的页框数目 |
| struct per_cpu_pageset[] | pageset | 用于实现单一页框的特殊高速缓存 |
| spinlock_t | lock | 保护该描述符的自旋锁 |
| struct free_area[] | free_area | 标识出管理区的空闲页框块 |
| spinlock_t | lru_lock | 活动以及非活动链表使用的自旋锁 |
| struct list_head | active_list | 管理区中的活动页链表 |
| struct list_head | inactive_list | 管理区中的非活动页链表 |
| unsigned long | nr_scan_active | 回收内存时需扫描的活动页数目 |
| unsigned long | nr_scan_inactive | 回收内存时需扫描的非活动页数目 |
| unsigned long | nr_active | 管理区的活动链表上的页数目 |
| unsigned long | nr_inactive | 管理区的非活动链表上的页数目 |
| unsigned long | pages_scanned | 管理区内回收页框时使用的计数器 |
| int | all_unreclaimable | 在管理区中填满不可回收页时此标志被置位 |
| int | temp_priority | 临时管理区的优先级 |
| int | prev_priority | 管理区优先级,范围在12和0之间 |
| wait_queue_head_t* | wait_table | 进等待队列的散列表,这些进程正在等待管理区中的某页 |
| unsigned long | wait_table_size | 等待队列散列表的大小 |
| unsigned long | wait_table_bits | 等待队列散列表数组大小,值为2^order |
| struct pglist_data* | zone_pgdat | 内存节点 |
| struct page* | zone_mem_map | 指向管理区的第一个页描述符的指针 |
| unsigned long | zone_start_pfn | 管理区第一个页框的下标 |
| unsigned long | spanned_pages | 以页为单位的管理区的总大小,包括洞 |
| unsigned long | present_pages | 以页为单位的管理区的总大小,不包括洞 |
| char* | name | 指针指向管理区的传统名称:“DMA”,“NORMAL”,“HighMem” |
每个页描述符都有到内存节点和节点内管理区的链接。为节省空间,这些链接被编码成索引存放在flags字段的高位。实际上,刻画页框的标志的数目是有限的。保留flags字段的最高位来编码特定内存节点和管理区号总是可能的。page_zone接收一个页描述符的地址作为它的参数,它读取页描述符中flags字段的最高位,然后通过查看zone_table数组来确定相应管理区描述符的地址。在启动时用所有内存节点的所有管理区描述符的地址初始化这个数组。
当内核调一个内存分配函数时,必须指明请求页框所在的管理区。内核通常指明它愿意使用哪个管理区。为了在内存分配请求中指定首选管理区,内核使用zonelist数据结构,这就是管理区描述符指针数组。
保留的页框池
可用两种不同的方法来满足内存分配请求。如有足够的空闲内存可用,请求就会被立刻满足。否则,必须回收一些内存,且将发出请求的内核控制路径阻塞,直到内存被释放。(NUMA下默认策略是本地节点内内存不足,从本地节点回收内存后再次尝试分配。若选择本地节点内存不足时,优先查看其他节点是否存在足量内存时,若存在从其他节点完成剩余部分分配的方案,在应用需要大内存场景下可能更高效)
当请求内存时,一些内核控制路径不能被阻塞。比如,这种情况发生在处理中断或执行临界区内的代码时。此时,一条内核控制路径应产生原子内存分配请求。原子请求从不被阻塞:如没有足够的空闲页,则仅仅是分配失败而已。尽管无法保证一个原子内存分配请求决不失败,但内核会设法尽量减少这种不幸事件发生的可能性。为做到这一点,内核为原子内存分配请求保留了一个页框池,只有在内存不足时才使用。
保留内存的数量(以KB为单位)存放在min_free_kbytes中。它的初始值在内核初始化时设置,并取决于直接映射到内核线性地址空间的第4个GB的物理内存的数量。即,取决于包含在ZONE_DMA和ZONE_NORMAL内存管理区内的页框数目。这是其公式:
但min_free_kbytes的初始值不能小于128也不能大于65536。
ZONE_DMA和ZONE_NORMAL内存管理区将一定数量的页框贡献给保留内存,这个数目与两个管理区的相对大小成比例。
例,如ZONE_NORMAL管理区比ZONE_DMA大8倍,则页框的7/8从ZONE_NORMAL获得。1/8从ZONE_DMA获得。
管理区描述符的pages_min存储了管理区内保留页框的数目。这个字段和pages_low,pages_high一起还在页框回收算法中起作用。pages_low总是设为pages_min的值的5/4,pages_high总是被设为pages_min的3/2。
分区页框分配器
分区页框分配器被称作分区页框分配器的内核子系统,处理对连续页框组的内存分配请求。它的主要组成如下:
管理区分配器下分给ZONE_DMA内存管理区,ZONE_NORMAL内存管理区,ZONE_HIGHMEM内存管理区。为了更加很合适的分配内存,每一个个管理区又有伙伴系统和Per-CPU页框高速缓存
其中,名为”管理区分配器”部分接受动态内存分配和释放的请求。在请求分配的情况下,该部分搜索一个能满足所请求的一组连续页框内存的管理区。在每个管理区内,页框被名为”伙伴系统”的部分来处理。为达到更好的系统性能,一小部分页框保留在高速缓存中用于快速地满足对单个页框的分配请求。
请求和释放页框
| API | 说明 | |
|---|---|---|
| alloc_pages(gfp_mask, order) | 用这个函数请求2^order个连续的页框。它返回第一个所分配页框描述符的地址,或,如分配失败,则返回NULL。 |
|
| alloc_page(gfp_mask) | 用于获得一个单独页框的宏;扩展为:alloc_pages(gfp_mask, 0)。 |
|
| __get_free_pages(gfp_mask, order) | 类似alloc_pages,返回第一个所分配页的线性地址。 |
|
| __get_free_page(gfp_mask) | 用于获得一个单独页框的宏;扩展为:__get_free_pages(gfp_mask, 0) | |
| get_zeroed_page(gfp_mask) | 获取填满0的页框;它调用:`alloc_pages(gfp_mask | __GFP_ZERO, 0);` |
| __get_dma_pages(gfp_mask, order) | 获得适用于DMA的页框,它扩展为:`__get_free_pages(gfp_mask | __GFP_DMA, order);` |
参数gfp_mask是一组标志,指明了如何寻找空闲的页框。能在gfp_mask中使用的标志如下:
| 标志 | 说明 |
|---|---|
| __GFP_DMA | 所请求的页框必须处于ZONE_DMA管理区。等价于GFP_DMA |
| __GFP_HIGHMEM | 所请求的页框处于ZONE_HIGHMEM管理区。 |
| __GFP_WAIT | 允许内核对等待空闲页框的当前进程进行阻塞 |
| __GFP_HIGH | 允许内核访问保留的页框池 |
| __GFP_IO | 允许内核在低端内存页上执行I/O传输以释放页框 |
| __GFP_FS | 如清0,则不允许内核执行依赖文件系统的操作 |
| __GFP_COLD | 所请求的页框可能为”冷的” |
| __GFP_NOWARN | 一次内存分配失败将不会产生警告信息 |
| __GFP_REPEAT | 内核重试内存分配直到成功 |
| __GFP_NOFAIL | 与__GFP_REPEAT相同 |
| __GFP_NORETRY | 一次内存分配失败后不再重试 |
| __GFP_NO_GROW | slab分配器不允许增大slab高速缓存 |
| __GFP_COMP | 属于扩展页的页框 |
| __GFP_ZERO | 任何返回的页框必须被填满0 |
实际上,Linux使用预定义标志值的组合。
| 组名 | 相应标志 |
|---|---|
| GFP_ATOMIC | __GFP_HIGH |
| GFP_NOIO | __GFP_WAIT |
| GFP_NOFS | __GFP_WAIT |
| GFP_KERNEL | __GFP_WAIT |
| GFP_USER | __GFP_WAIT |
| GFP_HIGHUSER | __GFP_WAIT |
__GFP_DMA和__GFP_HIGHMEM被称作管理区修饰符;它们标示寻找空闲页框时内核所搜索的管理区。contig_page_data节点描述符的node_zonelists是一个管理区描述符链表的数组,它代表后备管理区:对管理区修饰符的每一个设置,相应的链表包含的内存管理区能在原来的管理区缺少页框的情况下被用于满足内存分配请求。在80x86 UMA体系结构中,后备管理区如下:
- 如
__GFP_DMA被置位,则只能从ZONE_DMA内存管理区获取页框 - 如
__GFP_HIGHMEM没被置位,按优先次序从ZONE_NORMAL,ZONE_DMA内存管理区获取页框 __GFP_HIGHMEM被置位,按优先次序从ZONE_HIGHMEM,ZONE_NORMAL,ZONE_DMA内存管理区获取页框
释放页框
下面4个函数和宏中的任一个都可释放页框
| API | 说明 |
|---|---|
| __free_pages(page, order) | 先检查page指向的页描述符;如该页框未被保留,就把描述符的count字段减1。如count变为0,就假定从与page对应的页框开始的2^order个连续页框不再被使用。此时,函数释放页框。 |
| free_pages(addr, order) | 类似于__free_pages(page, order),它接收的参数为要释放的第一个页框的线性地址addr |
| __free_page(page) | 释放page所指描述符对应的页框;扩展为:__free_pages(page, 0) |
| free_page(addr) | 释放线性地址为addr的页框;扩展为:free_pages(addr, 0) |
高端内存页框的内核映射
与直接映射的物理内存末端,高端内存的始端所对应的线性地址存放在high_memory变量。被设置为896MB。896MB边界以上的页框并不会采用直接映射方式对应到内核线性地址空间的第4个GB中相应位置,因此,内核不能直接访问它们。意味着,返回所分配页框线性地址的页分配器函数不适用于高端内存。即不适用于ZONE_HIGHMEM内存管理区内的页框。如,假定内核调__get_free_pages(GFP_HIGHMEM, 0)在高端内存分配一个页框,如分配器在高端内存确实分配了一个页框,则__get_free_pages不能返回它的线性地址。依次类推,内核不能使用这个页框;甚至更坏情况下,也不能释放该页框。
在64位硬件平台上不存在这个问题,因为可使用的线性地址空间远大于能按照的RAM大小。简言之,这些体系结构的ZONE_HIGHMEM管理区总是空的。但在32位平台上,如80x86体系结构,Linux设计者不得不找到某种方法来允许内核使用所有可使用的RAM,达到PAE所支持的64GB。
采用的方法如下:
- 高端内存页框的分配只能通过
alloc_pages和它的快捷函数alloc_page。这些函数不返回第一个被分配页框的线性地址,因为如该页框属于高端内存,则这样的线性地址根本不存在。这些函数返回第一个被分配页框的页描述符的线性地址。这些线性地址总是存在的,因为所有页描述符被分配在低端内存,它们在内核初始化阶段完成后就不会改变。 - 没有线性地址的高端内存中的页框不能被内核访问。故,内核线性地址空间的最后
128MB中的一部分专门用于映射高端内存页框。这种映射是暂时的。通过重复使用线性地址,使得整个高端内存能在不同的时间被访问。
内核可采用三种不同的机制将页框映射到高端内存(线性地址):分别叫永久内核映射,临时内核映射,非连续内存分配。
建立永久内核映射可能阻塞当前进程;这发生在空闲页表项不存在时,即在高端内存上没有页表项可用作页框的”窗口”时。永久内核映射不能用于中断处理程序和可延迟函数。
建立临时内核映射不会要求阻塞当前进程;它的缺点是只有很少的临时内核映射可同时建立起来。使用临时内核映射的内核控制路径必须保证当前没其他的内核控制路径在使用同样的映射。意味着内核控制路径永不能被阻塞,否则其他内核控制路径很可能使用同一个窗口来映射其他的高端内存页。永久内核映射在64位体系下高端内存区不存在,自然也无永久内核映射
永久内核映射允许内核建立高端页框到内核地址空间(线性地址)的长期映射。它们使用主内核页表中一个专门的页表。地址存放在pkmap_page_table。页表中的表项数由LAST_PKMAP宏产生。页表照样含512或1024项,这取决于PAE是否被激活;因此,内核一次最多访问2MB或4MB的高端内存。该页表映射的线性地址从PKMAP_BASE开始。pkmap_count数组包含LAST_PKMAP个计数器,pkmap_page_table页表中的每一项都有一个。
- 计数器为0:对应的页表项没映射任何高端内存页框,且是可用的
- 计数器为1:对应的页表项没映射任何高端内存页框,但它不能使用,因为自从它最后一次使用以来,其相应的TLB表项还未被刷新。
- 计数器为n:相应的页表项映射一个高端内存页框,意味着正好有n-1个内核成分在使用这个页框。
为记录高端内存页框与永久内核映射包含的线性地址之间的关系,内核使用了page_address_htable散列表。该表包含一个page_address_map数据结构,用于为高端内存中的每一页框进行当前映射,该数据结构还包含一个指向页描述符的指针和分配给该页框的线性地址。
page_address–传入页框描述符线性地址,返回对应页框的线性地址
page_address返回页框(物理地址)对应的线性地址,如页框在高端内存(线性地址)中且没被映射,则返回NULL。这个函数接受一个页描述符指针page(描述一个页框)作为参数,区分以下两种情况:
(1).如页框不在高端内存(PG_highmem为0),则采用直接映射。则线性地址总是存在且是通过计算页框下标,然后将其转换成物理地址,最后根据相应的物理地址得到线性地址。
(2).如页框在高端内存(PG_highmem为1),该函数就到page_address_htable散列表中查找。如在散列表中找到页框,page_address就返回它的线性地址,否则返回NULL。kmap–建立永久内核映射。
void* kmap(struct page* page)
{
if(!PageHighMem(page))
return page_address(page);
return kmap_high(page); // 如页框确实属于高端内存,则调kmap_high
}void *kamp_high(struct page* page)
{
unsigned long vaddr;
spin_lock(&kmap_lock);// 永久内核映射对所有处理器可见。防止多核并发,需加锁保护。
vaddr = (unsigned long)page_address(page);// 查找哈希表
if(!vaddr)
vaddr = map_new_virtual(page);// 向哈希表插入,并返回线性地址
pkmap_count[(vaddr-PKMAP_BASE) >> PAGE_SHIFT]++;// 通过线性地址找到索引
spin_unlock(&kmap_lock);
return (void*)vaddr;
}中断处理程序和可延迟函数不能调kmap。kmap_high通过调page_address检查页框是否已经被映射。如不是,调map_new_virtual把页框的物理地址插入到pkmap_page_table的一个项,并在page_address_htable中加入一个元素。然后,kmap_high使页框的线性地址所对应的计数器加1来将调用该函数的新内核成分考虑在内。最后,kmap_high释放kmap_lock并返回对该页框进行映射的线性地址。
- map_new_virtual–完成页表注册,完成哈希表注册
本质上执行两个嵌套循环:
for(;;)
{
int count;
DECLARE_WAITQUEUE(wait, current);
for(count = LAST_PKMAP; count > 0; --count)// 遍历所有表项
{
last_pkmap_nr = (last_pkmap_nr+1)&(LAST_PKMAP-1);
// 后半部分搜索没找到可用表项时。先刷新,再从开始位置再搜索一遍
if(!last_pkmap_nr)
{
flush_all_zero_pkmaps();// 将使用者不存在的槽位清理腾出多余位置
count = LAST_PKMAP;
}
// 找到可用槽位
if(!pkmap_count[last_pkmap_nr])
{
unsigned long vaddr = PKMAP_BASE+(last_pkmap_nr<<PAGE_SHIFT);// 计算此位置对应线性地址
set_pte(&(pkmap_page_table[last_pkmap_nr]), mk_pte(page/*页框物理地址*/, __pgprot(0x63)));// 设置页表。完成页表注册。
pkmap_count[last_pkmap_nr] = 1;// 表示页表映射建立了。但此页表项映射的页框并没有使用者。
set_page_address(page, (void*)vaddr);// 哈希表注册
return vaddr;// 返回线性地址
}
}
// 执行到这里,表示后半部分没搜索到可用表项,且刷新从头搜依然没搜到
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue(&pkmap_map_wait, &wait);// 向完成队列加入新的等待项
spin_unlock(&kmap_lock);// 放弃cpu之前先释放锁。
schedule();// 主动放弃cpu,让内核选择另一进程运行。
// 走到这里,一定是其他进程腾出表项后,发现有人在等待空闲表项。所以,让等待者变为就绪,将进程重新加入cpu的可调度队列。
// 某次调度,等待者被调度恢复后继续执行这里
remove_wait_queue(&pkmap_map_wait, &wait);// 将自己从等待队列移除
spin_lock(&kmap_lock);// 重新加锁
if(page_address(page)) // 再次尝试页表注册,哈希表注册前,先检查,是否其他内核线程已经完成了注册工作。
return (unsigned long)page_address(page);// 其他内核线程已经完成注册后,可以直接返回。
} 内循环中,函数扫描pkmap_count中所有计数器直到找到一个空值。当在pkmap_count中找到一个未使用项时,大的if代码块运行。这段代码确定该项对应的线性地址,为它在pkmap_page_table页表中创建一个项,将count置1,调set_page_address插入一个新元素到page_address_htable散列表,返回线性地址。
搜索从上次因调map_new_virtual而跳出的地方开始。在pkmap_count中搜索完最后一个计数器尚未找到空闲槽位时,又从下标为0计数器开始搜索。继续之前,map_new_virtual调flush_all_zero_pkmaps开始寻址计数器为1的另一趟扫描。每个值为1的计数器都表示在pkmap_page_table中表项是空闲的,但不能使用,因为相应的TLB表项还没被刷新。flush_all_zero_pkmaps把它们的计数器重置为0,删除page_address_htable散列表中对应的元素,并对pkmap_page_table里的所有项上进行TLB刷新。
如内循环在pkmap_count中没找到空的计数器,map_new_virtual就阻塞当前进程,直到某个进程释放了pkmap_page_table页表中的一个表项,通过把current插入到pkmap_map_wait等待队列,把current设置为TASK_UNINTERRUPTIBLE,并调schedule放弃CPU来达到此目的。一旦进程被唤醒,函数就调page_address检查是否存在另一个进程已映射了该页。如还没其他进程映射该页,则内循环重新开始。
- kunmap撤销先前由kmap建立的永久内核映射。如页确实在高端内存中,则调kunmap_high。
void kunmap_high(struct page* page)
{
spin_lock(&kmap_lock);
// 这是检测此高端内存内页框释放后,此页框占据的页表表项是否没了使用者,进而可被清理后复用(用来服务于另一个页框)
if((--pkmap_count[((unsigned long)page_address(page)-PKMAP_BASE)>>PAGE_SHIFT]) == 1)
{
if(waitqueue_active(&pkmap_map_wait))// 检测等待队列上是否有等待对象
wake_up(&pkmap_map_wait);//唤醒首个等待对象
spin_unlock(&kmap_lock);
}
} 上述括号内的表达式从页的线性地址计算出pkmap_count数组的索引。计数器被减1并与1相比。匹配成功表明没进程在使用页了。函数最终能唤醒由map_new_virtual添加在等待队列中的进程。
在高端内存的任一页框都可通过一个”窗口”映射到内核地址空间。留给临时内核映射的窗口数是非常少的。
每个CPU有它自己的包含13个窗口的集合,它们用enum km_type数据结构表示。该数据结构中定义的每个符号,如KM_BOUNCE_READ,KM_USER0或KM_PTE0,标识了窗口的线性地址。内核必须确保同一窗口永不会被两个不同的控制路径同时使用。故,km_type中的每个符号只能由一种内核成分使用,并以该成分命名。最后一个符号KM_TYPE_NR本身并不表示一个线性地址,但由每个CPU用来产生不同的可用窗口数。
在km_type中的每个符号(除了最后一个)都是固定映射的线性地址的一个下标。enum fixed_address数据结构包含符号FIX_KMAP_BEGIN和FIX_KMAP_END;把后者的值赋成下标FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1。这种方式下,系统中的每个CPU都有KM_TYPE_NR个固定映射的线性地址。此外,内核用fix_to_virt(FIX_KMAP_BEGIN)线性地址对应的页表项的地址初始化kmap_pte变量。
1.kmap_atomic–建立临时内核映射。
void* kmap_atomic(struct page* page, enum km_type type)
{
enum fixed_address idx;
unsigned long vaddr;
current_thread_info()->preempt_count++;// 这样就禁止了内核抢占
if(!PageHighMem(page))
return page_address(page);
idx = type + KM_TYPE_NR * smp_processor_id();// 取得正确索引
vaddr = fix_to_virt(FIX_KMAP_BEGIN+idx);// 取得对应线性地址
set_pte(kmap_pte-idx/* pte表项地址 */, mk_pte(page/* 页框描述符线性地址 */, 0x63));// 页表注册
__flush_tlb_single(vaddr);// TLB刷新
return (void*)vaddr;
}type参数和CPU标识符指定必须用哪个固定映射的线性地址映射请求页。如页框不属于高端内存,则该函数返回页框的线性地址;否则,用页的物理地址及Present,Accessed,Read/Write和Dirty位建立该固定映射的线性地址对应的页表项。最后,该函数刷新适当的TLB项并返回线性地址。
2.kunmap_atomic–撤销临时内核映射。
在80x86结构中,这个函数减少当前进程的preempt_count。因此,如在请求临时内核映射之前能抢占内核控制路径, 则在同一个映射被撤销后可再次抢占。此外,kunmap_atomic检查当前进程的TIF_NEED_RESCHED标志是否被置位。如是,就调schedule。
伙伴系统算法
内核应为分配一组连续的页框建立一种健壮,高效的分配策略。频繁地请求和释放不同大小的一组连续页框,必然导致在已分配页框的块内分散了许多小块的空闲页框。
本质上,避免外碎片的方法有两种:
- 利用分页单元把一组非连续的空闲页框映射到连续的线性地址区间。
- 开发一种适当的技术来记录现存的空闲连续页框块的情况,以尽量避免为满足对小块的请求而分割大的空闲块。
基于以下三种原因,内核首选第二种方法:
- 某些情况下,连续的页框确实是必要的。因为仅连续的线性地址不足以满足请求。典型例子就是给DMA处理器分配缓存区的内存请求。因为当在一次单独的I/O操作中传送几个磁盘扇区的数据时,DMA忽略分页机制而直接访问地址总线(直接采用物理地址),故,所请求的缓冲区必须位于连续的页框中。
- 即使连续页框的分配并不是很必要,但它在保持内核页表不变方面所起的作用也不容忽视。在内核页表中,只需要为这些连续的页框创建一个条目,而不是为每个页框创建一个单独的条目。这可以减少内核页表的大小,并降低内存管理的开销。在查找页表时,操作系统只需要查找一个条目,而不是多个条目。操作系统只需要查找一个页表条目,就可以确定该虚拟地址对应的物理地址。连续页框的分配可以使得内存块更加连续和紧凑。这有助于提高内存利用率,因为操作系统可以更有效地管理和调度内存。修改页表会怎样?频繁修改页表势必导致平均访问内存次数增加,因为这会使CPU频繁刷新TLB(TLB不命中率提高)的内容。
- 内核通过4MB的页可访问大块连续的物理内存。这样减少了TLB失效率(TLB命中率提高),提高了访问内存的平均速度。
Linux采用著名的伙伴系统算法来解决外碎片。它把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512,1024个连续的页框的块的集合。对1024个页框的最大请求对应着4MB大小的连续RAM块。伙伴系统保证每个块的第一个页框的物理地址是该块大小的整数倍。例如,大小为16个页框的块,其起始地址是$16 \times 2^{12}$的倍数
通过举例来说明算法的工作原理:连续页框块申请–假设申请256个连续页框
- 先在256个页框的链表中检查是否有一个空闲块。如存在,分配此块。
- 如没有,算法会查找下一个更大的页块。即在512个页框的链表中找一个空闲块。
如存在,内核把空闲块分为两部分。一半用作满足请求。另一半作为新块插入到256个页框的链表。 - 如在512个页框的块链表没找到空闲块,就继续在1024找。
如找到,内核把1024个页框块的划分为一个256个页框的块用于满足需求。剩余部分划分为一个256页框的新快,一个512页框的新快分别插入对应的链表。 - 如1024页框链表还没找到,算法就放弃并发出错误信号。(意味着连续页框分配最大只能一次分配4MB内存)、
连续页框块释放:
连续页框块释放时,内核会检查释放块是否可以现有空闲块合并成更大的空闲块。允许合并时,将参与合并的空闲块从链表移除,组成一个新块。对新的块持续如此迭代,直到迭代到无法合并时,块加入链表。
合并成立条件:
- 两个块有相同的大小,记作
b。 - 它们的物理地址是连续的。
- 第一个块的第一个页框的物理地址是$2 \times b \times 2^{12}$的倍数。
1.数据结构
Linux 2.6为每个管理区使用不同的伙伴系统。因此,在80x86结构中,有三种伙伴系统:
- 第一种处理适合
ISA DMA的页框。 - 第二种处理”常规”页框。
- 第三种处理高端内存页框。
每个伙伴系统使用的主要数据结构如下:
- 前面介绍过的
mem_map数组。实际上,每个管理区都关系到mem_map元素的子集。子集中的第一个元素和元素的个数分别由管理区描述符的zone_mem_map和size字段指定。 - 包含有
11个元素,元素类型为free_area的一个数组,每个元素对应一种特定块大小的链表。该数组存放在管理区描述符的free_area字段中。
考虑管理区描述符中free_area数组的第k个元素,它标识所有大小为$2^k$个页框的空闲块。这个元素的free_list字段是双向循环链表的头,这个双向循环链表集中了大小为$2^k$个页框的空闲块对应的页描述符。更精确地说,是空闲块中起始页框的页描述符;指向链表中相邻元素的指针存放在页描述符的lru字段中。除了链表头外,free_area数组的第k个元素同样包含字段nr_free,它指定了大小为$2^k$个页框的空闲块的个数。如没大小为$2^k$个页框的空闲块,则nr_free等于0且free_list为空。
一个大小为$2^k$个页框的空闲块的第一个页框的描述符的private字段存放了块的order,即k。正是由于此字段,页块被释放时,内核可确定这个块的伙伴是否也空闲。如是,它可以把两个块结合成大小为$2^{k + 1}$页框的新块。
2.分配块
__rmqueue–用来在管理区找到一个空闲块
- 参数:管理区描述符地址,
order。order表示请求的空闲页块大小的对数值。 - 返回值:如页框被成功分配,
__rmqueue就返回第一个被分配页框的页描述符。否则, 返回NULL。
__rmqueue假设调用者已经禁止了本地中断,并获得了保护伙伴系统数据结构的zone->lock自旋锁。
从所请求order的链表开始,它扫描每个可用块链表进行循环搜索,如需要搜索更大的order,就继续搜索。
struct free_area* area;
unsigned int current_order;
for(current_order = order; current_order < 11; ++current_order)
{
area = zone->free_area + current_order;
if(!list_empty(&area->free_list))
goto block_found;
}
return NULL; 如直到循环结束还没找到合适的空闲块,则__rmqueue就返回NULL。否则,找到了一个合适的空闲块,这种情况下,从链表中删除它的第一个页框描述符,并减少管理区描述符中的free_pages的值。
block_found:
// 1.定位到链表首个有效元素
// 2.链表首个有效元素是一个struct page对象的lru字段。
// 3.从lru字段地址导出隶属的struct page对象起始地址
page = list_entry(area->free_list.next, struct page, lru);
// 从隶属的双向链表中移除该节点
list_del(&page->lru);
// 清理page的private字段
ClearPagePrivate(page);
// 暂时被设置为0
page->private = 0;
// 更新有效块数
area->nr_free--;
// 更新隶属管理区内空闲页框数
zone->free_pages -= 1UL << order; 当为了满足$2^h$个页框的请求而有必要使用$2^k$个页框的块时(h<k),
程序就分配前面的$2^h$个页框,把后面$2^k - 2^h$个页框循环再分配给free_area链表中下标在h到k之间的元素:
// 这是获得得到块尺寸
size = 1 << curr_order;
while(curr_order > order)
{
// 规模小一级空闲块
area--;
// 规模
curr_order--;
// 页数
size >>= 1;
// page是分配出去的块的首个页框。page+size得到剩余可放入当前规模块链表的起始页框
buddy = page + size;
// 将该页框放入当前规模块链表
list_add(&buddy->lru, &area->free_list);
// 规模块中可用块数量更新
area->nr_free++;
// 设置该page的private以记录其隶属的块的规模
buddy->private = curr_order;
// 设置page的标志。来表示其private字段有效。
SetPagePrivate(buddy);
}
return page;// 被分配出去的块的首个page的private字段无效因为__rmqueue已经找到了合适的空闲块,所以它返回所分配的第一个页框对应的页描述符的地址page。
上述分配过程看,每次分配页框会被规整到2的幂次后再执行页框分配(造成分配时内部碎片,牺牲容量,换取性能优化)。
3.释放块
__free_pages_bulk–按伙伴系统的策略释放页框
参数:
- page:被释放块中所包含的第一个页框描述符的地址
- zone:管理区描述符的地址
- order:块大小的对数
函数假设调用者已禁止本地中断(防止外部中断打断执行流程)并获得了保护伙伴系统数据结构的zone->lock(防止其他处理器打断执行流程)自旋锁。__free_pages_bulk先声明和初始化一些局部变量:
struct page* base = zone->zone_mem_map;
unsigned long buddy_idx, page_idx = page - base;
struct page* buddy, *coalesced;
int order_size = 1 << order;// 页数page_idx包含块中第一个页框的下标,这是相对于管理区中第一个页框而言的。order_size用于增加管理区中空闲页框的计数器:
zone->free_pages += order_size;现在函数开始执行循环,最多循环(10-order)次,每次都尽量把一个块和它的伙伴进行合并。函数以最小块开始,然后向上移动到顶部:
while(order < 10)
{
// order是当前规模
// 这里的意思是将page_idx的二进制下第order位取反。
// 若此位之前是1,buddy_idx此位是0。这样取得前一个buddy。因为只有前一个buddy才能作为合并后buddy的起始部分。对齐要求。
// 若此位之前是0,buddy_idx此位是1。这样取得后一个buddy。此时只有自己才能作为合并后buddy的起始部分。对齐要求。
buddy_idx = page_idx ^ (1 << order);
buddy = base + buddy_idx;
// 验证此page是否符合作为规模为order的buddy块首个page的条件
if(!page_is_buddy(buddy, order))
break;
list_del(&buddy->lru);// 将此buddy块从隶属的双向链表移除
zone->free_area[order].nr_free--;// 更新本来隶属的规模中可有块数量
// 清理此块首个page的private
ClearPagePrivate(buddy);
buddy->private = 0;
// 确定合并块的首个page的索引。
// page_idx的二进制下第order位
// 若此位之前是1,buddy_idx此位是0。
// 这样合并后块内首个page索引,取buddy_idx
// 若此位之前是0,buddy_idx此位是1。
// 这样合并后块内首个page索引,取page_idx
// page_idx &= buddy_idx得到的结果其余位和page_idx一致。但第order位固定为0。符合上述要求。
page_idx &= buddy_idx;
// 这样我们得到了规模为order+1的块及块内首个page。继续迭代。
order++;
}在循环体内,函数寻找块的下标buddy_idx,它是拥有page_idx页描述符下标的块的伙伴。结果这个下标可被简单地如下计算:
buddy_idx = page_idx ^ (1 << order);实际上,使用(1<<order)掩码的异或转换page_idx第order位的值。
因此,如这个位原先是0,buddy_idx就等于page_idx+order_size;如这个位原先是1,buddy_idx就等于page_idx - order_size。
一旦知道了伙伴块下标,就可通过下式很容易获得伙伴块的页描述符:
buddy = base + buddy_idx;现在调page_is_buddy来检查buddy是否描述了大小为order_size的空闲页框块的第一个页。
int page_is_buddy(struct page* page, int order)
{
if(PagePrivate(buddy) && page->private == order && !PageReserved(buddy) && page_count(page) == 0)
return 1;
return 0;
}buddy的第一个页必须为空闲(_count等于-1),它必须属于动态内存,它的private字段必须有意义,最后private字段必须存放将要被释放的块的order。如所有这些条件都符合,伙伴块就被释放,且函数将它从以order排序的空闲块链表上删除,并再执行一次循环以寻找两倍大小的伙伴块。如page_is_buddy中至少有一个条件没被满足,则该函数跳出循环,因为获得的空闲块不能再和其他空闲块合并。函数将它插入适当的链表并以块大小的order更新第一个页框的private。
// 得到最终合并块的首个page
coalesced = base + page_idx;
// 设置其private
coalesced->private = order;
SetPagePrivate(coalesced);
// 将page加入对应规模块的双向链表
list_add(&coalesced->lru, &zone->free_area[order].free_list);
zone->free_area[order].nr_free++;// 更新对应规模内有效块数每CPU页框高速缓存
内核经常请求和释放单个页框。为提升系统性能,每个内存管理区定义了一个”每CPU”页框高速缓存。所有”每CPU”高速缓存包含一些预先分配的页框,它们被用于满足本地CPU发出的单一内存请求。
实际上,这里为每个内存管理区和每个CPU提供了两个高速缓存: 一个热高速缓存,它存放的页框中所包含的内容很可能就在CPU硬件高速缓存中;还有一个冷高速缓存。
如内核或用户态进程在刚分配到页框后就立即向页框写,那么从热高速缓存中获得页框就对系统性能有利。实际上,每次对页框存储单元的访问都会导致从页框中给硬件高速缓存”窃取”一行。当然,除非硬件高速缓存包含有一行:它映射刚被访问的”热”页框单元。反过来,如页框将要被DMA操作填充,则从冷高速缓存中获得页框是方便的。在这种情况下,不会涉及到CPU,且硬件高速缓存的行不会被修改。
实现每CPU页框高速缓存的主要数据结构是存放在内存管理区描述符的pageset字段中的一个per_cpu_pageset数组数据结构。该数组包含为每个CPU提供的一个元素;这个元素依次由两个per_cpu_pages描述符组成,一个留给热高速缓存,另一个留给冷高速缓存。
per_cpu_pages描述符的字段
| 类型 | 名称 | 描述 |
|---|---|---|
| int | count | 高速缓存中的页框个数 |
| int | low | 下界,表示高速缓存需要补充 |
| int | high | 上界 |
| int | batch | 在高速缓存中将要添加或被删去的页框个数 |
| struct list_head | list | 高速缓存中包含的页框描述符链表 |
内核使用两个位来监视热高速缓存和冷高速缓存的大小:如页框个数低于下界low,内核通过从伙伴系统中分配batch个单一页框来补充对应的高速缓存。否则,如页框个数高于上界high,内核从高速缓存中释放batch个页框到伙伴系统。值batch,low,high本质上取决于内存管理区中包含的页框个数。
1.通过每CPU页框高速缓存分配页框
buffered_rmqueue–在指定的内存管理区中分配页框,它使用每CPU页框高速缓存来处理单一页框请求。
参数:
- 内存管理区描述符的地址,
- 请求分配的内存大小的对数
order, - 分配标志
gfp_flags。
如pfp_flags中的__GFP_COLD标志被置位,则页框应当从冷高速缓存中获取,否则,它应从热高速缓存中获取。(此标志只对单一页框分配有意义)
函数操作:
如
order不等于0,每CPU页框高速缓存就不能被使用;跳到4检查由
__GFP_COLD标志所标识的内存管理区本地每CPU高速缓存是否需补充。这种情况下,它执行:- 通过反复调
__rmqueue从伙伴系统中分配batch个单一页框 - 将已分配页框的描述符插入高速缓存链表
- 通过给
count增加实际被分配页框来更新它
- 通过反复调
如
count为正,则函数从高速缓存链表获得一个页框,count减1跳到5。这里,内存请求还没被满足,或是因为请求跨越了几个连续页框,或是因为被选中的页框高速缓存为空,调
__rmqueue从伙伴系统分配所请求的页框。如内存请求得到满足,初始化第一个页框的页描述符:清除一些标志,将
private置为0,将页框引用计数器置1。如gfp_flags中__GPF_ZERO被置位,则函数将被分配的内存区域填充0。返回(第一个)页框的页描述符地址。如内存分配请求失败,则返回NULL。
2.释放页框到每CPU页框高速缓存–位于伙伴系统和页框使用者的中间层
free_hot_page–释放单个页框到每CPU页框热高速缓存
free_cold_page–释放单个页框到每CPU页框冷高速缓存
它们都是free_hot_cold_page的封装。
参数:
- 将要释放的页框的描述符地址
page, cold标志;
free_hot_cold_page操作:
- 从
page->flags获取包含该页框的内存管理区描述符地址 - 获取由
cold标志选择的管理区高速缓存的per_cpu_pages描述符地址 - 检查高速缓存是否应被清空:如
count高于或等于high,则调free_pages_bulk,将管理区描述符,将被释放的页框个数(batch),高速缓存链表的地址及数字 0 传递给该函数。free_pages_bulkl依次反复调__free_pages_bulk来释放指定数量的页框到内存管理区的伙伴系统中。 - 把释放的页框添加到高速缓存链表上,增加
count。
热高速缓存中页框,适合供cpu使用。冷高速缓存中页框,适合供DMA使用。
管理区分配器
管理区分配器是内核页框分配器的前端。该构建必须分配一个包含足够多空闲页框的内存区,使它能满足内存请求。
管理区分配器必须满足几个目标:
应当保护保留的页框池
- 当内存不足且允许阻塞当前进程时它应触发页框回收算法。一旦某些页框被释放,管理区分配器将再次尝试分配。
- 如可能,它应保存小而珍贵的
ZONE_DMA内存管理区。例如,如是对ZONE_NORMAL或ZONE_HIGHMEM页框的请求,则管理区分配器会不太愿意分配ZONE_DMA内存管理区中的页框。对一组连续页框的每次请求实质上是通过执行alloc_pages宏来处理的。接着,这个宏又依次调__alloc_pages,该函数是管理区分配器的核心。
1.__alloc_pages–通过内存管理区执行页框分配__alloc_pages参数:
- gfp_mask–在内存分配请求中指定的标志。
- order–将要分配的一组连续页框数量的对数。
- zonelist–指向zonelist数据结构的指针,该数据结构按优先次序描述了适用于内存分配的内存管理区。
__alloc_pages扫描包含在zonelist数据结构中的每个内存管理区。
for(i = 0; (z = zonelist->zones[i]) != NULL; i++)
{
if(zone_watermark_ok(z, order, ...))
{
page = buffered_rmqueue(z, order, gfp_mask);
if(page)
return page;
}
}对每个内存管理区,该函数将空闲页框的个数与一个阈值作比较,该阈值取决于内存分配标志、当前进程的类型、管理区被函数检查过的次数。实际上, 如空闲内存不足,则每个内存管理区一般会被检查几遍,每一遍在所请求的空闲内存最低量的基础上使用更低的阈值扫描。
zone_watermark_ok接收几个参数,它们决定内存管理区中空闲页框个数的阈值min。特别是,如满足下列两个条件则函数返回1。
- 除被分配的页框外,在内存管理区中至少还有
min个空闲页框。不包括为内存不足保留的页框。 - 除了被分配的页框外,这里在
order至少为k的块中起码还有$min/2^{k}$个空闲页框,对于k,取值在1和分配的order之间。
阈值min的值由zone_watermark_ok确定:
- 作为参数传递的基本值可是内存管理区界值
pages_min,pages_low和pages_high中的任意一个。 - 作为参数传递的
gfp_high标志被置位,则base值被2除。通常,如gfp_mask中的__GFP_WAIT标志被置位(即能从高端内存中分配页框),则这个标志等于1。 - 如作为参数传递的
can_try_harder被置位,则阈值将会再减少四分之一。如gfp_mask中的__GFP_WAIT被置位,或如当前进程是一个实时进程且在进程上下文中(在中断处理程序和可延迟函数之外)已经完成了内存分配,则can_try_harder标志等于1。
__alloc_pages执行:
执行对内存管理区的第一次扫描
第一次扫描中,阈值min被设为z->pages_low其中z指向正被分析的管理区描述符。如函数在上一步没终止,则没剩下多少空闲内存:函数唤醒
kswapd内核线程来异步地开始回收页框。执行对内存管理区的第二次扫描,将值
z->pages_min作为阈值base传递。实际阈值由can_try_harder和gfp_high决定。如函数在上一步没终止,则系统内存肯定不足。如产生内存分配请求的内核控制路径不是一个中断处理程序或一个可延迟函数,且它试图回收页框(或是
current的PF_MEMALLOC被置位,或它的PF_MEMDIE被置位),则函数随即执行对内存管理区的第三次扫描,试图分配页框并忽略内存的阈值。即不调zone_watermark_ok。唯有这种情况下才允许内核控制路径耗用为内存不足预留的页。这种情况下,产生内存请求的内核控制路径最终将试图释放页框,因此只要有可能它就应得到它所请求的。如没有任何内存管理区包含足够的页框,函数返回NULL来提示调用者发生了错误。这里,正调用的内核控制路径并没试图回收内存。如
gfp_mask的__GFP_WAIT没被置位,函数就返回NULL来提示该内核控制路径内存分配失败:此时,如不阻塞当前进程就没办法满足请求。在这里当前进程能被阻塞:调
cond_resched检查是否有其他的进程需CPU。设置
current的PF_MEMALLOC来表示进程已经准备好执行内存回收将一个执行
reclaim_state数据结构的指针存入current->reclaim_state。这个数据结构只包含一个字段reclaimed_slab。调
try_to_free_pages寻找一些页框来回收。函数可能阻塞当前进程。一旦函数返回,__alloc_pages就重设current的PF_MEMALLOC并再次调cond_resched。如上一步已释放了一些页框,则函数还要执行一次与3步相同的内存管理区扫描。如内存分配请求不能被满足,则函数决定是否应继续扫描内存管理区;如
__GFP_NORETRY被清除,且内存分配请求跨越了多达8个页框或__GFP_REPEAT和__GFP_NOFAIL其中之一被置位,则函数就调blk_congestion_wait使进程休眠一会儿,跳回6。否则,返回NULL。如
9没释放任何页框,就意味着内核遇到很大的麻烦。如允许内核控制路径依赖于文件系统的操作来杀死一个进程且__GFP_NORETRY为0,则执行:- 使用等于
z->pages_high的阈值再一次扫描内存管理区 - 调
out_of_memory通过杀死一个进程开始释放一些内存 - 跳回
1。
- 使用等于
2.__free_pages–通过内存管理区执行释放页框
参数:
- 将要释放的第一个页框的页描述符的地址,
- 将要释放的一组连续页框的数量的对数。
步骤:
- 检查第一个页框是否真正属于动态内存(
PG_reserved清0);如不是,终止。 - 减少
page->count;如仍大于或等于0,终止。 - 如
order等于0,则调free_hot_base来释放页框给适当内存管理区的每CPU热高速缓存。 - 如
order大于0,则它将页框加入到本地链表中,调free_pages_bulk把它们释放到适当的内存管理区的伙伴系统中。
内存高速缓存
伙伴系统算法采用页框作为基本内存区,这适合于对大块内存的请求,如何处理对小内存区的请求?
引入一种新的数据结构来描述在同一个页框中如何分配小内存区。
内核建立了13个按几何分布的空闲内存区链表,它们的大小从32字节到131072字节。
1.内存高速缓存层次
内存高速高速缓存包含多个slab,每个slab由一个或多个连续的页框组成。这些页框中既包含已分配的对象,也包含空闲的对象。内核周期性地扫描高速缓存并释放空slab对应的页框。
2.内存高速缓存描述符
每个内存高速缓存由kmem_cache_t类型的数据结构来描述。
| 类型 | 名称 | 说明 |
|---|---|---|
| struct array_cache*[] | array | 每CPU指针数组指向包含空闲对象的本地高速缓存 |
| unsigned int | batchcount | 要转移进本地高速缓存或从本地高速缓存中转出的大批对象的数量 |
| unsigned int | limit | 本地高速缓存中空闲对象的最大数目。 |
| struct kmem_list3 | lists | 参见下一个表 |
| unsigned int | objsize | 高速缓存中包含的对象的大小 |
| unsigned int | flags | 描述高速缓存永久属性的一组标志 |
| unsigned int | num | 封装在一个单独slab中的对象个数 |
| unsigned int | free_limit | 整个slab高速缓存中空闲对象的上限 |
| spinlock_t | spinlock | 高速缓存自旋锁 |
| unsigned int | gfporder | 一个单独slab中包含的连续页框数目的对数 |
| unsigned int | gfpflags | 分配页框时传递给伙伴系统函数的一组标志 |
| size_t | colour | slab使用的颜色个数 |
| unsigned int | colour_off | slab中的基本对齐偏移 |
| unsigned int | colour_next | 下一个被分配的slab使用的颜色 |
| kmem_cache_t* | slabp_cache | 指针指向包含slab描述符的普通slab高速缓存 |
| unsigned int | slab_size | 单个slab的大小 |
| unsigned int | dflags | 描述高速缓存动态属性的一组标志 |
| void* | ctor | 指向与高速缓存相关的构造方法的指针 |
| void* | dtor | 指向与高速缓存相关的析构方法的指针 |
| const char* | name | 存放高速缓存名字的字符数组 |
| struct list_head | next | 高速缓存描述符双向链表使用的指针 |
kmem_cache_t描述符的lists是一个结构体
| 类型 | 名称 | 说明 |
|---|---|---|
| struct list_head | slabs_partial | 包含空闲和非空闲对象的slab描述符双向循环链表 |
| struct list_head | slabs_full | 不包含空闲对象的slab描述符双向循环链表 |
| struct list_head | slabs_free | 只包含空闲对象的slab描述符双向循环链表 |
| unsigned long | free_objects | 高速缓存中空闲对象的个数 |
| int | free_touched | 由slab分配器的页回收算法使用 |
| unsigned long | next_reap | 由slab分配器的页回收算法使用 |
| struct array_cache* | shared | 指向所有CPU共享的一个本地高速缓存的指针 |
3.slab描述符
| 类型 | 名称 | 说明 |
|---|---|---|
| struct list_head | list | slab描述符的三个双向循环链表中的一个 |
| unsigned long | colouroff | slab中第一个对象的偏移 |
| void* | s_mem | slab中第一个对象的地址 |
| unsigned int | inuse | 当前正使用的slab中的对象个数 |
| unsigned int | free | slab中下一个空闲对象的下标,如没剩下空闲对象则为BUFCTL_END |
slab描述符可存放在两个可能的地方:
外部slab描述符–存放在slab外部,位于cache_sizes指向的一个不适合ISA DMA的普通高速缓存中。
内部slab描述符–存放在slab内部,位于分配给slab的第一个页框的起始位置
当对象小于512MB,或当内部碎片为slab描述符和对象描述符在slab中留下足够的空间时,slab分配器选第二种方案。
如slab描述符存放在slab外部,则高速缓存描述符的flags中CFLAGS_OFF_SLAB置1。
4.普通和专用高速缓存
高速缓存被分为两种类型:普通和专用。
普通高速缓存只由slab分配器用于自己的目的,专用高速缓存由内核的其余部分使用。
普通高速缓存是:
1.第一个高速缓存叫kmem_cache,包括由内核使用的其余高速缓存的高速缓存描述符。cache_cache变量包含第一个高速缓存的描述符。
2.另外一些高速缓存包含用作普通用途的内存区。
内存区大小的范围一般包括13个几何分布的内存区。一个叫malloc_sizes的表分分别指向26个高速缓存描述符,与其相关的内存区大小为32,64,128,256,512,1024,2048,4096,8192,16384,32768,65536和131072字节。对每种大小,都有两个高速缓存:一个适用于ISA DMA分配,另一个适用于常规分配。
在系统初始化期间调kmem_cache_init来建立普通高速缓存。
专用高速缓存由kmem_cache_create创建。函数从cache_cache普通高速缓存中为新的高速缓存分配一个高速缓存描述符,插入到高速缓存描述符的cache_chain。kmem_cache_destroy撤销一个高速缓存,并将它从cache_chain链表上删除。
kmem_cache_shrink通过反复调slab_destroy来撤销高速缓存中所有的slab。
所有普通和专用高速缓存的名字都可在运行期间通过读/proc/slabinfo得到。这个文件也指明每个高速缓存中空闲对象的个数和已分配对象的个数。
5.为slab分配页框,释放页框
kmem_getpages–slab的页框获取
参数:cachep–指向需额外页框的高速缓存的高速缓存描述符,请求页框的个数由存放在cache->gfporder中的order决定。flags–说明如何请求页框。这组标志与存放在高速缓存描述符的gfpflags中的专用高速缓存分配标志相结合。
在UMA系统上该函数本质上等价于
void* kmem_getpages(kmem_cache_t* cachep, int flags)
{
struct page* page;
int i;
flags |= cachep->gfpflags;
page = alloc_pages(flags, cachep->gfporder);
if(!page)
return NULL;
i = (1 << cache->gfporder);
if(cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
while(i--)
SetPageSlab(page++);
return page_address(page);
}如已创建了slab高速缓存且SLAB_RECLARM_ACCOUNT标志已经置位,则内核检查是否有足够的内存来满足一些用户态请求时,分配给slab的页框将被记录为可回收的页。函数还将所分配页框的页描述符中的PG_slab标志置位。
kmem_freepages–释放分配给slab的页框
void kmem_freepages(kmem_cache_t* cachep, void* addr)
{
unsigned long i = (1 << cachep->gfporder);
struct page* page = virt_to_page(addr);
if(current->reclaim_state)
current->reclaim_state->reclaimed_slab += i;
while(i--)
ClearPageSlab(page++);
free_pages((unsigned long)addr, cachep->gfporder);
if(cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_sub(1 << cachep->gfporder, &slab_reclaim_pages);
}函数从线性地址addr开始释放页框,这些页框曾分配给由cachep标识的高速缓存中的slab。如当前进程正在执行内存回收,reclaim_state结构的reclaimed_slab就被适当地增加,于是刚被释放的页就能通过页框回收算法被记录下来。此外,如SLAB_RECLAIM_ACCOUNT标志置位,slab_reclaim_pages则被适当地减少。
6.内存给高速缓存分配slab
一个新创建的高速缓存没有包含任何slab,因此也没空闲的对象。只有当以下两个条件都为真时,才给高速缓存分配slab。
- 已发出一个分配新对象的请求
- 高速缓存不包含任何空闲对象
这些情况发生时,通过调cache_grow给高速缓存分配一个新的slab。这个函数调kmem_getpages从分区页框分配器获得一组页框来存放一个单独的slab,然后又调alloc_slabmgmt获得一个新的slab描述符。如高速缓存描述符的CFLGS_OFF_SLAB置位,则从高速缓存描述符的slabp_cache字段指向的普通高速缓存中分配这个slab描述符,否则,从slab的第一个页框中分配这个slab描述符。
给定一个页框,内核需确定它是否被slab分配器使用。如是, 迅速得到相应高速缓存和slab描述符地址。故,cache_grow扫描分配给新slab的页框的所有页描述符,将高速缓存描述符和slab描述符的地址分别赋给页描述符中lru的next和prev。只有当页框空闲时伙伴系统的函数才会使用lru。所以,lru不会误用。分配给slab的页框设置PG_slab标志。
在高速缓存中给定一个slab,可通过使用slab描述符的s_mem和高速缓存描述符的gfporder来找到依赖的页框描述符。接着,cache_grow调cache_init_objs,将构造方法应用到新slab包含的所有对象上。最后,cache_grow调list_add_tail将新的slab描述符添加到高速缓存描述符*cachep的slab链表末端,并更新高速缓存中的空闲对象计数器
list_add_tail(&slab->list, &cachep->lists->slabs_free);
cachep->lists->free_objects += cachep->num;7.从高速缓存中释放slab
在两种条件下才能撤销slab:
- 内存高速缓存中有太多的空闲对象
- 被周期性调用的定时器函数确定是否有完全未使用的slab能被释放。
在两种情况下,调slab_destroy撤销一个slab,并释放相应的页框到分区页框分配器。
void slab_destroy(kmem_cache_t *cachep, slab_t *slabp)
{
if(cachep->dtor)
{
int i;
for(i = 0; i < cachep->num; i++)
{
void* objp = slabp->s_mem + cachep->objsize * i;
(cachep->dtor)(objp, cachep, 0);
}
}
kmem_freepages(cachep, slabp->s_mem - slabp->colouroff);
if(cachep->flags & CFLAGS_OFF_SLAB)
kmem_cache_free(cachep->slabp_cache, slabp);
}检查高速缓存是否为它的对象提供了析构,如是,使用析构方法释放slab中所有对象。objp记录当前已检查的对象。kmem_freepages把slab使用的所有连续页框返回给伙伴系统。如slab描述符存放在slab外面,就从slab描述符的高速缓存释放这个slab描述符。实际上,该函数稍微复杂些。如,可使用SLAB_DESTROY_BY_RCU来创建slab高速缓存,这意味着应使用call_rcu注册一个回调来延期释放slab。回调函数接着调kmem_freepages,也可能调kmem_cache_free。
8.对象描述符
每个对象有类型为kmem_bufctl_t的一个描述符,对象描述符存放在一个数组中,位于相应的slab描述符后。类似slab描述符,slab的对象描述符也可用两种可能的方式来存放:
- 外部对象描述符–存放在
slab的外面,位于高速缓存描述符的slabp_cache字段指向的一个普通高速缓存中。内存区的大小取决于在slab中所存放的对象个数。 - 内部对象描述符–存放在
slab内部,正好位于描述符所描述的对象前
对象描述符只不过是一个无符号整数,只有在对象空闲时才有意义。它包含的是下一个空闲对象在slab中的下标。因此实现了slab内部空闲对象的一个简单链表。空闲对象链表中的最后一个元素的对象描述符用常规值BUFCTL_END标记。
9.对齐内存中的对象
slab分配器所管理的对象可在内存中进行对齐。即存放它们的内存单元的起始物理地址是一个给定常量的倍数。通常是2的倍数,这个常量就叫对齐因子。slab分配器所允许的最大对齐因子是4096,即页框大小。
通常,如内存单元的物理地址是字大小(即计算机内部内存总线宽度)对齐的,则微机对内存单元的存取会非常快。因此,缺省下,kmem_cache_create根据BYTES_PER_WORD宏所指定的字大小来对齐对象。对于,80x86处理器,这个宏产生值4。当创建一个新的slab高速缓存时,就可让它所包含的对象在第一级高速缓存中对齐。为做到这点,设置SLAB_HWCACHE_ALIGN标志。
kmem_cache_create按如下方式处理请求:
- 如对象的大小大于高速缓存行的一半,就在
RAM中根据L1_CACHE_BYTES的倍数对齐对象 - 否则,对象的大小就是
L1_CACHE_BYTES的因子取整。这可保证一个小对象不会横跨两个高速缓存行。
10.slab着色
同一硬件高速缓存行可映射RAM中很多不同的块。相同大小的对象倾向于存放在高速缓存内相同的偏移量处。在不同slab内具有相同偏移量的对象最终很可能映射在同一高速缓存行中。高速缓存的硬件可能因此而花费内存周期在同一高速缓存行与RAM内存单元之间来来往往传送两个对象,而其他的高速缓存行并未充分使用。
slab分配器通过一种叫slab着色的策略,尽量降低高速缓存的这种不愉快行为:把叫做颜色的不同随机数分配给slab。我们考虑某个高速缓存,它的对象在RAM中被对齐。意味着对象的地址肯定是某个给定正数值的倍数。连对齐的约束也考虑在内,在slab内放置对象就有很多种可能的方式。方式的选择取决于对下列变量所作的决定:
num–可在slab中存放的对象个数osize–对象的大小。包括对齐的字节。dsize–slap描述符的大小加上所有对象描述符的大小,就等于硬件高速缓存行大小的最小倍数。如slab描述符和对象描述符都放在slap外部,这个值等于0。free–在slab内未用字节个数
一个slab中的总字节长度=(num*osize)+dsize+free。free总是小于osize,不过可大于aln。slab分配器利用空闲未用的字节free来对slab着色。术语着色只是用来再细分slab,并允许内存分配器把对象展开在不同的线性地址中。这样的话,内核从微处理器的硬件高速缓存中可获得最好性能。具有不同颜色的slab把slab的第一个对象存放在不同的内存单元,同时满足对齐约束。
可用颜色的个数是free/aln(这个值存放在高速缓存描述符的colour字段)。故,第一个颜色表示0,最后一个颜色表示为(free/aln)-1。一种特殊的情况是,如free比aln小,则colour被设为0,不过所有slab都使用颜色0,故颜色的真正个数是1。
如用颜色col对一个slab着色,则,第一个对象的偏移量(相对于slab的起始地址)就等于col*aln+dsize。着色本质上导致把slab中的一些空闲区域从末尾移到开始。只有当free足够大时,着色才起作用。显然,如对象没请求对齐,或如果slab内的未使用字节数小于所请求的对齐(free<=aln),则唯一可能着色的slab就是具有颜色0的slab,即,把这个slab的第一个对象的偏移量赋为0。
通过把当前颜色存放在高速缓存描述符的colour_next字段,就可在一个给定对象类型的slab之间平等地发布各种颜色。 cache_grow把colour_next所表示的颜色赋给一个新的slab,并递增这个字段的值。当colour_next的值变为colour后,又从0开始。这样,每个新创建的slab都与前一个slab具有不同的颜色,直到最大可用颜色。此外,cache_grow从高速缓存描述符的colour_off字段获得值aln,根据slab内对象的个数计算dsize,最后把col*aln+dsize的值存放到slab描述符的colouroff字段中。
11.空闲Slab对象的本地高速缓存–slab分配器和内存申请使用者的中间层
Linux 2.6对多处理器系统上slab分配器的实现不同于Solaris 2.4最初实现。为减少处理器之间对自旋锁的竞争并更好利用硬件高速缓存,slab分配器的每个高速缓存包含一个被称作slab本地高速缓存的每CPU数据结构,该结构由一个指向被释放对象的小指针数组组成。slab对象的大多数分配和释放只影响本地数组,只有在本地数组下溢或上溢时才涉及slab数据结构。类似前面的每CPU页框高速缓存。高速缓存描述符的array字段是一组指向array_cache数据结构的指针,系统中的每个CPU对应于一个元素。每个array_cache数据结构是空闲对象的本地高速缓存的一个描述符。
| 类型 | 名称 | 说明 |
|---|---|---|
| unsigned int | avail | 指向本地高速缓存中可使用对象的指针的个数。同时作为高速缓存中第一个空槽的下标 |
| unsigned int | limit | 本地高速缓存的大小。即本地高速缓存中指针的最大个数 |
| unsigned int | batchcount | 本地高速缓存重新填充或腾空时使用的块大小 |
| unsigned int | touched | 如本地高速缓存最近已被使用过,则该标志设为1 |
本地高速缓存描述符并不包含本地高速缓存本身的地址;事实上,它正好位于描述符之后。当然,本地高速缓存存放的是指向已释放对象的指针。对象本身总是位于高速缓存的slab中。
当创建一个新的slab高速缓存时,kmem_cache_create决定本地高速缓存的大小(将这个值存放在高速缓存描述符的Limit字段),分配本地高速缓存,将它们的指针存放在高速缓存描述符的array字段。batchcount字段的初始值,即从一个本地高速缓存的块里添加或删除的对象的个数,被初始化为本地高速缓存大小的一半。
在多处理器系统中,slab高速缓存含一个附加的本地高速缓存,它的地址被存放在高速缓存描述符的lists.shared中。共享的本地高速缓存正如它的名字暗示那样,被所有CPU共享,它使得将空闲对象从一个本地高速缓存移动到另一个高速缓存的任务更容易。它的初始大小等于batchcount字段值的8倍。
12.分配slab对象
通过调kmem_cache_alloc可获得新对象。参数cachep指向高速缓存描述符,新空闲对象必须从该高速缓存描述符获得,参数flag表示传递给分区页框分配器函数的标志。该高速缓存的所有slab应是满的
void* kmem_cache_alloc(kmem_cache_t* cachep, int flags)
{
unsigned long save_flags;
void* objp;
struct array_cache* ac;
local_irq_save(save_flags);// 禁止本cpu上外部中断,保存标志信息
ac = cache_p->array[smp_processor_id()];// 从内存高速缓存中取得当前cpu的本地高速缓存
if(ac->avail)
{
ac->touched = 1;
objp = ((void**)(ac+1))[--ac->avail];
}
else
objp = cache_alloc_refill(cache_p, flags);
local_irq_restore(save_flags);// 恢复中断设置,恢复标志信息
return objp;
} 先试图从本地高速缓存获得一个空闲对象。如有,avail就包含指向最后被释放的对象的项在本地高速缓存中的下标。
因为本地高速缓存数组正好存放在ac描述符后面。故, ((void**)(ac+1))[--ac->avail];获得空闲对象地址,递减ac->avail。
当本地高速缓存没空闲对象时,cache_alloc_refill重新填充本地高速缓存并获得一个空闲对象。
cache_alloc_refill:
将本地高速缓存描述符地址放在
ac局部变量ac = cachep->array[smp_processor_id()]获得
cachep->spinlock如
slab高速缓存包含共享本地高速缓存,且该共享本地高速缓存包含一些空闲对象,就通过从共享本地高速缓存中上移ac->batchcount个指针来重新填充CPU的本地高速缓存。跳6。试图填充本地高速缓存,填充值为高速缓存的
slab中包含的多达ac->batchcount个空闲对象的指针查看高速缓存描述符的
slabs_partial和slabs_free,获得slab描述符的地址slabp,该slab描述符的相应slab或部分被填充,或为空。如不存在这样的描述符,跳5。对
slab中的每个空闲对象,增加slab描述符的inuse,将对象的地址插入本地高速缓存,更新free使得它存放了slab中下一空闲对象下标
slabp->inuse++; ((void**)(ac+1))[ac->avail++] = slabp->s_mem + slabp->free * cachep->obj_size; slabp->free = ((kmem_bufctl_t*)(slabp+1))[slabp->free];- 如必要,将清空的
slab插入到适当的链表上,可以是slab_full,也可是slab_partial。
这里,被加到本地高速缓存上的指针个数被存放在
ac->avail,函数递减同样数量的kmem_list3结构的free_objects来说明这些对象不再空闲释放
cachep->spinlock如现在
ac->avail字段大于0(一些高速缓存再填充的情况发生了),函数将ac->touched设为1,返回最后插入到本地高速缓存的空闲对象指针:return ((void**)(ac+1))[--ac->avail];否则,没发生高速缓存缓存再填充情况,调
cache_grow获得一个新slab。从而获得新的空闲对象。如
cache_grow失败了,函数返回NULL。否则,返回1。
13. 释放slab对象
void kmem_cache_free(kmem_cache_t* cachep, void *objp)
{
unsigned long flags;
struct array_cache* ac;
local_irq_save(flags);// 禁止本地中断,保存标志信息
ac = cachep->array[smp_procesor_id()];// 获取本地CPU高速缓存
if(ac->avail == ac->limit)// 本地cpu高速缓存满了
cache_flusharray(cachep, ac);
((void**)(ac+1))[ac->avail++] = objp;// 没满,直接放入
local_irq_restore(flags);// 恢复本地中断,恢复标志信息
} 先检查本地高速缓存是否有空间给指向一个空闲对象的额外指针,如有,该指针就被加到本地高速缓存然后返回。否则,它首选调cache_flusharray清空本地高速缓存,然后将指针加到本地高速缓存。
cache_flusharray:
获得
cachep->spinlock如
slab高速缓存包含一个共享本地高速缓存,且如该共享本地缓存还没满,函数就通过从CPU的本地高速缓存中上移ac->batchcount个指针来重新填充共享本地高速缓存调
free_block将当前包含在本地高速缓存中的ac->batchcount个对象归还给slab分配器。
对在地址objp处的每个对象,执行如下:增加高速缓存描述符的
lists.free_objects确定包含对象的
slab描述符的地址slabp = (struct slab*)(virt_to_page(objp)->lru.prev);记住,
slab页的描述符的lru.prev指向相应的slab描述符从它的
slab高速缓存链表(cachep->lists.slabs_partial或cachep->lists.slabs_full)上删除slab描述符。计算
slab内对象的下标objnr = (objp - slabp->s_mem) / cachep->objsize;将
slabp->free的当前值存放在对象描述符中,并将对象的下标放入slabp->free(最后被释放的对象将再次成为首先被分配的对象,提升硬件高速缓存命中率)((kmem_bufctl_t*)(slabp+1))[objnr] = slabp->free;// 利用对象内存(空闲对象)作为单向链表的索引值 slabp->free = objnr;// 下次分配将从上次释放对象开始分配(提升硬件高速缓存命中率)递减
slabp->inuse如
slabp->inuse等于0(即slab中所有对象空闲)且整个slab高速缓存中空闲对象的个数(cachep->lists.free_objects)大于cachep->free_limit字段中存放的限制,则函数将slab的页框释放到分区页框分配器cachep->lists.free_objects -= cachep->num; slab_destroy(cachep, slabp);存放在
cachep->free_limit字段中的值通常等于cachep->num+(1+N)*cachep->batchcount,其中N代表系统中CPU的个数否则,如
slab->inuse等于0,但整个slab高速缓存中空闲对象的个数小于cachep->free_limit,函数就将slab描述符插入到cachep->lists.slab_free链表中最后,如
slab->inuse大于0,slab被部分填充,则函数将slab描述符插入到cachep->lists.slabs_partial链表
释放
cachep->spinlock通过减去被移到共享本地高速缓存或被释放到
slab分配器的对象的个数来更新本地高速缓存描述符的avail移动本地高速缓存数组起始处的那个本地高速缓存中的所有指针。因为,已经把第一个对象指针从本地高速缓存上删除,故剩下的指针必须上移。
14.通用对象
如对存储器的请求不频繁,就用一组普通高速缓存来处理。普通高速缓存中的对象具有几何分布的大小,范围为32~131072字节。
void* kmalloc(size_t size, int flags)
{
struct cache_sizes *csizep = malloc_sizes;
kmem_cache_t* cachep;
for(; csizep->cs_size; csizep++)
{
if(size > csizep->cs_size)
continue;
if(flag & __GFP_DMA)
cachep = csizep->cs_dmacachep;
else
cachep = csizep->cs_cachep;
return kmem_cache_alloc(cachep, flags);
}
return NULL;
}函数用malloc_sizes表为所请求的大小分配最近的2的幂次方大小内存。然后,调kmem_cache_alloc分配对象。
依据flag,决定是采用适用于ISA DMA页框的高速缓存描述符,还是适用于”常规”页框的高速缓存描述符。
void kfree(const void* objp)
{
kmem_cache_t* c;
unsigned long flags;
if(!objp)
return;
local_irq_save(flags);
c = (kmem_cache_t*)(virt_to_page(objp)->lru.next);
kmem_cache_free(c, (void*)objp);
local_irq_restore(flags);
}通过读取内存区所在的第一个页框描述符的lru.next子字段,就可确定出合适的高速缓存描述符。
通过调kmem_cache_free来释放相应的内存区。
15.内存池–使用者可以直接与kmem_cache交互,也可与mempool_t交互
是Linux2.6的一个新特性。基本上讲,一个内存池允许一个内核成分,如块设备子系统,仅在内存不足的紧急情况下分配一些动态内存来使用。不应该将内存池与前面”保留的页框池”一节描述的保留页框混淆。实际上,这些页框只能用于满足中断处理程序或内部临界区发出的原子内存分配请求。而内存池是动态内存的储备,只能被特定的内核成分(即池的”拥有者”)使用。拥有者通常不使用储备;但,如动态内存变得极其稀有以至于所有普通内存分配请求都将失败的话,那么作为最后的解决手段, 内核成分就能调特定的内存池函数提取储备得到所需的内存。因此,创建一个内存池就像手头存放一些罐装食物作为储备,当没有新鲜食物时就使用开罐器。
一个内存池常常叠加在slab分配器之上–即,它用来保存slab对象的储备。但,一般而言,内存池能被用来分配任何一种类型的动态内存,从整个页框到使用kmalloc分配的小内存区。故,我们一般将内存池处理的内存单元看作”内存元素”。
内存池由mempool_t描述
| 类型 | 名称 | 说明 |
|---|---|---|
| spinlock_t | lock | 用来保护对象字段的自旋锁 |
| int | min_nr | 内存池中元素的最大个数 |
| int | curr_nr | 当前内存池中元素的个数 |
| void** | elements | 指向一个数组的指针,该数组由指向保留元素的指针组成 |
| void* | pool_data | 池的拥有者可获得的私有数据 |
| mempool_alloc_t* | alloc | 分配一个元素的方法 |
| mempool_free_t* | free | 释放一个元素的方法 |
| wait_queue_head_t | wait | 当内存池为空时使用的等待队列 |
min_nr字段存放了内存池中元素的初始个数。即,存放在该字段的值代表了内存元素的个数。内存池拥有者确信能从内存分配器得到这个数目。curr_nr字段总是低于或等于min_nr,它存放了内存池中当前包含的内存元素个数。内存元素自身被一个指针数组引用,指针数组地址存放在elements。
alloc,free与基本的内存分配器交互,分别用于获得和释放一个内存元素,两个方法可是拥有内存池的内核成分提供的定制函数。当内存元素是slab对象时,alloc,free一般由mempool_alloc_slab和mempool_free_slab实现,它们只是分别调kmem_cache_alloc和kmem_cache_free。这种情况下,mempool_t对象的pool_data字段存放了slab高速缓存描述符的地址。
mempool_create创建一个新的内存池;
它接收的参数为:内存元素的个数min_nr,实现alloc,free方法的函数的地址,赋给pool_data字段的值。
函数分别为mempool_t对象和指向内存元素的指针数组分配内存,然后反复调alloc方法来得到min_nr个内存元素。
相反地,mempool_destroy释放池中所有内存元素,然后释放元素数组和mempool_t对象自己。
mempool_alloc–从内存池分配一个元素:
内核调mempool_alloc,将mempool_t对象的地址和内存分配标志传递给它。
函数本质上依据参数所指定的内存分配标志,试图通过调alloc从基本内存分配器分配一个内存元素。
如成功,函数返回获得的内存元素而不触及内存池。否则,如分配失败,就从内存池获得内存元素。
当然,内存不足情况下过多的分配会用尽内存池:这种情况下,如__GFP_WAIT标志置位,则mempool_alloc阻塞当前进程直到有一个内存元素被释放到内存池中。
mempool_free–释放一个元素到内存池
内核调mempool_free。如内存池未满,则函数将元素加到内存池。否则,mempool_free调free方法来释放元素到基本内存分配器。
非连续内存区管理
把内存区映射到一组连续的页框是最好的选择,会充分利用高速缓存并获得较低的平均访问时间。
如对内存区的请求不频繁,则通过连续的线性地址来访问非连续的页框这样一种分配模式会很有意义。这种模式优点是避免了外碎片,缺点是打乱内核页表。显然,非连续内存区大小必须是4096倍数。
Linux在几个方面使用非连续内存区,如:为活动的交换区分配数据结构,为模块分配空间,或者给某些I/O驱动程序分配缓冲区。此外,非连续内存区还提供了另一种使用高端内存页框的方法。
1.非连续内存区的线性地址
要查找线性地址的一个空闲区,可从PAGE_OFFSET开始查找。
- 线性内存区的开始部分包含的是对前
896MB RAM进行映射的线性地址。直接映射的物理内存末尾所对应的线性地址保存在high_memory - 线性内存区的结尾部分包含的是固定映射的线性地址。
- 从
PKMAP_BASE开始,查找用于高端内存页框的永久内核映射的线性地址 - 其余的线性地址可用于非连续内存区。
在直接内存映射的末尾与第一个内存区之间插入一个大小为8MB的安全区,目的是为了”捕获”对内存的越界访问。
出于同样的理由,插入其他4KB大小的安全区来隔离非连续的内存区。
以下针对32位处理器:
- 直接映射线性地址区域:
[PAGE_OFFSET, high_memory] vmalloc线性地址空间:[VMALLOC_START,VMALLOC_END]- 永久内核映射的线性地址空间:
[PKMAP_BASE,FIXADDRSTART] - 固定映射的线性地址空间:
[FIXADDR_START,4GB]
为非连续内存区保留的线性地址空间的起始地址由VMALLOC_START定义,末尾地址由VMALLOC_END定义。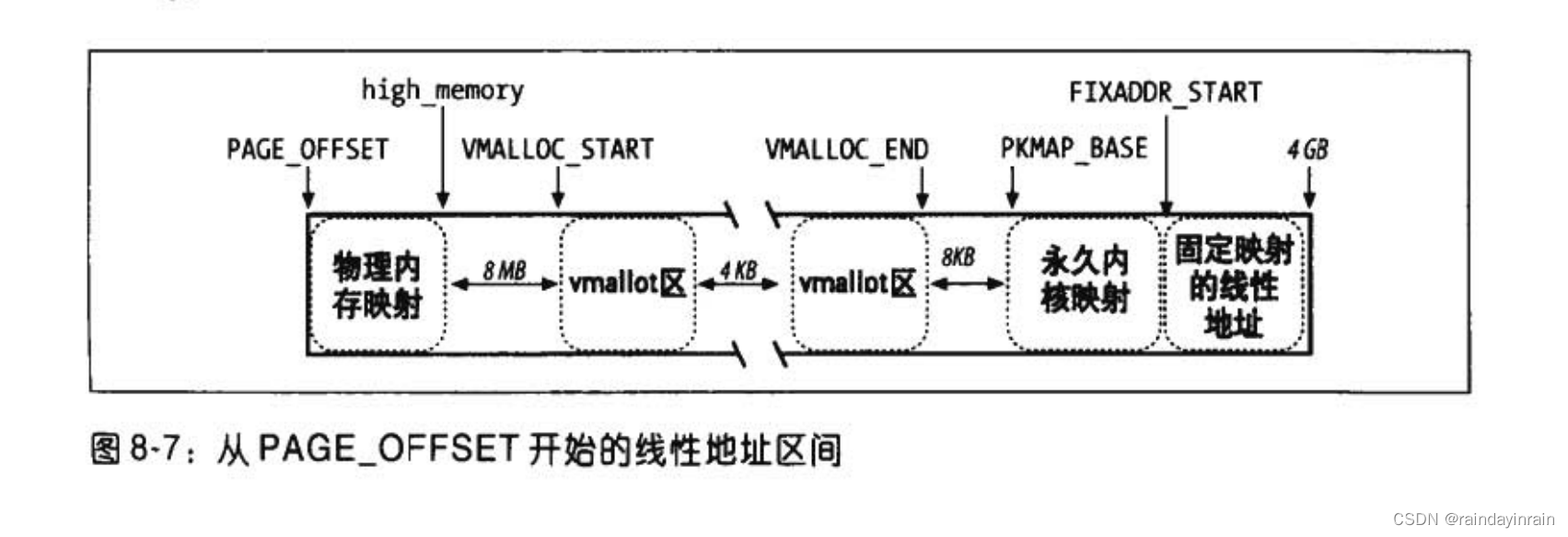
2.非连续内存区的描述符
每个非连续内存区都对应着一个类型为vm_struct的描述符
| 类型 | 名称 | 说明 |
|---|---|---|
| void* | addr | 内存区内第一个内存单元的线性地址 |
| unsigned long | size | 内存区的大小加4096 |
| unsigned long | flags | 非连续内存区映射的内存的类型 |
| struct page** | pages | 指向nr_pages数组的指针,该数组由指向页描述符的指针组成 |
| unsigned int | nr_pages | 内存区填充的页的个数 |
| unsigned long | phys_addr | 该字段设为0,除非内存已被创建来映射一个硬件设备的I/O共享内存 |
| struct vm_struct* | next | 指向下一个vm_struct结构的指针 |
通过next,这些描述符被插入到一个简单的链表中,链表的第一个元素的地址存放在vmlist变量中。对这个链表的访问依靠vmlist_lock读写自旋锁来保护。
flags字段标识了非连续区映射的内存的类型:VM_ALLOC表示使用vmalloc得到的页,VM_MAP表示使用vmap映射的已经被分配的页,VM_IOREMAP表示使用ioremap映射的硬件设备的板上内存。
get_vm_area–在线性地址VMALLOC_START和VMALLOC_END之间查找一个空闲区域
参数:
- 将被创建的内存区的字节大小,
- 指定空闲区类型的标志
步骤:
- 调
kmalloc为vm_struct类型的新描述符获得一个内存区 - 为写得到
vmlist_lock锁,并扫描类型为vm_struct的描述符链表来查找线性地址一个空闲区域,至少覆盖size+4096个地址(4096是内存区之间的安全区间大小) - 如存在这样一个区间,函数就初始化描述符的字段,释放
vmlist_lock,并以返回非连续内存区描述符的起始地址而结束 - 否则,
get_vm_area释放先前得到的描述符,释放vmlist_lock,返回NULL
3.分配非连续内存区
vmalloc–给内核分配一个非连续内存区
参数:
- size–表示所请求内存区的大小
void* vmalloc(unsigned long size)
{
struct vm_struct *area;
struct page **pages;
unsigned int array_size, i;
size = (size + PAGE_SIZE - 1) & PAGE_MASK;
area = get_vm_area(size, VM_ALLOC);
if(!area)
return NULL;
area->nr_pages = size >> PAGE_SHIFT;
array_size = (area->nr_pages * sizeof(struct page*));
area->pages = pages = kmalloc(array_size, GFP_KERNEL);
if(!area->pages)
{
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
memset(area->pages, 0, array_size);
for(i = 0; i < area->nr_pages; i++)
{
area->pages[i] = alloc_page(GFP_KERNEL | __GFP_HIGHMEM);
if(!area->pages[i])
{
area->nr_pages = i;
fail:
vfree(area->addr);
return NULL;
}
}
// 通过页表表项逐个处理构建连续线性地址和离散物理地址之间的映射
if(map_vm_area(area, __pgprot(0x63), &pages))
goto fail;
return area->addr;
}
}- 函数首先将
size设为4096的整数倍,然后,vmalloc调get_vm_area来创建一个新的描述符,并返回分配给这个内存区的线性地址。描述符的flags字段被初始化为VM_ALLOC标志,该标志意味着通过使用vmalloc函数,非连续的物理页框将被映射到一个线性地址空间。 - 然后,
vmalloc调kmalloc来请求一组连续页框,这组页框足够包含一个页描述符指针数组。调memset将所有这些指针设为NULL。接着重复调alloc_page,每一次为区间中nr_pages个页的每一个分配一个页框,并把对应页描述符的地址存放在area->pages中。 - 到这里,已经得到一个新的连续线性地址空间,且已分配了一组非连续页框来映射这些线性地址。
最后重要的步骤是修改内核使用的页表项,以此表明分配给非连续内存区的每个页框现在对应着一个线性地址,这个线性地址被包含在vmalloc产生的连续线性地址空间中。
map_vm_area
参数:
area–指向内存区的vm_struct描述符的指针prot–已分配页框的保护位。它总是被置为0x63,对应着Present,Accessed,Read/Write,Dirtypages–指向一个指针数组的变量的地址,该指针数组的指针指向页描述符
过程:
- 函数首先把内存区的开始和末尾的线性地址分别分配给局部变量
address和end:
address = area->addr;
end = address + (area->size - PAGE_SIZE);记住,
area->size存放的是内存区的实际地址加上4KB的安全区间。
函数使用pgd_offset_k宏来得到在主内核页全局目录中的目录项,该项对应于内存区起始线性地址,然后获得内核页表自旋锁:pgd = pgd_offset_k(address); spin_lock(&init_mm.page_table_lock);然后,函数执行下列循环
int ret = 0; for(i = pgd_index(address); i < pgd_index(end-1); i++) { pud_t* pud = pud_alloc(&init_mm, pgd, address); ret = -ENOMEM; if(!pud) break; next = (address + PGDIR_SIZE) & PGDIR_MASK; if(next < address || next > end) next = end; if(map_area_pud(pud, address, next, prot, pages)) break; address = next; pgd++; ret = 0; } spin_unlock(&init_mm.page_table_lock); flush_cache_vmap((unsigned long)area->addr, end); return ret每次循环都首先调
pub_alloc来为新内存区创建一个页上级目录,并把它的物理地址写入内核页全局目录的合适表项。
调alloc_area_pud为新的页上级目录分配所有相关的页表。接下来,把常量2的30幂次(在PAE被激活的情况下,否则为2的22幂次)与address的当前值相加(2的30幂次就是一个页上级目录所跨越的线性地址范围的大小)。
最后增加指向页全局目录的指针pgd。
循环结束的条件是:指向非连续内存区的所有页表项全被建立。map_area_pud为页上级目录所指向的所有页表执行一个类似的循环:do{ pmd_t* pmd = pmd_alloc(&init_mm, pud, address); if(!pmd) return -ENOMEM; if(map_area_pmd(pmd, address, end-address, prot, pages)) return -ENOMEM; address = (address + PUD_SIZE) & PUD_MASK; pud++; } while(address < end);map_area_pmd为页中间目录所指向的所有页表执行一个类似的循环do{ pre_t* pte = pte_alloc_kernel(&init_mm, pmd, address); if(!pte) return -ENOMEM; if(map_area_pte(pte, address, end-address, prot, pages)) return -ENOMEM; address = (address + PMD_SIZE) & PMD_MASK; pmd++; } while(address < end);pte_alloc_kernel分配一个新的页表,并更新页中间目录中相应的目录项。
接下来,map_area_pte为页表中相应的表项分配所有的页框。address值增加$2^{22}$($2^{22}$就是一个页表所跨越的线性地址区间的大小),且循环反复执行map_area_pte主循环为:do{ struct page* page = **pages; set_pte(pte, mk_pte(page, prot)); address += PAGE_SIZE; pte++; (*pages)++; } while(address < end);将被映射的页框的页描述符地址
page从地址pages处的变量指向的数组项读得的。
通过set_pte和mk_pte宏,把新页框的物理地址写进页表。把常量4096(即一个页框的长度)加到address上之后,循环又重复执行。
注意,map_vm_area并不触及当前进程的页表。故,当内核态的进程访问非连续内存区时,缺页发生。
因为该线性内存区所对应的进程页表的表项为空。然而,缺页处理程序要检查这个缺页线性地址是否在主内核页表中(即init_mm.pgd页全局目录和它的子页表)一旦处理程序发现一个主内核页表含有这个线性地址的非空项,就把它的值拷贝到相应的进程页表项中,并恢复进程的正常执行。
除了vmalloc外,非连续内存区还能由vmalloc_32分配,该函数与vmalloc相似,但它只从ZONE_NORMAL和ZONE_DMA管理区分配页框。
4.释放非连续内存区
vfree–释放vmalloc和vmalloc_32创建的非连续内存区
vunmap–释放vmap创建的内存区
两个函数都使用同一个参数,它们都依赖于__vunmap来作实质性的工作。:
- 将要释放的内存区的起始线性地址address,
__vunmap
参数:
将要释放的内存区的起始地址的地址addr,
标志deallocate_pages,如被映射到内存区的页框应当被释放到分区页框分配器,则这个标志被置位,否则被清除。
过程:
- 调
remove_vm_area得到vm_struct描述符的地址area,清除非连续内存区中的线性地址对应的内核的页表项 - 如
deallocate_pages被置位,函数扫描指向页描述符的area->pages指针数组;
对数组的每一个元素,调__free_page释放页框到分区页框分配器。执行kfree(area->pages)来释放数组自身。 - 调
kfree(area)来释放vm_struct
write_lock(&vmlist_lock);
for(p = &vmlist; (tmp = *p); p = &tmp->next)
{
if(tmp->addr == addr)
{
unmap_vm_area(tmp);
*p = tmp->next;
break;
}
}
write_unlock(&vmlist_lock);
return tmp;内存区本身通过调unmap_vm_area来释放。
unmap_vm_area
参数:
- 指向内存区的vm_struct描述符的指针area。
过程:
address = area->addr;
end = address + area->size;
pgd = pgd_offset_k(address);
for(i = pgd_index(address); i <= pgd_index(end-1); i++)
{
next = (address + PGDIR_SIZE) & PGDIR_MASK;
if(next <= address || next > end)
next = end;
unmap_area_pud(pgd, address, next - address);
address = next;
pgd++;
}unmap_area_pud依次在循环中执行map_area_pud的反操作:
do {
unmap_area_pmd(pud, address, end - address);
address = (address + PUD_SIZE) & PUD_MASK;
pud++;
} while(address && (address < end));unmap_area_pmd函数在循环体中执行map_area_pmd的反操作
do {
unmap_area_pte(pmd, address, end - address);
address = (address + PMD_SIZE) & PMD_MASK;
pmd++;
} while(address < end);最后,unmap_area_pte在循环中执行map_area_ate的反操作
do {
pte_t page = ptep_get_and_clear(pte);
address += PAGE_SIZE;
pte++;
if(!pte_none(page) && !pte_present(page))
printk("Whee ... Swapped out page in kernel page table\n");
} while(address < end); 在每次循环过程中,ptep_get_and_clear将pte指向的页表项设为0。与vmalloc一样,内核修改主内核页全局目录和它的子页表中的相应项,但映射第4个GB的进程页表的项保持不变。因为内核永远不会回收扎根于主内核页全局目录中的页上级目录,页中间目录,页表。如,假定内核态的进程访问一个随后要释放的非连续内存区。进程的页全局目录项等于主内核页全局目录中的相应项。这些目录项指向相同的页上级目录,页中间目录,页表。
unmap_area_pte只清除页表中的项(不回收页表本身)。进程对已释放非连续内存区的进一步访问必将由于空的页表项而触发缺页异常。缺页异常处理程序会认为这样的访问是一个错误,因为主内核页表不包含有效的表项。
进程地址空间
概述
我们在之前更加底层的层面看到了:内核中通过这些函数获得动态内存:__get_free_pages,alloc_pages,kmem_cache_alloc,kmalloc,vmalloc,vmalloc_32。
使用上述简单方法基于以下两个原因:
- 内核是操作系统中优先级最高的成分。如某个内核函数请求动态内存,则必定有正当的理由发出请求,因此,没道理试图推迟这个请求。
- 内核信任自己。所有的内核函数都假定没错误,故内核函数不必插入针对编程错误的任何保护措施。
给用户态进程分配内存时,情况完全不同:
- 进程对动态内存的请求被认为是不紧迫的。如进程的可执行文件被装入时,进程不一定立即对所有的代码页进行访问。如进程调
malloc获得请求的动态内存时,不意味着进程很快会访问所有所获得的内存。故一般来说,内核总是尽量推迟给用户态进程分配动态内存。 - 由于用户进程是不可信任的,故内核必须能随时准备捕获用户态进程引起的所有寻址错误。
当用户态进程请求动态内存时,并没有获得请求的页框,而仅仅获得对一个新的线性地址区间的使用权,而这一线性地址区间就成为进程地址空间的一部分。这一区间叫”线性区”。
进程的地址空间
进程的地址空间由允许进程使用的全部线性地址组成。每个进程所看到的线性地址集合是不同的,一个进程所使用的地址与另外一个进程所使用的地址之间没什么关系。内核可通过增加或删除某些线性地址区间来动态地修改进程的地址空间。
内核通过所谓线性区的资源来表示线性地址区间,线性区是由起始线性地址,长度和一些访问权限来描述的。
为效率起见,起始地址和线性区的长度必须是4096的倍数,以便每个线性区所识别的数据完全填满分配给它的页框。
下面是进程获得新线性区的一些典型情况:
- 当用户在控制台输入一条命令时,
shell进程创建一个新的进程去执行这个命令。结果是,一个全新的地址空间(一组线性区)分配给了新进程。 - 正在运行的进程有可能决定装入一个完全不同的程序。这种情况下,进程标识符仍保持不变,可是在装入这个程序以前所使用的线性区却被释放,并有一组新的线性区被分配给这个进程
- 正在运行的进程可能对一个文件(或它的一部分)执行”内存映射”。这种情况下,内核给这个进程分配一个新的线性区来映射这个文件。
- 进程可能持续向它的用户态堆栈增加数据,直到映射这个堆栈的线性区用完。这种情况下,内核也许会决定扩展这个线性区的大小。
- 进程可能创建一个IPC共享线性区来与其他合作进程共享数据。此情况下,内核给这个进程分配一个新的线性区以实现这个方案
- 进程可能通过调类似
malloc这样的函数扩展自己的动态区。结果是,内核可能决定扩展给这个堆所分配的线性区。
| 系统调用 | 说明 |
|---|---|
| brk | 改变进程堆的大小 |
| execve | 装入一个新的可执行文件,从而改变进程的地址空间 |
| _exit | 结束当前进程并撤销它的地址空间 |
| fork | 创建一个新进程,并为它创建新的地址空间 |
| map,map2 | 为文件创建一个内存映射,从而扩大进程的地址空间 |
| mremap | 扩大或缩小线性区 |
| remap_file_pages | 为文件创建非线性映射 |
| munmap | 撤销对文件的内存映射,从而缩小进程的地址空间 |
| shmat | 创建一个共享线性区 |
| shmdt | 撤销一个共享线性区 |
确定一个进程当前所拥有的线性区(即进程的地址空间)是内核的基本任务,因为这可以让缺页异常处理程序有效地区分引发这个异常处理程序的两种不同类型的无效线性地址:
- 由编程错误引发的无效线性地址
- 由缺页引发的无效线性地址;
即使这个线性地址属于进程的地址空间,但对应于这个地址的页框仍有待分配。从进程观点看,后一种地址不是无效的。内核要利用这种缺页以实现请求调页:内核通过提供页框来处理这种缺页,并让进程继续运行。(也就是说我们需要区分这两种情况才是!)
内存描述符
与进程地址空间有关的全部信息都包含在一个叫内存描述符的数据结构中,这个结构的类型为mm_struct,进程描述符的mm字段就指向这个结构。
| 类似 | 字段 | 说明 |
|---|---|---|
| struct vm_area_struct* | mmap | 指向线性区对象的链表头 |
| struct rb_root | mm_rb | 指向线性区对象的红黑树的根 |
| struct vm_area_struct* | mmap_cache | 指向最后一个引用的线性区对象 |
| unsigned long(*)() | get_unmapped_area | 在进程地址空间中搜索有效线性地址区间的方法 |
| void (*)() | unmap_area | 释放线性地址区间时调用的方法 |
| unsigned long | mmap_base | 标识第一个分配的匿名线性区或文件内存映射的线性地址 |
| unsigned long | free_area_cache | 内核从这个地址开始搜索进程地址空间中线性地址的空闲区间 |
| pdt_t* | pgd | 指向页全局目录 |
| atomic_t | mm_users | 次使用计数器 |
| atomic_t | mm_count | 主使用计数器 |
| int | map_count | 线性区的个数 |
| struct rw_semaphore | mmap_sem | 线性区的读/写信号量 |
| spinlock_t | page_table_lock | 线性区的自旋锁和页表的自旋锁 |
| struct list_head | mmlist | 指向内存描述符链表中的相邻元素 |
| unsigned long | start_code | 可执行代码的起始地址 |
| unsigned long | end_data | 可执行代码的最后地址 |
| unsigned long | start_brk | 堆的起始地址 |
| unsigned long | brk | 堆的当前最后地址 |
| unsigned long | start_stack | 用户态堆栈的起始地址 |
| unsigned long | arg_start | 命令行参数的起始地址 |
| unsigned long | arg_end | 命令行参数的最后地址 |
| unsigned long | env_start | 环境变量的起始地址 |
| unsigned long | env_end | 环境变量的最后地址 |
| unsigned long | rss | 分配给进程的页框数 |
| unsigned long | anon_rss | 分配给匿名内存映射的页框数 |
| unsigned long | total_vm | 进程地址空间的大小 |
| unsigned long | locked_vm | “锁住”而不能换出的页的个数 |
| unsigned long | shared_vm | 共享文件内存映射中的页数 |
| unsigned long | exec_vm | 可执行内存映射中的页数 |
| unsigned long | stack_vm | 用户态堆栈中的页数 |
| unsigned long | reserved_vm | 在保留区中的页数或在特殊线性区中的页数 |
| unsigned long | def_flags | 线性区默认的访问标志 |
| unsigned long | nr_ptes | 进程的页表数 |
| unsigned long[] | saved_auxv | 开始执行ELF程序时使用 |
| unsigned int | dumpable | 表示是否可产生内存信息转储的标志 |
| cpumask_t | cpu_vm_mask | 用于懒惰TLB交换的位掩码 |
| mm_context_t | context | 指向有关特定体系结构信息的表(如x86上的LDT地址) |
| unsigned long | swap_token_time | 进程在这个时间将有资格获得交换标记 |
| char | recent_pagein | 如最近发生了主缺页,设置该标志 |
| int | core_waiters | 正在把进程地址空间的内存转储到core文件中的轻量级进程的数量 |
| struct completion* | core_startup_done | 指向创建内存转储文件时的补充原语 |
| struct completion | core_done | 创建内存转储文件时使用的补充原语 |
| rwlock_t | ioctx_list_lock | 用于保护异步I/O上下文链表的锁 |
| struct kioctx* | ioctx_list | 异步I/O上下文链表 |
| struct kioctx | default_kioctx | 默认的异步I/O上下文 |
| unsigned long | hiwater_rss | 进程所拥有的最大页框数 |
| unsigned long | hiwater_vm | 进程线性区中的最大页数 |
所有的内存描述符存放在一个双向链表中,每个描述符在mmlist字段存放链表相邻元素的地址。链表的第一个元素是init_mm的mmlist,init_mm是初始化阶段进程0所使用的内存描述符。mmlist_lock保护多处理器系统对链表的同时访问。
mm_users字段存放共享mm_struct数据结构的轻量级进程的个数,叫做次使用计数器。mm_count字段是内存描述符的主使用计数器,在mm_users次使用计数器中的所有用户在mm_count中只作为一个单位。每当mm_count递减时,内核要检查它是否变为0,如是就解除这个内存描述符。
考虑一个内存描述符由两个轻量级进程共享。它的mm_users字段通常是2,而mm_count字段通常是1。如把内存描述符暂时借给一个内核线程,则,内核就增加mm_count。这样,即使两个轻量级进程都死亡,且mm_users变为0,则个内存描述符也不被释放,直到内核线程使用完。因为mm_count仍大于0。
如内核想确保内存描述符在一个长操作的中间不被释放,则应增加mm_users,而非mm_count字段的值。最终的结果是相同的,因为mm_users的增加确保了mm_count不变为0,即使拥有这个内存描述符的所有轻量级进程全部死亡。
mm_alloc用来获得一个新的内存描述符。由于这些描述符被保存在slab分配器高速缓存中。故mm_alloc调kmem_cache_alloc来初始化新的内存描述符,并把mm_count和mm_users字段都置为1。
mmput递减内存描述符的mm_users字段。如该字段变为0,这个函数就释放局部描述符表,线性区描述符,由内存描述符所引用的页表,并调mmdrop。后者把mm_count减1,如该字段变为0,就释放mm_struct。
内核线程的内存描述符
内核线程仅仅运行在内核态,它们永不会访问低于TASK_SIZE的线性地址。大于TASK_SIZE线性地址的相应页表项都应该总是相同的,因此,一个内核线程到底用什么样的页表集根本没关系。为避免无用的TLB和高速缓存刷新,内核线程使用一组最近运行的普通进程的页表。结果,在每个进程描述符中包含mm和active_mm。
进程描述符中的mm指向进程所拥有的内存描述符,active_mm指向进程运行时所使用的内存描述符。
对普通进程,两者值相同。对内核线程,mm总是NULL。active_mm为前一运行线程的active_mm。只要处于内核态的一个进程为”高端”线性地址(高于TASK_SIZE)修改了页表项,那么它就也应当更新系统中所有进程页表集合中的相应表项。一旦内核态的一个进程进行了设置,则映射应对内核态的所有其他进程都有效。触及所有进程的页表集合是相当费时的操作,因此,Linux才有一种延迟方式。每当一个高端地址被重新映射时(一般通过vmalloc,vfree),内核就更新被定位在swapper_pg_dir主内核页全局目录中的常规页表集合。这个页全局目录由主内存描述符的pgd字段指向,而主内存描述符存放于init_mm变量。
线性区
Linux通过类型为vm_area_struct的对象实现线性区
| 类型 | 字段 | 说明 |
|---|---|---|
| struct mm_struct* | vm_mm | 指向线性区所在的内存描述符 |
| unsigned long | vm_start | 线性区内的第一个线性地址 |
| unsigned long | vm_end | 线性区之后的第一个线性地址 |
| struct vm_area_struct* | vm_next | 进程拥有的线性区链表中的下一个线性区 |
| pgprot_t | vm_page_prot | 线性区中页框的访问许可权 |
| unsigned long | vm_flags | 线性区的标志 |
| struct rb_node | vm_rb | 用于红-黑树的数据 |
| union | shared | 链接到反映射所使用的数据结构 |
| struct list_head | anon_vma_node | 指向匿名线性区链表的指针 |
| struct anon_vma* | anon_vma | 指向anon_vma数据结构的指针 |
| struct vm_operations_struct* | vm_ops | 指向线性区的方法 |
| unsigned long | vm_pgoff | 在映射文件中的偏移量。对匿名页,它等于0或vm_start/PAGE_SIZE |
| struct file* | vm_file | 指向映射文件的文件对象 |
| void* | vm_private_data | 指向内存区的私有数据 |
| unsigned long | vm_truncate_count | 释放非线性文件内存映射中的一个线性地址区间时使用 |
每个线性区描述符表示一个线性地址区间。vm_start字段包含区间的第一个线性地址,vm_end字段包含区间之外的第一个线性地址。vm_end - vm_start表示线性区的长度。vm_mm字段指向拥有这个区间的进程的mm_struct。
进程所拥有的线性区从不重叠,且内核尽力把新分配的线性区与紧邻的现有线性区合并。如两个相邻区的访问权限匹配,就能合并在一起。vm_ops字段指向vm_operations_struct数据结构,该结构中存放的是线性区的方法。
| 方法 | 说明 |
|---|---|
| open | 当把线性区增加到进程所拥有的线性区集合时调用 |
| close | 当从进程所拥有的线性区集合删除线性区时调用 |
| nopage | 当进程试图访问RAM中不存在的一个页,但该页的线性地址属于线性区时,由缺页异常处理程序调用 |
| populate | 设置线性区的线性地址(预缺页)所对应的页表项时调用。主要用于非线性文件内存映射 |
线性区数据结构
进程所拥有的所有线性区是通过一个简单链表链接在一起。链表中的线性区是按内存地址升序排列的;每两个线性区可由未用的内存地址隔开。每个vm_area_struct元素的vm_next字段指向链表的下一个元素。
内核通过进程的内存描述符的mmap字段来查找线性区,其中mmap字段指向链表中的第一个线性区描述符。内存描述符的map_count字段存放进程所拥有的线性区数目。默认下,一个进程可最多拥有65536个不同的线性区,系统管理员可通过写/proc/sys/vm/max_map_count文件来修改这个限定值。
内核频繁执行的一个操作就是查找包含指定线性地址的线性区。由于,链表是经过排序的。故只要在指定线性地址之后找到一个线性区,搜索就可结束。仅当进程线性区非常少时,使用这种链表才是方便的。比如说,只有一二十个线性区。在链表中查找元素,插入元素,删除元素涉及许多操作,这些操作所花费的时间与链表的长度成线性比例。
尽管多数的Linux进程使用的线性区非常少,但诸如面向对象的数据库,或malloc的专用调试器那样过于庞大的大型应用程序可能由成百上千的线性区。此情况下,线性区链表的管理变得非常低效。与内存相关的系统调用的性能就降低到令人无法忍受的地步。故Linux 2.6把内存描述符存放在叫红-黑树的数据结构中。
红黑树小论
在红-黑树中,每个元素(或节点)通常有两个孩子:左孩子,右孩子。树中的元素被排序,对每个节点N,N的左子树上的所有元素都排在N之前。相反,N的右子树上的所有元素都排在N之后;节点的关键字被写入节点内部。此外,红-黑树必须满足下列规则:
- 每个节点必须或为黑或为红
- 树的根必须为黑
- 红节点的孩子必须为黑
- 从一个节点到后代叶子节点的每个路径都包含相同数量的黑节点。
统计黑节点个数时,空指针也算作黑节点。这4条规则确保有n个内部节点的任何红-黑树其高度最多为2*log(n+1)。
在红-黑树中搜索一个元素因此变得非常高效,因为其操作的执行时间与树大小的对数成线性比例。即,双倍的线性区个数只多增加一次循环。在红-黑树中插入和删除一个元素也是高效的,算法可很快便利树以确定插入元素的位置或删除元素的位置。任何新节点必须作为一个叶子插入并着成红色。如操作违背了上述规则,就需移动或重新着色。
为了存放进程的线性区,Linux既使用了链表,也使用了红-黑树。这两种数据结构包含指向同一线性区描述符的指针,插入或删除一个线性区描述符时,内核通过红-黑树搜索前后元素,用搜索结果快速更新链表而不用扫描链表。
链表的头由内存描述符的mmap字段所指向。任何线性区对象都在vm_next字段存放指向链表下一元素的指针。红-黑树首部由内存描述符的mm_rb字段所指向。任何线性区对象都在类型为rb_node的vm_rb字段中。存放节点颜色及指向双亲,左孩子,右孩子的指针。一般,红-黑树用来确定含有指定地址的线性区,链表通常在扫描整个线性区集合时来使用。红黑树可以和链表同时服务于存储一类元素的容器。插入,删除时,先在红黑树搜索前后元素。前后元素已知下链表插入,删除复杂度为O(1)。整体遍历元素时,链表比红黑树更有优势。
线性区访问权限
用页这个术语既表示一组线性地址,又表示这组地址中所存放的数据。我们把介于0~4095之间的线性地址区间称为第0页,介于4096~8191之间的线性地址区间称为第1页,以此类推。因此,每个线性区都由一组号码连续的页构成。注意,用页表示线性区域的刻度,用页框表示物理内存区域的刻度。
几类访问标志:
- 每个页表项中存放的标志,如:
Read/Write,Present或User/Supervisor。
由80x86硬件用来检查能否执行所请求的寻址类型; - 页框描述符
flags字段中的一组标志由Linux用于许多不同的目的。 vm_area_struct描述符的vm_flags用于为线性区内的页提供标志信息。
一些标志给内核提供有关这个线性区全部页的信息,如它们含什么内容,进程访问每个页的权限。
另外的标志描述线性区自身,如它应如何增长。
| 标志名 | 收纳 |
|---|---|
| VM_READ | 页是可读的 |
| VM_WRITE | 页是可写的 |
| VM_EXEC | 页是可执行的 |
| VM_SHARED | 页可由几个进程共享 |
| VM_MAYREAD | 可设置VM_READ标志 |
| VM_MAYWRITE | 可设置VM_WRITE标志 |
| VM_MAYEXEC | 可设置VM_EXEC标志 |
| VM_MAYSHARE | 可设置VM_SHARE标志 |
| VM_GROWSDOWN | 线性区可向低地址扩展 |
| VM_GROWSUP | 线性区可向高地址扩展 |
| VM_SHM | 线性区用于IPC的共享内存 |
| VM_DENYWRITE | 线性区映射一个不能打开用于写的文件 |
| VM_EXECUTABLE | 线性区映射一个可执行文件 |
| VM_LOCKED | 线性区中的页被锁住,且不能换出 |
| VM_IO | 线性区映射设备的I/O地址空间 |
| VM_SEQ_READ | 应用程序顺序地访问页 |
| VM_RAND_READ | 应用程序以真正的随机顺序访问页 |
| VM_DONTCOPY | 当创建一个新进程时不拷贝线性区 |
| VM_DONTEXPAND | 通过mremap禁止线性区扩展 |
| VM_RESERVED | 线性区是特殊的,因此它的页不能被交换出去 |
| VM_ACCOUNT | 创建IPC共享线性区时检查是否有足够的空闲内存用于映射 |
| VM_HUGETLB | 通过扩展分页机制处理线性区中的页 |
| VM_NONLINEAR | 线性区实现非线性文件映射 |
线性区描述符所包含的页访问权限可以任意组合。如,存在这样一种可能性,允许一个线性区中的页可执行但不可以读取。为了有效地实现这种保护方案,与线性区的页相关的访问权限(读,写,执行)必须被复制到相应的所有表项中,以便由分页单元直接执行检查。即,页访问权限表示何种类型的访问应产生一个缺页异常。Linux委派缺页处理程序查找导致缺页的原因。因为,缺页处理程序实现了许多页处理策略。
页表标志的值存放在vm_area_struct描述符的vm_page_prot字段。当增加一个页时,内核根据vm_page_prot字段的值设置相应页表项中的标志。然而,不能把线性区的访问权限直接转换成页保护位:
某些情况下,即使由相应线性区描述符的
vm_flags所指定的某个页的访问权限允许对该页进行访问,但,对该页的访问还是应产生一个缺页异常。如,本章后面”写时复制”。内核可能决定把属于两个不同进程的两个完全一样的可写私有页存入同一页框;这种情况下,无论哪一个进程试图改动这个页都应当产生一个异常。80x86处理器的页表仅有两个保护位,即Read/Write和User/Supervisor。一个线性区所包含的任何一个页的User/Supervisor需总是置为1,因为用户态进程需总能访问其中的页。启用
PAE的新近Intel Pentium 4,在所有64位页表项中支持NX标志。如内核没被继续编译成支持
PAE,则Linux采取如下规则以克服80x86微处理器的硬件限制:- 读访问权限总是隐含着执行访问权限,反之亦然。
- 写访问权限总是隐含着读访问权限。反之,如内核编程成支持
PAE,且CPU有NX标志(No Execute)。
Linux就采取不同的规则:- 执行访问权限总是隐含着读访问权限
- 写访问权限总是隐含着读访问权限
为做到在”写时复制”(Copy on Write)中适当地推迟页框的分配,只要相应的页不是由多个进程所共享,则这种页框应是写保护的。故要根据以下规则精简由读,写,执行,共享访问的16中可能组合
- 如页有写,共享。则
Read/Write设置为1。 - 如页有读或执行,但既没写,也没共享访问权限。则,
Read/Write置为0。 - 如支持
NX,且也没执行访问权限,则NX置为1。 - 如页没任何访问权限,则
Present置为0。以便每次访问都产生一个缺页异常。为了把这种情况与真正的页框不存在情况区分,Linux还把Pagesize置为1。 - 访问权限的每种组合对应的精简后的保护位存放在
protection_map。
线性区的处理
对控制内存处理所用的数据结构和状态信息有基本理解后,看一组对线性区描述符进行操作的底层函数。这些函数应被看作简化了do_map和do_unmap实现的辅助函数。这两个函数将在后面”分配线性地址区间”,”释放线性地址区间”中描述。它们分别扩大或缩小进程的地址空间。它们并不接受线性区描述符作为参数,而是用一个线性地址区间的起始地址,长度,访问权限作为参数。
查找给定地址的最近邻区:find_vma
参数:
- 进程内存描述符的地址
mm, - 线性地址
addr。
它查找线性区的vm_end大于addr的第一个线性区的位置,并返回这个线性区描述符的地址。如没这样的线性区存在,就返回一个NULL。注意, 由find_vma所选择的线性区并不一定要包含addr,因为addr可能位于任何线性区之外。
每个内存描述符包含一个mmap_cache字段,这个字段保存进程最后一次引用线性区的描述符地址。引进这个附加字段是为了减少查找一个给定线性地址所在线性区而花费的时间。程序中引用地址的局部性使下面这种情况出现的可能性很大:如检查的最后一个地址属于某一给定的线性区,则下一个要检查的线性地址也属于这一个线性区。故该函数一开始就检查由mmap_cache所指定的线性区是否包含addr。如是,就返回这个线性区描述符的指针
vma = mm->mmap_cache;
if(vma && vma->vm_end > addr && vma->vm_start <= addr)
return vma;否则,必须扫描进程的线性区,并在红-黑树中查找线性区
rb_node = mm->mm_rb.rb_node;
vma = NULL;
while(rb_node)
{
vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if(vma_tmp->vm_end > addr)
{
vma = vma_tmp;
if(vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
}
else
rb_node = rb_node->rb_right;
}
if(vma)
mm->mmap_cache = vma;
return vma; 函数用红rb_entry从指向红黑树的一个节点的指针导出相应线性区描述符的地址。
find_vma_prev,把函数中选中的前一个线性区描述符的指针赋给附加参数ppre。find_vma_prepare确定新叶子节点在与给定线性地址对应的红-黑树中的位置,返回前一个线性区的地址和要插入的叶子节点的父节点的地址。
查找一个与给定的地址区间相重叠的线性区:find_vma_intersection
参数:
mm指向进程的内存描述符,- 线性地址
start_addr和end_addr指定这个区间
vma = find_vma(mm, start_addr);
if(vma && end_addr <= vma->vm_start)
vma = NULL;
return vma; 如没这样的线性区存在,就返回一个NULL。如find_vma返回一个有效的地址,但所找到的线性区是从这个线性地址区间的末尾开始的,vma就置为NULL。
查找一个空闲的地址区间:get_unmapped_area
参数:
len,指定区间的长度,addr,非空的addr指定必须从哪个地址开始查找。
返回值:如查找成功,返回这个新区间的起始地址;否则,返回错误码-ENOMEM。
如addr不等于NULL,就检查所指定的地址是否在用户态空间并与页边界对齐。函数根据线性地址区间是否应用于文件内存映射或匿名内存映射,调两个方法(get_unmapped_area文件操作和内存描述符的get_unmapped_area)中的一个。前一种情况下,函数执行get_unmapped_area文件操作。第二种情况下,函数执行内存描述符的get_unmapped_area。根据进程的线性区类型,由函数arch_get_unmapped_area或arch_get_unmapped_area_topdown实现get_unmapped_area。
通过系统调用map,每个进程可获得两种不同形式的线区:一种从线性地址0x40000000开始并向高端地址增长,另一种正好从用户态堆栈开始并向低端地址增长。
在分配从低端地址向高端地址移动的线性区时使用arch_get_unmapped_area。
if(len > TASK_SIEZ)
return -ENOMEM;
addr = (addr + 0xfff) & 0xfffff000;
if(addr & addr + len <= TASK_SIZE)
{
vma = find_vma(current->mm, addr);
if(!vma || addr + len <= vma->vm_start)
return addr;
}
start_addr = addr = mm->free_area_cache;
for(vma = find_vma(current->mm, addr); ; vma = vma->vm_next)
{
if(addr + len > TASK_SIZE)
{
if(start_addr == (TASK_SIZE/3 + 0xfff) & 0xfffff000)
return -ENOMEM;
start_addr = addr = (TASK_SIZE/3 + 0xfff) & 0xfffff000;// 这是允许的最低起始线性地址
vma = find_vma(current->mm, addr);
}
if(!vma || addr + len <= vma->vm_start)
{
mm->free_area_cache = addr + len;
return addr;// 返回线性地址是满足分配要求线性区(尚未分配)的起始地址
}
addr = vma->vm_end;
}函数先检查区间的长度是否在用户态下线性地址区间的限长TASK_SIZE之内。
如
addr不为0,函数就试图从addr开始分配区间。为安全,函数把addr值调整为4KB倍数。
如addr等于0或前面的搜索失败,arch_get_unmapped_area就扫描用户态线性地址空间以查找一个可包含新区的足够大的线性地址范围。但任何已有的线性区都不包括这个地址范围。
为提高搜索速度,让搜索从最近被分配的线性区后面的线性地址开始,把内存描述符的字段mm->free_area_cache初始化为用户态线性地址空间的三分之一,并在以后创建新线性区时对它更新。如找不到一个合适的线性地址范围,就从用户态线性地址空间的三分之一的开始处重新开始搜索。其实,用户态线性地址空间的三分之一是为有预定义起始线性地址的线性区(典型的是可执行文件的正文段,数据段,bss段)而保留的。
函数调find_vma以确定搜索起点后第一个线性区终点的位置。三种情况:
- 如所请求的区间大于正待扫描的线性地址空间部分(
addr+len>TASK_SIZE),函数就从用户态地址空间的三分之一处重新开始搜索,如已完成第二次搜索,就返回-ENOMEM。 - 刚扫描过的线性区后面的空闲区没足够的大小,
vma != NULL && vma->vm_start < addr + len此时,继续考虑下一个线性区。 - 如以上两情况都没发生,则找到一个足够大的空闲区。函数返回
addr。
向内存描述符链表中插入一个线性区:insert_vm_struct
参数:
mm,指定进程内存描述符的地址,vmp指定要插入的vm_area_struct对象的地址,线性区对象的vm_start和vm_end必须已经初始化过。
函数调find_vma_prepare在红-黑树mm->mm_rb中查找vma应位于何处。然后,insert_vm_struct又调vma_link。
vma_link:
- 在
mm->mmap所指向的链表中插入线性区。 - 在红-黑树
mm->mm_rb中插入线性区。 - 如线性区是匿名的,就把它插入以相应的
anon_vma数据结构作为头节点的链表中。 - 如线性区包含一个内存映射文件,则执行相关任务。
- 递增
mm->map_count。
__vma_unlink:
参数:
- 为一个内存描述符地址
mm, - 两个线性区对象地址
vma和prev。两个线性区都应属于mm,prev应在线性区的排序中位于vma之前。
过程:
该函数从内存描述符链表和红-黑树中删除vma,
如mm->mmap_cache(存放刚被引用的线性区)字段指向刚被删除的线性区,则还要对mm->mmap_cache进行更新。
分配线性地址区间
do_mmap:
功能:
- 为当前进程创建并初始化一个新的线性区
参数:
file和offser,如新的线性区把一个文件映射到内存,则使用文件描述符指针file和文件偏移量offset。addr,这个线性地址指定从何处开始查找一个空闲的区间。len,线性地址区间的长度。prot,这个线性区所包含页的访问权限。可能的标志有PROT_READ,PROT_WRITE,PROT_EXEC和PROT_NONE。前三个标志与标志VM_READ,WM_WRITE及VM_EXEC意义一样。PROT_NONE表示进程没以上三个访问权限中任意一个。flag,指定线性区的其他标志MAP_GROWSDOWN,MAP_LOCKED,MAP_DENYWRITE和MAP_EXECUTEABLE,MAP_SHARED和MAP_PRIVATE,MAP_FIXED,MAP_ANONYMOUS,MAP_NORESERVE,MAP_POPULATE,MAP_NONBLOCK。
一些标志的解释:
| flag | 说明 |
|---|---|
MAP_FIXED |
区间的起始地址必须由参数addr指定。 |
MAP_ANONYMOUS |
没有文件与这个线性区相关联。 |
MAP_POPULATE |
函数应为线性区建立的映射提前分配需要的页框,该标志对映射文件的线性区和IPC共享的线性区有意义。 |
MAP_NONBLOCK |
只在MAP_POPULATE置位时才有意义,提前分配页框时,函数肯定不阻塞。 |
do_mmap对offset的值进行一些初步检查,然后执行do_mmap_pgoff。本节假设新的线性地址区间映射的不是磁盘文件,这里仅对实现匿名线性区的do_mmap_pgoff进行说明。
检查参数的值是否正确,所提的请求是否能被满足。尤其检查:
- 线性地址区间的长度为
0或包含的地址大于TASK_SIZE。 - 进程已映射了过多的线性区,即,
mm内存描述符的map_count字段的值超过了允许的最大值。 - flag参数指定新线性地址区间的页必须被锁在
RAM中,但不允许进程创建上锁的线性区,或进程加锁页的总数超过了保存在进程描述符signal->rlim[RLIMIT_MEMLOCK].rlim_cur字段的阈值。
以上任一情况成立,则
do_mmap_pgoff终止并返回一个负值、如线性地址区间的长度为0,则函数不执行任何操作就返回。- 线性地址区间的长度为
调
get_unmapped_area获得新线性区的线性地址区间通过把存放在
prot和flags参数中的值进行组合来计算新线性区描述符的标志>vm_flags = calc_vm_prot_bits(prot, flags) | calc_vm_flag_bits(prot, flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC; >if(flags & MAP_SHARED) vm_flags |= VM_SHARED | VM_MAYSHARE;只有在
prot中设置了相应的PROT_READ,PROT_WRITE和PROT_EXEC标志,calc_vm_prot_bits才在vm_flags中设置VM_READ,VM_WRITE,VM_EXEC;只有在flags设置了相应的MAP_GROWSDOWN,MAP_DENYWRITE,MAP_EXECUTABLE和MAP_LOCKED,calc_vm_flag_bits才在vm_flags中设置VM_GROWSDOWN,VN_DENYWRITE,VM_EXECUTABLE和VM_LOCKED。
在vm_flags中还有几个标志被置为1:VM_MAYREAD,VM_MAYWRITE,VM_MAYEXEC。在mm_def_flags中所有线性区的默认标志,及如线性区的页与其他进程共享时的VM_SHARED和VM_MAYSHARE。调
find_vma_prepare确定处于新区间之前的线性区对象的位置,及在红-黑树中新线性区的位置>for(;;) >{ vma = find_vma_prepare(mm, addr, &prev, &rb_link, &rb_parent); if(!vma || vma->vm_start >= addr + len) break; if(do_munmap(mm, addr, len))// 返回非0表示操作执行失败 return -ENOMEM; >}find_vma_prepare也检查是否还存在与新区间重叠的线性区。这情况发生在函数返回一个非空的地址,这个地址指向一个线性区,该区的起始位置位于新区间结束地址之前的时候。此情况下,do_mmap_pgoff调do_munmap删除新的区间,然后重复整个步骤。检查插入新的线性区是否引起进程地址空间的大小超过存放在进程描述符
signal->rlim[RLIMIT_AS].rlim_cur字段中的阈值。如是,就返回错误码-ENOMEM。这个检查只在这里进行,不在第一步与其他检查一起进行。若在
flags参数中没设置MAP_NORESERVE,新的线性区包含私有可写页,且没足够的空闲页框,则返回出错码-ENOMEM;这最后一个检查由security_vm_enough_memory实现。如新区间是私有的,且映射的不是磁盘上的一个文件,则调
vma_merge检查前一个线性区是否可以这样的方式进行扩展来包含新的区间。前一个线性区须与在vm_flags中存放标志的那些线性区有相同的标志。如前一个线性区可扩展,则vma_merge试图把它与随后的线性区合并。一旦扩展前一线性区成功,跳12。调
slab分配函数kmem_cache_alloc为新线性区分配一个vm_area_struct初始化新的线性区对象
vma->vm_mm = mm; vma->vm_start = addr; vma->vm_end = addr + len; vma->vm_flags = vm_flags; vma->vm_page_prot = protection_map[vm_flags & 0x0f]; vma->vm_ops = NULL; vma->vm_pgoff = pgoff; vma->vm_file = NULL; vma->vm_private_data = NULL; vma->vm_next = NULL; INIT_LIST_HEAD(&vma->shared);如
MAP_SHARED被设置,则该线性区是一个共享匿名区:调shmem_zero_setup对它进行初始化,共享匿名区主要用于进程间通信调
vma_link把新线性区插入到线性区链表和红-黑树增加存放在内存描述符
total_vm字段中的进程地址空间大小如设置了
VM_LOCKED,就调make_pages_present连续分配线性区 的所有页,并把它们锁在RAM中>if(vm_flags & VM_LOCKED) >{ mm->locked_vm += len >> PAGE_SHIFT; make_pages_present(addr, addr + len); >} >12345 >make_pages_present`按如下方式调`get_user_pages >write = (vma->vm_flags & VM_WRITE) != 0; >get_user_pages(current, current->mm, addr, len, write, 0, NULL, NULL);get_user_pages在addr和addr+len之间页的所有起始线性地址上循环;对其中的每个页,该函数调follow_page检查在当前页表中是否有物理页的映射。如没这样的物理页存在,则get_user_pages调handle_mm_fault,后一个函数分配一个页框并根据内存描述符的vm_flags设置它的页表项。函数通过返回新线性区的线性地址而终止
释放线性地址区间
do_munmap:
功能:
- 释放线性地址区间
参数:
- 进程描述符的地址
mm, - 地址区间的起始地址
start, - 它的长度
len。
split_vma:
功能:
- 把与线性地址区间交叉的线性区划分成两个较小的区,一个在线性地址区间外部,另一个在区间的内部。
参数:
- 内存描述符指针
mm, - 线性区描述符指针
vma, - 表示区间与线性区之间交叉点的地址
addr, - 表示区间与线性区之间交叉点在区间起始处还是结束处的标志
new_below。
步骤:
- 调
kmem_cache_alloc获得线性区描述符vm_area_struct。把它的地址存在新的局部变量中,如没可用的空闲空间,就返回-ENOMEM。 - 用
vma描述符的字段值初始化新描述符的字段 - 如标志
new_below为0,说明线性地址区间的起始地址在vma线性区的内部。因此须把新线性区放在vma线性区之后,函数把new->vm_start和vma->vm_end赋值为addr。 - 如
new_below等于1,说明线性地址区间的结束地址在vma线性区的内部。故需把新线性区放在vma线性区的前面,所以,函数把字段new->vm_end和vm->vm_start都赋值为addr。 - 如定义了新线性区的
open,执行它 - 把新线性区描述符链接到线性区链表
mm->mmap和红黑树mm->mm_rb,函数还要根据线性区vma的最新大小对红-黑树进行调整 - 返回0
unmap_region:
作用:
- 遍历线性区链表并释放它们的页框
参数:
- 内存描述符指针
mm, - 指向第一个被删除线性区描述符的指针
vma, - 指向进程链表中vma前面的线性区的指针
prev, - 地址
start, - 地址
end。
步骤:
- 调
lru_add_drain - 调
tlb_gather_mmu初始化每CPU变量mmu_gathers。mmu_gathers依赖于体系结构:通常该变量应存放成功更新进程页表项所需的所有信息。在80x86体系结构中,tlb_gather_mmu只是简单地把内存描述符指针mm的值赋给本地CPU的mmu_gathers - 把
mmu_gathers变量的地址存在局部变量tlb - 调
unmap_vmas扫描线性地址空间的所有页表项:如只有一个有效CPU,函数就调free_swap_and_cache反复释放相应页框。否则, 函数就把相应页描述符的指针保存在局部变量mmu_gathers - 调
free_pgtables(tlb, prev, start, end)回收上一步已清空的进程页表 - 调
tlb_finish_mmu(tlb, start, end)结束unmap_region的工作。
tlb_finish_mmu(tlb, start, end):
- 调
flush_tlb_mm刷新TLB - 在多处理器系统中,调
free_pages_and_swap_cache释放页框,这些页框的指针已经集中存放在mmu_gather中了。
do_munmap:
第一阶段,扫描进程所拥有的线性区链表,把包含在进程地址空间的线性地址区间中的所有线性区从链表中解除链接;
第二阶段,更新进程的页表,把第一阶段找到并标识出的线性区删除。
步骤如下:
- 对参数值检查。
- 确定要删除的线性地址区间之后第一个线性区
mpnt位置,如有这样的线性区
mpnt = find_vma_prev(mm, start, &prev);
1- 如没这样的线性区,也没与线性区间重叠的线性区,就什么都不做
end = start + len;
if(!mpnt || mpnt->vm_start >= end)
return 0;
123- 如线性区的起始地址在线性区
mpnt内,就调split_vma把线性区mpnt分成两个较小的区:一个区在线性地址区间外,另一个在区间内
if(start > mpnt->vm_start)
{
if(split_vma(mm, mpnt, start, 0))
return -ENOMEM;
prev = mpnt;
}更新局部变量prev,以前它存储的是指向线性区mpnt前面一个线性区的指针,现在让它指向mpnt,即指向线性地址区间外部的那个新线性区。这样prev仍指向要删除的第一个线性区前面的那个线性区
- 如线性区的结束地址在一个线性区内部,就再次调
split_vma把最后重叠的那个线性区划分成两个较小的区:一个在线性地址区间内,另一个在区间外
last = find_vma(mm, end);
if(last && end > last->vm_start)
{
if(split_vma(mm, last, start, end, 1))
return -ENOMEM;
}
123456- 更新
mpnt值,使它指向线性地址区间的第一个线性区。如prev为NULL,就从mm->mmap获得第一个线性区的地址
mpnt = prev ? prev->vm_next : mm->mmap;
1- 调
detach_vmas_to_be_unmapped从进程的线性地址空间中删除位于线性地址区间中的线性区。
vma = mpnt;
insertion_point = (prev ? &prev->vm_next : &mm->mmap);
do
{
rb_erase(&vma->vm_rb, &mm->mm_rb);
mm->map_count--;
tail_vma = vma;
vma = vma->next;
} while(vma && vma->start < end);
*insertion_point = vma;
tail_vma->vm_next = NULL;
mm->map_cache = NULL;
123456789101112要删除的线性区的描述符存放在一个排序好的链表中,局部变量mpnt指向该链表的头
- 获得
mm->page_table_lock - 调
unmap_region清除与线性地址区间对应的页表项并释放相应的页框
unmap_region(mm, mpnt, prev, start, end);
1- 释放
mm->page_table_lock - 释放
7步建立链表时收集的线性区描述符
do
{
struct vm_area_struct* next = mpnt->vm_next;
unmap_vma(mm, mpnt);
mpnt = next;
} while(mpnt != NULL);
123456对在链表中的所有线性区调unmap_vma,它本质上执行下述:
- 更新
mm->total_vm和mm->locked_vm - 执行内存描述符的
mm->unmap_area。根据进程线性区的不同类型可选择arch_unmap_area或arch_unmap_area_topdown中的一个来实现mm->unmap_area。如必要,在两种情况下都要更新mm->free_area_cache。 - 调线性区的
close - 如线性区是匿名的,则函数把它从
mm->anon_vma所指向的匿名线性区链表中删除 - 调
kmem_cache_free释放线性区描述符 - 返回
0
缺页异常处理程序
1.处理地址空间以外的错误地址
如address不属于进程的地址空间,则do_page_fault继续执行bad_area处语句。
bad_area:
up_read(&tsk->mm->mmap_sem);
bad_area_nosemaphore:
if(error_code & 4)
{
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code | (address >= TASK_SIZE);
tsk->thread.trap_no = 14;
info.si_signo = SIGSEGV;
info.si_errno = 0;
info.si_addr = (void*)address;
force_sig_info(SIGSEGV, &info, tsk);
return;
} 如错误发生在用户态,则发送一个SIGSEGV信号给current,force_sig_info确信进程不忽略或阻塞SIGSEGV信号,并通过info局部变量传递附加信息的同时把该信号发送给用户态进程;info.si_code字段已被置为SEGV_MAPERR或置为SEGV_ACCERR;
如异常发生在内核态(error_code的第2位被清0),仍有两种可选的情况:
- 异常的引起是由于把某个线性地址作为系统调用的参数传递给内核
- 异常是因一个真正的内核缺陷所引起
no_context:
if((fixup = search_exception_table(regs->eip)) != 0)
{
regs->eip = fixup;
return;
}
123456- 在第一种情况中,代码跳到一段”修正代码”处。这段代码的典型操作是向当前进程发
SIGSEGV信号,或用一个适当的出错码终止系统调用处理程序。 - 第二种情况中,函数把
CPU寄存器和内核态堆栈的全部转储打印到控制台,并输出到一个系统消息缓冲区,然后调do_exit杀死当前进程。这就是所谓按所显示的消息命名的”内核漏洞”错误。这些输出值可由内核编程高手用于推测引发此错误的条件,进而发现并纠正错误。
2.处理地址空间内的错误地址
如addr地址属于进程的地址空间,则do_page_fault转到good_area标记处的语句执行。
good_area:
info.si_code = SEGV_ACCERR;
write = 0;
if(error_code & 2)
{
if(!(vma->vm_flags & VM_WRITE))
goto bad_area;
write++;
}
else
if((error_code & 1) || !(vma->vm_flags & (VM_READ | VM_EXEC)))
goto bad_area;如异常由写访问引起,检查这个线性区是否可写。如不可写,跳到bad_area;如可写,把write局部变量置为1;如异常由读或执行访问引起,函数检查这一页是否已经存在于RAM。(权限引起)在存在的情况下,异常发生是由于进程试图访问用户态下的一个有特权的页框,故函数跳到bad_area。(NotExist引起)在不存在的情况下,函数还将检查这个线性区是否可读或可执行。如这个线性区的访问权限与引起异常的访问类型相匹配,则调handle_mm_fault分配一个新的页框
survive:
ret = handle_mm_fault(tsk->mm, vma, address, write);
if(ret == VM_FAULT_MINOR || ret == VM_FAULT_MAJOR)
{
if(ret == VM_FAULT_MINOR)
tsk->min_flt++;
else
tsk->maj_flt++;
up_read(&tsk->mm->mmap_sem);
return;
}- 如
handle_mm_fault成功给进程分配一个页框,则返回VM_FAULT_MINOR或VM_FAULT_MAJOR; - 值
VM_FAULT_MINOR表示在没阻塞当前进程的情况下处理了缺页。这种缺页叫次缺页; - 值
VM_FAULT_MAJOR表示缺页迫使当前进程睡眠,阻塞当前进程的缺页叫主缺页;
函数也返回VM_FAULT_OOM(没有足够的内存)或VM_FAULT_SIGBOS(其他任何错误);如handle_mm_fault返回值VM_FAULT_SIGBUS,则向进程发SIGBUS
if(ret == VM_FAULT_SIGBUS)
{
do_sigbus:
up_read(&tsk->mm->mmap_sem);
if(!(error_code & 4))
goto no_context;
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_no = 14;
info.si_signo = SIGBUS;
info.si_errno = 0;
info.si_code = BUS_ADRERR;
info.si_addr = (void*)address;
force_sig_info(SIGBUS, &info, tsk);
}- 如
handle_mm_fault不分配新页框,就返回VM_FAULT_OOM,此时内核通常杀死当前进程。 - 如当前进程是
init进程,则只是把它放在运行队列的末尾并调用调度程序。一旦init恢复执行,则handle_mm_fault又执行。
if(ret == VM_FAULT_OOM)
{
out_of_memory:
up_read(&tsk->mm->mmap_sem);
if(tsk->pid != 1)
{
if(error_code & 4)
do_exit(SIGKILL);
goto no_context;
}
yield();
down_read(&tsk->mm->mmap_sem);
goto survive;
}handle_mm_fault:
参数:
mm,执行异常发生时在CPU上运行的进程的内存描述符vma,执行引起异常的线性地址所在线性区的描述符address,引起异常的线性地址write_access,如tsk试图向address写,则置为1;如tsk试图在address读或执行,则置为0;
函数首先检查用来映射address的页中间目录和页表是否存在。即使address属于进程的地址空间,相应的页表也可能还没被分配。故在做别的事情前先执行分配页目录和页表的任务。
pgd = pgd_offset(mm, address);
spin_lock(&mm->page_table_lock);
pud = pud_alloc(mm, pgd, address);
if(pud)
{
pmd = pmd_alloc(mm, pud, address);
if(pmd)
{
pte = pte_alloc_map(mm, pmd, address);
if(pte)
return handle_pte_fault(mm, vma, address, write_access, pte, pmd);
}
}
spin_unlock(&mm->page_table_lock);
return VM_FAULT_OOM;pgd局部变量包含引用address的页全局目录项。如需要的话,调pud_alloc和pmd_alloc分别分配一个新的页上级目录和页中间目录;如需要,调pte_alloc_map分配一个新的页表;如这两步都成功, pte局部变量所指向的页表项就是引用address的表项。然后调handle_pte_fault检查address地址所对应的页表项,并决定如何为进程分配一个新页框:
- 如被访问的页不存在,即这个页还没被存放在任何一个页框中,则,内核分配一个新的页框并适当地初始化。这种技术称为请求调页
- 如被访问的页存在但标记为只读,即它已经被存放在一个页框中,则内核分配一个新的页框,并把旧页框的数据拷贝到新页框来初始化它的内容。这种技术称为写时复制
请求调页:
它把页框的分配推迟到不能再推迟为止。即一直推迟到进程要访问的页不在RAM中,由此引起一个缺页异常;请求调页背后的动机是:进程开始执行时并不访问其地址空间中的全部地址。事实上,一部分地址也许永远不会被进程使用。
此外,程序的局部性原理保证了在程序执行的每个阶段,真正引用的进程页只有一小部分。因此,临时用不着的页所在的页框可由其他进程来使用。故对全局分配来说,请求调页是首选的它增加了系统中空闲页框的平均数,从而更好地利用空闲内存;从另一个观点,在RAM总数保持不变下,请求调页从总体上能使系统有更大的吞吐量
为这一切优点付出的代价是系统额外的开销,由请求调页所引发的每个”缺页”异常必须由内核处理,这将浪费CPU的时钟周期。局部性原理保证了一旦进程开始在一组页上运行,在接下来相当长的一段时间内它会一直停留在这些页上而不去访问其他的页这样,就可认为”缺页”异常是一种稀有事件。
被访问的页不在主存中,其原因或者是进程从没访问过该页,或是内核已经回收了相应的页框;这两种情况下,缺页处理程序必须为进程分配新的页框;如何初始化这个页框取决于是哪一种页及页以前是否被进程访问过。特殊情况下:
- 这个页从未被进程访问到且没映射磁盘文件,或页属于线性磁盘文件的映射。内核能识别这些情况,因为页表相应的表项被填充为0,即
pte_none宏返回1。 - 页属于非线性磁盘文件的映射。内核能识别这种情况,因为
Present标志被清0,且Dirty被置1。即pte_file返回1 - 进程已访问过这个页,但其内容被临时保存在磁盘上。内核能识别这种情况,因为相应的表项没被填充为
0,但Present,Dirty被清0。
故handle_pte_fault通过检查address对应的页表项能区分三种情况
entry = *pte;
if(!pte_present(entry))// P是0
{
if(pte_none(entry))// 其余位也是0--no_page
return do_no_page(mm, vma, address, write_access, pte, pmd);
if(pte_file(entry))// Dirty是1-file_page
return do_file_page(mm, vma, address, write_access, pte, pmd);
return do_swap_page(mm, vma, address, pte, pmd, entry, write_access);// Dirty是0。swap_page
}在情况1下,当页从未被访问或页线性地映射磁盘文件时则调do_no_page;有两种方法装入所缺的页。这取决于这个页是否被映射到一个磁盘文件。该函数通过检查vma线性区描述符的nopage字段来确认。如页被映射到一个文件,nopage就指向一个函数,该函数把所缺的页从磁盘装入RAM。因此,可能的情况是:
vma->vm_ops->nopage字段不为NULL。此情况下,线性区连续映射磁盘文件。nopage指向装入页的函数。(用磁盘文件内容填充页框。)vma->vm_ops为NULL或vma->vm_ops->nopage为NULL。这情况下,线性区没映射磁盘文件,即它是一个匿名映射。故do_no_page调do_anonymous_page获得一个新的页框。(仅仅分配页框,不填充,或填充0)
if(!vma->vm_ops || !vma->vm_ops->nopage)
return do_anonymous_page(mm, vma, page_table, pmd, write_access, address);
12do_anonymous_page分别处理写请求,读请求
if(write_access)
{
pte_unmap(page_table);// 这里的page_table是pte_t表示一个页表项
spin_unlock(&mm->page_table_lock);
page = alloc_page(GFP_HIGHUSER | __GFP_ZERO);
spin_lock(&mm->page_table_lock);
page_table = pte_offset_map(pmd, addr);
mm->rss++;
entry = maybe_mkwrite(pte_mkdirty(mk_pte(page, vma->vm_page_prot)), vma);
lru_cache_add_active(page);
SetPageReferenced(page);
set_pte(page_table, entry);
pte_unmap(page_table);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR;
}pte_unmap的第一次执行释放一种临时内核映射,它映射了在调handle_pte_fault之前由pte_offset_map所建立页表项的高端内存物理地址;pte_offset_map和pte_unmap对获取和释放同一个临时内核映射。
临时内核映射需在调alloc_page之前释放,因为这个函数可能阻塞当前进程。函数递增内存描述符的rss字段以记录分配给进程的页框总数,相应的页表项设置为页框的物理地址;页表框被标记为既脏又可写的。lru_cache_add_active把新页框插入与交换相关的数据结构中。(匿名页框是可以被交换到磁盘的)
当处理读访问时,页的内容是无关紧要的,因为进程第一次对它访问。给进程一个填充为0的页要比给它一个由其他进程填充了信息的旧页更安全。Linux在请求调页方面做的更深入些。没必要立即给进程分配一个填充为0的新页框。我们可给它一个现有的称为零页的页,这样可进一步推迟页框的分配;零页在内核初始化期间被静态分配,并存放在empty_zero_page。因此,用零页的物理地址设置页表项。
entry = pte_wrprotect(mk_pte(virt_to_page(empty_zero_page), vma->vm_page_prot));
set_pte(page_table, entry);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR:由于这个页被标记为不可写,故如进程试图写这个页,则写时复制被激活。当且仅当此时,进程才获得一个属于自己的页并对它进行写操作。
写时复制:
第一代Unix发出fork系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为非常耗时,它需要:
- 为子进程的页表分配页框
- 为子进程的页分配页框
- 初始化子进程的页表
- 把父进程的页复制到子进程相应的页中
现在的Unix内核(包括Linux)采用一种更有效的方法:写时复制;
父进程和子进程共享页框而不是复制页框。只要页框被共享,它们就不能被修改;无论父进程还是子进程何时试图写一个共享的页框,就产生一个异常;这时内核就把这个页复制到一个新的页框并标记为可写,原来的页框仍是写保护的;当其他进程试图写入时,内核检查写进程是否是这个页框的唯一属主。如是,就把这个页框标记为对这个进程是可写的
页描述符的_count用于跟踪共享相应页框的进程数目,只要进程释放一个页框或在它上面执行写时复制。它的_count就减小,只有当_count变为-1时,这个页框才被释放。
我们讲述Linux如何实现写时复制。
handle_pte_fault:
当handle_pte_fault确定缺页异常由访问内存中现有的一个页而引起时,它执行
if(pte_present(entry))
{
if(write_access)
{
if(!pte_write(entry))
return do_wp_page(mm, vma, address, pte, pmd, entry);
entry = pte_mkdirty(entry);
}
entry = pte_mkyong(entry);
set_pte(pte, entry);
flush_tbl_page(vma, address);
pte_unmap(pte);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR;
} handle_pte_fault与体系结构无关,它考虑任何违背页访问权限的可能。
在80x86体系结构上,如页是存在的,则访问权限是写允许的而页框是写保护的。故总是要调do_wp_page。do_wp_page先获取与缺页异常相关的页框描述符。接下来,确定页的复制是否真正必要。如仅有一个进程拥有这个页,则写时复制不必应用,进程应自由写该页。具体说,函数读取页描述符的_count,如它等于0,写时复制就不必。实际上,检查稍微复杂些,因为当页插入到交换高速缓存且设置了页描述符的PG_private时,_count也增加。不过,写时复制不进行时,就把该页框标记为可写的
set_pte(page_table, maybe_mkwrite(pte_mkyong(pte_mkdirty(pte)), vma));
flush_tlb_page(vma, address);
pte_unmap(page_table);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR; 如两个或多个进程通过写时复制共享页框,则函数就把旧页框的内容复制到新分配的页框。为避免竞争条件,在开始复制操作前调get_page把old_page使用计数加1:
old_page = pte_page(pte);
pte_unmap(page_table);
get_page(old_page);
spin_unlock(&mm->page_table_lock);
if(old_page == virt_to_page(empty_zero_page))
new_page = alloc_page(GFP_HIGUUSER | __GFP_ZERO);
else
{
new_page = alloc_page(GFP_HIGHUSER);
vfrom = kmap_atomic(old_page, KM_USER0);
vto = kmap_atomic(new_page, KM_USER1);
copy_page(vto, vfrom);
kunmap_atomic(vfrom, KM_USER0);
kunmap_atomic(vto, KM_USER0)
} 如旧页框是零页,就在分配新的页框时(__GFP_ZERO)把它填充为0。否则,使用copy_page复制页框内容。因为页框的分配可能阻塞进程,故函数检查自从函数开始执行以来是否已修改了页表项。如是,新的页框被释放。old_page的使用计数器减少,结束。如所有事情进展顺利, 则新页框的物理地址最终被写进页表项,且相应的tlb寄存器无效
spin_lock(&mm->page_table_lock);
entry = maybe_mkwrite(pte_mkdirty(mk_pte(new_page, vma->vm_page_prot)), vma);
set_pte(page_table, entry);
flush_tlb_page(vma, address);
lru_cache_add_active(new_page);
pte_unmap(page_table);
spin_unlock(&mm->page_table_lock);
1234567lru_cache_add_active把新页框插入到与交换相关的数据结构中。最后,do_wp_page把old_page的使用计数器减少两次。第一次减少是取消复制页框内容之前进行的安全性增加,第二次的减少是反映当前进程不再拥有该页框这一事实
处理非连续内存区访问:
内核在更新非连续内存区对应的页表项时是非常懒惰的。事实上,vmalloc和vfree只把自己限制在更新主内核页表。一旦内核初始化阶段结束,任何进程或内核线程便都不直接使用主内核页表。因此,考虑内核态进程对非连续内存区的第一次访问,当把线性地址转换为物理地址时,CPU的内存管理单元遇到空的页表项并产生一个缺页。但缺页异常处理程序认识这种特殊情况,因为异常发生在内核态且产生缺页的线性地址大于TASK_SIZE。故do_page_fault检查相应的主内核页表项
vmalloc_fault:
asm("movl %%cr3,%0":"=r"(pgd_paddr));
pgd = pgd_index(address) + (pgd_t*)__va(pgd_paddr);
pgd_k = init_mm.pgd + pgd_index(address);
if(!pgd_present(*pgd_k))
goto no_context;
pud = pud_offset(pgd, address);
pud_k = pud_offset(pgd_k, address);
if(!pud_present(*pud_k))
goto no_context;
pmd = pmd_offset(pud, offset);
pmd_k = pmd_offset(pud_k, address);
if(!pmd_present(*pmd_k))
goto no_context;
set_pmd(pmd, *pmd_k);
pte_k = pte_offset_kernel(pmd_k, address);
if(!pte_present(*pte_k))
goto no_context;
return; 把存放在cr3寄存器中的当前进程页全局目录的物理地址赋给局部变量pgd_paddr,把与pgd_paddr相应的线性地址赋给局部变量pgd,且把主内核页全局目录的线性地址赋给pgd_k局部变量。如产生缺页的线性地址所对应的主内核页全局目录项为空,则函数跳到标号为no_context代码处。否则,函数检查与错误线性地址相对应的主内核页上级目录项和主内核页中间目录项。如它们中有一个为空,就再次跳到no_context处。否则,就把主目录项复制到进程页中间目录的相应项中。随后,对主页表项重复上述整个操作
缺页异常主程序
如前,Linux的缺页异常处理程序必须区分以下两种情况:
由编程错误所引起的异常,
由引用属于进程地址空间但还尚未分配物理页框的页所引起的异常。
线性区描述符可让缺页异常处理程序非常有效的完成它的工作。do_page_fault是80x86上的缺页异常中断服务程序,它把引起缺页的线性地址和当前进程的线性区相比较,从而能选择适当方法处理这个异常。
if(地址属于进程的地址空间)
if(访问类型与线性区的访问权限匹配)
合法访问。分配一个新的页面
else
非法访问。发送一个SIGSEGV信号
else
if(异常发生在用户态)
非法访问,发送一个SIGSEGV信号
else
内核错误,杀死进程 实际中,情况更复杂。因为缺页处理程序必须处理多种分得更细的特殊情况,它们不宜在总体方案中列出来,还必须区分许多种合理的访问。标识符vmalloc_fault,good_area,bad_area和no_context是出现在do_page_fault中的标记,它们有助于你理清流程图中的块与代码中特定行之间的关系。
do_page_fault接收参数:
pt_regs结构的地址regs,结构包含当异常发生时的微处理器寄存器的值三位的
error_code,当异常发生时由控制单元压入栈中。这些位有以下含义:- 如第
0位被清0,则异常由访问一个不存在的页引起,否则,如第0位被设置,则异常由无效的访问权限引起 - 如第
1位被清0,则异常由读访问或执行访问所引起;如该位被设置,则异常由写访问所引起 - 如第
2位被清0,则异常发生在处理器处于内核态时,否则, 异常发生在处理器处于用户态时。
- 如第
do_page_fault的第一步操作是读取引起缺页的线性地址。异常发生时,CPU控制单元把这个值存放在cr2控制寄存器中
asm("movl %%cr2, %0":"=r"(address));
if(regs->eflags & 0x00020200)
local_irq_enable();
tsk = current;这个线性地址保存在address。如缺页发生之前或CPU运行在虚拟8086模式时,打开了本地中断,则该函数还要确保本地中断打开,并把指向current进程描述符的指针保存在tsk局部变量中。
do_page_fault首先检查引起缺页的线性地址是否属于第4个GB:
info.si_code = SEGV_MAPERR;
if(address >= TASK_SIZE)
{
if(!(error_code & 5))
goto vmalloc_fault;
goto bad_area_nosemaphore;
} 如发生了由于内核试图访问不存在的页框引起的异常,就跳转去执行vmalloc_fault。该部分代码处理可能由于在内核态访问非连续内存区而引起的缺页。否则,就跳转去执行bad_area_nosemaphore。接下来,缺页处理程序检查异常发生时是否内核正在执行一些关键例程或正在运行内核线程
if(in_atomic() || !tsk->mm)
goto bad_area_nosemaphore;如缺页发生在下面任何一种情况下,则in_atomic产生等于1的值
- 内核正在执行中断处理程序或可延迟函数
- 内核正在禁用内核抢占的情况下执行临界区代码,如缺页的确发生在中断处理程序,可延迟函数,临界区,或内核线程中。
do_page_fault就不会试图把这个线性地址与current的线性区做比较。内核线程从来不使用小于TASK_SIZE的地址。
同样,中断处理程序,可延迟函数,临界区代码(这三者也在内核代码段)也不应使用小于TASK_SIZE的地址,因为这可能导致当前进程的阻塞。
我们假定缺页没发生在中断处理程序,可延迟函数,临界区或内核线程中。于是,函数必须检查进程所拥有的线性区以决定引起缺页的线性地址是否包含在进程的地址空间中,为此,必须获得进程的mmap_sem读写信号量。
if(!down_read_trylock(&tsk->mm->mmap_sem))
{
if((error_code & 4) == 0 && !search_exception_table(regs->eip))
goto bad_area_nosemaphore;
down_read(&tsk->mm->mmap_sem);
} 如内核bug和硬件故障有可能被排除,则当缺页发生时,当前进程就还没为写而获得信号量mmap_sem。尽管如此,do_page_fault还是想确定的确没获得这个信号量。因为如果不是这样就会发生死锁。
所以,函数用down_read_trylock而不是down_read。如这个信号量被关闭且缺页发生在内核态,do_page_fault就要确定异常发生的时候,是否正使用作为系统调用参数被传递给内核的线性地址。此时,因为每个系统调用服务例程都小心地避免在访问用户态地址空间以前为写而获得mmap_sem信号量,故do_page_fault确信mmap_sem信号量由另外一个进程占有了,从而do_page_fault一直等到该信号量被释放。否则,如缺页是由于内核bug或严重的硬件故障引起的,就跳到bad_area_nosemaphore标记处。假设已为读而获得了mmap_sem信号量。现在,do_page_fault开始搜索错误线性地址所在的线性区
vma = find_vma(tsk->mm, address);
if(!vma)
goto bad_area;
if(vma->vm_start <= address)
goto good_area; 如vma为NULL,说明address之后没线性区,因此这个错误的地址肯定是无效的,另一方面,如在address之后结束的第一个线性区包含address,则函数跳到标记为good_area的代码处。
如两个if都不满足,函数已确定address没包含在任何线性区中。可它还必须执行进一步的检查,由于这个错误地址可能是由push或pusha指令在进程的用户态堆栈上的操作所引起的。解释下栈如何映射到线性区上的。
每个向低地址扩展的栈所在的区,它的VM_GROWSDOWN标志被设置,这样,当vm_start字段的值可能被减小的时候,而vm_end保持不变。这种线性区的边界包括,但不严格限定用户态堆栈当前的大小。这种细微差别主要基于:
- 线性区的大小是4KB的倍数,栈的大小是任意的
- 分配给一个线性区的页框在这个线性区被删除前永远不被释放。尤其是,一个栈所在线性区的
vm_start字段的值只能减少,永远不能增加。甚至进程执行一系列pop指令时,这个线性区的大小仍保持不变
当进程填满分配给它的堆栈的最后一个页框后,进程如何引起一个”缺页”异常。push引用了这个线性区以外的一个地址(即引用一个不存在的页框)。这种异常不是由程序错误引起, 它必须由缺页处理程序单独处理
if(!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
if(error_code & 4 && address + 32 < regs->esp)
goto bad_area;
if(expand_stack(vma, address))
goto bad_area;
goto good_area; 如线性区的VM_GROWSDOWN被设置,且异常发生在用户态,函数就检查address是否小于regs->esp栈指针。几个与栈相关的汇编语言指令只有在访问内存之后才执行减esp寄存器的操作,所以允许进程有32字节的后备区间。如这个地址足够高,则代码调expand_stack函数检查是否允许进程既扩展它的栈也扩展它的地址空间。如一切都可以,就把vma的vm_start设为address,且返回0。否则,返回-ENOMEM
只要线性区的VM_GROWSDOWN标志被设置,但异常不是发生在用户态,上述代码就跳过容错检查。这些条件意味着内核正访问用户态的栈,意味着这段代码总是应运行expand_stack–缺页异常能看懂每处处理,但整理的显得杂乱。应该由自己结合源码进行更好的整理输出。
创建和删除进程的地址空间
1.创建进程的地址空间
之前的clone,fork,vfork已经提到,当创建一个新的进程时内核调copy_mm,这个函数通过建立新进程的所有页表和内存描述符来创建进程的地址空间。通常,每个进程有自己的地址空间,但轻量级进程可通过调clone来创建。这些轻量级进程共享同一地址空间,即允许它们对同一组页进行寻址。
按前面写时复制,传统的进程继承父进程的地址空间,只要页是只读的,就依然共享它们,当其中一个进程试图对某个页写时,这个页就被复制一份。一段时间后,所创建的进程通常获得与父进程不一样的完全属于自己的地址空间。
轻量级进程使用父进程的地址空间,Linux实现轻量级进程很简单,即不复制父进程地址空间,创建轻量级进程比创建普通进程相应快的多,且只要父进程和子进程谨慎地协调它们的访问,就认为页的共享是有益的。如通过clone已经创建了新进程且flag参数的CLONE_VM被设置,则copy_mm把父进程地址空间给子进程
if(clone_flags & CLONE_VM)
{
atomic_inc(¤t->mm->mm_users);
spin_unlock_wait(¤t->mm->page_table_lock);
tsk->mm = current->mm;
tsk->active_mm = current->mm;
return 0;
} 如其他CPU持有进程页表自旋锁,就调spin_unlock_wait保证在释放锁前,缺页处理程序不会结束。
实际上,这个自旋锁除了保护页表外,还需禁止创建新的轻量级进程,因为它共享current->mm描述符。
如没设置CLONE_VM,copy_mm就需创建一个新的地址空间,这个函数分配一个新的内存描述符,把它的地址存放在新进程描述符tsk的mm中,并把current->mm的内容复制到tsk->mm。然后,改变新进程描述符的一些字段
tsk->mm = kmem_cache_alloc(mm_cachep, SLAB_KERNEL);
memcpy(tsk->mm, current->mm, sizeof(*tsk->mm));
atomic_set(&tsk->mm->mm_users, 1);
atomic_set(&tsk->mm->mm_count, 1);
init_rwsem(&tsk->mm->mmap_sem);
tsk->mm->core_waiters = 0;
tsk->mm->page_table_lock = SPIN_LOCK_UNLOCKED;
tsk->mm->ioctx_list_lock = RW_LOCK_UNLOCKED;
tsk->mm->ioctx_list = NULL;
tsk->mm->default_kioctx = INIT_KIOCTX(tsk->mm->default_kioctx, *tsk->mm);
tsk->mm->free_area_cache = (TASK_SIZE/3 + 0xfff) & 0xfffff000;
tsk->mm->pgd = pgd_alloc(tsk->mm);
tsk->mm->def_flags = 0; pgd_alloc为新进程分配页全局目录。然后,调依赖于体系结构的init_new_context。对80x86,函数检查当前进程是否拥有定制的局部描述符表。如是,init_new_context复制一份current的局部描述符表并把它插入tsk的地址空间。最后,调dup_mmap既复制父进程的线性区,也复制父进程的页。dup_mmap把新内存描述符tsk->mm插入到内存描述符的全局链表中。然后,从current->mm->mmap所指向的线性区开始扫描父进程的线性区链表。它复制遇到的每个vm_area_struct线性区描述符,把复制品插入到子进程的线性区链表和红-黑树
在插入一个新的线性区描述符后,如需要,dup_mmap立即调copy_area_range创建必要的页表来映射这个线性区所包含的一组页且初始化新页表的表项,尤其是,与私有的,可写的页(VM_SHARED关闭,VM_MAYWRITE打开)所对应的任一页框都标记为对父子进程是只读的,以便这种页框能用写时复制机制进行处理。
2.删除进程的地址空间
进程结束时,调exit_mm释放进程的地址空间
mm_release(tsk, tsk->mm);
if(!(mm != tsk->mm))
return;
down_read(&mm->mmap_sem); mm_release唤醒在tsk->vfork_done补充原语上睡眠的任一进程。典型地,只当现有进程通过vfork被创建时,相应的等待队列才为非空,如正被终止的进程不是内核线程,exit_mm就需释放内存描述符和所有相关的数据结构。首先,它检查mm->core_waiters是否被置位。如是,进程把内存的所有内存转储到一个转储文件。为避免转储文件混乱,用mm->core_done和mm->core_startup_done补充原语使共享同一个内存描述符mm的轻量级进程的执行串行化。
函数递增内存描述符的主使用计数器,重新设置进程描述符的mm,使处理器处于懒惰TLB模式
atomic_inc(&mm->mm_count);
spin_lock(tsk->alloc_lock);
tsk->mm = NULL;
up_read(&mm->map_sem);
enter_lazy_tlb(mm, current);
spin_unlock(tsk->alloc_lock);
mmput(mm);
1234567 最后,调mmput释放局部描述符表,线性区描述符,页表。因为,exit_mm已经递增了主使用计数器,所以并不释放内存描述符本身。当要把正在被终止的进程从本地CPU撤销时,将由finish_task_switch释放内存描述符
堆的管理
每个Unix进程都有一个特殊的线性区,这个线性区就是堆,堆用于满足进程的动态内存请求。内存描述符的start_brk和brk分别限定了这个区的开始地址,结束地址。
进程可用下面API来请求和释放动态内存:malloc(size),分配成功时,返回所分配内存单元第一个字节的线性地址calloc(n, size),请求含n个大小为size的元素的一个数组。分配成功时,数组元素初始化为0,返回首个元素线性地址realloc(pte, size),分配新线性区域,将pte老区域内容拷贝到新区域起始部分free(addr),释放由malloc或calloc分配的起始地址为addr的线性区brk(addr),直接修改堆的大小,addr指定current->mm->brk新值,返回值是线性区新的结束地址sbrk(incr),incr指定是增加还是减少以字节为单位的堆大小
brk是唯一以系统调用的方式实现的函数。
其他所有函数都是使用brk和mmap系统调用实现的c语言库函数。
用户态进程调brk时,内核执行sys_brk(addr)。
函数先验证addr参数是否位于进程代码所在的线性区,如是,立即返回。因为堆不能与进程代码所在的线性区重叠。
mm = current->mm;
down_write(&mm->mmap_sem);
if(addr < mm->end_code)
{
out:
up_write(&mm->mmap_sem);
return mm->brk;
}由于brk系统调用作用于某一个线性区,它分配和释放完整的页;
故函数把addr值调整为PAGE_SIZE的倍数。然后,把调整的结果与内存描述符的brk字段值比较:
newbrk = (addr + 0xfff) & 0xfffff000;
oldbrk = (mm->brk + 0xfff) & 0xfffff000;
if(oldbrk == newbrk)
{
mm->brk = addr;
goto out;
}如进程请求缩小堆,则sys_brk调do_munmap完成这项任务,然后返回
if(addr <= mm->brk)
{
if(!do_munmap(mm, newbrk, oldbrk-newbrk))// 撤销内存映射允许在大的映射内撤销局部
mm->brk = addr;
goto out;
}如进程请求扩大堆,则sys_brk先检查是否允许进程这样做。
如进程企图分配在其限制范围外的内存,函数并不多分配内存,只简单返回mm->brk原有值
rlim = current->signal->rlim[RLIMIT_DATA].rlim_cur;
if(rlim < RLIM_INFINITY && addr - mm->start_data > rlim)
goto out;函数检查扩大后的堆是否和进程的其他线性区重叠。如是,不做任何事情就返回
if(find_vma_intersection(mm, oldbrk, newbrk + PAGE_SIZE))
goto out;如一切都顺序,则调do_brk,如它返回oldbrk,则分配成功且sys_brk返回addr的值。否则,返回旧的mm->brk值
if(do_brk(oldbrk, newbrk-oldbrk) == oldbrk)// 执行扩展现有映射区域。在现有线性区随后,再次申请线性区。并触发合并。
mm->brk = addr;
goto out;do_brk实际上仅处理匿名线性区的do_mmap的简化版。可认为它的调用等价于
do_mmap(NULL, oldbrk, newbrk-oldbrk, PROT_READ|PROT_WRITE|PROT_EXEC, MAP_FIXED|MAP_PRIVATE, 0);do_brk比do_mmap稍快,因为前者假定线性区不映射磁盘上的文件,从而避免了检查线性区对象的几个字段
系统调用
欸!回想起来我们用户层是如何与内核层进行交流的呢?或者说是如何请求服务的呢?那正是使用系统调用这个概念!使得用户层同下方的内核层架起交流的大桥!
回顾一下优点:
- 使得编程更加容易,把用户从学习硬件设备的低级编程特性中解放出来.(你真的不需要看手册写程序!)
- 极大提高了系统的安全性,内核在试图满足某个请求前在接口级就可检查这种请求的正确性.
- 接口使得程序更具有可移植性.接口使得程序更具有可移植性.
Unix系统通过向内核发出系统调用实现了用户态进程和硬件设备间的大部分接口.
POSIX API和系统调用
API:一个函数定义,说明了如何获得一个给定的服务.
系统调用:通过软中断向内核态发出一个明确的请求.
Unix系统给程序员提供了很多API的库函数。libc的标准C库所定义的一些API引用了封装例程。通常下,每个系统调用应对应一个封装例程,而封装例程定义了应用程序使用的API.
一个API没必要对应一个特定的系统调用。
- 首先,
API可能直接提供用户态的服务。 - 其次,一个单独的
API函数可能调几个系统调用。Posix标准针对API而不针对系统调用,判断一个系统是否与POSIX兼容要看它是否提供了一组合适的应用程序接口,而不管对应的函数是如何实现的。
事实上,一些非Unix系统被认为是与POSIX兼容的。因为它们在用户态的库函数中提供了传统Unix能提供的所有服务.
从编程者观点看,API和系统调用间的差别没关系:唯一相关的事情就是函数名,参数类型,返回代码的含义。从内核设计者观点看,这种差别确实有关系,因为系统调用属于内核,用户态的库函数不属于内核.
大部分封装例程返回一个整数,其值的含义依赖于相应的系统调用。返回值-1通常表示内核不能满足进程的要求。在libc库中定义的errno变量包含特定的出错码。
系统调用处理程序及服务例程
当用户态的进程调一个系统调用时,CPU切换到内核态并开始执行一个内核函数。在80x86体系结构中,可用两种不同的方式调Linux的系统调用。两种方式的最终结果都是跳转到所谓系统调用处理程序的汇编语言函数.
因为内核实现了很多不同的系统调用,故进程必须传递一个名为系统调用号的参数来识别所需的系统调用,eax寄存器就用作此目的。当调用一个系统调用时通常还要传递另外的参数.
所有的系统调用都返回一个整数值,这些返回值与封装例程返回值的约定不同,在内核中,正数或0表示系统调用成功结束,负数表示一个出错条件。后一种情况下,这个值就是存放在errno中必须返回给应用的负出错码。内核没设置或使用errno变量,而封装例程从系统调用返回后设置这个变量。
系统调用处理程序与其他异常处理程序结构类似,执行:
- 在内核态保存大多数寄存器的内容.
- 调名为系统调用服务例程的相应
C函数来处理系统调用.- 退出系统调用处理程序:用保存在内核栈中的值加载寄存器,
CPU从内核态切换回用户态.
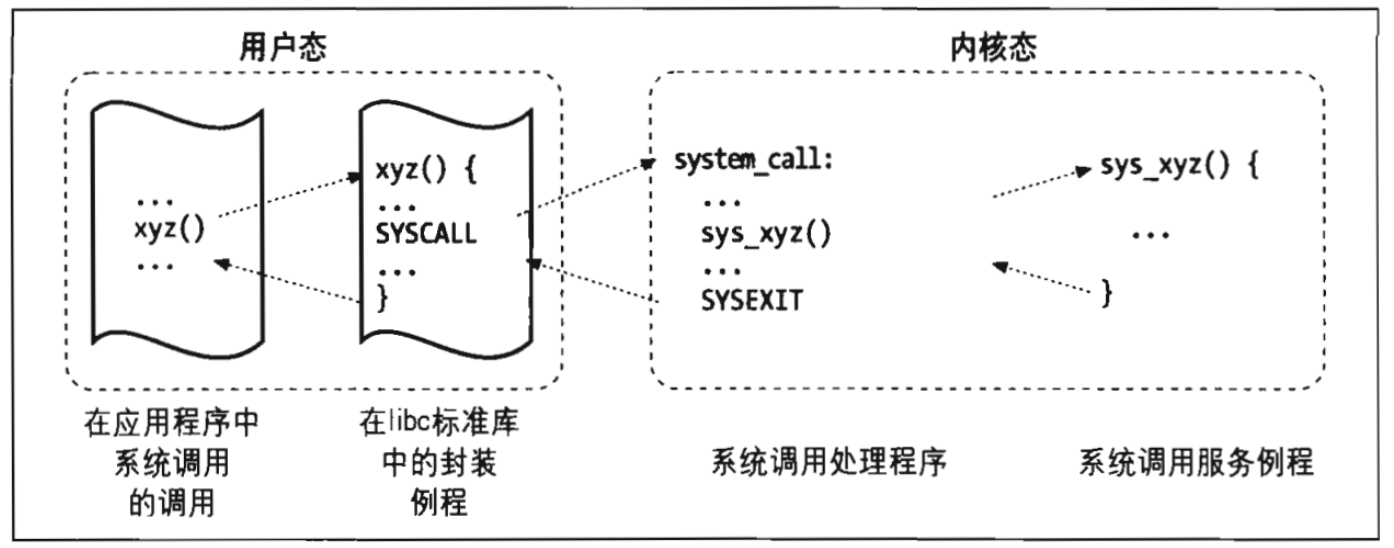
上面这个图深切的说明了我们的架构是如何搭建的——另外,图来自《深入理解Linux内核》
为了把系统调用号与相应的服务例程关联起来,内核利用了一个系统调用分派表。这个表存放在sys_call_table数组,有NR_syscalls个表项,第n个表项包含系统调用号为n的服务例程的地址。NR_syscalls只是对可实现的系统调用最大个数的静态限制,并不表示实际已实现的系统调用个数。实际上,分派表中的任意一个表项也可包含sys_ni_syscall函数的地址。这个函数是"未实现"系统调用的服务例程,它仅仅返回出错码-ENOSYS.
进入和退出系统调用
本地应用可通过两种不同方式调系统调用:
- 执行
int $0x80,在Linux内核老版本,这是从用户态切换到内核态的唯一方式。(手写过OS的都知道)- 执行
sysenter,在Intel Pentium 2中引入了这条指令,Linux 2.6内核支持此指令。
同样,内核可通过两种方式从系统调用退出,从而使CPU切换回用户态
- 执行
iret- 执行
sysexit
但支持进入内核的两种不同方式不像看起来那么简单:
- 内核必须既支持只使用
int $0x80;也支持sysenter.- 使用
sysenter的标准库必须能处理仅支持int $0x80的旧内核.- 内核和标准库必须既能运行在不包含
sysenter指令的旧处理器上;也能运行在包含它的新处理器上.
通过int $0x80发出系统调用
中断向量128对应于内核入口点,在内核初始化期间调的函数trap_init用下面的方式建立对应于向量128的中断描述符表项:
set_system_gate(0x80, &system_call);该调用把下列值存入这个门描述符的相应字段
| 字段 | 说明 |
|---|---|
Segment Selector |
内核代码段__KERNEL_CS的段选择符. |
Offset |
指向system_call系统调用处理程序的指针. |
Type |
15,表示这个异常是一个陷阱。相应的处理程序不禁止可屏蔽中断. |
DPL |
3,允许用户态进程调这个异常处理程序. |
当用户态进程发出int $0x80时,CPU切换到内核态并开始从地址system_call处开始执行指令.
system_call
首先把系统调用号和这个异常处理程序可用到的所有CPU寄存器保存到相应栈,不包含由控制单元已自动保存的eflags,cs,eip,ss和esp。在第4章已经讨论的SAVE_ALL,也在ds和es中装入内核数据段的段选择符.
system_call:
pushl %eax
SAVE_ALL
movl $0xffffe000, %ebx
andl %esp, %ebx 随后,这个函数在ebx中存放当前进程的thread_info的地址。这是通过获得内核栈指针的值并把它取整到4KB或8KB的倍数而完成的
接下来,system_call检查thread_info结构flag字段的TIF_SYSCALL_TRACE和TIF_SYSCALL_AUDIT之一是否被设置为1,即检查是否有某一调试程序正在跟踪执行程序对系统调用的调用。如是,则system_call两次调do_syscall_trace:一次正好在这个系统调用服务例程执行前,一次在其之后,这个函数停止current,并因此允许调试进程收集关于current的信息。然后, 对用户进程传递来的系统调用号进行有效性检查。如这个号大于或等于系统调用分派表中的表项数,系统调用处理程序就终止
cmpl $NR_syscalls, %eax
jb nobadsys
movl $(-ENOSYS), 24(%esp)
jmp resume_userspace
nobadsys: 如系统调用号无效,该函数就把-ENOSYS值存放在栈中曾保存eax寄存器的单元中(从当前栈顶开始偏移量为24的单元),然后跳到resume_userspace。这样,当进程恢复它在用户态的执行时,会在eax中发现一个负的返回码。最后,调与eax中所包含的系统调用号对应的特定服务例程.
call *sys_call_table(0, %eax, 4) 因为分派表中的每个表项占4个字节,故首先把系统调用号乘以4,再加上sys_call_table分派表的起始地址。然后从这个地址单元获取指向服务例程的指针,内核就找到了要调用的服务例程.
从系统调用退出
当系统调用服务例程结束时,system_call从eax获得它的返回值,把这个返回值存放在曾保存用户态eax寄存器值的那个栈单元的位置上.
movl %eax, 24(%esp) 故用户态进程将在eax中找到系统调用的返回码。然后,system_call关闭本地中断并检查当前进程的thread_info结构中的标志.
cli
movl 8(%ebp), %ecx
testw $0xffff, %cx
je restore_all flags字段在thread_info结构中的偏移量为8,所有标志都没设置,函数就跳到restore_all。restore_all恢复保存在内核栈中的寄存器的值,并执行iret以重新开始执行用户态进程.
只要任何一种标志被设置,则就要在返回用户态之前完成一些工作。如TIF_SYSCALL_TRACE被设置,system_call就第二次调do_syscall_trace,然后跳到resume_userspace;否则,如TIF_SYSCALL_TRACE没被设置,就跳到work_pending。在resume_userspace和work_pending处的代码检查重新调度请求,虚拟8086模式,挂起信号,单步执行,最终跳到restore_all处以恢复用户态进程的运行.
通过sysenter发出系统调用
int由于要执行几个一致性检查和安全性检查,故速度慢。在Intel文档中被称为”快速系统调用”的sysenter指令,提供了一种从用户态到内核态的快速切换方法.
sysenter
使用三种特殊的寄存器,它们需装入以下信息
| 字段 | 说明 |
|---|---|
SYSENTER_CS_MSR |
内核代码段的段选择符. |
SYSENTER_EIP_MSR |
内核入口点的线性地址. |
SYSENTER_ESP_MSR |
内核堆栈指针. |
执行sysenter指令时,CPU控制单元:
- 把
SYSENTER_CS_MSR内容拷贝到cs. - 把
SYSENTER_EIP_MSR内容拷贝到eip. - 把
SYSENTER_ESP_MSR内容拷贝到esp. - 把
SYSENTER_CS_MSR加8值装入ss.
故CPU切换到内核态并开始执行内核入口点的第一条指令.
在内核初始化期间,一旦系统中的每个CPU执行enable_sep_cpu,三个特定于模型的寄存器就由该函数初始化。enable_sep_cpu执行:
- 把内核代码
__KERNEL_CS的段选择符写入SYSENTER_CS_MSR. - 把下面要说明的函数
sysenter_entry的线性地址写入SYSENTER_CS_EIP. - 计算本地
TSS末端的线性地址,把这个值写入SYSENTER_CS_ESP,对SYSENTER_CS_ESP的设置有必要进行一些说明。
系统调用开始的时候,内核堆栈是空的。故esp寄存器应指向4KB或8KB内存区域的末端。该内存区域包括内核堆栈和当前进程的描述符,因为用户态的封装例程不知这个内存区域的地址,所以它不能正确设置此寄存器。另一方面,必须在切换到内核态前设置该寄存器的值。故内核初始化这个寄存器以便为本地CPU的任务状态段编址。
每次进程切换时,内核把当前进程的内核栈指针保存到本地TSS的esp0。这样,系统调用处理程序读esp,计算本地TSS的esp0,把正确的内核堆栈指针装入esp.
vsyscall页
只要CPU和Linux都支持sysenter,标准库libc中的封装函数就可使用。这个兼容性问题需要复杂的解决方案。本质上,初始化阶段sysenter_setup建立一个称为vsyscall页的页框。其中包括一个小的EFL共享对象(一个小的EFL动态链接库),当进程发出execve开始执行一个ELF程序时,vsyscall页中的代码会自动被链接到进程的地址空间,vsyscall页中的代码使用最有用的指令发出系统调用.
sysenter_setup为vsyscall页分配一个新页框,把它的物理地址与FIX_VSYSCALL固定映射的线性地址相关联。函数sysenter_setup把预先定义好的一个或两个EFL共享对象拷贝到该页.
如CPU不支持sysenter,sysenter_setup建立一个包含下列代码的vsyscall页
__kernel_vsyscall:
int $0x80
ret否则,如CPU的确支持sysenter,sysenter_setup建立一个包括下列代码的vsyscall页
__kernel_vsyscall:
pushl %ecx
pushl %edx
pushl %ebp
movl %esp, %ebp
sysenter当标准库中的封装例程必须调系统调用时,调__kernel_vsyscall,不管它的实现代码是什么,最后一个兼容问题是由于老版本Linux内核不支持sysenter。此情况下,内核当然不建立vsyscall页,且函数__kernel_vsyscall不会被链接到用户态进程的地址空间,当新近的标准库识别这种状况后,简单执行int $0x80调系统调用
进入系统调用
当用sysenter发出系统调用时,依次执行下述:
标准库的封装例程把系统调用号装入
eax寄存器调__kernel_vsyscall__kernel_vsyscall把ebp,edx,ecx的内容保存到用户态堆栈(系统调用处理程序将使用这些寄存器),把用户栈指针拷贝到ebp,执行sysenterCPU从用户态切换到内核态,内核开始执行sysenter_entry(由SYSENTER_EIP_MSR指向)sysenter_enter执行下述:建立内核堆栈指针,
movl -508(%esp), %esp,开始时,esp寄存器指向本地TSS的第一个位置,本地TSS的大小为512字节。故sysenter把本地TSS中偏移量为4处的字段的内容(esp0)装入esp。esp0总是存放当前进程的内核堆栈指针打开本地中断,
sti。把用户数据段的段选择符,当前用户栈指针,
eflags,用户代码段的段选择符及从系统调用退出时要执行的指令的地址保存到内核堆栈pushl $(__USER_DS) pushl %ebp pushfl pushl $(__USER_CS) pushl $SYSENTER_RETURN这些指令仿效
int所执行的一些操作把原来由封装例程传递的寄存器的值恢复到
ebp,movl (%ebp), %ebp,上面这指令完成恢复工作,因为__kernel_vsyscall把ebp原始值存入用户态堆栈,在随后把用户堆栈指针的当前值装入ebp通过执行一系列指令调用系统调用处理程序,这些指令与前面通过
int $0x80指令发出系统调用。一节描述的在system_call处开始的指令是一样的
退出系统调用
系统调用服务例程结束时,sysenter_entry本质上执行与system_call相同的操作
首先,它从eax获得系统调用服务例程的返回码,将返回码存入内核栈中保存用户态eax寄存器值的位置。然后,函数禁止本地中断,检查current的thread_info结构中的标志
如有任何标志被设置,则在返回到用户态前需完成一些工作,为避免代码复制,函数跳到resume_userspace或work_pending处。最后,汇编语言指令iret从内核堆栈中取五个参数,这样CPU切换到用户态并开始执行SYSENTER_RETURN标记处代码
如sysenter_entry确定标志被清0,它就快速返回到用户态
movl 40(%esp), %edx
movl 52(%esp), %ecx
xorl %ebp, %ebp
sti
sysexit把在上一节由sysenter_entry函数在第4c步保存的一对堆栈值加载到edx和ecx,edx获得SYSENTER_RETURN标记处地址,而ecx获得当前用户数据栈的指针
sysexit
sysexit是与sysenter配对的指令,它允许从内核态快速切换到用户态,执行此指令时,CPU控制单元执行下述:
- 把
SYSENTER_CS_MSR的值加16结果加载到cs - 把
edx寄存器的内容拷贝到eip - 把
SYSENTER_CS_MSR中的值加24得到的结果加载到ss - 把
ecx的内容拷贝到esp,因为SYSENTER_CS_MSR加载的是内核代码的选择符,cs加载的是用户代码的选择符,ss加载的用户数据段的选择符。结果,CPU从内核态切换到用户态,开始执行其地址存放在edx中的那条指令
SYSENTER_RETURN
存放在vsyscall页,当通过sysenter进入的系统调用被iret或sysexit终止时,该页框中的代码被执行。该代码恢复保存在用户态堆栈中的ebp,edx,ecx寄存器的原始内容,并把控制权返回给标准库中的封装例程
SYSENTER_RETURN:
popl %ebp
popl %edx
popl %ecx
ret参数传递
系统调用通常也许输入/输出参数,这些参数可能是实际的值。也可能是用户态进程地址空间的变量,甚至是指向用户态函数的指针的数据结构地址,因为system_call和sysenter_entry是Linux中所有系统调用的公共入口点。故每个系统调用至少有一个参数,即通过eax寄存器传递来的系统调用号。如,如一个应用程序调fork,则在执行int $0x80或sysenter之前就把eax置为2。因为这个寄存器的值由libc中的封装例程进行,故程序员通常不关系系统调用号。fork系统调用并不需其他的参数。不过,很多系统调用确实需由应用程序明确传递另外的参数,如mmap可能需多达6个额外参数。
普通c函数参数传递通过把参数值写入活动的程序栈,系统调用是横跨用户和内核的特殊函数。故既不能用用户态栈也不能用内核态栈。发出系统调用前,系统调用的参数被写入CPU寄存器。在调用系统调用服务例程前,内核再把存放在CPU中的参数拷贝到内核态堆栈。因为,系统调用服务例程是普通的c函数。
为何内核不直接把用户态的栈拷贝到内核态的栈?
- 同时操作两个栈比较复杂
- 寄存器的使用使系统调用处理程序的结构与其他异常处理程序的结构类似
然而,为了用寄存器传递参数,需满足:
- 每个参数的长度不能超过寄存器的长度, 即
32位 - 参数的个数不能超过
6个(除eax中传递的系统调用号),因为80x86处理器的寄存器数量有限
确实存在多于6个参数的系统调用,在此情况下,用一个单独的寄存器指向进程地址空间中这些参数值所在的一个内存区,编程者不用关心此工作区。调封装例程时,参数被自动保存在栈。封装例程将找到合适的方式把参数传递给内核,用于存放系统调用号和系统调用参数的寄存器是:
eax:系统调用号,ebx,ecx,edx,esi,edi,ebp
system_call和sysenter_entry使用SAVE_ALL把这些寄存器保存在内核态堆栈。故系统调用服务例程转到内核堆栈时,会找到system_call或sysenter_entry的返回地址,接着是存放在ebx中的参数,存放在ecx中的参数等。系统调用服务例程容易通过用c语言结构来引用它的参数,例
int sys_write(unsigned int fd, const char * buf, unsigned int count)
int sys_fork(struct pt_regs regs)服务例程的返回值必须写入eax寄存器中。这是在执行“return n;”指令时由C编译程序自动完成的。
验证参数
访问进程地址空间
系统调用服务例程需要非常频繁地读写进程地址空间的数据。Linux包含的一组宏使这种访问更加容易。我们将描述其中的两个名为get_user()和put_user()的宏。
第一个宏用来从一个地址读取1、2或4个连续字节,而第二个宏用来把这几种大小的内容写入一个地址中。这两个函数都接收两个参数,一个要传送的值x和一个变量ptr。第二变量还决定有多少个字节要传送。因此,在get_user(x, ptr)中,由ptr指向的变量大小使该函数展开为__get_user_1()、__get_user_2()或__get_user_4()汇编语言函数。让我们看一下其中一个,比如,__get_user_2():
__get_user_2:
addl $1,%eax
jc bad_get_user
movl $0xffffe000, %edx /*or xxfffff000 for 4-kb stacks */
andl %esp,%edx
cmpl 24(%edx), %eax
jae bad_get_user
2: movzwl -1(%eax), %edx
xorl %eax, %eax
ret
bad_get_user:
xorl %edx, %edx
movl $-EFAULT, %eax
reteax寄存器包含要读取的第一个字节的地址ptr。前6个指令所执行的检查事实上与access_ok()宏相同,即确保要读取的两个字节的地址小于4GB并小于current进程的addr_limit.seg字段(这个字段位于current的thread_info结构中偏移量为24处,出现在cmpl指令的第一个操作数中)。如果这个地址有效,函数就执行movzwl指令,把要读的数据存到edx寄存器的两个低字节,而把两个高字节置为0,然后在eax中设置返回码0并终止。如果这个地址无效,函数清edx,将eax置为-EFAULT并终止。put_user(x,ptr)宏类似于前边讨论的get_user,但它把值x写入以地址ptr为起始地址的进程地址空间。
根据x的大小,它使用__put_user_asm()宏(大小为1、2或4字节),或__put_user_u64()宏(大小为8字节)。这两个宏如果成功地写入了值那它们在eax寄存器中返回0,否则返回-EFAULT。在表10-1中列出了内核态下用来访问进程地址空间的另外几个函数或宏。注意,许多函数或宏的名字前缀有两个下划线(__)。首部没有下划线的函数或宏要用额外的时间对所请求的线性地址区间进行有效性检查,而有下划线的则会跳过检查。当内核必须重复访问进程地址空间的同一块线性区时,比较高效的办法是开始时只对该地址检查一次,以后就不用再对该进程区进行检查了。
下面是一些交互的宏:
| 函数 | 操作 |
|---|---|
get_user ,__get_user |
从用户空间读取一个整数 |
put_user, __put_user |
给用户空间写一个整数 |
copy_from_user, __copy_from_user |
从用户空间复制任意大小的块 |
copy_to_user, copy_to_user |
把任意大小的块复制到用户空间 |
strncpy_from_user, __strncpy_from_user |
从用户空间复制一个以空结束的字符串 |
strlen_user, __strlen_user |
返回用户空间以空结束的字符串的长度 |
clear_user, __clear_user |
用零填充用户空间的一个内存区域 |
动态地址检查:修正代码
我们先说明一下在内核态引起缺页异常的四种情况。这些情况必须由缺页异常处理程序来区分,因为不同情况采取的操作很不相同:
- 内核试图访问属于进程地址空间的页,但是,或者是相应的页框不存在,或者是内核试图去写一个只读页(写时复制)。在这些情况下,处理程序必须分配和初始化一个新的页框
- 内核寻址到属于其地址空间的页,但是相应的页表项还没有被初始化(参见第九章“处理非连续内存区访问”一节)。在这种情况下,内核必须在当前进程页表中适当地建立一些表项。也会分配页框。
- 某一内核函数包含编程错误,当这个函数运行时就引起异常;或者,可能由于瞬时的硬件错误引起异常。当这种情况发生时,处理程序必须执行一个内核漏洞(参见第九章的“处理地址空间以外的错误地址”一节)。
- 本章所讨论的一种情况:系统调用服务例程试图读写一个内存区,而该内存区的地址是通过系统调用参数传递来的,但却不属于进程的地址空间。
异常表
把访问进程地址空间的每条内核指令的地址放到一个叫异常表(exception table)的结构中并不用费太多功夫。当在内核态发生缺页异常时,do_page_fault()处理程序检查异常表:如果表中包含产生异常的指令地址,那么这个错误就是由非法的系统调用参数引起的,否则,就是由某一更严重的bug引起的。
Linux定义了几个异常表。主要的异常表在建立内核程序映像时由C编译器自动生成。它存放在内核代码段的__ex_table节,其起始与终止地址由C编译器产生的两个符号__start__ex_table和__stop__ex_table来标识。每个动态装载的内核模块(参看附录二)都包含有自己的局部异常表。这个表是在建立模块映像时由C编译器自动产生的,当把模块插入到运行中的内核时把这个表装入内存。每一个异常表的表项是一个exception_table_entry结构,它有两个字段:insn:访问进程地址空间的指令的线性地址。fixup:当存放在insn单元中的指令所触发的缺页异常发生时,fixup就是要调用的汇编语言代码的地址。
修正代码由几条汇编指令组成,用以解决由缺页异常所引起的问题。在后面我们将会看到,修正通常由插入的一个指令序列组成,这个指令序列强制服务例程返回一个出错码给用户态进程。这些指令通常在访问进程地址空间的同一函数或宏中定义;由C编译器把它们放置在内核代码段的一个叫作.fixup的独立部分。search_exception_tables()函数用来在所有异常表中查找一个指定地址:若这个地址在某一个表中,则返回指向相应exception_table_entry结构的指针;否则,返回NULL。因此,缺页处理程序do_page_fault()执行下列语句:
if((fixup = search_exception_tables(regs->eip))){
regs->eip = fixup->fixup;
return 1;
}regs->eip字段包含异常发生时保存到内核态栈eip寄存器中的值。如果eip寄存器(指令指针)中的这个值在某个异常表中,do_page_fault()就把所保存的值替换为search_exception_tables()的返回地址。然后缺页处理程序终止,被中断的程序以修正代码的执行而恢复运行。
生成异常表和修正代码
GNU汇编程序(Assembler)伪指令.section允许程序员指定可执行文件的哪部分包含紧接着要执行的代码。可执行文件包括一个代码段,这个代码段可能又依次被划分为节。因此,下面的汇编指令在异常表中加入一个表项;“a”属性指定必须把这一节与内核映像的剩余部分一块加载到内存中。
.section _ex_table, "a"
.long faulty_instruction_address, fixup_code_address
.previous.previous伪指令强制汇编程序把紧接着的代码插入到遇到上一个.section伪指令时激活的节。让我们再看一下前面论及过的__get_user_1()、__get_user_2()和__get_user_4()函数。访问进程地址空间的指令用1、2和3标记。
每个异常表项由两个标号组成。第一个是一个数字标号,其前缀b表示标号是“向后的”;换句话说,标号出现在程序的前一行。修正代码对这三个函数是公用的,且被标记为bad_get_user。如果缺页异常是由标号1、2或3处的指令产生的,那么修正代码就执行。在bad_get_user处的修正代码给发出系统调用的进程只简单地返回一个出错码-EFAULT。
内核封装例程
尽管系统调用主要由用户态进程使用,但也可以被内核线程调用,内核线程不能使用库函数。为了简化相应封装例程的声明,Linux定义了7个从_syscal10到_syscall6的一组宏。
每个宏名字中的数字0~6对应着系统调用所用的参数个数(系统调用号除外)。也可以用这些宏来声明没有包含在libc标准库中的封装例程(例如,因为Linux系统调用还未受到库的支持)。然而,不能用这些宏来为超过6个参数(系统调用号除外)的系统调用或产生非标准返回值的系统调用定义封装例程。每个宏严格地需要2+2×n个参数,n是系统调用的参数个数。前两个参数指明系统调用的返回值类型和名字;每一对附加参数指明相应的系统调用参数的类型和名字。因此,以fork()系统调用为例,其封装例程可以通过如下语句产生:_syscall0(int, fork)。而write()系统调用的封装例程可以通过如下语句产生:_syscall3(int, write, int, fd, const char *, buf, unsigned int, count).
#define _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3) \
type name(type1 arg1,type2 arg2,type3 arg3) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long)(arg2)), \
"d" ((long)(arg3))); \
__syscall_return(type,__res); \
}
#define __syscall_return(type, res) \
do { \
if ((unsigned long)(res) >= (unsigned long)(-(128 + 1))) { \
errno = -(res); \
res = -1; \
} \
return (type) (res); \
} while (0)在后一种情况下,可以把这个宏展开成如下的代码:
int write(int fd, const char* buf, unsigned int count)
{
long __res;
__asm__ ("int $0x80"
: "=a" (__res)
: "0" (__NR_write),"b" ((long)(fd)),"c" ((long)(buf)),
"d" ((long)(count)));
if ((unsigned long)(res) >= (unsigned long)(-(128 + 1))) {
errno = -(res);
__res = -1;
}
return (int) (__res);
}__NR_write宏来自_syscal13的第二个参数;它可以展开成write()的系统调用号。当编译前面的函数时,生成下面的汇编代码:
write:
pushl %eax ; ebx入栈
movl 8(%esp), %ebx ;把第一个参数放入ebx
movl 12(%esp), %ecx ;把第二个参数放入ecx
movl 16(%esp), %edx ; 把第三个参数放入edx
movl $4, %eax ; __NR_write放入eax中
int $0x80 ;调用系统调用
cmpl $-125, %eax ;检查返回码
jbe .L1 ;如无出错则跳转
negl %eax ;求EAX的补码
moovl %%eax, errno ;将结果放入errno
movl $-1, %eax ;把eax置为-1
.L1: pop1 %ebx ;从堆栈弹出EBX
ret ;返回调用程序 额外说明
代码段中插入了.section xxx这样的段定义,代码段顺序执行时,是否会接着执行.section xxx中的指令?不会。可以理解为.section xxx这样的定义会使得编译器编译可执行文件时,将.section xxx中的内容放在额外的节中。这样,实际的可执行文件中,.section xxx前面的可执行指令,和.section xxx中的可执行指令并不是相邻的。
xxx1
.section yyy1
...
.previous
.section yyy2
...
.previous
xxx2
12345678上述指令序列,编译出的可执行文件中
section yy1
...
xxx1
xxx2
...
section yyy1
...
section yyy2
...
123456789所以,xxx1指令执行后,接着执行的是xxx2代表的指令
#define __put_user_asm(x, addr, err, itype, rtype, ltype, errret) \
__asm__ __volatile__( \
"1: mov"itype" %"rtype"1,%2\n" \
"2:\n" \
".section .fixup,\"ax\"\n" \
"3: movl %3,%0\n" \
" jmp 2b\n" \
".previous\n" \
".section __ex_table,\"a\"\n" \
" .align 4\n" \
" .long 1b,3b\n" \
".previous" \
: "=r"(err) \
: ltype (x), "m"(__m(addr)), "i"(errret), "0"(err))信号
信号的作用
信号(signal)是很短的消息,可以被发送到一个进程或一组进程。使用信号的两个主要目的是:
- 让进程知道已经发生了一个特定的事件。
- 强迫进程执行它自己代码中的信号处理程序。
| 取值 | 名称 | 解释 | 默认动作 |
|---|---|---|---|
| 1 | SIGHUP | 挂起(在用户终端连接(正常或非正常)结束时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业, 这时它们与控制终端不再关联) | |
| 2 | SIGINT | 中断(程序终止(interrupt)信号, 在用户键入INTR字符(通常是Ctrl-C)时发出,用于通知前台进程组终止进程) | |
| 3 | SIGQUIT | 退出(和SIGINT类似, 但由QUIT字符(通常是Ctrl-/)来控制. 进程在因收到SIGQUIT退出时会产生core文件, 在这个意义上类似于一个程序错误信号) | |
| 4 | SIGILL | 非法指令(执行了非法指令. 通常是因为可执行文件本身出现错误, 或者试图执行数据段. 堆栈溢出时也有可能产生这个信号) | |
| 5 | SIGTRAP | 断点或陷阱指令(由断点指令或其它trap指令产生. 由debugger使用) | |
| 6 | SIGABRT | abort发出的信号(调用abort函数生成的信号) | |
| 7 | SIGBUS | 非法内存访问(非法地址, 包括内存地址对齐(alignment)出错。比如访问一个四个字长的整数, 但其地址不是4的倍数。它与SIGSEGV的区别在于后者是由于对合法存储地址的非法访问触发的(如访问不属于自己存储空间或只读存储空间)) | |
| 8 | SIGFPE | 浮点异常(在发生致命的算术运算错误时发出. 不仅包括浮点运算错误, 还包括溢出及除数为0等其它所有的算术的错误) | |
| 9 | SIGKILL | kill信号(用来立即结束程序的运行) | 不能被忽略、处理和阻塞 |
| 10 | SIGUSR1 | 用户信号1(留给用户使用) | |
| 11 | SIGSEGV | 无效内存访问(试图访问未分配给自己的内存, 或试图往没有写权限的内存地址写数据) | |
| 12 | SIGUSR2 | 用户信号2(留给用户使用) | |
| 13 | SIGPIPE | 管道破损,没有读端的管道写数据(这个信号通常在进程间通信产生,比如采用FIFO(管道)通信的两个进程,读管道没打开或者意外终止还往管道写,写进程会收到SIGPIPE信号。此外用Socket通信的两个进程,写进程在写Socket的时候,读进程已经终止,也会产生这个信号) | |
| 14 | SIGALRM | alarm发出的信号(时钟定时信号, 计算的是实际的时间或时钟时间. alarm函数使用该信号) | |
| 15 | SIGTERM | 终止信号(程序结束(terminate)信号, 与SIGKILL不同的是该信号可以被阻塞和处理。通常用来要求程序自己正常退出,shell命令kill缺省产生这个信号) | |
| 16 | SIGSTKFLT | 栈溢出 | |
| 17 | SIGCHLD | 子进程退出(子进程结束时, 父进程会收到这个信号) | 默认忽略 |
| 18 | SIGCONT | 进程继续 | 不能被阻塞 |
| 19 | SIGSTOP | 进程停止(停止(stopped)进程的执行. 注意它和terminate以及interrupt的区别:该进程还未结束, 只是暂停执行) | 不能被忽略、处理和阻塞 |
| 20 | SIGTSTP | 进程停止(停止进程的运行, 用户键入SUSP字符时(通常是Ctrl-Z)发出这个信号) | 该信号可以被处理和忽略 |
| 21 | SIGTTIN | 进程停止,后台进程从终端读数据时 | |
| 22 | SIGTTOU | 进程停止,后台进程想终端写数据时 | |
| 23 | SIGURG | I/O有紧急数据到达当前进程 | 默认忽略 |
| 24 | SIGXCPU | 进程的CPU时间片到期 | |
| 25 | SIGXFSZ | 文件大小的超出上限 | |
| 26 | SIGVTALRM | 虚拟时钟超时 | |
| 27 | SIGPROF | profile时钟超时 | |
| 28 | SIGWINCH | 窗口大小改变 | 默认忽略 |
| 29 | SIGIO | I/O相关 | |
| 30 | SIGPWR | 关机 | 默认忽略 |
| 31 | SIGSYS | 系统调用异常 |
POSIX标准还引入了一类新的信号,叫做实时信号(real-time signal);在Linux中它们的编码范围为32~64。它们与常规信号有很大的不同,因为它们必须排队以便发送的多个信号能被接收到。另一方面,同种类型的常规信号并不排队:如果一个常规信号被连续发送多次,那么,只有其中的一个发送到接收进程。尽管Linux内核并不使用实时信号,它还是通过几个特定的系统调用完全实现了POSIX标准。
信号的一个重要特点是它们可以随时被发送给状态经常不可预知的进程。 发送给非运行进程的信号必须由内核保存,直到进程恢复执行。阻塞一个信号(后面描述),要求信号的传递拖延,直到随后解除阻塞,这使得信号产生一段时间之后才能对其传递这一问题变得更加严重。因此,内核区分信号传递的两个不同阶段:
- 信号产生,内核更新目标进程的数据结构以表示一个信号已经被发送.
- 信号传递,内核强迫目标进程通过以下方式对信号做出反应: 或改变目标进程的执行状态,或开始执行一个特定的信号处理程序,或两者都是
信号一旦已传递出去,进程描述符中有关这个信号的所有信息都被取消。已经产生但还没有传递的信号称为挂起信号(pending signal)。
任何时候,一个进程仅存在给定类型的一个挂起信号,同一进程同种类型的其他信号不被排队,只被简单地丢弃。
但是,实时信号是不同的:同种类型的挂起信号可以有好几个。 一般来说,信号可以保留不可预知的挂起时间。必须考虑下列因素:
- 信号通常只被当前正运行的进程传递(即由
current进程传递)。 - 给定类型的信号可以由进程选择性地阻塞(
blocked). - 当进程执行一个信号处理程序的函数时,通常“屏蔽”相应的信号,即自动阻塞这个信号直到处理程序结束。因此,所处理的信号的另一次出现不能中断信号处理程序,所以,信号处理函数不必是可重入的。
所以,内核必须要做出以下工作!
- 记住每个进程阻塞哪些信号。
- 当从内核态切换到用户态时,对任何一个进程都要检查是否有一个信号已到达。
- 确定是否可以忽略信号。这发生在下列所有的条件都满足时:
- 目标进程没有被另一个进程跟踪(进程描述符中
ptrace字段的PT_PTRACED标志等于0)。 - 信号没有被目标进程阻塞。
- 信号被目标进程忽略
- 目标进程没有被另一个进程跟踪(进程描述符中
- 处理这样的信号,即信号可能在进程运行期间的任一时刻请求把进程切换到一个信号处理函数,并在这个函数返回以后恢复原来执行的上下文。
传递信号之前所执行的操作
进程以三种方式对一个信号做出应答:
- 显式地忽略信号。
- 执行与信号相关的缺省操作.
a.Terminate
进程被终止。
b.Dump
进程被终止,并且,如果可能,创建包含进程执行上下文的核心转储文件;
c.lgnore
信号被忽略。
d.Stop
进程被停止,即把进程置为TASK_STOPPED状态.
e.Continue
如果进程被停止(TASK_STOPPED),continue处理中就把它置为TASK_RUNNING状态。 - 通过调用相应的信号处理函数捕获信号。
如果一个进程正在被跟踪时接收到一个信号,内核就停止这个进程,并向跟踪进程发送一个SIGCHLD信号以通知它一下。跟踪进程又可以使用SIGCOUNT信号重新恢复被跟踪进程的执行。 SIGKILL和SIGSTOP信号不可以被显式地忽略、捕获或阻塞, 因此,通常必须执行它们的缺省操作。
POSIX信号和多线程应用
POSIX 1003.1标准对多线程应用的信号处理有一些严格的要求:
- 信号处理程序必须在多线程应用的所有线程之间共享;不过,每个线程必须有自己的挂起信号掩码和阻塞信号掩码。挂起是信号已经产生,等待处理中。阻塞是即使信号已经产生,也不会进行实际处理。
POSIX库函数kill()和sigqueue()必须向所有的多线程应用而不是某个特殊的线程发送信号。 所有由内核产生的信号同样如此(如:SIGCHLD、SIGINT或SIGQUIT)。- 每个发送给多线程应用的信号仅传送给一个线程,这个线程是由内核在从不会阻塞该信号的线程中随意选择出来的。
- 如果向多线程应用发送了一个致命的信号,那么内核将杀死该应用的所有线程,而不仅仅是杀死接收信号的那个线程。
有两个例外:不可能给进程0(swapper)发送信号,而发送给进程1(init)的信号在捕获到它们之前也总被丢弃。因此,进程0永不死亡,而进程1只有当init程序终止时才死亡。如果一个挂起信号被发送给了某个特定线程,那么这个信号是私有的;如果被发送给了整个线程组,它就是共享的。
结构
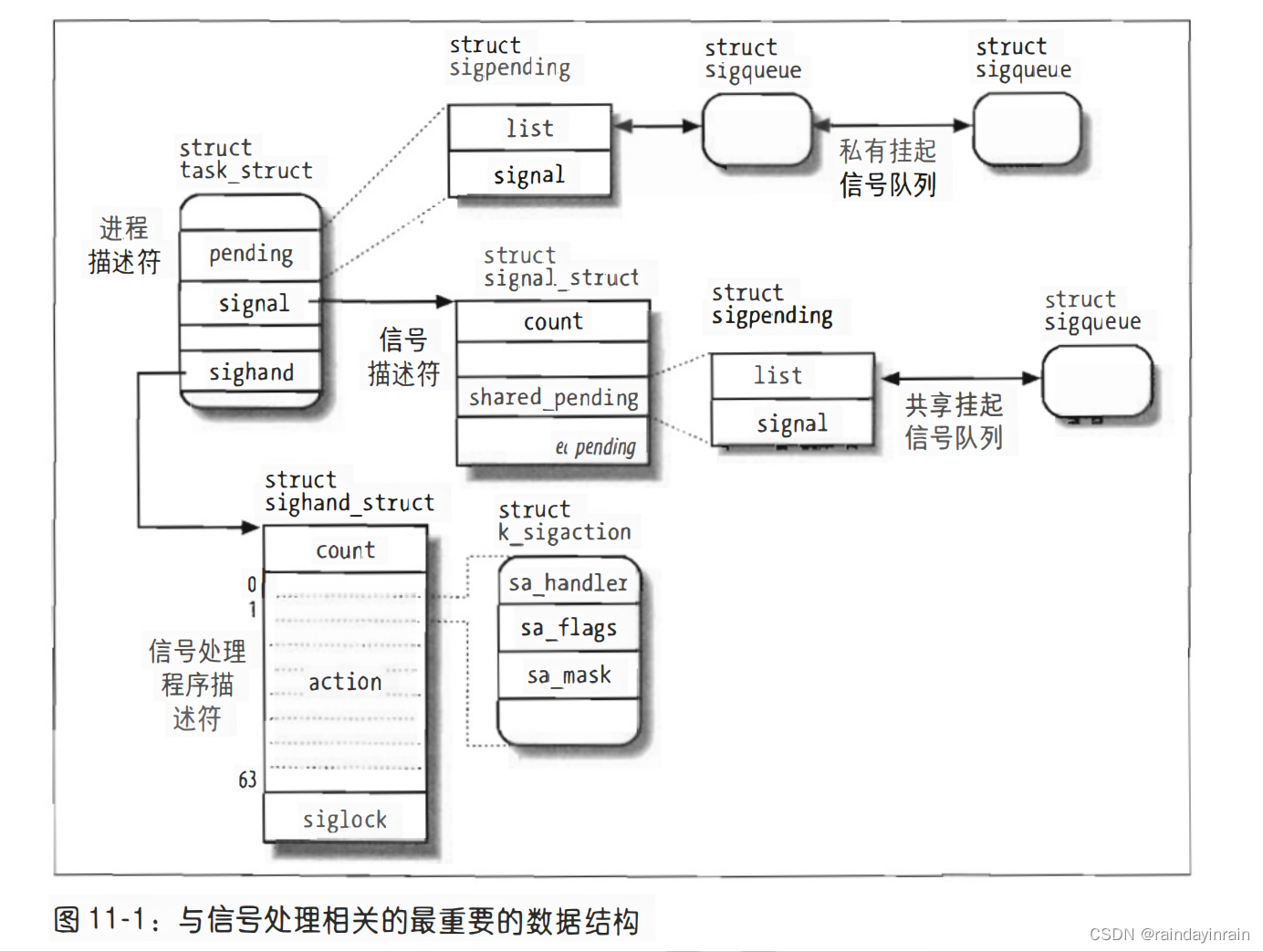
| 类型 | 名称 | 说明 |
|---|---|---|
struct signal_struct* |
signal |
|
struct sighand_struct* |
sighand |
|
sigset_t |
blocked |
|
sigset_t |
real_blocked |
|
struct sigpending |
pending |
|
unsigned long |
sas_ss_sp |
|
size_t |
sas_ss_size |
|
int(*)(void*) |
notifier |
|
void* |
notifier_data |
|
sigset_t* |
notifier_mask |
blocked字段存放进程当前所屏蔽的信号。它是一个sigset_t位数组,每种信号类型对应一个元素: 信号的编号对应于sigset_t类型变量中的相应位下标加1。
信号描述符和信号处理程序描述符
信号描述符被属于同一线程组的所有进程共享,信号描述符中与信号处理有关的字段如表11-4所示:

sigaction数据结构
(1). sa_handler:指向信号处理程序的一个指针/SIG_DFL/SIG_IGN.
(2). sa_flags:这是一个标志集.
(3). sa_mask:当运行信号处理程序时要屏蔽的信号。
挂起信号队列
有几个系统调用能产生发送给整个线程组的信号,如kill()和rt_sigqueueinfo(),而其他的一些则产生发送给特定进程的信号,如tkill()和tgkill()。内核把两个挂起信号队列与每个进程相关联:
(1). 共享挂起信号队列,存放整个线程组的挂起信号。
(2). 私有挂起信号队列,存放特定进程(轻量级进程)的挂起信号。
挂起信号队列由sigpending数据结构组成,它的定义如下:
struct siigpending{
struct list_head list;
sigset_t signal;
};| 类型 | 名称 | 说明 |
|---|---|---|
| struct list_head | list | 链接挂起信号对应的链表 |
| spinlock_t* | lock | 指向与挂起信号相应的信号处理程序描述符中siglock字段的指针 |
| int | flags | sigqueue数据结构的标志 |
| siginfo_t | info | 描述产生信号的事件 |
| struct user_struct | user | 指向进程拥有者的每用户数据结构的指针 |
siginfo_t是一个128字节的数据结构,其中存放有关出现特定信号的信息。它包含下列字段:
a. si_signo
信号编号。
b. si_errno
引起信号产生的指令的出错码,或者如果没有错误则为0。
c. si_code
发送信号者的代码(参见表11-8)。
| 代码名 | 发送者 |
|---|---|
| SI_USER | kill, raise |
| SI_KERNEL | 一般内核函数 |
| SI_QUEUE | sigqueue |
| SI_TIMER | 定时器到期 |
| SI_ASYNC | 异步IO完成 |
| SI_TKILL | tkill和tgkill |
产生信号
很多内核函数都会产生信号:即根据需要更新一个或多个进程的描述符。它们不直接执行第二步的信号传递操作,而是可能根据信号的类型和目标进程的状态唤醒一些进程,并促使这些进程接收信号。
| 函数名称 | 说明 |
|---|---|
| send_sig | 向单一进程发送信号 |
| send_sig_info | 与上类似,还使用siginfo_t扩展信息 |
| force_sig | 发送不能被进程显示忽略,也不能被进程阻塞的信号 |
| force_sig_info | 与上类似,还使用siginfo_t扩展信息 |
| force_sig_specific | 与上类似,优化了SIGSTOP和SIGKILL信号的处理 |
| sys_tkill | tkill系统调用的处理函数 |
| sys_tgkill | tgkill系统调用的处理函数 |
所有函数在结束时都调用specific_send_sig_info()函数.
| 函数名称 | 说明 |
|---|---|
| send_group_sig_info | 向某一个进线程组发送信号,该线程组由它的一个成员进程的描述符来标识。 |
| kill_pg | 向一个进程组中所有的进程组发送信号! |
| kill_pg_info | 与上一个类似只是,还使用siginfo_t扩展信息 |
| kill_proc | 向某一个线程组发送信号该线程组,有它的一个成员进程的pid来标识 |
| kill_proc_info | 与上一个类似只是,还使用siginfo_t扩展信息 |
| sys_kill | kill系统调用处理函数 |
| sus_rt_sigqueueinfo | rt_sigqueueinfo系统调用处理函数 |
所有函数在结束时都调用group_send_sig_info()函数.
specific_send_sig_info()函数
specific_send_sig_info()函数向指定进程发送信号,它作用于三个参数:
sig:信号编号
info:或者是
siginfo_t表的地址,或者是三个特殊值中的一个。零意味着信号是由用户态进程发送的,一意味着是由内核发送的,二意味着是由内核发送的信号t:指向目标进程描述符的指针
必须在关本地中断和已经获得t->sighand->siglock自旋锁的情况下调用specific_send_sig_info()函数。函数执行下面的步骤:
检查进程是否忽略信号,如果是就返回
0(不产生信号)。当下面的三个忽略信号的条件全部满足时,信号就被忽略:
- 进程没有被跟踪(
t->ptrace中的PT_PTRACED标志被清0).- 信号没有被阻塞(
sigismember(&t->blocked,sig)返回0).- 或者显式地忽略信号(
t->sighand->action[sig-1]的sa_handler字段等于SIG_IGN),或者隐含地忽略信号(sa_handler字段等于SIG_DFL而且信号是SIGCONT、SIGCHLD、SIGWINCH或SIGURG).检查信号是否是非实时的(
sig<32),而且是否在进程的私有挂起信号队列上已经有另外一个相同的挂起信号。如果是,就什么都不需要做,因此返回0。调用
send_signal( sig,info,t,&t->pending),把信号添加到进程的挂起信号集合中.如果
send_signal()成功地结束,而且信号不被阻塞(sigismember(&t->blocked,sig)返回0),就调用signal_wake_up()函数通知进程有新的挂起信号。
signal_wake_up
a. 把t->thread_info->flags中的TIF_SIGPENDING标志置位。
b. 如果进程处于TASK_INTERRUPTIBLE或TASK_STOPPED状态,而且信号是SIGKILL,就调用try_to_wake_up()唤醒进程。
c. 如果try_to_wake_up()返回0,那么说明进程已经是可运行的:这种情况下,它检查进程是否已经在另外一个CPU上运行,如果是就向那个CPU发送一个处理器间中断,以强制当前进程的重新调度。因为在从调度函数返回时,每个进程都检查是否存在挂起信号,因此,处理器间中断保证了目标进程能很快注意到新的挂起信号。
d. 返回1(已经成功地产生信号)。
send_signal()函数
send_sigmal()函数在挂起信号队列中插入一个新元素,
static int send_signal(int sig, struct siginfo *info, struct task_struct *t, struct sigpending *signals)将信号加入到进程挂起信号掩码。需要时,分配并构造sigqueue,加入sigqueue链表。sigqueue链表使得掩码中指定的一个信号,可以存在多个链表节。sigqueue可以使得进一步存储信号关联的数据信息。
group_send_sig_info()函数
group_send_sig_info()函数向整个线程组发送信号。它作用于三个参数:信号编号sig、siginfo_t表的地址info(可选的值为0、1或2,如前面“specific_send_sig_info()函数“一节中所描述的)以及进程描述符的地址p。
int group_send_sig_info(int sig, struct siginfo *info, struct task_struct *p)该函数主要执行下面的步骤:
- 检查参数
sig是否正确:
if(sig<0 Il sig>64)
return -EINVAL;如果信号是由用户态进程发送的,则该函数确定是否允许这个操作。下列条件中至少有一个成立时信号才能被传递:
- 发送进程的拥有者具有适当的权能(这通常意味着通过系统管理员发布信号)。
- 信号为
SIGCONT且目标进程与发送进程处于同一个注册会话中。 - 两个进程属于同一个用户。如果不允许用户态进程发送信号,函数就返回值
-EPERM。 - 如果参数
sig的值为0,则函数不产生任何信号,立即返回:
if(!sig ll !p->sighand)
return 0;- 因为
0是无效的信号编码,用于让发送进程检查它是否有向目标线程组发送信号所必需的特权。如果目标进程正在被杀死(通过检查它的信号处理程序描述符是否已经被释放来获知),那么函数也返回。 - 获取
p->sighand->siglock自旋锁并关闭本地中断。 - 调用
handle_stop_signal()函数,该函数检查信号的某些类型,这些类型可能使目标线程组的其他挂起信号无效。
handle_stop_signal()函数执行下面的步骤:
- 如果线程组正在被杀死(信号描述符的
flags字段的SIGNAL_GROUP_EXIT标志被设置),则函数返回。 - 如果
sig是SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU信号,就调用rm_from_queue()函数从共享挂起信号队列p->signal->shared_pending和线程组所有成员的私有信号队列中删除SIGCONT信号。 - 如果
sig是SIGCONT信号,就调用rm_from_queue()函数从共享挂起信号队列p->signal->shared_pending中删除所有的SIGSTOP、 SIGTSTP、SIGTTIN和SIGTTOU信号,然后从属于线程组的进程的私有挂起信号队列中删除上述信号,并唤醒进程:
rm_from_queue(0x003c0000,&p->signal->shared_pending);
t = p;
do {
rm_from_queue(0x003c0000,&t->pending);
try_to_wake_up(t,TASK_STOPPED,0);
t = next_thread(t);
} while(t != p);掩码0x003c0000选择以上四种停止信号。宏next_thread每次循环都返回线程组中不同轻量级进程的描述符地址.
- 检查线程组是否忽略信号,如果是就返回
0值(成功)。如果在前面“信号的作用”一节中所提到的忽略信号的三个条件都满足(也可参见前面“specific-send-sig.info()函数”一节中的第1步),就忽略信号。 - 检查信号是否是非实时的,并且在线程组的共享挂起信号队列中已经有另外一个相同的信号,如果是,就什么都不需要做,因此返回
0值(成功)。
if(sig<32 && sigismember(&p->signal->shared_pending.signal,sig))
return 0;
12调用send_signal()函数把信号添加到共享挂起信号队列中。如果send_signal()返回非0的错误代码,则函数终止并返回相同的值。
- 调用
__group_complete_signal()函数唤醒线程组中的一个轻量级进程. - 释放
p->sighand->siglock自旋锁并打开本地中断。 - 返回
0(成功)。
__group_complete_sigmal
函数__group_complete_sigmal()扫描线程组中的进程,查找能接收新信号的进程。满足下述所有条件的进程可能被选中:
- 进程不阻塞信号。
- 进程的状态不是
EXIT_ZOMBIE、EXIT_DEAD、TASK_TRACED或TASK_STOPPED(作为一种异常情况,如果信号是SIGKILL,那么进程可能处于TASK_TRACED或者TASK_STOPPED状态)。 - 进程没有正在被杀死,即它的
PF_EXITING标志没有置位。 - 进程或者当前正在
CPU上运行,或者它的TIF_SIGPENDING标志还没有设置。 - (实际上,唤醒一个有挂起信号的进程是毫无意义的:通常,唤醒操作已经由设置了
TIF_SIGPENDING标志的内核控制路径执行;另一方面,如果进程正在执行,则应该向它通报有新的挂起信号。)
一个线程组可能有很多满足上述条件的进程,函数按照下面的规则选择其中的一个进程:
如果
p标识的进程(由group_send_sig_info()的参数传递的描述符地址)满足所有的优先准则, 并因此而能接收信号,函数就选择该进程。否则,函数通过扫描线程组的成员搜索一个适当的进程,搜索从接收线程组最后一个信号的进程(
p->signal->curr_target)开始。如果函数
__group_complete_signal()成功地找到一个适当的进程,就开始向被选中的进程传递信号。首先,函数检查信号是否是致命的:
如果是,通过向线程组中的所有轻量级进程发送
SIGKILL信号杀死整个线程组。否则,函数调用
signal_wake_up()函数通知被选中的进程:有新的挂起信号到来。
传递信号
确保进程的挂起信号得到处理内核所执行的操作。内核在允许进程恢复用户态下的执行之前,检查进程TIF_SIGPENDING标志的值。每当内核处理完一个中断或异常时,就检查是否存在挂起信号。
do_signal
为了处理非阻塞的挂起信号,内核调用do_signal()函数,它接收两个参数:
regs: 栈区的地址,当前进程在用户态下的寄存器内容存放在这个栈中
oldset:变量的地址,假设函数把阻塞信号的位掩码数组存放在这个变量中!如果没有必要保存为掩码数组,则把它设为空
如果中断处理程序调用do_signal(),则该函数立刻返回:
if((regs->xcs & 3) != 3)
return l;如果oldset参数为NULL,函数就用current->blocked字段的地址对它初始化:
if (!oldset)
oldset =¤t->blocked;do_signal()函数的核心由重复调用dequeue_signal()函数的循环组成,直到在私有挂起信号队列和共享挂起信号队列中都没有非阻塞的挂起信号时,循环才结束。dequeue_signal()的返回码存放在signr局部变量中。如果值为0,意味着所有挂起的信号已全部被处理,并且do_signal()可以结束。只要返回一个非0值,就意味着挂起的信号正等待被处理,并且do_signal()处理了当前信号后又调用了dequeue_sigmal()。
dequeue_signal
dequeue_signal()函数首先考虑私有挂起信号队列中的所有信号,并从最低编号的挂起信号开始。然后考虑共享队列中的信号。它更新数据结构以表示信号不再是挂起的,并返回它的编号。看do_signal()函数如何处理每一个挂起的信号,其编号由dequeue_signal()返回。首先,它检查current接收进程是否正受到其他一些进程的监控;在肯定的情况下,do_signal()调用do_notify_parent_cldstop()和schedule()让监控进程知道进程的信号处理。然后,do_signal()把要处理信号的k_sigaction数据结构的地址赋给局部变量ka:ka =¤t->sig->action[signr-1];.根据ka的内容可以执行三种操作:忽略信号、执行缺省操作或执行信号处理程序。如果显式忽略被传递的信号,那么do_signal()函数仅仅继续执行循环,并由此考虑另一个挂起信号.
执行信号的缺省操作
如果ka->sa.sa_handler等于SIG_DFL,do_signal()就必须执行信号的缺省操作。唯一的例外是当接收进程是init时,在这种情况下,这个信号被丢弃:
if(current->pid == 1)
continue; 如果接收进程是其他进程,对缺省操作是Ignore的信号进行处理也很简单:
if(signr==SIGCONT ll signr==SIGCHLD II signr==SIGWINCH || signr==SIGURG)
continue; 缺省操作是Stop的信号可能停止线程组中的所有进程。为此,do_signal()把进程的状态都置为TASK_STOPPED,并在随后调用schedule()函数
if(signr==SIGSTOP ll signr==SIGTSTP || signr==SIGTTIN II signr==SIGTTOU) {
if(signr != SIGSTOP && is_orphaned_pgrp(current->signal->pgrp))
continue;
do_signal_stop(signr);
}
12345 SIGSTOP与其他信号的差异比较微妙:SIGSTOP总是停止线程组,而其他信号只停止不在“孤儿进程组”中的线程组。
do_signal_stop
do_signal_stop()函数检查current是否是线程组中第一个被停止的进程,如果是,它激活”组停止”:本质上,该函数把一个正数值赋给信号描述符中的group_stop_count字段,并唤醒线程组中的所有进程。所有这样的进程都检查该字段以确认正在进行“组停止”操作,然后把进程的状态置为TASK_STOPPED,并调用schedule()。如果线程组领头进程的父进程没有设置SIGCHLD的SA_NOCLDSTOP标志,那么do_signal_stop()函数还要向它发送SIGCHLD信号。
缺省操作为Dump的信号可以在进程的工作目录中创建一个“转储”文件,这个文件列出进程地址空间和CPU寄存器的全部内容。do_signal()创建了转储文件后,就杀死这个线程组。
剩余18个信号的缺省操作是Terminate, 它仅仅是杀死线程组。为了杀死整个线程组,函数调用do_group_exit()执行彻底的“组退出”过程。
捕获信号
如果信号有一个专门的处理程序,do_signal()就函数必须强迫该处理程序执行。这是通过调用handle_signal()进行的:
handle_signal(signr,&info,aka,oldset,regs);
if(ka->sa.sa_flags& SA_ONESHOT)
ka->sa.sa_handler = SIG_DFL;
return 1; 执行一个信号处理程序是件相当复杂的任务,因为在用户态和内核态之间切换时需要谨慎地处理栈中的内容。我们将正确地解释这里所承担的任务。
信号处理程序是用户态进程所定义的函数,并包含在用户态的代码段中。handle_signal()函数运行在内核态,而信号处理程序运行在用户态,这就意味着在当前进程恢复“正常”执行之前,它必须首先执行用户态的信号处理程序。此外,当内核打算恢复进程的正常执行时,内核态堆栈不再包含被中断程序的硬件上下文,因为每当从内核态向用户态转换时,内核态堆栈都被清空。而另外一个复杂性是因为信号处理程序可以调用系统调用,在这种情况下,执行了系统调用的服务例程以后,控制权必须返回到信号处理程序而不是到被中断程序的正常代码流。
Linux所采用的解决方法是把保存在内核态堆栈中的硬件上下文拷贝到当前进程的用户态堆栈中。用户态堆栈也以这样的方式被修改,即当信号处理程序终止时,自动调用sigreturn()系统调用把这个硬件上下文拷贝回到内核态堆栈中,并恢复用户态堆栈中原来的内容。
图11-2说明了有关捕获一个信号的函数的执行流。
- 一个非阻塞的信号发送给一个进程。
- 当中断或异常发生时,进程切换到内核态。正要返回到用户态前,内核执行
do_signal()函数, - 这个函数又依次处理信号(通过调用
handle_signal())和建立用户态堆栈(通过调用setup_frame()或setup_rt_frame())。当进程又切换到用户态时,因为信号处理程序的起始地址被强制放进程序计数器中,因此开始执行信号处理程序。
当处理程序终止时,setup_frame()或setup_rt_frame()函数放在用户态堆栈中的返回代码就被执行。这个代码调用sigreturn()或rt_sigreturn()系统调用,相应的服务例程把正常程序的用户态堆栈硬件上下文拷贝到内核态堆栈,并把用户态堆栈恢复到它原来的状态(通过调用restore_sigcontext())。当这个系统调用结束时,普通进程就因此能恢复自己的执行。
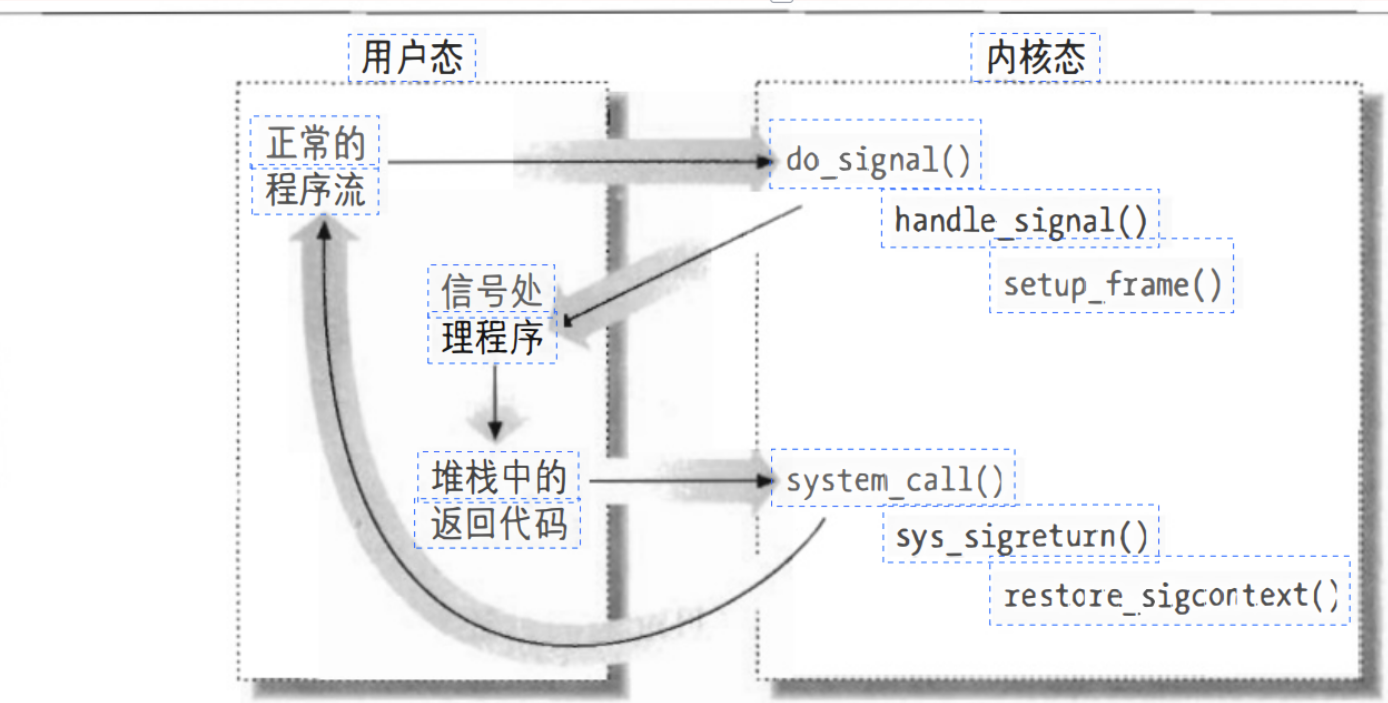
setup_frame
为了适当地建立进程的用户态堆栈,handle_signal()函数或者调用setup_frame()(对不需要siginfo_t表的信号;或者调用setup_rt_frame()。为了在这两个函数之间进行选择,内核检查与信号相关的sigaction表sa_flags字段的SA_SIGINFO标志值。setup_frame()函数接收四个参数,它们具有下列含义:
sig: 信号编号
ka: 与信号相关的k_sigaction表地址
oldset:掩码数组
regs: 栈区的地址
oldset:变量的地址,假设函数把阻塞信号的位掩码数组存放在这个变量中!如果没有必要保存为掩码数组,则把它设为空
如果中断处理程序调用do_signal(),则该函数立刻返回:setup_frame()函数把一个叫做帧(frame)的数据结构推进用户态堆栈中,这个帧含有处理信号所需要的信息,并确保正确返回到handle_signal()函数。一个帧就是包含下列字段的sigframe表(见图11-3):
pretcode:信号处理函数的返回地址
sig: 信号编号
sc:包含正好切换到内核态前用户态进程的硬件上下文
fpstate:可以用来存放用户态进程的浮点寄存器内容
被阻塞的实时信号的位数组
retcode:发出sig return系统调用的八字节代码
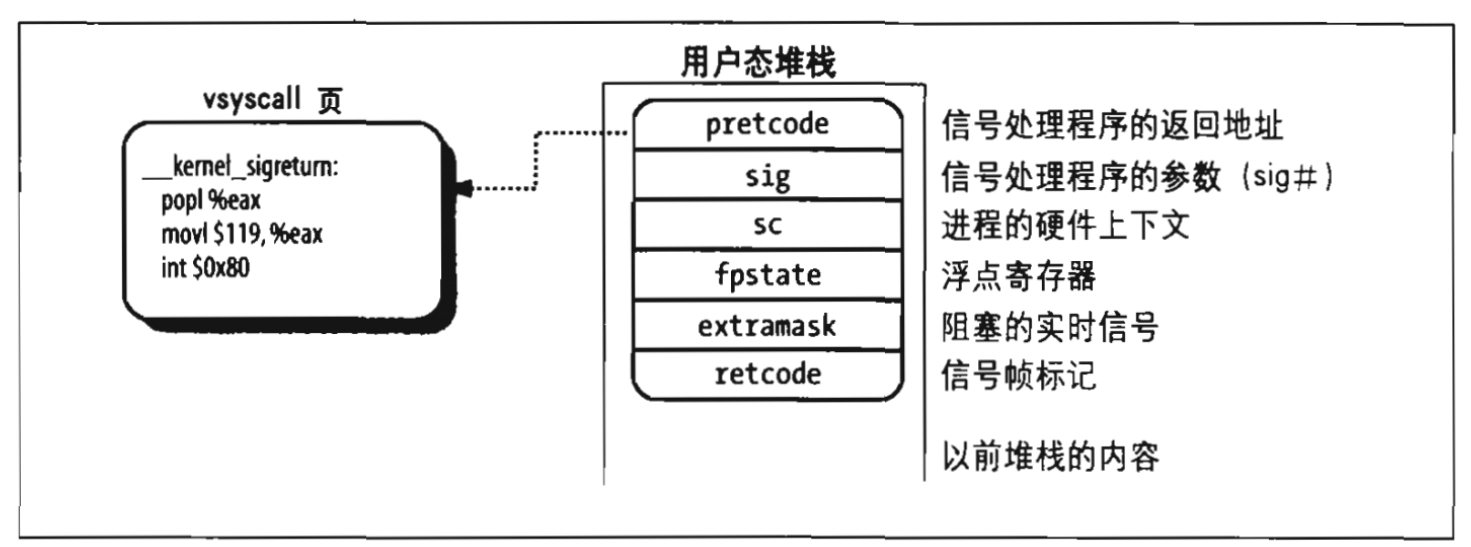
setup_frame()函数首先调用get_sigframe()计算帧的第一个内存单元,这个内存单元通常是在用户态堆栈中,因此函数返回值:(regs->esp - sizeof(struct sigframe))& 0xfffffff8。因为栈朝低地址方向延伸,所以通过把当前栈顶的地址减去它的大小,使其结果与8的倍数对齐,就获得了帧的起始地址。然后用access_ok宏对返回地址进行验证。如果地址有效,setup_frame()就反复调用__put_user()填充帧的所有字段。帧的pretcode字段初始化&__kernel_sigreturn,一些粘合代码的地址放在vsyscall页中。一旦完成了这个操作,就修改内核态堆栈的regs区,这就保证了当current恢复它在用户态的执行时,控制权将传递给信号处理程序。
regs->esp =(unsigned long)frame;
regs->eip =(unsigned long)ka->sa.sa_handler;
regs->eax =(unsigned long)sig;
regs->edx =regs->ecx = 0;
regs->xds = regs->xes = regs->xss=__USER_DS;
regs->xcs =__USER_CS;setup_frame()函数把保存在内核态堆栈的段寄存器内容重新设置成它们的缺省值以后才结束。现在,信号处理程序所需的信息就在用户态堆栈的顶部。setup_rt_frame()函数与setup_frame()非常相似,但它把用户态堆栈存放在一个扩展的帧中(保存在rt_sigframe数据结构中),这个帧也包含了与信号相关的siginfo_t表的内容。此外,该函数设置pretcode字段以使它指向vsyscall页中的__kernel_rt_sigreturm代码。
检查信号标志
建立了用户态堆栈以后,handle_signal()函数检查与信号相关的标志值。如果信号没有设置SA_NODEFER标志,在sigaction表中sa_mask字段对应的信号就必须在信号处理程序执行期间被阻塞:
if(!(ka->sa.sa_flags& SA_NODEFER)){
spin_lock_irq(¤t->sighand->siglock);
sigorsets(¤t->blocked,¤t->blocked,&ka->sa.sa_mask);
sigaddset(¤t->blocked,sig);
recalc_sigpending(current);
spin_unlock_irq(¤t->sighand->siglock);
}如前所述,recalc_sigpending()函数检查进程是否有非阻塞的挂起信号,并因此而设置它的TIF_SIGPENDING标志。然后,handle_signal()返回到do_signal(),do_signal()也立即返回。
开始执行信号处理程序
do_signal()返回时,当前进程恢复它在用户态的执行。由于如前所述setup_frame()的准备,eip寄存器指向信号处理程序的第一条指令,而esp指向已推进用户态堆栈顶的帧的第一个内存单元。因此,信号处理程序被执行。
终止信号处理程序
信号处理程序结束时,返回栈顶地址,该地址指向帧的pretcode字段所引用的vsyscall 页中的代码:
__kernel_sigreturn:
popl %eax
movl $__NR_sigreturn,%eax
int $0x80因此,信号编号(即帧的sig字段)被从栈中丢弃,然后调用sigreturn()系统调用。sys_sigreturn()函数计算类型为pt_regs的数据结构regs的地址,其中pt_regs包含用户态进程的硬件上下文。从存放在esp字段中的值,由此而导出并检查帧在用户态堆栈内的地址:
frame =(struct sigframe *)(regs.esp - 8);
if(verify_area(VERIFY_READ,frame,sizeof(*frame)){
force_sig(SIGSEGV,current);
return 0;
}然后,函数把调用信号处理程序前所阻塞的信号的位数组从帧的sc字段拷贝到current 的blocked字段。结果,为信号处理函数的执行而屏蔽的所有信号解除阻塞。然后调用recalc_sigpending()函数。此时,sys_sigreturn()函数必须把来自帧的sc字段的进程硬件上下文拷贝到内核态堆栈中,并从用户态堆栈中删除帧,这两个任务是通过调用restore_sigcontext()函数完成的。
像rt_sigqueueinfo()这样的系统调用需要与信号相关的siginfo_t表,如果信号是这种系统调用发送的,则其实现机制非常相似。扩展帧的pretcode字段指向vsyscall页面中的__kernel_rt_sigreturn代码,它依次调用rt_sigreturn()系统调用,其相应的sys_rt_sigreturn()服务例程把来自扩展帧的进程硬件上下文拷贝到内核态堆栈,并通过从用户态堆栈删除扩展帧以恢复用户态堆栈原来的内容。
系统调用的重新执行
内核并不总是能立即满足系统调用发出的请求,在这种情况发生时,把发出系统调用的进程置为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE状态。如果进程处于TASK_INTERRUPTIBLE状态,并且某个进程向它发送了一个信号,
那么,内核不完成系统调用就把进程置成TASK_RUNNING状态。当切换回用户态时信号被传递给进程。当这种情况发生时,系统调用服务例程没有完成它的工作,但返回EINTR、ERESTARTNOHAND、ERESTART_RESTARTBLOCK、ERESTARTSYS或ERESTARTNOINTR错误码。
实际上,这种情况下用户态进程获得的唯一错误码是EINTR,这个错误码表示系统调用还没有执行完(应用程序的编写者可以测试这个错误码并决定是否重新发出系统调用)。内核内部使用剩余的错误码来指定信号处理程序结束后是否自动重新执行系统调用。表11-11列出了与未完成的系统调用相关的出错码及这些出错码对信号三种可能的操作产生的影响。在表项中出现的几个术语的含义如下:
当传递信号时,内核在试图重新执行一个系统调用前必须确定进程确实发出过这个系统调用。这就是regs硬件上下文的orig_eax字段起重要作用之处。让我们回顾一下中断或异常处理程序开始时是如何初始化这个字段的:
- 中断:这个字段包含了只与中断相关的IRQ号减去256
- 0X80异常:这个字段包含系统调用号
- 其他异常:这个字段包含的值为-1
因此,orig_eax字段中的非负数意味着信号已经唤醒了在系统调用上睡眠的TASK_INTERRUPTIBLE进程。服务例程认识到系统调用曾被中断,并返回前面提到的某个错误码。
重新执行被未捕获信号中断的系统调用
如果信号被显式地忽略,或者如果它的缺省操作已被强制执行,do_signal()就分析系统调用的出错码,并如表11-11中所说明的那样决定是否重新自动执行未完成的系统调用。如果必须重新开始执行系统调用,那么do_signal()就修改regs硬件上下文,以便在进程返回到用户态时,eip指向int $0x80指令或sysenter指令,且eax包含系统调用号:
if(regs->orig_eax >= 0){
if(regs->eax ==-ERESTARTNOHAND ll regs->eax ==-ERESTARTSYS II regs->eax ==-ERESTARTNOINTR){
regs->eax = regs->orig_eax;
regs->eip -= 2;
}
if(regs->eax ==-ERESTART_RESTARTBLOCK){
regs->eax =__NR_restart_syscall;
regs->eip -= 2;
}
}把系统调用服务例程的返回代码赋给regs->eax字段。注意,int $0x80和sysreturn的长度都是两个字节,因此该函数从eip 中减去2,使eip指向引起系统调用的指令。
ERESTART_RESTARTBLOCK错误代码是特殊的,因为eax寄存器中存放了restart_syscall()的系统调用号,因此,用户态进程不会重新执行被信号中断的同一个系统调用。这个错误代码仅用于与时间相关的系统调用,当重新执行这些系统调用时,应该调整它们的用户态参数。一个典型的例子是nanosleep()系统调用。假设进程为了暂停执行20ms而调用了nanosleep(),而在10ms后出现了一个信号。如果像通常那样重新执行该系统调用(不调整其用户态参数),那么总的时间延迟会超过30ms。可以采用另一种方式,nanosleep()系统调用的服务例程把重新执行时所使用的特定服务例程的地址赋给current的thread_info结构中的restart_block字段,并在被中断时返回-ERESTART_RESTARTBLOCK。sys_restart_syscall()服务例程只执行特定的nanosleep()的服务例程,考虑到原始系统调用的调用到重新执行之间有时间间隔,该服务例程调整这种延迟。
为所捕获的信号重新执行系统调用
如果信号被捕获,那么handle_signal()分析出错码,也可能分析sigaction表的SA_RESTART标志来决定是否必须重新执行未完成的系统调用:
if(regs->orig_eax >= 0){
switch(regs->eax){
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->eax =-EINTR;
break;
case -ERESTARTSYS:
if(!(ka->sa.sa_flags & SA_RESTART)){
regs->eax =-EINTR;
break;
}
/* fallthrough */
case -ERESTARTNOINTR:
regs->eax = regs->orig_eax;
regs->eip -= 2;
}
}如果系统调用必须被重新开始执行,handle_signal()就与do_signal()完全一样地继续执行;否则,它向用户态进程返回一个出错码-EINTR。
与信号处理相关的系统调用
kill()系统调用
一般用kill(pid,sig)系统调用向普通进程或多线程应用发送信号,其相应的服务例程是sys_kill()函数。整数参数pid的几个含义取决于它的值:
pid > 0 :把sig信号发送器pid等于pid的进程所属进程组
pid = 0: 把sig信号发送到与调用进程同组的进程的所有进程组
pid = -1: 把信号发送到所有进程除了pid为0,1和当前进程以外的所有进程组
pid < -1:把信号发送到进程组-pid中进程的所有进程组
sys_kill()函数为信号建立最小的siginfo_t表,然后调用kill_something_info()函数:
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info._sifields._kill._pid = current->tgid;
info._sifields._kill._uid = current->uid;
return kill_something_info(sig,&info,pid);kill_something_info还依次调用kill_proc_info()(通过group_send_sig_info()向一个单独的线程组发送信号),或者调用kill_pg_info()(扫描目标进程组的所有进程,并为目标进程组中的每个进程调用send_sig_info()),或者为系统中的所有进程反复调用group_send_sig_info()(如果pid等于-1)。
kill()系统调用能发送任何信号,即使编号在32~64之间的实时信号。然而,我们在前面“产生信号”一节已看到,kill()系统调用不能确保把一个新的元素加入到目标进程的挂起信号队列,因此,挂起信号的多个实例可能被丢失。实时信号应当通过rt_sigqueueinfo()系统调用进行发送。
tkill()和tgkill()系统调用
tkill()和tgkill()系统调用向线程组中的指定进程发送信号。所有遵循POSIX标准的pthread库的pthread_kill()函数,都是调用这两个函数中的任意一个向指定的轻量级进程发送信号。
tkill()系统调用需要两个参数:信号接收进程的pid PID和信号编号sig。sys_tkill()服务例程为siginfo表赋值、获取进程描述符地址、进行许可性检查并调用specific_send_sig_info()发送信号。
tgkill()系统调用和tkill()有所不同,tgkill()还需要第三个参数:信号接收进程所在线程组的线程组ID(tgid)。sys_tgkill()服务例程执行的操作与sys_tkill()完全一样,不过还要检查信号接收进程是否确实属于线程组tgid。这个附加的检查解决了在向一个正在被杀死的进程发送消息时出现的竞争条件的问题:如果另外一个多线程应用正以足够快的速度创建轻量级进程,信号就可能被传递给一个错误的进程。因为线程组ID在多线程应用的整个生存期中是不会改变的,所以系统调用tgkill()解决了这个问题。
改变信号的操作
sigaction(sig,act,oact)系统调用允许用户为信号指定一个操作。当然,如果没有自定义的信号操作,那么内核执行与传递的信号相关的缺省操作。相应的sys_sigaction()服务例程作用于两个参数:sig信号编号和类型为old_sigaction 的act表(表示新的操作)。第三个可选的输出参数oact可以用来获得与信号相关的以前的操作。(old_sigaction数据结构包括与sigaction结构相同的字段,只是字段的顺序不同)。这个函数首先检查act地址的有效性。然后用*act相应的字段填充类型为k_sigaction 的new_ka局部变量的sa_handler、sa_flags和sa_mask字段:
_get_user(new_ka.sa.sa_handler,&act->sa_handler);
__get_user(new_ka.sa.sa_flags,&act->sa_flags);
-_get_user(mask,&act->sa_mask);
siginitset(&new_ka.sa.sa_mask,mask);
1234函数还调用do_sigaction()把新的new_ka表拷贝到current->sig->action的在sig-1位置的表项中(信号的编号大于在数组中的位置,因为没有0信号):
k =¤t->sig->action[sig-1];
if(act){
*k =*act;
sigdelsetmask(&k->sa.sa_mask, sigmask(SIGKILL)I sigmask(SIGSTOP));
if(k->sa.sa_handler== SIG_IGN II (k->sa.sa_handler == SIG_DFL && (sig==SIGCONT lI sig==SIGCHLD lI sig==SIGWINCH II sig==SIGURG))){
rm_from_queue(sigmask(sig),¤t->signal->shared_pending);
t = current;
do {
rm_from_queue(sigmask(sig),¤t->pending);
recalc_sigpending_tsk(t);
t = next_thread(t);
} while(t != current〉;
}
}
1234567891011121314POSIX标准规定,当缺省操作是“Ignore”时,把信号操作设置成SIG_IGN或SIG_DFL 将引起同类型的的任一挂起信号被丢弃。此外还要注意,对信号处理程序来说,不论请求屏蔽的信号是什么,SIGKILL和SIGSTOP从不被屏蔽。sigaction()系统调用还允许用户初始化表sigaction的sa_flags字段。在表11-6 (本章前面)中,我们列出了这个字段的可能取值及其相关的含义。
检查挂起的阻塞信号
sigpending()系统调用允许进程检查挂起的阻塞信号的集合,也就是说,检查信号被阻塞时已产生的那些信号。相应的服务例程sys_sigpending()只作用于一个参数set,即用户变量的地址,必须将位数组拷贝到这个变量中:
sigorsets(&pending, ¤t->pending.signal, ¤t->signal->shared_pending.signal);
sigandsets(&pending, ¤t->blocked, &pending);
copy_to_user(set, &pending, 4);
123修改阻塞信号的集合
sigprocmask()系统调用允许进程修改阻塞信号的集合。这个系统调用只应用于常规信号(非实时信号)。相应的sys_sigprocmask()服务例程作用于三个参数:
oset:进程地址空间的一个指针,指向存放以前为掩码的一个位数组
set: 进程地址空间的一个指针指向包含新位掩码的位数组
how: 一个标志可以有以下列的一个值
- SIG_BLOCK:*set位掩码数组中的信号,指定必须加到阻塞信号的位掩码
- SIG_UNBLOCK:*set位掩码数组中的信号,指定必须从阻塞信号的位掩码数组中删除的信号
- SIGG_SETMASK:*set位掩码数组中的信号,指定阻塞信号新的位掩码数组
sys_sigprocmask()调用copy_from_user()把set参数所指向的值拷贝到局部变量new_set中,并把current标准阻塞信号的位掩码数组拷贝到old_set局部变量中。然后根据how标志来指定这两个变量的值:
if(copy_from_user(&new_set, set, sizeof(*set)))
return -EFAULT;
new_set &=~(sigmask(SIGKILL) I sigmask(SIGSTOP));
old_set = current->blocked.sig[0];
if(how == SIG_BLOCK)
sigaddsetmask(¤t->blocked, new_set);
else if(how == SIG_UNBLOCK)
sigdelsetmask(¤t ->blocked, new_set);
else if(how == SIG_SETMASK)
current->blocked.sig[0]= new_set;
else
return -EINVAL;
recalc_sigpending(current);
if(oset && copy_to_user(oset, &old_set, sizeof(*oset)))
return -EFAULT;
return 0;挂起进程
sigsuspend()系统调用把进程置为TASK_INTERRUPTIBLE状态,当然这是把mask 参数指向的位掩码数组所指定的标准信号阻塞以后设置的。只有当一个非忽略、非阻塞的信号发送到进程以后,进程才被唤醒。相应的sys_sigsuspend()服务例程执行下列这些语句:
mask &=~(sigmask(SIGKILL) | sigmask(SIGSTOP));
saveset = current->blocked;
siginitset(¤t->blocked, mask);
recalc_sigpending(current);
regs->eax =-EINTR;
while (1)(
current->state = TASK_INTERRUPTIBLE;
schedule( );
if(do_signal(regs, &saveset))
return -EINTR;
}schedule()函数选择另一个进程运行。当发出sigsuspend()系统调用的进程又开始执行时,sys_sigsuspend()调用do_signal()函数来传递唤醒了该进程的信号。如果do_signal()的返回值为1,则不忽略这个信号。因此,这个系统调用返回-EINTR出错码后终止。sigsuspend()系统调用可能看似多余,因为sigprocmask()和sleep()的组合执行显然能产生同样的效果。但这并不正确:这是因为进程可能在任何时候交错执行,你必须意识到调用一个系统调用执行操作A,紧接着又调用另一个系统调用执行操作B,并不等于调用一个单独的系统调用执行操作A,然后执行操作B。
在这种特殊情况中,sigprocmask()可以在调用sleep()之前解除对所传递信号的阻塞。如果这种情况发生,进程就可以一直停留在TASK_INTERRUPTIBLE状态,等待已被传递的信号。另一方面,在解除阻塞之后、schedule()调用之前,因为其他进程在这个时间间隔内无法获得CPU,因此,sigsuspend()系统调用不允许信号被发送。
实时信号的系统调用
因为前面所提到的系统调用只应用到标准信号,因此,必须引入另外的系统调用来允许用户态进程处理实时信号。实时信号的几个系统调用(rt_sigaction()、rt_sigpending()、rt_sigprocmask()及rt_sigsuspend())与前面描述的类似,因此不再进一步讨论。
VFS 虚拟文件系统
概念
虚拟文件系统(Virtual Filesystem)也可以称之为虚拟文件系统转换(Virtual Filesystem Switch),是一个内核软件层,用来处理与Unix标准文件系统相关的所有系统调用。其健壮性表现在能为各种文件系统提供一个通用的接口。可以认为它屏蔽了不同文件系统之间的实现细节转而依赖它们的接口。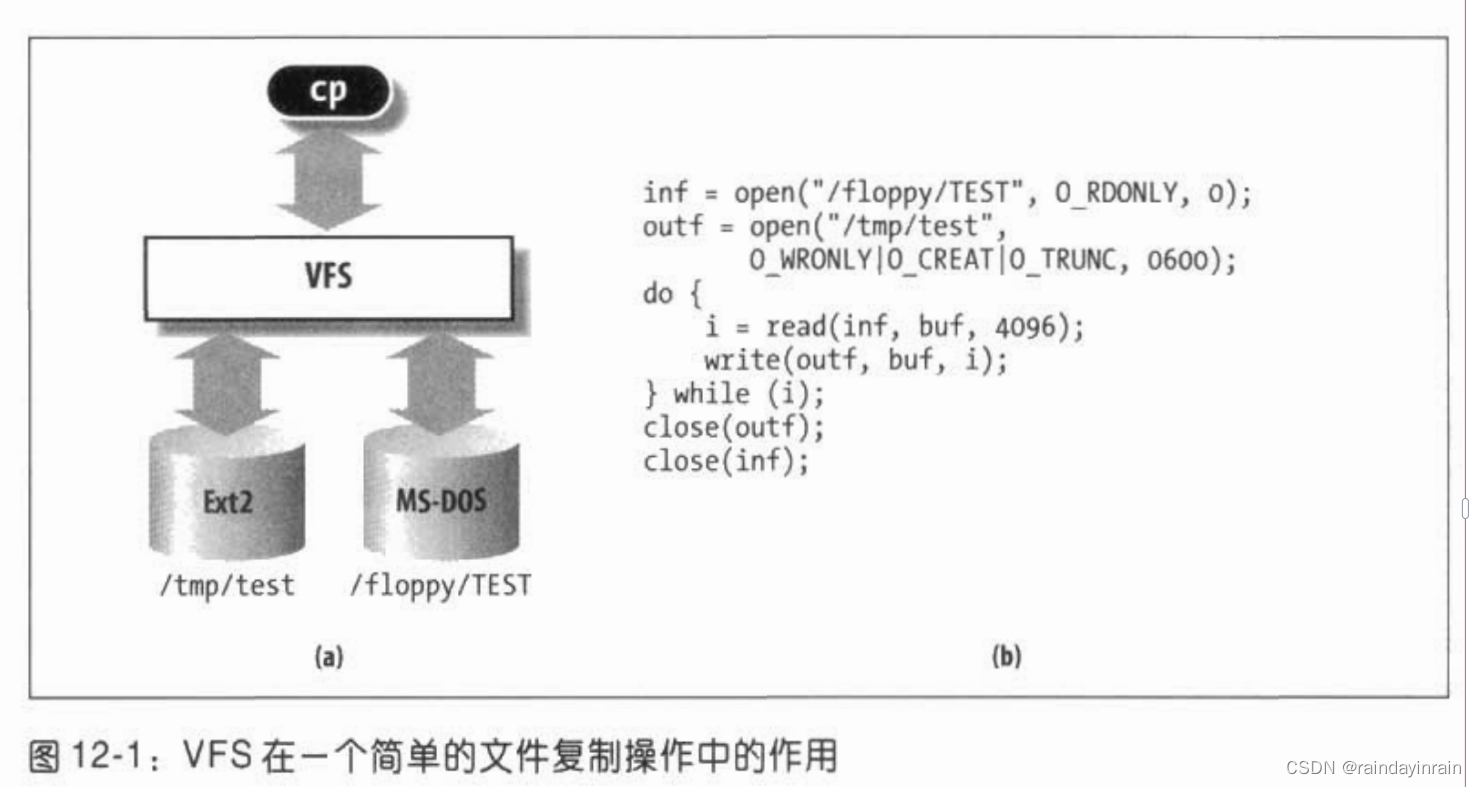
VFS支持的文件系统可以划分为三种主要类型:
- 磁盘文件系统
这些文件系统管理在本地磁盘分区中可用的存储空间或者其他可以起到磁盘作用的设备(比如说一个USB闪存)。VFS支持的基于磁盘的某些著名文件系统有:Disk-based 文件系统:Ext2, ext3, ReiserFS,Sysv, UFS, MINIX, VxFS,VFAT, NTFS,ISO9660 CD-ROM, UDF DVD,HPFS, HFS, AFFS, ADFS等等 - 网络文件系统
这些文件系统允许轻易地访问属于其他网络计算机的文件系统所包含的文件。虚拟文件系统所支持的一些著名的网络文件系统有:NFS、Coda、AFS(Andrew文件系统)、CIFS(用于Microsoft Windows的通用网络文件系统)以及NCP(Novell 公司的NetWare Core Protocol)。 - 特殊文件系统
这些文件系统不管理本地或者远程磁盘空间。/proc文件系统是特殊文件系统的一个典型范例(参见稍后“特殊文件系统“一节)。
根目录包含在根文件系统(root filesystem)中,在Linux中这个根文件系统通常就是Ext2或Ext3类型。其他所有的文件系统都可以被“安装“在根文件系统的子目录中基于磁盘的文件系统通常存放在硬件块设备中,如硬盘、软盘或者CD-ROM。Linux VFS 的一个有用特点是能够处理如/dev/loop0这样的虚拟块设备,这种设备可以用来安装普通文件所在的文件系统。作为一种可能的应用,用户可以保护自己的私有文件系统,这可以通过把自己文件系统的加密版本存放在一个普通文件中来实现。
通用文件模型
VFS所隐含的主要思想在于引入了一个通用的文件模型(common file model),这个模型能够表示所有支持的文件系统。该模型严格反映传统Unix文件系统提供的文件模型。
例如,在通用文件模型中,每个目录被看作一个文件,可以包含若干文件和其他的子目录。但是,存在几个非Unix的基于磁盘的文件系统,它们利用文件分配表(File Allocation Table,FAT)存放每个文件在目录树中的位置,在这些文件系统中,存放的是目录而不是文件。为了符合VFS的通用文件模型,对上述基于FAT的文件系统的实现,Linux必须在必要时能够快速建立对应于目录的文件。这样的文件只作为内核内存的对象而存在。
从本质上说,Linux内核不能对一个特定的函数进行硬编码来执行诸如read()或ioctl()这样的操作,而是对每个操作都必须使用一个指针,指向要访问的具体文件系统的适当函数为了进一步说明这一概念,参见图12-1,其中显示了内核如何把read()转换为专对MS-DOS文件系统的一个调用。应用程序对read()的调用引起内核调用相应的sys_read()服务例程,这与其他系统调用完全类似。
文件在内核内存中是由一个file数据结构来表示的。这种数据结构中包含一个称为f_op的字段,该字段中包含一个指向专对MS-DOS文件的函数指针,当然还包括读文件的函数。sys_read()查找到指向该函数的指针,并调用它。这样一来,应用程序的read()就被转化为相对间接的调用:file->f_op->read(…);与之类似,write()操作也会引发一个与输出文件相关的Ext2写函数的执行。简而言之,内核负责把一组合适的指针分配给与每个打开文件相关的file变量,然后负责调用针对每个具体文件系统的函数(由f_op字段指向)。(人话,调用具体的函数指针,想想虚函数表)
通用文件模型有下列对象组成:
- 超级块对象存放在已安装文件系统的有关信息,对基于磁盘的文件系统,,它们通常对应于存放在磁盘上的文件控制块
- 索引节点对象:也就是Iinode存放关于具体文件的一般信息
- 文件对象:存放打开文件与进程之间进行交互的有关信息,这类信息仅当进程访问文件期间存在于内核内存中!
- 目录项对象:存放目录项与对应文件进行链接的有关信息
如图12-2所示是一个简单的示例,说明进程怎样与文件进行交互。三个不同进程已经打开同一个文件,其中两个进程使用同一个硬链接。在这种情况下,其中的每个进程都使用自己的文件对象,但只需要两个目录项对象,每个硬链接对应一个目录项对象。这两个目录项对象指向同一个索引节点对象,该索引节点对象标识超级块对象,以及随后的普通磁盘文件。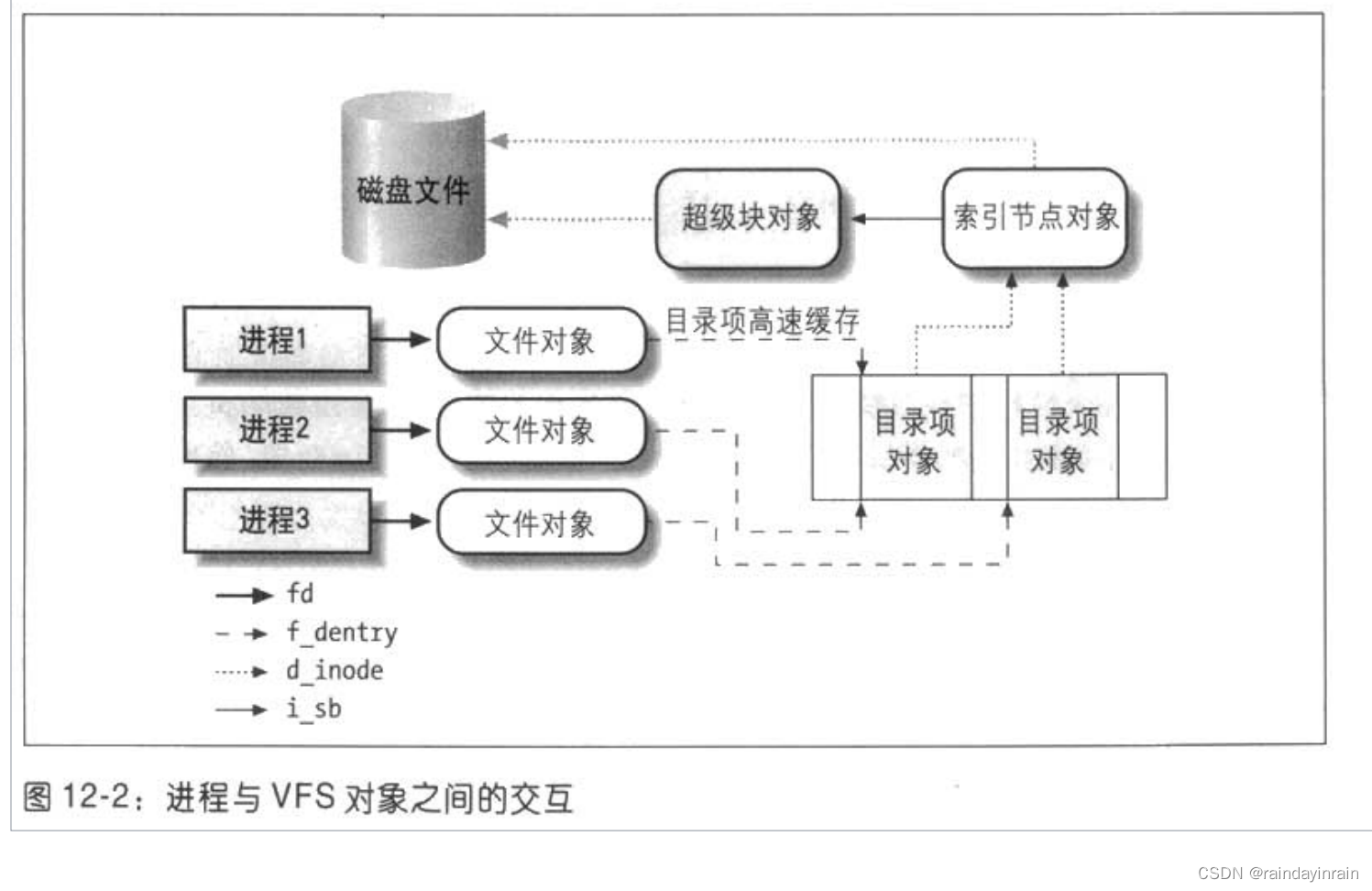
VFS除了能为所有文件系统的实现提供一个通用接口外,还具有另一个与系统性能相关的重要作用。最近最常使用的目录项对象被放在所谓目录项高速缓存(dentrycache)的磁盘高速缓存中,以加速从文件路径名到最后一个路径分量的索引节点的转换过程。
一般说来,磁盘高速缓存(diskcache)属于软件机制,它允许内核将原本存在磁盘上的某些信息保存在RAM中,以便对这些数据的进一步访问能快速进行,而不必慢速访问磁盘本身。
注意,磁盘高速缓存不同于硬件高速缓存(硬件高速缓存)或内存高速缓存(动态内存分配器),后两者都与磁盘或其他设备无关。硬件高速缓存是一个快速静态RAM,它加快了直接对慢速动态RAM的请求。内存高速缓存是一种软件机制,引入它是为了绕过内核内存分配器。除了目录项高速缓存和索引结点高速缓存之外,Linux还使用其他磁盘高速缓存。其中最重要的一种就是所谓的页高速缓存。
VFS所处理的系统调用
表12-1列出了VFS的系统调用,这些系统调用涉及文件系统、普通文件、目录文件以及符号链接文件。另外还有少数几个由VFS处理的其他系统调用,诸如ioperm()、ioctl()、pipe()和mknod(),涉及设备文件和管道文件,这些将在后续章节中讨论。最后一组由VFS处理的系统调用,诸如socket()、connect()和bind()属于套接字系统调用,并用于实现网络功能。与表12-1列出的系统调用对应的一些内核服务例程,我们会在本章或第十八章中陆续进行讨论。
- 文件系统相关:mount, umount, umount2, sysfs, statfs, fstatfs, fstatfs64, ustat
- 目录相关:chroot,pivot_root,chdir,fchdir,getcwd,mkdir,rmdir,getdents,getdents64,readdir,link,unlink,rename,lookup_dcookie
- 链接相关:readlink,symlink
- 文件相关:chown, fchown,lchown,chown16,fchown16,lchown16,hmod,fchmod,utime,stat,fstat,lstat,acess,oldstat,oldfstat,oldlstat,stat64,lstat64,lstat64,open,close,creat,umask,dup,dup2,fcntl, fcntl64,select,poll,truncate,ftruncate,truncate64,ftruncate64,lseek,llseek,read,write,readv,writev,sendfile,sendfile64,readahead
前面我们已经提到,VFS是应用程序和具体文件系统之间的一层。不过,在某些情况下,一个文件操作可能由VFS本身去执行,无需调用低层函数。例如,当某个进程关闭一个打开的文件时,并不需要涉及磁盘上的相应文件,因此VFS只需释放对应的文件对象。类似地,当系统调用lseek()修改一个文件指针,而这个文件指针是打开文件与进程交互所涉及的一个属性时,VFS就只需修改对应的文件对象,而不必访问磁盘上的文件,因此,无需调用具体文件系统的函数。从某种意义上说,可以把VFS看成“通用“文件系统,它在必要时依赖某种具体文件系统。
VFS的数据结构
每个VFS对象都存放在一个适当的数据结构中,其中包括对象的属性和指向对象方法表的指针。内核可以动态地修改对象的方法,因此可以为对象建立专用的行为。下面几节详细介绍VFS的对象及其内在关系。
超级块对象
超级块对象由super_block结构组成,表12-2列举了其中的字段。
| 字段 | 说明 |
|---|---|
| s_list | 指向超级块链表的指针,这个struct list_head是很熟悉的结构了,里面其实就是用于连接关系的prev和next字段。内核中的结构处理都是有讲究的(内核协议栈中也说过),内核单独使用一个简单的结构体将所有的super_block都链接起来,但是这个结构不是super_block本身,因为本身数据结构太大,效率不高,所有仅仅使用 `struct{list_head prev;list_head next;}这样的结构来将super_block中的s_list链接起来,那么遍历到s_list之后,直接读取super_block这么长的一个内存块,就可以将这个这个块读取进来 |
| s_dev | 包含该具体文件系统的块设备标识符。例如,对于 /dev/hda1,其设备标识符为 0x301 |
| s_blocksize | 文件系统中数据块大小,以字节单位 |
| s_blocksize_bits | 上面的size大小占用位数,例如512字节就是9 bits |
| s_dirt | 脏位,标识是否超级块被修改 |
| s_maxbytes | 允许的最大的文件大小(字节数) |
| struct file_system_type *s_type | 文件系统类型(也就是当前这个文件系统属于哪个类型?ext2还是fat32)要区分“文件系统”和“文件系统类型”不一样!一个文件系统类型下可以包括很多文件系统即很多的super_block,后面会说! |
| struct super_operations *s_op | 指向某个特定的具体文件系统的用于超级块操作的函数集合 |
| struct dquot_operations *dq_op | 指向某个特定的具体文件系统用于限额操作的函数集合 |
| struct quotactl_ops *s_qcop | 用于配置磁盘限额的的方法,处理来自用户空间的请求 |
| s_magic | 区别于其他文件系统的标识 |
| s_root | 指向该具体文件系统安装目录的目录项 |
| s_flags | 安装标识 |
| s_umount: | 对超级块读写时进行同步 |
| s_lock: | 锁标志位,若置该位,则其它进程不能对该超级块操作 |
| s_count: | 对超级块的使用计数 |
| s_active: | 引用计数 |
| s_dirty: | 已修改的索引节点inode形成的链表,一个文件系统中有很多的inode,有些inode节点的内容会被修改,那么会先被记录,然后写回磁盘。 |
| s_locked_inodes: | 要进行同步的索引节点形成的链表 |
| s_files: | 所有的已经打开文件的链表,这个file和实实在在的进程相关的 |
| s_bdev: | 指向文件系统被安装的块设备 |
| u: | u 联合体域包括属于具体文件系统的超级块信息 |
| s_instances: | 具体的意义后来会说的!(同一类型的文件系统通过这个子墩将所有的super_block连接起来) |
| s_dquot: | 磁盘限额相关选项 |
所有超级块对象都以双向循环链表的形式链接在一起。链表中第一个元素用super_blocks变量来表示,而超级块对象的s_list字段存放指向链表相邻元素的指针。sb_lock自旋锁保护链表免受多处理器系统上的同时访问。
s_fs_info字段指向属于具体文件系统的超级块信息;例如,假如超级块对象指的是Ext2文件系统,该字段就指向ext2_sb_info数据结构,该结构包括磁盘分配位掩码和其他与VFS的通用文件模型无关的数据。通常,为了效率起见,由s_fs_info字段所指向的数据被复制到内存。任何基于磁盘的文件系统都需要访问和更改自己的磁盘分配位图,以便分配或释放磁盘块。VFS允许这些文件系统直接对内存超级块的s_fs_info字段进行操作,而无需访问磁盘。但是,这种方法带来一个新问题:有可能VFS超级块最终不再与磁盘上相应的超级块同步。
因此,有必要引入一个s_dirt标志来表示该超级块是否是脏的——那磁盘上的数据是否必须要更新。缺乏同步还会导致产生我们熟悉的一个问题:当一台机器的电源突然断开而用户来不及正常关闭系统时,就会出现文件系统崩溃。Linux是通过周期性地将所有“脏“的超级块写回磁盘来减少该问题带来的危害。
与超级块关联的方法就是所谓的超级块操作。这些操作是由数据结构super_operations 来描述的,该结构的起始地址存放在超级块的s_op字段中。每个具体的文件系统都可以定义自己的超级块操作。当VFS需要调用其中一个操作时,比如说read_inode(),它执行下列操作:sb->s_op->read_inode(inode);这里sb存放所涉及超级块对象的地址。super_operations表的read_inode字段存放这一函数的地址,因此,这一函数被直接调用。让我们简要描述一下超级块操作,其中实现了一些高级操作,比如删除文件或安装磁盘。下面这些操作按照它们在super_operation表中出现的顺序来排列:
| 操作 | 操作 |
|---|---|
| alloc_inode | 被inode_alloc()函数调用用于分配inode内存并进行inode结构初始化。如果函数未定义,则简单的分配一个’struct inode’。通常alloc_inode用于底层文件系统分配一个包含inode结构体的更大的结构体(特定的inode结构,如:fuse_inode)。 |
| destroy_inode: | 被destroy_inode()函数调用用于释放inode相关申请的资源。只有alloc_inode定义了才需要定义destroy_inode,并且释放的也是alloc_inode里申请的相关资源。 |
| dirty_inode: | 由VFS调用标记inode dirty(元数据信息被修改过并且没有同步到磁盘或服务器)。 |
| write_inode: | 由VFS调用用于将inode同步到磁盘。第二个参数用于标识是否同步写盘 |
| drop_inode: | VFS在当inode的引用计数减为0时,调用该函数。调用者已经持有了inode->i_lock。该函数返回0,则inode将可能被丢到LRU链表里,返回1则会由调用者继续调用evict_inode和destroy_inode。如果文件系统不需要缓存inode,则该函数可以设置为NULL或者generic_delete_inode(函数里直接return 1) |
| delete_inode: | VFS删除inode时直接调用该函数。由于查看的Linux文档版本是2.6.39,所以有该函数指针,在3.10版本已经没有了detele_inode。 |
| put_super: | VFS想要释放sb时调用(如umount操作)。调用者已经持有sb的lock。 |
| sync_fs: | VFS想要把该文件系统所有的脏数据刷盘时调用。 |
| freeze_fs: | 目前只有LVM使用。用于冻结文件系统,不能进行写入操作 |
| unfreeze_fs: | 解冻文件系统,使其可以写入。 |
| statfs: | 用于获取文件系统的统计信息。 |
| remount_fs: | 用于重新挂载文件系统,调用者持有kernel lock。 |
| clear_inode: | 同样在3.10版本没有了。 |
| umount_begin: | 用于umount文件系统。 |
| show_options: | 用于/proc/mounts里显示文件系统的mount选项。 |
| quota_read和quota_write: | 用于读写文件系统的quota文件。 |
| nr_cached_objects和free_cache_objects | 用于返回可以释放的cache对象个数,以及进行实际的释放对象操作。 |
前述的方法对所有可能的文件系统类型均是可用的。但是,只有其中的一个子集应用到每个具体的文件系统;未实现的方法对应的字段置为NULL。注意,系统没有定义get_super方法来读超级块,那么,内核如何能够调用一个对象的方法而从磁盘读出该对象?我们将在描述文件系统类型的另一个对象中找到等价的get_sb方法。
索引节点对象(inode)
文件系统处理文件所需要的所有信息都放在一个名为索引节点的数据结构中。文件名可以随时更改,但是索引节点对文件是唯一的,并且随文件的存在而存在。内存中的索引节点对象由一个inode数据结构组成,其字段如表12-3所示。
struct inode {
umode_t i_mode; /* 访问权限 */
unsigned short i_opflags;
kuid_t i_uid; /* 使用者id */
kgid_t i_gid; /* 使用组id */
unsigned int i_flags; /* 文件系统标志 */
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl; /* 访问控制列表相关 */
struct posix_acl *i_default_acl;
#endif
const struct inode_operations *i_op; /* 索引节点操作函数 */
struct super_block *i_sb; /* 所属的超级块 */
struct address_space *i_mapping; /* 地址映射 */
#ifdef CONFIG_SECURITY
void *i_security; /* 安全模块 */
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino; /* 节点号 */
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink;
unsigned int __i_nlink; /*硬链接数,对于目录来说,是子目录数目*/
};
dev_t i_rdev; /* 实际设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改时间 */
struct timespec i_ctime; /* 最后改变时间 */
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;
unsigned int i_blkbits;
blkcnt_t i_blocks;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount; /* 对i_size进行串行计数 */
#endif
/* Misc */
unsigned long i_state; /* 状态标志 */
struct rw_semaphore i_rwsem;
unsigned long dirtied_when; /* jiffies of first dirtying */
unsigned long dirtied_time_when;
struct hlist_node i_hash; /*散列表,用于快速查找inode */
struct list_head i_io_list; /* backing dev IO list */
#ifdef CONFIG_CGROUP_WRITEBACK
struct bdi_writeback *i_wb; /* the associated cgroup wb */
/* foreign inode detection, see wbc_detach_inode() */
int i_wb_frn_winner;
u16 i_wb_frn_avg_time;
u16 i_wb_frn_history;
#endif
struct list_head i_lru; /* inode LRU list */
struct list_head i_sb_list; /* 超级块链表 */
struct list_head i_wb_list; /* backing dev writeback list */
union {
struct hlist_head i_dentry; /* 目录项链表 */
struct rcu_head i_rcu;
};
u64 i_version;
atomic_t i_count; /* 引用计数 */
atomic_t i_dio_count;
atomic_t i_writecount; /* 写者计数 */
#ifdef CONFIG_IMA
atomic_t i_readcount; /* struct files open RO */
#endif
const struct file_operations *i_fop; /* 缺省的索引节点操作 former ->i_op->default_file_ops */
struct file_lock_context *i_flctx;
struct address_space i_data; /* 设备地址映射 */
struct list_head i_devices; /* 块设备链表 */
union {
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备信息 */
struct cdev *i_cdev; /* 字符设备信息 */
char *i_link;
unsigned i_dir_seq;
};
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct hlist_head i_fsnotify_marks;
#endif
#if IS_ENABLED(CONFIG_FS_ENCRYPTION)
struct fscrypt_info *i_crypt_info;
#endif
void *i_private; /* fs or device private pointer */
};| 字段 | 说明 |
|---|---|
| i_hash: | 指向hash链表指针,用于inode的hash表 |
| i_list: | 指向索引节点链表指针,用于inode之间的连接 |
| i_dentry: | 指向目录项链表指针,注意一个inodes可以对应多个dentry,因为一个实际的文件可能被链接到其他的文件,那么就会有另一个dentry,这个链表就是将所有的与本inode有关的dentry都连在一起。 |
| i_dirty_buffers和i_dirty_data_buffers: | 脏数据缓冲区 |
| i_ino: | 索引节点号,每个inode都是唯一的 |
| i_count: | 引用计数 |
| i_dev: | 如果inode代表设备,那么就是设备号 |
| i_mode: | 文件的类型和访问权限 |
| i_nlink: | 与该节点建立链接的文件数(硬链接数) |
| i_uid: | 文件拥有者标号 |
| i_gid: | 文件所在组标号 |
| i_rdev: | 实际的设备标识(注意i_dev和i_rdev之间区别:如果是普通的文件,例如磁盘文件,存储在某块磁盘上,那么i_dev代表的就是保存这个文件的磁盘号,但是如果此处是特殊文件例如就是磁盘本身(因为所有的设备也看做文件处理),那么i_rdev就代表这个磁盘实际的磁盘号。) |
| i_size: | inode所代表的的文件的大小,以字节为单位 |
| i_atime: | 文件最后一次访问时间 |
| i_mtime: | 文件最后一次修改时间 |
| i_ctime: | inode最后一次修改时间 |
| i_blkbits: | 单位块大小,字节 |
| i_blksize: | 块大小,bit单位 |
| i_blocks: | 文件所占块数 |
| i_version: | 版本号 |
| i_bytes: | 文件中最后一个块的字节数 |
| i_sem: | 指向用于同步操作的信号量结构 |
| i_alloc_sem: | 保护inode上的IO操作不被另一个打断 |
| i_zombie: | 僵尸inode信号量 |
| i_op: | 索引节点操作 |
| i_fop: | 文件操作 |
| i_sb: | inode所属文件系统的超级块指针 |
| i_wait: | 指向索引节点等待队列指针 |
| i_flock: | 文件锁链表(注意:address_space不是代表某个地址空间,而是用于描述页高速缓存中的页面的。一个文件对应一个address_space,一个address_space和一个偏移量可以确定一个页高速缓存中的页面。) |
| i_mapping: | 表示向谁请求页面 |
| i_data: | 表示被inode读写的页面 |
| i_dquot: | inode的磁盘限额(关于磁盘限额:在多任务环境下,对于每个用户的磁盘使用限制是必须的,起到一个公平性作用。磁盘限额分为两种:block限额和inode限额,而且对于一个特文件系统来说,使用的限额机制都是一样的,所以限额的操作函数放在super_block中就OK!) |
| i_devices: | 设备链表。共用同一个驱动程序的设备形成的链表 |
| i_pipe: | 指向管道文件(如果文件是管道文件时使用) |
| i_bdev: | 指向块设备文件指针(如果文件是块设备文件时使用) |
| i_cdev: | 指向字符设备文件指针(如果文件是字符设备时使用) |
| i_dnotify_mask: | 目录通知事件掩码 |
| i_dnotify: | 用于目录通知 |
| i_state: | 索引节点的状态标识:I_NEW,I_LOCK,I_FREEING |
| i_flags: | 索引节点的安装标识 |
| i_sock: | 如果是套接字文件则为True |
| i_write_count: | 记录多少进程以刻写模式打开此文件 |
| i_attr_flags: | 文件创建标识 |
| i_generation: | 保留 |
| u: | 具体的inode信息 |
每个索引节点对象都会复制磁盘索引节点包含的一些数据,比如分配给文件的磁盘块数。如果i_state字段的值等于I_DIRTY_SYNC、I_DIRTY_DATASYNC或I_DIRTY_PAGES,该索引节点就是“脏“的,也就是说,对应的磁盘索引节点必须被更新。I_DIRTY宏可以用来立即检查这三个标志的值。i_state字段的其他值有I_LOCK(涉及的索引节点对象处于I/O传送中)、I_FREEING(索引节点对象正在被释放)、I_CLEAR(索引节点对象的内容不再有意义)以及I_NEW(索引节点对象已经分配但还没有用从磁盘索引节点读取来的数据填充)。
每个索引节点对象总是出现在下列双向循环链表的某个链表中(所有情况下,指向相邻元素的指针存放在i_list字段中):
- 有效未使用的索引节点链表,典型的如那些镜像有效的磁盘索引节点,且当前未被任何进程使用。这些索引节点不为脏,且它们的i_count字段置为0。链表中的首元素和尾元素是由变量inode_unused的next字段和prev字段分别指向的。这个链表用作磁盘高速缓存。
- 正在使用的索引节点链表,也就是那些镜像有效的磁盘索引节点,且当前被某些进程使用。这些索引节点不为脏,但它们的i_count字段为正数。链表中的首元素和尾元素是由变量inode_in_use引用的。
- 脏索引节点的链表。链表中的首元素和尾元素是由相应超级块对象的s_dirty字段引用的。这些链表都是通过适当的索引节点对象的i_list字段链接在一起的。
此外,每个索引节点对象也包含在每文件系统(per-filesystem)的双向循环链表中,链表的头存放在超级块对象的s_inodes字段中;索引节点对象的i_sb_list字段存放了指向链表相邻元素的指针。
最后,索引节点对象也存放在一个称为inode_hashtable的散列表中。散列表加快了对索引节点对象的搜索,前提是系统内核要知道索引节点号及文件所在文件系统对应的超级块对象的地址。由于散列技术可能引发冲突,所以索引节点对象包含一个i_hash字段,该字段中包含向前和向后的两个指针,分别指向散列到同一地址的前一个索引节点和后一个索引节点;该字段因此创建了由这些索引节点组成的一个双向链表。
与索引节点对象关联的方法也叫索引节点操作。它们由inode_operations结构来描述,该结构的地址存放在i_op字段中。以下是索引节点的操作,以它们在inode_operations表中出现的次序来排列:
| 操作 | 说明 |
|---|---|
| create(dir, dentry, mode, nameidata) | 在某一目录下,为与目录项对象相关的普通文件创建一个新的磁盘索引节点。 |
| lookup(dir, dentry, nameidata) | 为包含在一个目录项对象中的文件名对应的索引节点查找目录。 |
| link(old_dentry, dir, new_dentry) | 创建一个新的名为new_dentry的硬链接,它指向dir目录下名为old_dentry的文件。 |
| unlink(dir, dentry) | 从一个目录中删除目录项对象所指定文件的硬链接。 |
| symlink(dir, dentry, symname) | 在某个目录下,为与目录项对象相关的符号链接创建一个新的索引节点。 |
| mkdir(dir, dentry, mode) | 在某个目录下,为与目录项对象相关的目录创建一个新的索引节点。 |
| rmdir(dir, dentry) | 从一个目录删除子目录,子目录的名称包含在目录项对象中。 |
| mknod(dir, dentry, mode, rdev) | 在某个目录中位于目录项对象相关的特定文件创建一个新的磁盘索引节点!其中参数mode和rdev分别表示文件的类型和设备的 |
| rename(old_dir, old_dentry, new_dir, new_dentry) | 将old_dir目录下由old_entry标识的文件移到new_dir目录下。新文件名包含在new_dentry指向的目录项对象中。 |
| readlink(dentry, buffer, buflen) | 将目录项所指定的符号链接中对应的文件路径名拷贝到buffer所指定的用户态内存区。 |
| follow_link(inode, nameidata) | 解析索引节点对象所指定的符号链接;如果该符号链接是一个相对路径名,则从第二个参数所指定的目录开始进行查找。 |
| put_link(dentry, nameidata) | 释放由 follow_link方法分配的用于解析符号链接的所有临时数据结构。 |
| truncate(inode) | 修改与索引节点相关的文件长度。在调用该方法之前,必须将inode对象的i_size字段设置为需要的新长度值。 |
| permission(inode, mask, nameidata) | 检查是否允许对与索引节点所指的文件进行指定模式的访问。 |
| setattr(dentry, iattr) | 在触及索引节点属性后通知一个“修改事件“。 |
| getattr(mnt, dentry, kstat) | 由一些文件系统用于读取索引节点属性。 |
| setxattr(dentry, name, value, size, flags) | 为索引节点设置“扩展属性“(扩展属性存放在任何索引节点之外的磁盘块中)。 |
| getxattr(dentry, name, buffer, size) | 获取索引节点的扩展属性。 |
| listxattr(dentry, buffer, size) | 获取扩展属性名称的整个链表。 |
| removexattr(dentry, name) | 删除索引节点的扩展属性。上述列举的方法对所有可能的索引节点和文件系统类型都是可用的。不过,只有其中的一个子集应用到某一特定的索引节点和文件系统;未实现的方法对应的字段被置为NULL。 |
文件对象
文件对象描述进程怎样与一个打开的文件进行交互。文件对象是在文件被打开时创建的,由一个file结构组成,其中包含的字段如表12-4所示。注意,文件对象在磁盘上没有对应的映像,因此file结构中没有设置“脏“字段来表示文件对象是否已被修改。
| 字段 | 说明 |
|---|---|
| f_list | 用于通用文件对象链表的指针 |
| f_dentry | 与文件相关的目录项对象 |
| f_vfsmnt | 含有该文件的已安装文件系统 |
| f_op | 指向文件操作表的指针 |
| f_count | 文件对象的引用计数器 |
| f_flags | 当打开文件时所指定的标志 |
| f_mode | 进程的访问模式 |
| f_error | 网络写操作的错误码 |
| f_pos | 当前的文件位移量(文件指针) |
| f_version | 版本号,每次使用后自动递增 |
| f_security | 指向文件对象的安全结构的指针 |
| private_data | 指向特定文件系统或设备驱动程序所需的数据 的指针 |
| f_ep_links | 文件的事件轮询等待者链表的头 |
| f_ep_lock | 保护f_ep_links链表的自旋锁 |
| f_mapping | 指向文件地址空间对象的指针 |
存放在文件对象中的主要信息是文件指针,即文件中当前的位置,下一个操作将在该位置发生。由于几个进程可能同时访问同一文件,因此文件指针必须存放在文件对象而不是索引节点对象中。
文件对象通过一个名为filp的slab高速缓存分配,filp描述符地址存放在filp_cachep 变量中。由于分配的文件对象数目是有限的,因此files_stat变量在其max_files字段中指定了可分配文件对象的最大数目,也就是系统可同时访问的最大文件数(注4)。
在使用“文件对象包含在由具体文件系统的超级块所确立的几个链表中。每个超级块对象把文件对象链表的头存放在s_files字段中;因此,属于不同文件系统的文件对象就包含在不同的链表中。链表中分别指向前一个元素和后一个元素的指针都存放在文件对象的f_list字段中。files_lock自旋锁保护超级块的s_files链表免受多处理器系统上的同时访问。
文件对象的f_count字段是一个引用计数器:它记录使用文件对象的进程数(记住,以CLONE_FILES标志创建的轻量级进程共享打开文件表,因此它们可以使用相同的文件对象)。当内核本身使用该文件对象时也要增加计数器的值——例如,把对象插入链表中或发出dup()系统调用时。
当VFS代表进程必须打开一个文件时,它调用get_empty_filp()函数来分配一个新的文件对象。该函数调用kmem_cache_alloc()从filp高速缓存中获得一个空闲的文件对象,然后初始化这个对象的字段,如下所示:
// 重置
memset(f, 0, sizeof(*f));
// 初始化
INIT_LIST_HEAD(&f->f_ep_links);
spin_lock_init(&f->f_ep_lock);
atomic_set(&f->f_count, 1);
f->f_uid = current->fsuid;
f->f_gid = current->fsgid;
f->f_owmer.lock = RW_LOCK_UNLOCKED;
INIT_LIST_HEAD(&f->f_list〉;
f->f_maxcount = INT_MAX; 正如在“通用文件模型“一节中讨论过的那样,每个文件系统都有其自己的文件操作集合,执行诸如读写文件这样的操作。当内核将一个索引节点从磁盘装入内存时,就会把指向这些文件操作的指针存放在file_operations结构中,而该结构的地址存放在该索引节点对象的i_fop字段中。
当进程打开这个文件时,VFS就用存放在索引节点中的这个地址初始化新文件对象的f_op字段,使得对文件操作的后续调用能够使用这些函数。如果需要,VFS随后也可以通过在f_op字段存放一个新值而修改文件操作的集合。下面的列表描述了文件的操作,以它们在file_operations表中出现的次序来排列:
- loff_t (llseek) (struct file filp , loff_t p, int orig);
(指针参数filp为进行读取信息的目标文件结构体指针;参数 p 为文件定位的目标偏移量;参数orig为对文件定位的起始地址,这个值可以为文件开头(SEEK_SET,0,当前位置(SEEK_CUR,1),文件末尾(SEEK_END,2))
llseek 方法用作改变文件中的当前读/写位置, 并且新位置作为(正的)返回值.
loff_t 参数是一个”long offset”, 并且就算在 32位平台上也至少 64 位宽. 错误由一个负返回值指示;如果这个函数指针是 NULL, seek 调用会以潜在地无法预知的方式修改 file 结构中的位置计数器( 在”file 结构” 一节中描述).
ssize_t (read) (struct file filp, char __user buffer, size_t size , loff_t p);
(指针参数 filp 为进行读取信息的目标文件,指针参数buffer 为对应放置信息的缓冲区(即用户空间内存地址),参数size为要读取的信息长度,参数 p 为读的位置相对于文件开头的偏移,在读取信息后,这个指针一般都会移动,移动的值为要读取信息的长度值)这个函数用来从设备中获取数据。在这个位置的一个空指针导致 read 系统调用以 -EINVAL(“Invalid argument”) 失败。一个非负返回值代表了成功读取的字节数( 返回值是一个 “signed size” 类型, 常常是目标平台本地的整数类型).
ssize_t (aio_read)(struct kiocb , char __user * buffer, size_t size , loff_t p);
可以看出,这个函数的第一、三个参数和本结构体中的read()函数的第一、三个参数是不同 的,异步读写的第三个参数直接传递值,而同步读写的第三个参数传递的是指针,因为AIO从来不需要改变文件的位置。异步读写的第一个参数为指向kiocb结构体的指针,而同步读写的第一参数为指向file结构体的指针,每一个I/O请求都对应一个kiocb结构体);初始化一个异步读 -- 可能在函数返回前不结束的读操作.如果这个方法是 NULL, 所有的操作会由 read 代替进行(同步地ssize_t (write) (struct file filp, const char __user buffer, size_t count, loff_t ppos);
(参数filp为目标文件结构体指针,buffer为要写入文件的信息缓冲区,count为要写入信息的长度,ppos为当前的偏移位置,这个值通常是用来判断写文件是否越界)
发送数据给设备.。如果 NULL, -EINVAL 返回给调用 write 系统调用的程序. 如果非负, 返回值代表成功写的字节数。
(注:这个操作和上面的对文件进行读的操作均为阻塞操作)
- ssize_t (aio_write)(struct kiocb , const char __user buffer, size_t count, loff_t ppos);
初始化设备上的一个异步写.参数类型同aio_read()函数; - int (readdir) (struct file filp, void *, filldir_t);
对于设备文件这个成员应当为 NULL; 它用来读取目录, 并且仅对文件系统有用. - unsigned int (poll) (struct file , struct poll_table_struct *);
(这是一个设备驱动中的轮询函数,第一个参数为file结构指针,第二个为轮询表指针)
这个函数返回设备资源的可获取状态,即POLLIN,POLLOUT,POLLPRI,POLLERR,POLLNVAL等宏的位“或”结果。每个宏都表明设备的一种状态,如:POLLIN(定义为0x0001)意味着设备可以无阻塞的读,POLLOUT(定义为0x0004)意味着设备可以无阻塞的写。
(poll 方法是 3 个系统调用的后端: poll, epoll, 和 select, 都用作查询对一个或多个文件描述符的读或写是否会阻塞.poll 方法应当返回一个位掩码指示是否非阻塞的读或写是可能的, 并且, 可能地, 提供给内核信息用来使调用进程睡眠直到 I/O 变为可能. 如果一个驱动的 poll 方法为 NULL, 设备假定为不阻塞地可读可写.
(这里通常将设备看作一个文件进行相关的操作,而轮询操作的取值直接关系到设备的响应情况,可以是阻塞操作结果,同时也可以是非阻塞操作结果)
int (ioctl) (struct inode inode, struct file *filp, unsigned int cmd, unsigned long arg);
(inode 和 filp 指针是对应应用程序传递的文件描述符 fd 的值, 和传递给 open 方法的相同参数.cmd 参数从用户那里不改变地传下来, 并且可选的参数 arg 参数以一个 unsigned long 的形式传递, 不管它是否由用户给定为一个整数或一个指针.如果调用程序不传递第 3 个参数, 被驱动操作收到的 arg 值是无定义的.因为类型检查在这个额外参数上被关闭, 编译器不能警告你如果一个无效的参数被传递给 ioctl, 并且任何关联的错误将难以查找.)ioctl 系统调用提供了发出设备特定命令的方法(例如格式化软盘的一个磁道, 这不是读也不是写). 另外, 几个 ioctl 命令被内核识别而不必引用 fops 表.如果设备不提供 ioctl 方法, 对于任何未事先定义的请求(-ENOTTY, “设备无这样的 ioctl”), 系统调用返回一个错误.
int (mmap) (struct file , struct vm_area_struct *);
mmap 用来请求将设备内存映射到进程的地址空间。 如果这个方法是 NULL, mmap 系统调用返回 -ENODEV.int (open) (struct inode inode , struct file * filp ) ;
(inode 为文件节点,这个节点只有一个,无论用户打开多少个文件,都只是对应着一个inode结构;但是filp就不同,只要打开一个文件,就对应着一个file结构体,file结构体通常用来追踪文件在运行时的状态信息)
尽管这常常是对设备文件进行的第一个操作, 不要求驱动声明一个对应的方法. 如果这个项是 NULL, 设备打开一直成功, 但是你的驱动不会得到通知.与open()函数对应的是release()函数。
int (flush) (struct file );
flush 操作在进程关闭它的设备文件描述符的拷贝时调用
它应当执行(并且等待)设备的任何未完成的操作.这个必须不要和用户查询请求的 fsync 操作混淆了. 当前, flush 在很少驱动中使用;SCSI 磁带驱动使用它, 例如, 为确保所有写的数据在设备关闭前写到磁带上. 如果 flush 为 NULL, 内核简单地忽略用户应用程序的请求.
int (release) (struct inode , struct file *);
release ()函数当最后一个打开设备的用户进程执行close()系统调用的时候,内核将调用驱动程序release()函数:
- void release(struct inode inode,struct file *file)
release函数的主要任务是清理未结束的输入输出操作,释放资源,用户自定义排他标志的复位等。在文件结构被释放时引用这个操作. 如同 open, release 可以为 NULL.
int(synch)(struct file ,struct dentry *,int datasync);
刷新待处理的数据,允许进程把所有的脏缓冲区刷新到磁盘。int (aio_fsync)(struct kiocb , int);
这是 fsync 方法的异步版本.所谓的fsync方法是一个系统调用函数。系统调用fsync把文件所指定的文件的所有脏缓冲区写到磁盘中(如果需要,还包括存有索引节点的缓冲区)。相应的服务例程获得文件对象的地址,并随后调用fsync方法。通常这个方法以调用函数__writeback_single_inode()结束,这个函数把与被选中的索引节点相关的脏页和索引节点本身都写回磁盘int (fasync) (int, struct file , int);
这个函数是系统支持异步通知的设备驱动,int (lock) (struct file , int, struct file_lock *);
lock 方法用来实现文件加锁; 加锁对常规文件是必不可少的特性, 但是设备驱动几乎从不实现它.ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t \*);
ssize_t (*writev) (struct file , const struct iovec , unsigned long, loff_t *);
这些方法实现发散/汇聚读和写操作. 应用程序偶尔需要做一个包含多个内存区的单个读或写操作;这些系统调用允许它们这样做而不必对数据进行额外拷贝. 如果这些函数指针为 NULL, read 和 write 方法被调用( 可能多于一次 ).
ssize_t (sendfile)(struct file , loff_t , size_t, read_actor_t, void );
这个方法实现 sendfile 系统调用的读, 使用最少的拷贝从一个文件描述符搬移数据到另一个.例如, 它被一个需要发送文件内容到一个网络连接的 web 服务器使用. 设备驱动常常使 sendfile 为 NULL.ssize_t (sendpage) (struct file , struct page , int, size_t, loff_t , int);
sendpage 是 sendfile 的另一半; 它由内核调用来发送数据, 一次一页, 到对应的文件. 设备驱动实际上不实现 sendpage.unsigned long (get_unmapped_area)(struct file , unsigned long, unsigned long, unsigned long, unsigned long);
这个方法的目的是在进程的地址空间找一个合适的位置来映射在底层设备上的内存段中。这个任务通常由内存管理代码进行; 这个方法存在为了使驱动能强制特殊设备可能有的任何的对齐请求. 大部分驱动可以置这个方法为 NULL.[10]int (*check_flags)(int)
这个方法允许模块检查传递给 fnctl(F_SETFL...) 调用的标志.int (dir_notify)(struct file , unsigned long);
这个方法在应用程序使用 fcntl 来请求目录改变通知时调用. 只对文件系统有用; 驱动不需要实现 dir_notify.
以上描述的方法对所有可能的文件类型都是可用的。不过,对于一个具体的文件类型,只使用其中的一个子集;那些未实现的方法对应的字段被置为NULL。
目录项对象
在“通用文件模型“一节中我们曾提到,VFS把每个目录看作由若干子目录和文件组成的一个普通文件。然而,一旦目录项被读入内存,VFS就把它转换成基于dentry结构的一个目录项对象,该结构的字段如表12-5所示。对于进程查找的路径名中的每个分量,内核都为其创建一个目录项对象;目录项对象将每个分量与其对应的索引节点相联系。例如,在查找路径名/tmp/test时,内核为根目录“/“创建一个目录项对象,为根目录下的tmp项创建一个第二级目录项对象,为/tmp目录下的test项创建一个第三级目录项对象。
请注意,目录项对象在磁盘上并没有对应的映像,因此在dentry结构中不包含指出该对象已被修改的字段。目录项对象存放在名为dentry_cache的slab分配器高速缓存中。因此,目录项对象的创建和删除是通过调用kmem_cache_alloc()和kmem_cache_free()实现的。
| 字段 | 说明 |
|---|---|
| d_revalidate: | VFS用于检查在dcache里找到的dentry是否有效。通常设置为NULL,则只要在dcache找到即认为是有效的。但对网络文件系统如NFS来说,dentry可能在一段时间之后就会失效,因此需要实现该函数用于检查是否有效。如果有效,函数需要返回一个正数。 |
| d_weak_revalidate: | 用于检查’jumped’的dentry,即那些不是通过lookup获取的dentry,如’’, ‘.’或者’..’。这种场景只需要检查dentry对应inode是否OK即可。该函数不会在rcu-walk模式下调用,所以可以放心的使用inode。 |
| d_hash: | 用于VFS将dentry放入HASH列表。并不清楚HASH表用来做啥,通常不需要设置它,使用VFS默认的即可。 |
| d_compare: | 用于比较dentry name和指定的name。该函数必须是可重入的,即每次的返回结果一样。 |
| d_revalidate | 可能在rcu-walk模式(flags & LOOKUP_RCU)下被调用。此时该函数里不能阻塞也不能写入数据到dentry,并且d_parent和d_inode不能使用,因为他们可能瞬间就可能被修改。如果在rcu-walk模式遇到困难,则返回-ECHILD,将在ref-walk模式下重新调用。 |
| d_release: | 用于释放dentry资源。 |
| d_delete: | 用于引用计数递减为0时调用,返回1则dcache立即删除dentry,返回0则继续缓存该dentry。默认为NULL,则总是将dentry进行缓存。该函数必须是可重入的,即每次的返回结果一样。 |
| d_iput: | 用于释放dentry对应inode引用计数。该函数在释放dentry之前调用。如果为NULL,则VFS默认调用iput()。 |
| d_dname: | 用于生成dentry的pathname,主要是一些伪文件系统(sockfs, pipefs等)用于延迟生成pathname。一般文件系统不实现该函数,因为其dentry存在于dcache的hash表里(通过pathname做hash),所以并不希望pathname变化。 |
| d_automount: | 可选函数,用于穿越到一个自动挂载的dentry。它会创建一个新的vfsmount记录,并将其返回,成功后调用者将根据vfsmount去尝试mount它到挂载点。 |
| d_manage: | 可选函数,用于管理从dentry进行transition。 |
每个目录项对象可以处于以下四种状态之一:
- 空闲状态(free)
处于该状态的目录项对象不包括有效的信息,且还没有被VFS使用。对应的内存区由slab分配器进行处理。 - 未使用状态(unused)
处于该状态的目录项对象当前还没有被内核使用。该对象的引用计数器d_count的值为0,但其d_inode字段仍然指向关联的索引节点。该目录项对象包含有效的信息,但为了在必要时回收内存,它的内容可能被丢弃。 - 正在使用状态(in use)
处于该状态的目录项对象当前正在被内核使用。该对象的引用计数器d_count的值为正数,其d_inode字段指向关联的索引节点对象。该目录项对象包含有效的信息,并且不能被丢弃。 - 负状态(negative)
与目录项关联的索引节点不复存在,那是因为相应的磁盘索引节点已被删除,或者因为目录项对象是通过解析一个不存在文件的路径名创建的。目录项对象的d_inode字段被置为NULL,但该对象仍然被保存在目录项高速缓存中,以便后续对同一文件目录名的查找操作能够快速完成。术语“负状态“容易使人误解,因为根本不涉及任何负值。
与目录项对象关联的方法称为目录项操作。这些方法由dentry_operations结构加以描述,该结构的地址存放在目录项对象的d_op字段中。尽管一些文件系统定义了它们自己的目录项方法,但是这些字段通常为NULL,而VFS使用缺省函数代替这些方法。以下按照其在dentry_operations表中出现的顺序来列举一些方法。
| 操作 | 说明 |
|---|---|
| d_revalidate(dentry,nameidata) | 在把目录项对象转换为一个文件路径名之前,判定该目录项对象是否仍然有效。缺 省的VFS函数什么也不做,而网络文件系统可以指定自已的函数。 |
| d_hash(dentry, name) | 生成一个散列值,这是用于目录项散列表的、特定于具体文件系统的散列函数。参 数dentry标识包含路径分量的自录。参数name指向一个结构,该结构包含要查找 的路径名分量以及由散列函数生成的散列值。 |
| d_compare(dir,namel,name2) | 比较两个文件名。name1应该属于dir所指的目录。缺省的VFS函数是常用的字 符串匹配函数。不过,每个文件系统可用自已的方式实现这一方法。例如,MS-DOS 文件系统不区分大写和小写字母。 |
| d_delete(dentry) | 当对自录项对象的最后一个引用被删除(dcount变为“0“)时,调用该方法。缺省的VFS函数什么也不做。 |
| d_release(dentry) | 当要释放一个目录项对象时(放人slab分配器),调用该方法。缺省的VFS函数什 么也不做。 |
| d_iput(dentry,ino) | 当一个自录项对象变为“负“状态(即丢弃它的索引节点)时,调用该方法。缺省 的VFS函数调用iput()释放索引节点对象。 |
目录项高速缓存
由于从磁盘读入一个目录项并构造相应的目录项对象需要花费大量的时间,所以,在完成对目录项对象的操作后,可能后面还要使用它,因此仍在内存中保留它有重要的意义。例如,我们经常需要编辑文件,随后编译它,或者编辑并打印它,或者复制它并编辑这个拷贝,在诸如此类的情况中,同一个文件需要被反复访问。为了最大限度地提高处理这些目录项对象的效率,Linux使用目录项高速缓存,它由两种类型的数据结构组成:
一个处于正在使用未使用或负状态的目录项对象的集合
一个散列表,其中能够快速获取与给定的文件和目录名对应的目录项对象!同样如果访问的对象不在目录项高速缓存中,该散列函数会返回一个空值
目录项高速缓存的作用还相当于索引节点高速缓存(inode cache)的控制器。在内核内存中,并不丢弃与未用目录项相关的索引节点,这是由于目录项高速缓存仍在使用它们。因此,这些索引节点对象保存在RAM中,并能够借助相应的目录项快速引用它们。
所有“未使用“目录项对象都存放在一个“最近最少使用(Least Recently used,LRU)“的双向链表中,该链表按照插入的时间排序。换句话说,最后释放的目录项对象放在链表的首部,所以最近最少使用的目录项对象总是靠近链表的尾部。一旦目录项高速缓存的空间开始变小,内核就从链表的尾部删除元素,使得最近最常使用的对象得以保留。
LRU链表的首元素和尾元素的地址存放在list_head类型的dentry_unused变量的next字段和prev字段中。目录项对象的d_1ru字段包含指向链表中相邻目录项的指针。
每个“正在使用“的目录项对象都被插入一个双向链表中,该链表由相应索引节点对象的i_dentry字段所指向(由于每个索引节点可能与若干硬链接关联,所以需要一个链表)。目录项对象的d_alias字段存放链表中相邻元素的地址。这两个字段的类型都是struct list_head。
当指向相应文件的最后一个硬链接被删除后,一个“正在使用“的目录项对象可能变成“负“状态。在这种情况下,该目录项对象被移到“未使用“目录项对象组成的LRU链表中。每当内核缩减目录项高速缓存时,“负“状态目录项对象就朝着LRU链表的尾部移动,这样一来,这些对象就逐渐被释放。
散列表是由dentry_hashtable数组实现的。数组中的每个元素是一个指向链表的指针,这种链表就是把具有相同散列表值的目录项进行散列而形成的。该数组的长度取决于系统已安装RAM的数量;缺省值是每兆字节RAM包含256个元素。目录项对象的d_hash 字段包含指向具有相同散列值的链表中的相邻元素。散列函数产生的值是由目录的目录项对象及文件名计算出来的。
dcache_lock自旋锁保护目录项高速缓存数据结构免受多处理器系统上的同时访问。d_lookup()函数在散列表中查找给定的父目录项对象和文件名;为了避免发生竞争,使用顺序锁(seqlock)。__d_lookup()函数与之类似,不过它假定不会发生竞争,因此不使用顺序锁。
与进程相关的文件
每个进程都有它自己当前的工作目录和它自己的根目录。这仅仅是内核用来表示进程与文件系统相互作用所必须维护的数据中的两个例子。类型为fs_struc的整个数据结构就用于此目的(参见表12-6),且每个进程描述符的fs字段就指向进程的fs_struc结构。
| 字段 | 说明 |
|---|---|
| count: | 共享这个表的进程个数 |
| lock: | 用于表中字段的读/写自旋锁 |
| umask: | 当打开文件设置文件权限时所使用的位掩码 |
| root: | 根目录的目录项 |
| pwd: | 当前工作目录的目录项 |
| altroot: | 模拟根目录的目录项(在80x86结构上始终为NULL) |
| rootmnt: | 根目录所安装的文件系统对象 |
| pwdmnt: | 当前工作目录所安装的文件系统对象 |
| altrootmnt: | 模拟根目录所安装的文件系统对象(在80x86结构上始终为NULL) |
第二个表表示进程当前打开的文件表的地址存放于进程描述符的files字段。该表的类型为files_struct结构,它的各个字段如表12-7所示。
| 字段 | 说明 |
|---|---|
| count | 共享该表的进程数目 |
| file_lock | 于表中字段的读/写自旋锁 |
| max_fds | 用文件对象的当前最大数目 |
| max_fdset | 文件描述符的当前最大数目 |
| next_fd | 所分配的最大文件描述符加1 |
| close_on_exec | 指向执行exec()时需要关闭的文件描述符的 指针 |
| fd | 指向文件对象指针数组的指针 |
| open_fds | 指向打开文件描述符的指针 |
| close_on_exec_init | 执行exec()时需要关闭的文件描述符的初始集合 |
| open_fds_init | 文件描述符的初始集合 |
| fd_array | 文件对象指针的初始化数组 |
fd字段指向文件对象的指针数组。该数组的长度存放在max_fds字段中。通常,fd字段指向files_struct结构的fd_array字段,该字段包括32个文件对象指针。如果进程打开的文件数目多于32,内核就分配一个新的、更大的文件指针数组,并将其地址存放在fd字段中,内核同时也更新max_fds字段的值。
对于在fd数组中有元素的每个文件来说,数组的索引就是文件描述符(file descriptor)。通常,数组的第一个元素(索引0)是进程的标准输入文件,数组的第二个元素(索引1)是进程的标准输出文件,数组的第三个元素(索引2)是进程的标准错误文件。
Unix进程将文件描述符作为主文件标识符。请注意,借助于dup()、dup2()和fcntl()系统调用,两个文件描述符可以指向同一个打开的文件,也就是说,数组的两个元素可能指向同一个文件对象。当用户使用shell结构(如2>&1)将标准错误文件重定向到标准输出文件上时,用户总能看到这一点。
进程不能使用多于NR_OPEN(通常为1048576)个文件描述符。内核也在进程描述符的signal->rlim[RLIMIT_NOFILE]结构上强制限制文件描述符的最大数;这个值通常为1024,但是如果进程具有超级用户特权,就可以增大这个值。
open_fds字段最初包含open_fds_init字段的地址,open_fds_init字段表示当前已打开文件的文件描述符的位图。max_fdset字段存放位图中的位数。由于fd_set数据结构有1024位,所以通常不需要扩大位图的大小。但,如果确有必要的话,内核仍能动态增加位图的大小,这非常类似于文件对象的数组的情形。
当内核开始使用一个文件对象时,内核提供fget()函数以供调用。函数接收fd作为参数,返回在current->files->fd[fd]中的地址,即对应文件对象的地址,如果没有任何文件与fd对应,则返回NULL。在第一种情况下,fget()使文件对象引用计数器f_count的值增1。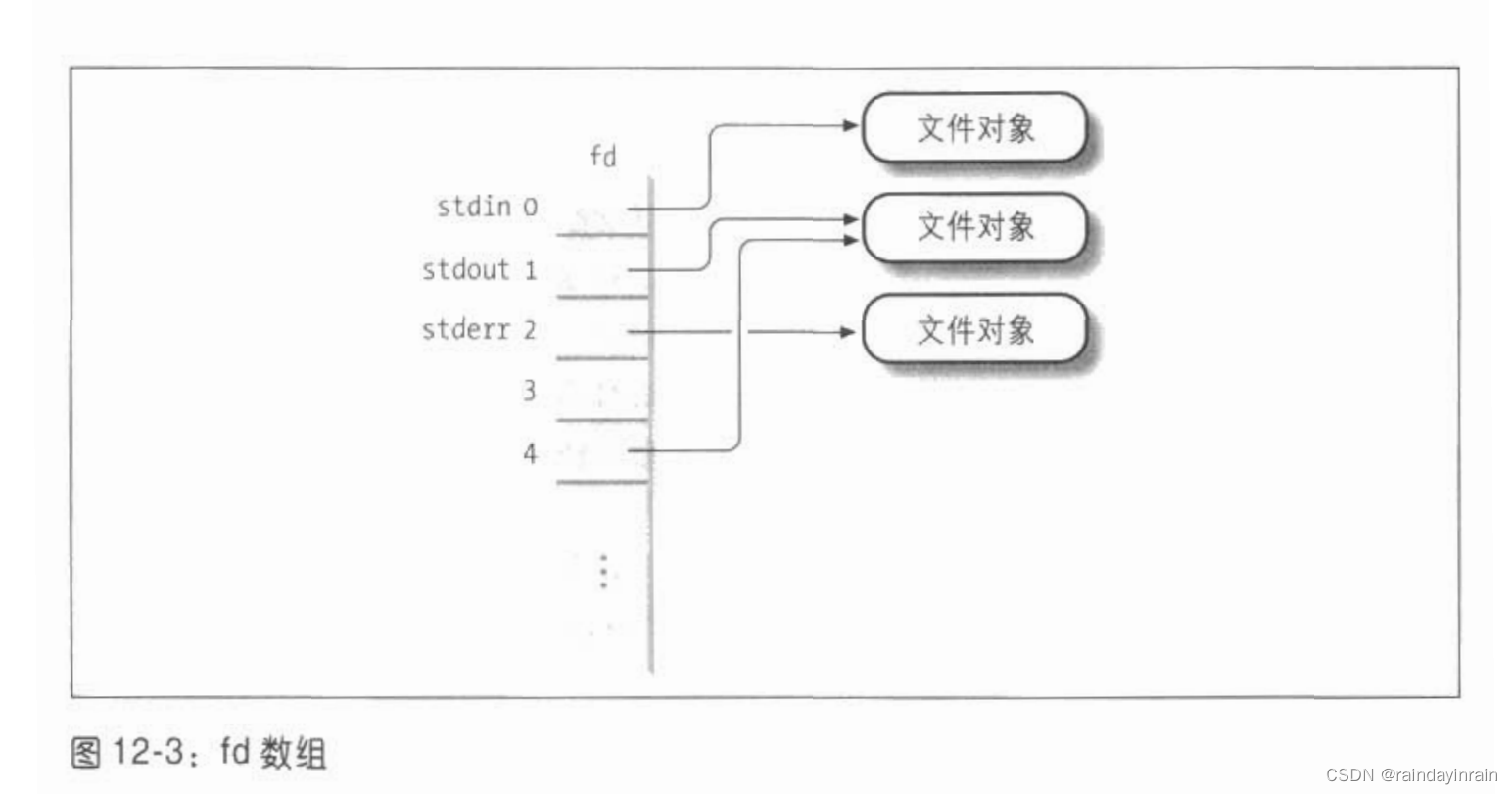
当内核控制路径完成对文件对象的使用时,调用内核提供的fput()函数。该函数将文件对象的地址作为参数,并减少文件对象引用计数器f_count的值。另外,如果这个字段变为0,该函数就调用文件操作的release方法(如果已定义):
- 减少索引节点对象的i_write count字段的值(如果该文件是可写的)。
- 将文件对象从超级块链表中移走。
- 释放文件对象给slab分配器。
- 最后减少相关的文件系统描述符的目录项对象的引用计数器的值。
fget_light()和fget_light()函数是fget()和fput()的快速版本:内核要使用它们,前提是能够安全地假设当前进程已经拥有文件对象,即进程先前已经增加了文件对象引用计数器的值。例如,它们由接收一个文件描述符作为参数的系统调用服务例程使用,这是由于先前的open()系统调用已经增加了文件对象引用计数器的值。
文件系统类型
Linux内核支持很多不同的文件系统类型。在下面的内容中,我们介绍一些特殊的文件系统类型,它们在Linux内核的内部设计中具有非常重要的作用。接下来,我们将讨论文件系统注册——也就是通常在系统初始化期间并且在使用文件系统类型之前必须执行的基本操作。一旦文件系统被注册,其特定的函数对内核就是可用的,因此文件系统类型可以安装在系统的目录树上。
特殊文件系统
当网络和磁盘文件系统能够使用户处理存放在内核之外的信息时,特殊文件系统可以为系统程序员和管理员提供一种容易的方式来操作内核的数据结构并实现操作系统的特殊特征。表12-8列出了Linux中所用的最常用的特殊文件系统;对于其中的每个文件系统,表中给出了它的安装点和简短描述。注意,有几个文件系统没有固定的安装点(表中的关键词“任意”)。这些文件系统可以由用户自由地安装和使用。一些特殊文件系统根本没有安装点(表中的“无”),它们不是用于与用户交互,但是内核可以用它们来很容易地重新使用VFS层的某些代码.
特殊文件系统不限于物理块设备,然而,内核给每个安装的特殊文件系统分配一个虚拟的块设备,让其主设备号为0而次设备号具有任意值(每个特殊文件系统有不同的值)。set_anon_super()函数用于初始化特殊文件系统的超级块;函数获得一个未使用的次设备号dev,然后用主设备号0和次设备号dev设置新超级块的s_dev字段。
而另一个kill_anon_super()函数移走特殊文件系统的超级块。unnamed_dev_idr变量包含指向一个辅助结构(记录当前在用的次设备号)的指针。尽管有些内核设计者不喜欢虚拟块设备标识符,但是这些标识符有助于内核以统一的方式处理特殊文件系统和普通文件系统。
文件系统类型注册
通常,用户在为自己的系统编译内核时可以把Linux配置为能够识别所有需要的文件系统。但是,文件系统的源代码实际上要么包含在内核映像中,要么作为一个模块被动态装入。VFS必须对代码目前已在内核中的所有文件系统的类型进行跟踪。这就是通过进行文件系统类型注册来实现的。每个注册的文件系统都用一个类型为file_system_type的对象来表示,该对象的所有字段在表12-9中列出。
struct file_system_type {
115 const char *name;
116 int fs_flags;
117 struct dentry *(*mount) (struct file_system_type *, int,
118 const char *, void *);
119 void (*kill_sb) (struct super_block *);
120 struct module *owner;
121 struct file_system_type * next;
122 struct list_head fs_supers;
123 struct lock_class_key s_lock_key;
124 struct lock_class_key s_umount_key;
125 }; 其中,name是文件系统名称,如ext4, xfs等等。fs_flags为各种标识,如FS_REQUIRES_DEV, FS_NO_DCACHE等。mount()函数指针用于挂载一个新的文件系统实例。kill_sb()函数指针用于关闭文件系统实例。owner是VFS内部使用,通常设置为THIS_MODULE。next也是VFS内部使用,初始化时设置为NULL即可。s_lock_key和s_umount_key是lockdep相关的结构。
mount()函数有几个参数:fs_type为对应的file_sytem_type结构指针。flags为挂载的标识。dev_name为挂载的设备名,对于网络文件系统通常是一个网络路径。data为挂载的选项,通常为一组ASCII字符串。
mount()必须返回文件系统目录树的root dentry。文件系统的super block增加一个引用计数并处于locked状态。mount失败时返回ERR_PTR(err)。mount()函数可以选择返回一个已经存在的文件系统的一个子树,而不是创建一个新的文件系统实例,这种情况返回的是子树的root dentry。
底层文件系统实现mount,可以直接调用通用的mount实现:mount_bdev(在块设备上挂载文件系统)、mount_nodev(挂载没有设备的文件系统)和mount_single(挂载在不同的mounts间共享实例的文件系统),并提供一个fill_super()的回调函数用于创建root dentry和inode。比如FUSE就通过调用mount_nodev来实现mount操作。
其中file_super()回调函数的参数包括:struct super_block sb(文件系统sb,需要在fill_super()里进行初始化)、void data(文件系统挂载的选项字符串)、int silent(是否忽略error)。
当然也可以参考通用的mount实现自己的mount操作,比如Ceph就直接调用了sget()函数创建sb并通过set()回调函数初始化sb。所有文件系统类型的对象都插入到一个单向链表中。由变量file_systems指向链表的第一个元素,而结构中的next字段指向链表的下一个元素。file_systems_lock读/写自旋锁保护整个链表免受同时访问。
fs_supers字段表示给定类型的已安装文件系统所对应的超级块链表的头(第一个伪元素)。链表元素的向后和向前链接存放在超级块对象的s_instances字段中。get_sb字段指向依赖于文件系统类型的函数,该函数分配一个新的超级块对象并初始化它(如果需要,可读磁盘)。而kill_sb字段指向删除超级块的函数。fs_flags字段存放几个标志,如表12-10所示。
| 名称 | 说明 |
|---|---|
| FS_REQUIRES_DEV | 这种类型的任何文件系统必须位于物理磁盘设备上 |
| FS_BINARY_MOUNTDATA | 文件系统使用的二进制安装数据 |
| FS_REVAL_DOT | 始终在目录项高速缓存中时.和..路径重新生效 |
| FS_ODD_RENAME | 重命名操作就是移动操作 |
在系统初始化期间,调用register_filesystem()函数来注册编译时指定的每个文件系统;该函数把相应的file_system_type对象插入到文件系统类型的链表中。当实现了文件系统的模块被装入时,也要调用register_filesystem()函数。在这种情况下,当该模块被卸载时,对应的文件系统也可以被注销(调用unregister_filesystem()函数)。
get_fs_type()函数(参数为文件系统名)扫描已注册的文件系统链表以查找文件系统类型的name字段,并返回指向相应的file_system_type对象(如果存在)的指针。
文件系统处理
就像每个传统的Unix系统一样,Linux也使用系统的根文件系统(system’s rootfilesystem):它由内核在引导阶段直接安装,并拥有系统初始化脚本以及最基本的系统程序。其他文件系统要么由初始化脚本安装,要么由用户直接安装在已安装文件系统的目录上。
作为一个目录树,每个文件系统都拥有自己的根目录(root directory)。安装文件系统的这个目录称之为安装点(mount point)。已安装文件系统属于安装点目录的一个子文件系统。例如,/proc虚拟文件系统是系统的根文件系统的孩子(且系统的根文件系统是/proc的父亲)。已安装文件系统的根目录隐藏了父文件系统的安装点目录原来的内容,而且父文件系统的整个子树位于安装点之下。
文件系统的根目录有可能不同于进程的根目录:进程的根目录是与“/“路径对应的目录。缺省情况下,进程的根目录与系统的根文件系统的根目录一致(更准确地说是与进程的命名空间中的根文件系统的根目录一致,这一点将在下一节描述),但是可以通过调用chroot()系统调用改变进程的根目录。
命名空间
在传统的Unix系统中,只有一个已安装文件系统树:从系统的根文件系统开始,每个进程通过指定合适的路径名可以访问已安装文件系统中的任何文件。从这个方面考虑,Linux 2.6更加的精确:每个进程可拥有自己的已安装文件系统树——叫做进程的命名空间(namespace)。
通常大多数进程共享同一个命名空间,即位于系统的根文件系统且被init进程使用的已安装文件系统树。不过,如果clone()系统调用以CLONE_NEWNS标志创建一个新进程,那么进程将获取一个新的命名空间。这个新的命名空间随后由子进程继承(如果父进程没有以CLONE_NEWNS标志创建这些子进程)。当进程安装或卸载一个文件系统时,仅修改它的命名空间。因此,所做的修改对共享同一命名空间的所有进程都是可见的,并且也只对它们可见。
进程甚至可通过使用Linux 特有的pivot_root()系统调用来改变它的命名空间的根文件系统。进程的命名空间由进程描述符的namespace字段指向的namespace结构描述。该结构的字段如表12-11所示。
| 名称 | 说明 |
|---|---|
| count | 引用计数器(共享命名空间的进程数) |
| root | 命名空间根目录的已安装文件系统描述符 |
| list | 所有已安装文件系统描述符链表的头 |
| sem | 保护这个结构的读/写信号量 |
list字段是双向循环链表的头,该表聚集了属于命名空间的所有已安装文件系统。root 字段表示已安装文件系统,它是这个命名空间的已安装文件系统树的根。
文件系统安装
在大多数传统的类Unix内核中,每个文件系统只能安装一次。假定存放在/dev/fd0软磁盘上的Ext2文件系统通过如下命令安装在/flp:mount -t ext2 /dev/fd0 /flp在用umount命令卸载该文件系统前,所有其他作用于/dev/fd0的安装命令都会失败。然而,Linux有所不同:同一个文件系统被安装多次是可能的。当然,如果一个文件系统被安装了n次,那么它的根目录就可通过n个安装点来访问。尽管同一文件系统可以通过不同的安装点来访问,但是文件系统的的确确是唯一的。因此,不管一个文件系统被安装了多少次,都仅有一个超级块对象。
安装的文件系统形成一个层次:一个文件系统的安装点可能成为第二个文件系统的目录,第二个文件系统又安装在第三个文件系统之上等。把多个安装堆叠在一个单独的安装点上也是可能的。尽管已经使用先前安装下的文件和目录的进程可以继续使用,但在同一安装点上的新安装隐藏前一个安装的文件系统。当最顶层(最后一个)的安装被删除时,下一层的安装再一次变为可见的。你可以想像,跟踪已安装的文件系统很快会变为一场恶梦。对于每个安装操作,内核必须在内存中保存安装点和安装标志,以及要安装文件系统与其他已安装文件系统之间的关系。信息保存在已安装文件系统描述符中;每个描述符是一个具有vfsmount 类型的数据结构,其字段如表12-12所示。
| 字段 | 说明 |
|---|---|
| mnt_hash | 用于散列表链表的指针 |
| mntparent | 指向父文件系统,这个文件系统安装在其上 |
| mnt_mountpoint | 指向这个文件系统安装点目录的dentry |
| mnt_root | 指向这个文件系统根目录的dentry |
| mnt_sb | 指向这个文件系统的超级块对象 |
| mnt_mounts | 包含所有文件系统描述符链表的头(相对于这 个文件系统) |
| mnt_child | 用于已安装文件系统链表mnt_mounts的指针 |
| mnt_mounts | 已安装文件系统链表的指针 |
| mnt_count | 引用计数器(增加该值以禁止文件系统被卸载) |
| mnt_flags | 标志 |
| mnt_expiry_mark | 如果文件系统标记为到期,那么就设置该标志 为true(如果设置了该标志,并且没有任何人 使用它,那么就可以自动卸载这个文件系统 |
| mnt_devmame | 设备文件名 |
| mnt_list | 已安装文件系统描述符的namespace链表的指针 |
| mnt fslink | 具体文件系统到期链表的指针 |
| mnt_namespace | 指向安装了文件系统的进程命名空间的指针 |
vfsmount数据结构保存在几个双向循环链表中:
- 由父文件系统vfsmount描述符的地址和安装点目录的目录项对象的地址索引的散列表。散列表存放在mount_hashtable数组中,其大小取决于系统中RAM的容量。表中每一项是具有同一散列值的所有描述符形成的双向循环链表的头。描述符的mnt_hash字段包含指向链表中相邻元素的指针。
- 对于每一个命名空间,所有属于此命名空间的已安装的文件系统描述符形成了一个双向循环链表。namespace结构的list字段存放链表的头,vfsmount描述符的mnt_list字段包含链表中指向相邻元素的指针。
- 对于每一个已安装的文件系统,所有已安装的子文件系统形成了一个双向循环链表。每个链表的头存放在已安装的文件系统描述符的mnt_mounts字段;此外,描述符的mnt_child字段存放指向链表中相邻元素的指针
vfsmount_lock自旋锁保护已安装文件系统对象的链表免受同时访问。描述符的mnt_flags字段存放几个标志的值,用以指定如何处理已安装文件系统中的某些种类的文件。可通过mount命令的选项进行设置,其标志如表12-13所示。
| 名称 | 说明 |
|---|---|
| MNT_NOSUID | 在已安装文件系统中禁止标志setuid和setgid |
| MNT_NODEV | 在已安装文件系统中禁止访问设备 |
| MNT_NOEXEC | 在已安装新文件系统中不允许程序的执行 |
下列函数处理已安装文件系统描述符:
- alloc_vfsmnt(name): 分配和初始化一个已安装文件系统的描述服务
- free_vfsmnt(mnt): 释放已有以mnt指向的已安装文件系统描述符
- lookup_mnt(mnt, dentry):在散列表中查找一个描述符并且返回它的地址
安装普通文件系统
我们现在描述安装一个文件系统时内核所要执行的操作。我们首先考虑一个文件系统将被安装在一个已安装文件系统之上的情形(在这里我们把这种新文件系统看作“普通的”)。mount()系统调用被用来安装一个普通文件系统;它的服务例程sys_mount()作用于以下参数:
- 文件系统所在的设备文件的路径名,或者如果不需要的话就为空
- 文件系统被安装器上的某个目录的目录路径
- 文件系统的类型,必须是已注册文件系统的名称
- 安装标志
- 指向一个与文件系统相关的数据结构的指针
/*
* These are the fs-independent mount-flags: up to 32 flags are supported
*/
#define MS_RDONLY 1 /* 对应-o ro/rw */
#define MS_NOSUID 2 /* 对应-o suid/nosuid */
#define MS_NODEV 4 /* 对应-o dev/nodev */
#define MS_NOEXEC 8 /* 对应-o exec/noexec */
#define MS_SYNCHRONOUS 16 /* 对应-o sync/async */
#define MS_REMOUNT 32 /* 对应-o remount,告诉mount这是一次remount操作 */
#define MS_MANDLOCK 64 /* 对应-o mand/nomand */
#define MS_DIRSYNC 128 /* 对应-o dirsync */
#define MS_NOATIME 1024 /* 对应-o atime/noatime */
#define MS_NODIRATIME 2048 /* 对应-o diratime/nodiratime */
#define MS_BIND 4096 /* 对应-B/--bind选项,告诉mount这是一次bind操作 */
#define MS_MOVE 8192 /* 对应-M/--move,告诉mount这是一次move操作 */
#define MS_REC 16384 /* rec是recursive的意思,这个flag一般不单独出现,都是伴随这其它flag,表示递归的进行操作 */
#define MS_VERBOSE 32768 /* 对应-v/--verbose */
#define MS_SILENT 32768 /* 对应-o silent/loud */
#define MS_POSIXACL (1<<16) /* 让VFS不应用umask,如NFS */
#define MS_UNBINDABLE (1<<17) /* 对应--make-unbindable */
#define MS_PRIVATE (1<<18) /* 对应--make-private */
#define MS_SLAVE (1<<19) /* 对应--make-slave */
#define MS_SHARED (1<<20) /* 对应--make-shared */
#define MS_RELATIME (1<<21) /* 对应-o relatime/norelatime */
#define MS_KERNMOUNT (1<<22) /* 这个一般不在应用层使用,一般内核挂载的文件系统如sysfs使用,表示使用kern_mount()进行挂载 */
#define MS_I_VERSION (1<<23) /* 对应-o iversion/noiversion */
#define MS_STRICTATIME (1<<24) /* 对应-o strictatime/nostrictatime */
#define MS_LAZYTIME (1<<25) /* 对应 -o lazytime/nolazytime*/
/* 下面这几个flags都是内核内部使用的,不由mount系统调用传递 */
#define MS_SUBMOUNT (1<<26)
#define MS_NOREMOTELOCK (1<<27)
#define MS_NOSEC (1<<28)
#define MS_BORN (1<<29)
#define MS_ACTIVE (1<<30)
#define MS_NOUSER (1<<31)
/*
* Superblock flags that can be altered by MS_REMOUNT
*/
#define MS_RMT_MASK (MS_RDONLY|MS_SYNCHRONOUS|MS_MANDLOCK|MS_I_VERSION|\
MS_LAZYTIME) // 可以在remount时改变的flags
/*
* Old magic mount flag and mask
*/
#define MS_MGC_VAL 0xC0ED0000 /* magic number */
#define MS_MGC_MSK 0xffff0000 /* flags mask */ sys_mount()函数把参数的值拷贝到临时内核缓冲区,获取大内核锁,并调用do_mount()函数。一旦do_mount()返回,则这个服务例程释放大内核锁并释放临时内核缓冲区。do_mount()函数通过执行下列操作处理真正的安装操作:
如果安装标志MS_NOSUID、MS_NODEV或MS_NOEXEC中任一个被设置,则清除它们,并在已安装文件系统对象中设置相应的标志(MNT_NOSUID、MNT_NODEV、MNT_NOEXEC)。
调用path_lookup()查找安装点的路径名,该函数把路径名查找的结果存放在nameidata类型的局部变量nd中。
检查安装标志以决定必须做什么。尤其是:
- 如果MS_REMOUNT标志被指定,其目的通常是改变超级块对象s_flags字段的安装标志,以及已安装文件系统对象mnt_flags字段的安装文件系统标志。do_remount()函数执行这些改变。
- 否则,检查MS_BIND标志。如果它被指定,则用户要求在在系统目录树的另一个安装点上的文件或目录能够可见。
- 否则,检查MS_MOVE标志。如果它被指定,则用户要求改变已安装文件系统的安装点。do_move_mount()函数原子地完成这一任务。
- 否则,调用do_new_mount()。这是最普通的情况。当用户要求安装一个特殊文件系统或存放在磁盘分区中的普通文件系统时,触发该函数。它调用do_kern_mount()函数,给它传递的参数为文件系统类型、安装标志以及块设备名。
do_kern_mount()处理实际的安装操作并返回一个新安装文件系统描述符的地址(如下描述)。然后,do_new_mount()调用do_add_mount(),后者本质上执行下列操作;
- 获得当前进程的写信号量namespace->sem,因为函数要更改namespace结构。
- do_kern_mount()函数可能让当前进程睡眠;同时,另一个进程可能在完全相同的安装点上安装文件系统或者甚至更改根文件系统(current->namespace->root)。验证在该安装点上最近安装的文件系统是否仍指向当前的namespace;如果不是,则释放读/写信号量并返回一个错误码。
- 如果要安装的文件系统已经被安装在由系统调用的参数所指定的安装点上,或该安装点是一个符号链接,则释放读/写信号量并返回一个错误码。
- 初始化由do_kern_mount()分配的新安装文件系统对象的mnt_flags字段的标志。
- 调用graft_tree()把新安装的文件系统对象插入到namespace链表、散列表及父文件系统的子链表中。
- 释放namespace->sem读/写信号量并返回。
- 调用path_release()终止安装点的路径名查找并返回0。
do_kern_mount()函数
安装操作的核心是do_kern_mount()函数,它检查文件系统类型标志以决定安装操作是如何完成的。该函数接收下列参数:
fstype: 要安装的文件系统的类型名
flags:安装标志
name: 存放文件系统的块设备的路径名
data: 指向传递给文件系统的readsuper方法的附加数据的指针
本质上,该函数通过执行下列操作实现实际的安装操作:
- 调用get_fs_type()在文件系统类型链表中搜索并确定存放在fstype参数中的名字的位置;返回局部变量type中对应file_system_type描述符的地址。
- 调用alloc_vfsmnt()分配一个新的已安装文件系统的描述符,并将它的地址存放在mnt局部变量中。
- 调用依赖于文件系统的type->get_sb()函数分配,并初始化一个新的超级块。
- 用新超级块对象的地址初始化mnt->mnt_sb字段。
- 将mnt->mnt_root字段初始化为与文件系统根目录对应的目录项对象的地址,并增加该目录项对象的引用计数器值。
- 用mnt中的值初始化mnt->mnt_parent字段(对于普通文件系统,当graft_tree()把已安装文件系统的描述符插入到合适的链表中时,要把mnt_parent字段置为合适的值)。
- 用current->namespace中的值初始化mnt->mnt_namespace字段。
- 释放超级块对象的读/写信号量s_umount(在第3步中分配对象时获得)。
- 返回已安装文件系统对象的地址mnt。
分配超级块对象
文件系统对象的get_sb方法通常是由单行函数实现的。例如,在Ext2文件系统中该方法的实现如下:
struct super_block * ext2_get_sb(struct file_system_type *type, int flags, const char *dev_name, void *data)
{
return get_sb_bdev(type, flags, dev_name, data, ext2_fill_super);
}get_sb_bdev() VFS函数分配并初始化一个新的适合于磁盘文件系统的超级块;它接收ext2_fill_super()函数的地址,该函数从Ext2磁盘分区读取磁盘超级块。为了分配适合于特殊文件系统的超级块,VFS也提供get_sb_pseudo()函数(对于没有安装点的特殊文件系统,例如pipefs)、get_sb_single()函数(对于具有唯一安装点的特殊文件系统,例如sysfs)以及get_sb_nodev()函数(对于可以安装多次的特殊文件系统,例如tmpfs)。
get_sb_bdev()执行的最重要的操作如下:
- 调用open_bdev_excl()打开设备文件名为dev_name的块设备。
- 调用sget()搜索文件系统的超级块对象链表(type->fs_supers)。如果找到一个与块设备相关的超级块,则返回它的地址。否则,分配并初始化一个新的超级块对象,把它插入到文件系统链表和超级块全局链表中,并返回其地址。
- 如果不是新的超级块(它不是上一步分配的,因为文件系统已经被安装),则跳到第6步。
- 把参数flags中的值拷贝到超级块的s_flags字段,并将s_id、s_old_blocksize以及s_blocksize字段设置为块设备的合适值。
- 调用依赖文件系统的函数(该函数作为传递给get_sb_bdev()的最后一个参数)访问磁盘上的超级块信息,并填充新超级块对象的其他字段。
- 返回新超级块对象的地址。
安装根文件系统
安装根文件系统是系统初始化的关键部分。这是一个相当复杂的过程,因为Linux内核允许根文件系统存放在很多不同的地方,比如硬盘分区、软盘、通过NFS共享的远程文件系统,甚至保存在ramdisk中(RAM中的虚拟块设备)。为了使叙述变得简单,让我们假定根文件系统存放在硬盘分区(毕竟这是最常见的情况)。当系统启动时,内核就要在变量ROOT_DEV中寻找包含根文件系统的磁盘主设备号。当编译内核时,或者向最初的启动装入程序传递一个合适的“root”选项时,根文件系统可以被指定为/dev目录下的一个设备文件。类似地,根文件系统的安装标志存放在root_mountflags变量中。用户可以指定这些标志,或者通过对已编译的内核映像使用rdev外部程序,或者向最初的启动装入程序传递一个合适的rootflags选项来达到(参见附录一)。
安装根文件系统分两个阶段,如下所示:
- 内核安装特殊rootfs文件系统,该文件系统仅提供一个作为初始安装点的空目录。
- 内核在空目录上安装实际根文件系统。
为什么内核不怕麻烦,要在安装实际根文件系统之前安装rootfs文件系统呢?我们知道,rootfs文件系统允许内核容易地改变实际根文件系统。事实上,在某些情况下,内核逐个地安装和卸载几个根文件系统。例如,一个发布版的初始启动光盘可能把具有一组最小驱动程序的内核装入RAM中,内核把存放在ramdisk中的一个最小的文件系统作为根安装。接下来,在这个初始根文件系统中的程序探测系统的硬件(例如,它们判断硬盘是否是EIDE、SCSI等等),装入所有必需的内核模块,并从物理块设备重新安装根文件系统。
阶段1:安装rootfs文件系统
第一阶段是由init_rootfs()和init_mount_tree()函数完成的,它们在系统初始化过程中执行。
init_rootfs
init_rootfs()函数注册特殊文件系统类型rootfs;
struct file_system_type rootfs_fs_type ={
.name ="rootfs“;
·get_sb = rootfs_get_sb;
.kill_sb= kill_litter_super;
};
register_filesystem(&rootfs_fs_type);init_mount_tree
init_mount_tree()函数执行如下操作:
- 调用do_kern_mount()函数,把字符串“rootfs”作为文件系统类型参数传递给它,并把该函数返回的新安装文件系统描述符的地址保存在mnt局部变量中。正如前一节所介绍的,do_kern_mount()最终调用rootfs文件系统的get_sb方法,也即rootfs_get_sb()函数:
struct superblock *rootfs_get_sb(struct file_system_type *fs_type, int flags, const char *dev_name, void *data)
{
return get_sb_nodev(fs_type, flags I MS_NOUSER, data, ramfs_fill_super);
}get_sb_nodev()函数执行如下步骤:
- 调用sget()函数分配新的超级块,传递set_anon_super()函数的地址作为参数。接下来,用合适的方式设置超级块的s_dev字段:主设备号为0,次设备号不同于其他已安装的特殊文件系统的次设备号。
- 将flags参数的值拷贝到超级块的s_flags字段中。
- 调用ramfs_fill_super()函数分配索引节点对象和对应的目录项对象,并填充超级块字段值。由于rootfs是一种特殊文件系统,没有磁盘超级块,因此只需执行两个超级块操作。
- 返回新超级块的地址。
- 为进程0的命名空间分配一个namespace对象,并将它插入到由do_kern_mount()函数返回的已安装文件系统描述符中:
namespace = kmalloc(sizeof(*namespace, GFP_KERNEL);
list_add(&mnt->mnt_list, &namespace->list);
namespace->root = mnt;
mnt->mnt_namespace = init_task.namespace = namespace;- 将系统中其他每个进程的namespace字段设置为namespace对象的地址;同时初始化引用计数器namespace->count(缺省情况下,所有的进程共享同一个初始namespace)。
- 将进程0的根目录和当前工作目录设置为根文件系统。
阶段2:安装实际根文件系统
根文件系统安装操作的第二阶段是由内核在系统初始化即将结束时进行的。根据内核被编译时所选择的选项,和内核装入程序所传递的启动选项,可以有几种方法安装实际根文件系统。为了简单起见,我们只考虑磁盘文件系统的情况,它的设备文件名已通过“root”启动参数传递给内核。同时我们假定除了rootfs文件系统外,没有使用其他初始特殊文件系统。
prepare_namespace()函数执行如下操作:
把root_device_name变量置为从启动参数“root”中获取的设备文件名。同样,把ROOT_DEV变量置为同一设备文件的主设备号和次设备号。
调用mount_root()函数,依次执行如下操作:
- 调用sys_mknod()在rootfs初始根文件系统中创建设备文件/dev/root,其主、次设备号与存放在ROOT_DEV中的一样。
- 分配一个缓冲区并用文件系统类型名链表填充它。该链表要么通过启动参数“rootfstype”传送给内核,要么通过扫描文件系统类型单向链表中的元素建立。
- 扫描上一步建立的文件系统类型名链表。对每个名字,调用sys_mount()试图在根设备上安装给定的文件系统类型。由于每个特定于文件系统的方法使用不同的魔数,因此,对get_sb()的调用大都会失败,但有一个例外,那就是用根设备上实际使用过的文件系统的函数来填充超级块的那个调用,该文件系统被安装在rootfs文件系统的/root目录上。
- 调用sys_chdir(“/root”)改变进程的当前目录。此目录项通过目录项所在的文件系统挂载点,路径对应的目录项对象唯一确定。
移动rootfs文件系统根目录上的已安装文件系统的安装点。
// param1:dev_path---/root
// param2:mount_path---上一级文件系统根目录
// 这样新安装的文件系统成为全局根文件系统
sys_mount(".”, “/", NULL, MS_MOVE, NULL);
sys_chroot(".");注意,rootfs特殊文件系统没有被卸载:它只是隐藏在基于磁盘的根文件系统下了。
卸载文件系统
umount()系统调用用来卸载一个文件系统。相应的sys_umount()服务例程作用于两个参数:文件名(多是安装点目录或是块设备文件名)和一组标志。该函数执行下列操作:
调用path_lookup()查找安装点路径名;该函数把返回的查找操作结果存放在nameidata类型的局部变量nd中。
如果查找的最终目录不是文件系统的安装点,则设置retval返回码为-EINVAL并跳到第6步。这种检查是通过验证nd->mnt->mnt_root(它包含由nd.dentry指向的目录项对象地址)进行的。
如果要卸载的文件系统还没有安装在命名空间中,则设置retval返回码为-EINVAL并跳到第6步(回想一下,某些特殊文件系统没有安装点)。这种检查是通过在nd->mnt上调用check_mnt()函数进行的。
如果用户不具有卸载文件系统的特权,则设置retval返回码为-EPERM并跳到第6步。
调用do_umount(),传递给它的参数为nd.mnt(已安装文件系统对象)和flags(一组标志)。该函数执行下列操作:
- 从已安装文件系统对象的mnt_sb字段检索超级块对象sb的地址。
- 如果用户要求强制卸载操作,则调用umount_begin超级块操作中断任何正在进行的安装操作。
- 如果要卸载的文件系统是根文件系统,且用户并不要求真正地把它卸载下来,则调用do_remount_sb()重新安装根文件系统为只读并终止。
- 为进行写操作而获取当前进程的namespace->sem读/写信号量和vfsmount_lock自旋锁。
- 如果已安装文件系统不包含任何子安装文件系统的安装点,或者用户要求强制卸载文件系统,则调用umount_tree()卸载文件系统(及其所有子文件系统)。
- 释放vfsmount_lock自旋锁和当前进程的namespace->sem读/写信号量。
减少相应文件系统根目录的目录项对象和已安装文件系统描述符的引用计数器值;这些计数器值由path_lookup()增加。
返回retval的值。
路径名查找
当进程必须识别一个文件时,就把它的文件路径名传递给某个VFS系统调用,如open()、mkdir()、rename()或stat()。本节我们要说明VFS如何实现路径名查找,也就是说如何从文件路径名导出相应的索引节点。执行这一任务的标准过程就是分析路径名并把它拆分成一个文件名序列。除了最后一个文件名以外,所有的文件名都必定是目录。如果路径名的第一个字符是“/”,那么这个路径名是绝对路径,因此从current->fs->root(进程的根目录)所标识的目录开始搜索。否则,路径名是相对路径,因此从current->fs->pwd(进程的当前目录)所标识的目录开始搜索。
在对初始目录的索引节点进行处理的过程中,代码要检查与第一个名字匹配的目录项,以获得相应的索引节点。然后,从磁盘读出包含那个索引节点的目录文件,并检查与第二个名字匹配的目录项,以获得相应的索引节点。对于包含在路径中的每个名字,这个过程反复执行。
目录项高速缓存极大地加速了这一过程,因为它把最近最常使用的目录项对象保留在内存中。正如我们以前看到的,每个这样的对象使特定目录中的一个文件名与它相应的索引节点相联系。因此在很多情况下,路径名的分析可以避免从磁盘读取中间目录。但是,事情并不像看起来那么简单,因为必须考虑如下的Unix和VFS文件系统的特点:
- 对每个目录的访问权必须进行检查,以验证是否允许进程读取这一目录的内容。
- 文件名可能是与任意一个路径名对应的符号链接;在这种情况下,分析必须扩展到那个路径名的所有分量。
- 符号链接可能导致循环引用;内核必须考虑这个可能性,并能在出现这种情况时将循环终止。
- 文件名可能是一个已安装文件系统的安装点。这种情况必须检测到,这样,查找操作必须延伸到新的文件系统。
- 路径名查找应该在发出系统调用的进程的命名空间中完成。由具有不同命名空间的两个进程使用的相同路径名,可能指定了不同的文件。
路径名查找是由path_lookup()函数执行的,它接收三个参数:
name
指向要解析的文件路径名的指针。
flags
标志的值,表示将会怎样访问查找的文件。在后面的表12-16中列出了所允许的标志。
nd
nameidata数据结构的地址,这个结构存放了查找操作的结果,其字段如表12-15 所示。
当path_lookup()返回时,nd指向的nameidata结构用与路径名查找操作有关的数据来填充。
| 字段 | 说明 |
|---|---|
| dentry | 自录项对象的地址 |
| mnt | 已安装文件系统对象的地址 |
| last | 路径名的最后一个分量(当LOOKUP PARENT标志被设置时使用) |
| flags | 查找标志 |
| last_type | 径名最后一个分量的类型(当LOOKUP PARENT标志被设置时使用) |
| depth | 号链接嵌套的当前级别,它必须小于6 |
| saved_names | 与嵌套的符号链接关联的路径名数组 |
| intent | 单个成员联合体指定如何访问文件 |
dentry和mnt字段分别指向所解析的最后一个路径分量的目录项对象和已安装文件系统对象。这两个字段“描述“由给定路径名表示的文件。由于path_lookup()函数返回的nameidata结构中的目录项对象和已安装文件系统对象代表了查找操作的结果,因此在path_lookup()的调用者完成使用查找结果之前,这两个对象都不能被释放。因此,path_lookup()增加两个对象引用计数器的值。如果调用者想释放这些对象,则调用path_release()函数,传递给它的参数为nameidata结构的地址。flags字段存放查找操作中使用的某些标志的值;它们在表12-16中列出。这些标志中的大部分可由调用者在path_lookup()的flags参数中进行设置。
| 宏 | 说明 |
|---|---|
| LOOKUP_FOLLOW | 如果最后一个分量是符号链接,则解释(追踪)它 |
| LOOKUP_DIRECTORY | 最后一个分量必须是自录 |
| LOOKUP_CONTINUE | 在路径名中还有文件名要检查 |
| LOOKUPPARENT | 查找最后一个分量名所在的目录 |
| LOOKUP_NOALT | 不考虑模拟根目录 |
| LOOKUP_OPEN | 试图打开一个文件 |
| LOOKUP_CREATE | 试图创建一个文件(如果不存在) |
| LOOKUP_ACCESS | 试图为一个文件检查用户的权限 |
path_lookup()函数执行下列步骤:
如下初始化nd参数的某些字段:
- 把last_type字段置为LAST_ROOT(如果路径名是一个“/”或“/”序列,那么这是必需的)。
- 把flags字段置为参数flags的值。
- 把depth字段置为0。
为进行读操作而获取当前进程的current->fs->lock读/写信号量。
如果路径名的第一个字符是“/“,那么查找操作必须从当前根目录开始:获取相应已安装文件对象(current->fs->rootmnt)和目录项对象(current->fs->root)的地址,增加引用计数器的值,并把它们的地址分别存放在nd->mnt和nd->dentry中。
否则,如果路径名的第一个字符不是“/“,则查找操作必须从当前工作目录开始:获得相应已安装文件系统对象(current->fs->pwdmmt)和目录项对象(current->fs->pwd)的地址,增加引用计数器的值,并把它们的地址分别存放在nd->mnt和nd->dentry中。
释放当前进程的current->fs->lock读/写信号量。
把当前进程描述符中的total_link_count字段置为0。
调用link_path_walk()函数处理正在进行的查找操作:return link_path_walk(name,nd);
我们现在准备描述路径名查找操作的核心,也就是link_path_walk()函数。它接收的参数为要解析的路径名指针name和nameidata数据结构的地址nd。为了简单起见,我们首先描述当LOOKUP_PARENT未被设置且路径名不包含符号链接时,link_path_walk()做些什么(标准路径名查找)。接下来,我们讨论LOOKUP_PARENT 被设置的情况:这种类型的查找在创建、删除或更名一个目录项时是需要的,也就是在父目录名查找过程中是需要的。最后,我们阐明该函数如何解析符号链接。
标准路径名查找
嗯,很长!
当LOOKUP_PARENT标志被清零时,link_path_walk()执行下列步骤:
用nd->flags初始化lookup_flags局部变量。
跳过路径名第一个分量前的任何斜杠(/)。
如果剩余的路径名为空,则返回0。在nameidata数据结构中,dentry和mnt字段指向原路径名最后一个所解析分量对应的对象。
如果nd描述符中的depth字段的值为正,则把lookup_flags局部变量置为LOOKUP_FOLLOW标志。
执行一个循环,把name参数中传递的路径名分解为分量(中间的“/”被当作文件名分隔符对待);对于每个找到的分量,该函数:
a. 从nd->dentry->d_inode检索最近一个所解析分量的索引节点对象的地址(在第一次循环中,索引节点指向开始路径名查找的目录)。
b. 检查存放到索引节点中的最近那个所解析分量的许可权是否允许执行(在Unix中,只有目录是可执行的,它才可以被遍历)。如果索引节点有自定义的permission方法,则执行它;否则,执行exec_permission_lite()函数,该函数检查存放在索引节点i_mode字段的访问模式和运行进程的特权。在两种情况中,如果最近所解析分量不允许执行,那么link_path_walk()跳出循环并返回一个错误码。
c. 考虑要解析的下一个分量。从它的名字,函数为目录项高速缓存散列表计算一个32位的散列值。
d. 如果“/”终止了要解析的分量名,则跳过“/”之后的任何尾部“/”。
e. 如果要解析的分量是原路径名中的最后一个分量,则跳到第6步。
f. 如果分量名是一个“.“(单个圆点),则继续下一个分量(“.“指的是当前目录,因此,这个点在目录内没有什么效果)。
g. 如果分量名是“…“(两个圆点),则尝试回到父目录:(1) 如果最近解析的目录是进程的根目录(nd->dentry等于current->fs->root,而nd->mnt等于current->fs->rootmnt),那么再向上追踪是不允许的:在最近解析的分量上调用follow_mount(),继续下一个分量。
(2) 如果最近解析的目录是nd->mnt文件系统的根目录(nd->dentry等于nd->mnt->mnt_root),并且这个文件系统也没有被安装在其他文件系统之上(nd->mnt等于nd->mnt->mnt_parent),那么nd->mnt文件系统通常就是命名空间的根文件系统:在这种情况下,再向上追踪是不可能的,因此在最近解析的分量上调用follow_mount(),继续下一个分量。
(3) 如果最近解析的目录是nd->mnt文件系统的根目录,而这个文件系统被安装在其他文件系统之上,那么就需要文件系统交换。因此,把nd->dentry置为nd->mnt->mnt_mountpoint(这个是在上一级文件系统下的路径),且把nd->mnt置为nd->mnt->mnt_parent,然后重新开始第5g步(回想一下,几个文件系统可以安装在同一个安装点上)。这样进入一个新的文件系统,在此系统中执行…逻辑。
(4) 如果最近解析的目录不是已安装文件系统的根目录,那么必须回到父目录:把nd->dentry置为nd->dentry->d_parent,在父目录上调用follow_mount(),继续下一个分量。follow_mount()函数检查nd->dentry是否是某文件系统的安装点(nd->dentry->d_mounted的值大于0);如果是,则调用lookup_mnt()搜索目录项高速缓存中已安装文件系统的根目录,并把nd->dentry和nd->mnt更新为相应已安装文件系统的对象地址;然后重复整个操作(几个文件系统可以安装在同一个安装点上)。从本质上说,由于进程可能从某个文件系统的目录开始路径名的查找,而该目录被另一个安装在其父目录上的文件系统所隐藏,那么当需要回到父目录时,则调用follow_mount()函数。
h. 分量名既不是“.”,也不是“…”,因此函数必须在目录项高速缓存中查找它。如果低级文件系统有一个自定义的d_hash目录项方法,则调用它来修改已在第5c步计算出的散列值。
i. 把nd->flags字段中LOOKUP_CONTINUE标志对应的位置位,这表示还有下一个分量要分析。
j. 调用do_lookup(),得到与给定的父目录(nd->dentry)和文件名(要解析的路径名分量)相关的目录项对象。该函数本质上首先调用__d_lookup()在目录项高速缓存中搜索分量的目录项对象。如果没有找到这样的目录项对象,则调用real_lookup()。而real_lookup()执行索引节点的lookup方法从磁盘读取目录,创建一个新的目录项对象并把它插入到目录项高速缓存中,然后创建一个新的索引节点对象并把它插入到索引节点高速缓存中。在这一步结束时,next局部变量中的dentry和mnt字段将分别指向这次循环要解析的分量名的目录项对象和已安装文件系统对象。
k. 调用follow_mount()函数检查刚解析的分量(next.dentry)是否指向某个文件系统安装点的一个目录(next.dentry->d_mounted值大于0)。follow_mount()更新next.dentry和next.mnt的值,以使它们指向由这个路径名分量所表示的目录上安装的最上层文件系统的目录项对象和已安装文件系统对象。
l. 检查刚解析的分量是否指向一个符号链接(next.dentry->d_inode具有一个自定义的follow_link方法)。
m. 检查刚解析的分量是否指向一个目录(next.dentry->d_inode具有一个自定义的lookup方法)。如果没有,返回一个错误码-ENOTDIR,因为这个分量位于原路径名的中间。
n. 把nd->dentry和nd->mnt分别置为next.dentry和next.mnt,然后继续路径名的下一个分量。现在,除了最后一个分量,原路径名的所有分量都被解析。清除nd->flags中的LOOKUP_CONTINUE标志。
如果路径名尾部有一个“/”,则把lookup_flags局部变量中LOOKUP_FOLLOW和LOOKUP_DIRECTORY标志对应的位置位,以强制由后面的函数来解释最后一个作为目录名的分量。
检查lookup_flags变量中LOOKUP_PARENT标志的值。下面假定这个标志被置为0,并把相反的情况推迟到下一节介绍。
如果最后一个分量名是“.”(单个圆点),则终止执行并返回值0(无错误)。在nd指向的nameidata数据结构中,dentry和mnt字段指向路径名中倒数第二个分量对应的对象(任何分量“.”在路径名中没有效果)。
如果最后一个分量名是“…”(两个圆点),则尝试回到父目录:
a. 如果最后解析的目录是进程的根目录(nd->dentry等于current->fs->root,nd->mnt等于current->fs->rootmnt),则在倒数第二个分量上调用follow_mount(),终止执行并返回值0(无错误)。nd->dentry和nd->mnt指向路径名的倒数第二个分量对应的对象,也就是进程的根目录。
b. 如果最后解析的目录是nd->mnt文件系统的根目录(nd->dentry等于nd->mnt->mnt_root),并且该文件系统没有被安装在另一个文件系统之上(nd->mnt等于nd->mnt->mnt_parent),那么再向上搜索是不可能的,因此在倒数第二个分量上调用follow_mount(),终止执行并返回值0(无错误)。
c. 如果最后解析的目录是nd->mnt文件系统的根目录,并且该文件系统被安装在其他文件系统之上,那么把nd->dentry和nd->mnt分别置为nd->mnt->mnt_mountpoint和nd->mnt->mnt_parent,然后重新执行第10步。
d. 如果最后解析的目录不是已安装文件系统的根目录,则把nd->dentry置为nd->dentry->d_parent,在父目录上调用follow_mount(),终止执行并返回值0(无错误)。nd->dentry和nd->mnt指向前一个分量(即路径名倒数第二个分量)对应的对象。
- 路径名的最后分量名既不是“.”也不是“…”,因此,必须在高速缓存中查找它。如果低级文件系统有自定义的d_hash目录项方法,则该函数调用它来修改在第5c步已经计算出的散列值。
- 调用do_lookup(),得到与父目录和文件名相关的目录项对象(在这一步结束时,next局部变量存放的是指向最后分量名对应的目录项和已安装文件系统描述符的指针。)
- 调用follow_mount()检查最后一个分量名是否是某个文件系统的一个安装点,如果是,则把next局部变量更新为最上层已安装文件系统根目录对应的目录项对象和已安装文件系统对象的地址。
- 检查在lookup_flags中是否设置了LOOKUP_FOLLOW标志,且索引节点对象next.dentry->d_inode是否有一个自定义的follow_link方法。如果是,分量就是一个必须进行解释的符号链接。
- 要解析的分量不是一个符号链接或符号链接不该被解释。把nd->mnt和nd->dentry字段分别置为next.mnt和next.dentry的值。最后的目录项对象就是整个查找操作的结果。
- 检查nd->dentry->d_inode是否为NULL。这发生在没有索引节点与目录项对象关联时,通常是因为路径名指向一个不存在的文件。在这种情况下,返回一个错误码-ENOENT。
- 路径名的最后一个分量有一个关联的索引节点。如果在lookup_flags中设置了LOOKUP_DIRECTORY标志,则检查索引节点是否有一个自定义的lookup方法,也就是说它是一个目录。如果没有,则返回一个错误码-ENOTDIR。
- 返回值0(无错误)。nd->dentry和nd->mnt指向路径名的最后分量。
父路径名查找
在很多情况下,查找操作的真正目的并不是路径名的最后一个分量,而是最后一个分量的前一个分量。例如,当文件被创建时,最后一个分量表示还不存在的文件的文件名,而路径名中的其余路径指定新链接必须插入的目录。因此,查找操作应当取回最后分量的前一个分量的目录项对象。另举一个例子,把路径名/foo/bar表示的文件bar拆分出来就包含从目录foo中移去bar。因此,内核真正的兴趣在于访问文件目录foo而不是bar。当查找操作必须解析的是包含路径名最后一个分量的目录而不是最后一个分量本身时,使用LOOKUP_PARENT标志。当LOOKUP_PARENT标志被设置时,link_path_walk()函数也在nameidata数据结构中建立last和last_type字段。last字段存放路径名中的最后一个分量名。last_type 字段标识最后一个分量的类型;可以把它置为如表12-17所示的值之一。
| 值 | 说明 |
|---|---|
| LAST_NORM | 最后一个分量是普通文件名 |
| LAST_ROOT | 最后一个分量是“/”(也就是整个路径名为“/”) |
| LAST_DOT | 最后一个分量是“.” |
| LAST_DOTDOT | 最后一个分量是“..” |
| LAST_BIND | 最后一个分量是链接到特殊文件系统的符号链接 |
当整个路径名的查找操作开始时,LAST_ROOT标志是由path_lookup()设置的缺省值。如果路径名正好是“/”,则内核不改变last_type字段的初始值。last_type字段的其他值在LOOKUP_PARENT标志置位时由link_path_walk()设置;
在这种情况下,函数执行前一节描述的步骤,直到第8步。不过,从第8步往后,路径名中最后一个分量的查找操作是不同的:
- 把nd->last置为最后一个分量名。
- 把nd->last_type初始化为LAST_NORM。
- 如果最后一个分量名为“.”(一个圆点),则把nd->last_type置为LAST_DOT。
- 如果最后一个分量名为“…”(两个圆点),则把nd->last_type置为LAST_DOTDOT。
- 通过返回值0(无错误)终止。
你可以看到,最后一个分量根本就没有被解释。因此,当函数终止时,nameidata数据结构的dentry和mnt字段指向最后一个分量所在目录对应的对象。
符号链接的查找
回想一下,符号链接是一个普通文件,其中存放的是另一个文件的路径名。路径名可以包含符号链接,且必须由内核来解析。例如,如果/foo/bar是指向(包含路径名)…/dir的一个符号链接,那么,/foo/bar/file 路径名必须由内核解析为对/dir/file文件的引用。在这个例子中,内核必须执行两个不同的查找操作。第一个操作解析/foo/bar,当内核发现bar是一个符号链接名时,就必须提取它的内容并把它解释为另一个路径名。第二个路径名操作从第一个操作所达到的目录开始,继续到符号链接路径名的最后一个分量被解析。接下来,原来的查找操作从第二个操作所达到的目录项恢复,且有了原目录名中紧随符号链接的分量。
对于更复杂的情景,含有符号链接的路径名可能包含其他的符号链接。你可能认为解析这类符号链接的内核代码是相当难理解的,但并非如此;代码实际上是相当简单的,因为它是递归的。
然而,难以驾驭的递归本质上是危险的。例如,假定一个符号链接指向自己。当然,解析含有这样符号链接的路径名可能导致无休止的递归调用流,这又依次引发内核栈的溢出。当前进程的描述符中的link_count字段用来避免这种问题:每次递归执行前增加这个字段的值,执行之后减少其值。如果该字段的值达到6,整个循环操作就以错误码结束。因此,符号链接嵌套的层数不超过5。
此外,当前进程的描述符中的total_link_count字段记录在原查找操作中有多少符号链接(甚至非嵌套的)被跟踪。如果这个计数器的值到40,则查找操作中止。没有这个计数器,怀有恶意的用户就可能创建一个病态的路径名,让其中包含很多连续的符号链接,使内核在无休止的查找操作中冻结。
这就是代码基本工作的方式:一旦link_path_walk()函数检索到与路径名分量相关的目录项对象,就检查相应的索引节点对象是否有自定义的follow_link方法。如果是,索引节点就是一个符号链接,在原路径名的查找操作进行之前就必须先对这个符号链接进行解释。
在这种情况下,link_path_walk()函数调用do_follow_link(),前者传递给后者的参数为符号链接目录项对象的地址dentry和nameidata数据结构的地址nd。
do_follow_link()依次执行下列步骤:
- 检查current->link_count小于5;否则,返回错误码-ELOOP。
- 检查current->total_link_count小于40;否则,返回错误码-ELOOP。
- 如果当前进程需要,则调用cond_resched()进行进程交换(设置当前进程描述符thread_info中的TIF_NEED_RESCHED标志)。
- 递增current->link_count、current->total_link_count和nd->depth的值。
- 更新与要解析的符号链接关联的索引节点的访问时间。
- 调用与具体文件系统相关的函数来实现follow_link方法,给它传递的参数为dentry和nd。它读取存放在符号链接索引节点中的路径名,并把这个路径名保存在nd->saved_names数组的合适项中。
- 调用__vfs_follow_link()函数,给它传递的参数为地址nd和nd->saved_names数组中路径名的地址。
- 如果定义了索引节点对象的put_link方法,就执行它,释放由follow_link方法分配的临时数据结构。
- 减少current->link_count和nd->depth字段的值。
- 返回由__vfs_follow_link()函数返回的错误码(0表示无错误)。
__vfs_follow_link()函数本质上依次执行下列操作:
a. 检查符号链接路径名的第一个字符是否是“/“:在这种情况下,已经找到一个绝对路径名,因此没有必要在内存中保留前一个路径的任何信息。 如果是,对nameidata数据结构调用path_release(),因此释放由前一个查找步骤产生的对象; 然后,设置nameidata数据结构的dentry和mnt字段,以使它们指向当前进程的根目录。
b. 调用link_path_walk()解析符号链的路径名,传递给它的参数为路径名和nd。
c. 返回从link_path_walk()取回的值。
当do_follow_link()最后终止时,它把局部变量next的dentry字段设置为目录项对象的地址,而这个地址由符号链接传递给原先就执行的link_path_walk()。link_path_walk()函数然后进行下一步 。
VFS系统调用的实现
为了简短起见,我们不打算对表12-1中列出的所有VFS系统调用的实现进行讨论。不过,概略叙述几个系统调用的实现还是有用的,这里仅仅说明VFS的数据结构怎样互相作用。让我们重新考虑一下在本章开始所提到的例子,用户发出了一条shell命令:把/floppy/TEST中的MS-DOS文件拷贝到/tmp/test中的Ext2文件中。命令shell调用一个外部程序(如cp),我们假定cp执行下列代码片段:
inf = open(“/floppy/TEST“, O_RDONLY, 0);
outf = open(“/tmp/test“, 0_WRONLY I O_CREATIO_TRUNC, 0600);
do {
len =read(inf, buf, 4096);
write(outf, buf, len);
} while(len);
close(outf);
close(inf);
12345678 实际上,真正的cp程序的代码要更复杂些,因为它还必须检查由每个系统调用返回的可能的出错码。在我们的例子中,我们只把注意力集中在拷贝操作的“正常“行为上。
open()系统调用
open()系统调用的服务例程为sys_open()函数,该函数接收的参数为:要打开文件的路径名filename、访问模式的一些标志flags,以及如果该文件被创建所需要的许可权位掩码mode。如果该系统调用成功,就返回一个文件描述符,也就是指向文件对象的指针数组current->files->fd中分配给新文件的索引;否则,返回-1。
在我们的例子中,open()被调用两次;第一次是为读(O_RDONLY标志)而打开/floppy/TEST,第二次是为写(O_WRONLY标志)而打开/mp/test。如果/mp/test不存在,则该文件被创建(0_CREAT标志),文件主对该文件具有独占的读写访问权限(在第三个参数中的八进制数0600)。
相反,如果该文件已经存在,则从头开始重写它(0_TRUNC标志)。表12-18列出了open()系统调用的所有标志。
- O_RDONLY :以只读方式打开文件
- O_WRONLY :以只写方式打开文件
- O_RDWR :以可读可写方式打开文件
- O_APPEND:每次进行写操作时,内核都会先定位到文件尾,再执行写操作。
- O_ASYNC:使用异步 I/O 模式。
- O_CLOEXEC :在打开文件的时候,就为文件描述符设置 FD_CLOEXEC 标志。这是一个新的选项,用于解决在多线程下 fork 与用 fcntl 设置 FD_CLOEXEC 的竞争问题。某些应用使用 fork 来执行第三方的业务,为了避免泄露已打开文件的内容, 那些文件会设置 FD_CLOEXEC 标志。但是 fork 与 fcntl 是两次调用,在多线程下, 可能会在 fcntl 调用前,就已经 fork 出子进程了,从而导致该文件句柄暴露给子进程。关于 O_CLOEXEC 的用途。
- O_CREAT:当文件不存在时,就创建文件。
- O_DIRECT:对该文件进行直接 I/O,不使用 VFS Cache。
- O_DIRECTORY:要求打开的路径必须是目录。
- O_EXCL:该标志用于确保是此次调用创建的文件,需要与 O_CREAT 同时使用; 当文件已经存在时,open 函数会返回失败。
- O_LARGEFILE:表明文件为大文件。
- O_NOATIME:读取文件时,不更新文件最后的访问时间。
- O_NONBLOCK、O_NDELAY:将该文件描述符设置为非阻塞的(默认都是阻塞的)。
- O_SYNC :设置为 I/O 同步模式,每次进行写操作时都会将数据同步到磁盘,然后write 才能返回。
- O_TRUNC:在打开文件的时候,将文件长度截断为0,需要与O_RDWR或O_WRONLY同时使用。在写文件时,如果是作为新文件重新写入,一定要使用O_TRUNC标志,否则可能会造成旧内容依然存在于文件中的错误,如生成配置文件、pid文件等。
下面来描述一下sys_open()函数的操作。它执行如下操作:
- 调用getname()从进程地址空间读取该文件的路径名。
- 调用get_unused_fd()在current->files->fd中查找一个空的位置。相应的索引(新文件描述符)存放在fd局部变量中。
- 调用filp_open()函数,传递给它的参数为路径名、访问模式标志以及许可权位掩码。这个函数依次执行下列步骤:
a. 把访问模式标志拷贝到namei_flags标志中,但是,用特殊的格式对访问模式标志O_RDONLY、O_WRONLY和O_RDWR进行编码:如果文件访问需要读特权,那么只设置namei_flags标志的下标为0的位(最低位);类似地,如果文件访问需要写特权,就只设置下标为1的位。注意,不可能在open()系统调用中不指定文件访问的读或写特权;不过,这种情况在涉及符号链接的路径名查找中则是有意义的。
b. 调用open_namei(),传递给它的参数为路径名、修改的访问模式标志以及局部nameidata数据结构的地址。该函数以下列方式执行查找操作:
b.1. 如果访问模式标志中没有设置O_CREAT,则不设置LOOKUP_PARENT标志而设置LOOKUP_OPEN标志后开始查找操作。
b.2. 只有O_NOFOLLOW被清零,才设置LOOKUP_FOLLOW标志。
b.3. 只有设置了O_DIRECTORY标志,才设置LOOKUP_DIRECTORY标志。
b.4. 如果在访问模式标志中设置了O_CREAT,则以LOOKUP_PARENT、LOOKUP_OPEN和LOOKUP_CREATE标志的设置开始查找操作。一旦path_lookup()函数成功返回,则检查请求的文件是否已存在。如果不存在,则调用父索引节点的create方法分配一个新的磁盘索引节点。open_namei()函数也在查找操作确定的文件上执行几个安全检查。例如,该函数检查与已找到的目录项对象关联的索引节点是否存在、它是否是一个普通文件,以及是否允许当前进程根据访问模式标志访问它。如果文件也是为写打开的,则该函数检查文件是否被其他进程加锁。
c. 调用dentry_open()函数,传递给它的参数为访问模式标志、目录项对象的地址以及由查找操作确定的已安装文件系统对象。该函数依次执行下列操作:
(1). 分配一个新的文件对象。
(2). 根据传递给open()系统调用的访问模式标志初始化文件对象的f_flags和f_mode字段。
(3). 根据作为参数传递来的目录项对象的地址和已安装文件系统对象的地址初始化文件对象的f_fentry和f_vfsmnt字段。
(4). 把f_op字段设置为相应索引节点对象i_fop字段的内容。这就为进一步的文件操作建立起所有的方法。
(5). 把文件对象插入到文件系统超级块的s_files字段所指向的打开文件的链表。
(6). 如果文件操作的open方法被定义,则调用它。
(7). 调用file_ra_state_init()初始化预读的数据结构。
(8). 如果O_DIRECT标志被设置,则检查直接I/O操作是否可以作用于文件。
(9). 返回文件对象的地址。
d… 返回文件对象的地址。
- 把current->files->fd[fd]置为由dentry_open()返回的文件对象的地址。
- 返回fd。
read()和write()系统调用
让我们再回到cp例子的代码。open()系统调用返回两个文件描述符,分别存放在inf 和outf变量中。然后,程序开始循环。在每次循环中,/floppy/TEST文件的一部分被拷贝到本地缓冲区(read()系统调用)中,然后,这个本地缓冲区中的数据又被拷贝到/tmp/test文件(write()系统调用)。read()和write()系统调用非常相似。它们都需要三个参数:一个文件描述符fd、一个内存区的地址buf(该缓冲区包含要传送的数据),以及一个数count(指定应该传送多少字节)。当然,read()把数据从文件传送到缓冲区,而write()执行相反的操作。两个系统调用都返回所成功传送的字节数,或者发送一个错误条件的信号并返回-1。
返回值小于count并不意味着发生了错误。即使请求的字节没有都被传送,也总是允许内核终止系统调用,因此用户应用程序必须检查返回值并重新发出系统调用(如果必要)。在以下几种典型情况下返回小的值:当从管道或终端设备读取时,当读到文件的末尾时,或者当系统调用被信号中断时。文件结束条件(EOF)很容易从read()的空返回值中判断出来。这个条件不会与因信号引起的异常终止混淆在一起,因为如果读取数据之前read()被一个信号中断,则发生一个错误。
读或写操作总是发生在由当前文件指针所指定的文件偏移处(文件对象的f_pos字段)。两个系统调用都通过把所传送的字节数加到文件指针上而更新文件指针。简而言之,sys_read()(read()的服务例程)和sys_write()(write()的服务例程)几乎都执行相同的步骤:
- 调用fget_light()从fd获取相应文件对象的地址file。
- 如果file->f_mode中的标志不允许所请求的访问(读或写操作),则返回一个错误码-EBADF。
- 如果文件对象没有read()或aio_read()(write()或aio_write())文件操作,则返回一个错误码-EINVAL。
- 调用access_ok()粗略地检查buf和count参数。
- 调用rw_verify_area()对要访问的文件部分检查是否有冲突的强制锁。如果有,则返回一个错误码,如果该锁已经被F_SETLKW命令请求,那么就挂起当前进程。
- 调用file->f_op->read或file->f_op->write方法(如果已定义)来传送数据;否则,调用file->f_op->aio_read或file->f_op->aio_write方法。所有这些方法都返回实际传送的字节数。另一方面的作用是,文件指针被适当地更新。
- 调用fput_light()释放文件对象。
- 返回实际传送的字节数。
close()系统调用
在我们例子的代码中,循环结束发生在read()系统调用返回0时,也就是说,发生在/floppy/TEST中的所有字节被拷贝到/tmp/test中时。然后,程序关闭打开的文件,这是因为拷贝操作已经完成。close()系统调用接收的参数为要关闭文件的文件描述符fd。sys_close()服务例程执行下列操作:
- 获得存放在current->files->fd[fd]中的文件对象的地址;如果它为NULL,则返回一个出错码。
- 把current->files->fd[fd]置为NULL。释放文件描述符fd,这是通过清除current->files中的open_fds和close_on_exec字段的相应位来进行的。
- 调用filp_close(),该函数执行下列操作:
a. 调用文件操作的flush方法(如果已定义)。
b. 释放文件上的任何强制锁。
c. 调用fput()释放文件对象。 - 返回0或一个出错码。出错码可由flush方法或文件中的前一个写操作错误产生。
文件加锁
当一个文件可以被多个进程访问时,就会出现同步问题。如果两个进程试图对文件的同一位置进行写会出现什么情况?或者,如果一个进程从文件的某个位置进行读而另一个进程正在对同一位置进行写会出现什么情况?
在传统的Unix系统中,对文件同一位置的同时访问会产生不可预料的结果。但是,Unix 系统提供了一种允许进程对一个文件区进行加锁的机制,以使同时访问可以很容易地被避免。POSIX标准规定了基于fcntl()系统调用的文件加锁机制。这样就有可能对文件的任意一部分(甚至一个字节)加锁或对整个文件(包含以后要追加的数据)加锁。因为进程可以选择仅仅对文件的一部分加锁,因此,它也可以在文件的不同部分保持多个锁。
这种锁并不把不知道加锁的其他进程关在外面。与用于保护代码中临界区的信号量类似,可以认为这种锁起“劝告“的作用,因为只有在访问文件之前其他进程合作检查锁的存在时,锁才起作用。因此,POSIX的锁被称为劝告锁(advisory lock)。
传统的BSD变体通过flock()系统调用来实现劝告锁。这个调用不允许进程对文件的一个区字段进行加锁,而只能对整个文件进行加锁。传统的System V变体提供了lockf()库函数,它仅仅是fcntl()的一个接口。
更重要的是,System V Release3引入了强制加锁(mandatory locking);内核检查open()、read()和write()系统调用的每次调用都不违背在所访问文件上的强制锁。因此,强制锁甚至在非合作的进程之间也被强制加上。
不管进程是使用劝告锁还是强制锁,它们都可以使用共享读锁和独占写锁。在文件的某个区字段上,可以有任意多个进程进行读,但在同一时刻只能有一个进程进行写。此外,当其他进程对同一个文件都拥有自己的读锁时,就不可能获得一个写锁,反之亦然。
Linux文件加锁
Linux支持所有的文件加锁方式:劝告锁和强制锁,以及fcntl()、flock(〉和lockf()系统调用。不过,lockf()系统调用仅仅是一个标准的库函数。flock()系统调用不管MS_MANDLOCK安装标志如何设置,只产生劝告锁。这是任何类Unix操作系统所期望的系统调用行为。在Linux中,增加了一种特殊的flock()强制锁,以允许对专有的网络文件系统的实现提供适当的支持。这就是所谓的共享模式强制锁;当这个锁被设置时,其他任何进程都不能打开与锁访问模式冲突的文件。不鼓励本地Unix应用程序中使用这个特征,因为这样加锁的源代码是不可移植的。
在Linux中还引入了另一种基于fcntl()的强制锁,叫做租借锁(lease)。当一个进程试图打开由租借锁保护的文件时,它照样被阻塞。然而,拥有锁的进程接收到一个信号。一旦该进程得到通知,它应当首先更新文件,以使文件的内容保持一致,然后释放锁。如果拥有者不在预定的时间间隔(可以通过在/proc/sys/fs/lease-break-time文件中写入秒数来进行调整,通常为45s)内这么做,则租借锁由内核自动删除,且允许阻塞的进程继续执行。
进程可以采用以下两种方式获得或释放一个文件劝告锁:
· 发出flock()系统调用。传递给它的两个参数为文件描述符fd和指定锁操作的命令。该锁应用于整个文件。
· 使用fcntl()系统调用。传递给它的三个参数为文件描述符fd、指定锁操作的命令以及指向flock结构的指针(参见表12-20)。flock结构中的几个字段允许进程指定要加锁的文件部分。因此进程可以在同一文件的不同部分保持几个锁。
fcntl()和flock()系统调用可以在同一文件上同时使用,但是通过fcntl()加锁的文件看起来与通过flock()加锁的文件不一样,反之亦然。这样当应用程序使用一种依赖于某个库的锁,而该库同时使用另一种类型的锁时,可以避免发生死锁。
处理强制文件锁要更复杂些。步骤如下:
- 安装文件系统时强制锁是必需的,可使用mount命令的-o mand选项在mount()系统调用中设置MS_MANDLOCK标志。缺省操作是不使用强制锁。
- 通过设置文件的set-group位(SGID)和清除group-execute许可权位将它们标记为强制锁的候选者。因为当group-execute位为0时,set-group位也没有任何意义,因此内核将这种合并解释成使用强制锁而不是劝告锁。
- 使用fcntl()系统调用获得或释放一个文件锁。
处理租借锁比处理强制锁要容易得多:
调用具有F_SETLEASE或F_GETLEASE命令的系统调用fcntl()就足够了。使用另一个带有F_SETSIG命令的fcntl()系统调用可以改变传送给租借锁进程拥有者的信号类型。
当维护所有可以修改文件内容的系统调用时,除了read()和write()系统调用中的检查以外,内核还需要考虑强制锁的存在性。例如,如果文件中存在任何强制锁,那么带有O_TRUNC标志的open()系统调用就会失效。下一节描述内核使用的主要数据结构,它们用于处理由flock()(FL_FLOCK锁)和fcntl()系统调用(FL_POSIX锁)实现的文件锁。
文件锁的数据结构
Linux中所有类型的锁都是由相同的file_lock数据结构描述的,它的字段如表12-19 所示。
| struct file_lock* | fl_next | 与索引节点相关的锁列表中下一个元素 |
|---|---|---|
| struct list_head | fl_link | 指向活跃列表或者被阻塞列表 |
| struct list_head | fl_block | 指向锁等待列表 |
| struct files_struct * | fl_owner | 锁拥有者的 files_struct |
| unsigned char | fl_flags | 锁标识 |
| unsigned char | fl_type | 锁类型 |
| unsigned int | fl_pid | 进程拥有者的 pid |
| wait_queue_head_t | fl_wait | 被阻塞进程的等待队列 |
| struct file * | fl_file | 指向文件对象 |
| loff_t | fl_start | 被锁区域的开始位移 |
| loff_t | fl_end | 被锁区域的结束位移 |
| struct fasync_struct * | fl_fasync | 用于租借暂停通知 |
| unsigned long | fl_break_time | 租借的剩余时间 |
| struct file_lock_operations * | fl_ops | 指向文件锁操作 |
| struct lock_manager_operations * | fl_mops | 指向锁管理操作 |
| union | fl_u | 文件系统特定信息 |
指向磁盘上同一文件的所有lock_file结构都被收集在一个单向链表中,其第一个元素由索引节点对象的i_flock字段所指向。file_lock结构的fl_next字段指向链表中的下一个元素。
当发出阻塞系统调用的进程请求一个独占锁而同一文件也存在共享锁时,该请求不能立即得到满足,并且进程必须被挂起。因此该进程被插入到由阻塞锁file_lock结构的fl_wait字段指向的等待队列中。
使用两个链表区分已满足的锁请求(活动锁)和那些不能立刻得到满足的锁请求(阻塞锁)。所有的活动锁被链接在“全局文件锁链表”中,该表的首元素被存放在file_lock_list 变量中。类似地,所有的阻塞锁被链接在“阻塞链表“中,该表的首元素被存放在blocked_list变量中。使用fl_link字段可把lock_file结构插入到上述任何一个链表中。
最后的一项要点是,内核必须跟踪所有与给定活动锁(“blocker”)关联的阻塞锁(“waiters”);这就是为什么要使用链表根据给定的blocker把所有的waiter链接在一起的原因。blocker的fl_block字段是链表的伪首部,而waiter的fl_block字段存放了指向链表中相邻元素的指针。
FL_FLOCK锁
FL_LOCK锁总是与一个文件对象相关联,因此由一个打开该文件的进程(或共享同一打开文件的子进程)来维护。当一个锁被请求或允许时,内核就把进程保持在同一文件对象上的任何其他锁都替换掉。这只发生在进程想把一个已经拥有的读锁改变为一个写锁,或把一个写锁改变为一个读锁时。此外,当fput()函数正在释放一个文件对象时,对这个文件对象加的所有FL_LOCK锁都被撤销。不过,也有可能由其他进程对这同一文件(索引节点)设置了其他FL_LOCK读锁,它们依然是有效的。
flock()系统调用允许进程在打开文件上申请或删除劝告锁。它作用于两个参数:要加锁文件的文件描述符fd和指定锁操作的参数cmd。如果cmd参数为LOCK_SH,则请求一个共享的读锁;为LOCK_EX,则请求一个互斥的写锁;为LOCK_UN,则释放一个锁。
如果请求不能立即得到满足,系统调用通常阻塞当前进程,例如,如果进程请求一个独占锁而其他某个进程已获得了该锁。不过,如果LOCK_NB标记与LOCK_SH或LOCK_EX 操作进行“或“,则这个系统调用不阻塞;换句话说,如果不能立即获得该锁,则该系统调用就返回一个错误码。
当sys_flock()服务例程被调用时,则执行下列步骤:
- 检查fd是否是一个有效的文件描述符;如果不是,就返回一个错误码。否则,获得相应文件对象filp的地址。
- 检查进程在打开文件上是否有读和/或写权限;如果没有,就返回一个错误码。
- 获得一个新的file_lock对象锁并用适当的锁操作初始化它:根据参数cmd的值设置fl_type字段,把fl_file字段设为文件对象filp的地址,fl_flags字段设为FL_FLOCK,fl_pid字段设为current->tgid,并把fl_end字段设为-1,这表示对整个文件(而不是文件的一部分)加锁的事实。
- 如果参数cmd不包含LOCK_NB位,则把FL_SLEEP标志加入fl_flags字段。
- 如果文件具有一个flock文件操作,则调用它,传递给它的参数为文件对象指针filp、一个标志(F_SETLKW或F_SETLK,取决于LOCK_NB位的值)以及新的file_lock对象锁的地址。
- 否则,如果没有定义flock文件操作(通常情况下),则调用flock_lock_file_wait()试图执行请求的锁操作。传递给它的两个参数为:文件对象指针filp和在第3步创建的新的file_lock对象的地址lock。
- 如果上一步中还没有把file_lock描述符插入活动或阻塞链表中,则释放它。
- 返回0(成功)。
flock_lock_file_wait()函数执行下列循环操作:
调用flock_lock_file(),传递给它的参数为文件对象指针filp和新的file_lock对象锁的地址lock。 这个函数依次执行下列操作:
- 搜索filp->f_dentry->d_inode->i_flock指向的链表。如果在同一文件对象中找到FL_FLOCK锁,则检查它的类型(LOCK_SH或LOCK_EX):如果该锁的类型与新锁相同,则返回0(什么也没有做)。 否则,从索引节点锁链表和全局文件锁链表中删除这个file_lock元素,唤醒fl_block链表中在该锁的等待队列上睡眠的所有进程,并释放file_lock结构。
- 如果进程正在执行开锁(LOCK_UN),则什么事情都不需要做:该锁已不存在或已被释放,因此返回0。
- 如果已经找到同一个文件对象的FL_FLOCK锁——表明进程想把一个已经拥有的读锁改变为一个写锁(反之亦然),那么调用cond_resched()给予其他更高优先级进程(特别是先前在原文件锁上阻塞的任何进程)一个运行的机会。
- 再次搜索索引节点锁链表以验证现有的FL_FLOCK锁并不与所请求的锁冲突。
在索引节点链表中,肯定没有FL_FLOCK写锁,此外,如果进程正在请求一个写锁,那么根本就没有FL_FLOCK锁。 - 如果不存在冲突锁,则把新的file_lock结构插入索引节点锁链表和全局文件锁链表中,然后返回0(成功)。
- 发现一个冲突锁:如果fl_flags字段中FL_SLEEP对应的标志位置位,则把新锁(waiter锁)插入到blocker锁循环链表和全局阻塞链表中。返回一个错误码-EAGAIN。
检查flock_lock_file()的返回码:
a. 如果返回码为0(没有冲突迹象),则返回0(成功)。
b. 不相容的情况。如果fl_flags字段中的FL_SLEEP标志被清除,就释放file_lock锁描述符,并返回一个错误码-EAGAIN。
c. 否则,不相容但进程能够睡眠的情况:调用wait_event_interruptible()把当前进程插入到lock->fl_wait等待队列中并挂起它。当进程被唤醒时(正好在释放blocker锁后),跳转到第1步再次执行这个操作。
FL_POSIX锁
FL_POSIX锁总是与一个进程和一个索引节点相关联。当进程死亡或一个文件描述符被关闭时(即使该进程对同一文件打开了两次或复制了一个文件描述符),这种锁会被自动地释放。此外,FL_POSIX锁绝不会被子进程通过fork()继承。
当使用fcntl()系统调用对文件加锁时,该系统调用作用于三个参数:要加锁文件的文件描述符fd、指向锁操作的参数cmd,以及指向存放在用户态进程地址空间中的flock 数据结构的指针f1。
sys_fcntl()服务例程执行的操作取决于在cmd参数中所设置的标志值:
F_GETLK
确定由flock结构描述的锁是否与另一个进程已获得的某个FL_POSIX锁互相冲突。在冲突的情况下,用现有锁的有关信息重写flock结构。
F_SETLK
设置由flock结构描述的锁。如果不能获得该锁,则这个系统调用返回一个错误码。
F_SETLKW
设置由flock结构描述的锁。如果不能获得该锁,则这个系统调用阻塞,也就是说,调用进程进入睡眠状态直到该锁可用时为止。
F_GETLK64,F_SETLK64,F_SETLKW64
与前面描述的几个标志相同,但是使用的是flock64结构而不是flock结构。
12345678sys_fcntl()服务例程首先获取与参数fd对应的文件对象,然后调用fcntl_getlk()或fcntl_setlk()函数(这取决于传递的参数:F_GETLK表示前一个函数,F_SETLK 或F_SETLKW表示后一个函数)。我们仅仅考虑第二种情况。fcntl_setlk()函数作用于三个参数:指向文件对象的指针filp、cmd命令(F_SETLK 或F_SETLKW),以及指向flock数据结构的指针。该函数执行下列操作:
读取局部变量中的参数f1所指向的flock结构。
检查这个锁是否应该是一个强制锁,且文件是否有一个共享内存映射。在肯定的情况下,该函数拒绝创建锁并返回-EAGAIN出错码,说明文件正在被另一个进程访问。
根据用户flock结构的内容和存放在文件索引节点中的文件大小,初始化一个新的file_lock结构。
如果命令cmd为F_SETLKW,则该函数把file_lock结构的fl_flags字段设为FL_SLEEP标志对应的位置位。
如果flock结构中的l_type字段为F_RDLCK,则检查是否允许进程从文件读取;类似地,如果l_type为F_WRLCK,则检查是否允许进程写入文件。如果都不是,则返回一个出错码。
调用文件操作的lock方法(如果已定义)。对于磁盘文件系统,通常不定义该方法。
调用__posix_lock_file()函数,传递给它的参数为文件的索引节点对象地址以及file_lock对象地址。该函数依次执行下列操作:
- 对于索引节点的锁链表中的每个FL_POSIX锁,调用posix_locks_conflict()。
该函数检查这个锁是否与所请求的锁互相冲突。从本质上说,在索引节点的链表中,必定没有用于同一区的FL_POSIX写锁,并且,如果进程正在请求一个写锁,那么同一个区字段也可能根本没有FL_POSIX锁。但是,同一个进程所拥有的锁从不会冲突;这就允许进程改变它已经拥有的锁的特性。 - 如果找到一个冲突锁,则检查是否以F_SETLKW标志调用fcntl()。如果是,当前进程应当被挂起:这种情况下,调用posix_locks_deadlock()来检查在等待FL_POSIX锁的进程之间没有产生死锁条件,然后把新锁(waiter锁)插入到冲突锁(blocker锁)blocker链表和阻塞链表中,最后返回一个出错码。否则,如果以F_SETLK标志调用fcntl(),则返回一个出错码。
- 只要索引节点的锁链表中不包含冲突的锁,就检查把文件区重叠起来的当前进程的所有FL_POSIX锁,当前进程想按需要对文件区中相邻的区字段进行锁定、组合及拆分。例如,如果进程为某个文件区请求一个写锁,而这个文件区落在一个较宽的读锁区字段内,那么,以前的读锁就会被拆分为两部分,这两部分覆盖非重叠区域,而中间区域由新的写锁进行保护。在重叠的情况下,新锁总是代替旧锁。
- 把新的file_lock结构插入到全局锁链表和索引节点链表中。
- 返回值0(成功)。
- 对于索引节点的锁链表中的每个FL_POSIX锁,调用posix_locks_conflict()。
检查__posix_lock_file()的返回码
- 如果返回码为0(没有冲突迹象),则返回0(成功)。
- 不相容的情况。如果fl_flags字段的FL_SLEEP标志被清除,就释放新的file_lock描述符,并返回一个错误码-EAGAIN。
- 否则,如果不相容但进程能够睡眠时,调用wait_event_interruptible()把当前进程插入到lock->fl_wait等待队列中并挂起它。当进程被唤醒时(正好在释放blocker锁后),跳转到第7步再次执行这个操作。
Reference
[高级操作系统] VFS详解(虚拟文件系统)_操作系统vfs层-CSDN博客
一般的文件系统样板
Ext2
Ext2的一般特征
类Unix操作系统使用多种文件系统。尽管所有这些文件系统都有少数POSIX API(如state())所需的共同的属性子集,但每种文件系统的实现方式是不同的。Linux的第一个版本是基于MINIX文件系统的。
当Linux成熟时,引入了扩展文件系统(Extended Filesystem,Ext FS)。它包含了几个重要的扩展但提供的性能不令人满意。在1994年引入了第二扩展文件系统(Ext2);它除了包含几个新的特点外,还相当高效和稳定,Ext2及它的下代文件系统Ext3已成为广泛使用的Linux文件系统。
下列特点有助于Ext2的效率:
- 当创建Ext2文件系统时,系统管理员可以根据预期的文件平均长度来选择最佳块大小(从1024B~4096B)。例如,当文件的平均长度小于几千字节时,块的大小为1024B是最佳的,因为这会产生较少的内部碎片——也就是文件长度与存放它的磁盘分区有较少的不匹配。另一方面,大的块对于大于几千字节的文件通常比较合适,因为这样的磁盘传送较少,因而减轻了系统的开销。
- 当创建Ext2文件系统时,系统管理员可以根据在给定大小的分区上预计存放的文件数来选择给该分区分配多少个索引节点。这可以有效地利用磁盘的空间。文件系统把磁盘块分为组。每组包含存放在相邻磁道上的数据块和索引节点。正是这种结构,使得可以用较少的磁盘平均寻道时间对存放在一个单独块组中的文件进行访问。在磁盘数据块被实际使用之前,文件系统就把这些块预分配给普通文件。因此,当文件的大小增加时,因为物理上相邻的几个块已被保留,这就减少了文件的碎片。
- 支持快速符号链接。如果符号链接表示一个短路径名(小于或等于60个字符),就把它存放在索引节点中而不用通过读一个数据块进行转换。
此外,Ext2还包含了一些使它既健壮又灵活的特点:
- 文件更新策略的谨慎实现将系统崩溃的影响减到最少。
- 在启动时支持对文件系统的状态进行自动的一致性检查。这种检查是由外部程序e2fsck完成的,这个外部程序不仅可以在系统崩溃之后被激活,也可以在一个预定义的文件系统安装数(每次安装操作之后对计数器加1)之后被激活,或者在自从最近检查以来所花的预定义时间之后被激活。
- 支持不可变(immutable)的文件(不能修改、删除和更名)和仅追加(append-only)的文件(只能把数据追加在文件尾)。
- 既与Unix System VRelease4(SVR4)相兼容,也与新文件的用户组ID的BSD 语义相兼容。在SVR4中,新文件采用创建它的进程的用户组ID;而在BSD中,新文件继承包含它的目录的用户组ID。Ext2包含一个安装选项,由你指定采用哪种语义。
即使Ext2文件系统是如此成熟、稳定的程序,也还要考虑引入另外几个特性。一些特性已被实现并以外部补丁的形式来使用。另外一些还仅仅处于计划阶段,但在一些情况下,已经在Ext2的索引节点中为这些特性引入新的字段。最重要的一些特点如下:
- 块片(block fragmentation):系统管理员对磁盘的访问通常选择较大的块,因为计算机应用程序常常处理大文件。因此,在大块上存放小文件就会浪费很多磁盘空间。这个问题可以通过把几个文件存放在同一块的不同片上来解决。
- 透明地处理压缩和加密文件:这些新的选项(创建一个文件时必须指定)将允许用户透明地在磁盘上存放压缩和(或)加密的文件版本。
- 逻辑删除:一个undelete选项将允许用户在必要时很容易恢复以前已删除的文件内容。
- 日志:日志避免文件系统在被突然卸载(例如,作为系统崩溃的后果)时对其自动进行的耗时检查。
Ext2中缺少的最突出的功能就是日志,日志是高可用服务器必需的功能。为了平顺过渡,日志没有引入到Ext2文件系统;但是,我们在后面“Ext3文件系统”一节会讨论,完全与Ext2兼容的一种新文件系统已经创建,这种文件系统提供了日志。不真正需要日志的用户可以继续使用良好而老式的Ext2文件系统,而其他用户可能采用这种新的文件系统。现在发行的大部分系统采用Ext3作为标准的文件系统。
Ext2磁盘数据结构
任何Ext2分区中的第一个块从不受Ext2文件系统的管理,因为这一块是为分区的引导扇区所保留的。Ext2分区的其余部分分成块组(block group),每个块组的分布图如图18-1所示。正如你从图中所看到的,一些数据结构正好可以放在一块中,而另一些可能需要更多的块。在Ext2文件系统中的所有块组大小相同并被顺序存放,因此,内核可以从块组的整数索引很容易地得到磁盘中一个块组的位置。
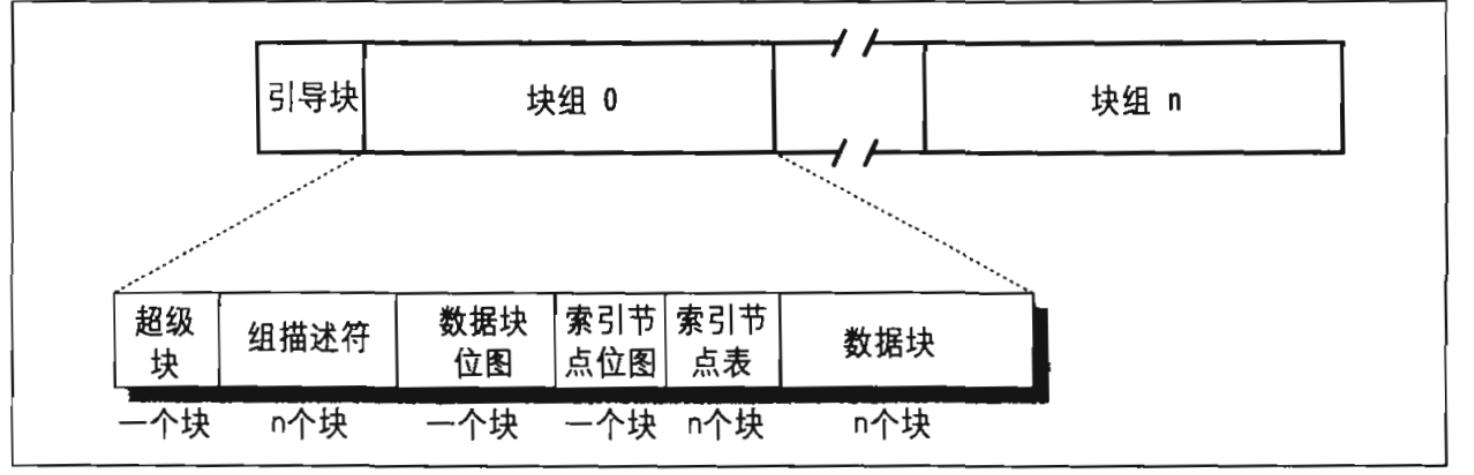
纠正:
上图中,组描述符占据的块数n,索引节点表占据的块数n,数据块占据的块数n,块数数n之间没有关联。
- 组描述符占据块数=(文件系统快组数组描述符尺寸) / 块尺寸+(文件系统快组数组描述符尺寸) % 块尺寸 ? 1 : 0;
- 索引节点位置占据块数=(每个快组索引节点数索引节点尺寸) / 块尺寸+(每个快组索引节点数索引节点尺寸) % 块尺寸 ? 1 : 0;
- 数据块数= 快组占据块数-1-组描述符占据块数-1-1-索引节点占据块数
- 文件系统快组数,每个快组索引节点数,快组占据块数在磁盘格式化为文件系统时确定
由于内核尽可能地把属于一个文件的数据块存放在同一块组中,所以块组减少了文件的碎片。块组中的每个块包含下列信息之一:
- 文件系统的超级块的一个拷贝
- 一组块组描述符的拷贝
- 一个数据块位图
- 一个索引节点位图
- 一个索引节点表
- 属于文件的一大块数据,即数据块。如果一个块中不包含任何有意义的信息,就说这个块是空闲的。
只有块组0中所包含的超级块和组描述符才由内核使用,而其余的超级块和组描述符保持不变;事实上,内核甚至不考虑它们。
当e2fsck程序对Ext2文件系统的状态执行一致性检查时,就引用存放在块组0中的超级块和组描述符,然后把它们拷贝到其他所有的块组中。如果出现数据损坏,并且块组0中的主超级块和主描述符变为无效,那么,系统管理员就可以命令e2fsck 引用存放在某个块组(除了第一个块组)中的超级块和组描述符的旧拷贝。
通常情况下,这些多余的拷贝所存放的信息足以让e2fsck把Ext2分区带回到一个一致的状态。有多少块组呢?这取决于分区的大小和块的大小。其主要限制在于块位图,因为块位图必须存放在一个单独的块中。块位图用来标识一个组中块的占用和空闲状况。所以,每组中至多可以有8×b个块,b是以字节为单位的块大小。因此,块组的总数大约是s/(8×b),这里s是分区所包含的总块数。
举例说明,让我们考虑一下32GB的Ext2分区,块的大小为4KB。在这种情况下,每个4KB的块位图描述32K个数据块,即128MB。因此,最多需要256个块组。显然,块的大小越小,块组数越大。
超级块
Ext2在磁盘上的超级块存放在一个ext2_super_block结构中,它的字段在表18-1中列出。u8、u16及u32数据类型分别表示长度为8、16及32位的无符号数,而s8、s16及s32数据类型表示长度为8、16及32位的有符号数。
为清晰地表示磁盘上字或双字中字节的存放顺序,内核又使用了le16、le32、be16和be32数据类型,前两种类型分别表示字或双字的“小尾(little-endian)”排序方式(低阶字节在高位地址),而后两种类型分别表示字或双字的“大尾(big-endian)”排序方式(高阶字节在高位地址)。每个块组都有自己的组描述符
当分配新索引节点和数据块时,会用到bg_free_blocks_count、bg_free_inodes_count 和bg_used_dirs_count字段。这些字段确定在最合适的块中给每个数据结构进行分配。位图是位的序列,其中值0表示对应的索引节点块或数据块是空闲的,1表示占用。因为每个位图必须存放在一个单独的块中,又因为块的大小可以是1024、2048或4096字节,因此,一个单独的位图描述8192、16384或32768个块的状态。
索引节点表
索引节点表由一连串连续的块组成,其中每一块包含索引节点的一个预定义号。索引节点表第一个块的块号存放在组描述符的bg_inode_table字段中。所有索引节点的大小相同,即128字节。一个1024字节的块可以包含8个索引节点,一个4096字节的块可以包含32个索引节点。为了计算出索引节点表占用了多少块,用一个组中的索引节点总数(存放在超级块的s_inodes_per_group字段中)除以每块中的索引节点数。
与POSIX规范相关的很多字段类似于VFS索引节点对象的相应字段。其余的字段与Ext2的特殊实现相关,主要处理块的分配。特别地,i_size字段存放以字节为单位的文件的有效长度,而i_blocks字段存放已分配给文件的数据块数(以512字节为单位)。i_size和i_blocks的值没有必然的联系。因为一个文件总是存放在整数块中,一个非空文件至少接受一个数据块(因为还没实现片)且i_size可能小于512× i_blocks。
一个文件可能包含有洞。在那种情况下,i_size可能大于512×i_blocks。i_block字段是具有EXT2_N_BLOCKS(通常是15)个指针元素的一个数组,每个元素指向分配给文件的数据块。
留给i_size字段的32位把文件的大小限制到4GB。事实上,i_size字段的最高位没有使用,因此,文件的最大长度限制为2GB。然而,Ext2文件系统包含一种“脏技巧”,允许像AMD的Opteron和IBM的PowerPC G5这样的64位体系结构使用大型文件。从本质上说,索引节点的i_dir_acl字段(普通文件没有使用)表示i_size字段的32位扩展。因此,文件的大小作为64位整数存放在索引节点中。
Ext2文件系统的64位版本与32位版本在某种程度上兼容,因为在64位体系结构上创建的Ext2文件系统可以安装在32位体系结构上,反之亦然。但是,在32位体系结构上不能访问大型文件,除非以O_LARGEFILE标志打开文件。回忆一下,VFS模型要求每个文件有不同的索引节点号。在Ext2中,没有必要在磁盘上存放文件的索引节点号与相应块号之间的转换,因为后者的值可以从块组号和它在索引节点表中的相对位置而得出。
例如,假设每个块组包含4096个索引节点,我们想知道索引节点13021在磁盘上的地址。在这种情况下,这个索引节点属于第三个块组,它的磁盘地址存放在相应索引节点表的第733个表项中。正如你看到的,索引节点号是Ext2例程用来快速搜索磁盘上合适的索引节点描述符的一个关键字。
索引节点的增强属性
Ext2索引节点的格式对于文件系统设计者就好像一件紧身衣,索引节点的长度必须是2 的幂,以免造成存放索引节点表的块内碎片。实际上,一个Ext2索引节点的128个字符空间中充满了信息,只有少许空间可以增加新的字段。另一方面,将索引节点的长度增加至256不仅相当浪费,而且使用不同索引节点长度的Ext2文件系统之间还会造成兼容问题。
引入增强属性(extended attribute)就是要克服上面的问题。这些属性存放在索引节点之外的磁盘块中。索引节点的i_file_acl字段指向一个存放增强属性的块。具用同样增强属性的不同索引节点可以共享同一个块。每个增强属性有一个名称和值。两者都编码为变长字符数组,并由ext2_xattr_entry 描述符来确定。
图18-2表示Ext2中增强属性块的结构。每个属性分成两部分:在块首部的是ext2_xattr_entry描述符与属性名,而属性值则在块尾部。块前面的表项按照属性名称排序,而值的位置是固定的,因为它们是由属性的分配次序决定的。
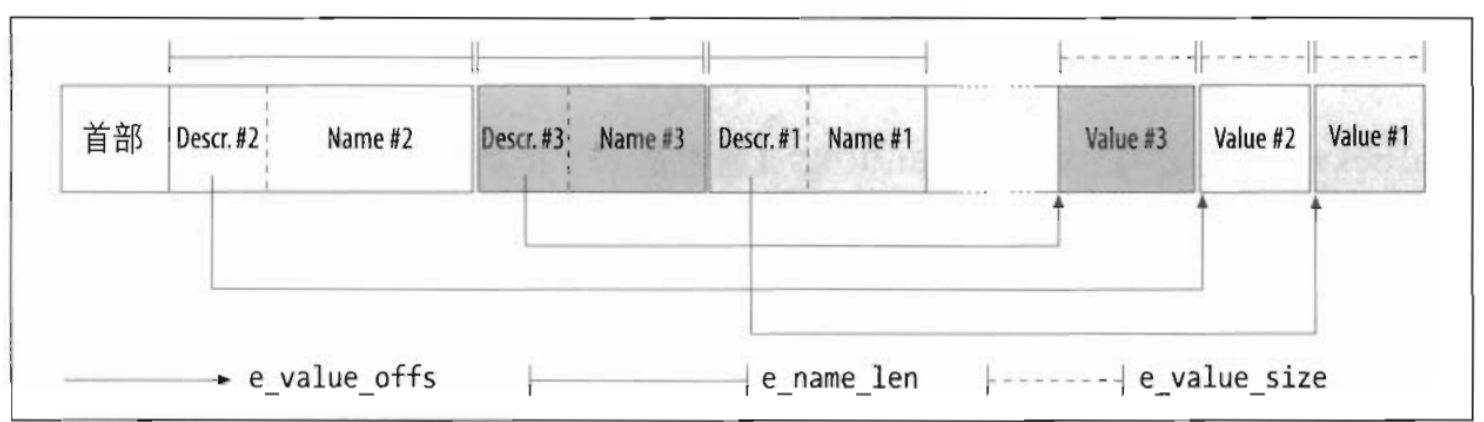
有很多系统调用用来设置、取得、列表和删除一个文件的增强属性。系统调用setxattr()、lsetxattr()和fsetxattr()设置文件的增强属性,它们在符号链接的处理与文件限定的方式(或者传递路径名或者是文件描述符)上根本不同。类似地,系统调用getxattr()、lgetxattr()和fgetxattr()返回增强属性的值。系统调用listxattr()、llistxattr()和flistxattr()则列出一个文件的所有增强属性。最后,系统调用removexattr()、lremovexattr()和fremovexattr()从文件删除一个增强属性。
访问控制列表
很早以前访问控制列表就被建议用来改善Unix文件系统的保护机制。不是将文件的用户分成三类:拥有者、组和其他,访问控制列表(access controllist,ACL)可以与每个文件关联。有了这种列表,用户可以为他的文件限定可以访问的用户(或用户组)名称以及相应的权限。Linux 2.6通过索引节点的增强属性完整实现ACL。实际上,增强属性主要就是为了支持ACL才引入的。因此,能让你处理文件ACL的库函数chacl()、setfacl()和getfacl()就是通过上一节中介绍的setxattr()和getxattr()系统调用实现的。
不幸的是,在POSIX 1003.1系列标准内,定义安全增强属性的工作组所完成的成果从没有正式成为新的POSIX标准。因此现在,不同的类Unix文件系统都支持ACL,但不同的实现之间有一些微小的差别。
各种文件类型如何使用磁盘块
Ext2所认可的文件类型(普通文件、管道文件等)以不同的方式使用数据块。有些文件不存放数据,因此根本就不需要数据块。本节讨论每种文件类型的存储要求,如表18-4所示。
- 未知 0
- 普通文件 1
- 目录 2
- 字符设备 3
- 块设备 4
- 命名管道 5
- 套接字 6
- 符号链接 7
普通文件
普通文件是最常见的情况,本章主要关注它。但普通文件只有在开始有数据时才需要数据块。普通文件在刚创建时是空的,并不需要数据块;也可以用truncate()或open()系统调用清空它。这两种情况是相同的,例如,当你发出一个包含字符串>filename的shell命令时,shell创建一个空文件或截断一个现有文件。
目录
Ext2以一种特殊的文件实现了目录,这种文件的数据块把文件名和相应的索引节点号存放在一起。特别说明的是,这样的数据块包含了类型为ext2_dir_entry_2的结构。表18-5列出了这个结构的字段。因为该结构最后一个name字段是最大为EXT2_NAME_LEN (通常是255)个字符的变长数组,因此这个结构的长度是可变的。此外,因为效率的原因,目录项的长度总是4的倍数,并在必要时用null字符(\0)填充文件名的末尾。name_len字段存放实际的文件名长度(参见图18-3)。
| 字段 | 说明 |
|---|---|
| inode | inode节点号 |
| rec_len | 目录项长度 |
| name_len | 文件名长度 |
| file_type | 文件类型 |
| name | 文件名 |
file_type字段存放指定文件类型的值(见表18-4)。rec_len字段可以被解释为指向下一个有效目录项的指针:它是偏移量,与目录项的起始地址相加就得到下一个有效目录项的起始地址。为了删除一个目录项,把它的inode字段置为0并适当地增加前一个有效目录项rec_len字段的值就足够了。仔细看一下图18-3的rec_len字段,你会发现oldfile 项已被删除,因为usr的rec_len字段被置为12+16(usr和oldfile目录项的长度)。
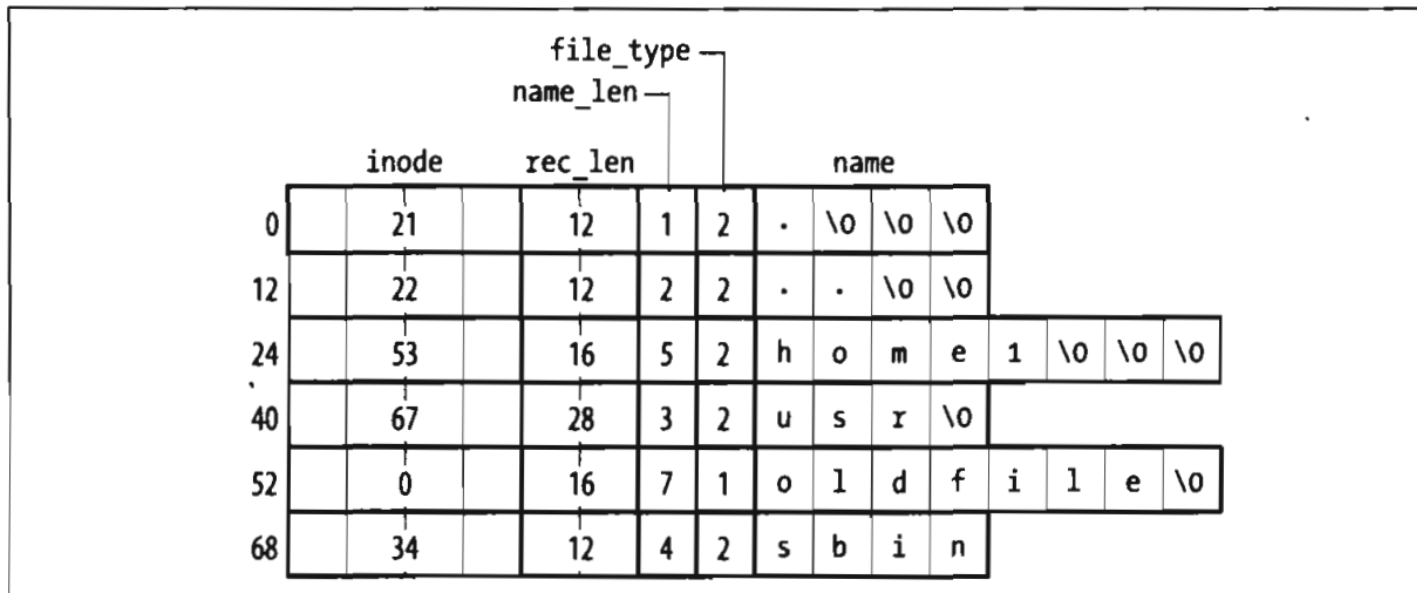
符号链接
如前所述,如果符号链接的路径名小于等于60个字符,就把它存放在索引节点的i_blocks字段,该字段是由15个4字节整数组成的数组,因此无需数据块。但是,如果路径名大于60个字符,就需要一个单独的数据块。
设备文件、管道和套接字
这些类型的文件不需要数据块。所有必要的信息都存放在索引节点中。
Ext2的内存数据结构
为了提高效率,当安装Ext2文件系统时,存放在Ext2分区的磁盘数据结构中的大部分信息被拷贝到RAM中,从而使内核避免了后来的很多读操作。那么一些数据结构如何经常更新呢?让我们考虑一些基本的操作:
- 当一个新文件被创建时,必须减少Ext2超级块中s_free_inodes_count字段的值和相应的组描述符中bg_free_inodes_count字段的值。
- 如果内核给一个现有的文件追加一些数据,以使分配给它的数据块数因此也增加,那么就必须修改Ext2超级块中s_free_blocks_count字段的值和组描述符中bg_free_blocks_count字段的值。
- 即使仅仅重写一个现有文件的部分内容,也要对Ext2超级块的s_wtime字段进行更新。因为所有的Ext2磁盘数据结构都存放在Ext2分区的块中,因此,内核利用页高速缓存来保持它们最新。
对于与Ext2文件系统以及文件相关的每种数据类型,表18-6详细说明了在磁盘上用来表示数据的数据结构、在内存中内核所使用的数据结构以及决定使用多大容量高速缓存的经验方法。频繁更新的数据总是存放在高速缓存,也就是说,这些数据一直存放在内存并包含在页高速缓存中,直到相应的Ext2分区被卸载。内核通过让缓冲区的引用计数器一直大于0来达到此目的。
在任何高速缓存中不保存“从不缓存”的数据,因为这种数据表示无意义的信息。相反,“总是缓存”的数据也总在RAM中,这样就不必从磁盘读数据了(但是,数据必须周期性地写回磁盘)。除了这两种极端模式外,还有一种动态模式。在动态模式下,只要相应的对象(索引节点、数据块或位图)还在使用,它就保存在高速缓存中;而当文件关闭或数据块被删除后,页框回收算法会从高速缓存中删除有关数据。有意思的是,索引节点与块位图并不永久保存在内存里,而是需要时从磁盘读。有了页高速缓存,最近使用的磁盘块保存在内存里,这样可以避免很多磁盘读。
Ext2的超级块对象
VFS超级块的s_fs_info字段指向一个包含文件系统信息的数据结构。对于Ext2,该字段指向ext2_sb_info类型的结构,它包含如下信息:
- 磁盘超级块中的大部分字段
- s_sbh指针,指向包含磁盘超级块的缓冲区的缓冲区首部
- s_es指针,指向磁盘超级块所在的缓冲区
- s_desc_per_block,可以放在一个块中的组描述符的个数
- s_group_desc指针,指向一个缓冲区(包含组描述符的缓冲区)首部数组(通常一项就够)
- 其他与安装状态、安装选项等有关的数据
图18-4表示的是与Ext2超级块和组描述符有关的缓冲区与缓冲区首部和ext2_sb_info 数据结构之间的关系。
当内核安装Ext2文件系统时,它调用ext2_fill_super()函数来为数据结构分配空间,并写入从磁盘读取的数据。这里是对该函数的一个简要说明,只强调缓冲区与描述符的内存分配。
ext2_fill_super: - 分配一个ext2_sb_info描述符,将其地址当作参数传递并存放在超级块的s_fs_info字段。
- 调用__bread()在缓冲区页中分配一个缓冲区和缓冲区首部。然后从磁盘读入超级块存放在缓冲区中。如果一个块已在页高速缓存的缓冲区页而且是最新的,那么无需再分配。将缓冲区首部地址存放在Ext2超级块对象的s_sbh字段。
- 分配一个字节数组,每组一个字节,把它的地址存放在ext2_sb_info描述符的s_debts字段。
- 分配一个数组用于存放缓冲区首部指针,每个组描述符一个,把该数组地址存放在ext2_sb_info的s_group_desc字段。
- 重复调用__bread()分配缓冲区,从磁盘读入包含Ext2组描述符的块。把缓冲区首部地址存放在上一步得到的s_group_desc数组中。
- 为根目录分配一个索引节点和目录项对象,为超级块建立相应的字段,从而能够从磁盘读入根索引节点对象(超级块包含根目录文件索引节点的编号)。
很显然,ext2_fill_super()函数返回后,分配的所有数据结构都保存在内存里,只有当Ext2文件系统卸载时才会被释放。当内核必须修改Ext2超级块的字段时,它只要把新值写入相应缓冲区内的相应位置然后将该缓冲区标记为脏即可。
Ext2的索引节点对象
在打开文件时,要执行路径名查找。对于不在目录项高速缓存内的路径名元素,会创建一个新的目录项对象和索引节点对象。当VFS 访问一个Ext2磁盘索引节点时,它会创建一个ext2_inode_info类型的索引节点描述符。该描述符包含下列信息:
- 存放在vfs_inode字段的整个VFS索引节点对象
- 磁盘索引节点对象结构中的大部分字段(不保存在VFS索引节点中)
- 索引节点对应的i_block_group块组索引
- i_next_alloc_block和i_next_alloc_goal字段,分别存放着最近为文件分配的磁盘块的逻辑块号与物理块号
- i_prealloc_block和i_prealloc_count字段,用于数据块预分配
- xattr_sem字段,一个读写信号量,允许增强属性与文件数据同时读入
- i_acl和i_default_acl字段,指向文件的ACL。
当处理Ext2文件时,alloc_inode超级块方法是由ext2_alloc_inode()函数实现的。它首先从ext2_inode_cachep slab分配器高速缓存得到一个ext2_inode_info描述符,然后返回在这个ext2_inode_info描述符中的索引节点对象的地址。
创建Ext2文件系统
在磁盘上创建一个文件系统通常有两个阶段。第一步格式化磁盘,以使磁盘驱动程序可以读和写磁盘上的块。现在的硬磁盘已经由厂家预先格式化,因此不需要重新格式化;在Linux上可以使用superformat或fdformat等实用程序对软盘进行格式化。第二步才涉及创建文件系统,这意味着建立本章前面详细描述的结构。
Ext2文件系统是由实用程序mke2fs创建的。mke2fs采用下列缺省选项,用户可以用命令行的标志修改这些选项:
- 块大小:1024字节(小文件系统的缺省值)
- 片大小:块的大小(块的分片还没有实现)
- 所分配的索引节点个数:每8192字节的组分配一个索引节点·
- 保留块的百分比:5%
mke2fs程序执行下列操作:
- 初始化超级块和组描述符。
- 作为选择,检查分区是否包含有缺陷的块;如果有,就创建一个有缺陷块的链表。
- 对于每个块组,保留存放超级块、组描述符、索引节点表及两个位图所需要的所有磁盘块。
- 把索引节点位图和每个块组的数据映射位图都初始化为0。
- 初始化每个块组的索引节点表。
- 创建/root目录。
- 创建lost+found目录,由e2fsck使用这个目录把丢失和找到的缺陷块连接起来。
- 在前两个已经创建的目录所在的块组中,更新块组中的索引节点位图和数据块位图。
- 把有缺陷的块(如果存在)组织起来放在lost+found目录中。
让我们看一下mke2fs是如何以缺省选项初始化Ext2的1.44 MB软盘的。软盘一旦被安装,VFS就把它看作由1412个块组成的一个卷,每块大小为1024字节。为了查看磁盘的内容,我们可以执行如下Unix命令:
dd if=/dev/fd0 bs=1k count=1440 l od -tx1 -Ax > /tmp/dump_hex
从而获得了/tmp目录下的一个文件,这个文件包含十六进制的软盘内容的转储。
通过查看dump_hex文件我们可以看到,由于软盘有限的容量,一个单独的块组描述符就足够了。我们还注意到保留的块数为72(1440块的5%),并且根据缺省选项,索引节点表必须为每8192个字节设置一个索引节点,也就是有184个索引节点存放在23个块中。表18-7总结了按缺省选项如何在软盘上建立Ext2文件系统。

Ext2的方法
在第十二章所描述的关于VFS的很多方法在Ext2都有相应的实现。因为对所有的方法都进行描述将需要整整一本书,因此我们仅仅简单地回顾一下在Ext2中所实现的方法。一旦你真正搞明白了磁盘和内存数据结构,你就应当能理解实现这些方法的Ext2函数的代码。
Ext2超级块的操作
很多VFS超级块操作在Ext2中都有具体的实现,这些方法为alloc_inode、destroy_inode、readinode、write_inode、delete_inode、put_super、write_super、statfs、remount_fs和clear_inode。超级块方法的地址存放在ext2_sops指针数组中。
Ext2索引节点的操作
一些VFS索引节点的操作在Ext2中都有具体的实现,这取决于索引节点所指的文件类型。Ext2的普通文件和目录文件的索引节点操作见表18-8。每个方法的目的在第十二章的“索引节点对象”一节有介绍。表中没有列出普通文件和目录中未定义的方法(NULL指针)。回忆一下,如果方法未定义,VFS要么调用通用函数,要么什么也不做。普通文件与目录的Ext2方法地址分别存放在ext2_file_inode_operations和ext2_dir_inode_operations 表中。
Ext2的符号链接的索引节点操作见表18-9(省略未定义的方法)。实际上有两种符号链接:快速符号链接(路径名全部存放在索引节点内)与普通符号链接(较长的路径名)。因此,有两套索引节点操作,分别存放在ext2_fast_symlink_inode_operations和ext2_symlink_inode_operations表中


如果索引节点指的是一个字符设备文件、块设备文件或命名管道,那么这种索引节点的操作不依赖于文件系统,其操作分别位于chrdev_inode_operations、blkdev_inode_operations和fifo_inode_operations 表中。
Ext2的文件操作
表18-10列出了Ext2文件系统特定的文件操作。正如你看到的,一些VFS方法是由很多文件系统共用的通用函数实现的。这些方法的地址存放在ext2_file_operations表中。
注意,Ext2的read和write方法是分别通过generic_file_read()和generic_file_write()函数实现的。
管理Ext2磁盘空间
文件在磁盘的存储不同于程序员所看到的文件,这表现在两个方面:块可以分散在磁盘上(尽管文件系统尽力保持块连续存放以提高访问速度),以及程序员看到的文件似乎比实际的文件大,这是因为程序可以把洞引入文件(通过lseek()系统调用)。
在本节,我们将介绍Ext2文件系统如何管理磁盘空间,也就是说,如何分配和释放索引节点和数据块。有两个主要的问题必须考虑:
- 空间管理必须尽力避免文件碎片,也就是说,避免文件在物理上存放于几个小的、不相邻的盘块上。
- 文件碎片增加了对文件的连续读操作的平均时间,因为在读操作期间,磁头必须频繁地重新定位。
- 空间管理必须考虑效率,也就是说,内核应该能从文件的偏移量快速地导出Ext2 分区上相应的逻辑块号。为了达到此目的,内核应该尽可能地限制对磁盘上寻址表的访问次数,因为对该表的访问会极大地增加文件的平均访问时间。
创建索引节点
ext2_new_inode()函数创建Ext2磁盘的索引节点,返回相应的索引节点对象的地址(或失败时为NULL)。该函数谨慎地选择存放该新索引节点的块组;它将无联系的目录散放在不同的组,而且同时把文件存放在父目录的同一组。为了平衡普通文件数与块组中的目录数,Ext2为每一个块组引入“债(debt)”参数。
ext2_new_inode作用于两个参数:
dir,一个目录对应的索引节点对象的地址,新创建的索引节点必须插入到这个目录中;
mode,要创建的索引节点的类型。mode还包含一个MS_SYNCHRONOUS标志,该标志请求当前进程一直挂起,直到索引节点被分配。
该函数执行如下操作:调用new_inode()分配一个新的VFS索引节点对象,并把它的i_sb字段初始化为存放在dir->i_sb中的超级块地址。然后把它追加到正在用的索引节点链表与超级块链表中。
如果新的索引节点是一个目录,函数就调用find_group_orlov()为目录找到一个合适的块组。该函数执行如下试探法:
以文件系统根root为父目录的目录应该分散在各个组。这样,函数在这些块组去查找一个组,它的空闲索引节点数和空闲块数比平均值高。如果没有这样的组则跳到第2c步。
如果满足下列条件,嵌套目录(父目录不是文件系统根root)就应被存放到父目录组:
- 该组没有包含太多的目录
- 该组有足够多的空闲索引节点
- 该组有一点小“债”。(块组的债存放在一个ext2_sb_info描述符的s_debts字段所指向的计数器数组中。每当一个新目录加入,债加一;每当其他类型的文件加入,债减一);如果父目录组不满足这些条件,那么选择第一个满足条件的组。如果没有满足条件的组,则跳到第2c步。
- 这是一个“退一步”原则,当找不到合适的组时使用。函数从包含父目录的块组开始选择第一个满足条件的块组,这个条件是:它的空闲索引节点数比每块组空闲索引节点数的平均值大。
如果新索引节点不是个目录,则调用find_group_other(),在有空闲索引节点的块组中给它分配一个。该函数从包含父目录的组开始往下找。具体如下:
- 从包含父目录dir的块组开始,执行快速的对数查找。这种算法要查找log(n)个块组,这里n是块组总数。该算法一直向前查找直到找到一个可用的块组,具体如下:如果我们把开始的块组称为i,那么,该算法要查找的块组为i mod(n),i+1 mod(n),i+1+2 mod(n),i+l+2+4 mod(n),等等。
- 如果该算法没有找到含有空闲索引节点的块组,就从包含父目录dir的块组开始执行彻底的线性查找。
调用read_inode_bitmap()得到所选块组的索引节点位图,并从中寻找第一个空位,这样就得到了第一个空闲磁盘索引节点号。
分配磁盘索引节点:把索引节点位图中的相应位置位,并把含有这个位图的缓冲区标记为脏。此外,如果文件系统安装时指定了MS_SYNCHRONOUS标志,则调用sync_dirty_buffer()开始I/O写操作并等待,直到写操作终止。
减小组描述符的bg_free_inodes_count字段。如果新的索引节点是一个目录,则增加bg_used_dirs_count字段,并把含有这个组描述符的缓冲区标记为脏。
依据索引节点指向的是普通文件或目录,相应增减超级块内s_debts数组中的组计数器。
减小ext2_sb_info数据结构中的s_freeinodes_counter字段;而且如果新索引节点是目录,则增大ext2_sb_info数据结构的s_dirs_counter字段。
将超级块的s_dirt标志置1,并把包含它的缓冲区标记为脏。
把VFS超级块对象的s_dirt字段置1。
初始化这个索引节点对象的字段。特别是,设置索引节点号i_no,并把xtime.tv_sec的值拷贝到i_atime、i_mtime及i_ctime。把这个块组的索引赋给ext2_inode_info结构的i_block_group字段。关于这些字段的含义请参考表18-3。
初始化这个索引节点对象的访问控制列表(ACL)。
将新索引节点对象插入散列表inode_hashtable,调用mark_inode_dirty()把该索引节点对象移进超级块脏索引节点链表。
调用ext2_preread_inode()从磁盘读入包含该索引节点的块,将它存入页高速缓存。进行这种预读是因为最近创建的索引节点可能会被很快写入。(在执行索引节点刷新时,先刷新到磁盘高速缓存,磁盘高速缓存再刷新到磁盘)
返回新索引节点对象的地址。
删除索引节点
用ext2_free_inode()函数删除一个磁盘索引节点,把磁盘索引节点表示为索引节点对象,其地址作为参数来传递。内核在进行一系列的清除操作(包括清除内部数据结构和文件中的数据)之后调用这个函数。具体来说,它在下列操作完成之后才执行:
索引节点对象已经从散列表中删除,
指向这个索引节点的最后一个硬链接已经从适当的目录中删除,
文件的长度截为0以回收它的所有数据块。
函数执行下列操作:调用clear_inode(),它依次执行如下步骤
- 删除与索引节点关联的“间接”脏缓冲区。它们都存放在一个链表中,该链表的首部在address_space对象inode->i_data的private_list字段。
- 如果索引节点的I_LOCK标志置位,则说明索引节点中的某些缓冲区正处于I/O数据传送中;于是,函数挂起当前进程,直到这些I/O数据传送结束。
- 调用超级块对象的clear_inode方法(如果已定义),但Ext2文件系统没有定义这个方法。
- 如果索引节点指向一个设备文件,则从设备的索引节点链表中删除索引节点对象,这个链表要么在cdev字符设备描述符的cdev字段,要么在block_device块设备描述符的bd_inodes字段。
- 把索引节点的状态置为I_CLEAR(索引节点对象的内容不再有意义)。
从每个块组的索引节点号和索引节点数计算包含这个磁盘索引节点的块组的索引。
调用read_inode_bitmap()得到索引节点位图。
增加组描述符的bg_free_inodes_count字段。如果删除的索引节点是一个目录,那么也要减小bg_used_dirs_count字段。把这个组描述符所在的缓冲区标记为脏。
如果删除的索引节点是一个目录,就减小ext2_sb_info结构的s_dirs_counter字段,把超级块的s_dirt标志置1,并把它所在的缓冲区标记为脏。
清除索引节点位图中这个磁盘索引节点对应的位,并把包含这个位图的缓冲区标记为脏。此外,如果文件系统以MS_SYNCHRONIZE标志安装,则调用sync_dirty_buffer()并等待,直到在位图缓冲区上的写操作终止。
数据块寻址
每个非空的普通文件都由一组数据块组成。这些块或者由文件内的相对位置(它们的文件块号)来标识,或者由磁盘分区内的位置(它们的逻辑块号)来标识。
从文件内的偏移量f导出相应数据块的逻辑块号需要两个步骤:
- 从偏移量f导出文件的块号,即在偏移量f处的字符所在的块索引。
- 把文件的块号转化为相应的逻辑块号。因为Unix文件不包含任何控制字符,因此,导出文件的第f个字符所在的文件块号是相当容易的,只是用f除以文件系统块的大小,并取整即可。
例如,让我们假定块的大小为4KB。如果f小于4096,那么这个字符就在文件的第一个数据块中,其文件的块号为0。如果f等于或大于4096而小于8192,则这个字符就在文件块号为1的数据块中,以此类推。只用关注文件的块号确实不错。但是,由于Ext2文件的数据块在磁盘上不必是相邻的,因此把文件的块号转化为相应的逻辑块号可不是这么直截了当的。因此,Ext2文件系统必须提供一种方法,用这种方法可以在磁盘上建立每个文件块号与相应逻辑块号之间的关系。
在索引节点内部部分实现了这种映射(回到了AT&T Unix 的早期版本)。这种映射也涉及一些包含额外指针的专用块,这些块用来处理大型文件的索引节点的扩展。磁盘索引节点的i_block字段是一个有EXT2_N_BLOCKS个元素且包含逻辑块号的数组。在下面的讨论中,我们假定EXT2_N_BLOCKS的默认值为15。如图18-5所示,这个数组表示一个大型数据结构的初始化部分。正如从图中所看到的,数组的15个元素有4种不同的类型:
- 最初的12个元素产生的逻辑块号与文件最初的12个块对应,即对应的文件块号从0~11。
- 下标12中的元素包含一个块的逻辑块号(叫做间接块),这个块表示逻辑块号的一个二级数组。这个数组的元素对应的文件块号从12~b/4+11,这里b是文件系统的块大小(每个逻辑块号占4个字节,因此我们在式子中用4作除数)。因此,内核为了查找指向一个块的指针必须先访问这个元素,然后,在这个块中找到另一个指向最终块(包含文件内容)的指针。
- 下标13中的元素包含一个间接块的逻辑块号,而这个块包含逻辑块号的一个二级数组,这个二级数组的数组项依次指向三级数组,这个三级数组存放的才是文件块号对应的逻辑块号,范围从b/4+12~(b/4)²+(b/4)+11。
- 最后,下标14中的元素使用三级间接索引,第四级数组中存放的才是文件块号对应的逻辑块号,范围从(b/4)²+(b/4)+12~(b/4)³+(b/4)²+(b14)+11。
在图18-5中,块内的数字表示相应的文件块号。箭头(表示存放在数组元素中的逻辑块号)指示了内核如何通过间接块找到包含文件实际内容的块。注意这种机制是如何支持小文件的。如果文件需要的数据块小于12,那么两次磁盘访问就可以检索到任何数据:一次是读磁盘索引节点i_block数组的一个元素,另一次是读所需要的数据块。对于大文件来说,可能需要三四次的磁盘访问才能找到需要的块。实际上,这是一种最坏的估计,因为目录项、索引节点、页高速缓存都有助于极大地减少实际访问磁盘的次数。还要注意文件系统的块大小是如何影响寻址机制的,因为大的块允许Ext2把更多的逻辑块号存放在一个单独的块中。
表18-11显示了对每种块大小和每种寻址方式所存放文件大小的上限。例如,如果块的大小是1024字节,并且文件包含的数据最多为268KB,那么,通过直接映射可以访问文件最初的12KB数据,通过简单的间接映射可以访问剩余的13~268KB的数据。大于2GB的大型文件通过指定O_LARGEFILE打开标志必须在32 位体系结构上进行打开。
文件的洞
文件的洞(file hole)是普通文件的一部分,它是一些空字符但没有存放在磁盘的任何数据块中。洞是Unix文件一直存在的一个特点。例如,下列的Unix命令创建了第一个字节是洞的文件。
$ echo -n “X” l dd of=/tmp/hole bs=1024 seek=6
现在,/tmp/hole有6145个字符(6144个空字符加一个X字符),然而,这个文件在磁盘上只占一个数据块。引入文件的洞是为了避免磁盘空间的浪费。它们被广泛地用在数据库应用中,更一般地说,用于在文件上进行散列的所有应用。文件洞在Ext2中的实现是基于动态数据块的分配的:只有当进程需要向一个块写数据时,才真正把这个块分配给文件。每个索引节点的i_size字段定义程序所看到的文件大小,包括洞,而i_blocks字段存放分配给文件有效的数据块数(以512字节为单位)。
在前面dd命令的例子中,假定/tmp/hole文件创建在块大小为4096的Ext2分区上。其相应磁盘索引节点的i_size字段存放的数为6145,而i_blocks字段存放的数为8(因为每4096字节的块包含8个512字节的块)。i_block数组的第二个元素(对应块的文件块号为1)存放已分配块的逻辑块号,而数组中的其他元素都为空(参看图18-6)。
分配数据块
当内核要分配一个数据块来保存Ext2普通文件的数据时,就调用ext2_get_block()函数。
如果块不存在,该函数就自动为文件分配块。请记住,每当内核在Ext2普通文件上执行读或写操作时就调用这个函数;显然,这个函数只在页高速缓存内没有相应的块时才被调用。
ext2_get_block()函数处理在“数据块寻址”一节描述的数据结构,并在必要时调用ext2_alloc_block()函数在Ext2分区真正搜索一个空闲块。如果需要,该函数还为间接寻址分配相应的块(参见图18-5)。
为了减少文件的碎片,Ext2文件系统尽力在已分配给文件的最后一个块附近找一个新块分配给该文件。如果失败,Ext2文件系统又在包含这个文件索引节点的块组中搜寻一个新的块。作为最后一个办法,可以从其他一个块组中获得空闲块。Ext2文件系统使用数据块的预分配策略。文件并不仅仅获得所需要的块,而是获得一组多达8个邻接的块。
ext2_inode_info结构的i_prealloc_count字段存放预分配给某一文件但还没有使用的数据块数,而i_prealloc_block字段存放下一次要使用的预分配块的逻辑块号。当下列情况发生时,释放预分配而一直没有使用的块;当文件被关闭时,当文件被缩短时,或者当一个写操作相对于引发块预分配的写操作不是顺序的时。
ext2_getblk()函数根据下列的试探法设置目标参数:
- 如果正被分配的块与前面已分配的块有连续的文件块号,则目标就是前一块的逻辑块号加1。这很有意义,因为程序所看到的连续的块在磁盘上将会是相邻的。
- 如果第一条规则不适用,并且至少给文件已分配了一个块,那么目标就是这些块的逻辑块号中的一个。更确切地说,目标是已分配块的逻辑块号,位于文件中待分配块之前。
- 如果前面的规则都不适用,那么目标就是文件索引节点所在的块组中第一个块的逻辑块号(不必空闲)。
ext2_alloc_block()函数接收的参数为
- 指向索引节点对象的指针、
- 目标(goal),目标是一个逻辑块号,表示新块的首选位置。
- 存放错误码的变量地址。
ext2_alloc_block()函数检查目标是否指向文件的预分配块中的一块。如果是,就分配相应的块并返回它的逻辑块号;否则,丢弃所有剩余的预分配块并调用ext2_new_block()。
ext2_new_block()函数用下列策略在Ext2分区内搜寻一个空闲块:
- 如果传递给ext2_alloc_block()的首选块(目标块)是空闲的,就分配它。
- 如果目标为忙,就检查首选块后的其余块之中是否有空闲的块。
- 如果在首选块附近没有找到空闲块,就从包含目标的块组开始,查找所有的块组。对每个块组:
a. 寻找至少有8个相邻空闲块的一个组块。
b. 如果没有找到这样的一组块,就寻找一个单独的空闲块。只要找到一个空闲块,搜索就结束。在结束前,ext2_new_block()函数还尽力在找到的空闲块附近的块中找8个空闲块进行预分配,并把磁盘索引节点的i_prealloc_block 和i_prealloc_count字段置为适当的块位置及块数。
释放数据块
当进程删除一个文件或把它的长度截为0时,其所有数据块必须回收。这是通过调用ext2_truncate()函数(其参数是这个文件的索引节点对象的地址)来完成的。实际上,这个函数扫描磁盘索引节点的i_block数组,以确定所有数据块的位置和间接寻址用的块的位置。然后反复调用ext2_free_blocks()函数释放这些块。
ext2_free_blocks()函数释放一组含有一个或多个相邻块的数据块。除ext2_truncate()调用它外,当丢弃文件的预分配块时也主要调用它。函数参数如下:
- inode: 文件的索引节点对象的地址。
- block: 要释放的第一个块的逻辑块号。
- count: 要释放的相邻块数。
这个函数对每个要释放的块执行下列操作:
- 获得要释放块所在块组的块位图。
- 把块位图中要释放的块的对应位清0,并把位图所在的缓冲区标记为脏。
- 增加块组描述符的bg_free_blocks_count字段,并把相应的缓冲区标记为脏。
- 增加磁盘超级块的s_free_blocks_count字段,并把相应的缓冲区标记为脏,把超级块对象的s_dirt标记置位。
- 如果Ext2文件系统安装时设置了MS_SYNCHRONOUS标志,则调用sync_dirty_buffer()并等待,直到对这个位图缓冲区的写操作终止。
Ext3文件系统
在本节我们将简单描述从Ext2发展而来的增强型文件系统,即Ext3。这个新的文件系统在设计时曾秉持两个简单的概念:
- 成为一个日志文件系统
- 尽可能与原来的Ext2文件系统兼容
Ext3完全达到了这两个目标。尤其是,它很大程度上是基于Ext2的,因此,它在磁盘上的数据结构从本质上与Ext2文件系统的数据结构是相同的。事实上,如果Ext3文件系统已经被彻底卸载,那么就可以把它作为Ext2文件系统来重新安装;反之,创建Ext2 文件系统的日志并把它作为Ext3文件系统来重新安装,也是一种简单、快速的操作。
由于Ext3与Ext2之间的兼容性,本章前面几节的很多描述也适用于Ext3。因此,本节我们集中于Ext3所提供的新特点——“日志”。
日志文件系统
随着磁盘变得越来越大,传统Unix文件系统(像Ext2)的一种设计选择证明是不相称的。
对文件系统块的更新可能在内存保留相当长的时间后才刷新到磁盘。因此,像断电故障或系统崩溃这样不可预测的事件可能导致文件系统处于不一致状态。
为了克服这个问题,每个传统的Unix文件系统在安装之前都要进行检查;如果它没有被正常卸载,那么,就有一个特定的程序执行彻底、耗时的检查,并修正磁盘上文件系统的所有数据结构。
例如,Ext2文件系统的状态存放在磁盘上超级块的s_mount_state字段中。由启动脚本调用e2fsck实用程序检查存放在这个字段中的值;如果它不等于EXT2_VALID_FS,说明文件系统没有正常卸载,因此,e2fsck开始检查文件系统的所有磁盘数据结构。
显然,检查文件系统一致性所花费的时间主要取决于要检查的文件数和目录数;因此,它也取决于磁盘的大小。如今,随着文件系统达到几百个GB,一次一致性检查就可能花费数个小时。造成的停机时间对任何生产环境和高可用服务器都是无法接受的。
日志文件系统的目标就是避免对整个文件系统进行耗时的一致性检查,这是通过查看一个特殊的磁盘区达到的,因为这种磁盘区包含所谓日志(journal)的最新磁盘写操作。系统出现故障后,安装日志文件系统只不过是几秒钟的事。
Ext3日志文件系统
Ext3日志所隐含的思想就是对文件系统进行的任何高级修改都分两步进行。
- 首先,把待写块的一个副本存放在日志中;
- 其次,当发往日志的I/O数据传送完成时(简而言之,把数据提交到日志),块就被写入文件系统。当发往文件系统的I/O数据传送终止时(把数据提交给文件系统),日志中的块副本就被丢弃。(先写磁盘日志,再写磁盘文件系统)
当从系统故障中恢复时,e2fsck程序区分下列两种情况:
- 提交到日志之前系统故障发生。
与高级修改相关的块副本或者从日志中丢失,或者是不完整的;在这两种情况下,e2fsck都忽略它们。 - 提交到日志之后系统故障发生。
块的副本是有效的,且e2fsck把它们写入文件系统。
- 在第一种情况下,对文件系统的高级修改被丢失,但文件系统的状态还是一致的。
- 在第二种情况下,e2fsck应用于整个高级修改,因此,修正由于把未完成的I/O数据传送到文件系统而造成的任何不一致。
不要对日志文件系统有太多的期望。它只能确保系统调用级的一致性。
例如,当你正在发出几个write()系统调用拷贝一个大型文件时发生了系统故障,这将会使拷贝操作中断,因此,复制的文件就会比原来的文件短。因此,日志文件系统通常不把所有的块都拷贝到日志中。
事实上,每个文件系统都由两种块组成:包含所谓元数据(metadata)的块和包含普通数据的块。
在Ext2和Ext3的情形中,有六种元数据:超级块、块组描述符、索引节点、用于间接寻址的块(间接块),数据位图块和索引节点位图块。其他的文件系统可能使用不同的元数据。
很多日志文件系统(如SGI的XFS以及IBM的JFS)都限定自己把影响元数据的操作记入日志。
事实上,元数据的日志记录足以恢复磁盘文件系统数据结构的一致性。然而,因为文件的数据块不记入日志,因此就无法防止系统故障造成的文件内容的损坏。不过,可以把Ext3文件系统配置为把影响文件系统元数据的操作和影响文件数据块的操作都记入日志。因为把每种写操作都记入日志会导致极大的性能损失,因此,Ext3让系统管理员决定应当把什么记入日志;具体来说,它提供三种不同的日志模式:
- 日志(Journal): 文件系统所有数据和元数据的改变都被记入日志。这种模式减少了丢失每个文件修改的机会,但是它需要很多额外的磁盘访问。例如,当一个新文件被创建时,它的所有数据块都必须复制一份作为日志记录。这是最安全和最慢的Ext3日志模式。
- 预定(Ordered): 只有对文件系统元数据的改变才被记入日志。然而,Ext3文件系统把元数据和相关的数据块进行分组,以便在元数据之前把数据块写入磁盘。这样,就可以减少文件内数据损坏的机会;例如,确保增大文件的任何写访问都完全受日志的保护。这是缺省的Ext3日志模式。
写回(Writeback): 只有对文件系统元数据的改变才被记入日志;这是在其他日志文件系统中发现的方法,也是最快的模式。 - Ext3文件系统的日志模式由mount系统命令的一个选项来指定。例如,为了在/jdisk安装点对存放在/dev/sda2分区上的Ext3文件系统以“写回”模式进行安装,系统管理员可以键入如下命令.
mount -t ext3 -o data=writeback /dev/sda2 /jdisk日志块设备层
Ext3日志通常存放在名为.journal的隐藏文件中,该文件位于文件系统的根目录。Ext3文件系统本身不处理日志,而是利用所谓日志块设备(Journaling Block Device,JBD)的通用内核层。现在,只有Ext3使用JDB层,而其他文件系统可能在将来才使用它。
JDB层是相当复杂的软件部分。Ext3文件系统调用JDB例程,以确保在系统万一出现故障时它的后续操作不会损坏磁盘数据结构。然而,JDB典型地使用同一磁盘来把Ext3文件系统所做的改变记入日志,因此,它与Ext3一样易受系统故障的影响。换言之,JDB 也必须保护自己免受任何系统故障引起的日志损环。因此,Ext3与JDB之间的交互本质上基于三个基本单元:
- 日志记录: 描述日志文件系统一个磁盘块的一次更新。
- 原子操作处理: 包括文件系统的一次高级修改对应的日志记录;一般来说,修改文件系统的每个系统调用都引起一次单独的原子操作处理。
- 事务: 包括几个原子操作处理,同时,原子操作处理的日志记录对e2fsck标记为有效。
日志记录
日志记录(log record)本质上是文件系统将要发出的一个低级操作的描述。在某些日志文件系统中,日志记录只包括操作所修改的字节范围及字节在文件系统中的起始位置。然而,JDB层使用的日志记录由低级操作所修改的整个缓冲区组成。
这种方式可能浪费很多日志空间(例如,当低级操作仅仅改变位图的一个位时),但是,它还是相当快的,因为JBD层直接对缓冲区和缓冲区首部进行操作。因此,日志记录在日志内部表示为普通的数据块(或元数据)。但是,每个这样的块都是与类型为journal_block_tag_t的小标签相关联的,这种小标签存放块在文件系统中的逻辑块号和几个状态标志。随后,只要一个缓冲区得到JBD的关注,或者因为它属于日志记录,或者因为它是一个数据块,该数据块应当在相应的元数据之前刷新到磁盘(处于“预定”模式),那么,内核把journal_head数据结构加入到缓冲区首部。在这种情况下,缓冲区首部的b_private 字段存放journal_head数据结构的地址,并把BH_JBD标志置位。
原子操作处理
修改文件系统的任一系统调用通常都被划分为操纵磁盘数据结构的一系列低级操作。
例如,假定Ext3必须满足用户把一个数据块追加到普通文件的请求。文件系统层必须确定文件的最后一个块,定位文件系统中的一个空闲块,更新适当块组内的数据块位图,存放新块的逻辑块号在文件的索引节点或间接寻址块中,写新块的内容,并在最后更新索引节点的几个字段。你可以看到,追加操作转换为对文件系统数据块和元数据块很多低级的操作。现在,仅仅想象一下,如果在追加操作的中间一些低级操作已经执行,另一些还没有执行,而系统出现了故障会发生什么事情。当然,对于影响两个或多个文件的高级操作(例如,把文件从一个目录移到另一个目录),情况会更糟。为了防止数据损坏,Ext3文件系统必须确保每个系统调用以原子的方式进行处理。原子操作处理(atomic operation handle)是对磁盘数据结构的一组低级操作,这组低级操作对应一个单独的高级操作。当从系统故障中恢复时,文件系统确保要么整个高级操作起作用,要么没有一个低级操作起作用。
任何原子操作处理都用类型为handle_t的描述符来表示。为了开始一个原子操作,Ext3 文件系统调用journal_start() JBD函数,该函数在必要时分配一个新的原子操作处理并把它插入到当前的事务中。因为对磁盘的任何低级操作都可能挂起进程,因此,活动原子操作处理的地址存放在进程描述符的journal_info字段中。为了通知原子操作已经完成,Ext3文件系统调用journal_stop()函数。
事务
出于效率的原因,JBD层对日志的处理采用分组的方法,即把属于几个原子操作处理的日志记录分组放在一个单独的事务(transaction)中。此外,与一个处理相关的所有日志记录都必须包含在同一个事务中。一个事务的所有日志记录存放在日志的连续块中。JBD层把每个事务作为整体来处理。
例如,只有当包含在一个事务的日志记录中的所有数据都提交给文件系统时才回收该事务所使用的块。事务一旦被创建,它就能接受新处理的日志记录。当下列情况之一发生时,事务就停止接受新处理:
- 固定的时间已经过去,典型情况下为5s。
- 日志中没有空闲块留给新处理
- 事务是由类型为transaction_t的描述符来表示的。其最重要的字段为t_state,该字段描述事务的当前状态。
从本质上说,事务可以是:
完成的: 包含在事务中的所有日志记录都已经从物理上写入日志。当从系统故障中恢复时,e2fsck考虑日志中每个完成的事务,并把相应的块写入文件系统。在这种情况下,t_state字段存放值T_FINISHED。
未完成的: 包含在事务中的日志记录至少还有一个没有从物理上写入日志,或者新的日志记录还正在追加到事务中。在系统故障的情况下,存放在日志中的事务映像很可能不是最新的。因此,当从系统故障中恢复时,e2fsck不信任日志中未完成的事务,并跳过它们。在这种情况下,i_state存放下列值之一:
- T_RUNNING: 还在接受新的原子操作处理。
- T_LOCKED: 不接受新的原子操作处理,但其中的一些还没有完成。
- T_FLUSH: 所有的原子操作处理都已完成,但一些日志记录还正在写入日志。
- T_COMMIT: 原子操作处理的所有日志记录都已经写入磁盘,但在日志中,事务仍然被标记为完成。
在任何时刻,日志可能包含多个事务,但其中只有一个处于T_RUNNING状态,即它是活动事务(active transaction)。所谓活动事务就是正在接受由Ext3文件系统发出的新原子操作处理的请求。日志中的几个事务可能是未完成的,因为包含相关日志记录的缓冲区还没有写入日志。如果事务完成,说明所有日志记录已被写入日志,但是一部分相应的缓冲区还没有写入文件系统。只有当JDB层确认日志记录描述的所有缓冲区都已成功写入Ext3文件系统时,一个完成的事务才能从日志中删除。
日志如何工作
让我们用一个例子来试图解释日志如何工作:Ext3文件系统层接受向普通文件写一些数据块的请求。你可能很容易猜到,我们不打算详细描述Ext3文件系统层和JDB层的每个单独操作。那将会涉及太多问题!但是,我们描述本质的操作:
- write()系统调用服务例程触发与Ext3普通文件相关的文件对象的write方法。对于Ext3来说,这个方法是由generic_file_write()函数实现的。
- generic_file_write()函数几次调用address_space对象的prepare_write方法,写方法涉及的每个数据页都调用一次。对Ext3来说,这个方法是由ext3_prepare_write()函数实现的。
- ext3_prepare_write()函数调用journal_start() JBD函数开始一个新的原子操作。这个原子操作处理被加到活动事务中。实际上,原子操作处理是在第一次调用journal_start()函数时创建的。后续的调用确认进程描述符的journal_info字段已经被置位,并使用这个处理。
- ext3_prepare_write()函数调用第十六章已描述过的block_prepare_write()函数,传递给它的参数为ext3_get_block()函数的地址。回想一下,block_prepare_write()负责准备文件页的缓冲区和缓冲区首部。
- 当内核必须确定Ext3文件系统的逻辑块号时,就执行ext3_get_block()函数。这个函数实际上类似于ext2_get_block(),后者在前面“分配数据块”一节已经描述。但是,有一个主要的差异在于Ext3文件系统调用JDB层的函来确保低级操作记入日志:在对Ext3文件系统的元数据块发出低级写操作之前,该函数调用journal_get_write_access()。后一个函数主要把元数据缓冲区加入到活动事务的链表中。但是,它也必须检查元数据是否包含在日志的一个较老的未完成的事务中;在这种情况下,它把缓冲区复制一份以确保老的事务以老的内容提交。在更新元数据块所在的缓冲区之后,Ext3文件系统调用journal_dirty_metadata()把元数据缓冲区移到活动事务的适当脏链表中,并在日志中记录这一操作。注意,由JDB层处理的元数据缓冲区通常并不包含在索引节点的缓冲区的脏链表中,因此,这些缓冲区并不由第十五章描述的正常磁盘高速缓存的刷新机制写入磁盘。
- 如果Ext3文件系统已经以“日志”模式安装,则ext3_prepare_write()函数在写操作触及的每个缓冲区上也调用journal_get_write_access()。
- 控制权回到generic_file_write()函数,该函数用存放在用户态地址空间的数据更新页,并调用address_space对象的commit_write方法。对于Ext3,函数如何实现这个方法取决于Ext3文件系统的安装方式:
如果Ext3文件系统已经以“日志”模式安装,那么commit_write方法是由ext3_journalled_commit_write()函数实现的,它对页中的每个数据(不是元数据)缓冲区调用journal_dirty_metadata()。这样,缓冲区就包含在活动事务的适当脏链表中,但不包含在拥有者索引节点的脏链表中;此外,相应的日志记录写入日志。最后,ext3_journalled_commit_write()调用journal_stop通知JBD层原子操作处理已关闭。
如果Ext3文件系统已经以“预定”模式安装,那么commit_write方法是由ext3_ordered_commit_write()函数实现的,它对页中的每个数据缓冲区调用journal_dirty_data()函数以把缓冲区插入到活动事务的适当链表中。JDB层确保在事务中的元数据缓冲区写入之前这个链表中的所有缓冲区写入磁盘。没有日志记录写入日志。然后,ext3_ordered_commit_write()函数执行第十五章描述的常规generic_commit_write()函数,该函数把数据缓冲区插入拥有者索引节点的脏缓冲区链表中。最后,ext3_ordered_commit_write()调用journal_stop()通知JBD层原子操作处理已关闭。
如果Ext3文件系统已经以“写回”模式安装,那么commit_write方法是由ext3_writeback_commit_write()函数实现的,它执行第十五章描述的常规generic_commit_write()函数,该函数把数据缓冲区插入拥有者索引节点的脏缓冲区链表中。然后,ext3_writeback_commit_write()调用journal_stop()通知JBD层原子操作处理已关闭。
- write()系统调用的服务例程到此结束。但是,JDB层还没有完成它的工作。终于,当事务的所有日志记录都物理地写入日志时,我们的事务才完成。然后,执行journal_commit_transaction()。
- 如果Ext3文件系统已经以“预定”模式安装,则journal_commit_transaction()函数为事务链表包含的所有数据缓冲区激活I/O数据传送,并等待直到数据传送终止。
- journal_commit_transaction()函数为包含在事务中的所有元数据缓冲区激活I/O数据传送(如果Ext3以“日志”模式安装,则也为所有的数据缓冲区激活I/O数据传送)。
- 内核周期性地为日志中每个完成的事务激活检查点活动。检查点主要验证由journal_commit_transaction()触发的I/O数据传送是否已经成功结束。如果是,则从日志中删除事务。当然,除非发生系统故障,否则日志中的日志记录根本就没有什么积极作用。事实上,只有在系统发生故障时,e2fsck实用程序才扫描存放在文件系统中的日志,并重新安排完成的事务中的日志记录所描述的所有写操作。
I/O体系结构和设备驱动程序
I/O体系结构
为了确保计算机能够正常工作,必须提供数据通路,让信息在连接到个人计算机的CPU、RAM和I/O设备之间流动。这些数据通路总称为总线,担当计算机内部主通信通道的作用。
所有计算机都拥有一条系统总线,它连接大部分内部硬件设备。一种典型的系统总线是PCl(Peripheral Component Interconnect)总线。目前使用其他类型的总线也很多,例如ISA、EISA、MCA、SCSI和USB。典型的情况是,一台计算机包括几种不同类型的总线,它们通过被称作“桥”的硬件设备连接在一起。两条高速总线用于在内存芯片上来回传送数据:
前端总线将CPU连接到RAM控制器上,而后端总线将CPU直接连接到外部硬件的高速缓存上。主机上的桥将系统总线和前端总线连接在一起。
任何I/O设备有且仅能连接一条总线。总线的类型影响I/O设备的内部设计,也影响着内核如何处理设备。本节我们将讨论所有PC体系结构共有的功能性特点,而不具体介绍特定总线类型的技术细节。
CPU和I/O设备之间的数据通路通常称为I/O总线。
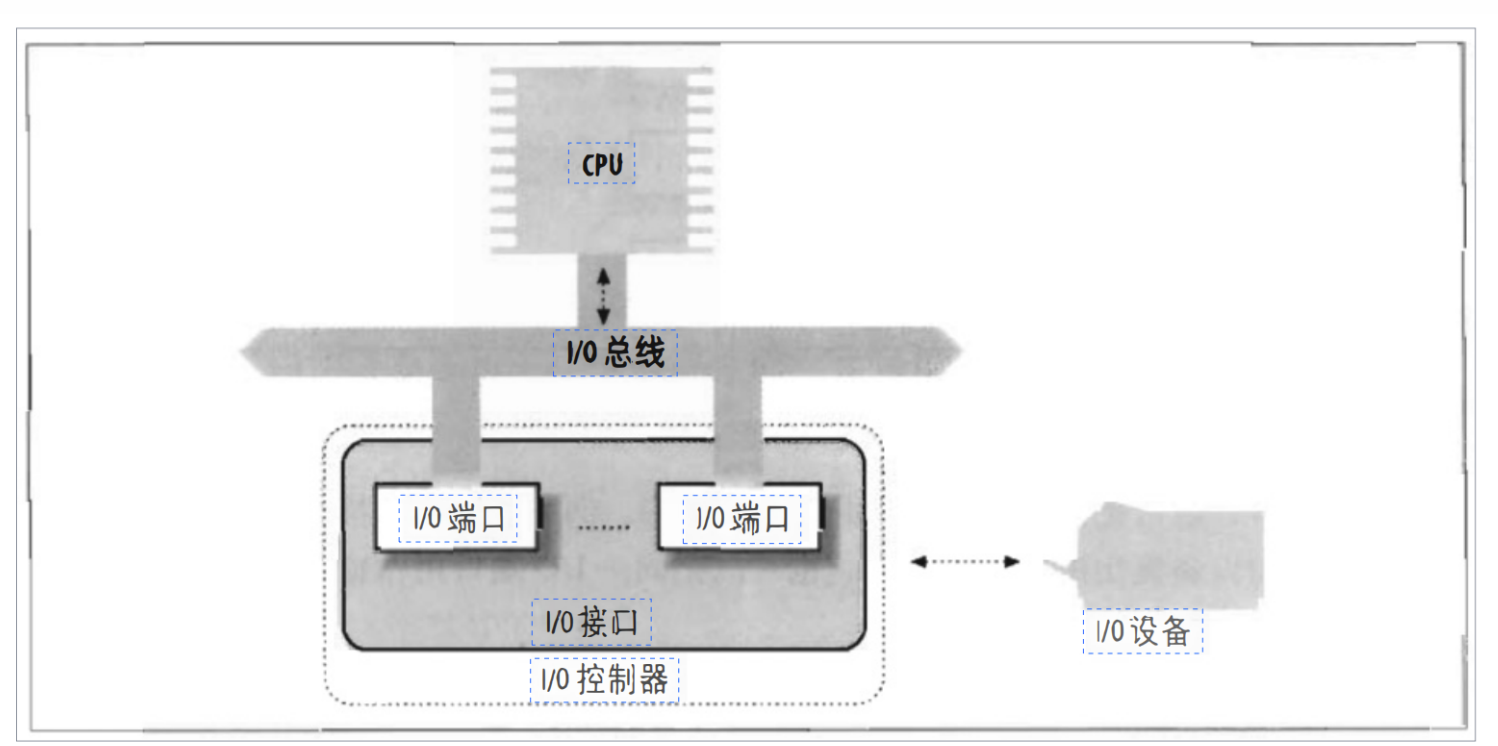
I/O端口
每个连接到I/O总线上的设备都有自己的I/O地址集,通常称为I/O端口(1/O port)。在IBM PC体系结构中,I/O地址空间一共提供了65536个8位的I/O端口。可以把两个连续的8位端口看成一个16位端口,但是这必须从偶数地址开始。同理,也可以把两个连续的I6位端口看成一个32位端口,但是这必须是从4的整数倍地址开始。
有四条专用的汇编语言指令可以允许CPU对I/O端口进行读写,它们是in、ins、out.和outs。在执行其中的一条指令时,CPU使用地址总线选择所请求的I/O端口,使用数据总线在CPU寄存器和端口之间传送数据。
I/O端口还可以被映射到物理地址空间。因此,处理器和I/O设备之间的通信就可以使用对内存直接进行操作的汇编语言指令(例如,mov、and、or等等)。现代的硬件设备更倾向于映射的I/O,因为这样处理的速度较快,并可以和DMA结合起来。
系统设计者的主要目的是对I/O编程提供统一的方法,但又不牺牲性能。为了达到这个目的,每个设备的I/O端口都被组织成如图13-2所示的一组专用寄存器。CPU把要发送给设备的命令写入设备控制寄存器(device control register),并从设备状态寄存器(device status register)中读出表示设备内部状态的值。CPU还可以通过读取设备输入寄存器(device input register)的内容从设备取得数据,也可以通过向设备输出寄存器(device output register)中写入字节而把数据输出到设备。
为了降低成本,通常把同一I/O端口用于不同目的。例如,某些位描述设备的状态,而其他位指定向设备发出的命令。同理,也可以把同一I/O端口用作输入寄存器或输出寄存器。
访问I/O端口
in、out、ins和outs汇编语言指令都可以访问I/O端口。内核中包含了以下辅助函数来简化这种访问:
- inb(),inw(),inl():分别从I/O端口读取1、2或4个连续字节。后缀“b”、“w”、“I”分别代表一个字节(8位)、一个字(16位)以及一个长整型(32位)。
- inb_p(),inw_p(),inl_p():分别从I/O端口读取1、2或4个连续字节,然后执行一条“哑元(dummy,即空指令)”指令使CPU暂停。
- outb(),outw(),outl():分别向一个I/O端口写入1、2或4个连续字节。
- outb_p(),outw_p(),outl_p():分别向一个I/O端口写入1、2或4个连续字节,然后执行一条“哑元”指令使CPU 暂停。
- insb(),insw(),insl():分别从I/O端口读取以1、2或4个字节为一组的连续字节序列。字节序列的长度由该函数的参数给出。
- outsb(),outsw(),outsl():分别向I/O端口写入以1、2或4个字节为一组的连续字节序列。
虽然访问I/O端口非常简单,但是检测哪些I/O端口已经分配给I/O设备可能就不这么简单了,对基于ISA总线的系统来说更是如此。通常,I/O设备驱动程序为了探测硬件设备,需要盲目地向某一I/O端口写入数据;但是,如果其他硬件设备已经使用了这个端口,那么系统就会崩溃。为了防止这种情况的发生,内核必须使用“资源”来记录分配给每个硬件设备的I/O端口。
资源(resource)表示某个实体的一部分,这部分被互斥地分配给设备驱动程序。在我们的情况中,一个资源表示I/O端口地址的一个范围。每个资源对应的信息存放在resource数据结构中,其字段如表13-1所示。所有的同种资源都插入到一个树型数据结构中;例如,表示I/O端口地址范围的所有资源都包含在一个根节点为ioport_resource 的树中。
节点的孩子被收集在一个链表中,其第一个元素由child指向。sibling字段指向链表中的下一个节点。为什么使用树?
例如,考虑一下IDE硬盘接口所使用的I/O端口地址——比如说从0xf000到0xf00f。然后,start字段为0xf000且end字段为0xf00f的这样一个资源包含在树中,控制器的常规名字存放在name字段中。但是,IDE设备驱动程序需要记住另外的信息,也就是IDE链(IDE chain)的主盘(master disk)使用0xf000~0xf007 的子范围,从盘(slave disk)使用0xf008~0xf00f的子范围。
为了做到这点,设备驱动程序把两个子范围对应的孩子插入到0xf000,0xf00f的整个范围对应的资源下。一般来说,树中的每个节点肯定相当于父节点对应范围的一个子范围。I/O端口资源树(ioport_resource)的根节点跨越了整个I/O地址空间(从端口0~65535)。
任何设备驱动程序都可以使用下面三个函数,传递给它们的参数为资源树的根节点和要插入的新资源数据结构的地址:
- request_resource():把一个给定范围分配给一个I/O设备。
- allocate_resource():在资源树中寻找一个给定大小和排列方式的可用范围;若存在,就将这个范围分配给一个I/O设备(主要由PCI设备驱动程序使用,这种驱动程序可以配置成使用任意的端口号和主板上的内存地址对其进行配置)。
- release_resource():释放以前分配给I/O设备的给定范围。
内核也为以上应用于I/O端口的函数定义了一些快捷函数:request_region()分配I/O 端口的给定范围,release_region()释放以前分配给I/O端口的范围。当前分配给I/O 设备的所有I/O地址的树都可以从/proc/ioports文件中获得。
I/O接口
I/O接口(1/0 interface)是处于一组I/O端口和对应的设备控制器之间的一种硬件电路。它起翻译器的作用,即把I/O端口中的值转换成设备所需要的命令和数据。在相反的方向上,它检测设备状态的变化,并对起状态寄存器作用的I/O端口进行相应的更新。还可以通过一条IRQ线把这种电路连接到可编程中断控制器上,以使它代表相应的设备发出中断请求。有两种类型的接口:
- 专用1/0接口:专门用于一个特定的硬件设备。在一些情况下,设备控制器与这种I/O接口处于同一块卡中。连接到专用I/O接口上的设备可以是内部设备(位于PC机箱内部的设备),也可以是外部设备(位于PC机箱外部的设备)。
- 通用I/O接口:用来连接多个不同的硬件设备。连接到通用I/O接口上的设备通常都是外部设备。
每块卡都要插入PC的一个可用空闲总线插槽中。如果一块卡通过一条外部电缆连接到一个外部设备上,那么在PC后面的面板中就有一个对应的连接器。
专用IO接口
专用I/O接口的种类很多,因此目前已装在PC上设备的种类也很多,我们无法一一列出,在此只列出一些最通用的接口:
- 键盘接口:连接到一个键盘控制器上,这个控制器包含一个专用微处理器。这个微处理器对按下的组合键进行译码,产生一个中断并把相应的键盘扫描码写入输入寄存器。
- 图形接口:和图形卡中对应的控制器封装在一起,图形卡有自己的帧缓冲区,还有一个专用处理器以及存放在只读存储器(ROM)芯片中的一些代码。帧缓冲区是显卡上固化的存储器,其中存放的是当前屏幕内容的图形描述。
- 磁盘接口:由一条电缆连接到磁盘控制器,通常磁盘控制器与磁盘放在一起。例如,IDE接口由一条40线的带形电缆连接到智能磁盘控制器上,在磁盘本身就可以找到这个控制器。
- 总线鼠标接口:由一条电缆把接口和控制器连接在一起,控制器就包含在鼠标中。
- 网络接口:与网卡中的相应控制器封装在一起,用以接收或发送网络报文。虽然广泛采用的网络标准很多,但还是以太网(IEEE 802.3)最为通用。
通用IO接口
现代PC都包含连接很多外部设备的几个通用I/O接口。最常用的接口有:
- 并口:传统上用于连接打印机,它还可以用来连接可移动磁盘、扫描仪、备份设备、其他计算机等等。数据的传送以每次1字节(8位)为单位进行。
- 串口:与并口类似,但数据的传送是逐位进行的。串口包括一个通用异步收发器(UART)芯片,它可以把要发送的字节信息拆分成位序列,也可以把接收到的位流重新组装成字节信息。由于串口本质上速度低于并口,因此主要用于连接那些不需要高速操作的外部设备,如调制解调器、鼠标以及打印机。
- CMCIA接口:大多数便携式计算机都包含这种接口。在不重新启动系统的情况下,这种形状类似于信用卡的外部设备可以被插入插槽或从插槽中拔走。最常用的PCMCIA设备是硬盘、调制解调器、网卡和扩展RAM。
- SCSI(小型计算机系统接口)接口:是把PC主总线连接到次总线(称为SCSI总线)的电路。SCSI-2总线允许一共8 个PC和外部设备(硬盘、扫描仪、CR-ROM刻录机等等)连接在一起。如果有附加接口,宽带SCSI-2和新的SCSI-3接口可以允许你连接多达16个以上的设备。SCSI标准是通过SCSI总线连接设备的通信协议。
- 通用串行总线(USB):高速运转的通用I/O接口,可用于连接外部设备,代替传统的并口、串口以及SCSI接口。
设备控制器
复杂的设备可能需要一个设备控制器(device controller)来驱动。从本质上说,控制器起两个重要作用:
- 对从I/O接口接收到的高级命令进行解释,并通过向设备发送适当的电信号序列强制设备执行特定的操作。
- 对从设备接收到的电信号进行转换和适当地解释,并修改(通过I/O接口)状态寄存器的值。
典型的设备控制器是磁盘控制器,它从微处理器(通过I/O接口)接收诸如“写这个数据块”之类的高级命令,并将其转换成诸如“把磁头定位在正确的磁道上”和“把数据写入这个磁道”之类的低级磁盘操作。现代的磁盘控制器相当复杂,因为它们可以把磁盘数据快速保存到内存的高速缓存中,还可以根据实际磁盘的几何结构重新安排CPU的高级请求,使其最优化。
比较简单的设备没有设备控制器,可编程中断控制器和可编程间隔定时器就是这样的设备。很多硬件设备都有自己的存储器,通常称之为I/O共享存储器。例如,所有比较新的图形卡在帧缓冲区中都有几MB的RAM,用它来存放要在屏幕上显示的屏幕映像。
设备驱动程序模型
Linux内核的早期版本为设备驱动程序的开发者提供微不足道的基本功能:分配动态内存,保留I/O地址范围或中断请求(IRQ),激活一个中断服务例程来响应设备的中断。事实上,在更老的硬件设备上编程棘手而困难重重,还有即使两种不同的硬件设备连在同一条总线上,但二者也很少有共同点。因此,试图为这种硬件设备的驱动程序开发者提供一种统一的模型是难以做到的。
现在的情形大不一样。诸如PCI这样的总线类型对硬件设备的内部设计提出了强烈的要求;因此,新的硬件设备即使类型不同但也有相似的功能。对这种设备的驱动程序应当特别关注:
- 电源管理(控制设备电源线上不同的电压级别)
- 即插即用(配置设备时透明的资源分配)
- 热插拔(系统运行时支持设备的插入和移走)
系统中所有硬件设备由内核全权负责电源管理。而且,硬件设备必须按准确的顺序进人“待机”状态,否则一-些设备可能会处于错误的电源状态。例如,内核必须首先将硬盘置于“待机”状态,然后才是它们的磁盘控制器,因为若按照相反的顺序执行,磁盘控制器就不能向硬盘发送命令。
为了实现这些操作,Linux 2.6提供了一些数据结构和辅助函数,它们为系统中所有的总线、设备以及设备驱动程序提供了一个统一的视图;这个框架被称为设备驱动程序模型。
sysfs文件系统
sysfs文件系统是一种特殊的文件系统。/proc 文件系统是首次被设计成允许用户态应用程序访问内核内部数据结构的一种文件系统。/sysfs文件系统本质上与/proc有相同的目的,但是它还提供关于内核数据结构的附加信息;此外,/sysfs的组织结构比/proc更有条理。或许,在不远的将来,/proc和/sysfs将会继续共存。sysfs文件系统的目标是要展现设备驱动程序模型组件间的层次关系。该文件系统的相应高层目录是:
- block:块设备,它们独立于所连接的总线。
- devices:所有被内核识别的硬件设备,依照连接它们的总线对其进行组织。
- bus:系统中用于连接设备的总线。
- drivers:在内核中注册的设备驱动程序。
- class:系统中设备的类型(声卡、网卡、显卡等等);同一类可能包含由不同总线连接的设备,于是由不同的驱动程序驱动。
- power:处理一些硬件设备电源状态的文件。
- firmware:处理一些硬件设备的固件的文件。
sysfs文件系统中所表示的设备驱动程序模型组件之间的关系就像目录和文件之间符号链接的关系一样。例如,文件/sys/block/sda/device可以是一个符号链接,指向在/sys/devices/pci0000:00(表示连接到PCI总线的SCSI控制器)中嵌入的一个子目录。此外,文件/sys/block/sda/device/block是到目录/sys/block/sda的一个符号链接,这表明这个PCI设备是SCSI磁盘的控制器。
sysfs文件系统中普通文件的主要作用是表示驱动程序和设备的属性。例如,位于目录/sys/block/hda下的dev文件含有第一个IDE链主磁盘的主设备号和次设备号。
kobject
设备驱动程序模型的核心数据结构是一个普通的数据结构,叫做kobject,它与sysfs文件系统自然地绑定在一起:每个kobject对应于sysfs文件系统中的一个目录。kobject被嵌入一个叫做“容器”的更大对象中,容器描述设备驱动程序模型中的组件。容器的典型例子有总线、设备以及驱动程序的描述符;例如,第一个IDE磁盘的第一个分区描述符对应于/sys/block/hda/hdal目录。将一个kobject嵌入容器中允许内核:
- 为容器保持一个引用计数器。
- 维持容器的层次列表或组(例如,与块设备相关的sysfs目录为每个磁盘分区包含一个不同的子目录)。
- 为容器的属性提供一种用户态查看的视图。
kobject、kset和subsystem每个kobject由kobject数据结构描述,其各字段如表13-2所示。
name: 用来表示内核对象的名称,如果该内核对象加入到系统,那么它的name就会出现在sys目录下。
entry: 用来将一系列的内核对象kobject连接成链表
parent: 用来指向该内核对象的上层节点,从而可以实现内核对象的层次化结构
kset: 用来执行内核对象所属的kset。kset对象用来容纳一系列同类型的kobject
ktype: 用来定义该内核对象的sys文件系统的相关操作函数和属性。
sd: 用来表示该内核对象在sys文件系统中的目录项实例
kref: 其核心是原子操作变量,用来表示该内核对象的引用计数。
state_initialized: 用来表示该内核对象的初始化状态,1表示已经初始化,0表示未初始化。
state_in_sysfs: 用来表示该内核对象是否在sys中已经存在。
state_add_uevent_sent: 用来表示该内核对象是否向用户空间发送了ADD uevent事件
state_remove_uevent_sent:用来表示该内核对象是否向用户空间发送了Remove uevent事件
uevent_suppress: 用来表示该内核对象状态发生改变时,时候向用户空间发送uevent事件,1表示不发送。
ktype字段指向kobj_type对象,该对象描述了kobject的“类型” ——本质上,它描述的是包括kobject的容器的类型。kobj_type数据结构包括三个字段:release方法(当kobject被释放时执行),指向sysfs操作表的sysfs_ops指针以及sysfs文件系统的缺省属性链表。
kref字段是一个k_ref类型的结构,它仅包括一个refcount字段。顾名思义,这个字段就是kobject的引用计数器,但它也可以作为kobject容器的引用计数器。kobject_get()和kobject_put()函数分别用于增加和减少引用计数器的值;如果该计数器的值等于0,就会释放kobject使用的资源,并且执行kobject的类型描述符kobj_type对象的release 方法。该方法用于释放容器本身,通常只有在动态地分配kobject容器时才定义该方法。通过kset数据结构可将kobjects组织成一棵层次树。
kset是同类型kobject结构的一个集合体——也就是说,相关的kobject包含在同类型的容器中。kset数据结构的字段如表13-3所示。
/**
* struct kset - a set of kobjects of a specific type, belonging to a specific subsystem.
*
* A kset defines a group of kobjects. They can be individually
* different "types" but overall these kobjects all want to be grouped
* together and operated on in the same manner. ksets are used to
* define the attribute callbacks and other common events that happen to
* a kobject.
*
* list: the list of all kobjects for this kset
* list_lock: a lock for iterating over the kobjects
* kobj: the embedded kobject for this kset (recursion, isn't it fun...)
* uevent_ops: the set of uevent operations for this kset. These are
* called whenever a kobject has something happen to it so that the kset
* can add new environment variables, or filter out the uevents if so
* desired.
*/
struct kset {
struct list_head list;//该kset上的kobject链表
spinlock_t list_lock;
struct kobject kobj;//内嵌的kobject
const struct kset_uevent_ops *uevent_ops;//该kset的uevent操作函数集。当任何Kobject需要上报uevent时,都要调用它所从属的kset的uevent_ops,添加环境变量,或者过滤event(kset可以决定哪些event可以上报)。因此,如果一个kobject不属于任何kset时,是不允许发送uevent的。
}; kobj字段是嵌入在kset数据结构中的kobject;而位于kset中的kobject,其parent字段指向这个内嵌的kobject结构。因此,一个kset就是kobject集合体,但是它依赖于层次树中用于引用计数和连接的更高层kobject。这种设计编码效率很高,并可获得最大的灵活性。例如,分别用于增加和减少kset引用计数器值的kset_get()函数和kset_put()函数,只需简单地调用内嵌的kobject结构中的kobject_get()函数和kobject_put()函数;因为kset的引用计数器只不过是内嵌在kset中的类型为kobject 的kobj的引用计数器。而且,由于有了内嵌的kobject结构,kset数据结构可以嵌入到“容器”对象中,非常类似于嵌入的kobject数据结构。最后,kset可以作为其他kset的一个成员:它足以将内嵌的kobject插入到更高层次的kset中。还存在所谓subsystem的kset集合。一个subsystem可以包括不同类型的kset,用包含两个字段的subsystem数据结构来描述:
- kset:内嵌的kset结构,用于存放subsystem中的kset。
- rwsem:读写信号量,保护递归地包含于subsystem中的所有kset和kobject。
subsystem数据结构甚至也可以嵌入到一个更大的“容器”对象中;因此,容器的引用计数器也是内嵌subsystem的引用计数器——也就是嵌入在subsystem中的kset所嵌的kobject的引用计数器。subsys_get()和subsys_put()函数分别用于增加和减少这个引用计数器的值。
图13-3显示了设备驱动程序模型层次的一个例子。bus子系统包括一个pci子系统,pci 子系统又依次包含驱动程序的一个kset。这个kset包含一个串口kobject(具有唯一new-id属性的串口对应的设备驱动器程序)。
注册kobject、kset和subsystem
一般来说,如果想让kobject、kset或subsystem出现在sysfs子树中,就必须首先注册它们。与kobject对应的目录总是出现在其父kobject的目录中。例如,位于同一个kset中的kobject的目录出现在kset本身的目录中。因此,sysfs子树的结构就描述了各种已注册的kobject之间以及各种容器对象之间的层次关系。
通常,sysfs文件系统的上层目录肯定是已注册的subsystem。kobject_register()函数用于初始化kobject,并且将其相应的目录增加到sysfs文件系统中。在调用此函数之前,调用程序应该先设置kobject结构中的kset字段,使它指向其父kset(如果有的话)。kobject_unregister()函数则将kobject的目录从sysfs文件系统中移走。为了更易于内核开发者进行开发,Linux也提供了kset_register()和kset_unregister()函数,以及subsystem_register()subsystem_unregister()函数,但本质上它们是围绕kobject_register()和kobject_unregister()的封装函数。
如前所述,许多kobject目录都包括称作属性(attribute)的普通文件。sysfs_create_file()函数接收kobject的地址和属性描述符作为它的参数,并在合适的目录中创建特殊文件。sysfs文件系统中所描述的对象间的其他关系可以通过符号链接的方式来建立:sysfs_create_link()函数为目录中与其他kobject相关联的特定kobject创建一个符号链接。
设备驱动程序模型的组件
设备驱动程序模型建立在几个基本数据结构之上,这些结构描述了总线、设备、设备驱动器等等。让我们来考察一下它们。
设备
设备驱动程序模型中的每个设备是由一个device对象来描述的,其字段如表13-4所示。
- device 结构体 - 设备驱动模型中的基础结构体之一
- parent: 设备所依附的“父设备”。
- 大多数情况下,这样的父设备是某种总线或主控制器。
- 如果该成员变量的值为 NULL 表示当前设备是一个最“顶端”设备,
- 通常这样的设备都不是你想得到的那个。
- p: 该成员变量是一个指向设备结构体中驱动内核部分的私有数据的指针。
- 更详细的信息可以阅读 device_private 结构体的注释。
- kobj: kobj是最“顶层”的抽象类,所有其它的类都继承自它。
- init_name: 设备结构体所对应的设备的名称。
- type: 设备结构体所对应的设备的类型。
- 该成员变量用于标识设备类型,并存储着该类型设备特有的信息。
- mutex: 用于同步驱动中的函数调用的互斥锁。
- bus: 设备所挂接的总线的类型。
- driver: 该成员变量指向开辟当前设备结构体空间的设备驱动。
- platform_data: 该成员变量用于保存和设备硬件相关的平台数据。
- 示例:对于自定义电路板上的设备来说,典型的情况譬如嵌入式设备
- 以及一些基于 SOC 的硬件,Linux 系统通常会使用 platform_data 指针指向
- 与电路板硬件相关的结构体,这些结构体中的成员描述了它们对应的设备硬件资源
- 以及电路板的电路连接情况。这些被描述的内容可以包括芯片的哪些端口可用,与
- 上一代芯片相比有什么改动,哪个 GPIO 引脚有额外的功能等等。
- 这个成员变量的实现使得 BSP 的工作量减小了许多,
- 同时也减少了我们为兼容不同的电路板而写的 #ifdefs 语句的数量。
- driver_data: 指向驱动特定信息的私有指针。
- power: 用于设备的电源管理。
- 更详细的信息可以阅读 Documentation/power/devices.txt 文档。
- pm_domain: 为设备提供当系统被挂起、
- 休眠、唤醒和电源状态切换时的回调函数,
- 以及子系统级别和驱动级别的回调函数。
- pins: 用于设备引脚管理。
- 更详细的信息可以阅读 Documentation/pinctrl.txt 文档。
- msi_list: 主机 MSI 描述符。
- msi_domain: 设备结构体所使用的 MSI 域。
- numa_node: 与设备结构体最邻近的 NUMA 节点。
- dma_mask: DMA掩码(前提是当前设备可进行 DMA 操作)。
- coherent_dma_mask: 作用和 dma_mask 类似,用于一致性 DMA 地址映射。因为并不是所有
- 硬件都支持在 64 位地址下开辟连续的内存空间。
- dma_pfn_offset: DMA区域范围在内存中的地址偏移量。
- dma_parms: 一个低权限级别的驱动会通过这个成员变量告知 IOMMU 代码关于
- 段操作限制相关的规则。
- dma_pools: 指向 DMA池 的指针(前提是当前设备可进行 DMA 操作)。
- dma_mem: 一致性 DMA 的可读写区域。
- cma_area: DMA区域中的连续内存空间。
- archdata: 芯片架构相关的内容。
- of_node: 设备所在设备树的节点。
- fwnode: 平台固件对应的设备树节点。
- devt: 用于在 sysfs 中创建设备文件。
- id: 设备实例(ID 编号)。
- devres_lock: 用于保护设备上的资源访问的自旋锁。
- devres_head: 设备上的资源列表。
- knode_class: 用于将当前设备加入到类列表的节点。
- class: 设备所属的类。
- groups: 设备的属性集合(可选)。
- release: 当设备的引用计数减少为 0 时,使用该成员变量所指向的析构函数
- 释放当前设备结构体。这个成员变量的值应该由当前设备的创建者进行
- 设置(比如成功找到设备的总线驱动)。
- iommu_group: 设备所属的 IOMMU 集合。
- offline_disabled: 如果这个成员变量的值被置 1,则设备将处于永远在线状态。
- offline: 如果总线类型所辖的 offline() 函数被成功调用,则该成员变量的值将被置 1。
device对象全部收集在devices_subsys子系统中,该子系统对应的目录为/sys/devices 。设备是按照层次关系组织的:一个设备是某个“孩子”的“父亲”,其条件为子设备离开父设备无法正常工作。例如,在基于PCI总线的计算机上,位于PCI总线和USB总线之间的桥就是连接在USB总线上的所有设备的父设备。device对象的parent字段是指向其父设备描述符的指针,children字段是子设备链表的首部,而node字段存放指向children链表中相邻元素的指针。device对象中内嵌的kobject间的亲子关系也反映了设备的层次关系;因此,/sys/devices下的目录结构与硬件设备的物理组织是匹配的。
每个设备驱动程序都保持一个device对象链表,其中链接了所有可被管理的设备;device对象的driver_list字段存放指向相邻对象的指针,而driver字段指向设备驱动程序的描述符。此外,对于任何总线类型来说,都有一个链表存放连接到该类型总线上的所有设备;device对象的bus_list字段存放指向相邻对象的指针,而bus字段指向总线类型描述符。
引用计数器记录device对象的使用情况,它包含在kobject类型的kobj结构中,通过调用get_device()和put_device()函数分别增加和减少该计数器的值。
device_register()函数的功能是往设备驱动程序模型中插入一个新的device对象,并自动地在/sys/devices目录下为其创建一个新的目录。相反地,device_unregister()函数的功能是从设备驱动程序模型中移走一个设备。通常,device对象被静态地嵌入到一个更大的描述符中。例如,PCI设备是由数据结构pci_dev描述;该数据结构的dev字段就是一个device对象,而其他字段则是PCI总线所特有的。在PCI内核层上,当注册或注销设备时就会分别执行device_register()函数和device_unregister()函数。
驱动程序
设备驱动程序模型中的每个驱动程序都可由device_driver对象描述,其各字段如表13-5所示。
- name 设备驱动程序的名称
- bus 指向总线描述符的指针,总线连接所支持的设备
- unload_sem 禁止卸载设备驱动程序的信号量,当引用计数器的值为0时释放该信号量
- kobj 内嵌的kobject结构
- devices 驱动程序支持的所有设备组成的链表的首部
- owner 标识实现设备驱动程序的模块,如果有的话
- probe 探测设备的方法(检验设备驱动程序是否 可以控制该设备)
- remove 移走设备时所调用的方法
- shutdown 设备断电(关闭)时所调用的方法
- suspend 设备置于低功率状态时所调用的方法
- resume 设备恢复正常状态时所调用的方法
device_driver对象包括四个方法,它们用于处理热插拔、即插即用和电源管理。当总线设备驱动程序发现一个可能由它处理的设备时就会调用probe方法;相应的函数将会探测该硬件,从而对该设备进行更进一步的检查。当移走一个可热插拔的设备时驱动程序会调用remove方法;而驱动程序本身被卸载时,它所处理的每个设备也会调用remove方法。当内核必须改变设备的供电状态时,设备会调用shutdown、suspend和resume三个方法。
内嵌在描述符中的kobject类型的kobj所包含的引用计数器用于记录device_driver对象的使用情况。通过调用get_driver()函数和put_driver()函数可分别增加和减少该计数器的值。driver_register()函数的功能是往设备驱动程序模型中插入一个新的device_driver 对象,并自动地在sysfs文件系统下为其创建一个新的目录。相反,driver_unregister()函数的功能则是从设备驱动程序模型中移走一个设备驱动对象。通常,device_driver对象静态地被嵌入到一个更大的描述符中。例如,PCI设备驱动程序是由数据结构pci_driver描述的;该数据结构的driver字段是一个device_driver 对象,而其他字段则是PCI总线所特有的。
总线
内核所支持的每一种总线类型都由一个bus_type对象描述,其各字段如表13-6所示。
- name总线类型的名称
- subsys与总线类型相关的 kobject 子系统
- drivers 驱动程序的kobject 集合
- devices 设备的kobject集合
- bus_attrs 指向对象的指针,该对象包含总线属 性和用于导出此属性到
- sysfs 文件系统的方法
- dev_attrs 指向对象的指针,该对象包含设备属 性和用于导出此属性到 sysfs 文件系 统的方法
- drv_ attrs 指问对象的指针,该对象包含设备驱动程序属性和用于导出此属性到 sysfs文件系统的方法
- match 检验给定的设备驱动程序是否支持特定设备的方法
- hotplug 注册设备时调用的方法
- suspend 保存硬件设备的上下文状态并改变设备供电状态的方法
- resume 改变供电状态和恢复硬件设备上下文的方法
每个bus_type类型的对象都包含一个内嵌的子系统;存放于bus_subsys变量中的子系统把嵌入在bus_type对象中的所有子系统都集合在一起。bus_subsys子系统与目录/sys/bus是对应的;因此,例如,有一个/sys/bus/pci目录,它与PCI总线类型相对应。每种总线的子系统通常包括两个kset,它们是drivers和devices(分别对应于bus_type 对象中的drivers和devices字段)。
名为drivers的kset包含描述符device_driver,它描述与该总线类型相关的所有设备驱动程序,而名为devices的kset包含描述符device,它描述给定总线类型上连接的所有设备。因为设备的kobject目录已经出现在/sys/devices下的sysfs文件系统中,所以每种总线子系统的devices目录存放了指向/sys/devices下目录的符号链接。bus_for_each_drv()和bus_for_each_dev()函数分别用于循环扫描drivers和devices 链表中的所有元素。当内核检查一个给定的设备否可以由给定的驱动程序处理时,就会执行match方法。对于连接设备的总线而言,即使其上每个设备的标识符都拥有一个特定的格式,实现match方法的函数通常也很简单,因为它只需要在所支持标识符的驱动程序表中搜索设备的描述符。在设备驱动程序模型中注册某个设备时会执行hotplug方法;实现函数应该通过环境变量把总线的具体信息传递给用户态程序,以通告一个新的可用设备。最后,当特定类型总线上的设备必须改变其供电状态时,就会执行suspend和resume方法。
类
每个类是由一个class对象描述的。所有的类对象都属于与/sys/class目录相对应的class_subsys子系统。此外,每个类对象还包括一个内嵌的子系统;因此,例如有一个/sys/class/input目录,它就与设备驱动程序模型的input类相对应。每个类对象包括一个class_device描述符链表,其中每个描述符描述了一个属于该类的单独逻辑设备。class_device结构中包含一个dev字段,它指向一个设备描述符,因此一个逻辑设备总是对应于设备驱动程序模型中的一个给定的设备。然而,可以存在多个class_device描述符对应同一个设备。事实上,一个硬件设备可能包括几个不同的子设备,每个子设备都需要一个不同的用户态接口。
例如,声卡就是一个硬件设备,它通常包括一个DSP(digital singnal processor,数字信号处理器)、一个混音器、一个游戏端口接口等等;每个子设备需要一个属于自己的用户态接口,因此sysfs文件系统中都有与它们相对应的目录。同一类中的设备驱动程序可以对用户态应用程序提供相同的功能;
例如,声卡上的所有设备驱动程序都提供一个可以向DSP中写入声音样本的方法。设备驱动程序模型中的类本质上是要提供一个标准的方法,从而为向用户态应用程序导出逻辑设备的接口。每个class_device描述符中内嵌一个kobject,这是一个名为dev 的属性(特殊文件)。该属性存放设备文件的主设备号和次设备号,通过它们可以访问相应的逻辑设备。
设备文件
正如在第一章中所提到的那样,类Unix操作系统都是基于文件概念的,文件是由字节序列而构成的信息载体。根据这一点,可以把I/O设备当作设备文件(device file)这种所谓的特殊文件来处理;因此,与磁盘上的普通文件进行交互所用的同一系统调用可直接用于I/O设备。
例如,用同一write()系统调用既可以向普通文件中写入数据,也可以通过向/dev/lp0设备文件中写入数据从而把数据发往打印机。根据设备驱动程序的基本特性,设备文件可以分为两种:块和字符。这两种硬件设备之间的差异并不容易划分,但我们至少可以假定以下的差异:
- 块设备的数据可以被随机访问,而且从人类用户的观点看,传送任何数据块所需的时间都是较少且大致相同的。块设备的典型例子是硬盘、软盘、CD-ROM驱动器及DVD播放器。
- 字符设备的数据或者不可以被随机访问(考虑声卡这样的例子),或者可以被随机访问,但是访问随机数据所需的时间很大程度上依赖于数据在设备内的位置(考虑磁带驱动器这样的例子)。
网卡是这种模式的一种明显的例外,因为网卡是不直接与设备文件相对应的硬件设备。自从Unix操作系统早期版本以来,设备文件就一直在使用。设备文件是存放在文件系统中的实际文件。然而,它的索引节点并不包含指向磁盘上数据块(文件的数据)的指针,因为它们是空的。相反,索引节点必须包含硬件设备的一个标识符,它对应字符或块设备文件。传统上,设备标识符由设备文件的类型(字符或块)和一对参数组成。第一个参数称为主设备号(major number),它标识了设备的类型。通常,具有相同主设备号和类型的所有设备文件共享相同的文件操作集合,因为它们是由同一个设备驱动程序处理的。第二个参数称为次设备号(minor number),它标识了主设备号相同的设备组中的一个特定设备。例如,由相同的磁盘控制器管理的一组磁盘具有相同的主设备号和不同的次设备号。
mknod()系统调用用来创建设备文件。其参数有设备文件名、设备类型、主设备号及次设备号。设备文件通常包含在/dev目录中。表13-7显示了一些设备文件的属性。注意字符设备和块设备有独立的编号,因此,块设备(3, 0)不同于字符设备(3, 0)。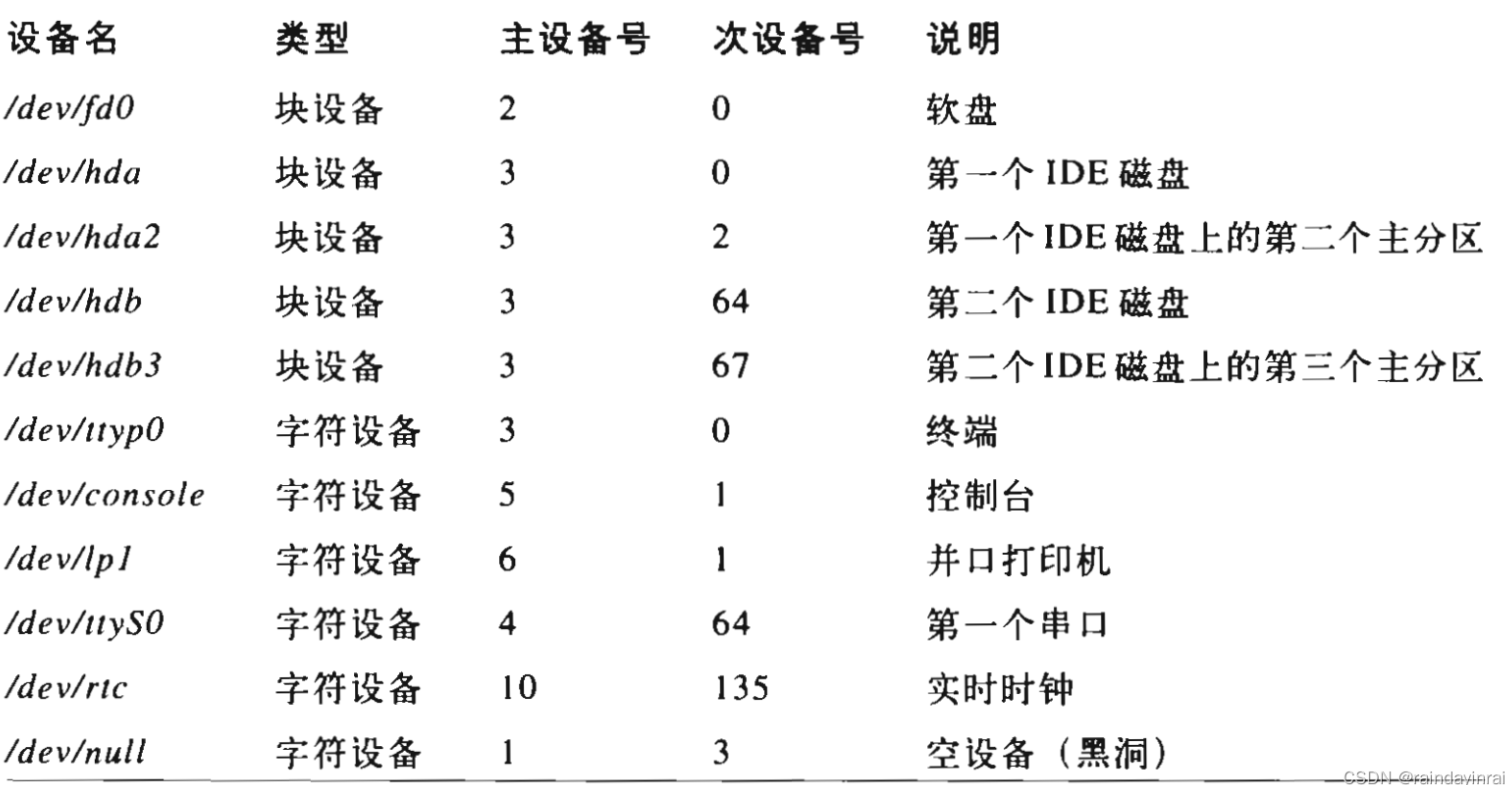
设备文件通常与硬件设备(如硬盘/dev/hda),或硬件设备的某一物理或逻辑分区(如磁盘分区/dev/hda2)相对应。但在某些情况下,设备文件不会和任何实际的硬件对应,而是表示一个虚拟的逻辑设备。例如,/dev/null就是一个和“黑洞”对应的设备文件,所有写入这个文件的数据都被简单地丢弃,因此,该文件看起来总为空。
就内核所关心的内容而言,设备文件名是无关紧要的。如果你建立了一个名为/mp/disk 的设备文件,类型为“块”,主设备号是3,次设备号是0,那么这个设备文件就和表13-7 中的/dev)hda等价。另一方面,对某些应用程序来说,设备文件名可能就很有意义。例如,通信程序可能假设第一个串口和/dev/ttyS0设备文件对应。但是,通常可以把大部分应用程序设定为随意地与指定的设备文件进行交互。
设备文件的用户态处理
传统的Unix系统中(以及Linux的早期版本中),设备文件的主设备号和次设备号都是8位长。因此,最多只能有65536个块设备文件和65536个字符设备文件。你可能认为这些已经足够了,但遗憾的是它们并不够用。真正的问题是设备文件被分配一次且永远保存在/dev目录中;因此,系统中的每个逻辑设备都应该有一个与其相对应的、明确定义了设备号的设备文件。Documentation/devices.txt文件存放了官方注册的已分配设备号和/dev目录节点;include /linux/major.h文件也可能包含设备的主设备号对应的宏。
不幸的是,如今各种不同的硬件设备数量惊人,几乎分配了所有的设备号。官方注册的设备号对于一般的Linux系统还能胜任;然而,它却不能很好地适用于大规模的系统。此外,高端系统可能使用数百或数千的同类型磁盘,因而8位的次设备号是远远不够的。
例如,注册表为16个SCSI磁盘保留了设备号,而每个SCS[磁盘拥有15个分区;如果一个高端系统拥有多于16个的SCSI磁盘,那么必须改变原先主设备号和次设备号的标准分配——这是一个非常繁琐的工作,它需要改变内核源代码并且使得系统难以维护。
为了解决上述问题,Linux 2.6已经增加了设备号的编码大小:目前主设备号的编码为12位,次设备号的编码为20位。通常把这两个参数合并成一个32位的dev_t变量MAJOR宏和MINOR宏可以从dev_t中分别提取主设备号和次设备号,而MKDEV宏可以把主设备号和次设备号合并成一个dev_t值。为了实现向后兼容,内核仍然可以正确地处理设备号编码为16位的老式设备文件。官方注册表不能静态地分配这些附加的可用设备号,只有在处理设备号的特殊要求时才允许使用。事实上,对分配设备号和创建设备文件来说,如今更倾向的做法是高度动态地处理设备文件。
动态分配设备号
每个设备驱动程序在注册阶段都会指定它将要处理的设备号范围。然而,驱动程序可以只指定设备号的分配范围,无需指定精确的值:在这种情形下,内核会分配一个合适的设备号范围给驱动程序。
因此,新的硬件设备驱动程序不再需要从官方注册表中分配的一个设备号;它们可以仅仅使用当前系统中空闲的设备号。然而,在这种情形下,就不能永久性地创建设备文件;它只在设备驱动程序初始化一个主设备号和次设备号时才创建。因此,这就需要有一个标准的方法将每个驱动程序所使用的设备号输出到用户态应用程序中。
动态创建设备文件
Linux内核可以动态地创建设备文件:它无需把每一个可能想到的硬件设备的设备文件都填充到/dev目录下,因为设备文件可以按照需要来创建。
由于设备驱动程序模型的存在,Linux 2.6内核提供了一个非常简单的方法来处理这个问题。系统中必须安装一组称为udev工具集的用户态程序。当系统启动时,/dev目录是清空的,这时udev程序将扫描/sys/class子目录来寻找dev文件。对每一个这样的文件(主设备号和次设备号的组合表示一个内核所支持的逻辑设备文件),udev程序都会在/dev目录下为它创建一个相应的设备文件。
udev程序也会根据配置文件为其分配一个文件名并创建一个符号链接,该方法类似于Unix设备文件的传统命名模式。最后,/dev目录里只存放了系统中内核所支持的所有设备的设备文件,而没有任何其他的文件。
通常在系统初始化后才创建设备文件。它要么发生在加载设备驱动程序(系统尚未支持该设备)所在的模块时,要么发生在一个热拔插的设备(如USB外围设备)加入系统中时。
udev工具集可以自动地创建相应的设备文件,因为设备驱动程序模型支持设备的热插拔。当发现一个新的设备时,内核会产生一个新的进程来执行用户态shell脚本文件/sbin/hotplug,并将新设备上的有用信息作为环境变量传递给shell脚本。用户态脚本文件读取配置文件信息并关注完成新设备初始化所必需的任何操作。如果安装了udev工具集,脚本文件也会在/dev目录下创建适当的设备文件。可以通过写/proc/sys/kernel/hotplug文件改变在发生热插拔事件时所调用的用户态程序的路径名
设备文件的VFS处理
虽然设备文件也在系统的目录树中,但是它们和普通文件以及目录文件有根本的不同。当进程访问普通文件时,它会通过文件系统访问磁盘分区中的一些数据块;而在进程访问设备文件时,它只要驱动硬件设备就可以了。
例如,进程可以访问一个设备文件以从连接到计算机的温度计读取房间的温度。为应用程序隐藏设备文件与普通文件之间的差异正是VFS的责任。为了做到这点,VFS在设备文件打开时改变其缺省文件操作;因此,可以把设备文件的每个系统调用都转换成与设备相关的函数的调用,而不是对主文件系统相应函数的调用。与设备相关的函数对硬件设备进行操作以完成进程所请求的操作。让我们假定进程在设备文件(块或字符类型)上执行open()系统调用。从本质上说,相应的服务例程解析到设备文件的路径名,并建立相应的索引节点对象、目录项对象和文件对象。通过适当的文件系统函数(通常为ext2_read_inode()或ext3_read_inode();)读取磁盘上的相应索引节点来对索引节点对象进行初始化。
当这个函数确定磁盘索引节点与设备文件对应时,则调用init_special_inode(),该函数把索引节点对象的i_rdev字段初始化为设备文件的主设备号和次设备号,而把索引节点对象的i_fop字段设置为def_blk_fops或者def_chr_fops文件操作表的地址(根据设备文件的类型)。因此,open()系统调用的服务例程也调用dentry_open()函数,后者分配一个新的文件对象并把其f_op字段设置为i_fop中存放的地址,即再一次指向def_blk_fops或def_chr_fops的地址。正是这两个表的引入,才使得在设备文件上所发出的任何系统调用都将激活设备驱动程序的函数而不是基本文件系统的函数。
设备驱动程序
设备驱动程序是内核例程的集合,它使得硬件设备响应控制设备的编程接口,而该接口是一组规范的VFS函数集(open,read,lseek,ioctl等等)。这些函数的实际实现由设备驱动程序全权负责。由于每个设备都有一个唯一的I/O控制器,因此就有唯一的命令和唯一的状态信息,所以大部分IO设备都有自己的驱动程序。设备驱动程序的种类有很多。它们在对用户态应用程序提供支持的级别上有很大的不同,也对来自硬件设备的数据采集有不同的缓冲策略。这些选择极大地影响了设备驱动程序的内部结构,我们将在“直接内存访问(DMA)”和“字符设备的缓冲策略”两节进行讨论。设备驱动程序并不仅仅由实现设备文件操作的函数组成。在使用设备驱动程序之前,有几个活动是肯定要发生的。我们将在下面几节考察它们。
注册设备驱动程序
我们知道在设备文件上发出的每个系统调用都由内核转化为对相应设备驱动程序的对应函数的调用。为了完成这个操作,设备驱动程序必须注册自己。换句话说,注册一个设备驱动程序意味着分配一个新的device_driver描述符,将其插入到设备驱动程序模型的数据结构中,并把它与对应的设备文件(可能是多个设备文件)连接起来。如果设备文件对应的驱动程序以前没有注册,则对该设备文件的访问会返回错误码-ENODEV。如果设备驱动程序被静态地编译进内核,则它的注册在内核初始化阶段进行。相反,如果驱动程序是作为一个内核模块来编译的,则它的注册在模块装入时进行。在后一种情况下,设备驱动程序也可以在模块卸载时注销自己。
例如,我们考虑一个通用的PCI设备。为了能正确地对其进行处理,其设备驱动程序必须分配一个pci_driver类型的描述符,PCI内核层使用该描述符来处理设备。初始化描述符的一些字段后,设备驱动程序就会调用pci_register_driver()函数。事实上,pci_driver描述符包括一个内嵌的device_driver描述符;pci_register_driver()函数仅仅初始化内嵌的驱动程序描述符中的字段,然后调用driver_register()函数把驱动程序插入设备驱动程序模型的数据结构中。
注册设备驱动程序时,内核会寻找可能由该驱动程序处理但还尚未获得支持的硬件设备。为了做到这点,内核主要依靠相关的总线类型描述符bus_type的match方法,以及device_driver对象的probe方法。如果探测到可被驱动程序处理的硬件设备,内核会分配一个设备对象,然后调用device_register()函数把设备插入设备驱动程序模型中。
初始化设备驱动程序
对设备驱动程序进行注册和初始化是两件不同的事。设备驱动程序应当尽快被注册,以便用户态应用程序能通过相应的设备文件使用它。相反,设备驱动程序在最后可能的时刻才被初始化。事实上,初始化驱动程序意味着分配宝贵的系统资源,这些资源因此就对其他驱动程序不可用了。我们已经在第四章“I/O中断处理”一节看到一个例子:把IRQ分配给设备通常是自动进行的,这正好发生在使用设备之前,因为多个设备可能共享同一条IRQ线。其他可以在最后时刻被分配的资源是用于DMA传送缓冲区的页框和DMA通道本身(用于像软盘驱动器那样的老式非PCI设备)。
为了确保资源在需要时能够获得,在获得后不再被请求,设备驱动程序通常采用下列模式:
- 引用计数器记录当前访问设备文件的进程数。在设备文件的open方法中计数器被增加,在release方法中被减少。
- open方法在增加引用计数器的值之前先检查它。如果计数器为0,则设备驱动程序必须分配资源并激活硬件设备上的中断和DMA。
- release方法在减少使用计数器的值之后检查它。如果计数器为0,说明已经没有进程使用这个硬件设备。
如果是这样,该方法将禁止I/O控制器上的中断和DMA,然后释放所分配的资源。
监控I/O操作
I/O操作的持续时间通常是不可预知的。这可能和机械装置的情况有关(对于要传送的数据块来说是磁头的当前位置),和实际的随机事件有关(数据包什么时候到达网卡),还和人为因素有关(用户在键盘上按下一个键或者发现打印机夹纸了)。在任何情况下,启动I/O操作的设备驱动程序都必须依靠一种监控技术在I/O操作终止或超时时发出信号。
在终止操作的情况下,设备驱动程序读取I/O接口状态寄存器的内容来确定I/O操作是否成功执行。在超时的情况下,驱动程序知道一定出了问题,因为完成操作所允许的最大时间间隔已经用完,但什么也没做。监控I/O操作结束的两种可用技术分别称为轮询模式(polling mode)和中断模式(interrupt mode)。
轮询模式
CPU依照这种技术重复检查(轮询)设备的状态寄存器,直到寄存器的值表明I/O操作已经完成为止。我们已经在第五章的“自旋锁”一节中提到一种基于轮询的技术:当处理器试图获得一个繁忙的自旋锁时,它就重复地查询变量的值,直到该值变成0为止。但是,应用到I/O操作中的轮询技术更加巧妙,这是因为驱动程序还必须记住检查可能的超时。下面是轮询的一个简单例子:
for (;;){
if(read_status(device)& DEVICE_END_OPERATION) break;
if(--count == 0}break;
} 在进入循环之前,count变量已被初始化,每次循环都对count的值减1,因此就可以使用这个变量实现一种粗略的超时机制。另外,更精确的超时机制可以通过这样的方法实现:在每次循环时读取节拍计数器jiffies的值,并将它与开始等待循环之前读取的原值进行比较。
如果完成I/O操作需要的时间相对较多,比如说毫秒级,那么这种模式就变得低效,因为CPU花费宝贵的机器周期去等待I/O操作的完成。在这种情况下,在每次轮询操作之后,可以通过把schedule()的调用插入到循环内部来自愿放弃CPU。
中断模式
如果I/O控制器能够通过IRQ线发出I/O操作结束的信号,那么中断模式才能被使用。我们现在通过一个简单的例子说明中断模式如何工作。假定我们想实现一个简单的输入字符设备的驱动程序。当用户在相应的设备文件上发出read()系统调用时,一条输入命令被发往设备的控制寄存器。在一个不可预知的长时间间隔后,设备把一个字节的数据放进输入寄存器。设备驱动程序然后将这个字节作为read()系统调用的结果返回。这是一个用中断模式实现驱动程序的典型例子。实质上,驱动程序包含两个函数:
- 实现文件对象read方法的foo_read()函数。
- 处理中断的foo_interrupt()函数。只要用户读设备文件,foo_read()函数就被触发:
ssize_t foo_read(struct file *filp,char *buf,size_t count, loff_t *ppos)
{
foo_dev_t* foo_dev =filp->private_data;
if(dowm_interruptible(&foo_dev->sem)
return -ERESTARTSYS;
foo_dev->intr = 0;
outb(DEV_FOO_READ, DEV_F0O_CONTROL_PORT);
wait_event_interruptible(foo_dev->wait, (foo_dev->intr == 1));
if(put_user(foo_dev->data, buf))
return -EFAULT;
up(&foo_dev->sem);
return 1;
} 设备驱动程序依赖类型为foo_dev_t的自定义描述符;它包含信号量sem(保护硬件设备免受并发访问)、等待队列wait、标志intr(当设备发出一个中断时设置)及单个字节缓冲区data(由中断处理程序写入且由read方法读取)。
一般而言,所有使用中断的I/O驱动程序都依赖中断处理程序及read和write方法均访问的数据结构。foo_dev_t描述符的地址通常存放在设备文件的文件对象的private_data字段中或一个全局变量中。foo_read()函数的主要操作如下:
- 获取foo_dev->sem信号量,因此确保没有其他进程访问该设备。
- 清intr标志。
- 对I/O设备发出读命令。
- 执行wait_event_interruptible以挂起进程,直到intr标志变为1。一定时间后,我们的设备发出中断信号以通知I/O操作已经完成,数据已经放在适当的DEV_FOO_DATA_PORT数据端口。中断处理程序置intr标志并唤醒进程。当调度程序决定重新执行这个进程时,foo_read()的第二部分被执行,步骤如下:
- 把准备在foo_dev->data变量中的字符拷贝到用户地址空间。
- 释放foo_dev->sem信号量后终止。
为了简单起见,我们没有包含任何超时控制。一般来说,超时控制是通过静态或动态定时器实现的;定时器必须设置为启动I/O操作后正确的时间,并在操作结束时删除。让我们来看一下foo_interrupt()函数的代码:
void foo_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
foo->data = inb(DEV_FOO_DATA_PORT);
foo->intr = 1;
wake_up_interruptible(&foo->wait);
return l;
}中断处理程序从设备的输入寄存器中读字符,并把它存放在foo全局变量指向的驱动程序描述符foo_dev_t的data字段中。然后设置intr标志,并调用wake_up_interruptible()函数唤醒在foo->wait等待队列上阻塞的进程。注意,三个参数中没有一个被中断处理程序使用,这是相当普遍的情况。
访问I/O共享存储器
根据设备和总线的类型,PC体系结构里的I/O共享存储器可以被映射到不同的物理地址范围。主要有:
对于连接到ISA总线上的大多数设备
I/O共享存储器通常被映射到0xa0000~0xfffff的16位物理地址范围;这就在640 KB和1MB之间留出了一段空间,就是我们在第二章的“物理内存布局”一节中所介绍的那个“空洞”。
对于连接到PCl总线上的设备
I/O共享存储器被映射到接近4 GB的32位物理地址范围。这种类型的设备更加容易处理。几年以前,Intel引入了图形加速端口(AGP)标准,该标准是适合于高性能图形卡的PCI 的增强。这种卡除了有自己的I/O共享存储器外,还能够通过图形地址再映像表(GART)这个特殊的硬件电路直接对主板的RAM部分进行寻址。GART电路能够使AGP卡比老式的PCI卡具有更高的数据传输速率。然而,从内核的观点看,物理存储器位于何处根本没有什么关系,GART映射的存储器与其他种类I/O共享存储器的处理方式完全一样。设备驱动程序如何访问一个I/O共享存储器单元?让我们从比较简单的PC体系结构开始入手,之后再扩展到其他体系结构。
不要忘了内核程序作用于线性地址,因此I/O共享存储器单元必须表示成大于PAGE_OFFSET的地址。在后面的讨论中,我们假设PAGE_OFFSET等于0xc0000000,也就是说,内核线性地址是在第4个GB。设备驱动程序必须把I/O共享存储器单元的物理地址转换成内核空间的线性地址。在PC 体系结构中,这可以简单地把32位的物理地址和0xc0000000常量进行或运算得到。
例如,假设内核需要把物理地址为0x000b0fe4的I/O单元的值存放在t1中,把物理地址为0xfc000000的I/O单元的值存放在t2中。你可能认为使用下面的表达式就可以完成这项工作:
t1=*((unsigned char *)(0xc00b0fe4));
t2 =*((unsigned char *)(0xfc000000)); 在初始化阶段,内核已经把可用的RAM物理地址映射到线性地址空间第4个GB的开始部分。因此,分页单元把出现在第一个语句中的线性地址0xc00b0fe4映射回到原来的I/O物理地址0x000b0fe4,这正好落在从640KB到IMB的这段“ISA洞”中。这工作得很好。
但是,对于第二个语句来说,这里有一个问题,因为其I/O物理地址超过了系统RAM的最大物理地址。因此,线性地址0xfc000000就不需要与物理地址0xfc000000相对应。在这种情况下,为了在内核页表中包括对这个I/O物理地址进行映射的线性地址,必须对页表进行修改。这可以通过调用ioremap()或ioremap_nocache()函数来实现。第一个函数与vmalloc()函数类似,都调用get_vm_area()为所请求的I/O共享存储器区的大小建立一个新的vm_struct描述符。然后,这两个函数适当地更新常规内核页表中的对应页表项。ioremap_nocache()不同于ioremap(),因为前者在适当地引用再映射的线性地址时还使硬件高速缓存内容失效。因此,第二个语句的正确形式应该为:
io_mem = ioremap(0xfb000000, 0×200000);// 起始物理地址,尺寸。返回值区域起始线性地址
t2 =*((unsigned char *)(io_mem +0x100000));// 目标处线性地址第一条语句建立一个2MB的新的线性地址区间,该区间映射了从0xfb000000开始的物理地址;第二条语句读取地址为0xfc000000的内存单元。设备驱动程序以后要取消这种映射,就必须使用iounmap()函数。在其他体系结构(PC之外的体系结构)上,简单地间接引用物理内存单元的线性地址并不能正确访问I/O共享存储器。因此,Linux定义了下列依赖于体系结构的函数,当访问I/O共享存储器时来使用它们:
readb(),readw(),readl()
分别从一个I/O共享存储器单元读取1、2或者4个字节
writeb(),writew(),writel()
分别向一个I/O共享存储器单元写入1、2或者4个字节
memcpy_fromio(),memcpy_toio()
把一个数据块从一个I/O共享存储器单元拷贝到动态内存中,另一个函数正好相反
memset_io()
用一个固定的值填充一个I/O共享存储器区域因此,对于0xfc000000I/O单元的访问推荐使用这样的方法:
io_mem = ioremap(0xfb000000, 0×200000);
t2 = readb(io_mem + 0x100000);正是由于这些函数,就可以隐藏不同平台访问I/O共享存储器所用方法的差异。
直接内存访问(DMA)
在最初的PC体系结构中,CPU是系统中唯一的总线主控器,也就是说,为了提取和存储RAM存储单元的值,CPU是唯一可以驱动地址/数据总线的硬件设备。随着更多诸如PCI这样的现代总线体系结构的出现,如果提供合适的电路,每一个外围设备都可以充当总线主控器。因此,现在所有的PC都包含一个辅助的DMA电路,它可以用来控制在RAM和I/O设备之间数据的传送。DMA一旦被CPU激活,就可以自行传送数据;当数据传送完成之后,DMA发出一个中断请求。当CPU和DMA同时访问同一内存单元时,所产生的冲突由一个名为内存仲裁器的硬件电路来解决。使用DMA最多的是磁盘驱动器和其他需要一次传送大量字节的设备。因为DMA的设置时间相当长,所以在传送数量很少的数据时直接使用CPU效率更高。
原来的ISA总线所使用的DMA电路非常复杂,难于对其进行编程,并且限于物理内存的低16MB。PCI和SCSI总线所使用的最新DMA电路依靠总线中的专用硬件电路,这就简化了设备驱动程序开发人员的开发工作。
同步DMA和异步DMA
设备驱动程序可以采用两种方式使用DMA,分别是同步DMA和异步DMA。第一种方式,数据的传送是由进程触发的;而第二种方式,数据的传送是由硬件设备触发的。
采用同步DMA传送的例子如声卡,它可以播放电影音乐。用户态应用程序将声音数据(称为样本)写入一个与声卡的数字信号处理器(DSP)相对应的设备文件中。声卡的驱动程序把写入的这些样本收集在内核缓冲区中。同时,驱动程序命令声卡把这些样本从内核缓冲区拷贝到预先定时的DSP中。当声卡完成数据传送时,就会引发一个中断,然后驱动程序会检查内核缓冲区是否还有要播放的样本;如果有,驱动程序就再启动一次DMA数据传送。
采用异步DMA传送的例子如网卡,它可以从一个LAN中接收帧(数据包)。网卡将接收到的帧存储在自己的I/O共享存储器中,然后引发一个中断。其驱动程序确认该中断后,命令网卡将接收到的帧从I/O共享存储器拷贝到内核缓冲区。当数据传送完成后,网卡会引发新的中断,然后驱动程序将这个新帧通知给上层内核层。
DMA传送的辅助函数
当为使用DMA传送方式的设备设计驱动程序时,开发者编写的代码应该与体系结构和总线(就DMA传送方式来说)二者都不相关。由于内核提供了丰富的DMA辅助函数,因而现在上述目标是可以实现的。这些辅助函数隐藏了不同硬件体系结构的DMA实现机制的差异。
这是DMA辅助函数的两个子集:
老式的子集为PCI设备提供了与体系结构无关的函数;新的子集则保证了与总线和体系结构两者都无关。我们现在将介绍其中的一些函数,同时指出DMA的一些硬件特性。
总线地址
DMA的每次数据传送(至少)需要一个内存缓冲区,它包含硬件设备要读出或写入的数据。一般而言,启动一次数据传送前,设备驱动程序必须确保DMA电路可以直接访问RAM内存单元。到现在为止,我们已区分了三类存储器地址:逻辑地址、线性地址以及物理地址,前两个在CPU内部使用,最后一个是CPU从物理上驱动数据总线所用的存储器地址。但是,还有第四种存储器地址,称为总线地址(bus address),它是除CPU之外的硬件设备驱动数据总线时所用的存储器地址。
从根本上说,内核为什么应该关心总线地址呢?
这是因为在DMA操作中,数据传送不需要CPU的参与;I/O设备和DMA电路直接驱动数据总线。因此,当内核开始DMA操作时,必须把所涉及的内存缓冲区总线地址或写入DMA适当的I/O端口,或写入I/O设备适当的I/O端口。
在80x86体系结构中,总线地址与物理地址是一致的。然而,其他的体系结构例如Sun 公司的SPARC和HP的Alpha都包括一个所谓的I/O存储器管理单元(IO-MMU)的硬件电路,它类似于微处理器的分页单元,将物理地址映射为总线地址。使用DMA的所有I/O驱动程序在启动一次数据传送前必须设置好IO-MMU。
不同的总线具有不同的总线地址大小。例如,ISA的总线地址是24位长,因此,在80x86 体系结构中,可以在物理内存的低16 MB中完成DMA传送——这就是为什么DMA 使用的内存缓冲区分配在ZONE_DMA内存区中(设置了GFP_DMA标志)。
原来的PCI标准定义了32位的总线地址;但是,一些PCI硬件设备最初是为ISA总线而设计的,因此它们仍然访问不了物理地址0x00ffffff以上的RAM内存单元。新的PCI-X标准采用64位的总线地址并允许DMA电路可以直接寻址更高的内存。
在Linux中,数据类型dma_addr_t代表一个通用的总线地址。在80x86体系结构中,dma_addr_t对应一个32位长的整数,若内核支持PAE ,在这种情形下,dma_addr_t代表一个64位的整数。
pci_set_dma_mask()和dma_set_mask()两个辅助函数用于检查总线是否可以接收给定大小的总线地址(mask),如果可以,则通知总线层给定的外围设备将使用该大小的总线地址。
高速缓存的一致性
系统体系结构没有必要在硬件级为硬件高速缓存与DMA电路之间提供一个一致性协议,因此,执行DMA映射操作时,DMA辅助函数必须考虑硬件高速缓存。为了弄清楚这是为什么,假设设备驱动程序把一些数据填充到内存缓冲区中,然后立刻命令硬件设备利用DMA传送方式读取该数据。如果DMA访问这些物理RAM内存单元,而相应的硬件高速缓存行的内容还没有写入RAM中,那么硬件设备所读取的值就是内存缓冲区中的旧值。
设备驱动程序开发人员可以采用两种方法来处理DMA缓冲区,他们分别使用两类不同的辅助函数来完成。用Linux的术语来说,开发人员在下面两种DMA映射类型中进行选择:
- 一致性DMA映射: 使用这种映射方式时,内核必须保证内存与硬件设备间高速缓存一致性不是什么问题;也就是说CPU在RAM内存单元上所执行的每个写操作对硬件设备而言都是立即可见的,反过来也一样。这种映射方式也称为“同步的”或“一致的”。
- 流式DMA映射: 使用这种映射方式时,设备驱动程序必须了解高速缓存一致性问题,这可以使用适当的同步辅助函数来解决。这种映射方式也称为“异步的”或“非一致性的”。
在80×86体系结构中使用DMA时,从不存在高速缓存一致性根本不是什么问题,因为硬件设备驱动程序本身会“窥探”所访问的硬件高速缓存。因此,80×86体系结构中为硬件设备所设计的驱动程序会从前述的两种DMA映射方式中选择一个:它们二者在本质上是等价的。另一方面,在诸如MIPS、SPARC以及PowerPC的一些模型等许多其他的体系结构中,硬件设备通常不窥探硬件高速缓存,因而就会产生高速缓存一致性问题。总的来说,为与体系结构无关的驱动程序选择一个合适的DMA映射方式是很重要的。
一般来说,如果CPU和DMA处理器以不可预知的方式去访问一个缓冲区,那么必须强制使用一致性DMA映射方式(例如,SCSI适配器的command数据结构的缓冲区)。其他情形下,流式DMA映射方式更可取,因为在一些体系结构中处理一致性DMA映射是很麻烦的,并且可能导致更低的系统性能。
一致性DMA映射的辅助函数
通常,设备驱动程序在初始化阶段会分配内存缓冲区并建立一致性DMA映射;在卸载时释放映射和缓冲区。为了分配内存缓冲区和建立一致性DMA映射,内核提供了依赖体系结构的pci_alloc_consistent()和dma_alloc_coherent()两个函数。它们均返回新缓冲区的线性地址和总线地址。在80x86体系结构中,它们返回新缓冲区的线性地址和物理地址。为了释放映射和缓冲区,内核提供了pci_free_consistent()和dma_free_coherent()两个函数。
流式DMA映射的辅助函数
流式DMA映射的内存缓冲区通常在数据传送之前被映射,在传送之后被取消映射。也有可能在几次DMA传送过程中保持相同的映射,但是在这种情况下,设备驱动程序开发人员必须知道位于内存和外围设备之间的硬件高速缓存。
为了启动一次流式DMA数据传送,驱动程序必须首先利用分区页框分配器或通用内存分配器来动态地分配内存缓冲区。然后,驱动程序调用pci_map_single()函数或者dma_map_single()函数建立流式DMA映射,这两个函数接收缓冲区的线性地址作为其参数并返回相应的总线地址。为了释放该映射,驱动程序调用相应的pci_urmap_single()函数或dma_unmap_single()函数。
为了避免高速缓存一致性问题,驱动程序在开始从RAM到设备的DMA数据传送之前,如果有必要,应该调用pci_dma_sync_single_for_device()函数或dma_sync_single_for_device()函数刷新与DMA缓冲区对应的高速缓存行。同样地,从设备到RAM的一次DMA数据传送完成之前设备驱动程序是不可以访问内存缓冲区的:相反,如果有必要,在读缓冲区之前,驱动程序应该调用pci_dma_sync_single_for_cpu()函数或dma_sync_single_for_cpu()函数使相应的硬件高速缓存行无效。
在80x86体系结构中,上述函数几乎不做任何事情,因为硬件高速缓存和DMA之间的一致性是由硬件来维护的。即使是高端内存的缓冲区也可以用于DMA传送;开发人员使用pci_map_page()或dma_map_page()函数,给其传递的参数为缓冲区所在页的描述符地址和页中缓冲区的偏移地址。相应地,为了释放高端内存缓冲区的映射,开发人员使用pci_unmap_page()或dma_unmap_page()函数。
内核支持的级别
Linux内核并不完全支持所有可能存在的I/O设备。一般来说,事实上有三种可能的方式支持硬件设备:
- 根本不支持:应用程序使用适当的in和out汇编语言指令直接与设备的I/O端口进行交互。
- 最小支持:内核不识别硬件设备,但能识别它的I/O接口。用户程序把I/O接口视为能够读写字符流的顺序设备。
- 扩展支持:内核识别硬件设备,并处理I/O接口本身。事实上,这种设备可能就没有对应的设备文件。
第一种方式与内核设备驱动程序毫无关系,最常见的例子是X Window系统对图形显示的传统处理方式。这种方法效率很高,尽管它限制了X服务器使用I/O设备产生的硬件中断。为了让X服务器访问所请求的I/O端口,这种方法还需要做一些其他努力。正如第三章的“任务状态段”一节中所介绍的那样,iopl()和ioperm()系统调用给进程授权访问I/O端口。只有具有root权限的用户才可以调用这两个系统调用。但是通过设置可执行文件的setuid标志,普通用户也可以使用这些程序。新近的Linux版本支持几种广泛使用的图形卡。/dev/fb设备文件为图形卡的帧缓冲区提供了一种抽象,并允许应用软件无需知道图形接口的I/O端口的任何事情就可以访问它。此外,内核提供了直接绘制基本架构(Direct Rendering Infrastructure,DRI),DRI允许应用软件充分挖掘3D加速图形卡的硬件特性。不管怎样,传统的“自己动手配置”X Window系统服务器还依然被广泛采用。
最小支持方法是用来处理连接到通用I/O接口上的外部硬件设备的。内核通过提供设备文件(由此而提供一个设备驱动程序)来处理I/O接口;应用程序通过读写设备文件来处理外部硬件设备。最小支持优于扩展支持,因为它保持内核尽可能小。但是,在基于PC的通用I/O接口之中,只有串口和并口的处理使用了这种方法。因此,诸如X服务器之类的应用程序可以直接控制串口鼠标,而串口调制解调器通常都需要一个诸如Minicom、Seyon或PPP(点对点协议)守护进程之类的通信程序。最小支持的应用范围是有限的,因为当外部设备必须频繁地与内核内部数据结构进行交互时不能使用这种方法。例如,考虑一个连到通用I/O接口上的可移动硬盘。应用程序不能和所有的内核数据结构进程交互,也不能与识别磁盘所需要的函数和装载文件系统所需要的函数进行交互,因此,这种情况下就必须使用扩展支持。一般情况下,直接连接到I/O总线上的任何硬件设备(如内置硬盘)都要根据扩展支持方法进行处理:内核必须为每个这样的设备提供一个设备驱动程序。通用串行总线(USB)、笔记本电脑上的PCMCIA接口或者SCSI接口——简而言之,除串口和并口之外的所有通用I/O接口之上连接的外部设备都需要扩展支持。
值得注意的是,与标准文件相关的系统调用,如open()、read()和write(),并不总让应用程序完全控制底层硬件设备。事实上,VFS的“最小公分母(lowest-common-denominator)”方法没有包含某些设备所需的特殊命令,或不让应用程序检查设备是否处于某一特殊的内部状态。已引入的ioctl()系统调用可以满足这样的需要。这个系统调用除了设备文件的文件描述符和另一个表示请求的32位参数之外,还可以接收任意多个额外的参数。例如,特殊的ioctl()请求可以用来获得CD-ROM的音量或者弹出CD-ROM介质。应用程序可以用这类ioctl()请求提供一个CD播放器的用户接口。
字符设备驱动程序
处理字符设备相对比较容易,因为通常并不需要复杂的缓冲策略,也不涉及磁盘高速缓存。当然,字符设备在它们的需求方面有所不同:有些必须实现复杂的通信协议以驱动硬件设备,而有些仅仅需要从硬件设备的一对I/O端口读几个值。例如,多端口串口卡设备(一个硬件设备提供多个串口)的驱动程序比总线鼠标的设备驱动程序要复杂得多。另一方面,块设备驱动程序本身就比字符设备驱动程序复杂得多。
事实上,应用程序可以反复地要求读或写同一个数据块。此外,访问这些设备通常是很慢的。这些特性对磁盘驱动程序的结构产生了深刻的影响。然而,就如我们将在下一章看到的,内核提供了诸如页面高速缓存和块I/O子系统这些高级组件去处理驱动程序。在本章剩下的部分中我们把注意力集中于字符设备驱动程序。字符设备驱动程序是由一个cdev结构描述的:
- kobj 内嵌的kobject
- owner 指向实现驱动程序模块(如果有的话)的指
- ops 指向设备驱动程序文件操作表的指针
- list 与字符设备文件对应的索引节点链表的头
- dev 给设备驱动程序所分配的初始主设备号和次设备号
- count 给设备驱动程序所分配的设备号范围的大小
- list字段是双向循环链表的首部,该链表用于收集相同字符设备驱动程序所对应的字符设备文件的索引节点。
可能很多设备文件具有相同的设备号,并对应于相同的字符设备。此外,一个设备驱动程序对应的设备号可以是一个范围,而不仅仅是一个号;设备号位于同一范围内的所有设备文件均由同一个字符设备驱动程序处理。设备号范围的大小存放在count字段中。
cdev_alloc()函数的功能是动态地分配cdev描述符,并初始化内嵌的kobject数据结构,因此在引用计数器的值变为0时会自动释放该描述符。cdev_add()函数的功能是在设备驱动程序模型中注册一个cdev描述符。它初始化cdev 描述符中的dev和count字段,然后调用kobj_map()函数。kobj_map()则依次建立设备驱动程序模型的数据结构,把设备号范围复制到设备驱动程序的描述符中。
设备驱动程序模型为字符设备定义了一个kobject映射域,该映射域由一个kobj_map类型的描述符描述,并由全局变量cdev_map引用。kobj_map描述符包括一个散列表,它有255个表项,并由0~255范围的主设备号进行索引。散列表存放probe类型的对象,每个对象都拥有一个已注册的主设备号和次设备号,其中各字段如表13-9所示。
- next dev:散列冲突链表中的下一个元素设备号范围的初始设备号(主、次设备号)
- range 设备号范围的大小
- owner 如果有的话,指向实现设备驱动程序模块的指钅
- get 探测谁拥有这个设备号范围
- lock 增加设备号范围内拥有者的引用计数器
- data 设备号范围内拥有者的私有数据
调用kobj_map()函数时,把指定的设备号范围加入到散列表中。相应的probe对象的data字段指向设备驱动程序的cdev描述符。执行get和lock方法时把data字段的值传递给它们。在这种情况下,get方法通过一个简捷函数实现,其返回值为cdev描述符中内嵌的kobject数据结构的地址;相反,lock方法本质上用于增加内嵌的kobject数据结构的引用计数器的值。
kobj_lookup()函数接收kobject映射域和设备号作为输入参数;它搜索散列表,如果找到,则返回该设备号所在范围的拥有者的kobject的地址。当这个函数应用到字符设备的映射域时,就返回设备驱动程序描述符cdev中所嵌入的kobject的地址。
分配设备号
为了记录目前已经分配了哪些字符设备号,内核使用散列表chrdevs,表的大小不超过设备号范围。两个不同的设备号范围可能共享同一个主设备号,但是范围不能重叠,因此它们的次设备号应该完全不同。chrdevs包含255个表项,由于散列函数屏蔽了主设备号的高四位——因此,主设备号的个数少于255个,它们被散列到不同的表项中。
每个表项指向冲突链表的第一个元素,而该链表是按主、次设备号的递增顺序进行排序的。冲突链表中的每个元素是一个char_device_struct结构,其各字段如表13-10所示。
- next major:指向散列冲突链表中下一个元素的指针 设备号范围内的主设备号
- baseminor:设备号范围内的初始次设备号
- minorct 设备号范围的大小
- name 处理设备号范围内的设备驱动程序的名称
- fops 没有使用
- cdev 指向字符设备驱动程序描述符的指针
本质上可以采用两种方法为字符设备驱动程序分配一个范围内的设备号。所有新的设备驱动程序使用第一种方法,该方法使用register_chrdev_region()函数和alloc_chrdev_region()函数为驱动程序分配任意范围内的设备号。例如,为了获得从dev(类型为dev_t)开始的大小为size的一个设备号范围:
register_chrdev_region(dev, size, "foo");上述函数并不执行cdev_add(),因此设备驱动程序在所要求的设备号范围被成功分配时必须执行cdev_add()函数。第二种方法使用register_chrdev()函数,它分配一个固定的设备号范围,该范围包含唯一一个主设备号以及0~255的次设备号。在这种情形下,设备驱动程序不必调用cdev_add()函数。
register_chrdev_region()函数和alloc_chrdev_region()函数
register_chrdev_region()函数接收三个参数:初始的设备号(主设备号和次设备号)、请求的设备号范围大小(与次设备号的大小一样)以及这个范围内的设备号对应的设备驱动程序的名称。该函数检查请求的设备号范围是否跨越一些次设备号,如果是,则确定其主设备号以及覆盖整个区间的相应设备号范围;然后,在每个相应设备号范围上调用__register_chrdev_region()函数。
alloc_chrdev_region()函数与register_chrdev_region()相似,但它可以动态地分配一个主设备号;因此,该函数接收的参数为设备号范围内的初始次设备号、范围的大小以及设备驱动程序的名称。结束时它也调用register_chrdev_region()函数。register_chrdev_region()函数执行以下步骤:
- 分配一个新的char_device_struct结构,并用0填充。
- 如果设备号范围内的主设备号为0,那么设备驱动程序请求动态分配一个主设备号。函数从散列表的末尾表项开始继续向后寻找一个与尚未使用的主设备号对应的空冲突链表(NULL指针)。若没有找到空表项,则返回一个错误码。
- 初始化char_device_struct结构中的初始设备号、范围大小以及设备驱动程序名称。
- 执行散列函数计算与主设备号对应的散列表索引。
- 遍历冲突链表,为新的char_device_struct结构寻找正确的位置。同时,如果找到与请求的设备号范围重叠的一个范围,则返回一个错误码。
- 将新的char_device_struct描述符插入冲突链表中。
- 返回新的char_device_struct描述符的地址。
register_chrdev()函数
驱动程序使用register_chrdev()函数时需要一个老式的设备号范围:一个单独的主设备号和0~255的次设备号范围。该函数接收的参数为:请求的主设备号major(如果是0则动态分配)、设备驱动程序的名称name和一个指针fops(它指向设备号范围内的特定字符设备文件的文件操作表)。该函数执行下列操作:
- 调用__register_chrdev_region()函数分配请求的设备号范围。如果返回一个错误码(不能分配该范围),函数将终止运行。
- 为设备驱动程序分配一个新的cdev结构。
- 初始化cdev结构:
a. 将内嵌的kobject类型设置为ktype_cdev_dynamic类型的描述符。
b. 将owner字段设置为fops->owner的内容。
c. 将ops字段设置为文件操作表的地址fops。
d. 将设备驱动程序的名称拷贝到内嵌的kobject结构里的name字段中。 - 调用cdev_add()函数(在前面解释过)。
- 将__register_chrdev_region()函数在第1步中返回的char_device_struct描述符的cdev字段设置为设备驱动程序的cdev描述符的地址。
- 返回分配的设备号范围的主设备号。
访问字符设备驱动程序
我们在“设备文件的VFS处理”一节中曾提到,由open()系统调用服务例程触发的dentry_open()函数定制字符设备文件的文件对象的f_op字段,以使它指向def_chr_fops表。这个表几乎为空;它仅仅定义了chrdev_open()函数作为设备文件的打开方法。这个方法由dentry_open()直接调用。chrdev_open()函数接收的参数为索引节点的地址inode、指向所打开文件对象的指针filp。本质上它执行以下操作:
- 检查指向设备驱动程序的cdev描述符的指针inode->i_cdev。如果该字段不为空,则inode结构已经被访问:增加cdev描述符的引用计数器值并跳转到第6步。
- 调用kobj_lookup()函数搜索包括该设备号在内的范围。如果该范围不存在,则返回一个错误码;否则,函数计算与该范围相对应的cdev描述符的地址。
- 将inode对象的inode->i_cdev字段设置为cdev描述符的地址。
- 将inode->i_cindex字段设置为设备驱动程序的设备号范围内的设备号的相关索引(设备号范围内的第一个次设备号的索引值为0,第二个为1,依此类推)。
- 将inode对象加入到由cdev描述符的list字段所指向的链表中。
- 将filp->f_ops文件操作指针初始化为cdev描述符的ops字段的值。
- 如果定义了filp->f_ops->open方法,chrdev_open()函数就会执行该方法。若设备驱动程序处理一个以上的设备号,则chrdev_open()一般会再次设置file对象的文件操作,这样可以为所访问的设备文件安装合适的文件操作。
- 成功时返回0结束。
字符设备的缓冲策略
传统的类Unix操作系统把硬件设备划分为块设备和字符设备。但是,这种分类并不能说明整个事实。某些设备在一次单独的I/O操作中能够传送大量的数据,而有些设备则只能传送几个字符。
例如,PS/2鼠标驱动程序在每次读操作中获得几个字节——它们对应鼠标按钮的状态和屏幕上鼠标的指针。这种设备是最容易处理的。首先从设备的输入寄存器中一次读一个字符的输入数据,并存放在合适的内核数据结构中;然后,在空闲时把这个数据拷贝到进程的地址空间。同理,把输出数据首先从进程的地址空间拷贝到合适的内核数据结构中,然后,再一次一个字符地写到I/O设备的输出寄存器。显然,这种设备的I/O驱动程序没有使用DMA,因为CPU建立DMA I/O操作所花费的时间跟把数据移到I/O 端口所花费的时间差不多。
另一方面,内核也必须准备处理在每次I/O操作中产生大量字节的设备,这些设备或者是诸如声卡或网卡的顺序设备,或者是诸如各类磁盘(软盘、光盘、SCS1磁盘等)的随机访问设备。例如,假定你已经为自己的计算机配置了声卡,以便能够录下来自麦克风的声音。声卡以固定的频率(比如说44.14kHz)对来自麦克风的电信号进行采样,并产生一个16位数的输入数据块的流。声卡驱动程序必须能处理所有可能情况下这种蜂拥而至的数据,即使当CPU暂时忙于运行某个其他进程也不例外。
这可以结合两种不同的技术做到:
- 使用DMA方式传送数据块。
- 运用两个或多个元素的循环缓冲区,每个元素具有一个数据块的大小。
当一个中断(发送一个信号表明新的数据块已被读入)发生时,中断处理程序把指针移到循环缓冲区的下一个元素,以便将来的数据会存放在一个空元素中。相反,只要驱动程序把数据成功地拷贝到用户地址空间,就释放循环缓冲区中的元素,以便用它来保存从硬件设备传送来的新数据。循环缓冲区的作用是消除CPU负载的峰值;即使接收数据的用户态应用程序因为其他高优先级任务而慢下来,DMA也要能够继续填充循环缓冲区中的元素,因为中断处理程序代表当前运行的进程执行。
当接收来自网卡的数据包时有类似的情况发生,只是在这种情况下,进入的数据流都是异步的。数据包被互相独立地接收,且两个连续的数据包之间到达的时间间隔是不可预测的。总而言之,顺序设备的缓冲区是容易处理的,因为同一缓冲区从不会被重用:音频应用程序不能要求麦克风重新传送同一数据块。
块设备
块设备的处理
块设备驱动程序上的每个操作都涉及很多内核组件下面是内核对进程请求给予回应的一般步骤: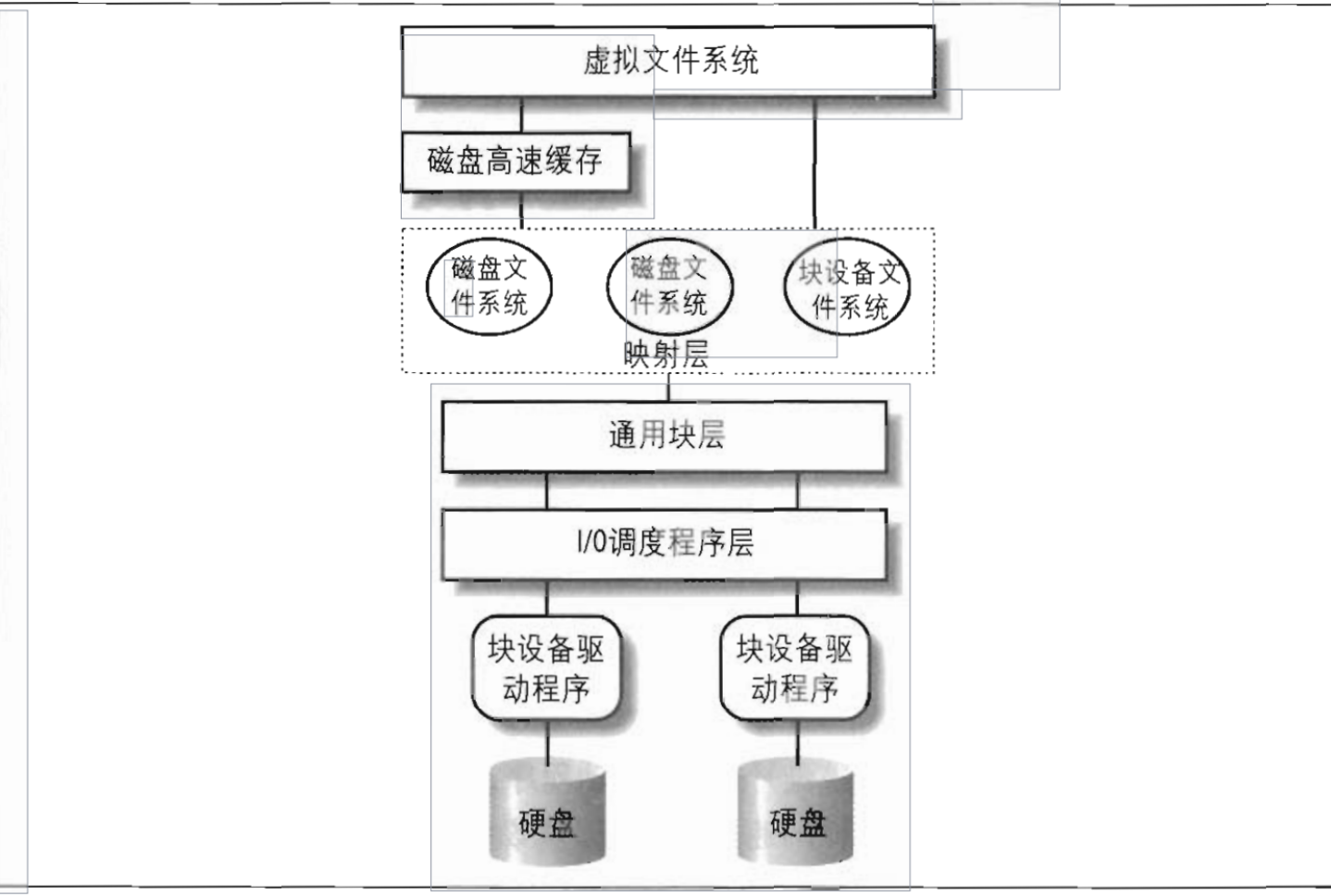
- read()系统调用的服务例程调用一个适当的VFS函数,将文件描述符和文件内的偏移量传递给它。虚拟文件系统位于块设备处理体系结构的上层,它提供一个通用的文件模型,Linux支持的所有文件系统均采用该模型。
- VFS函数确定所请求的数据是否已经存在,如果有必要的话,它决定如何执行read操作。有时候没有必要访问磁盘上的数据,因为内核将大多数最近从块设备读出或写入其中的数据保存在RAM中。
- 我们假设内核从块设备读数据,那么它就必须确定数据的物理位置。为了做到这点,内核依赖映射层(mapping layer),主要执行下面两步:
- 内核确定该文件所在文件系统的块大小,并根据文件块的大小计算所请求数据的长度。本质上,文件被看作拆分成许多块,因此内核确定请求数据所在的块号(文件开始位置的相对索引)。
- 接下来,映射层调用一个具体文件系统的函数,它访问文件的磁盘节点,然后根据逻辑块号确定所请求数据在磁盘上的位置。事实上,磁盘也被看作拆分成许多块,因此内核必须确定存放所请求数据的块对应的号(磁盘或分区开始位置的相对索引)。由于一个文件可能存储在磁盘上的不连续块中,因此存放在磁盘索引节点中的数据结构将每个文件块号映射为一个逻辑块号。
- 现在内核可以对块设备发出读请求。内核利用通用块层(generic block Inyer)启动I/O操作来传送所请求的数据。一般而言,每个I/O操作只针对磁盘上一组连续的块。由于请求的数据不必位于相邻的块中,所以通用块层可能启动几次I/O操作。每次I/O操作是由一个“块I/O”(简称“bio”)结构描述,它收集底层组件需要的所有信息以满足所发出的请求。通用块层为所有的块设备提供了一个抽象视图,因而隐藏了硬件块设备间的差异性。几乎所有的块设备都是磁盘,所以通用块层也提供了一些通用数据结构来描述“磁盘”或“磁盘分区”。
- 通用块层下面的“I/O调度程序”根据预先定义的内核策略将待处理的I/O数据传送请求进行归类。调度程序的作用是把物理介质上相邻的数据请求聚集在一起。
- 最后,块设备驱动程序向磁盘控制器的硬件接口发送适当的命令,从而进行实际的数据传送。如你所见,块设备中的数据存储涉及了许多内核组件;每个组件采用不同长度的块来管理磁盘数据:
- 硬件块设备控制器采用称为“扇区”的固定长度的块来传送数据。因此,I/O调度程序和块设备驱动程序必须管理数据扇区。
- 虚拟文件系统、映射层和文件系统将磁盘数据存放在称为“块”的逻辑单元中。
- 一个块对应文件系统中一个最小的磁盘存储单元。
我们很快会看到,块设备驱动程序应该能够处理数据的“段”:一个段就是一个内存页或内存页的一部分,它们包含磁盘上物理相邻的数据块。 - 磁盘高速缓存作用于磁盘数据的“页”上,每页正好装在一个页框中。通用块层将所有的上层和下层的组件组合在一起,因此它了解数据的扇区、块、段以及页。即使有许多不同的数据块,它们通常也是共享相同的物理RAM单元。
例如,图14-2显示了一个具有4096字节的页的构造。上层内核组件将页看成是由4个1024字节组成的块缓冲区。块设备驱动程序正在传送页中的后3个块,因此这3块被插入到涵盖了后3072 字节的段中。硬盘控制器将该段看成是由6个512字节的扇区组成。
本章我们介绍处理块设备的下层内核组件:通用块层、I/O调度程序以及块设备驱动程序,因此我们将注意力集中在扇区、块和段上。
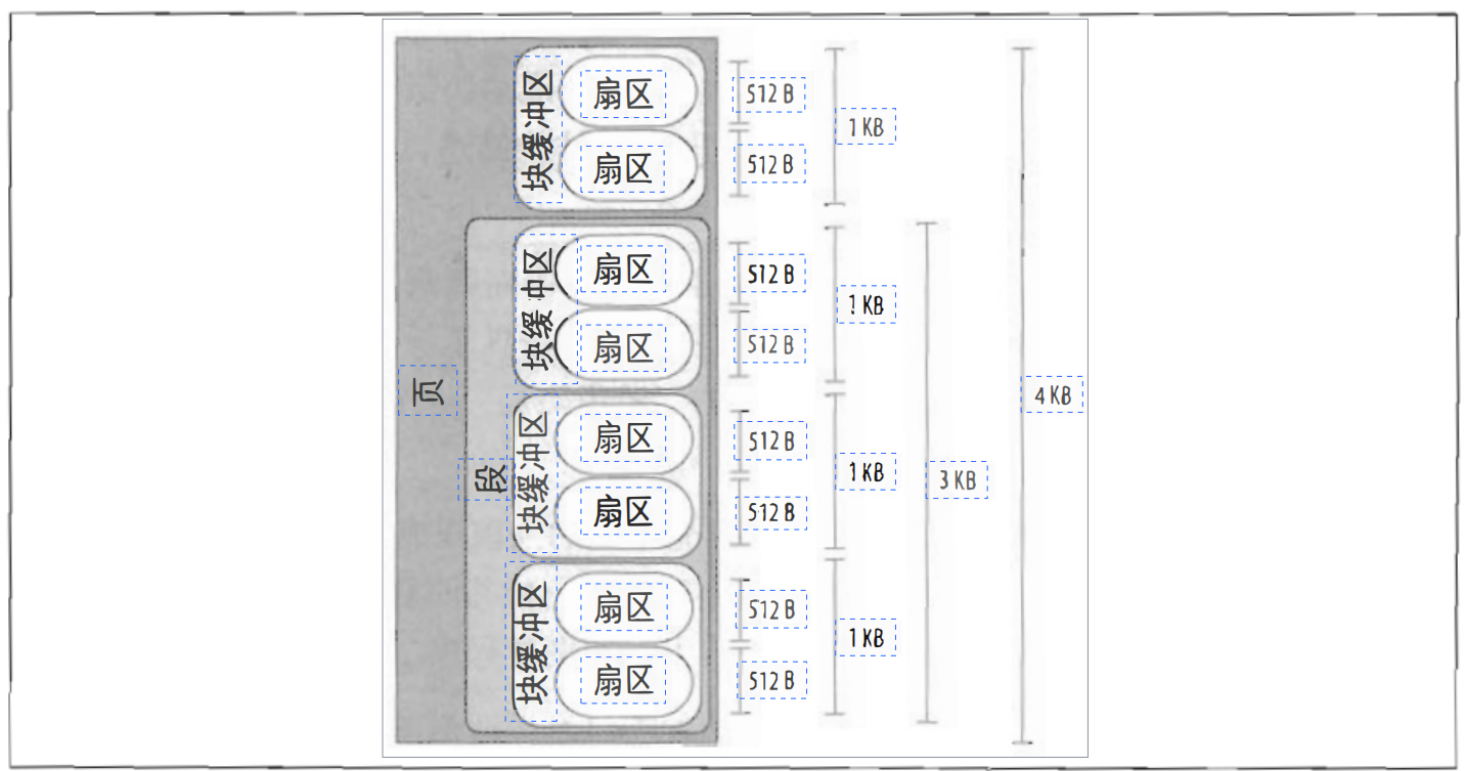
扇区
为了达到可接受的性能,硬盘和类似的设备快速传送几个相邻字节的数据。块设备的每次数据传送操作都作用于一组称为扇区的相邻字节。在下面的讨论中,我们假定字节按相邻的方式记录在磁盘表面,这样一次搜索操作就可以访问到它们。尽管磁盘的物理构造很复杂,但是硬盘控制器接收到的命令将磁盘看成一大组扇区。在大部分磁盘设备中,扇区的大小是512字节,但是一些设备使用更大的扇区(1024和2048字节)。
注意,应该把扇区作为数据传送的基本单元;不允许传送少于一个扇区的数据,尽管大部分磁盘设备都可以同时传送几个相邻的扇区。在Linux中,扇区大小按惯例都设为512字节;如果一个块设备使用更大的扇区,那么相应的底层块设备驱动程序将做些必要的变换。因此,对存放在块设备中的一组数据是通过它们在磁盘上的位置来标识,即其首个512字节扇区的下标以及扇区的数目。扇区的下标存放在类型为sector_c的32位或64位的变量中。
块
扇区是硬件设备传送数据的基本单位,而块是VFS和文件系统传送数据的基本单位。例如,内核访问一个文件的内容时,它必须首先从磁盘上读文件的磁盘索引节点所在的块。该块对应磁盘上一个或多个相邻的扇区,而VFS将其看成是一个单一的数据单元。在Linux中,块大小必须是2的幂,而且不能超过一个页框。此外,它必须是扇区大小的整数倍,因为每个块必须包含整数个扇区。因此,在80×86体系结构中,允许块的大小为512、1024、2048和4096字节。
块设备的块大小不是唯一的。创建一个磁盘文件系统时,管理员可以选择合适的块大小。因此,同一个磁盘上的几个分区可能使用不同的块大小。此外,对块设备文件的每次读或写操作是一种“原始”访问,因为它绕过了磁盘文件系统;内核通过使用最大的块(4096字节)执行该操作。每个块都需要自己的块缓冲区,它是内核用来存放块内容的RAM内存区。当内核从磁盘读出一个块时,就用从硬件设备中所获得的值来填充相应的块缓冲区;同样,当内核向磁盘中写入一个块时,就用相关块缓冲区的实际值来更新硬件设备上相应的一组相邻字节。块缓冲区的大小通常要与相应块的大小相匹配。
缓冲区首部是一个与每个缓冲区相关的buffer_head类型的描述符。它包含内核处理缓冲区需要了解的所有信息;因此,在对每个缓冲区进行操作之前,内核都要首先检查其缓冲区首部。我们将在第十五章中详细介绍缓冲区首部中的所有字段值;但是在本章中我们仅仅介绍其中的一些字段:b_page、b_data、b_blocknr和b_bdev。
b_page字段存放的是块缓冲区所在页框的页描述符地址。如果页框位于高端内存中,那么b_data字段存放页中块缓冲区的偏移量;否则,b_data存放块缓冲区本身的起始线性地址。
b_blocknr字段存放的是逻辑块号(例如磁盘分区中的块索引)。
最后,b_bdev 字段标识使用缓冲区首部的块设备。
段
我们知道对磁盘的每个I/O操作就是在磁盘与一些RAM单元之间相互传送一些相邻扇区的内容。大多数情况下,磁盘控制器直接采用DMA方式进行数据传送。块设备驱动程序只要向磁盘控制器发送一些适当的命令就可以触发一次数据传送;一旦完成数据的传送,控制器就会发出一个中断通知块设备驱动程序。
DMA方式传送的是磁盘上相邻扇区的数据。这是一个物理约束:磁盘控制器允许DMA 传送不相邻的扇区数据,但是这种方式的传送速率很低,因为在磁盘表面上移动读/写磁头是相当慢的。老式的磁盘控制器仅仅支持“简单的”DMA传送方式:在这种传送方式中,磁盘必须与RAM中的连续内存单元相互传送数据。但是,新的磁盘控制器也支持所谓的分散-聚集(scatter-gather)DMA传送方式:此种方式中,磁盘可以与一些非连续的内存区相互传送数据。
启动一次分散-聚集DMA传送,块设备驱动程序需要向磁盘控制器发送:
- 要传送的起始磁盘扇区号和总的扇区数
- 内存区的描述符链表,其中链表的每项包含一个地址和一个长度。磁盘控制器负责整个数据传送;例如,在读操作中控制器从相邻磁盘扇区中获得数据,然后将它们存放到不同的内存区中。为了使用分散-聚集DMA传送方式,块设备驱动程序必须能够处理称为段的数据存储单元。一个段就是一个内存页或内存页中的一部分,它们包含一些相邻磁盘扇区中的数据。因此,一次分散-聚集DMA操作可能同时传送几个段。注意,块设备驱动程序不需要知道块、块大小以及块缓冲区。因此,即使高层将段看成是由几个块缓冲区组成的页,块设备驱动程序也不用对此给予关注。正如我们所见,如果不同的段在RAM中相应的页框正好是连续的并且在磁盘上相应的数据块也是相邻的,那么通用块层可以合并它们。通过这种合并方式产生的更大的内存区就称为物理段。然而,在多种体系结构上还允许使用另一个合并方式:通过使用一个专门的总线电路[如IO-MMU;参见第十三章中的“直接内存访问(DMA)”一节]来处理总线地址与物理地址间的映射。
通过这种合并方式产生的内存区称为硬件段。由于我们将注意力集中在80×86体系结构上,它在总线地址和物理地址之间不存在动态的映射,因此在本章剩余部分我们假定硬件段总是对应物理段。
通用块层
通用块层是一个内核组件,它处理来自系统中的所有块设备发出的请求。由于该层所提供的函数,内核可以容易地做到:
- 将数据缓冲区放在高端内存——仅当CPU访问其数据时,才将页框映射为内核中的线性地址空间,并在数据访问完后取消映射。
- 通过一些附加的手段,实现一个所谓的“零-复制”模式,将磁盘数据直接存放在用户态地址空间而不是首先复制到内核内存区;事实上,内核为I/O数据传送使用的缓冲区所在的页框就映射在进程的用户态线性地址空间中。
- 管理逻辑卷,例如由LVM(逻辑卷管理器)和RAID(廉价磁盘冗余阵列)使用的逻辑卷:几个磁盘分区,即使位于不同的块设备中,也可以被看作是一个单一的分区。
- 发挥大部分新磁盘控制器的高级特性,例如大主板磁盘高速缓存、增强的DMA性能、I/O传送请求的相关调度等等。
bio结构
通用块层的核心数据结构是一个称为bio的描述符,它描述了块设备的I/O操作。每个bio结构都包含一个磁盘存储区标识符(存储区中的起始扇区号和扇区数目)和一个或多个描述与I/O操作相关的内存区的段。bio由bio数据结构描述,其各字段如表14-1 所示。
- bi_sector:块1/0操作的第一个磁盘扇区
- bi_next: 链接到请求队列中的下一个bio
- bi_bdev :指向块设备描述符的指针
- bi_flags : bio 的状态标志
- bi_rw 1/0操作标志
- bi_vcnt: bio的 bio_vec数组中段的数目
- bi_idx :bio 的 bio_vec数组中段的当前索引值
- bi_phys_segments :合并之后bio中物理段的数目
- bi_hw_segments 合并之后硬件段的数目
- bi_size 需要传送的字节数
- bi_hw_front_size 硬件段合并算法使用
- bi_hw_back_size 硬件段合并算法使用
- bi_max_vecs bio的bio_vec数组中允许的最大段数
- bi_io_vec 指向 bio的 bio_vec数组中的段的指
- bi_end_io bio的1/O操作结束时调用的方法
- bi_cnt bio的引用计数器
- bi_private 通用块层和块设备驱动程序的1/0完成方法使用的指针
- bi_destructor 释放bio时调用的析构方法(通常是 bio_destructor()方法)
bio中的每个段是由一个bio_vec数据结构描述的,其中各字段如表14-2所示。bio中的bi_io_vec字段指向bio_vec数据结构的第一个元素,bi_vcnt字段则存放了bio_vec数组中当前的元素个数。
- bv_page:指向页的页框中页描述符的指针
- bv_len段的字节长度
- bv_offset:页框中段数据的偏移量
在块I/O操作期间bio描述符的内容一直保持更新。例如,如果块设备驱动程序在一次分散-聚集DMA操作中不能完成全部的数据传送,那么bio中的bi_idx字段会不断更新来指向待传送的第一个段。为了从索引bi_idx指向的当前段开始不断重复bio中的段,设备驱动程序可以执行宏bio_for_each_segment。当通用块层启动一次新的I/O操作时,调用bio_alloc()函数分配一个新的bio结构。
通常,bio结构是由slab分配器分配的,但是,当内存不足时,内核也会使用一个备用的bio小内存池。内核也为bio_vec结构分配内存池——毕竟,分配一个bio结构而不能分配其中的段描述符也是没有什么意义的。相应地,bio_put()函数减少bio中引用计数器(bi_cnt)的值,如果该值等于0,则释放bio结构以及相关的bio_vec结构。
磁盘和磁盘分区的表示
磁盘是一个由通用块层处理的逻辑块设备。通常一个磁盘对应一个硬件块设备,例如硬盘、软盘或光盘。但是,磁盘也可以是一个虚拟设备,它建立在几个物理磁盘分区之上或一些RAM专用页中的内存区上。在任何情形中,借助通用块层提供的服务,上层内核组件可以以同样的方式工作在所有的磁盘上。磁盘是由gendisk对象描述的,其中各字段如表14-3所示。
- major 磁盘主设备号
- first_minor 与磁盘关联的第一个次设备号
- minors 与磁盘关联的次设备号范围
- disk_name 磁盘的标准名称(通常是相应设备文件的规范名称 )
- part 磁盘的分区描述符数组
- fops 指向块设备操作表的指针
- queue 指问磁盘请求队列的指针
- private_data 块设备驱动程序的私有数据
- capacity 磁盘内存区的大小(扇区数目)
- flags 描述磁盘类型的标志(见下文)
devfs_name devfs特殊文件系统(现在已不赞成 使用)中的设备文件名称
number 不再使用
- driverfs_dev 指向磁盘的硬件设备的device对象 的指针
- kobj 内嵌的kobject结构
- random 该指针指向的这个数据结构记录磁盘 中断的定时,由内核内置的随机数发 生器使用
- policy 如果磁盘是只读的,则置为1(写操 作禁止),否则为0
- sync_io 写入磁盘的扇区数计数器,仅为 RAID使用
- stamp 统计磁盘队列使用情况的时间戳
- stamp_idl 同上
- in_flight 正在进行的I/O操作数
- dkstats 统计每个CPU使用磁盘的情况
Aflags字段存放了关于磁盘的信息。其中最重要的标志是GENHD_FL_UP;如果设置它,那么磁盘将被初始化并可以使用。另一个相关的标志是GENHD_FL_REMOVABLE,如果是诸如软盘或光盘这样可移动的磁盘,那么就要设置该标志。gendisk对象的fops字段指向一个表block_device_operations,该表为块设备的主要操作存放了几个定制的方法(如表14-4所示)。
- open 打开块设备文件
- release关闭对块设备文件的最后一个引用
- ioctl 在块设备文件上发出ioct1()系统调用(使用大内核锁)
- compat_ioctl 在块设备文件上发出ioct1()系统调用(不使用大内核锁)
- media_changed 检查可移动介质是否已经变化(例如软盘)
- revalidate_disk 检查块设备是否持有有效数据
通常硬盘被划分成几个逻辑分区。每个块设备文件要么代表整个磁盘,要么代表磁盘中的某一个分区。例如,一个主设备号为3、次设备号为0的设备文件/dev/hda代表的可能是一个主EIDE磁盘;该磁盘中的前两个分区分别由设备文件/dev/hdal和/dev/hda2 代表,它们的主设备号都是3,而次设备号分别为1和2。一般而言,磁盘中的分区是由连续的次设备号来区分的。如果将一个磁盘分成了几个分区,那么其分区表保存在hd_struct结构的数组中,该数组的地址存放在gendisk对象的part字段中。通过磁盘内分区的相对索引对该数组进行索引。
当内核发现系统中一个新的磁盘时(在启动阶段,或将一个可移动介质插入一个驱动器中时,或在运行期附加一个外置式磁盘时),就调用alloc_disk()函数,该函数分配并初始化一个新的gendisk对象,如果新磁盘被分成了几个分区,那么alloc_disk()还会分配并初始化一个适当的hd_struct类型的数组。然后,内核调用add_disk()函数将新的gendisk对象插入到通用块层的数据结构中。
提交请求
我们介绍一下当向通用块层提交一个I/O操作请求时,内核所执行的步骤顺序。我们假设被请求的数据块在磁盘上是相邻的,并且内核已经知道了它们的物理位置。第一步是执行bio_alloc()函数分配一个新的bio描述符。然后,内核通过设置一些字段值来初始化bio描述符:
- 将bi_sector设为数据的起始扇区号(如果块设备分成了几个分区,那么扇区号是相对于分区的起始位置的)。
- 将bi_size设为涵盖整个数据的扇区数目。
- 将bi_bdev设为块设备描述符的地址。
- 将bi_io_vec设为bio_vec结构数组的起始地址,数组中的每个元素描述了I/0操作中的一个段(内存缓存);此外,将bi_vcnt设为bio中总的段数。
- 将bi_rw设为被请求操作的标志。其中最重要的标志指明数据传送的方向:READ (0)或WRITE(1)。
- 将bi_end_io设为当bio上的I/O操作完成时所执行的完成程序的地址。
一旦bio描述符被进行了适当的初始化,内核就调用generic_make_request()函数,它是通用块层的主要入口点。该函数主要执行下列操作:
- 检查bio->bi_sector没有超过块设备的扇区数。如果超过,则将bio->bi_flags设置为BIO_EOF标志,然后打印一条内核错误信息,调用bio_endio()函数,并终止。bio_endio()更新bio描述符中的bi_size和bi_sector值,然后调用bio的bi_end_io方法。bi_end_io函数的实现本质上依赖于触发I/O数据传送的内核组件;我们将在下面的章节中看到bi_end_io方法的一些例子。
- 获取与块设备相关的请求队列q;其地址存放在块设备描述符的bd_disk字段中,其中的每个元素由bio->bi_bdev指向。
- 调用block_wait_queue_running()函数检查当前正在使用的I/O调度程序是否可以被动态取代;若可以,则让当前进程睡眠直到启动一个新的I/O调度程序。
- 调用blk_partition_remap()函数检查块设备是否指的是一个磁盘分区(bio->bi_bdev不等于bio->bi_dev->bd_contains)。如果是,则从bio->bi_bdev获取分区的hd_struct描述符,从而执行下面的子操作:
a. 根据数据传送的方向,更新hd_struct描述符中的read_sectors和reads值,或write_sectors和writes值。
b. 调整bio->bi_sector值使得把相对于分区的起始扇区号转变为相对于整个磁盘的扇区号。
c. 将bio->bi_bdev设置为整个磁盘的块设备描述符(bio->bd_contains)。从现在开始,通用块层、I/O调度程序以及设备驱动程序将忘记磁盘分区的存在,直接作用于整个磁盘。 - 调用q->make_request_fn方法将bio请求插入请求队列q中。
- 返回。
在本章后面的“向I/O调度程序发出请求”一节中我们将讨论make_request_fn方法典型实现。
I/O调度程序
虽然块设备驱动程序一次可以传送一个单独的扇区,但是块I/O层并不会为磁盘上每个被访问的扇区都单独执行一次I/O操作;这会导致磁盘性能的下降,因为确定磁盘表面上扇区的物理位置是相当费时的。取而代之的是,只要可能,内核就试图把几个扇区合并在一起,并作为一个整体来处理,这样就减少了磁头的平均移动时间。当内核组件要读或写一些磁盘数据时,实际上创建一个块设备请求。从本质上说,请求描述的是所请求的扇区以及要对它执行的操作类型(读或写)。然而,并不是请求一发出,内核就满足它——I/O操作仅仅被调度,执行会向后推迟。这种人为的延迟是提高块设备性能的关键机制。
当请求传送一个新的数据块时,内核检查能否通过稍微扩展前一个一直处于等待状态的请求而满足新请求(也就是说,能否不用进一步的寻道操作就能满足新请求)。由于磁盘的访问大都是顺序的,因此这种简单机制就非常高效。延迟请求复杂化了块设备的处理。
例如,假设某个进程打开了一个普通文件,然后,文件系统的驱动程序就要从磁盘读取相应的索引节点。块设备驱动程序把这个请求加入一个队列,并把这个进程挂起,直到存放索引节点的块被传送为止。然而,块设备驱动程序本身不会被阻塞,因为试图访问同一磁盘的任何其他进程也可能被阻塞。为了防止块设备驱动程序被挂起,每个I/O操作都是异步处理的。
特别是块设备驱动程序是中断驱动的;通用块层调用I/O调度程序产生一个新的块设备请求或扩展一个已有的块设备请求,然后终止。随后激活的块设备驱动程序会调用一个所谓的策略例程(strategy routine)选择一个待处理的请求,并向磁盘控制器发出一条适当的命令来满足这个请求。
当I/O操作终止时,磁盘控制器就产生一个中断,如果需要,相应的中断处理程序就又调用策略例程去处理队列中的另一个请求。 每个块设备驱动程序都维持着自己的请求队列,它包含设备待处理的请求链表。如果磁盘控制器正在处理几个磁盘,那么通常每个物理块设备都有一个请求队列。在每个请求队列上单独执行I/O调度,这样可以提高磁盘的性能。
请求队列描述符
请求队列是由一个大的数据结构request_queue表示的实质上,请求队列是一个双向链表,其元素就是请求描述符(也就是request数据结构)。请求队列描述符中的queue_head字段存放链表的头(第一个伪元素),而请求描述符中queuelist字段的指针把任一请求链接到链表的前一个和后一个元素之间。
队列链表中元素的排序方式对每个块设备驱动程序是特定的;然而,I/O调度程序提供了几种预先确定好的元素排序方式,这将在后面的“I/O调度算法”一节中讨论。backing_dev_info字段是一个backing_dev_info类型的小对象,它存放了关于基本硬件块设备的I/O数据流量的信息。例如,它保存了关于预读以及关于请求队列拥塞状态的信息。
请求描述符
每个块设备的待处理请求都是用一个请求描述符来表示的。每个请求包含一个或多个bio结构。最初,通用块层创建一个仅包含一个bio结构的请求。然后,I/O调度程序要么向初始的bio中增加一个新段,要么将另一个bio结构链接到请求中,从而“扩展”该请求。可能存在新数据与请求中已存在的数据物理相邻的情况。请求描述符的bio字段指向请求中的第一个bio结构,而biotail字段则指向最后一个bio结构。rq_for_each_bio宏执行一个循环,从而遍历请求中的所有bio结构。
请求描述符中的几个字段值可能是动态变化的。例如,一旦bio中引用的数据块全部传送完毕,bio字段立即更新从而指向请求链表中的下一个bio。在此期间,新的bio可能被加入到请求链表的尾部,所以biotail的值也可能改变。当磁盘数据块正在传送时,请求描述符的其它几个字段的值由I/O调度程序或设备驱动程序修改。
例如,nr_sectors存放整个请求还需传送的扇区数,current_nr_sectors 存放当前bio结构中还需传送的扇区数。flags中存放了很多标志,如表14-8中所示。到目前为止,最重要的一个标志是REQ_RW,它确定数据传送的方向。
REQ_RW 数据传送的方向:READ(O)或WRITE(1)
REQ_FAILFAST 万一出错请求申明不再重试10操作
REQ_SOFTBARRIER 请求相当于I/O调度程序的屏障
REQ_HARDBARRIER 请求相当于I/O调度程序和设备驱动程序的屏障——应当在旧请求与新请求之间处理该请求
REQ_CMD 包含一个标准的读或写1/0数据传送的请求
REQ_NOMERGE 不允许扩展或与其它请求合并的请求
REQSTARTED 正处理的请求
REQ_DONTPREP 不调用请求队列中的prep_rq_fn方法预先准备把命令发送给 硬件设备
REQ_QUEUED 请求被标记——也就是说,与该请求相关的硬件设备可以同 时管理很多未完成数据的传送
REQ_PC 请求包含发送给硬件设备的直接命令
REQ_BLOCK_PC 与前一个标志功能相同,但发送的命令包含在bio结构中
REQ_SENSE 请求包含一个“sense”请求命令(SCSI和ATAPI设备使用)
REQ_FAILED 当请求中的sense或direct命令的操作与预期的不一致时设置 该标志
REQ_QUIET 万一I/O操作出错请求申明不产生内核消息
REQ_SPECIAL 请求包含对硬件设备的特殊命令(例如,重设驱动器)
REQ_DRIVE_CMD 请求包含对IDE磁盘的特殊命令
REQ_DRIVE_TASK 请求包含对IDE磁盘的特殊命令
REQ_DRIVE_TASKFILE 请求包含对IDE磁盘的特殊命令
REQ_PREEMPT 请求取代位于请求队列前面的请求(仅对IDE磁盘而言)
REQ_PM_SUSPEND 请求包含一个挂起硬件设备的电源管理命令
REQ_PM_RESUME 请求包含一个唤醒硬件设备的电源管理命令
REQ_PM_SHUTDOWN 请求包含一个切断硬件设备的电源管理命令
REQ_BAR_PREFLUSH 请求包含一个要发送给磁盘控制器的刷新队列命令
REQ_BAR_POSTFLUSH 请求包含一个已发送给磁盘控制器的刷新队列命令 对请求描述符的分配进行管理
在重负载和磁盘操作频繁的情况下,固定数目的动态空闲内存将成为进程想要把新请求加入请求队列q的瓶颈。为了解决这种问题,每个request_queue描述符包含一个request_list数据结构,其中包括:
- 一个指针,指向请求描述符的内存池。
- 两个计数器,分别用于记录分配给READ和WRITE请求的请求描述符数。
- 两个标志,分别用于标记为读或写请求的分配是否失败。
- 两个等待队列,分别存放了为获得空闲的读和写请求描述符而睡眠的进程。一个等待队列,存放等待一个请求队列被刷新(清空)的进程。
blk_get_request()函数试图从一个特定请求队列的内存池中获得一个空闲的请求描述符;如果内存区不足并且内存池已经用完,则要么挂起当前进程,要么返回NULL(如果不能阻塞内核控制路径)。如果分配成功,则将请求队列的request_list数据结构的地址存放在请求描述符的r1字段中。blk_put_request()函数则释放一个请求描述符;如果该描述符的引用计数器的值为0,则将描述符归还回它原来所在的内存池。
避免请求队列拥塞
每个请求队列都有一个允许处理的最大请求数。请求队列描述符的nr_requests字段存放了每个数据传送方向所允许处理的最大请求数。缺省情况下,一个队列至多有128个待处理读请求和128个待处理写请求。
如果待处理的读(写)请求数超过了nr_requests 值,那么通过设置请求队列描述符的queue_flags字段的QUEUE_FLAG_READFULL (QUEUE_FLAG_WRITEFULL)标志将该队列标记为已满,试图把请求加入到某个传送方向的可阻塞进程被放置到request_list结构所对应的等待队列中睡眠。一个填满的请求队列对系统性能有负面影响,因为它会强制许多进程去睡眠以等待I/O 数据传送的完成。因此,如果给定传送方向上的待处理请求数超过了存放在请求描述符的nr_congestion_on字段中的值(缺省值为113),那么内核认为该队列是拥塞的,并试图降低新请求的创建速率。
当待处理请求数小于nr_congestion_off的值(缺省值为111)时,拥塞的请求队列才变为不拥塞。blk_congestion_wait()函数挂起当前进程,直到所有请求队列都变为不拥塞或超时已到。
激活块设备驱动程序
正如我们在前面已经看到的一样,延迟激活块设备驱动程序有利于把相邻块的请求进行集中。这种延迟是通过所谓的设备插入和设备拔出技术来实现的。在块设备驱动程序被插入时,该驱动程序并不被激活,即使在驱动程序队列中有待处理的请求。blk_plug_device()函数的功能是插入一个块设备——更准确地说,插入到某个块设备驱动程序处理的请求队列中。
本质上,该函数接收一个请求队列描述符的地址q作为其参数。它设置q->queue_flags字段中的QUEUE_FLAG_PLUGGED位;然后,重新启动q->unplug_timer字段中的内嵌动态定时器。blk_remove_plug()则拔去一个请求队列q;清除QUEUE_FLAG_PLUGGED标志并取消q->unplug_timer动态定时器的执行。当“视线中”所有可合并的请求都被加入请求队列时,内核就会显式地调用该函数。此外,如果请求队列中待处理的请求数超过了请求队列描述符的unplug_thresh字段中存放的值(缺省值为4),那么I/O调度程序也会去掉该请求队列。
如果一个设备保持插入的时间间隔为q->unplug_delay(通常为3ms),那么说明由blk_plug_device()函数激活的动态定时器的时间已用完,因此就会执行blk_unplug_timeout()函数。因而,唤醒内核线程kblockd所操作的工作队列kblockd_workqueue。kblockd执行blk->unplug_work()函数,其地址存放在q->unplug_work结构中。接着,该函数会调用请求队列中的q->unplug_fn方法,通常该方法是由generic_unplug_device()函数实现的。
generic_unplug_device()函数的功能是拔出块设备:
- 首先,检查请求队列是否仍然活跃;
- 然后,调用blk_remove_plug()函数;
- 最后,执行策略例程request_fn方法来开始处理请求队列中的下一个请求。
IO调度算法
当向请求队列增加一条新的请求时,通用块层会调用I/O调度程序来确定请求队列中新请求的确切位置。I/O调度程序试图通过扇区将请求队列排序。如果顺序地从链表中提取要处理的请求,那么就会明显减少磁头寻道的次数,因为磁头是按照直线的方式从内磁道移向外磁道(反之亦然),而不是随意地从一个磁道跳跃到另一个磁道。这可以从电梯算法中得到启发,回想一下,电梯算法处理来自不同层的上下请求。电梯是往一个方向移动的;当朝一个方向上的最后一个预定层到达时,电梯就会改变方向而开始向相反的方向移动。因此,I/O调度程序也被称为电梯算法(elevator)。
在重负载情况下,严格遵循扇区号顺序的I/O调度算法运行的并不是很好。在这种情形下,数据传送的完成时间主要取决于磁盘上数据的物理位置。因此,如果设备驱动程序处理的请求位于队列的首部(小扇区号),并且拥有小扇区号的新请求不断被加入队列中,那么队列末尾的请求就很容易会饿死。因而I/O调度算法会非常复杂。
当前,Linux 2.6中提供了四种不同类型的I/O调度程序或电梯算法,分别为“预期(Anticipatory)”算法、“最后期限(Deadline)”算法、“CFQ(Complete Fairness Queueing,完全公平队列)”算法以及“Noop(No Operation)”算法。对大多数块设备而言,内核使用的缺省电梯算法可在引导时通过内核参数elevator=进行再设置,其中值可取下列任何一个:as、deadline、cfq和noop。如果没有给定引导参数,那么内核缺省使用“预期”I/O调度程序。总之,设备驱动程序可以用任何一个调度程序取代缺省的电梯算法;设备驱动程序也可以自己定制I/O调度算法,但是这种情况很少见。此外,系统管理员可以在运行时为一个特定的块设备改变I/O调度程序。例如,为了改变第一个IDE通道的主磁盘所使用的I/O调度程序,管理员可把一个电梯算法的名称写入sysfs特殊文件系统的/sys/block/hda/queue/scheduler文件中。
请求队列中使用的I/O调度算法是由一个elevator_t类型的elevator对象表示的;该对象的地址存放在请求队列描述符的elevator字段中。elevator对象包含了几个方法,它们覆盖了elevator所有可能的操作:链接和断开elevator,增加和合并队列中的请求,从队列中删除请求,获得队列中下一个待处理的请求等等。elevator对象也存放了一个表的地址,表中包含了处理请求队列所需的所有信息。而且,每个请求描述符包含一个elevator_private字段,该字段指向一个由I/O调度程序用来处理请求的附加数据结构。
现在我们从易到难简要地介绍一下四种I/O调度算法。注意,设计一个I/O调度程序与设计一个CPU调度程序很相似:启发算法和采用的常量值是测试和基准外延量的结果。一般而言,所有的算法都使用一个调度队列(dispatch queue),队列中包含的所有请求按照设备驱动程序应当处理的顺序进行排序——也即设备驱动程序要处理的下一个请求通常是调度队列中的第一个元素。
调度队列实际上是由请求队列描述符的queue_head 字段所确定的请求队列。几乎所有的算法都使用另外的队列对请求进行分类和排序。它们允许设备驱动程序将bio结构增加到已存在请求中,如果需要,还要合并两个“相邻的”请求。
“Noop”算法
这是最简单的I/O调度算法。它没有排序的队列:新的请求通常被插在调度队列的开头或末尾,下一个要处理的请求总是队列中的第一个请求。
“CFQ”算法
“CFQ(完全公平队列)”算法的主要目标是在触发I/O请求的所有进程中确保磁盘I/O 带宽的公平分配。为了达到这个目标,算法使用许多个排序队列,它们存放了不同进程发出的请求。
当算法处理一个请求时,内核调用一个散列函数将当前进程的线程组标识符(通常,它对应其PID,参见第三章“标识一个进程”一节)转换为队列的索引值;然后,算法将一个新的请求插入该队列的末尾。因此,同一个进程发出的请求通常被插入相同的队列中。为了再填充调度队列,算法本质上采用轮询方式扫描I/O输入队列,选择第一个非空队列,然后将该队列中的一组请求移动到调度队列的末尾。
“最后期限”算法
除了调度队列外,“最后期限”算法还使用了四个队列。其中的两个排序队列分别包含读请求和写请求,其中的请求是根据起始扇区数排序的。另外两个最后期限队列包含相同的读和写请求,但这是根据它们的“最后期限”排序的。引入这些队列是为了避免请求饿死,由于电梯策略优先处理与上一个所处理的请求最近的请求,因而就会对某个请求忽略很长一段时间,这时就会发生这种情况。请求的最后期限本质上就是一个超时定时器,当请求被传给电梯算法时开始计时。
缺省情况下,读请求的超时时间是500ms,写请求的超时时间是5s——读请求优先于写请求,因为读请求通常阻塞发出请求的进程。最后期限保证了调度程序照顾等待很长一段时间的那个请求,即使它位于排序队列的末尾。当算法要补充调度队列时,首先确定下一个请求的数据方向。如果同时要调度读和写两个请求,算法会选择“读”方向,除非该“写”方向已经被放弃很多次了(为了避免写请求饿死)。接下来,算法检查与被选择方向相关的最后期限队列:如果队列中的第一个请求的最后期限已用完,那么算法将该请求移到调度队列的末尾;也可以从超时的那个请求开始移动来自排序队列的一组请求。如果将要移动的请求在磁盘上物理相邻,那么组的长度会变长,否则就变短。
最后,如果没有请求超时,算法对来自于排序队列的最后一个请求之后的一组请求进行调度。当指针到达排序队列的末尾时,搜索又从头开始(“单方向算法”)。
“预期”算法
“预期”算法是Linux提供的最复杂的一种I/O调度算法。基本上,它是“最后期限”算法的一个演变,借用了“最后期限”算法的基本机制:两个最后期限队列和两个排序队列;I/O调度程序在读和写请之间交互扫描排序队列,不过更倾向于读请求。扫描基本上是连续的,除非有某个请求超时。读请求的缺省超时时间是125ms,写请求的缺省超时时间是250ms。但是,该算法还遵循一些附加的启发式准则:
- 有些情况下,算法可能在排序队列当前位置之后选择一个请求,从而强制磁头从后搜索。这种情况通常发生在这个请求之后的搜索距离小于在排序队列当前位置之后对该请求搜索距离的一半时。
- 算法统计系统中每个进程触发的I/O操作的种类。当刚刚调度了由某个进程p发出的一个读请求之后,算法马上检查排序队列中的下一个请求是否来自同一个进程p。如果是,立即调度下一个请求。否则,查看关于该进程p的统计信息:如果确定进程p可能很快发出另一个读请求,那么就延迟一小段时间(缺省大约为7ms)。
因此,算法预测进程p发出的读请求与刚被调度的请求在磁盘上可能是“近邻”。
向I/O调度程序发出请求
正如我们在本章前面的“提交请求”一节中所看到的,generic_make_request()函数调用请求队列描述符的make_request_fn方法向I/O调度程序发送一个请求。通常该方法是由__make_request()函数实现的;该函数接收一个request_queue类型的描述符q和一个bio结构的描述符bio作为其参数,然后执行如下操作:
如果需要,调用blk_queue_bounce()函数建立一个回弹缓冲区(参见后面)。如果回弹缓冲区被建立,__make_request()函数将对该缓冲区而不是原先的bio结构进行操作。
调用I/O调度程序的elv_queue_empty()函数检查请求队列中是否存在待处理请求。注意,调度队列可能是空的,但是I/O调度程序的其他队列可能包含待处理请求。如果没有待处理请求,那么调用blk_plug_device()函数插入请求队列,然后跳转到第5步。
插入的请求队列包含待处理请求。调用I/O调度程序的elv_merge()函数检查新的bio结构是否可以并入已存在的请求中。该函数将返回三个可能值:
- ELEVATOR_NO_MERGE:已经存在的请求中不能包含bio结构;这种情况下,跳转到第5步。
- 3.2. ELEVATOR_BACK_MERGE:bio结构可作为末尾的bio而插入到某个请求req中;这种情形下,函数调用q->back_merge_fn方法检查是否可以扩展该请求。如果不行,则跳转到第5步。否则,将bio描述符插入req链表的末尾并更新req的相应字段值。然后,函数试图将该请求与其后面的请求合并(新的bio可能填充在两个请求之间)。
- ELEVATOR_FRONT_MERGE:bio结构可作为某个请求req的第一个bio被插入;这种情形下,函数调用q->front_merge_fn方法检查是否可以扩展该请求。如果不行,则跳转到第5步。否则,将bio描述符插入req链表的首部并更新req的相应字段值。然后,试图将该请求与其前面的请求合并。
bio已经被并入存在的请求中,跳转到第7步终止函数。
bio必须被插入到一个新的请求中。分配一个新的请求描述符。如果没有空闲的内存,那么挂起当前进程,直到设置了bio->bi_rw中的BIO_RW_AHEAD标志, 该标志表明这个I/O操作是一次预读;在这种情形下,函数调用bio_endio()并终止:此时将不会执行数据传送。
初始化请求描述符中的字段。主要有:
- 根据bio描述符的内容初始化各个字段,包括扇区数、当前bio以及当前段。
- 设置flags字段中的REQ_CMD标志(一个标准的读或写操作)。
- 如果第一个bio段的页框存放在低端内存,则将buffer字段设置为缓冲区的线性地址。
- 将rq_disk字段设置为bio->bi_bdev->bd_disk的地址。
- 将bio插入请求链表。
- 将start_time字段设置为jiffies的值。
所有操作全部完成。但是,在终止之前,检查是否设置了bio->bi_rw中的BIO_RW_SYNC标志。如果是,则对“请求队列”调用generic_unplug_device()函数以卸载设备驱动程序。
函数终止。
如果在调用make_request()函数之前请求队列不是空的,那么说明该请求队列要么已经被拔掉过,要么很快将被拔掉——因为每个拥有待处理请求的插入请求队列q都有一个正在运行的动态定时器q->unplug_timer。另一方面,如果请求队列是空的,则make_request()函数插入请求队列。或迟(最坏的情况是当拔出的定时器到期了)或早(从__make_request()中退出时,如果设置了bio的BIO_RW_SYNC标志),该请求队列都会被拔掉。任何情形下,块设备驱动程序的策略例程最后都将处理调度队列中的请求。
blk_queue_bounce()函数
blk_queue_bounce()函数的功能是查看q->bounce_gfp中的标志以及q->bounce_pfn 中的阈值,从而确定回弹缓冲区(buffer bouncing)是否是必需的。通常当请求中的一些缓冲区位于高端内存而硬件设备不能访问它们时发生这种情况。
ISA总线使用的老式DMA方式只能处理24位的物理地址。因此,回弹缓冲区的上限设为16 MB,也就是说,页框号为4096。然而,当处理老式设备时,块设备驱动程序通常不依赖回弹缓冲区;相反,它们更倾向于直接在ZONE_DMA内存区中分配DMA缓冲区。如果硬件设备不能处理高端内存中的缓冲区,则blk_queue_bounce()函数检查bio中的一些缓冲区是否真的必须是回弹的。
如果是,则将bio描述符复制一份,接着创建一个回弹bio;然后,当段中的页框号等于或大于q->bounce_pfn的值时,执行下列操作
- 根据分配的标志,在ZONE_NORMAL或ZONE_DMA内存区中分配一个页框。
- 更新回弹bio中段的bv_page字段的值,使其指向新页框的描述符。
- 如果bio->bio_rw代表一个写操作,则调用kmap()临时将高端内存页映射到内核地址空间中,然后将高端内存页复制到低端内存页上,最后调用kunmap()释放该映射。然后blk_queue_bounce()函数设置回弹bio中的BIO_BOUNCED标志,为其初始化一个特定的bi_end_io方法,最后将它存放在回弹bio的bi_private字段中,该字段是指向初始bio的指针。当在回弹bio上的I/O数据传送终止时,函数执行bi_end_io方法将数据复制到高端内存区中(仅适合读操作),并释放该回弹bio结构。
块设备驱动程序
块设备驱动程序是Linux块子系统中的最底层组件。它们从I/O调度程序中获得请求,然后按要求处理这些请求。当然,块设备驱动程序是设备驱动程序模型的组成部分。因此,每个块设备驱动程序对应一个device_driver类型的描述符;此外,设备驱动程序处理的每个磁盘都与一个device描述符相关联。但是,这些描述符没有什么特别的:块I/O子系统必须为系统中的每个块设备存放附加信息。
块设备
一个块设备驱动程序可能处理几个块设备。例如,IDE设备驱动程序可以处理几个IDE 磁盘,其中的每个都是一个单独的块设备。而且,每个磁盘通常是被分区的,每个分区又可以被看作是一个逻辑块设备。很明显,块设备驱动程序必须处理在块设备对应的块设备文件上发出的所有VFS系统调用。每个块设备都是由一个block_device结构的描述符来表示的,其字段如表14-9所示。
所有的块设备描述符被插入一个全局链表中,链表首部是由变量all_bdevs表示的;链表链接所用的指针位于块设备描述符的bd_list字段中。如果块设备描述符对应一个磁盘分区,那么bd_contains字段指向与整个磁盘相关的块设备描述符,而bd_part字段指向hd_struct分区描述符。否则,若块设备描述符对应整个磁盘,那么bd_contains字段指向块设备描述符本身,bd_part_count字段用于记录磁盘上的分区已经被打开了多少次。bd_holder字段存放代表块设备持有者的线性地址。持有者并不是进行I/O数据传送的块设备驱动程序;准确地说,它是一个内核组件,使用设备并拥有独一无二的特权(例如,它可以自由使用块设备描述符的bd_private字段)。
典型地,块设备的持有者是安装在该设备上的文件系统。当块设备文件被打开进行互斥访问时,另一个普遍的问题出现了:持有者就是对应的文件对象。bd_claim()函数将bd_holder字段设置为一个特定的地址;相反,bd_release()函数将该字段重新设置为NULL。然而,值得注意的是,同一个内核组件可以多次调用bd_claim()函数,每调用一次都增加bd_holders的值。为了释放块设备,内核组件必须调用bd_release()函数bd_holders次。图14-3对应的是一个整盘,它说明了块设备描述符是如何被链接到块I/O子系统的其他重要数据结构上的。
struct block_device {
dev_t bd_dev;
struct inode * bd_inode; /*分区结点*/
int bd_openers;
struct semaphore bd_sem; /*打开/关闭锁*/
struct semaphore bd_mount_sem; /* 加载互斥锁*/
struct list_head bd_inodes;
void * bd_holder;
int bd_holders;
struct block_device * bd_contains;
unsigned bd_block_size;//分区块大小
struct hd_struct * bd_part;
unsigned bd_part_count;//打开次数
int bd_invalidated;
struct gendisk * bd_disk;
struct list_head bd_list;
struct backing_dev_info *bd_inode_backing_dev_info;
unsigned long bd_private;
}; 访问块设备
当内核接收一个打开块设备文件的请求时,必须首先确定该设备文件是否已经是打开的。事实上,如果文件已经是打开的,内核就没有必要创建并初始化一个新的块设备描述符;相反,内核应该更新这个已经存在的块设备描述符。然而,真正的复杂性在于具有相同主设备号和次设备号但有不同路径名的块设备文件被VFS看作不同的文件,但是它们实际上指向同一个块设备。因此,内核无法通过简单地在一个对象的索引节点高速缓存中检查块设备文件的存在就确定相应的块设备已经在使用。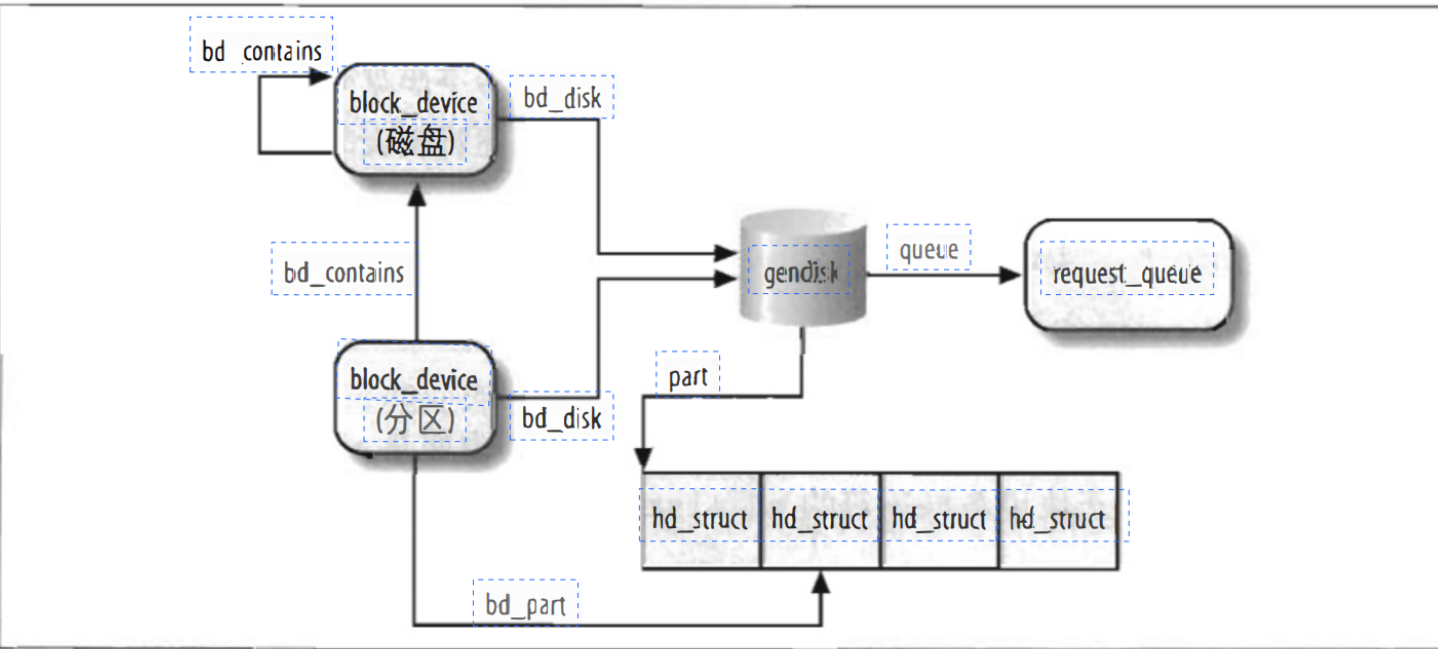
主、次设备号和相应的块设备描述符之间的关系是通过bdev特殊文件系统来维护的。每个块设备描述符都对应一个bdev特殊文件:块设备描述符的bd_inode字段指向相应的bdev索引节点;而该索引节点则将块设备的主、次设备号和相应描述符的地址进行编码。bdget()接收块设备的主设备号和次设备号作为其参数:在bdev文件系统中查寻相关的索引节点;如果不存在这样的节点,那么就分配一个新索引节点和新块设备描述符。在任何情形下,函数都返回一个与给定主、次设备号对应的块设备描述符的地址。一旦找到了块设备的描述符,那么内核通过检查bd_openers字段的值来确定块设备当前是否在使用:如果值是正的,说明块设备已经在使用(可能通过不同的设备文件)。同时内核也维护一个与已打开的块设备文件对应的索引节点对象的链表。该链表存放在块设备描述符的nd_inodes字段中;索引节点对象的i_devices字段存放用于链接链表中的前后元素的指针。
注册和初始化设备驱动程序
现在我们来说明一下为一个块设备设计一个新的驱动程序所涉及的基本步骤。显然,其描述是比较简单的,但是理解何时并怎样初始化块I/O子系统使用的主要数据结构是很有用的。我们省略了所有块设备驱动程序需要的但在第十三章中已经讲过的步骤。例如,我们跳过了注册一个驱动程序本身的所有步骤。通常,块设备属于一个诸如PCI或SCSI这样的标准总线体系结构,内核提供了相应的辅助函数,作为一个辅助作用,就是在驱动程序模型中注册驱动程序。
自定义驱动程序描述符
首先,设备驱动程序需要一个foo_dev_t类型的自定义描述符foo,它拥有驱动硬件设备所需的数据。该描述符存放每个设备的相关信息,例如操作设备时使用的I/O端口、设备发出中断的IRQ线、设备的内部状态等等。同时它也包含块I/O子系统所需的一些字段:
struct foo_dev_t {
[...]
spinlock_t lock;
struct gendisk *gd;
[...]
} foo;lock字段是用来保护foo描述符中字段值的自旋锁;通常将其地址传给内核辅助函数,从而保护对驱动程序而言特定的块I/O子系统的数据结构。gd字段是指向gendisk描述符的指针,该描述符描述由这个驱动程序处理的整个块设备(磁盘)。
预订主设备号
设备驱动程序必须自己预订一个主设备号。传统上,该操作通过调用register_blkdev()函数完成:
err = register_blkdev(FOO_MAJOR, "foo");
if(err) goto error_major_is_busy;该函数类似于第十三章的“分配设备号”一节中出现的register_chrdev()函数:预订主设备号FOO_MAJOR并将设备名称foo赋给它。注意,这不能分配次设备号范围,因为没有类似的register_chrdev_region()函数;此外,预订的主设备号和驱动程序的数据结构之间也没有建立链接。register_blkdev()函数产生的唯一可见的效果是包含一个新条目,该条目位于/proc/devices特殊文件的已注册主设备号列表中。
初始化自定义描述符
在使用驱动程序之前必须适当地初始化foo描述符中的所有字段。为了初始化与块I/O子系统相关的字段,设备驱动程序主要执行如下操作:
spin_lock_init(&foo.lock);
foo.gd = alloc_disk(16);
if(!foo.gd) goto error_no_gendisk;驱动程序首先初始化自旋锁,然后分配一个磁盘描述符。正如在前面的图14-3中所看到的,gendisk结构是块I/O子系统中最重要的数据结构,因为它涉及许多其他的数据结构。alloc_disk()函数也分配一个存放磁盘分区描述符的数组。该函数所需要的参数是数组中hd_struct结构的元素个数;16表示驱动程序可以支持16个磁盘,而每个磁盘可以包含15个分区(0分区不使用)。
初始化gendisk描述符
接下来,驱动程序初始化gendisk描述符的一些字段:
foo.gd->private_data =&foo;
foo.gd->major = FOO_MAJOR;
foo.gd->first_minor = 0;
foo.gd->minors = 16;
set_capacity(foo.gd,foo_disk_capacity_in_sectors);strcpy(foo.gd->disk_name,“foo”);
foo.gd->fops =&foo_ops;foo描述符的地址存放在gendisk结构的private_data字段中,因此被块I/O子系统当作方法调用的低级驱动程序函数可以迅速地查找到驱动程序描述符如果驱动程序可以并发地处理多个磁盘,那么这种方式可以提高效率。set_capacity()函数将capacity字段初始化为以512字节扇区为单位的磁盘大小,这个值也可能在探测硬件并询问磁盘参数时确定
初始化块设备操作表
gendisk描述符的fops字段被初始化为自定义的块设备方法表的地址。类似地,设备驱动程序的foo_ops表中包含设备驱动程序的特有函数。例如,如果硬件设备支持可移动磁盘,通用块层将调用media_changed方法检查自从最后一次安装或打开该块设备以来磁盘是否被更换。通常通过向硬件控制器发送一些低级命令来完成该检查,因此,每个设备驱动程序所实现的media_changed方法都是不同的。类似地,仅当通用块层不知道如何处理ioctl命令时才调用ioctl方法。例如,当一个ioctl()系统调用询问磁盘构造时,也就是磁盘使用的柱面数、磁道数、扇区数以及磁头数时,通常调用该方法。因此,每个设备驱动程序所实现的ioctl方法也都是不同的。
分配和初始化请求队列
我们勇敢的设备驱动程序设计者现在将要建立一个请求队列,该队列用于存放等待处理的请求。可以通过如下操作轻松地建立请求队列:
foo.gd->rq = blk_init_queue(foo_strategy,&foo.lock);
if(!foo.gd->rq) goto error_no_request_queue;
blk_queue_hardsect_size(foo.gd->rd, foo_hard_sector_size);
blk_queue_max_sectors(foo.gd->rd, foo_max_sectors);
blk_queue_max_hw_segments(foo.gd->rd, foo_max_hw_segments);
blk_queue_max_phys_segments(foo.gd->rd, foo_max_phys_segments);blk_init_queue()函数分配一个请求队列描述符并将其中许多字段初始化为缺省值。它接收的参数为设备描述符的自旋锁的地址(foo.gd->rq->queue_lock字段值)和设备驱动程序的策略例程(参见下一节“策略例程”)的地址(foo.gd->rq->request_fn字段值)。
该函数也初始化foo.gd->rq->elevator字段,并强制驱动程序使用缺省的I/O 调度算法。如果设备驱动程序想要使用其他的调度算法,可在稍后覆盖elevator字段的地址。接下来,使用几个辅助函数将请求队列描述符的不同字段设为设备驱动程序的特征值(参考表14-6中的类似字段)。
设置中断处理程序
正如第四章的“I/O中断处理”一节中所介绍的,设备驱动程序需要为设备注册IRQ线。这可以通过如下操作完成:
request_irq(foo_irq, foo_interrupt, SA_INTERRUPTISA_SHIRQ, "foo", NULL);foo_interrupt()函数是设备的中断处理程序;
注册磁盘
最后,设备驱动程序的所有数据结构已经准备好了:初始化阶段的最后一步就是“注册”和激活磁盘。这可以简单地通过执行下面的操作完成:add_disk(foo.gd);
add_disk()函数接收gendisk描述符的地址作为其参数,主要执行下列操作:
- 设置gd->flags的GENHD_FL_UP标志。
- 调用kobj_map()建立设备驱动程序和设备的主设备号(连同相关范围内的次设备号)之间的连接(注意,在这种情况下,kobject映射域由bdev_map变量表示)。
- 注册设备驱动程序模型的gendisk描述符中的kobject结构,它作为设备驱动程序处理的一个新设备(例如/sys/block/foo)。
- 如果需要,扫描磁盘中的分区表;对于查找到的每个分区,适当地初始化foo.gd->part数组中相应的hd_struct描述符。同时注册设备驱动程序模型中的分区(例如/sys/block/foo/foo1)。
- 注册设备驱动程序模型的请求队列描述符中内嵌的kobject结构(例如/sys/block/foo/queue)。一旦add_disk()返回,设备驱动程序就可以工作了。进行初始化的函数终止;策略例程和中断处理程序开始处理I/O调度程序传送给设备驱动程序的每个请求。
策略例程
策略例程是块设备驱动程序的一个函数或一组函数,它与硬件块设备之间相互作用以满足调度队列中所汇集的请求。通过请求队列描述符中的request_fn方法可以调用策略例程——例如前面一节介绍的foo_strategy()函数,I/O调度程序层将请求队列描述符q的地址传递给该函数。如前所述,在把新的请求插入到空的请求队列后,策略例程通常才被启动。只要块设备驱动程序被激活,就应该对队列中的所有请求都进行处理,直到队列为空才结束。策略例程的简单实现如下:对于调度队列中的每个元素,与块设备控制器相互作用共同为请求服务,等待直到数据传送完成,然后把已经服务过的请求从队列中删除,继续处理调度队列中的下一个请求。这种实现效率并不高。即使假设可以使用DMA传送数据,策略例程在等待I/O操作完成的过程中也必须自行挂起。也就是说策略例程应该在一个专门的内核线程上执行(我们不想处罚毫不相关的用户进程)。而且,这样的驱动程序也不能支持可以一次处理多个I/O数据传送的现代磁盘控制器。因此,很多块设备驱动程序都采用如下策略:
- 策略例程处理队列中的第一个请求并设置块设备控制器,以便在数据传送完成时可以产生一个中断。然后策略例程就终止。
- 当磁盘控制器产生中断时,中断控制器重新调用策略例程(通常是直接的,有时也通过激活一个工作队列)。策略例程要么为当前请求再启动一次数据传送,要么当请求的所有数据块已经传送完成时,把该请求从调度队列中删除然后开始处理下一个请求。
请求是由几个bio结构组成的,而每个bio结构又是由几个段组成的。基本上,块设备驱动程序以以下两种方式使用DMA: - 驱动程序建立不同的DMA传送方式,为请求的每个bio结构中的每个段进行服务。
- 驱动程序建立一种单独的分散-聚集DMA传送方式,为请求的所有bio中的所有段服务。
最后,设备驱动程序策略例程的设计依赖块控制器的特性。每个物理块设备都有不同于其他物理块设备的固有特性(例如,软盘驱动程序把磁道上的块分组为磁道,一次单独的I/O操作传送整个磁道),因此对设备驱动程序怎样为每个请求进行服务而做一般假设并没有多大意义。
在我们的例子中,foo_strategy()策略例程应该执行以下操作:
- 通过调用I/O调度程序的辅助函数elv_next_request()从调度队列中获取当前的请求。如果调度队列为空,就结束这个策略例程:req = elv_next_request(q); if(!req) return;
- 执行blk_fs_request宏检查是否设置了请求的REQ_CMD标志,也即,请求是否包含一个标准的读或写操作:
if(!blk_fs_request(req))
goto handle_special_request;- 如果块设备控制器支持分散-聚集DMA,那么对磁盘控制器进行编程,以便为整个请求执行数据传送并在传送完成时产生一个中断。blk_rq_map_sg()辅助函数返回一个可以立即被用来启动数据传送的分散-聚集链表。
- 否则,设备驱动程序必须一段一段地传送数据。在这种情形下,策略例程执行rq_for_each_bio和bio_for_each_segment两个宏,分别遍历bio链表和每个bio中的段链表。
rq_for_each_bio(bio, rq)
bio_for_each_segment(bvec, bio, i) {
/* transfer the i-th segment bvec */
local_irq_save(flags);
addr = kmap_atomic(bvec->bv_page, KM_BIO_SRC_IRQ);
foo_start_dma_transfer(addr + bvec->bv_offset, bvec->bv_len);
kunmap_atomic(bvec->bv_page, KM_BIO_SRC_IRQ);
local_irq_restore(flags);如果要传送的数据在高端内存中,那么kmap_atomic()和kunmap_atomic()两个函数就是必需的。foo_start_dma_transfer()函数对硬件设备进行编程,以便启动DMA数据传送并在I/O操作完成时产生一个中断。然后返回。
中断处理程序
块设备驱动程序的中断处理程序是在DMA数据传送结束时被激活的。它检查是否已经传送完请求的所有数据块。如果是,中断处理程序就调用策略例程处理调度队列中的下一个请求。否则,中断处理程序更新请求描述符的相应字段并调用策略例程处理还没有完成的数据传送。我们的设备驱动程序foo的中断处理程序的一个典型片段如下:
irqreturn_t foo_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
struct foo_dev_t *p =(struct foo_dev_t *)dev_id;
struct request_queue *rq= p->gd->rq;
[...]
if(!end_that_request_first(rq,uptodate,nr_sectors)){
blkdev_dequeue_request(rq);
end_that_request_last(rq);
}
rq->request_fn(rq);
[...]
return IRQ_HANDLED;
}end_that_request_first()和end_that_request_last()两个函数共同承担结束一个请求的任务。end_that_request_first()函数接收的参数为一个请求描述符、一个指示DMA数据传送成功完成的标志以及DMA所传送的扇区数(end_that_request_chunk()函数类似,只不过该函数接收的是传送的字节数而不是扇区数)。本质上,它扫描请求中的bio 结构以及每个bio中的段,然后采用如下方式更新请求描述符的字段值:
- 修改bio字段使其指向请求中的第一个未完成的bio结构。
- 修改未完成bio结构的bi_idx字段使其指向第一个未完成的段。
- 修改未完成段的bv_offset和bv_len两个字段使其指定仍需传送的数据。该函数也在每个已经完成数据传送的bio结构上调用bio_endio()函数。如果已经传送完请求中的所有数据块,那么end_that_request_first()返回0;否则返回1。如果返回值是1,则中断处理程序重新调用策略例程,继续处理该请求。否则,中断处理程序把请求从请求队列中删除(主要由blkdev_dequeue_request()完成),然后调用end_that_request_last()辅助函数,并再次调用策略例程处理调度队列中的下一个请求。end_that_request_last()函数的功能是更新一些磁盘使用统计数,把请求描述符从I/O调度程序rq->elevator的调度队列中删除,唤醒等待请求描述符完成的任一睡眠进程,并释放删除的那个描述符。
打开块设备文件
通过描述打开一个块设备文件时VFS所执行的操作,我们将总结本章的内容。每当一个文件系统被映射到磁盘或分区上时,每当激活一个交换分区时,每当用户态进程向块设备文件发出一个open()系统调用时,内核都会打开一个块设备文件。在所有情况下,内核本质上执行相同的操作:寻找块设备描述符(如果块设备没有在使用,那么就分配一个新的描述符),为即将开始的数据传送设置文件操作方法。
open <-> blkdev_open()release <-> blkdev_close()llseek <-> block_llseek()read <-> generic_ file_readwrite <->blkdev_file_write()aio_read <-> generic_file_aio_ read()aio_write <-> blkdev_file_aio_write()mmap <-> generic_file mmap()fsync <-> block fsync()ioctl <-><-> block ioctl()compat_ioctl <-> compat_blkdev_ioctlo()readv <-> generic_file_readv()writev <-> generic_file_write_no_lock()sendfile <-> generic_file_sendfile()
我们仅仅考虑open方法,它由dentry_open()函数调用。blkdev_open()接收inode和filp作为其参数,它们分别存放了索引节点和文件对象的地址;该函数本质上执行下列操作:
执行bd_acquire(inode)从而获得块设备描述符bdev的地址。该函数接收索引节点对象的地址并执行下列主要步骤:
- 检查索引节点对象的inode->i_bdev字段是否不为NULL;如果是,表明块设备文件已经打开了,该字段存放了相应块描述符的地址。在这种情况下,增加与块设备相关联的bdev特殊文件系统的inode->i_bdev->bd_inode索引节点的引用计数器的值,并返回描述符inode->i_bdev的地址。
- 块设备文件没有被打开的情况。根据块设备文件的主设备号和次设备号,执行bdget( inode->i_rdev)获取块设备描述符的地址。如果描述符不存在,bdget()就分配一个;但是,要注意的是描述符可能已经存在,例如其他块设备文件已经访问了该块设备。
- 将块设备描述符的地址存放在inode->i_bdev中,以便加速将来对相同块设备文件的打开操作。
- 将inode->i_mapping字段设置为bdev索引节点中相应字段的值。该字段指向地址空间对象。
- 把索引节点插入到由bdev->bd_inodes确立的块设备描述符的已打开索引节点链表中。
- 返回描述符bdev的地址。
将filp->i_mapping字段设置为inode->i_mapping的值(参见前面的第1d步)。
获取与这个块设备相关的gendisk描述符的地址:disk = get_gendisk(bdev->bd_dev, &part);如果被打开的块设备是一个分区,则返回的索引值存放在本地变量part中;否则,part为0。get_gendisk()函数在kobject映射域bdev_map上简单地调用kobj_lookup()来传递设备的主设备号和次设备号。
如果bdev->bd_openers的值不等于0,表明块设备已经被打开了。检查bdev->bd_contains字段:
- 如果值等于bdev,那么块设备是一个整盘:调用块设备方法bdev->bd_disk->fops->open(如果定义了),然后检查bdev->bd_invalidated字段的,如果需要,调用rescan_partitions()函数。
- 如果不等于bdev,那么块设备是一个分区:增加bdev->bd_contains->bd_part_count计数器的值。然后跳到第8步。
这里块设备是第一次被访问。初始化bdev->bd_disk为gendisk描述符的地址disk。
如果块设备是一个整盘(part等于0),则执行下列子步骤:
- 如果定义了disk->fops->open块设备方法,就执行它:该方法是由块设备驱动程序定义的定制函数,它执行任何特定的最后一分钟初始化。
- 从disk->queue请求队列的hardsect_size字段中获取扇区大小(字节数),使用该值适当地设置bdev->bd_block_size和bdev->bd_inode->i_blkbits两个字段。同时用从disk->capacity中计算来的磁盘大小设置bdev->bd_inode->i_size字段。
- 如果设置了bdev->bd_invalidated标志,那么调用rescan_partitions()扫描分区表并更新分区描述符。该标志是由check_disk_change块设备方法设置的,仅适用于可移动设备。
否则如果块设备是一个分区,则执行下列子步骤:
- 再次调用bdget()——这次是传递disk->first_minor次设备号——获取整盘的块描述符地址whole。
- 对整盘的块设备描述符重复第3步~第6步,如果需要则初始化该描述符。
- 将bdev->bd_contains设置为整盘描述符的地址。
- 增加whole->bd_part_count的值从而说明磁盘分区上新的打开操作。
- 用disk->part[part - 1]中的值设置bdev->bd_part;它是分区描述符hd_struct的地址。同样,执行kobject_get(&bdev->bd_part->kobj)增加分区引用计数器的值。
- 与第6.2步中的一样,设置索引节点中表示分区大小和扇区大小的字段。
增加bdev->bd_openers计数器的值。
如果块设备文件以独占方式被打开(设置了filp->f_flags中的O_EXCL标志),那么调用bd_claim( bdev, filp)设置块设备的持有者。万一出错——块设备已经有一个拥有者——释放该块设备描述符并返回一个错误码-EBUSY。
返回0(成功)终止。
blkdev_open()函数一旦终止,open()系统调用如往常一样继续进行。对已打开的文件上将来发出的每个系统调用都将触发一个缺省的块设备文件操作。
访问文件
五种常见的模式
- 规范模式
规范模式下文件打开后,标志O_SYNC与0_DIRECT清0,而且它的内容是由系统调用read()和write()来存取。系统调用read()将阻塞调用进程,直到数据被拷贝进用户态地址空间(内核允许返回的字节数少于要求的字节数)。但系统调用write()不同,它在数据被拷贝到页高速缓存(延迟写)后就马上结束。这会在“读写文件”这一节详细阐述。 - 同步模式
同步模式下文件打开后,标志0_SYNC置1或稍后由系统调用fcntl()对其置1。这个标志只影响写操作(读操作总是会阻塞),它将阻塞调用进程,直到数据被有效地写入磁盘。这也会在“读写文件”这一节详细阐述。 - 内存映射模式
内存映射模式下文件打开后,应用程序发出系统调用mmap()将文件映射到内存中。因此,文件就成为RAM中的一个字节数组,应用程序就可以直接访问数组元素,而不需用系统调用read()、write()或lseek()。这将在“内存映射”这一节详细阐述。 - 直接I/O模式
直接I/O模式下文件打开后,标志0_DIRECT置1。任何读写操作都将数据在用户态地址空间与磁盘间直接传送而不通过页高速缓存。这将在“直接I/O传送”这一节详细阐述。(标志O_SYNC和O_DIRECT的值可以有四种组合。) - 异步模式
异步模式下,文件的访问可以有两种方法,即通过一组POSIX APl或Linux特有的系统调用来实现。所谓异步模式就是数据传输请求并不阻塞调用进程,而是在后台执行,同时应用程序继续它的正常运行。这将在“异步I/O”这一节详细阐述。
读写文件
在第十二章的“read()和write()系统调用”一节中已经说明了read()和write()系统调用是如何实现的。相应的服务例程最终会调用文件对象的read和write方法,这两个方法可能依赖文件系统。对磁盘文件系统来说,这些方法能够确定正被访问的数据所在物理块的位置,并激活块设备驱动程序开始数据传送。读文件是基于页的,内核总是一次传送几个完整的数据页。如果进程发出read()系统调用来读取一些字节,而这些数据还不在RAM中,那么,内核就要分配一个新页框,并使用文件的适当部分来填充这个页,把该页加入页高速缓存,最后把所请求的字节拷贝到进程地址空间中。
对于大部分文件系统来说,从文件中读取一个数据页就等同于在磁盘上查找所请求的数据存放在哪些块上。只要这个过程完成了,内核就可以通过向通用块层提交适当的I/O操作来填充这些页。事实上,大多数磁盘文件系统的read方法是由名为generic_file_read()的通用函数实现的。
对基于磁盘的文件来说,写操作的处理相当复杂,因为文件大小可以改变,因此内核可能会分配磁盘上的一些物理块。当然,这个过程到底如何实现要取决于文件系统的类型。不过,很多磁盘文件系统是通过通用函数generic_file_write()实现它们的write方法的。这样的文件系统如Ext2、System V/Coherent/Xenix及Minix。另一方面,还有几个文件系统(如日志文件系统和网络文件系统)通过自定义的函数实现它们的write方法。
从文件中读取数据
让我们讨论一下generic_file_read()函数,该函数实现了几乎所有磁盘文件系统中的普通文件及任何块设备文件的read方法。该函数作用于以下参数:
filp:文件对象的地址
buf:用户态线性区的线性地址,从文件中读出的数据必须存放在这里
count:要读取的字符个数
ppos:指向一个变量的指针,该变量存放读操作开始处的文件偏移量(通常为filp文件对象的f_pos字段) 第一步,函数初始化两个描述符。第一个描述符存放在类型为iovec的局部变量local_iov 中;它包含用户态缓冲区的地址(buf)与长度(count),该缓冲区用来存放待读文件中的数据。第二个描述符存放在类型为kiocb的局部变量kiocb中;它用来跟踪正在运行的同步和异步I/O操作的完成状态。函数generic_file_read()通过执行宏init_sync_kiocb来初始化描述符kiocb,并设置一个同步操作对象的有关字段。具体地说就是,该宏设置ki_key字段为KIOCB_SYNC_KEY、ki_filp字段为filp、ki_obj字段为current。然后,generic_file_read()调用__generic_file_aio_read()并将刚填完的iovec 和kiocb描述符地址传给它。后面这个函数返回一个值,这个值通常就是从文件有效读入的字节数。generic_file_read()返回值后结束。
函数_generic_file_aio_read()是所有文件系统实现同步和异步读操作所使用的通用例程。该函数接受四个参数:
- kiocb描述符的地址iocb,
- iovec描述符数组的地址iov、
- 数组的长度
- 存放文件当前指针的一个变量的地址ppos。
iovec描述符数组被函数generic_file_read()调用时只有一个元素,该元素描述待接收数据的用户态缓冲区。
我们现在来说明函数__generic_file_aio_read()的操作。为简单起见,我们只针对最常见的情形,即对页高速缓存文件的系统调用read()所引发的同步操作。本章后面我们会阐述该函数执行的其他情形。同样,我们不讨论如何对错误和异常的处理。
generic_file_read该函数执行的步骤如下:
- 调用access_ok()来检查iovec描述符所描述的用户态缓冲区是否有效。因为起始地址和长度已经从sys_read()服务例程得到,因此在使用前需要对它们进行检查(参见第十章“验证参数”一节)。如果参数无效,则返回错误代码-EFAULT。
- 建立一个读操作描述符,也就是一个read_descriptor_t类型的数据结构。该结构存放与单个用户态缓冲相关的文件读操作的当前状态。该描述符的字段参见表16-2。
- 调用函数do_generic_file_read(),传送给它文件对象指针filp、文件偏移量指针ppos、刚分配的读操作描述符的地址和函数file_read_actor()的地址(后面还会阐述)。
- 返回拷贝到用户态缓冲区的字节数,即read_descriptor_t数据结构中written字段的值。
函数do_generic_file_read()
从磁盘读入所请求的页并把它们拷贝到用户态缓冲区。具体执行如下步骤:
获得要读取的文件对应的address_space对象;它的地址存放在filp->f_mapping。
获得地址空间对象的所有者,即索引节点对象,它将拥有填充了文件数据的页面。它的地址存放在address_space对象的host字段中。如果所读文件是块设备文件,那么所有者就不是由filp->f_dentry->d_inode所指向的索引节点对象,而是bdev特殊文件系统中的索引节点对象。
把文件看作细分的数据页(每页4096字节),并从文件指针*ppos导出第一个请求字节所在页的逻辑号,即地址空间中的页索引,并把它存放在index局部变量中。也把第一个请求字节在页内的偏移量存放在offset局部变量中。
开始一个循环来读入包含请求字节的所有页,要读数据的字节数存放在read_descriptor_t描述符的count字段中。在一次单独的循环期间,函数通过执行下列的子步骤来传送一个数据页:
- 如果index*4096+offset超过存放在索引节点对象的i_size字段中的文件大小,则从循环退出,并跳到第5步。
- 调用cond_resched()来检查当前进程的标志TIF_NEED_RESCHED。如果该标志置位,则调用函数schedule()。
- 如果有预读的页,则调用page_cache_readahead()读入这些页面。
- 调用find_get_page(),并传入指向address_space对象的指针及索引值作为参数;它将查找页高速缓存以找到包含所请求数据的页描述符(如果有的话)。
- 如果find_get_page()返回NULL指针,则所请求的页不在页高速缓存中。如果这样,它将执行如下步骤:
- 调用handle_ra_miss()来调整预读系统的参数。
- 分配一个新页。
- 调用add_to_page_cache()插入该新页描述符到页高速缓存中。记住该函数将新页的PG_locked标志置位。
- 调用lru_cache_add()插入新页描述符到LRU链表。
- 跳到第4j步,开始读文件数据。
如果函数已运行至此,说明页已经位于页高速缓存中。检查标志PG_uptodate;如果置位,则页所存数据是最新的,因此无需从磁盘读数据。跳到第4m步。
页中的数据是无效的,因此必须从磁盘读取。函数通过调用lock-page()函数获取对页的互斥访问。如果PG_locked已经置位,则lock_page()阻塞当前进程直到标志被清0。
现在页已由当前进程锁定。然而,另一个进程也许会在上一步之前已从页高速缓存中删除该页,那么,它就要检查页描述符的mapping字段是否为NULL。在这种情形下,它将调用unlock_page()来解锁页,减少它的引用计数(find get_page()增加计数),并跳回第4a步来重读同一页。
如果函数已运行至此,说明页已被锁定且在页高速缓存中。再次检查标志PG_uptodate,因为另一个内核控制路径可能已经完成第4f步和第4g步的必要读操作。如果标志置位,则调用unlock_page()并跳至第4m来跳过读操作。
现在真正的I/O操作可以开始了,调用文件的address_spac对象之readpage方法。相应的函数会负责激活磁盘到页之间的I/O数据传输。我们以后再讨论该函数对普通文件与块设备文件都会做些什么。
如果标志PG_uptodate还没有置位,则它会等待直到调用lock_page()函数后页被有效读入。该页在第4g步中锁定,一旦读操作完成就被解锁。因此当前进程在I/O数据传输完成时才停止睡眠。
如果index超出文件包含的页数(该数是通过将inode对象的i_size字段的值除于4096得到的),那么它将减少页的引用计数器,并跳出循环至第5步。这种情况发生在这个正被本进程读的文件同时有其他进程正在删减它的时候。
将应被拷入用户态缓冲区的页中的字节数存放在局部变量nr中。这个值应该等于页的大小(4096字节),除非offset非0(这只发生在读请求书的首尾页时)或请求数据不全在该文件中。
调用mark_page_accessed()将标志PG_referenced或PG_active置位,从而表示该页正被访问并且不应该被换出。如果同一文件(或它的一部分)在do_generic_file_read()的后续执行中要读几次,那么这个步骤只在第一次读时执行。
现在到了把页中的数据拷贝到用户态缓冲区的时候了。为了这么做,o_generic_file_read()调用file_read_actor()函数,该函数的地址作为参数传递。
file_read_actor()执行下列步骤
- 调用kmap(),该函数为处于高端内存中的页建立永久的内核映射。
- 调用__copy_to_user(),该函数把页中的数据拷贝到用户态地址空间。注意,这个操作在访问用户态地址空间时如果有缺页异常将会阻塞进程。
- 调用kunmap()来释放页的任一永久内核映射。
- 更新read_descriptor_t描述符的count、written和buf字段。
- 根据传入用户态缓冲区的有效字节数来更新局部变量index和count。一般情况下,如果页的最后一个字节已拷贝到用户态缓冲区,那么index的值加1而offset的值清0;否则,index的值不变而offset的值被设为已拷贝到用户态缓冲区的字节数。
- 减少页描述符的引用计数器。
- 如果read_descriptor_t描述符的count字段不为0,那么文件中还有其他数据要读,跳至第4a步继续循环来读文件中的下一页数据。
所有请求的或者说可以读到的数据已读完。函数更新预读数据结构filp->f_ra来标记数据已被顺序从文件读入。
把index4096+offset值赋给ppos,从而保存以后调用read()和write()进行顺序访问的位置。
调用update_atime()把当前时间存放在文件的索引节点对象的i_atime字段中,并把它标记为脏后返回。
普通文件的readpage方法
我们从前一节看到,do_generic_file_read()反复使用readpage方法把一个个页从磁盘读到内存中。address_space对象的readpage方法存放的是函数地址,这种函数有效地激活从物理磁盘到页高速缓存的I/O数据传送。对于普通文件,这个字段通常指向调用mpage_readpage()函数的封装函数。例如,Ext3文件系统的readpage方法由下列函数实现:
int ext3_readpage(struct file *file,struct page *page)
{
return mpage_readpage(page,ext3_get_block);
} 需要封装函数是因为mpage_readpage()函数接收的参数为待填充页的页描述符page及有助于mpage_readpage()找到正确块的函数的地址get_block。封装函数依赖文件系统并因此能提供适当的函数来得到块。这个函数把相对于文件开始位置的块号转换为相对于磁盘分区中块位置的逻辑块号。当然,后一个参数依赖于普通文件所在文件系统的类型;在前面的例子中,这个参数就是ext3_get_block()函数的地址。
所传递的get_block函数总是用缓冲区首部来存放有关重要信息,如块设备(b_dev字段)、设备上请求数据的位置(b_blocknr字段)和块状态(b_state字段)。get_block函数依赖于文件系统,它的一个重要作用就是:确定文件中的下一块在磁盘上是否也是下一块。
函数mpage_readpage()在从磁盘读入一页时可选择两种不同的策略。如果包含请求数据的块在磁盘上是连续的,那么函数就用单个bio描述符向通用块层发出读I/O操作。而如果不连续,函数就对页上的每一块用不同的bio描述符来读。
mpage_readpage()函数执行下列步骤:
- 检查页描述符的PG_private字段:如果置位,则该页是缓冲区页,也就是该页与描述组成该页的块的缓冲区首部链表相关。这意味着该页过去已从磁盘读入过,而且页中的块在磁盘上不是相邻的。跳到第11步,用一次读一块的方式读该页。
- 得到块的大小(存放在page->mapping->host->i_blkbits索引节点字段),然后计算出访问该页的所有块所需要的两个值,即页中的块数及页中第一块的文件块号,也就是相对于文件起始位置页中第一块的索引。
- 对于页中的每一块,调用依赖于文件系统的get_block函数,作为参数传递过去,得到逻辑块号,即相对于磁盘或分区开始位置的块索引。页中所有块的逻辑块号存放在一个本地数组中。
- 在执行上一步的同时,检查可能发生的异常条件。具体有这几种情况:当一些块在磁盘上不相邻时,或某块落入“文件洞”内时,或一个块缓冲区已经由get_block函数写入时。那么跳到第11步,用一次读一块的方式读该页。
- 如果函数运行至此,说明页中的所有块在磁盘上是相邻的。然而,它可能是文件中的最后一页,因此页中的一些块可能在磁盘上没有映像。如果这样的话,它将页中相应的块缓冲区填上0;如果不是这样,它将页描述符的标志PG_mappedtodisk置位。
- 调用bio_alloc()分配包含单一段的一个新bio描述符,并且分别用块设备描述符地址和页中第一个块的逻辑块号来初始化bi_bdev字段和bi_sector字段。这两个信息已在上面的第3步中得到。
- 用页的起始地址、所读数据的首字节偏移量(0)和所读的字节总数设置bio段的bio_vec描述符。
- 将mpage_end_io_read()函数的地址赋给bio->bi_end_io字段。
- 调用submit_bio(),它将用数据传输的方向设定bi_rw标志,更新每CPU变量page_states来跟踪所读扇区数,并在bio描述符上调用generic_make_request()函数。
- 返向0(成功)。
- 如果函数跳至这里,则页中含有的块在磁盘上不连续。如果页是最新的(PG_uptodate置位),函数就调用unlock_page()来对该页解锁;否则调用block_read_full_page()用一次读一块的方式读该页(见下面)。
- 返回0(成功)。
函数mpage_end_io_read()是bio的完成方法,一旦I/O数据传输结束它就开始执行。假定没有I/O错误,该函数将页描述符的标志PC_uptodate置位,调用unlock_page()来对该页解锁并唤醒任何因为该事件而睡眠的进程,然后调用bio_put()来清除bio描述符。
块设备文件的readpage方法
在第十三章“设备文件的VFS处理”一节和第十四章的“打开块设备文件”一节中,我们讨论了内核如何处理请求以打开块设备文件。我们还看到init_special_inode()函数如何建立设备的索引节点及blkdev_open()如何完成其打开阶段。在bdev特殊文件系统中,块设备使用address_space对象,该对象存放在对应块设备索引节点的i_data字段。不像普通文件(在address_space对象中它的readpage方法依赖于文件所属的文件系统的类型),块设备文件的readpage方法总是相同的。它是由blkdev_readpage()函数实现的,该函数调用block_read_full_page():
int blkdev_readpage(struct file *file,struct * page page){
return block_read_full_page(page, blkdev_get_block);
}正如你看到的,这个函数又是一个封装函数,这里是block_read_full_page()函数的封装函数。这一次,第二个参数也指向一个函数,该函数把相对于文件开始处的文件块号转换为相对于块设备开始处的逻辑块号。不过,对于块设备文件来说,这两个数是一致的;因此,blkdev_get_block()函数执行下列步骤:
检查页中第一个块的块号是否超过块设备的最后一块的索引值(存放在bdev->bd_inode->i_size中的块设备大小除以存放在bdev->bd_block_size中的块大小得到该索引值;bdev指向块设备描述符)。如果超过,那么对于写操作它返回-EIO,而对于读操作它返回0。
(超出块设备读也是不允许的,但不返回错误代码。内核可以对块设备的最后数据试着发出读请求,而得到的缓冲区页只被部分映射)。设置缓冲区首部的b_dev字段为b_dev。
设置缓冲区首部的b_blocknr字段为文件块号,它将被作为参数传给本函数。
把缓冲区首部的BH_Mapped标志置位,以表明缓冲区首部的b_dev和b_blocknr字段是有效的。函数block_read_full_page()以一次读一块的方式读一页数据。正如我们已看到的,当读块设备文件和磁盘上块不相邻的普通文件时都使用该函数。它执行如下步骤:
检查页描述符的标志PG_private,如果置位,则该页与描述组成该页的块的缓冲区首部链表相关;否则,调用create_empty_buffers()来为该页所含所有块缓冲区分配缓冲区首部。页中第一个缓冲区的缓冲区首部地址存放在page->private字段中。每个缓冲区首部的b_this_page字段指向该页中下一个缓冲区的缓冲区首部。
从相对于页的文件偏移量(page->index字段)计算出页中第一块的文件块号。
对该页中每个缓冲区的缓冲区首部,执行如下子步骤:
- 如果标志BH_Uptodate置位,则跳过该缓冲区继续处理该页的下一个缓冲区。
- 如果标志BH_Mapped未置位,并且该块未超出文件尾,则调用依赖于文件系统的get_block函数,该函数的地址已被作为参数得到。对于普通文件,该函数在文件系统的磁盘数据结构中查找,得到相对于磁盘或分区开始处的缓冲区逻辑块号。对于块设备文件,不同的是该函数把文件块号当作逻辑块号。对这两种情形,函数都将逻辑块号存放在相应缓冲区首部的b_blocknr字段中,并将标志BH_Mapped置位。(BH_Mapped表示内存得块缓存区是否映射到了磁盘某个块缓冲区)
- 再检查标志BH_Uptodate,因为依赖于文件系统的get_block函数可能已触发块I/O操作而更新了缓冲区。如果BH_Uptodate置位,则继续处理该页的下一个缓冲区。
- 将缓冲区首部的地址存放在局部数组arr中,继续该页的下一个缓冲区。
假如上一步中没遇到“文件洞”,则将该页的标志PG_mappedtodisk置位。
现在局部变量arr中存放了一些缓冲区首部的地址,与其对应的缓冲区的内容不是最新的。如果数组为空,那么页中的所有缓冲区都是有效的,因此,该函数设置页描述符的PG_uptodate标志,调用unlock_page()对该页解锁并返回。
局部数组arr非空。对数组中的每个缓冲区首部,block_read_full_page()执行下列子步骤:
将BH_Lock标志置位。该标志一旦置位,函数将一直等到该缓冲区释放。
将缓冲区首部的b_end_io字段设为end_buffer_async_read()函数的地址,并将缓冲区首部的BH_Async_Read标志置位。
对局部数组arr中的每个缓冲区首部调用submit_bh(),将操作类型设为READ。就像我们在前面看到的那样,该函数触发了相应块的I/O数据传输。
返回0。
函数end_buffer_async_read()是缓冲区首部的完成方法。对块缓冲区的I/O数据传输一结束,它就执行。假定没有I/O错误,函数将缓冲区首部的BH_Uptodate标志置位而将BH_Async_Read标志清0。那么,函数就得到包含块缓冲区的缓冲区页描述符(它的地址存放在缓冲区首部的b_page字段中),同时检查是否页中所有块是最新的;如果是,函数将该页的PG_uptodate标志置位并调用unlock_page()。
文件的预读
很多磁盘的访问都是顺序的。我们在第十八章会看到,普通文件以相邻扇区成组存放在磁盘上,因此很少移动磁头就可以快速检索到文件。当程序读或拷贝一个文件时,它通常从第一个字节到最后一个字节顺序地访问文件。因此,在处理进程对同一文件的一系列读请求时,可以从磁盘上很多相邻的扇区读取。
预读(read-ahead)是一种技术,这种技术在于在实际请求前读普通文件或块设备文件的几个相邻的数据页。在大多数情况下,预读能极大地提高磁盘的性能,因为预读使磁盘控制器处理较少的命令,其中的每条命令都涉及一大组相邻的扇区。此外,预读还能提高系统的响应能力。顺序读取文件的进程通常不需要等待请求的数据,因为请求的数据已经在RAM中了。但是,预读对于随机访问的文件是没有用的;在这种情况下,预读实际上是有害的,因为它用无用的信息浪费了页高速缓存的空间。因此,当内核确定出最近所进行的I/O访问与前一次I/O访问不是顺序的时就减少或停止预读。
文件的预读需要更复杂的算法,这是由于以下几个原因:
- 由于数据是逐页进行读取的,因此预读算法不必考虑页内偏移量,只要考虑所访问的页在文件内部的位置就可以了。
- 只要进程持续地顺序访问一个文件,预读就会逐渐增加。
- 当前的访问与上一次访问不是顺序的时(随机访问),预读就会逐渐减少乃至禁止。
- 当一个进程重复地访问同一页(即只使用文件的很小一部分)时,或者当几乎所有的页都已在页高速缓存内时,预读就必须停止。低级I/O设备驱动程序必须在合适的时候激活,这样当将来进程需要时,页已传送完毕。
如果请求的第一页紧跟上次访问所请求的最后一页,那么相对于上次的文件访问,内核把文件的这次访问看作是顺序的。当访问给定文件时,预读算法使用两个页面集,各自对应文件的一个连续区域。这两个页面集分别叫做当前窗(current window)和预读窗(ahead window)。
当前窗内的页是进程请求的页和内核预读的页,且位于页高速缓存内(当前窗内的页不必是最新的,因为I/O数据传输仍可能在运行中)。当前窗包含进程顺序访问的最后一页,且可能有内核预读但进程未请求的页。预读窗内的页紧接着当前窗内的页,它们是内核正在预读的页。预读窗内的页都不是进程请求的,但内核假定进程会迟早请求。当内核认为是顺序访问而且第一页在当前窗内时,它就检查是否建立了预读窗。如果没有,内核创建一个预读窗并触发相应页的读操作。理想情况下,进程继续从当前窗请求页,同时预读窗的页则正在传送。当进程请求的页在预读窗,那么预读窗就成为当前窗。预读算法使用的主要数据结构是file_ra_state描述符,它的字段见表16-3。每个文件对象在它的f_ra字段中存放这样的一个描述符。
- start 当前窗内第一页的索引
- size 当前窗内的页数(当临时禁止预读时为一1,0表示当 前窗空)
- flags 控制预读的一些标志
- cache_hit 连续高速缓存命中数(进程请求的页同时又在页高递 缓存内)
- prev_page 预读窗内第一页的索引
- ahead_start 进程请求的最后一页的索引
- ahead_size 预读窗的页数(0表示预读窗口空)
- ra_pages 预读窗的最大页数(0表示预读窗永久禁止)
- mmap_hit 预读命中计数器(用于内存映射文件)
- mmap_miss 预读失败计数器 (用于内存映射文件)
当一个文件被打开时,在它的file_ra_state描述符中,除了prev_page和ra_pages 这两个字段,其他的所有字段都置为0。prev_page字段存放着进程在上一次读操作中所请求页的最后一页的索引,它的初值是-1。ra_pages字段表示当前窗的最大页数,即对该文件允许的最大预读量。该字段的初始值(缺省值)存放在该文件所在块设备的backing_dev_info描述符中。一个应用可以修改一个打开文件的ra_pages字段从而调整预读算法;具体的实现方法是调用posix_fadvise()系统调用,并传给它命令POSIX_FADV_NORMAL(设最大预读量为缺省值,通常是32页)、POSIX_FADV_SEQUENTIAL (设最大预读量为缺省值的两倍)和POSIX_FADV_RANDOM(最大预读量为0,从而永久禁止预读)。
flags字段内有两个重要的字段RA_FLAG_MISS和RA_FLAG_INCACHE。如果已被预读的页不在页高速缓存内(可能的原因是内核为了释放内存而加以收回了),则第一个标志置位,这时候下一个要创建的预读窗大小将被缩小。当内核确定进程请求的最后256页都在页高速缓存内时(连续高速缓存命中数存放在ra->cache_hit字段中),第二个标志置位,这时内核认为所有的页都已在页高速缓存内,进而关闭预读。
何时执行预读算法?这有下列几种情形:
- 当内核用用户态请求来读文件数据的页时。这一事件触发page_cache_readahead()函数的调用。
- 当内核为文件内存映射分配一页时。
- 当用户态应用执行readahead()系统调用时,它会对某个文件描述符显式触发某预读活动。
- 当用户态应用使用POSIX_FADV_NOREUSE或POSIX_FADV_WILLNEED命令执行posix_fadvise()系统调用时,它会通知内核,某个范围的文件页不久将要被访问。
- 当用户态应用使用MADV_WILLNEED命令执行madvise()系统调用时,它会通知内核,某个文件内存映射区域中的给定范围的文件页不久将要被访问。
page_cache_readahead()函数
page_cache_readahead()函数处理没有被特殊系统调用显式触发的所有预读操作。它填写当前窗和预读窗,根据预读命中数更新当前窗和预读窗的大小,也就是根据过去对文件访问预读策略的成功程度来调整。当内核必须满足对某个文件一页或多页的读请求时,函数就被调用,该函数有下面五个参数:
- mapping描述页所有者的address_space对象指针
- ra包含该页的文件file_ra_state描述符指针
- filp文件对象地址
- offset文件内页的偏移量
- req_size要完成当前读操作还需要读的页数
图16-1是page_cache_readahead()的流程图。该函数基本上作用于file_ra_state 描述符的字段,因此,尽管流程图中的行为描述不很正规,你还是能很容易地确定函数执行的实际步骤。例如,为了检查请求页是否与刚读的页相同,函数检查ra->prev_page字段的值和offset参数的值是否一致。当进程第一次访问一个文件,并且其第一个请求页是文件中偏移量为0的页时,函数假定进程要进行顺序访问。那么,函数从第一页创建一个新的当前窗。初始当前窗的长度(总是为2的幂)与进程第一个读操作所请求的页数有一定的联系。
请求页数越大,当前窗越大,一直到最大值,最大值存放在ra->ra_pages字段。反之,当进程第一次访问文件,但其第一个请求页在文件中的偏移量不为0时,函数假定进程不是执行顺序读。那么,函数暂时禁止预读(ra->size字段设为-1)。但是当预读暂时被禁止而函数又认为需要顺序访问时,将建立一个新的当前窗。如果预读窗不存在,一旦函数认为在当前窗内进程执行了顺序读,则预读窗将被建立。预读窗总是从当前窗的最后一页开始。但它的长度与当前窗的长度相关:如果RA_FLAG_MISS标志置位,则预读窗长度是当前窗长度减2,小于4时设为4;否则,预读窗长度是当前窗长度的4倍或2倍。如果进程继续顺序这样,随着进程顺序地读文件,预读会大大地增强。
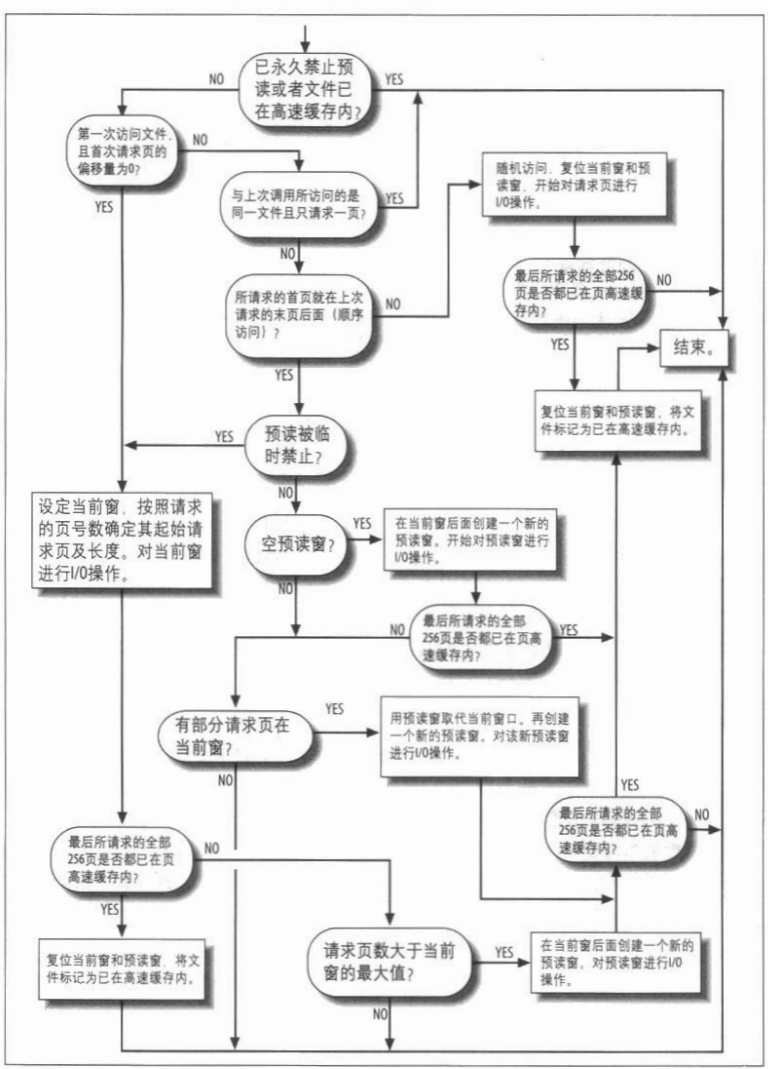
一旦函数认识到对文件的访问相对于上一次不是顺序的,当前窗与预读窗就被清空,预读被暂时禁止。当进程的读操作相对于上一次文件访问为顺序时,预读将重新开始。每次page_cache_readahead()创建一个新窗,它就开始对所包含页的读操作。 为了读一大组页,函数page_cache_readahead()调用blockable_page_cache_readahead()。
为减少内核开销,后面这个函数采用下面灵活的方法:
- 如果服务于块设备的请求队列是读拥塞的,就不进行读操作。
- 将要读的页与页高速缓存进行比较,如果该页已在页高速缓存内,跳过即可。
- 在从磁盘进行读之前,读请求所需的全部页框是一次性分配的。如果不能一次性得到全部页框,预读操作就只在可以得到的页上进行。而且把预读推迟至所有页框都得到时再进行并没有多大意义。
- 只要可能,通过使用多段bio描述符向通用块层发出读操作。这通过address_space对象专用的readpages方法实现(假如已定义);如果没有定义,就通过反复调用readpage方法来实现。readpage方法在前面“从文件中读取数据”一节中对于单段情形有详细描述,但稍作修改就可以很容易地将它用于多段情形。
handle_ra_miss()函数
在某些情况下,预读策略似乎不是十分有效,内核就必须修正预读参数。让我们考虑本章前面“从文件中读取数据”一节中描述的do_generic_file_read()函数。在第4c步中调用函数page_cache_readahead()。
图16-1中展示了两种情形:请求页在当前窗或预读窗表明它已经被预先读入了;或者还没有,则调用blockable_page_cache_readahead()来读入。在这两种情形下,函数do_generic_file_read()应该在第4d步中就在页高速缓存中找到了该页,如果没有,就表示该页框已被收回算法从高速缓存中删除。在这种情形下,do_generic_file_read()调用handle_ra_miss()函数,这个函数会通过将RA_FLAG_MISS标志置位与RA_FLAG_INCACHE标志清0来调整预读算法。
写入文件
回想一下,write()系统调用涉及把数据从调用进程的用户态地址空间中移动到内核数据结构中,然后再移动到磁盘上。文件对象的write方法允许每种文件类型都定义一个专用的写操作。在Linux 2.6中,每个磁盘文件系统的write方法都是一个过程,该过程主要标识写操作所涉及的磁盘块,把数据从用户态地址空间拷贝到页高速缓存的某些页中,然后把这些页中的缓冲区标记成脏。许多文件系统(包括Ext2或JFS)通过generic_file_write()函数来实现文件对象的write 方法。它有如下参数:
- file文件对象指针
- buf用户态地址空间中的地址,必须从这个地址获取要写入文件的字符
- count要写入的字符个数
- ppos存放文件偏移量的变量地址,必须从这个偏移量处开始写入
该函数执行以下操作:
- 初始化iovec类型的一个局部变量,它包含用户态缓冲区的地址与长度。
- 确定所写文件索引节点对象的地址inode(file->f_mapping->host)和获得信号量(inode->i_sem)。有了这个信号量,一次只能有一个进程对某个文件发出write()系统调用。
- 调用宏init_sync_kiocb初始化kiocb类型的局部变量。就像本章前面“从文件读取数据”一节中描述的那样,该宏将ki_key字段设置为KIOCB_SYNC_KEY(同步I/O操作)、ki_filp字段设置为filp、ki_obj字段设置为current。
- 调用__generic_file_aio_write_nolock()函数(见下面)将涉及的页标记为脏,并传递相应的参数:iovec和kiocb类型的局部变量地址、用户态缓冲区的段数(这里只有一个)和ppos。
- 释放inode->i_sem信号量。
- 检查文件的O_SYNC标志、索引节点的S_SYNC标志及超级块的MS_SYNCHRONOUS标志。如果至少一个标志置位,则调用函数sync_page_range()来强制内核将页高速缓存中第4步涉及的所有页刷新,阻塞当前进程直到I/O数据传输结束。
然后依次地,sync_page_range()先执行address_space对象的writepages方法(如果有定义)或mpage_writepages()函数来开始这些脏页的I/O传输,然后调用generic_osync_inode()将索引节点和相关的缓冲区刷新到磁盘,最后调用wait_on_page_bit()挂起当前进程一直到全部所刷新页的PG_writeback标志清0。 - 将__generic_file_aio_write_nolock()函数的返回值返回,通常是写入的有效字节数。
函数generic_file_aio_write_nolock()接收四个参数:
kiocb描述符的地址iocb、iovec描述符数组的地址iov、该数组的长度以及存放文件当前指针的变量的地址ppos。
当被generic_file_write()调用时,iovec描述符数组只有一个元素,该元素描述待写数据的用户态缓冲区。我们现在来解释generic_file_aio_write_nolock()函数的行为。为简单起见,我们只讨论最常见的情形,即对有页高速缓存的文件进行write()系统调用的一般情况。我们在本章后面会讨论该函数在其他情况下的行为。我们不讨论如何处理错误和异常条件。该函数执行如下步骤:
调用access_ok()确定iovec描述符所描述的用户态缓冲区是有效的(起始地址和长度已从服务例程sys_write()得到,因此使用前必须对其检查。如果参数无效,则返回错误-EFAULT。
确定待写文件(file->f_mapping->host)索引节点对象的地址inode。记住:如果文件是一个块设备文件,这就是一个bdev特殊文件系统的索引节点。
将文件(file->f_mapping->backing_dev_info)的backing_dev_info描述符的地址设为current->backing_dev_info。实际上,即使相应请求队列是拥塞的,这个设置也会允许当前进程写回由file->f_mapping拥有的脏页。
如果file->flags的O_APPEND标志置位而且文件是普通文件(非块设备文件),它将*ppos设为文件尾,从而新数据将都追加到文件的后面。
对文件大小进行几次检查。比如,写操作不能把一个普通文件增大到超过每用户的上限或文件系统的上限,每用户上限存放在current->sigmal->rlim[RLIMIT_FSIZE],文件系统上限存放在inode->i_sb->s_maxbytes。另外,如果文件不是“大型文件”(当file->f_flags的O_LARGEFILE标志清0时),那么它的大小不能超出2GB。如果没有设定所述限制,它就减少待写字节数。
如果设定,则将文件的suid标志清0,而且如果是可执行文件的话就将sgid标志也清0。我们并不要用户能修改setuid文件。
将当前时间存放在inode->mtime字段(文件写操作的最新时间)中,也存放在inode->ctime字段(修改索引节点的最新时间)中,而且将索引节点对象标记为脏。
开始循环以更新写操作中涉及的所有文件页。在每次循环期间,执行下列子步骤:
- 调用find_lock_page()在页高速缓存中搜索该页。如果函数找到了该页,则增加引用计数并将PG_locked标志置位。
- 如果该页不在页高速缓存中,则分配一个新页框并调用add_to_page_cache()在页高速缓存内插入此页。这个函数也会增加引用计数并将PG_locked标志置位。另外函数还在内存管理区的非活动链表中插入一页。
- 调用索引节点(file→f-mapping)中address_space对象的prepare_write方法。对应的函数会为该页分配和初始化缓冲区首部。我们在后面的章节中再讨论该函数对于普通文件和块设备文件做些什么。
- 如果缓冲区在高端内存中,则建立用户态缓冲区的内核映射,然后它调用__copy_from_user()把用户态缓冲区中的字符拷贝到页中,并且释放内核映射。
- 调用索引节点(file→f-mapping)中address_space对象的commit_write方法。对应的函数把基础缓冲区标记为脏,以便随后把它们写到磁盘。我们在后面两节讨论该函数对于普通文件和块设备文件做些什么。
- 调用unlock_page()清PG_locked标志,并唤醒等待该页的任何进程。
- 调用mark_page_accessed()来为内存回收算法更新页状态。
- 减少页引用计数来撤销第8a或8b步中的增加值。
- 在这一步,还有另一页被标记为脏,它检查页高速缓存中脏页比例是否超过一个固定的阈值(通常为系统中页的40%)。如果这样,则调用writeback_inodes()来刷新几十页到磁盘。
- 调用cond_resched()来检查当前进程的TIF_NEED_RESCHED标志。如果该标志置位,则调用schedule()函数。
现在,在写操作中所涉及的文件的所有页都已处理。更新*ppos的值,让它正好指向最后一个被写入的字符之后的位置。
设置current->backing_dev_info为NULL。
返回写入文件的有效字符数后结束。
普通文件的prepare_write和commit_write方法
address_space对象的prepare_write和commit_write方法专用于由generic_file_write()实现的通用写操作,这个函数适用于普通文件和块设备文件。对文件的受写操作影响的每一页,调用一次这两个方法。每个磁盘文件系统都定义了自己的prepare_write方法。与读操作类似,这个方法只不过是普通函数的一个封装函数。例如,Ext2文件系统通过下列函数实现prepare_write 方法:
int ext2_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page, from, to, ext2_get_block);
} 在前面“从文件读取数据”一节已经提到ext2_get_block()函数;它把相对于文件的块号转换为逻辑块号(表示数据在物理块设备上的位置)。blockprepare_write()函数通过执行下列步骤为文件页的缓冲区和缓冲区首部做准备:
检查某页是否是一个缓冲区页(如果是则PG_Private标志置位);如果该标志清0,则调用create_empty_buffers()为页中所有的缓冲区分配缓冲区首部。
对与页中包含的缓冲区对应的每个缓冲区首部,及受写操作影响的每个缓冲区首部,执行下列操作:
如果BH_New标志置位,则将它清0。
如果BH_New标志已清0,则函数执行下列子步骤:
- 调用依赖于文件系统的函数,该函数的地址get_block以参数形式传递过来。查看这个文件系统磁盘数据结构并查找缓冲区的逻辑块号(相对于磁盘分区的起始位置而不是普通文件的起始位置)。与文件系统相关的函数把这个数存放在对应缓冲区首部的b_blocknr字段,并设置它的BH_Mapped 标志。与文件系统相关的函数可能为文件分配一个新的物理块(例如,如果访问的块掉进普通文件的一个“洞”中)。在这种情况下,设置BH_New标志。
- 检查BH_New标志的值;如果它被置位,则调用unmap_underlying_metadata()来检查页高速缓存内的某个块设备缓冲区页是否包含指向磁盘同一块的一个缓冲区。该函数实际上调用__find_get_block()在页高速缓存内查找一个旧块。如果找到一块,函数将BH_Dirty标志清0并等待直到该缓冲区的I/O数据传输完毕。此外,如果写操作不对整个缓冲区进行重写,则用0填充未写区域。然后考虑页中的下一个缓冲区。
- 如果写操作不对整个缓冲区进行重写且它的BH_Delay和BH_Uptodate标志未置位(也就是说,已在磁盘文件系统数据结构中分配了块,但是RAM中的缓冲区并没有有效的数据映像),函数对该块调用ll_rw_block()从磁盘读取它的内容。
阻塞当前进程,直到在第2c步触发的所有读操作全部完成。
返回0。
一旦prepare_write方法返回,generic_file_write()函数就用存放在用户态地址空间中的数据更新页。接下来,调用address_space对象的commit_write方法。这个方法由generic_commit_write()函数实现,几乎适用于所有非日志型磁盘文件系统。 generic_commit_write()函数执行下列步骤:
调用__block_commit_write()函数,然后依次执行如下步骤:
- 考虑页中受写操作影响的所有缓冲区;对于其中的每个缓冲区,将对应缓冲区首部的BH_Uptodate和BH_Dirty标志置位。
- 标记相应索引节点为脏,这需要将索引节点加入超级块脏的索引节点链表。
- 如果缓冲区页中的所有缓冲区是最新的,则将PG_uptodate标志置位。
- 将页的PG_dirty标志置位,并在基树中将页标记成脏。
检查写操作是否将文件增大。如果增大,则更新文件索引节点对象的i_size字段。
返回0。
块设备文件的prepare_write和commit_write方法
写入块设备文件的操作非常类似于对普通文件的相应操作。事实上,块设备文件的address_space对象的prepare_write方法通常是由下列函数实现的:
int blkdev_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page, from, to, blkdev_get_block);
} 你可以看到,这个函数只不过是前一节讨论过的block_prepare_write()函数的封装函数。当然,唯一的差异是第二个参数,它是一个指向函数的指针,该函数必须把相对于文件开始处的文件块号转换为相对于块设备开始处的逻辑块号。回想一下,对于块设备文件来说,这两个数是一致的。用于块设备文件的commit_write方法是由下列简单的封装函数实现的:
int blkdev_commit_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_commit_write(page, from, to);
}正如你所看到的,用于块设备的commit_write方法与用于普通文件的commit_write方法本质上做同样的事情。唯一的差异是这个方法不检查写操作是否扩大了文件;你根本不可能在块设备文件的末尾追加字符来扩大它。
将脏页写到磁盘
系统调用write()的作用就是修改页高速缓存内一些页的内容,如果页高速缓存内没有所要的页则分配并追加这些页。某些情况下(例如文件带O_SYNC标志打开),I/O数据传输立即启动。但是通常I/O数据传输是延迟进行的。当内核要有效启动I/O数据传输时,就要调用文件address_space对象的writepages 方法,它在基树中寻找脏页,并把它们刷新到磁盘。例如Ext2文件系统通过下面的函数实现writepages方法:
int ext2_writepages(struct address_space *mapping, struct writeback_control *wbc)
{
return mpage_writepages(mapping, wbc, ext2_get_block);
}你可以看到,该函数是通用mpage_writepages()的一个简单的封装函数。事实上,若文件系统没有定义writepages方法,内核则直接调用mpage_writepages()并把NULL 传给第三个参数。ext2_get_block()函数在前面“从文件读取数据”一节中已讲到过,这是一个依赖于文件系统的函数,它将文件块号转换成逻辑块号。writeback_control数据结构是一个描述符,它控制writeback写回操作如何执行。
mpage_writepages()函数执行下列步骤:
如果请求队列写拥塞,但进程不希望阻塞,则不向磁盘写任何页就返回。
确定文件的首页,如果writeback_control描述符给定一个文件内的初始位置,函数将把它转换成页索引。否则,如果writeback_control描述符指定进程无需等待I/O数据传输结束,它将mapping->writeback_index的值设为初始页索引(即从上一个写回操作的最后一页开始扫描)。最后,如果进程必须等待I/O数据传输完毕,则从文件的第一页开始扫描。
调用find_get_pages_tag()在页高速缓存中查找脏页描述符。
对上一步得到的每个页描述符,执行如下步骤:
- 调用lock_page()来锁定该页。
- 确认页是有效的并在页高速缓存内(因为另一个内核控制路径可能已在第3步与第4a步间作用于该页)。
- 检查页的PG_writeback标志。如果置位,表明页已被刷新到磁盘。如果进程必须等待I/O数据传输完毕,则调用wait_on_page_bit()在PG_writeback清0之前一直阻塞当前进程;当函数结束时,以前运行的任何writeback操作都被终止。否则,如果进程无需等待,它将检查PG_dirty标志:如果PG_dirty标志现已清0,则正在运行的写回操作将处理该页,将它解锁并跳回第4a步继续下一页。
- 如果get_block的参数是NULL(没有定义writepages方法),它将调用文件address_space对象的mapping->writepage方法将页刷新到磁盘。否则,如果get_block的参数不是NULL,它就调用mpage_writepage()函数。详见第8步。
调用cond_resched()来检查当前进程的TIF_NEED_RESCHED标志,如果该标志置位就调用schedule()函数。
如果函数没有扫描完给定范围内的所有页,或者写到磁盘的有效页数小于writeback_control描述符中原先的给定值,那么跳回第3步。
如果writeback_control描述符没有给定文件内的初始位置,它将最后一个扫描页的索引值赋给mapping->writeback_index字段。
如果在第4d步中调用了mpage_writepage()函数,而且返回了bio描述符地址,那么调用mpage_bio_submit()。像Ext2这样的典型文件系统所实现的writepage方法是一个通用的block_write_full_page()函数的封装函数,并将依赖于文件系统的get_block函数的地址作为参数传给它。就像本章前面“从文件读取数据”一节描述的block_read_full_page()一样,block_write_full_page()函数也依次执行:分配页缓冲区首部(如果还不在缓冲区页中),对每页调用submit_bh()函数来指定写操作。
就块设备文件而言,就用block_write_full_page()的封装函数blkdev_writepage()实现writepage 方法。许多非日志型文件系统依赖于mpage_writepage()函数而不是自定义的writepage方法。这样能改善性能,因为mpage_writepage()函数进行I/O传输时,在同一个bio描述符中聚集尽可能多的页。这就使得块设备驱动程序能利用现代硬盘控制器的DMA分散-聚集能力。
长话短说,mpage_writepage()函数将检查:待写页包含的块在磁盘上是否不相邻,该页是否包含文件洞,页上的某块是否没有脏或不是最新的。如果以上情况至少一条成立,函数就像上面那样仍然用依赖于文件系统的writepage方法。否则,将页追加为bio描述符的一段。bio描述符的地址将作为参数被传给函数;如果该地址为NULL,mpage_writepage()将初始化一个新的bio描述符并将地址返回给调用函数,调用函数转而在未来调用mpage_writepage()时再将该地址传回来。这样,同一个bio可以加载几个页。如果bio中某页与上一个加载页不相邻,mpage_writepage()就调用mpage_bio_submit()开始该bio的I/O数据传输,并为该页分配一个新的bio。mpage_bio_submit()函数将bio的bi_end_io方法设为mpage_end_io_write()的地址,然后调用submit_bio()开始传输。一旦数据传输成功结束,完成函数mpage_end_io_write()就唤醒那些等待页传输结束的进程,并清除bio描述符。
内存映射
正如我们在第九章的“线性区”一节中已经介绍过的一样,一个线性区可以和磁盘文件系统的普通文件的某一部分或者块设备文件相关联。这就意味着内核把对线性区中页内某个字节的访问转换成对文件中相应字节的操作。这种技术称为内存映射(memory mapping)。有两种类型的内存映射:
- 共享型(可读,可写):在线性区页上的任何写操作都会修改磁盘上的文件;而且,如果进程对共享映射中的一个页进行写,那么这种修改对于其他映射了这同一文件的所有进程来说都是可见的。
- 私有型(只读,写入不影响磁盘,参考写时复制)::当进程创建的映射只是为读文件,而不是写文件时才会使用此种映射。出于这种目的,私有映射的效率要比共享映射的效率更高。但是对私有映射页的任何写操作都会使内核停止映射该文件中的页。因此,写操作既不会改变磁盘上的文件,对访问相同文件的其他进程也不可见。但是私有内存映射中还没有被进程改变的页会因为其他进程进行的文件更新而更新。
进程可以发出一个mmap()系统调用来创建一个新的内存映射。程序员必须指定一个MAP_SHARED标志或MAP_PRIVATE标志作为这个系统调用的参数。正如你可以猜到的那样,前一种情况下,映射是共享的,而后一种情况下,映射是私有的。一旦创建了这种映射,进程就可以从这个新线性区的内存单元读取数据,也就等价于读取了文件中存放的数据。如果这个内存映射是共享的,那么进程可以通过对相同的内存单元进行写而达到修改相应文件的目的。为了撤消或者缩小一个内存映射,进程可以使用munmap()系统调用。
作为一条通用规则,如果一个内存映射是共享的,相应的线性区就设置了VM_SHARED标志;如果一个内存映射是私有的,那么相应的线性区就清除了VM_SHARED标志。正如我们在后面会看到的一样,对于只读共享内存映射来说,有一个特例不符合本规则。
内存映射的数据结构
内存映射可以用下列数据结构的组合来表示:
- 与所映射的文件相关的索引节点对象
- 所映射文件的address_space对象
- 不同进程对一个文件进行不同映射所使用的文件对象
- 对文件进行每一不同映射所使用的vm_area_struct描述符对文件进行映射的线性区所分配的每个页框所对应的页描述符
图16-2说明了这些数据结构是如何链接在一起的。图的左边给出了标识文件的索引节点。每个索引节点对象的i_mapping字段指向文件的address_space对象。每个address_space对象的page_tree字段又指向该地址空间的页的基树,而i_mmap字段指向第二棵树,叫做radix优先级搜索树(priority search tree,PST),这种树由地址空间的线性区组成。PST的主要作用是为了执行“反向映射”,这是为了快速标识共享一页的所有进程。我们将在下一章中详细讨论PST,因为它们用于页框回收。对同一文件的文件对象和索引节点之间链接的建立是通过f_mapping字段达到的。
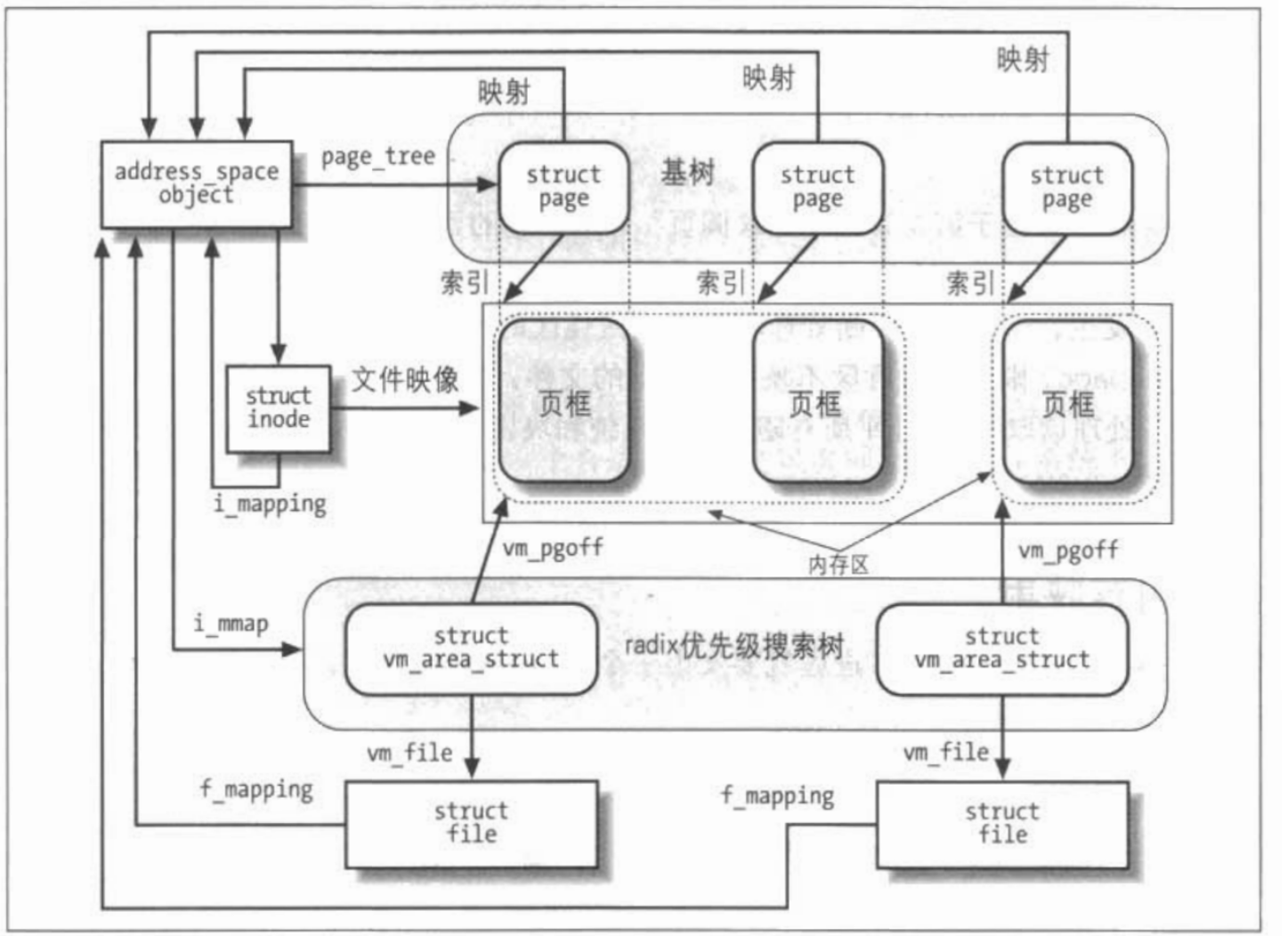
每个线性区描述符都有一个vm_file字段,与所映射文件的文件对象链接(如果该字段为NULL,则线性区没有用于内存映射)。第一个映射单元的位置存放在线性区描述符的vm_pgoff字段,它表示以页大小为单位的偏移量。所映射的文件那部分的长度就是线性区的大小,这可以从vm_start和vm_end字段计算出来。共享内存映射的页通常都包含在页高速缓存中;私有内存映射的页只要还没有被修改,也都包含在页高速缓存中。当进程试图修改一个私有内存映射的页时,内核就把该页框进行复制,并在进程页表中用复制的页来替换原来的页框,这是第八章中介绍的写时复制机制的应用之一。虽然原来的页框还仍然在页高速缓存中,但不再属于这个内存映射,这是由于被复制的页框替换了原来的页框。依次类推,这个复制的页框不会被插入到页高速缓存中,因为其中所包含的数据不再是磁盘上表示那个文件的有效数据。图16-2还显示了包含在页高速缓存中的几个指向内存映射文件的页的页描述符。注意图中的第一个线性区有三页,但是只为它分配了两个页框;猜想一下,大概是拥有这个线性区的进程从没有访问过第三页。
对每个不同的文件系统,内核提供了几个钩子(hook)函数来定制其内存映射机制。内存映射实现的核心委托给文件对象的mmap方法。对于大多数磁盘文件系统和块设备文件,这个方法是由叫做generic_file_mmap()的通用函数实现的,该函数将在下一节进行描述。文件内存映射依赖于第九章的“请求调页”一节描述的请求调页机制。事实上,一个新建立的内存映射就是一个不包含任何页的线性区。当进程引用线性区中的一个地址时,缺页异常发生,缺页异常中断处理程序检查线性区的nopage方法是否被定义。如果没有定义nopage,则说明线性区不映射磁盘上的文件;否则,进行映射,这个方法通过访问块设备处理读取的页。几乎所有磁盘文件系统和块设备文件都通过filemap_nopage()函数实现nopage方法。
创建内存映射
要创建一个新的内存映射,进程就要发出一个mmap()系统调用,并向该函数传递以下参数:
- 文件描述符,标识要映射的文件。
- 文件内的偏移量,指定要映射的文件部分的第一个字符。
- 要映射的文件部分的长度。
- 一组标志。进程必须显式地设置MAP_SHARED标志或MAP_PRIVATE标志来指定所请求的内存映射的种类。
- 一组权限,指定对线性区进行访问的一种或者多种权限:读访问(PROT_READ)、写访问(PROT_WRITE)或执行访问(PROT_EXEC)。
- 一个可选的线性地址,内核把该地址作为新线性区应该从哪里开始的一个线索。如果指定了MAP_FIXED标志,且内核不能从指定的线性地址开始分配新线性区,那么这个系统调用失败。
mmap()系统调用返回新线性区中第一个单元位置的线性地址。为了兼容起见,在80× 86体系结构中,内核在系统调用表中为mmap()保留两个表项:一个在索引90处,一个在索引192处。前一个表项对应于old_mmap()服务例程(由老的C库使用),而后一个表项对应于sys_mmap2()服务例程(由新近的C库使用)。这两个服务例程仅在如何传递系统调用的第6个参数时有所差异。这两个服务例程都调用do_mmap_pgoff()函数。我们现在就详细介绍当创建对文件进行映射的线性区时执行的步骤。我们所讨论的是do_mmap_pgoff()的file参数(文件对象指针)非空的情形。
为清楚起见,我们要列举描述do_mmap_pgoff()的步骤,并指出在新条件下执行的其他步骤。
检查是否为要映射的文件定义了mmap文件操作。如果没有,就返回一个错误码。文件操作表中的mmap值为NULL说明相应的文件不能被映射(例如,因为这是一个目录)。
函数get_unmapped_area()调用文件对象的get_unmapped_area方法,如果已定义,就为文件的内存映射分配一个合适的线性地址区间。磁盘文件系统不会定义这个方法,get_unmapped_area()函数就调用内存描述符的get_unmapped_area方法。
除了进行正常的一致性检查之外,还要对所请求的内存映射的种类(存放在mmap()系统调用的flags参数中)与在打开文件时所指定的标志(存放在file->f_mode 字段中)进行比较。根据这两个消息源,执行以下的检查:
- 如果请求一个共享可写的内存映射,就检查文件是为写入而打开的,而不是以追加模式打开的(open()系统调用的O_APPEND标志)。
- 如果请求一个共享内存映射,就检查文件上没有强制锁。
- 对于任何种类的内存映射,都要检查文件是为读操作而打开的。如果以上这些条件都不能满足,就返回一个错误码。另外,当初始化新线性区描述符的vm_flags字段时,要根据文件的访问权限和所请求的内存映射的种类设置VM_READ、VM_WRITE、VM_EXEC、VM_SHARED、VM_MAYREAD、VM_MAYWRITE、VM_MAYEXEC和VM_MAYSHARE标志。最佳情况下,对于不可写共享内存映射,标志VM_SHARED和VM_MAYWRITE清0。可以这样处理是因为不允许进程写入这个线性区的页,因此,这种映射的处理就与私有映射的处理相同。但是,内核实际上允许共享该文件的其他进程读这个线性区中的页。
用文件对象的地址初始化线性区描述符的vm_file字段,并增加文件的引用计数器。对映射的文件调用mmap方法,将文件对象地址和线性区描述符地址作为参数传给它。对于大多数文件系统,该方法由generic_file_mmap()实现,它执行下列步骤:
将当前时间赋给文件索引节点对象的i_atime字段,并将该索引节点标记为脏。
用generic_file_vm_ops表的地址初始化线性区描述符的vm_ops字段。在这个表中的方法,除了nopage和populate方法外,其他所有都为空。nopage方法由filemap_nopage()实现,而populate方法由filemap_populate()实现。
增加文件索引节点对象i_writecount字段的值,该字段就是写进程的引用计数器。
撤消内存映射
当进程准备撤消一个内存映射时,就调用munmap();该系统调用还可用于减少每种内存区的大小。给它传递的参数如下:要删除的线性地址区间中第一个单元的地址。要删除的线性地址区间的长度。
该系统调用的sys_munmap()服务例程实际上是调用do_munmap()函数。注意,不需要将待撤销可写共享内存映射中的页刷新到磁盘。实际上,因为这些页仍然在页高速缓存内,因此继续起磁盘高速缓存的作用。
内存映射的请求调页
出于效率的原因,内存映射创建之后并没有立即把页框分配给它,而是尽可能向后推迟到不能再推迟——也就是说,当进程试图对其中的一页进行寻址时,就产生一个“缺页”异常。我们在第九章中的“缺页异常处理程序”一节中已经看到,内核是如何验证缺页所在的地址是否包含在某个进程的线性区中的。如果是这样,那么内核就检查这个地址所对应的页表项,如果表项为空就调用do_no_page()函数。do_no_page()函数执行对请求调页的所有类型都通用的操作,例如分配页框和更新页表。它还检查所涉及的线性区是否定义了nopage方法。
在第九章的“请求调页”一节中,我们已经介绍了这个方法没有定义的情况(匿名线性区)。
现在我们讨论当nopage 方法被定义时,do_no_page()所执行的主要操作:
- 调用nopage方法,它返回包含所请求页的页框的地址。
- 如果进程试图对页进行写入而该内存映射是私有的,则通过把刚读取的页拷贝一份并把它插入页的非活动链表中来避免进一步的“写时复制”异常。如果私有内存映射区域还没有一个包含新页的被动匿名线性区(slave anonymousmemory region),它要么追加一个新的被动匿名线性区,要么增大现有的。在下面的步骤中,该函数使用新页而不是nopage方法返回的页,所以后者不会被用户态进程修改。
- 如果某个其他进程删改或作废了该页(address_space描述符的truncate_count字段就是用于这种检查的),函数将跳回第1步,尝试再次获得该页。
- 增加进程内存描述符的rss字段,表示一个新页框已分配给进程。
- 用新页框的地址以及线性区的vm_page_prot字段中所包含的页访问权来设置缺页所在的地址对应的页表项。
- 如果进程试图对这个页进行写入,则把页表项的Read/Write和Dirty位强制置为1。在这种情况下,或者把这个页框互斥地分配给进程,或者让页成为共享;在这两种情况下,都应该允许对这个页进行写入。
请求调页算法的核心在于线性区的nopage方法。一般来说,该方法必须返回进程所访问页所在的页框地址。其实现依赖于页所在线性区的种类。在处理对磁盘文件进行映射的线性区时,nopage方法必须首先在页高速缓存中查找所请求的页。如果没有找到相应的页,这个方法就必须将其从磁盘上读入。大部分文件系统都是使用filemap_nopage()函数来实现nopage方法的,该函数接收三个参数:
- area 所请求页所在线性区的描述符地址。
- address 所请求页的线性地址。
- type 存放函数侦测到的缺页类型(VM_FAULT_MAJOR或VM_FAULT_MINOR)的变量的指针。
filemap_nopage()函数执行以下步骤:
- 从area->vm_file字段得到文件对象地址file;从file->f_mapping得到address_space对象地址;从address_space对象的host字段得到索引节点对象地址。
- 用area的vm_star和vm_pgoff字段来确定从address开始的页对应的数据在文件中的偏移量。
- 检查文件偏移量是否大于文件大小。如果是,就返回NULL,这就意味着分配新页失败,除非缺页是由调试程序通过ptrace()系统调用跟踪另一个进程引起的,我们不打算讨论这种特殊情况。
- 如果线性区的VM_RAND_READ标志置位,我们假定进程以随机方式读内存映射中的页,那么它忽略预读,跳到第10步。
- 如果线性区的VM_SEQ_READ标志置位,我们假定进程以严格顺序方式读内存映射中的页,那么它调用page_cache_readahead()从缺页处开始预读。
- 调用find_get_page(),在页高速缓存内寻找由address_space对象和文件偏移量标识的页。如果找到这样的页,跳到第11步。
- 如果函数运行至此,说明没在页高速缓存内找到页,检查内存区的VM_SEQ_READ标志:
a. 如果标志置位,内核将强行预读线性区中的页,从而预读算法失败,它就调用handle_ra_miss()来调整预读参数,并跳到第10步。
b. 否则,如果标志未置位,将文件file_ra_state描述符中的mmap_miss计数器加1。如果失败数远大于命中数(存放在mmap_hit计数器内),它将忽略预读,跳到第10步。 - 如果预读没有永久禁止(file_ra_state描述符的ra_pages字段大于0),它将调用do_page_cache_readahead(),读入围绕请求页的一组页。
- 调用find_get_page()来检查请求页是否在页高速缓存中,如果在,则跳到第11步。
- 调用page_cache_read()。这个函数检查请求页是否在页高速缓存中,如果不在,则分配一个新页框,把它追加到页高速缓存,执行mapping->a_ops->readpage方法,安排一个I/O操作从磁盘读入该页内容。
- 调用grab_swap_token()函数,尽可能为当前进程分配一个交换标记。
- 请求页现已在页高速缓存内,将文件file_ra_state描述符的mmap_hit计数器加1。
- 如果页不是最新的(标志PG_uptodate flag未置位),就调用lock_page()锁定该页,执行mapping->a_ops->readpage方法来触发I/O数据传输,调用wait_on_page_bit()后睡眠,一直等到该页被解锁,就是说等到数据传输完成。
- 调用mark_page_accessed()来标记请求页为访问过。
- 如果在页高速缓存内找到该页的最新版,将*type设为VM_FAULT_MINOR,否则设为VM_FAULT_MAJOR。
- 返回请求页地址。用户态进程可以通过madvise()系统调用来调整filemap_nopage()函数的预读行为。
MADV_RANDOM命令将线性区的VM_RAND_READ标志置位,从而指定以随机方式访问线性区的页。
MADV_SEQUENTIAL命令将线性区的VM_SEQ_READ标志置位,从而指定以严格顺序方式访问页。
最后,MADV_NORMAL命令将复位VM_RAND_READ和VM_SEQ_READ标志,从而指定以不确定的顺序访问页。
把内存映射的脏页刷新到磁盘
进程可以使用msync()系统调用把属于共享内存映射的脏页刷新到磁盘。这个系统调用所接收的参数为:一个线性地址区间的起始地址、区间的长度以及具有下列含义的一组标志。
- MS_SYNC要求这个系统调用挂起进程,直到I/O操作完成为止。在这种方式中,调用进程就可以假设当系统调用完成时,这个内存映射中的所有页都已经被刷新到磁盘。
- MS_ASYNC(对MS_SYNC的补充)要求系统调用立即返回,而不用挂起调用进程。
- MS_INVALIDATE要求系统调用使同一文件的其他内存映射无效(没有真正实现,因为在Linux中无用)。
对线性地址区间中所包含的每个线性区,sys_msync()服务例程都调用msync_interval()。后者依次执行以下操作:
- 如果线性区描述符的vm_file字段为NULL,或者如果VM_SHARED标志清0,就返回0(说明这个线性区不是文件的可写共享内存映射)。
- 调用filemap_sync()函数,该函数扫描包含在线性区中的线性地址区间所对应的页表项。对于找到的每个页,重设对应页表项的Dirty标志,调用flush_tlb_page()刷新相应的转换后援缓冲器(translation lookaside buffer,TLB)。然后设置页描述符中的PG-dirty标志,把页标记为脏。
- 如果MS_ASYNC标志置位,它就返回。因此,MS_ASYNC标志的实际作用就是将线性区的页标志PG_dirty置位。该系统调用并没有实际开始I/O数据传输。
- 如果函数运行至此,则MS_SYNC标志置位,因此函数必须将内存区的页刷新到磁盘,而且,当前进程必须睡眠一直到所有I/O数据传输结束。为做到这一点,函数要得到文件索引节点的信号量i_sem。
- 调用filemap_fdatawrite()函数,该函数接收的参数为文件的address_space对象的地址。该函数必须用WB_SYNC_ALL同步模式建立一个writeback_control描述符,而且要检查地址空间是否有内置的writepages方法。如果有,则调用这个函数后返回。如果没有,就执行mpage_writepages()函数。
- 检查文件对象的fsync方法是否已定义,如果是,就执行它。对于普通文件,这个方法限制自己把文件的索引节点对象刷新到磁盘。然而,对于块设备文件,这个方法调用sync_blockdev(),它会激活该设备所有脏缓冲区的I/O数据传输。
- 执行filemap_fdatawait()函数。页高速缓存中的基树标识了所有通过PAGECACHE_TAG_WRITEBACK标记正在往磁盘写的页。函数快速地扫描覆盖给定线性地址区间的这一部分基树来寻找PG_writeback标志置位的页。函数调用wait_on_page_bit()使其在每一页上睡眠,一直到PG_writeback标志清0,也就是等到正在进行的该页的I/O数据传输结束。
- 释放文件的信号量i_sem并返回。
非线性内存映射
对普通文件,Linux 2.6内核还提供一个访问方法,即非线性内存映射。非线性内存映射基本上还是前面所述的文件内存映射,但它的内存页映射的并不是文件的顺序页,而是每一内存页都映射的是文件数据的随机页。
当然,一个用户态应用每次针对同一文件的不同4096字节部分重复调用mmap()系统调用,也可以得到同样的结果。然而,因为每个映射需要一个独立的线性区,所以这种方法对于大文件的非线性映射是非常低效的。
为了实现非线性映射,内核使用了另外的一些数据结构。
首先,线性区描述符的VM_NONLINEAR标志用于表示线性区存在一个非线性映射。给定文件的所有非线性映射线性区描述符都存放在一个双向循环链表,该链表根植于address_space对象的i_mmap_nonlinear字段。为创建一个非线性内存映射,用户态进程首先以mmap()系统调用创建一个常规的共享内存映射。应用然后调用remap_file_pages()来重新映射内存映射中的一些页。该系统调用的sys_remap_file_pages()服务例程有下面几个参数:
- start调用进程共享文件内存映射区域内的线性地址
- size文件重新映射部分的字节数
- prot未用(必须为0)
- pgoff待映射文件初始页的页索引
- flags控制非线性映射的标志
该服务例程用线性地址start、页索引pgoff和映射尺寸size所确定的文件数据部分进行重新映射。如果线性区非共享或不能容纳要映射的所有页,则系统调用失败并返回错误码。实际上,该服务例程把线性区插入文件的i_mmap_nonlinear链表,并调用该线性区的populate方法。对于所有普通文件,populate方法是由filemap_populate()函数实现的。它执行以下步骤:
- 检查remap_file_pages()系统调用的flags参数中MAP_NONBLOCK标志是否清0。如果是,则调用do_page_cache_readahead()预读待映射文件的页。
- 对重新映射的每一页,执行下列步骤:
a. 检查页描述符是否已在页高速缓存内,如果不在且MAP_NONBLOCK未置位,那从磁盘读入该页。
b. 如果页描述符在页高速缓存内,它将更新对应线性地址的页表项来指向该页框,并更新线性区描述符的页引用计数器。
c. 否则,如果没有在页高速缓存内找到该页描述符,它将文件页的偏移量存放在该线性地址对应的页表项的最高32位,并将页表项的Present位清0、Dirty位置位。
正如第九章“请求调页”一节所述,当处理请求调页错误时,handle_pte_fault()函数检查页表项的Present和Dirty位。如果它们的值对应一个非线性内存映射,则handle_pte_fault()调用do_file_page()函数,从页表项的高位中取出所请求文件页的索引,然后,do_file_page()函数调用线性区的populate方法从磁盘读入页并更新页表项本身。因为非线性内存映射的内存页是按照相对于文件开始处的页索引存放在页高速缓存中,而不是按照相对于线性区开始处的索引存放的,所以非线性内存映射刷新到磁盘的方式与线性内存映射是一样的。
直接I/O传送
我们已经看到,在Linux 2.6版本中,通过文件系统与通过引用基本块设备文件上的块,甚至与通过建立文件内存映射访问一个普通文件之间没有什么本质的差异。但是,还是有一些非常复杂的程序(自缓存的应用程序,self-caching application)更愿意具有控制I/O数据传送机制的全部权力。例如,考虑高性能数据库服务器:它们大都实现了自己的高速缓存机制,以充分挖掘对数据库独特的查询机制。对于这些类型的程序,内核页高速缓存毫无帮助;相反,因为以下原因它可能是有害的:
- 很多页框浪费在复制已在RAM中的磁盘数据上(在用户级磁盘高速缓存中)。
- 处理页高速缓存和预读的多余指令降低了read()和write()系统调用的执行效率,也降低了与文件内存映射相关的分页操作。
- read()和write()系统调用不是在磁盘和用户存储器之间直接传送数据,而是分两次传送:在磁盘和内核缓冲区之间和在内核缓冲区与用户存储器之间。因为必须通过中断和直接内存访问(DMA)处理块硬件设备,而且这只能在内核态完成,因此,最终需要某种内核支持来实现自缓存的应用程序。
Linux提供了绕过页高速缓存的简单方法:直接I/O传送。
在每次I/O直接传送中,内核对磁盘控制器进行编程,以便在自缓存的应用程序的用户态地址空间中的页与磁盘之间直接传送数据。我们知道,任何数据传送都是异步进行的。当数据传送正在进行时,内核可能切换当前进程,CPU可能返回到用户态,产生数据传送的进程的页可能被交换出去,等等。这对于普通I/O数据传送没有什么影响,因为它们涉及磁盘高速缓存中的页,磁盘高速缓存由内核拥有,不能被换出去,并且对内核态的所有进程都是可见的。另一方面,直接I/O传送应当在给定进程的用户态地址空间的页内移动数据。内核必须当心这些页是由内核态的任一进程访问的,当数据传送正在进行时不能把它们交换出去。让我们看看这是如何实现的。
当自缓存的应用程序要直接访问文件时,它以O_DIRECT标志置位的方式打开文件。在运行open()系统调用时,dentry_open()函数检查打开文件的address_space对象是否有已实现的direct_IO方法,如果没有则返回错误码。对一个已打开的文件也可以由fcntl()系统调用的F_SETFL命令把O_DIRECT 置位。让我们首先看第一种情况,这里自缓存应用程序对一个以O_DIRECT标志置位的方式打开的文件调用read()系统调用。文件的read方法通常是由generic_file_read()函数实现的,它初始化iovec和kiocb描述符并调用__generic_file_aio_read()。后面这个函数检查iovec描述符描述的用户态缓冲区是否有效,然后检查文件的O_DIRECT标志是否置位。当被read()调用时,该函数执行的代码段实际上等效于下面的代码:
if〈filp->f_flags & O_DIRECT) {
if(count == 0 Il*ppos>filp->f_mapping->host->i_size)
return 0;
retval = generic_file_direct_IO(READ, iocb, iov, *ppos, 1);
if(retval > 0)
*ppos += retval;
file_accessed(filp);
return retval;
}函数检查文件指针的当前值、文件大小与请求的字符数,然后调用generic_file_direct_IO()函数,传给它READ操作类型、iocb描述符、iovec描述符、文件指针的当前值以及io_vec描述符中指定的用户态缓冲区号。当generic_file_direct_IO()结束时,__generic_file_aio_read()更新文件指针,设置对文件索引节点的访问时间戳,然后返回。 对一个以O_DIRECT标志置位打开的文件调用write()系统调用时,情况类似。文件的write方法就是调用generic_file_aio_write_nolock()。该函数检查O_DIRECT标志是否置位,如果置位,则调用generic_file_direct_IO()函数,而这次限定的是WRITE操作类型。generic_file_direct_IO()函数有以下参数:
rw
操作类型:READ或WRITE
iocb
kiocb描述符指针
iov
iove描述符数组指针
offset
文件偏移量
nr_segs
iov数组中iovec描述符数generic_file_direct_IO()函数的执行步骤如下:
- 从kiocb描述符的ki_filp字段得到文件对象的地址file,从file->f_mapping字段得到address_space对象的地址mapping。
- 如果操作类型为WRITE,而且一个或多个进程已创建了与文件的某个部分关联的内存映射,那么它调用unmap_mapping_range()取消该文件所有页的内存映射。如果任何取消映射的页所对应的页表项,其Dirty位置位,则该函数也确保它在页高速缓存内的相应页被标记为脏。
- 如果根植于mapping的基树不为空(mapping->nrpages大干0),则调用filemap_fdatawrite()和filemap_fdatawait()函数刷新所有脏页到磁盘,并等待I/O操作结束。(即使自缓存应用程序是直接访问文件的,系统中还可能有通过页高速缓存访问文件的其他应用程序。为了避免数据的丢失,在启动直接I/O传送之前,磁盘映像要与页高速缓存进行同步)。
- 调用mapping地址空间的direct_IO方法。
- 如果操作类型为WRITE,则调用invalidate_inode_pages2()扫描mapping基树中的所有页并释放它们。该函数同时也清空指向这些页的用户态页表项。
大多数情况下,direct_IO方法都是blockdev_direct_IO()函数的封装函数。这个函数相当复杂,它调用大量的辅助数据结构和函数,但是实际上它所执行的操作与本章所描述的操作一样:对存放在相应块中要读或写的数据进行拆分,确定数据在磁盘上的位置,并添加一个或多个用于描述要进行的I/O操作的bio描述符。当然,数据将被直接从iov数组中iovec描述符确定的用户态缓冲区读写。调用submit_bio()函数将bio 描述符提交给通用块层。通常情况下,blockdev_direct_IO()函数并不立即返回,而是等所有的直接I/O传送都已完成才返回;因此,一旦read()或write()系统调用返回,自缓存应用程序就可以安全地访问含有文件数据的缓冲区。
异步/0
POSIX 1003.1标准为异步方式访问文件定义了一套库函数。“异步”实际上就是:当用户态进程调用库函数读写文件时,一旦读写操作进入队列函数就结束,甚至有可能真正的I/O数据传输还没有开始。这样调用进程可以在数据正在传输时继续自己的运行。
- aio_read() 从文件异步读数据
- aio_write() 向文件异步写数据
- aio_fsync() 请求刷新所有正在运行的异步I/O操作(不阻塞)
- aio_error() 获得正在运行的异步I/O操作的错误代码
- aio_return() 获得一个已完成异步I/O操作的返回码
- aio_cancel() 取消正在运行的异步I/O操作
- aio_suspend() 挂起正在允许的异步I/O操作
使用异步I/O很简单,应用程序还是通过open()系统调用打开文件,然后用描述请求操作的信息填充struct aiocb类型的控制块。struct aiocb控制块最常用的字段有:
- aio_fildes 文件的文件描述符(由open()系统调用返回)
- aio_buf 文件数据的用户态缓冲区
- aio_nbytes 待传输的字节数
- aio_offset 读写操作在文件中的起始位置(与“同步”文件指针无关)
最后,应用程序将控制块地址传给aio_read()或aio_write()。一旦请求的I/O数据传输已由系统库或内核送进队列,这两个函数就结束。应用程序稍后可以调用aio_error()检查正在运行的I/0操作的状态。如数据传输仍在进行当中,则返回EINPROGRESS;如果成功完成,则返回0;如果失败,则返回一个错误码。aio_return()函数返回已完成异步I/O操作的有效读写字节数;或者如果失败,返回-1。
Linux 2.6中的异步IO
异步I/O可以由系统库实现而完全不需要内核支持。实际上aio_read()或aio_write()库函数克隆当前进程,让子进程调用同步的read()或write()系统调用,然后父进程结束aio_read()或aio_write()函数并继续程序的执行。因此,它不用等待由子进程启动的同步操作完成。但是,这个“穷人版”POSIX函数比内核层实现的异步I/O要慢很多。
Linux 2.6内核版运用一组系统调用实现异步I/O。但在Linux2.6.11中,这个功能还在实现中,异步I/O只能用于打开O_DIRECT标志置位的文件。表16-5列出了异步I/O的系统调用。
- io_setup() 为当前进程初始化一个异步环境
- io_submit() 提交一个或多个异步I/O操作
- io_getevents() 获得正在运行的异步I/O操作的完成状态
- io_cancel() 取消一个正在运行的异步I/O操作
- io_destroy() 删除当前进程的异步环境
异步I/O环境
如果一个用户态进程调用io_submit()系统调用开始异步I/O操作,那么它必须预先创建一个异步I/O环境。基本上,一个异步I/O环境(简称AIO环境)就是一组数据结构,这个数据结构用于跟踪进程请求的异步I/O操作的运行情况。每个AIO环境与一个kioctx对象关联,它存放了与该环境有关的所有信息。一个应用可以创建多个AIO环境。一个给定进程的所有的kioctx描述符存放在一个单向链表中,该链表位于内存描述符的ioctx_list字段。
我们不再详细讨论kioctx对象。但是我们应当注意一个kioctx对象使用的重要的数据结构:AIO环。AIO环是用户态进程中地址空间的内存缓冲区,它也可以由内核态的所有进程访问。kioctx对象中的ring_info.mmap_base和ring_info.mmap_size字段分别存放AIO环的用户态起始地址和长度。ring_info.ring_pages字段则存放有一个数组指针,该数组存放所有含AIO环的页框的描述符。
AIO环实际上是一个环形缓冲区,内核用它来写正运行的异步I/O操作的完成报告。AIO 环的第一个字节有一个首部(struct aio_ring数据结构),后面的所有字节是io_event 数据结构,每个都表示一个已完成的异步I/O操作。因为AIO环的页映射至进程的用户态地址空间,应用可以直接检查正运行的异步I/O操作的情况,从而避免使用相对较慢的系统调用。
io_setup()系统调用为调用进程创建一个新的AIO环境。它有两个参数:正在运行的异步I/O操作的最大数目(这将确定AIO环的大小)和一个存放环境句柄的变量指针。这个句柄也是AIO环的基地址。sys_io_setup()服务例程实际上是调用do_mmap()为进程分配一个存放AIO环的新匿名线性区,然后创建和初始化描述该AIO环境的kioctx对象。相反地,io_destroy()系统调用删除AIO环境,还删除含有对应AIO环的匿名线性区。这个系统调用阻塞当前进程直到所有正在运行的异步I/O操作结束。
提交异步I0操作
为开始异步I/O操作,应用要调用io_submit()系统调用。该系统调用有三个参数:
- ctx_id 由io_setup()(标识AIO环境)返回的句柄
- iocbpp iocb类型描述符的指针数组的地址,其中描述符的每项描述一个异步I/O操作
- nr iocbpp指向的数组长度
iocb数据结构与POSIX aiocb描述符有同样的字段aio_fildes、aio_buf、aio_nbytes、aio_offset,另外还有aio_lio_opcode字段存放请求操作的类型(典型地有:read、write或sync)。sys_io_submit()服务例程执行下列步骤:
验证iocb描述符数组的有效性。
在内存描述符的ioctx_list字段所对应的链表中查找ctx_id句柄对应的kioctx对象。
对数组中的每一个iocb描述符,执行下列子步骤:
- 获得aio_fildes字段中的文件描述符对应的文件对象地址。
- 为该I/O操作分配和初始化一个新的kiocb描述符。
- 检查AIO环中是否有空闲位置来存放操作的完成情况。
- 根据操作类型设置kiocb描述符的ki_retry方法(见下面)。
- 执行aio_run_iocb()函数,它实际上调用ki_retry方法为相应的异步I/O操作启动数据传输。如果ki_retry方法返回-EIOCBRETRY,则表示异步I/O操作已提交但还没有完全成功:稍后在这个kiocb上,aio_run_iocb()函数会被再次调用(见下面);否则,调用aio_complete(),为异步I/O操作在AIO环境的环中追加完成事件。
如果异步I/O操作是一个读请求,那么对应kiocb描述符的ki_retry方法是由aio_pread()实现的。该函数实际上执行的是文件对象的aio_read方法,然后按照aio_read方法的返回值更新kiocb描述符的ki_buf和ki_left字段(参见本章前面的表16-1)。最后aio_pread()返回从文件读入的有效字节数,或者,如果函数确定请求的字节没有传输完,则返回-EIOCBRETRY。对于大部分文件系统,文件对象的aio_read方法就是调用generic_file_aio_read()函数。假如文件的O_DIRECT标志置位,函数就调用generic_file_direct_IO()函数,这在上一节描述过。但在这种情况下,blockdev_direct_IO()函数不是阻塞当前进程使之等待I/O数据传输完毕,而是立即返回。因为异步I/O操作仍在运行,aio_run_iocb()会被再次调用,而这一次的调用者是aio_wq工作队列的aio内核线程。kiocb描述符跟踪I/O数据传输的运行。终于所有数据传输完毕,将完成结果追加到AIO环。
类似地,如果异步I/O操作是一个写请求,那么对应kiocb描述符的ki_retry方法是由aio_pwrite()实现的。该函数实际上执行的是文件对象的aio_write方法,然后按照aio_write方法的返回值更新kiocb描述符的ki_buf和ki_left字段(参见本章前面的表16-1)。最后aio_pwrite()返回写入文件的有效字节数,或者,如果函数确定请求的字节没有完全传输完,则返回-EIOCBRETRY。
对于大部分文件系统,文件对象的aio_write方法就是调用generic_file_aio_write_nolock()函数。假如文件的O_DIRECT标志置位,跟上面一样,函数就调用generic_file_direct_IO()函数。
页高速缓存
页高速缓存
在绝大多数情况下,内核在读写磁盘时都引用页高速缓存。新页被追加到页高速缓存以满足用户态进程的读请求。
如果页不在高速缓存中,新页就被加到高速缓存中,然后用从磁盘读出的数据填充它。
如果内存有足够的空闲空间,就让该页在高速缓存(内存)中长期保留,使其他进程再使用该页时不再访问磁盘。
同样,在把一页数据写到块设备之前,内核首先检查对应的页是否已经在高速缓存中;
如果不在,就要先在其中增加一个新项,并用要写到磁盘中的数据填充该项。
I/O数据的传送并不是马上开始,而是要延迟几秒之后才对磁盘进行更新,从而使进程有机会对要写入磁盘的数据做进一步的修改(换句话说,就是内核执行延迟的写操作)。以便对磁盘IO进行寻道优化等。
内核的代码和内核数据结构不必从磁盘读,也不必写入磁盘,因此,页高速缓存中的页(磁盘页)可能是下面的类型:
- 含有普通文件数据的页。
- 含有目录的页。
- 含有直接从块设备文件(跳过文件系统层)读出的数据的页。
- 含有用户态进程数据的页,但页中的数据已经被交换到磁盘。
- 内核可能会强行在页高速缓存中保留一些页面,而这些页面中的数据已经被写到交换区(可能是普通文件或磁盘分区)。
- 属于特殊文件系统文件的页,如共享内存的进程间通信所使用的特殊文件系统
shm。
页高速缓存中的页所包含的数据属于某个文件时。这个文件(或者更准确地说是文件的索引节点)就称为页的所有者(owner)。
几乎所有的文件读和写操作都依赖于页高速缓存。页高速缓存是内存和磁盘的中间层。
只有在O_DIRECT标志被置位而进程打开文件的情况下才会出现例外:此时,I/0数据的传送绕过了页高速缓而使用了进程用户态地址空间的缓冲区;少数数据库应用软件为了能采用自己的磁盘高速缓存算法而使用了O_DIRECT标志。
内核设计者实现页高速缓存主要为了满足下面两种需要:
快速定位含有给定所有者相关数据的特定页。为了尽可能充分发挥页高速缓存的优势,对它应该采用高速的搜索操作。
记录在读或写页中的数据时应当如何处理高速缓存中的每个页。
例如,从普通文件、块设备文件或交换区(这些都存储在磁盘上)读一个数据页必须用不同的实现方式,因此内核必须根据页的所有者选择适当的操作。一个页中包含的磁盘块在物理上不一定是相邻的,通过页的所有者和所有者数据中的索引(通常是一个索引节点和在相应文件中的偏移量)来识别页高速缓存中的页。
address_space对象
页高速缓存的核心数据结构是address_space对象,它是一个嵌入在页所有者的索引节点对象中的数据结构。
高速缓存中的许多页可能属于同一个所有者,从而可能被链接到同一个address_space对象。
每个页描述符的mapping字段指向拥有页的索引节点的address_space对象,
每个页描述符的index 字段表示在所有者的地址空间中以页大小为单位的偏移量,也就是在所有者的磁盘映像中页中数据的位置。
可以用下述方式访问普通文件的同一4KB的数据块:
(1). 读文件,数据就包含在普通文件的索引节点所拥有的页中。
(2). 从文件所在的设备文件(磁盘分区)读取块;数据就包含在块设备文件的主索引节点所拥有的页中。两个不同address_space对象所引用的两个不同的页中出现了相同的磁盘数据。。
- host 指向拥有该对象的索引节点的指针(如 果存在)
- page_tree 表示拥有者页的基树(radix tree)的根
- tree_lock Spin lock 保护基树的自旋锁
- i_mmap_writable 地址空间中共享内存映射的个数
- i_mmap radix优先搜索树的根
- i_mmap_nonlinear 地址空间中非线性内存区的链表
- i_mmap_lock 保护radix优先搜索树的自旋锁
- truncate_count 截断文件时使用的顺序计数器
- nrpages writeback_index a..ops 所有者的页总数最后一次回写操作所作用的页的索引!对所有者页进行操作的方法
- flags 指向拥有所有者数据的块设备的错误位和内存分配器的标志
- backing_dev_info backing_dev_info的指针
- private_lock 通常是管理private_list链表时使用的自旋锁
- private_list 通常是与索引节点相关的间接块的脏缓冲区的链表
- assoc_mapping 通常是指向间接块所在块设备的address_space对象的指针
(1). 如果页高速缓存中页的所有者是一个文件,address_space对象就嵌入在VFS索引节点对象的i_data字段中。VFS索引节点的i_mapping字段总是指向索引节点的数据页所有者的address_space对象。address_space对象的host字段指向其所有者的索引节点对象。
故,如果页属于一个文件(存放在Ext3文件系统中),那么页的所有者就是文件的索引节点,而且相应的address_space对象存放在VFS索引节点对象的i_data字段中。索引节点的i_mapping字段指向同一个索引节点的i_data字段,而address_space对象的host字段也指向这个索引节点。
(2). 如果页中包含的数据来自块设备文件,即页含有存放着块设备的“原始”数据,
那么就把address_space对象嵌入到与该块设备相关的特殊文件系统bdev中文件的“主”索引节点中(块设备描述符的bd_inode字段引用这个索引节点)。块设备文件对应索引节点的i_mapping 字段指向主索引节点中的address_space对象。address_space对象的host 字段指向主索引节点。
backing_dev_info字段指向backing_dev_info描述符,后者是对所有者的数据所在块设备进行有关描述的数据结构。address_space对象的关键字段是a_ops,它指向一个类型为address_space_operations 的表,表中定义了对所有者的页进行处理的各种方法。这些方法如表15-2所示。
- writepage 写操作(从页写到所有者的磁盘映像)
- readpage 读操作(从所有者的磁盘映像读到页)
- sync_page 如果对所有者页进行的操作已推备好,则立刻开始1/0数据的传输
- writepages 把指定数量的所有者脏页写回磁盘
- set_page_dirty 把所有者的页设置为脏页
- readpages 从磁盘中读所有者页的链表
- prepare_write 为写操作做准备(由磁盘文件系统使用)
- commit_write 完成写操作(由磁盘文件系统使用)
- bmap 从文件块索引中获取逻辑块号
- invalidatepage 使所有者的页无效(截断文件时使用)
- releasepage 由日志文件系统使用以准备释放页
- direct_IO 所有者页的直接IO传输(绕过页高速缓存)
在绝大多数情况下,这些方法把所有者的索引节点对象和访问物理设备的低级驱动程序联系起来。
例如,为普通文件的索引节点实现readpage方法的函数知道如何确定文件页的对应块在物理磁盘设备上的位置。
基树
访问大文件时,页高速缓存中可能充满太多的文件页,以至于顺序扫描这些页要消耗大量的时间。
为了实现页高速缓存的高效查找,Linux 2.6 采用了大量的搜索树,其中每个address_space对象对应一棵搜索树。
address_space对象的page_tree字段是基树(radix tree)的根。
给定的页索引表示页在所有者磁盘映像中的位置,内核能够通过快速搜索操作来确定所需要的页是否在页高速缓存中。
当查找所需要的页时,内核把页索引转换为基树中的路径,并快速找到页描述符所(或应当)在的位置。
如果找到,内核可以从基树获得页描述符,而且还可以很快确定所找到的页是否是脏页(也就是应当被刷新到磁盘的页),以及其数据的I/O传送是否正在进行。
基树的每个节点可以有多到64个指针指向其他节点或页描述符。底层节点存放指向页描述符的指针(叶子节点),而上层的节点存放指向其他节点(孩子节点)的指针。
每个节点由radix_tree_node数据结构表示,它包括三个字段:
slots是包括64个指针的数组,count是记录节点中非空指针数量的计数器,tags是二维的标志数组,
树根由radix_tree_root数据结构表示,它有三个字段:
height表示树的当前深度(不包括叶子节点的层数),gfp_mask指定为新节点请求内存时所用的标志,rnode指向与树中第一层节点相应的数据结构radix_tree_node(如果有的话)。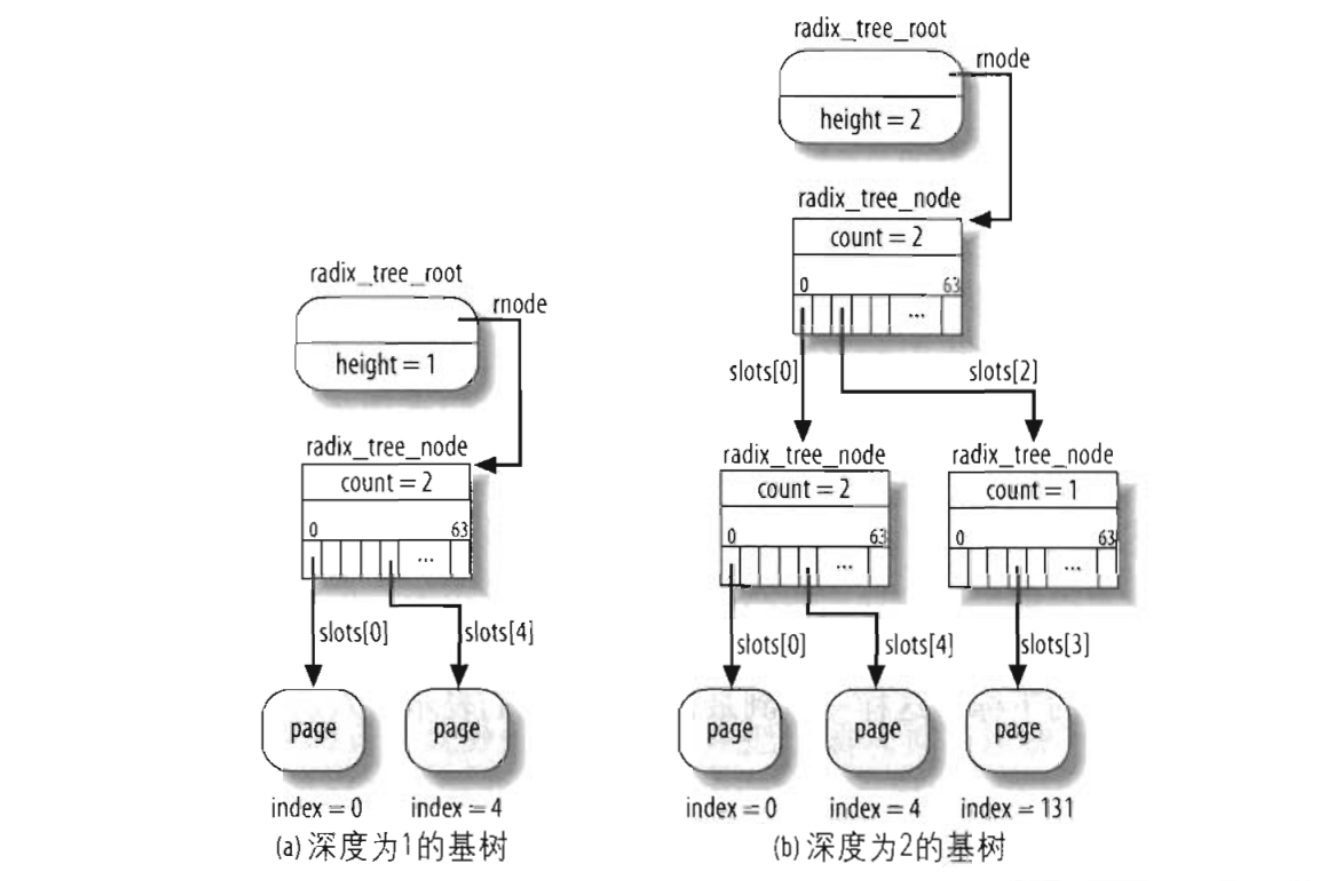
页高速缓存的处理函数
查找页–find_get_page()
参数:
- 指向address_space对象的指针,
- 偏移量。
它获取地址空间的自旋锁,调用radix_tree_lookup()函数搜索拥有指定偏移量的基树的叶子节点。该函数根据偏移量值中的位依次从树根开始并向下搜索,如上节所述。如果遇到空指针,函数返回NULL;否则,返回叶子节点的地址,也就是所需要的页描述符指针。如果找到了所需要的页,
find_get_page()函数就增加该页(页框)的使用计数器,释放自旋锁,返回该页的地址;否则,函数就释放自旋锁并返回NULL。
find_get_pages():
与find_get_page()类似,但它实现在高速缓存中查找一组具有相邻索引的页。
参数:
- 指向address_space对象的指针、
- 地址空间中相对于搜索起始位置的偏移量、
- 所检索到页的最大数量、
- 指向由该函数赋值的页描述符数组的指针。
依赖radix_tree_gang_lookup()函数实现查找操作。radix_tree_gang_lookup()函数为指针数组赋值并返回找到的页数。
find_lock_page()函数:
与find_get_page()类似,但它增加返回页的使用记数器,并调用lock_page()设置PG_locked标志,从而当函数返回时调用者能够以互斥的方式访问返回的页。如果页已经被加锁,lock_page()函数就阻塞当前进程。调用_wait_on_bit_lock()函数。当前进程置为TASK_UNINTERRUPTIBLE 状态,把进程描述符存入等待队列,执行address_space对象的sync_page方法以取消文件所在块设备的请求队列,最后调用schedule()函数来挂起进程,直到把PG_locked 标志清0。内核使用unlock_page()函数对页进行解锁,并唤醒在等待队列上睡眠的进程。
增加页–add_to_page_cache()
把一个新页的描述符插入到页高速缓存。
参数:
- 页描述符的地址
page、 address_space对象的地址mapping、- 表示在地址空间内的页索引的值
offset - 为基树分配新节点时所使用的内存分配标志
gfp_mask。
函数执行以下操作:
调用
radix_tree_preload()函数,它禁用内核抢占,并把一些空的radix_tree_node结构赋给每CPU变量radix_tree_preloads。radix_tree_node结构的分配由slab分配器高速缓存radix_tree_node_cachep来完成。如果radix_tree_preload()预分配radix_tree_node结构不成功,函数add_to_page_cache()就终止并返回错误码-ENOMEM。否则,如果radix_tree_preload()成功地完成预分配,add_to_page_cache()函数肯定不会因为缺乏空闲内存或因为文件的大小达到了64GB而无法完成新页描述符的插入。获取
mapping->tree_lock自旋锁——注意,radix_tree_preload()函数已经禁用了内核抢占。调用
radix_tree_insert()在树中插入新节点,该函数执行下述操作:- 调用
radix_tree_maxindex()获得最大索引,该索引可能被插入具有当前深度的基树;如果新页的索引不能用当前深度表示,就调用radix_tree_extend()通过增加适当数量的节点来增加树的深度(例如,对图15-1(a)所示的基树,radix_tree_extend()在它的顶端增加一个节点)。分配新节点是通过执行radix_tree_node_alloc()函数实现的,该函数试图从slab分配器高速缓存获得radix_tree_node结构,如果分配失败,就从存放在radix_tree_preloads中的预分配的结构池中获得radix_tree_node结构。 - 根据页索引的偏移量,从根节点(
mapping->page_tree)开始遍历树,直到叶子节点,如上一节所述。如果需要,就调用radix_tree_node_alloc()分配新的中间节点。 - 把页描述符地址存放在对基树所遍历的最后节点的适当位置,并返回
0。
- 调用
增加页描述符的使用计数器
page->_count。由于页是新的,所以其内容无效:函数设置页框的
PG_locked标志,以阻止其他的内核路径并发访问该页。用
mapping和offset参数初始化page->mapping和page->index。递增在地址空间所缓存页的计数器(
mapping->nrpages)。释放地址空间的自旋锁。
调用
radix_tree_preload_end()重新启用内核抢占。返回
0(成功)。
删除页
函数remove_from_page_cache()通过下述步骤从页高速缓存中删除页描述符:
获取自旋锁
page->mapping->tree_lock并关中断。调用
radix_tree_delete()函数从树中删除节点。该函数接收树根的地址(page->mapping->page_tree)和要删除的页索引作为参数,并执行下述步骤:- 如上节所述,根据页索引从根节点开始遍历树,直到到达叶子节点。遍历时,建立
radix_tree_path结构的数组,描述从根到与要删除的页相应的叶子节点的路径构成。 - 从最后一个节点(包含指向页描述符的指针)开始,对路径数组中的节点开始循环操作。对每个节点,把指向下一个节点(或页描述符)位置数组的元素置为
NULL,并递减count字段。如果count变为0,就从树中删除节点并把radix_tree_node结构释放给slab分配器高速缓存。然后继续循环处理路径数组中的节点。否则,如果count不等于0,继续执行下一步。 - 返回已经从树中删除的页描述符指针。
- 如上节所述,根据页索引从根节点开始遍历树,直到到达叶子节点。遍历时,建立
把
page->mapping字段置为NULL。把所缓存页的
page->mapping->nrpages计数器的值减1。释放自旋锁
page->mapping->tree_lock,打开中断,函数终止。
更新页
函数read_cache_page()确保高速缓存中包括最新版本的指定页。它的参数是
- 指向
address_space对象的指针mapping、 - 表示所请求页的偏移量的值
index、 - 指向从磁盘读页数据的函数的指针
filler(通常是实现地址空间readpage方法的函数) - 传递给
filler函数的指针data(通常为NULL)。
下面是对这个函数的简单说明:
调用函数
find_get_page()检查页是否已经在页高速缓存中。如果页不在页高速缓存中,则执行下述子步骤:
- 调用
alloc_pages()分配一个新页框。 - 调用
add_to_page_cache()在页高速缓存中插入相应的页描述符。 - 调用
1ru_cache_add()把页插入该管理区的非活动LRU链表中。
- 调用
此时,所请求的页已经在页高速缓存中了。调用
mark_page_accessed()函数记录页已经被访问过的事实。如果页不是最新的(
PG_uptodate标志为0),就调用filler函数从磁盘读该页。返回页描述符的地址。
基树的标记
前面我们曾强调,页高速缓存不仅允许内核快速获得含有块设备中指定数据的页,还允许内核从高速缓存中快速获得给定状态的页。
例如,我们假设内核必须从高速缓存获得属于指定所有者的所有页和脏页(即其内容还没有写回磁盘)。
存放在页描述符中的PG_dirty标志表示页是否是脏的,但是,如果绝大多数页都不是脏页,遍历整个基树以顺序访问所有叶子节点(页描述符)的操作就太慢了。
相反,为了能快速搜索脏页,基树中的每个中间节点都包含一个针对每个孩子节点(或叶子节点)的脏标记,当有且只有至少有一个孩子节点的脏标记被置位时这个标记被设置。最底层节点的脏标记通常是页描述符的PG_dirty标志的副本。通过这种方式,当内核遍历基树搜索脏页时,就可以跳过脏标记为0的中间结点的所有子树:中间结点的脏标记为0说明其子树中的所有页描述符都不是脏的。
同样的想法应用到了PG_writeback标志,该标志表示页正在被写回磁盘。这样,为基树的每个结点引入两个页描述符的标志:PG_dirty和PG_writeback。每个结点的tags字段中有两个64位的数组来存放这两个标志。tags[0](PAGECACHE_TAG_DIRTY)数组是脏标记,而tags[1](PAGECACHE_TAG_WRITEBACK)数组是写回标记。
设置页高速缓存中页的PG_dirty或PG_writeback标志时调用函数radix_tree_tag_set(),它作用于三个参数:
- (1). 基树的根、
- (2). 页的索引
- (3). 要设置的标记的类型(
PAGECACHE_TAG_DIRTY或PAGECACHE_TAG_WRITEBACK)。
函数从树根开始并向下搜索到与指定索引对应的叶子结点;对于从根通往叶子路径上的每一个节点,函数利用指向路径中下一个结点的指针设置标记。然后,函数返回页描述符的地址。结果是,从根结点到叶子结点的路径中的所有结点都以适当的方式被加上了标记。
清除页高速缓存中页的PG_dirty或PG_writeback标志时调用函数radix_tree_tag_clear(),它的参数与函数radix_tree_tag_set()的参数相同。函数从树根开始并向下到叶子结点,建立描述路径的radix_tree_path结构的数组。然后,函数从叶子结点到根结点向后进行操作:清除底层结点的标记,然后检查是否结点数组中所有标记都被清0,如果是,函数把上层父结点的相应标记清0,并如此继续上述操作。最后,函数返回页描述符的地址。从基树删除页描述符时,必须更新从根结点到叶子结点的路径中结点的相应标记。函数radix_tree_delete()可以正确地完成这个工作(尽管我们在上一节没有提到这一点)。而函数radix_tree_insert()不更新标记,因为插入基树的所有页描述符的PG_dirty 和PG_writeback标志都被认为是清零的。如果需要,内核可以随后调用函数radix_tree_tag_set()。
函数radix_tree_tagged()利用树的所有结点的标志数组来测试基树是否至少包括一个指定状态的页。
函数通过执行下面的代码轻松地完成这一任务(root是指向基树的radix_tree_root结构的指针,tag是要测试的标记):因为可能假设基树所有结点的标记都正确地更新过,所以radix_tree_tagged()函数只需要检查第一层的标记。使用该函数的一个例子是:确定一个包含脏页的索引节点是否要写回磁盘。
注意,函数在每次循环时要测试在无符号长整型的32个标志中,是否有被设置的标志。函数find_get_pages_tag()和find_get_pages()类似,只有一点不同,就是前者返回的只是那些用tag参数标记的页。正如我们将在“把脏页写入磁盘”一节所见的,该函数对快速找到一个索引节点的所有脏页是非常关键的。
把块存放在页高速缓存中
VFS(映射层)和各种文件系统以叫做“块”的逻辑单位组织磁盘数据。在Linux内核的旧版本中,主要有两种不同的磁盘高速缓存:
页高速缓存和缓冲区高速缓存,前者用来存放访问磁盘文件内容时生成的磁盘数据页,后者把通过VFS(管理磁盘文件系统)访问的块的内容保留在内存中。
从2.4.10的稳定版本开始,缓冲区高速缓存其实就不存在了。事实上,由于效率的原因,不再单独分配块缓冲区;
相反,把它们存放在叫做“缓冲区页”的专门页中,而缓冲区页保存在页高速缓存中。缓冲区页在形式上就是与称做“缓冲区首部”的附加描述符相关的数据页,其主要目的是快速确定页中的一个块在磁盘中的地址。实际上,页高速缓存内的页中的一大块数据在磁盘上的地址不一定是相邻的。
块缓冲区和缓冲区首部
每个块缓冲区都有buffer_head类型的缓冲区首部描述符。该描述符包含内核必须了解的、有关如何处理块的所有信息。因此,在对所有块操作之前,内核检查缓冲区首部。
缓冲区首部的两个字段编码表示块的磁盘地址:
- (1).
b_bdev字段表示包含块的块设备,通常是磁盘或分区; - (2).
b_blocknr字段存放逻辑块号,即块在磁盘或分区中的编号。 (3).
b_data字段表示块缓冲区在缓冲区页中的位置。实际上,这个位置的编号依赖于页是否在高端内存。如果页在高端内存,则b_data字段存放的是块缓冲区相对于页的起始位置的偏移量,否则,b_data存放的是块缓冲区的线性地址。b_state字段可以存放几个标志。其中一些标志是通用的,把它们列在表15-5中。每个文件系统还可以定义自己的私有缓冲区首部标志。BH_UptodateBH_Dirty 缓冲区包含有效数据时被置位如果缓冲区脏就置位(表示缓冲区中的数据必须写回块设备)
- BH_Lock 如果缓冲区加锁就置位,通常发生在缓冲区进行磁盘传输时
- BH_Req 如果已经为初始化缓冲区而请求数据传输就置位
- BH_Mapped 如果缓冲区被映射到磁盘就置位,即:如果相应的缓冲区首部的b bdev和 b_blocknr是有效的就置位
- BH_New 如果相应的块刚被分配而还没有被访问过就置位
- BH_Async_Read 如果在异步地读缓冲区就置位
- BH_Async_Write 如果在异步地写缓冲区就置位
- BH_Delay 如果还没有在磁盘上分配缓冲区就置位
- BH_Boundary 如果两个相邻的块在其中一个提交之后不再相邻就置位
- BH_Write_EIO 如果写块时出现I/O错误就置位
- BH_Ordered 如果必须严格地把块写到在它之前提交的块的后面就置位(用于日 志文件系统)
- BH_Eopnotsupp 如果块设备的驱动程序不支持所请求的操作就置位
管理缓冲区首部
缓冲区首部有它们自己的slab分配器高速缓存,其描述符kmem_cache_s存在变量bh_cachep中。alloc_buffer_head()和free_buffer_head()函数分别用于获取和释放缓冲区首部。
缓冲区首部的b_count字段是相应的块缓冲区的引用计数器。在每次对块缓冲区进行操作之前递增计数器并在操作之后递减它。
除了周期性地检查保存在页高速缓存中的块缓冲区之外,当空闲内存变得很少时也要对它进行检查,只有引用计数器等于0的块缓冲区才可以被回收。当内核控制路径希望访问块缓冲区时,应该先递增引用计数器。确定块在页高速缓存中的位置的函数(__getblk(),自动完成这项工作,因此,高层函数通常不增加块缓冲区的引用计数器。
当内核控制路径停止访问块缓冲区时,应该调用__brelse()或__bforget()递减相应的引用计数器。这两个函数之间的不同是__bforget()还从间接块链表(缓冲区首部的b_assoc_buffers字段)中删除块,并把该缓冲区标记为干净的,因此强制内核忽略对缓冲区所做的任何修改,但实际上缓冲区依然必须被写回磁盘。
缓冲区页
只要内核必须单独地访问一个块,就要涉及存放块缓冲区的缓冲区页,并检查相应的缓冲区首部。
下面是内核创建缓冲区页的两种普通情况:
(1). 当读或写的文件页在磁盘块中不相邻时。发生这种情况是因为文件系统为文件分配了非连续的块,或因为文件有“洞”。
(2). 当访问一个单独的磁盘块时(例如,当读超级块或索引节点块时)。
在第一种情况下,把缓冲区页的描述符插入普通文件的基树;
保存好缓冲区首部,因为其中存有重要的信息,即存有数据在磁盘中位置的块设备和逻辑块号。
在第二种情况下,把缓冲区页的描述符插入基树,
树根是与块设备相关的特殊bdev文件系统中索引节点的address_space对象。
这种缓冲区页必须满足很强的约束条件,就是所有的块缓冲区涉及的块必须是在块设备上相邻存放的。
这种情况的一个应用实例是:
如果虚拟文件系统要读大小为1024个字节的索引节点块(包含给定文件的索引节点)。
内核并不是只分配一个单独的缓冲区,而是必须分配一个整页,从而存放四个缓冲区;
这些缓冲区将存放块设备上相邻的4块数据,其中包括所请求的索引节点块。
本章我们将重点讨论第二种类型的缓冲区页,即所谓的块设备缓冲区页(有时简称为块设备页)。
在一个缓冲区页内的所有块缓冲区大小必须相同,因此,在80x86体系结构上,根据块的大小,一个缓冲区页可以包括1~8个缓冲区。
如果一个页作为缓冲区页使用,那么与它的块缓冲区相关的所有缓冲区首部都被收集在一个单向循环链表中。
缓冲区页描述符的private字段指向页中第一个块的缓冲区首部;
每个缓冲区首部在b_this_page字段中,该字段是指向链表中下一个缓冲区首部的指针。
此外,每个缓冲区首部还把缓冲区页描述符的地址存放在b_page字段中。
图15-2显示了一个缓冲区页,其中包含四个块缓冲区和对应的缓冲区首部。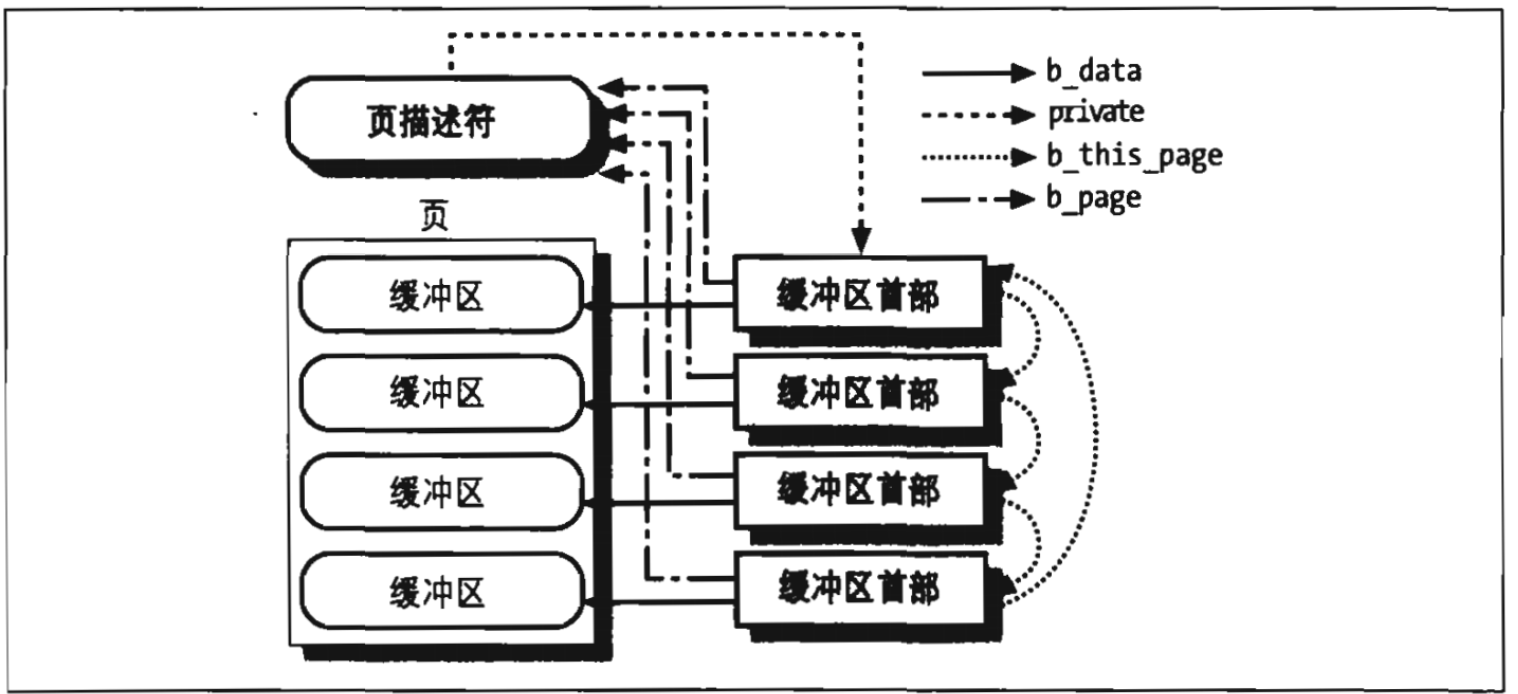
分配块设备缓冲区页
当内核发现指定块的缓冲区所在的页不在页高速缓存中时,就分配一个新的块设备缓冲区页。
特别是,对块的查找操作会由于下述原因而失败:
- 包含数据块的页不在块设备的基树中:这种情况下,必须把新页的描述符加到基树中。
- 包含数据块的页在块设备的基树中,但这个页不是缓冲区页:在这种情况下,必须分配新的缓冲区首部,并将它链接到所属的页,从而把它变成块设备缓冲区页。
- 包含数据块的缓冲区页在块设备的基树中,但页中块的大小与所请求的块大小不相同:
这种情况下,必须释放旧的缓冲区首部,分配经过重新赋值的缓冲区首部并将它链接到所属的页。内核调用函数grow_buffers()把块设备缓冲区页添加到页高速缓存中。
该函数接收三个标识块的参数:
- (1). block_device描述符的地址bdev。
- (2). 逻辑块号block(块在块设备中的位置)。
- (3). 块大小size。
该函数本质上执行下列操作:
计算数据页在所请求块的块设备中的偏移量
index。如果需要,就调用
grow_dev_page()创建新的块设备缓冲区页。
该函数依次执行下列子步骤:- 调用函数
find_or_create_page(),传递给它的参数有:
- 块设备的
address_space对象(bdev->bd_inode->i_mapping)、 - 页偏移
index - 以及
GFP_NOFS标志。
find_or_create_page()在页高速缓存中搜索需要的页,如果需要,就把新页插入高速缓存。- 此时,所请求的页已经在页高速缓存中,而且函数获得了它的描述符地址。函数检查它的
PG_private标志;
如果为空,说明页还不是一个缓冲区页(没有相关的缓冲区首部),就跳到第2e步。 - 页已经是缓冲区页。从页描述符的
private字段获得第一个缓冲区首部的地址bh,并检查块大小bh->size是否等于所请求的块大小;
如果大小相等,在页高速缓存中找到的页就是有效的缓冲区页,因此跳到第2g步。 - 如果页中块的大小有错误,就调用
try_to_free_buffers()释放缓冲区页的上一个缓冲区首部。 - 调用函数
alloc_page_buffers()根据页中所请求的块大小分配缓冲区首部,并把它们插入由b_this_page字段实现的单向循环链表。此外,函数用页描述符的地址初始化缓冲区首部的b_page字段,用块缓冲区在页内的线性地址或偏移量初始化b_data字段。 - 在字段
private中存放第一个缓冲区首部的地址,把PG_private字段置位,并递增页的使用计数器(页中的块缓冲区被算作一个页用户)。 - 调用
init_page_buffers()函数初始化连接到页的缓冲区首部的字段b_bdev、b_blocknr和b_bstate。
因为所有的块在磁盘上都是相邻的,因此逻辑块号是连续的,而且很容易从块得出。
h. 返回页描述符地址。
- 调用函数
为页解锁(函数
find_or_create_page()曾为页加了锁)。递减页的使用计数器(函数
find_or_create_page()曾递增了计数器)。返回
1(成功)。
释放块设备缓冲区页
当内核试图获得更多的空闲内存时,就释放块设备缓冲区页。
显然,不可能释放有脏缓冲区或上锁的缓冲区的页。内核调用函数try_to_release_page()释放缓冲区页,该函数接收页描述符的地址page。
执行下述步骤:
如果设置了页的
PG_writeback标志,则返回0(因为正在把页写回磁盘,所以不可能释放该页)。如果已经定义了块设备
address_space对象的releasepage方法,就调用它(通常没有为块设备定义的releasepage方法)。调用函数
try_to_free_buffers()并返回它的错误代码。
函数try_to_free_buffers()依次扫描链接到缓冲区页的缓冲区首部,它本质上执行下列操作:- 检查页中所有缓冲区的缓冲区首部的标志。如果有些缓冲区首部的
BH_Dirty或BH_Locked标志被置位,说明函数不可能释放这些缓冲区,所以函数终止并返回0(失败)。 - 如果缓冲区首部在间接缓冲区的链表中,该函数就从链表中删除它
- 检查页中所有缓冲区的缓冲区首部的标志。如果有些缓冲区首部的
清除页描述符的
PG_private标记,把private字段设置为NULL,并递减页的使用计数器。清除页的PG_dirty标记。反复调用free_buffer_head(),以释放页的所有缓冲区首部。返回
1(成功)。
在页高速缓存中搜索块
当内核需要读或写一个单独的物理设备块时(例如一个超级块),必须检查所请求的块缓冲区是否已经在页高速缓存中。
在页高速缓存中搜索指定的块缓冲区(由块设备描述符的地址bdev和逻辑块号nr表示)的过程分成三个步骤:
- (1). 获取一个指针,让它指向包含指定块的块设备的
address_space对象(bdev->bd_inode->i_mapping)。 - (2). 获得设备的块大小(
bdev->bd_block_size),并计算包含指定块的页索引。 - 这需要在逻辑块号上进行位移操作。例如,如果块的大小是
1024字节,每个缓冲区页包含四个块缓冲区,那么页的索引是nr / 4。 - (3). 在块设备的基树中搜索缓冲区页。
获得页描述符之后,内核访问缓冲区首部,它描述了页中块缓冲区的状态。不过,实现的细节要更为复杂。为了提高系统性能,内核维持一个小磁盘高速缓存数组bh_lrus(每个CPU对应一个数组元素),即所谓的最近最少使用(LRU)块高速缓存。每个磁盘高速缓存有8个指针,指向被指定CPU最近访问过的缓冲区首部。对每个CPU 数组的元素排序,使指向最后被使用过的那个缓冲区首部的指针索引为0。相同的缓冲区首部可能出现在几个CPU数组中(但是同一个CPU数组中不会有相同的缓冲区首部)。在LRU块高速缓存中每出现一次缓冲区首部,该缓冲区首部的使用计数器b_count 就加1。
__find_get_block()函数
函数__find_get_block()的参数有:block_device描述符地址bdev、块号block和块大小size。
函数返回页高速缓存中的块缓冲区对应的缓冲区首部的地址;如果不存在指定的块,就返回NULL。
该函数本质上执行下面的操作:
- 检查执行
CPU的LRU块高速缓存数组中是否有一个缓冲区首部,其b_bdev、b_blocknr和b_size字段分别等于bdev、block和size。 - 如果缓冲区首部在
LRU块高速缓存中,就刷新数组中的元素,以便让指针指在第一个位置(索引为0)刚找到的缓冲区首部,递增它的b_count字段,并跳转到第8步。 - 如果缓冲区首部不在
LRU块高速缓存中,根据块号和块大小得到与块设备相关的页的索引:index= block >> (PAGE_SHIFT- bdev->bd_inode->i_blkbits) - 调用
find_get_page()确定存有所请求的块缓冲区的缓冲区页的描述符在页高速缓存中的位置。该函数传递的参数有:指向块设备的address_space对象的指针(bdev->bd_inode->i_mapping)和页索引。页索引用于确定存有所请求的块缓冲区的缓冲区页的描述符在页高速缓存中的位置。如果高速缓存中没有这样的页,就返回NULL(失败)。 - 此时,函数已经得到了缓冲区页描述符的地址:它扫描链接到缓冲区页的缓冲区首部链表,查找逻辑块号等于
block的块。 - 递减页描述符的
count字段(find_get_page()曾递增它的值)。 - 把
LRU块高速缓存中的所有元素向下移动一个位置,并把指向所请求块的缓冲区首部的指针插入到第一个位置。如果一个缓冲区首部已经不在LRU块高速缓存中,就递减它的引用计数器b_count。 - 如果需要,就调用
mark_page_accessed()把缓冲区页移至适当的LRU链表中。 - 返回缓冲区首部指针。
__getblk()函数
函数__getblk()与__find_get_block()接收相同的参数,也就是block_device描述符的地址bdev、块号block和块大小size,并返回与缓冲区对应的缓冲区首部的地址。即使块根本不存在,该函数也不会失败,__getblk()友好地分配块设备缓冲区页并返回将要描述块的缓冲区首部的指针。注意,__getblk()返回的块缓冲区不必存有有效数据——缓冲区首部的BH_Uptodate标志可能被清0。
函数__getblk()本质上执行下面的步骤:
- 调用
__find_get_block()检查块是否已经在页高速缓存中。如果找到块,则函数返回其缓冲区首部的地址。 - 否则,调用
grow_buffers()为所请求的页分配一个新的缓冲区页。 - 如果
grow_buffers()分配这样的页失败,__getblk()试图通过调用函数free_more_memory()回收一部分内存。 - 跳转到第
1步。
__bread()函数
函数__bread()接收与__getblk()相同的参数,即block_device描述符的地址bdev、块号block和块大小size,并返回与缓冲区对应的缓冲区首部的地址。与__getblk()相反的是,如果需要的话,在返回缓冲区首部之前函数__bread()从磁盘读块。
函数__bread()执行下述步骤:
- 调用
__getblk()在页高速缓存中查找与所请求的块相关的缓冲区页,并获得指向相应的缓冲区首部的指针。 - 如果块已经在页高速缓存中并包含有效数据(
BH_Uptodate标志被置位),就返回缓冲区首部的地址。 - 否则,递增缓冲区首部的引用计数器。
- 把
end_buffer_read_sync()的地址赋给b_end_io字段。 - 调用
submit_bh()把缓冲区首部传送到通用块层。 - 调用
wait_on_buffer()把当前进程插入等待队列,直到I/O操作完成,即直到缓冲区首部的BH_Lock标志被清0。 - 返回缓冲区首部的地址。
向通用块层提交缓冲区首部
一对submit_bh()和ll_rw_block()函数,允许内核对缓冲区首部描述的一个或多个缓冲区进行I/O数据传送。
submit_bh()函数
内核利用submit_bh()函数向通用块层传递一个缓冲区首部,并由此请求传输一个数据块。它的参数是数据传输的方向(本质上就是READ或WRITE)和指向描述块缓冲区的缓冲区首部的指针bh。
submit_bh()函数假设缓冲区首部已经被彻底初始化;尤其是,必须正确地为b_bdev、b_blocknr和b_size字段赋值以标识包含所请求数据的磁盘上的块。如果块缓冲区在块设备缓冲区页中,就由__find_get_block()完成对缓冲区首部的初始化,就像在上一节所描述的。不过,我们将在下一章看到,还可以对普通文件所有的缓冲区页中的块调用submit_bh()。submit_bh()函数只是一个起连接作用的函数,它根据缓冲区首部的内容创建一个bio 请求,并随后调用generic_make_request()。
函数执行的主要步骤如下:
设置缓冲区首部的
BH_Req标志以表示块至少被访问过一次。此外,如果数据传输的方向是WRITE,就将BH_Write_EIO标志清0。调用
bio_alloc()分配一个新的bio描述符。根据缓冲区首部的内容初始化
bio描述符的字段:- 把块中的第一个扇区的号(
bh->b_blocknr * bh->b_size / 512)赋给bi_sector字段。 - 把块设备描述符的地址(
bh->b_bdev)赋给bi_bdev字段。 - 把块大小(
bh->b_size)赋给bi_size字段。 - 初始化
bi_io_vec数组的第一个元素以使该段对应于块缓冲区:把bh->b_page赋给bi_io_vec[0].bv_page,把bh->b_size赋给bi_io_vec[0].bv_len,并把块缓冲区在页中的偏移量bh->b_data赋给bi_io_vec[0].bv_offset。 - 把
bi_vcnt置为1(只有一个涉及bio的段),并把bi_idx置为0(将要传输的是当前段)。 - 把
end_bio_bh_io_sync()的地址赋给bi_end_io字段,并把缓冲区首部的地址赋给bi_private字段;数据传输结束时调用函数。
- 把块中的第一个扇区的号(
递增
bio的引用计数器(它变为2)。调用
submit_bio(),把bi_rw标志设置为数据传输的方向,更新每CPU变量page_states以表示读和写的扇区数,并对bio描述符调用generic_make_request()函数。递减
bio的使用计数器;因为bio描述符现在已经被插人I/O调度程序的队列,所以没有释放bio描述符。返回
0(成功)。当针对bio上的I/O数据传输终止的时候,内核执行bi_end_io方法,具体来说执行end_bio_bh_io_sync()函数。后者本质上从bio的bi_private字段获取缓冲区首部的地址,然后调用缓冲区首部(在调用submit_bh()之前已为它正确赋值)的方法b_end_io,最后调用bio_put()释放bio结构。
ll_rw_block()函数
有些时候内核必须立刻触发几个数据块的数据传输,这些数据块不一定物理上相邻。ll_rw_block()函数接收的参数有数据传输的方向(本质上就是READ或WRITE)、要传输的数据块的块号以及指向块缓冲区所对应的缓冲区首部的指针数组。
该函数在所有缓冲区首部上进行循环,每次循环执行下面的操作:
- 检查并设置缓冲区首部的
BH_Lock标志;如果缓冲区已经被锁住,而另外一个内核控制路径已经激活了数据传输,就不处理这个缓冲区,而跳转到第9步。 - 把缓冲区首部的使用计数器
b_count加1。 - 如果数据传输的方向是
WRITE,就让缓冲区首部的方法b_end_io指向函数end_buffer_write_sync()的地址,否则让b_end_io指向end_buffer_read_sync()函数的地址。 - 如果数据传输的方向是
WRITE,就检查并清除缓冲区首部的BH_Dirty标志。如果该标志没有置位,就不必把块写入磁盘,因此跳转到第7步。 - 如果数据传输的方向是
READ或READA(向前读),检查缓冲区首部的BH_Uptodate标志是否被置位;如果是,就不必从磁盘读块,因此跳转到第7步。 - 此时必须读或写数据块:调用
submit_bh()函数把缓冲区首部传递到通用块层,然后跳转到第9步。 - 通过清除
BH_Lock标志为缓冲区首部解锁,然后唤醒所有等待块解锁的进程。 - 递减缓冲区首部的
b_count字段。 - 如果数组中还有其他的缓冲区首部要处理,就选择下一个缓冲区首部并跳转回到第
1步,否则,就结束。
注意,如果函数1l_rw_block()把缓冲区首部传递到通用块层,而留下加了锁的缓冲区和增加了的引用计数器,这样,在完成数据传输之前就不可能访问该缓冲区,也不可能释放这个缓冲区。当块的数据传送结束时,内核执行缓冲区首部的b_end_io方法。
假设没有I/O错误,end_buffer_write_sync()和end_buffer_read_sync()函数只是简单地把缓冲区首部的BH_Uptodate字段置位,为缓冲区解锁,并递减它的引用计数器。
把脏页写入磁盘
正如我们所了解的,内核不断用包含块设备数据的页填充页高速缓存。
只要进程修改了数据,相应的页就被标记为脏页,即把它的PG_dirty标志置位。Unix系统允许把脏缓冲区写入块设备的操作延迟执行,因为这种策略可以显著地提高系统的性能。
对高速缓存中的页的几次写操作可能只需对相应的磁盘块进行一次缓慢的物理更新就可以满足。
此外,写操作没有读操作那么紧迫,因为进程通常是不会由于延迟写而挂起,而大部分情况都因为延迟读而挂起。
正是由于延迟写,使得任一物理块设备平均为读请求提供的服务将多于写请求。
一个脏页可能直到最后一刻(即直到系统关闭时)都一直逗留在主存中。然而,从延迟写策略的局限性来看,它有两个主要的缺点:
(1). 如果发生了硬件错误或电源掉电的情况,那么就无法再获得RAM的内容,因此,从系统启动以来对文件进行的很多修改就丢失了。
(2). 页高速缓存的大小(由此存放它所需的RAM的大小)就可能要很大——至少要与所访问块设备的大小相同。
因此,在下列条件下把脏页刷新(写入)到磁盘:
a. 页高速缓存变得太满,但还需要更多的页,或者脏页的数量已经太多。
b. 自从页变成脏页以来已过去太长时间。
c. 进程请求对块设备或者特定文件任何待定的变化都进行刷新。
通过调用sync()、fsync()或fdatasync()系统调用来实现。
缓冲区页的引入使问题更加复杂。与每个缓冲区页相关的缓冲区首部使内核能够了解每个独立块缓冲区的状态。如果至少有一个缓冲区首部的BH_Dirty标志被置位,就应该设置相应缓冲区页的PG_dirty标志。当内核选择要刷新的缓冲区页时,它扫描相应的缓冲区首部,并只把脏块的内容有效地写到磁盘。一旦内核把页缓冲区的所有脏块刷新到磁盘,就把页的PG_dirty标记清0。
pdflush内核线程
早期版本的Linux使用bdflush内核线程系统地扫描页高速缓存以搜索要刷新的脏页,并且使用另一个内核线程kupdate来保证所有的页不会“脏”太长的时间。Linux 2.6用一组通用内核线程pdflush代替上述两个线程。
这些内核线程结构灵活,它们作用于两个参数:
一个指向线程要执行的函数的指针和一个函数要用的参数。
系统中pdflush内核线程的数量是要动态调整的:pdflush线程太少时就创建,太多时就杀死。
因为这些内核线程所执行的函数可以阻塞,所以创建多个而不是一个pdflush内核线程可以改善系统性能。
根据下面的原则控制pdflush线程的产生和消亡:
- (1). 必须有至少两个,最多八个
pdflush内核线程。 - (2). 如果到最近的1s期间没有空闲
pdflush,就应该创建新的pdflush。 - (3). 如果最近一次
pdflush变为空闲的时间超过了1s,就应该删除一个pdflush。
所有的pdflush内核线程都有pdflush_work描述符。空闲pdflush内核线程的描述符都集中在pdFlush_list链表中;
在多处理器系统中,pdflush_lock自旋锁保护该链表不会被并发访问。nr_pdflush_threads变量存放pdflush内核线程(空闲的或忙的)的总数。最后,last_empty_jifs变量存放pdflush线程的pdflush_list链表变为空的时间(以jiffies表示)。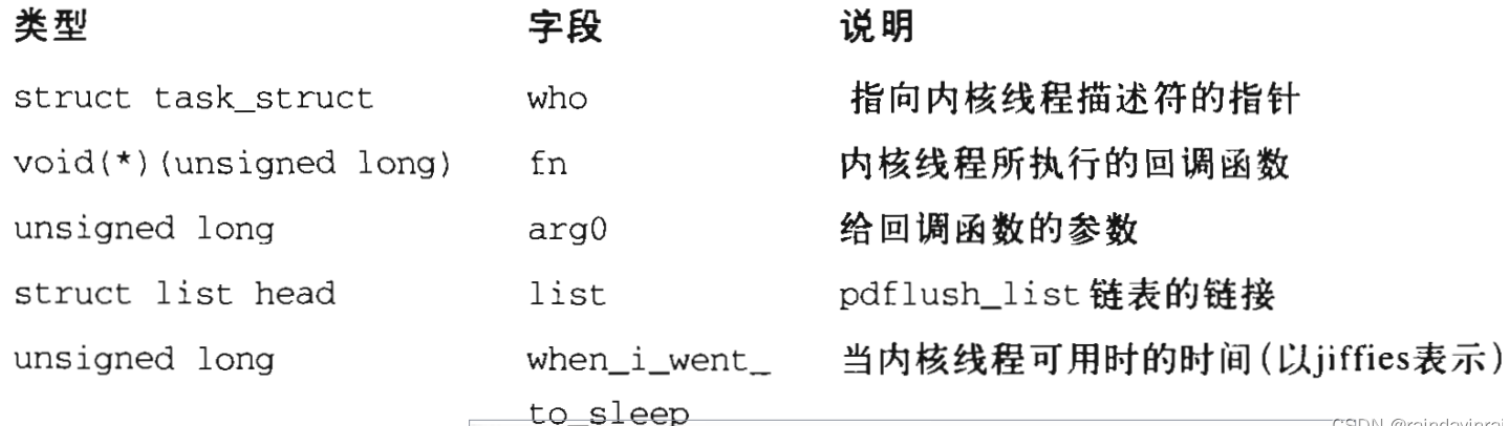
所有pdflush内核线程都执行函数__pdflush(),它本质上循环执行一直到内核线程死亡。我们不妨假设pdflush内核线程是空闲的,而进程正在TASK_INTERRUPTIBLE状态睡眠。一但内核线程被唤醒,__pdflush()就访问其pdflush_work描述符,并执行字段fn中的回调函数,把arg0字段中的参数传递给该函数。
当回调函数结束时,__pdflush()检查last_empty_jifs变量的值如果不存在空闲pdflush内核线程的时间已经超过1s,而且pdflush内核线程的数量不到8个,函数__pdflush()就创建另外一个内核线程。相反,如果pdflush_list链表中的最后一项对应的pdflush内核线程空闲时间超过了1s,而且系统中有两个以上的pdflush内核线程,函数__pdflush()就终止:相应的内核线程执行_exit()系统调用,并因此而被撤消。否则,如果系统中pdflush内核线程不多于两个,__pdflush()就把内核线程的pdflush_work描述符重新插入到pdflush_list链表中,并使内核线程睡眠。
pdflush_operation()函数用来激活空闲的pdflush内核线程。该函数作用于两个参数:一个指针fn,指向必须执行的函数;以及参数arg0。
函数执行下面的步骤:
(1). 从pdflush_list链表中获取pdf指针,它指向空闲pdlush内核线程的pdflush_work描述符。如果链表为空,就返回-1。如果链表中仅剩一个元素,就把jiffies的值赋给变量last_empty_jifs。
(2). 把参数fn和arg0分别赋给pdf->fn和pdf->arg0。
(3). 调用wake_up_process()唤醒空闲的pdflush内核线程,即pdf->who。把哪些工作委托给Pdflush内核线程来完成呢?其中一些工作与脏数据的刷新相关。尤其是,pdflush通常执行下面的回调函数之一:
a. background_writeout():系统地扫描页高速缓存以搜索要刷新的脏页。
b. wb_kupdate():检查页高速缓存中是否有“脏”了很长时间的页。
搜索要刷新的脏页
所有的基树都可能有要刷新的脏页。为了得到所有这些页,就要彻底搜索与在磁盘上有映像的索引节点相应的所有address_space对象。由于页高速缓存可能有大量的页,如果用一个单独的执行流来扫描整个高速缓存,会令CPU和磁盘长时间繁忙。因此,Linux 使用一种复杂的机制把对页高速缓存的扫描划分为几个执行流。
wakeup_bdflush()函数接收页高速缓存中应该刷新的脏页数量作为参数;0值表示高速缓存中的所有脏页都应该写回磁盘。
该函数调用pdflush_operation()唤醒pdflush内核线程,并委托它执行回调函数background_writeout(),后者有效地从页高速缓存获得指定数量的脏页,并把它们写回磁盘。当内存不足或用户显式地请求刷新操作时执行wakeup_bdflush()函数。
特别是在下述情况下会调用该函数:
- (1). 用户态进程发出
sync()系统调用 - (2).
grow_buffers()函数分配一个新缓冲区页时失败 - (3). 页框回收算法调用
free_more_memory()或try_to_free_pages() - (4).
mempool_alloc()函数分配一个新的内存池元素时失败
此外,执行background_writeout()回调函数的pdflush内核线程也可由满足以下两个条件的进程唤醒的:
一是对页高速缓存中的页内容进行了修改,
二是引起脏页部分增加到超过某个脏背景阈值(background threshold)。
背景阈值通常设置为系统中所有页的10%,不过可以通过修改文件/proc/sys/vm/dirty_background_ratio来调整这个值。
background_writeout()函数依赖于作为双向通信设备的writeback_control结构:
一方面,它告诉辅助函数writeback_inodes()要做什么;
另一方面,它保存写回磁盘的页的数量的统计值。下面是这个结构最重要的字段:sync_mode,表示同步模式:WB_SYNC_ALL表示如果遇到一个上锁的索引节点,必须等待而不能略过它;WB_SYNC_HOLD表示把上锁的索引节点放入稍后涉及的链表中;WB_SYNC_NONE表示简单地略过上锁的索引节点。bdi,如果不为空,就指向backing_dev_info结构。此时,只有属于基本块设备的脏页将会被刷新。older_than_this,如果不为空,就表示应该略过比指定值还新的索引节点。nr_to_write,当前执行流中仍然要写的脏页的数量。nonblocking,如果这个标志被置位,就不能阻塞进程。
background_writeout()函数只作用于一个参数nr_pages,表示应该刷新到磁盘的最少页数。它本质上执行下述步骤:
- 从每
CPU变量page_state中读当前页高速缓存中页和脏页的数量。如果脏页所占的比例低于给定的阀值,而且已经至少有nr_pages页被刷新到磁盘,该函数就终止。这个阈值通常大约是系统中总页数的40%,可以通过写文件/proc/sys/vmldirty_ratio来调整这个值。 - 调用
writeback_inodes()尝试写1024个脏页(见下面)。 - 检查有效写过的页的数量,并减少需要写的页的个数。
- 如果已经写过的页少于
1024页,或略过了一些页,则可能块设备的请求队列处于拥塞状态:此时,background_writeout()函数使当前进程在特定的等待队列上睡眠100ms,或使当前进程睡眠到队列变得不拥塞。 - 返回到第
1步。
writeback_inodes()函数只作用于一个参数,就是指针wbc,它指向writeback_control 描述符。该描述符的nr_to_write字段存有要刷新到磁盘的页数。函数返回时,该字段存有要刷新到磁盘的剩余页数,如果一切顺利,则该字段的值被赋为0。
我们假设writeback_inodes()函数被调用的条件为:
- 指针
wbc->bdi和wbc ->older_than_this被置为NULL, WB_SYNC_NONE同步模式和wbc->nonblocking标志置位(这些值都由background_writeout()函数设置)。
函数writeback_inodes()扫描在super_blocks变量中建立的超级块链表。当遍历完整个链表或刷新的页数达到预期数量时,就停止扫描。对每个超级块sb。
函数执行下述步骤:
检查
sb->s_dirty或sb->s_io链表是否为空:第一个链表集中了超级块的脏索引节点,而第二个链表集中了等待被传输到磁盘的索引节点(见下面)。如果两个链表都为空,说明相应文件系统的索引节点没有脏页,因此函数处理链表中的下一个超级块。此时,超级块有脏索引节点。对超级块
sb调用sync_sb_inodes(),该函数执行下面的操作:- 把
sb->s_dirty的所有索引节点插入sb->s_io指向的链表,并清空脏索引节点链表。 - 从
sb->s_io获得下一个索引节点的指针。如果该链表为空,就返回。 - 如果
sync_sb_inodes()函数开始执行后,索引节点变为脏节点,就略过这个索引节点的脏页并返回。注意,sb->s_io链表中可能残留一些脏索引节点。 - 如果当前进程是
pdflush内核线程,sync_sb_inodes()就检查运行在另一个CPU上的pdflush内核线程是否已经试图刷新这个块设备文件的脏页。这是通过一个原子测试和对索引节点的backing_dev_info的BDI_pdflush标志的设置操作来完成的。本质上,它对同一个请求队列上有多个pdflush内核线程是毫无意义的。 - 把索引节点的引用计数器加1。
- 调用
__writeback_single_inode()回写与所选择的索引节点相关的脏缓冲区 - 如果索引节点被锁定,就把它移到脏索引节点链表中(
inode->i_sb->s_dirty)并返回0。(因为我们假定wbc->sync_mode字段不等于WB_SYNC_ALL,所以函数不会因为等待索引结点解锁而阻塞。) - 使用索引节点地址空间的
writepages方法,或者在没有这个方法的情况下使用mpage_writepages()函数来写wbc->nr_to_write个脏页。该函数调用find_get_pages_tag()函数快速获得索引节点地址空间的所有脏页,细节将在下一章描述。 - 如果索引节点是脏的,就用超级块的
write_inode方法把索引节点写到磁盘。实现该方法的函数通常依靠submit_bh()来传输一个数据块。 - 检查索引节点的状态。如果索引节点还有脏页,就把索引节点移回
sb->s_dirty链表;如果索引节点引用计数器为0,就把索引节点移到inode_unused链表中;否则就把索引节点移到inode_in_use链表中。 - 返回在错误代码。
- 回到
sync_sb_inodes()函数中。如果当前进程是pdflush内核线程,就把在第2d步设置的BDI_pdflush标志清0。 - 如果略过了刚处理的索引节点中的一些页,那么该索引节点包括锁定的缓冲区:把
sb->S_io链表中的所有剩余索引节点移回到sb->s_dirty链表中,以后将重新处理它们。 - 把索引节点的引用计数器减
1。 - 如果
wbc->nr_to_write大于0,则回到第2.2步搜索同一个超级块的其他脏索引节点。否则,sync_sb_inodes()函数终止。
- 把
回到
writeback_inodes()函数中。如果wbc->nr_to_write大于0,就跳转到第1步,并继续处理全局链表中的下一个超级块。否则,就返回。
回写陈旧的脏页
如前所述,内核试图避免当一些页很久没有被刷新时发生饥饿危险。因此,脏页在保留一定时间后,内核就显式地开始进行I/O数据的传输,把脏页的内容写到磁盘。回写陈旧脏页的工作委托给了被定期唤醒的pdflush内核线程。在内核初始化期间,page_writeback_init()函数建立wb_timer动态定时器,以便定时器的到期时间发生在dirty_writeback_centisecs文件中所规定的几百分之一秒之后(通常是500分之一秒,不过可以通过修改/proc/sys/vm/dirty_writeback_centisecs文件调整这个值)。
定时器函数wb_timer_fn()本质上调用pdflush_operation()函数,传递给它的参数是回调函数wb_kupdate()的地址。wb_kupdate()函数遍历页高速缓存搜索陈旧的脏索引节点。
它执行下面的步骤:
- 调用
sync_supers()函数把脏的超级块写到磁盘中。虽然这与页高速缓存中的页刷新没有很密切的关系,但对sync_supers()的调用确保了任何超级块脏的时间通常不会超过5s。 - 把当前时间减
30s所对应的值(用jiffies表示)的指针存放在writeback_control描述符的older_than_this字段中。允许一个页保持脏状态的最长时间是30s。 - 根据每
CPU变量page_state确定当前在页高速缓存中脏页的大概数量。 - 反复调用
writeback_inodes(),直到写入磁盘的页数等于上一步所确定的值,或直到把所有保持脏状态时间超过30s的页都写到磁盘。如果在循环的过程中一些请求队列变得拥塞,函数就可能去睡眠。 - 用
mod_timer()重新启动wb_timer动态定时器: - 一旦从调用该函数开始经历过文件
dirty_writeback_centisecs中规定的几百分之一秒时间后,定时器到期(或者如果本次执行的时间太长,就从现在开始1s后到期)。
sync()、fsync()和fdatasync()系统调用
在本节我们简要介绍用户应用程序把脏缓冲区刷新到磁盘会用到的三个系统调用:sync(),允许进程把所有的脏缓冲区刷新到磁盘fsync(),允许进程把属于特定打开文件的所有块刷新到磁盘。fdatasync(),与fsync()非常相似,但不刷新文件的索引节点块。
sync()系统调用
sync()系统调用的服务例程sys_sync()调用一系列辅助函数:
wakeup_bdflush(0);
sync_inodes(0);
sync_supers();
sync_filesystems(0);
sync_filesystems(1);
sync_inodes(1);正如上一节所描述的,wakeup_bdflush()启动pdflush内核线程,把页高速缓存中的所有脏页刷新到磁盘。sync_inodes()函数扫描超级块的链表以搜索要刷新的脏索引节点;它作用于参数wait,该参数表示在执行完刷新之前函数是否必须等待。函数扫描当前已安装的所有文件系统的超级块;对于每个包含脏索引节点的超级块,sync_inodes()
首先调用sync_sb_inodes()刷新相应的脏页,然后调用sync_blockdev()显式刷新该超级块所在块设备的脏缓冲区页。
这一步之所以能完成是因为许多磁盘文件系统的write_inode超级块方法仅仅把磁盘索引节点对应的块缓冲区标记为“脏”;
- 函数
sync_blockdev()确保把sync_sb_inodes()所完成的更新有效地写到磁盘。 - 函数
sync_supers()把脏超级块写到磁盘,如果需要,也可以使用适当的write_super超级块操作。 - 最后,
sync_filesystems()为所有可写的文件系统执行sync_fs超级块方法。
该方法只不过是提供给文件系统的一个“钩子”,在需要对每个同步执行一些特殊操作时使用,只有像Ext3这样的日志文件系统使用这个方法。注意,sync_inodes()和sync_filesystems()都是被调用两次,一次是参数wait等于0时,另一次是wait等于1时。
这样做的目的是:首先,它们把未上锁的索引节点快速刷新到磁盘;其次,它们等待所有上锁的索引节点被解锁,然后把它们逐个地写到磁盘。
fsync()和fdatasync()系统调用
系统调用fsync()强制内核把文件描述符参数fd所指定文件的所有脏缓冲区写到磁盘中(如果需要,还包括存有索引节点的缓冲区)。相应的服务例程获得文件对象的地址,并随后调用fsync方法。通常这个方法以调用函数__writeback_single_inode结束,该函数把与被选中的索引节点相关的脏页和索引节点本身都写回磁盘。
系统调用fdatasync()与fsync()非常相似,但是它只把包含文件数据而不是那些包含索引节点信息的缓冲区写到磁盘。由于Linux 2.6没有提供专门的fdatasync()文件方法,该系统调用使用fsync方法,因此与fsync()是相同的。
页框回收
算法
Linux内核的页框回收算法(page frame reclaiming algorithm,PFRA)采取从用户态进程和内核高速缓存“窃取”页框的办法补充伙伴系统的空闲块列表。
1.选择目标页
页框回收算法(PFRA)的目标就是获得页框并使之空闲。显然,PFRA选取的页框肯定不是空闲的,即这些页框原本不在伙伴系统的任何一个free_area数组中。PFRA按照页框所含内容,以不同的方式处理页框。
我们将它们区分成:不可回收页、可交换页、可同步页和可丢弃页,如表17-1所示。
| 页框类型 | 说明 | 回收操作 |
|---|---|---|
| 不可回收页 | 空闲页,保留页(PG_reserved),内核动态分配页,进程内核态堆栈页,临时锁定页(PG_locked),内存锁定页(VM_LOCKED) | 无需回收 |
| 可交换页 | 用户态地址空间的匿名线性区的页(用户态堆,用户态栈),tmpfs文件系统的映射页(IPC共享内存页) | 将页的内容写入磁盘交换区 |
| 可同步页 | 用户态地址空间有名线性区(又可分为匿名映射,文件映射)下的页,存有磁盘文件数据且在高速缓存中的页,块设备缓存区页 | 将页内容写入磁盘对应位置 |
| 可丢弃页 | 用于slab的页 | 无需操作 |
采用mmap得到的用户态线性区中的页称为可同步的,为回收页框,内核必须检查页是否为脏,而且必要时将页的内容写到相应的磁盘文件中。
进程的匿名线性区(如进程的用户态堆和堆栈对应的线性区)中的页称为可交换的,为回收页框,内核必须将页中内容保存到一个专门的磁盘分区或磁盘文件,叫做“交换区”。tmpfs下的映射页用于实现IPC共享内存,也算可交换的。
当PFRA必须回收属于某进程用户态地址空间的页框时,它必须考虑页框是否为共享的。共享页框属于多个用户态地址空间,而非共享页框属于单个用户态地址空间。同一线程组内多个线程共享一个用户态地址空间。
2.PFRA设计
让我们先看看PFRA采用的几个总的原则,这些原则包含在本章后面介绍的几个函数中。
- 首先释放“无害”页
先回收没有被任何进程使用的磁盘高速缓存,内存高速缓存中的页框。
再回收被进程使用的页框。
- 将用户态进程的所有页定为可回收页,除了锁定页,
FPRA必须能够窃得任何用户态进程页,包括匿名页。 - 同时取消引用一个共享页框的所有页表项的映射,就可以回收该共享页框。当
PFRA要释放几个进程共享的页框时,它就清空引用该页框的所有页表项,然后回收该页框。 - 只回收“未用”页。使用简化的最近最少使用(
Least Recently Used,LRU)置换算法,PFRA将页分为“在用(in_use)”与“未用(unused)”。如果某页很长时间没有被访问,那么它将来被访问的可能性较小,就可以将它看作未用;另一方面,如果某页最近被访问过,那么它将来被访问的可能性较大,就必须将它看作在用。PFRA只回收未用页。
Linux使用每个页表项中的访问标志位(Accessed),在页被访问时,该标志位由硬件自动置位;而且,页年龄由页描述符在链表(两个不同的链表之一)中的位置来表示。因此,页框回收算法是几种启发式方法的混合:
- (1). 谨慎选择检查高速缓存的顺序。
- (2). 基于页年龄的变化排序(在释放最近访问的页之前,应当释放最近最少使用的页)。
- (3). 区别对待不同状态的页(例如,不脏的页与脏页之间,最好把前者换出,因为前者不必写磁盘)。
3.反向映射
Linux 2.6内核能够快速定位指向同一页框的所有页表项。这个过程就叫做反向映射(reverse mapping)。
实际上,对任何可回收的用户态页,内核保留系统中该页所在所有线性区(“对象”)的反向链接,每个线性区描述符存放一个指针指向一个内存描述符,而该内存描述符又包含一个指针指向一个页全局目录(Page Global Directory)。因此,这些反向链接使得PFRA能够检索引用某页的所有页表项。因为线性区描述符比页描述符少,所以更新共享页的反向链接就比较省时间。我们来看看这一方法是如何实现的。
首先,PFRA必须要确定待回收页是共享的或是非共享的,以及是映射页或是匿名页。为做到这一点,内核要查看页描述符的两个字段:_mapcount和mapping。_mapcount字段存放引用页框的页表项数目。计数器的起始值为-1,这表示没有页表项引用该页框;如果值为0,就表示页是非共享的;而如果值大于0,则表示页是共享的。
page_mapcount函数接收页描述符地址,返回值为_mapcount + 1 (这样,如返回值为1,表明是某个进程的用户态地址空间中存放的一个非共享页)。
页描述符的mapping字段用于确定页是映射的或匿名的。说明如下:
- 如果
mapping字段空,则该页属于交换高速缓存。 - 如果
mapping字段非空,且最低位是1,表示该页为匿名页;同时mapping字段中存放的是指向anon_vma(用于找到匿名线性区)描述符的指针。 - 如果
mapping字段非空,且最低位是0,表示该页为映射页;同时mapping字段指向对应文件的address_space(用于找到位于磁盘后备对象)对象。
PageAnon():函数接收页描述符地址作为参数,如果mapping字段的最低位置位,则函数返回1;否则返回0。try_to_unmap():函数接收页描述符指针作为参数,尝试清空所有引用该页描述符对应页框的页表项。如果从页表项中成功清除所有对该页框的应用,函数返回SWAP_SUCCESS (0);如果有些引用不能清除,函数返回SWAP_AGAIN(1);如果出错,函数返回SWAP_FAIL
这个函数很短:
int try_to_unmap(struct page *page)
{
int ret;
if(PageAnon(page))
ret = try_to_unmap_anon(page);
else
ret = try_to_unmap_file(page);
if(!page_mapped(page))
ret = SWAP_SUCCESS;
return ret;
}函数try_to_unmap_anon()和try_to_unmap_file()分别处理匿名页和映射页。后面会对这两个函数加以说明。
3.1.匿名页的反向映射
匿名页的共享主要在父子进程间。将引用同一个页框的所有匿名页链接起来的策略非常简单,即将该页框所在的匿名线性区存放在一个双向循环链表中。当为一个匿名线性区分配第一页时,内核创建一个新的anon_vma数据结构,它只有两个字段:lock和head。lock字段是竞争条件下保护链表的自旋锁;head字段是线性区描述符双向循环链表的头部。然后,内核将匿名线性区的vm_area_struct描述符插入anon_vma链表。为实现这个目的,vm_area_struct数据结构中包含有对应该链表的两个字段:anon_vma_node(自身作为一个节点存在于双向链表)和anon_vma(指向双向链表哨兵节点)。最后,按前面所述,内核将anon_vma数据结构的地址存放在匿名页描述符的mapping字段。调用fork()系统调用实现匿名页父子间共享时,内核只是将第二个进程的匿名线性区插入anon_vma数据结构的双向循环链表。
3.2.try_to_unmap_anon()函数
当回收匿名页框时,PFRA必须扫描anon_vma链表中的所有线性区,仔细检查是否每个区域都存有一个匿名页,而其对应的页框就是目标页框。
try_to_unmap_anon():
参数:
- 目标页框描述符
主要步骤:
- 获得
anon_vma数据结构的自旋锁,页描述符的mapping字段指向该数据结构。 - 扫描线性区描述符的
anon_vma链表。
对该链表中的每一个vma线性区描述符,调用try_to_unmap_one()函数,传给它参数vma和页描述符。如果由于某种原因返回值为SWAP_FAIL,或如果页描述符的_mapcount字段表明已找到所有引用该页框的页表项,那么停止扫描,而不用扫描到链表底部。 - 释放第1步得到的自旋锁。
- 返回最后调用
try_to_unmap_one()函数得到的值:SWAP_AGAIN(部分成功)或SWAP_FAIL(失败)。
3.3.try_to_unmap_one()函数
try_to_unmap_one()函数由try_to_unmap_anon()和try_to_unmap_file()重复调用。
参数:
page,是一个指向目标页描述符的指针;vma,而vma是指向线性区描述符的指针。
步骤:
计算出待回收页的线性地址,所依据的参数有:线性区的起始线性地址(
vma->vm_start)、被映射文件的线性区偏移量(vma->vmpgoff),被映射文件内的页偏移量(page->index,这说明匿名页在多个共享其的线性区内相对于线性区起始的偏移一致)。对于匿名页,vma->vmpgoff字段是0或者vm_start / PAGE_SIZE;相应地,page->index字段是区域内的页索引或是页的线性地址除以PAGE_SIZE。如果目标页是匿名页,则检查页的线性地址是否在线性区内。如果不是,则结束并返回
SWAP_AGAIN。从
vma->vm_mm得到内存描述符地址,并获得保护页表的自旋锁vma->vm_mn->page_table_lock。成功调用
pgd_offset()、pud_offset()、pmd_offset()和pte_offset_map()以获得对应目标页线性地址的页表项地址。执行一些检查来验证目标页可有效回收。
下面的检查步骤中,如果任何一步失败,函数跳到第(12)步,结束并返回一个有关的错误码:SWAP_AGAIN或SWAP_FAIL。- 检查指向目标页的页表项。如果不成功,则函数返回
SWAP_AGAIN。这可能在以下几种情形下发生:
- 指向页框的页表项与
COW关联,而vma标识的匿名线性区仍然属于原页框的anon_vma链表。 mremap()系统调用可重新映射线性区,并通过直接修改页表项将页移到用户态地址空间。这种特殊情况下,因为页描述符的index字段不能用于确定页的实际线性地址,所以面向对象的反向映射就不能使用了。
- 文件内存映射是非线性的。
- 验证线性区不是锁定(
VM_LOCKED)或保留(VM_RESERVED)的。如果有锁定(VM_LOCKED)或保留情况之一出现,函数就返回SWAP_FAIL。 - 验证页表项中的访问标志位(
Accessed)被清0。如果没有,该函数将它清0,并返回SWAP_FAIL。访问标志位置位表示页在用,因此不能被回收。
d. 检查页是否属于交换高速缓存,且此时它正由get_user_pages()处理。在这种情形下,为避免恶性竞争条件,函数返回SWAP_FAIL。
- 检查指向目标页的页表项。如果不成功,则函数返回
页可以被回收。如果页表项的
Dirty标志位置位,则将页的PG_dirty标志置位。清空页表项,刷新相应的
TLB。这样就取消了匿名页在一个页表中的注册。如果是匿名页,函数将换出页(
swapped-out page)标识符插入页表项,以便将来访问时将该页换入。而且,递减存放在内存描述符anon_rss字段中的匿名页计数器。
因为匿名页变为空闲页框的逻辑是:- 解除匿名页与所有进程联系
- 将匿名页现有内容写入磁盘
- 此时匿名页变为空闲页。可作为空闲页框进行物理内存分配。
- 每个使用此匿名页的页表中表项需要能包含此页表项指向了一个暂时不在内存的页。且包含此页在磁盘的定位信息。
递减存放在内存描述符
rss字段中的页框计数器。递减页描述符的
_mapcount字段,因为对用户态页表项中页框的引用已被删除。递减存放在页描述符
_count字段中的页框使用计数器。如果计数器变为负数,则从活动或非活动链表中删除页描述符,活动或非活动链表中的页框都是分配出去供外部使用的。现在将页描述符移除,表明对应页框不再供外部使用。而且调用free_hot_page()释放页框,释放后此页框成为空闲页框便可被页框分配器用于新的分配。释放第3步中获得的自旋锁
vma->vm_mm->page_table_lock。返回相应的错误码(成功时返回
SWAP_AGAIN)。
映射页的反向映射
共享匿名页框的数量不是很大,因此用双向链表记录所有使用匿名页框的线性区可行。映射页的共同使用者可能较多,因此,Linux2.6依靠叫做“优先搜索树(priority search tree)”的结构来快速定位引用同一页框的所有线性区。因为映射页描述符的mapping字段指向address_space对象,所以总是能够快速检索搜索树的根。
优先搜索树
Linux 2.6使用的优先搜索树(PST)是基于Edward McCreight于1985年提出的一种数据结构,用于表示一组相互重叠的区间。McCreight树是一个堆和对称搜索树的混合体,且用于对一个区间集进行查询。PST中的每一个区间相当于一个树的节点,它由基索引(radix index)和堆索引(heap index)两个索引来标识。基索引表示区间的起始点而堆索引表示终点。除了基索引和堆索引,PST的每个节点附带一个大小索引(size index)。该大小索引的值为线性区大小(页数)减1。
该大小索引使搜索程序能够区分同一起始文件位置的不同线性区。然而,大小索引会大大增加不同的节点数,会使PST溢出。特别是,当有很多节点具有相同的基索引但堆索引不同时,PST就无法全部容下它们。为了解决这个问题,PST可以包括溢出子树(overflow subtree),该子树以PST的叶为根,且包含具有相同基索引的节点。
此外,不同进程拥有的线性区可能是映射了相同文件的相同部分(如上面提及的标准C 库)。在这种情况下,对应这些区域的所有节点具有相同的基索引、堆索引和大小索引。当必须在PST中插入一个与现存某个节点具有相同索引值(基索引、堆索引和大小索引都相同)的线性区时,内核将该线性区描述符插入一个以原PST节点为根的双向循环列表。
图17-2所示是一个简单的优先搜索树。在图的左侧,我们看到有七个线性区覆盖着一个文件的前六页。每个区间都标有基索引、堆索引和大小索引。在图的右侧,则是对应的PST。注意,子节点的堆索引都不大于相应父节点的堆索引。而且我们可以看到,任意一个节点的左子节点基索引也都不大于右子节点基索引,如果基索引相等,则按照大小索引排序。让我们假定:PFRA搜索包含某页(索引为5)的全部线性区。搜索算法从根(0,5,5)开始,因为相应区间包含该页,那么这就是得到的第一个线性区。然后算法搜索根的左子节点(0,4,4),比较堆索引(4)和页索引,因为堆索引较小,所以区间不包括该页。而且,有了PST的类堆属性,该节点的所有子节点都不包括该页。因此,算法直接跳到根的右子节点(2,3,5),其相应区间包含该页,因此得到这个区间。然后,算法搜索子节点(1,2,3)和(2,0,2),但它们都不包含该页。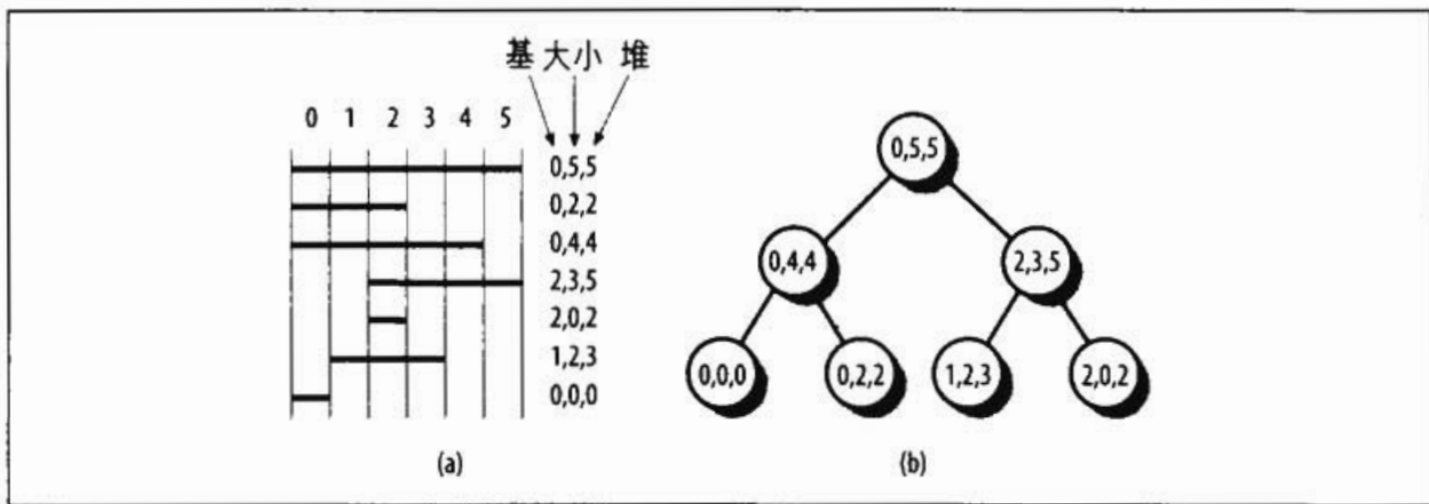
因篇幅有限,我们对实现Linux PST的数据结构与函数无法作详尽阐述。我们只讨论由prio_tree_node数据结构表示的一个PST节点。该数据结构在每个线性区描述符的shared.prio_tree_node字段中。shared.vm_set数据结构作为shared.prio_tree_node 的替代品,可以用来将线性区描述符插入一个PST节点的链表副本。可以用vma_prio_tree_insert()和vma_prio_tree_remove()函数分别插入和删除PST节点。两个函数的参数都是线性区描述符地址与PST根地址。对PST的搜索可调用vma_prio_tree_foreach宏来实现,该宏循环搜索所有线性区描述符,这些描述符在给定范围的线性地址中包含至少一页。
try_to_unmap_file()函数
try_to_unmap_file()函数由try_to_unmap()调用,并执行映射页的反向映射。
当为线性内存映射时,该函数就很容易描述。这种情况下,它执行的步骤如下:
- 获得
page->mapping->i_mmap_lock自旋锁。 - 对搜索树应用
vma_prio_tree_foreach()宏,搜索树的根存放在page->mapping->i_mmap字段。对宏发现的每个vm_area_struct描述符,函数调用try_to_unmap_one(),尝试对该页所在的线性区页表项清0。如果由于某种原因,返回SWAP_FAIL,或者如果页描述符的_mapcount字段表明引用该页框的所有页表项都已找到,则搜索过程马上结束。 - 释放
page->mapping->i_mmap_lock自旋锁。 - 根据所有的页表项清
0与否,返回SWAP_AGAIN或SWAP_FAIL。如果映射是非线性的,那么try_to_unmap_one()函数可能无法清0某些页表项,这是因为页描述符的index字段(该字段存放文件中页的位置)不再对应线性区中的页位置,
try_to_unmap_one()函数就无法确定页的线性地址,也就无法得到页表项地址。唯一的解决方法是对文件非线性线性区的穷尽搜索。双向链表以文件的所有非线性线性区的描述符所在的page->mapping文件的address-space对象的i_rmap_nonlinear字段为根。对每个这样的线性区,try_to_unmap_file()函数调用try_to_unmap_cluster(),而try_to_unmap_cluster()函数会扫描该线性区线性地址所对应的所有页表项,并尝试将它们清0。因为搜索可能很费时,所以执行有限扫描,而且通过试探法决定扫描线性区的哪一部分,vma_area_struct描述符的vm_private_data字段存有当前扫描的当前指针。因此,try_to_unmap_file()函数在某些情况下可能会找不到待停止映射的页。出现这种情况时,try_to_unmap()函数发现页仍然是映射的,那么返回SWAP_AGAIN而不是SWAP_SUCCESS。
PFRA实现
页框回收算法必须处理多种属于用户态进程、磁盘高速缓存的页,“内存高速缓存”(slab中页),而且必须遵照几条试探法准则。因此,PFRA有很多函数也就不奇怪了。图17-3列出了PFRA的主要函数,箭头表示函数调用。例如,try_to_free_pages()函数调用shrink_caches()、shrink_slab()和out_of_memory()三个函数。
正如你所看到的,PFRA有几个入口(entry point)。实际上,页框回收算法的执行有三种基本情形: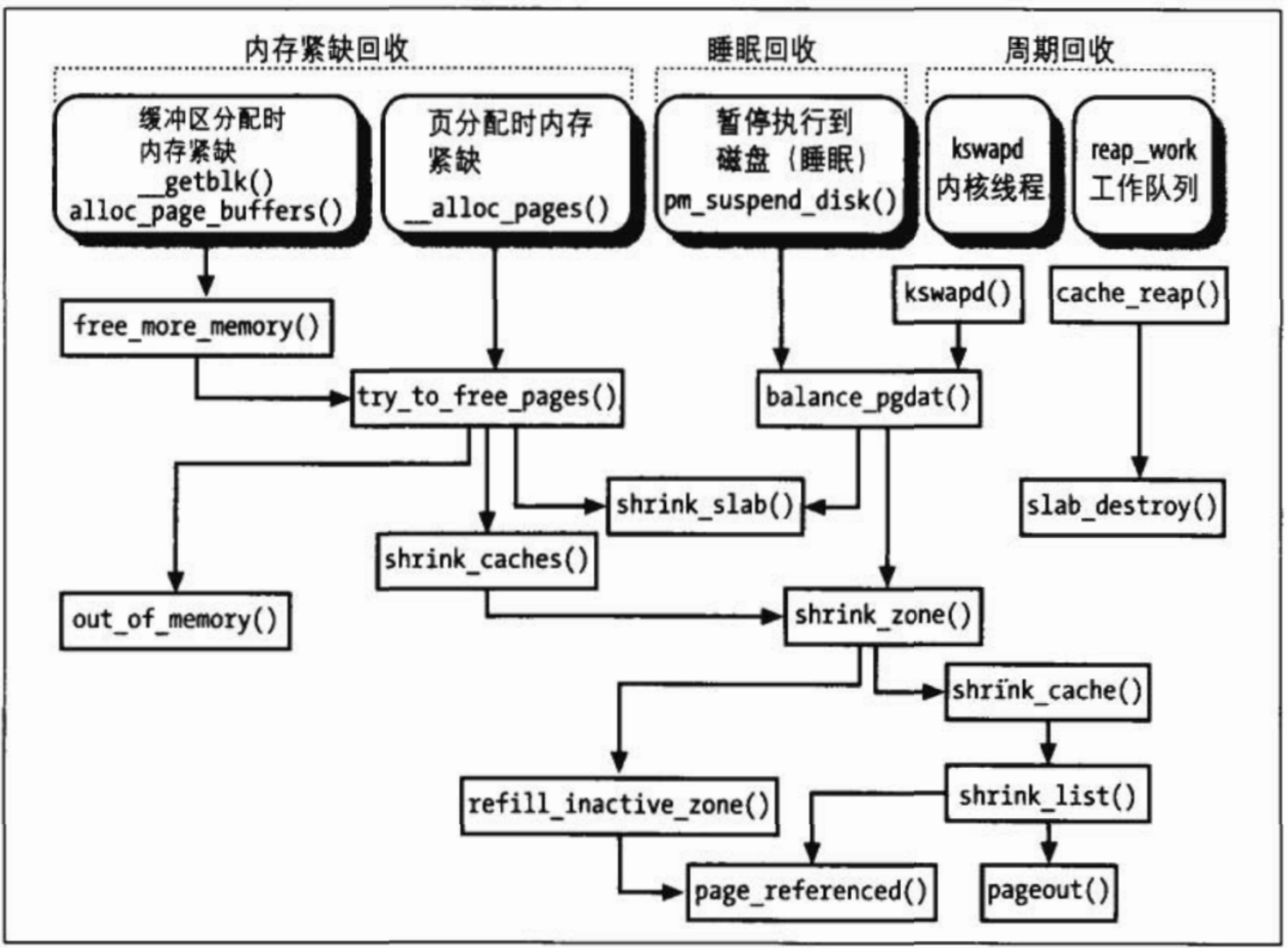
内存紧缺回收,内核发现内存紧缺
睡眠回收,在进入suspend-to-disk状态时,内核必须释放内存
周期回收,必要时,周期性激活内核线程执行内存回收算法
内存紧缺回收在下列几种情形下激活:
grow_buffers()函数(由__getblk()调用)无法获得新的缓冲区页。alloc_page_buffers()函数(由create_empty_buffers()调用)无法获得页临时缓冲区首部。__alloc_pages()函数无法在给定的内存管理区(memory zone)中分配一组连续页框。
周期回收由下面两种不同的内核线程激活:
kswapd内核线程,它检查某个内存管理区中空闲页框数是否已低于pages_high值的标高。events内核线程,它是预定义工作队列的工作者线程;PFRA周期性地调度预定义工作队列中的一个任务执行,从而回收slab分配器处理的位于”内存高速缓存”中的所有空闲slab。
最近最少使用(LRU)链表
属于进程用户态地址空间或页高速缓存的所有页被分成两组:活动链表与非活动链表。它们被统称为LRU链表。前面一个链表用于存放最近被访问过的页;后面的则存放有一段时间没有被访问过的页。显然,页必须从非活动链表中窃取。页的活动链表和非活动链表是页框回收算法的核心数据结构。这两个双向链表的头分别存放在每个zone描述符的active_list(双向链表哨兵节点)和inactive_list(双向链表哨兵节点)字段,而该描述符的nr_active和nr_inactive字段表示存放在两个链表中的页数。最后,lru_lock字段是一个自旋锁,保护两个链表免受SMP系统上的并发访问。
如果页属于LRU链表,则设置页描述符中的PG_1ru标志。此外,如果页属于活动链表,则设置PG_active标志,而如果页属于非活动链表,则清PG_active标志。页描述符的lru字段(双向链表的节点)存放指向LRU链表中下一个元素和前一个元素的指针。另外有几个辅助函数处理LRU链表:
add_page_to_active_list(),将页加入管理区的活动链表头部并递增管理区描述符的nr_active字段。add_page_to_inactive_list(),将页加入管理区的非活动链表头部并递增管理区描述符的nr_inactive字段。del_page_from_active_list(),从管理区的活动链表中删除页并递减管理区描述符的nr_active字段del_page_from_inactive_list(),从管理区的非活动链表中删除页并递减管理区描述符的nr_inactive字段。del_page_from_lru(),检查页的PG_active标志。依据检查结果,将页从活动或非活动链表中删除,递减管理区描述符的nr_active或nr_inactive字段,且如有必要,将PG_active标志清0。activate_page(),检查PG_active标志,如果未置位(页在非活动链表中),将页移到活动列表中,依次调用del_page_from_inactive_list()和add_page_to_active_list(),最后将PG_active标志置位。在移动页之前,获得管理区的lru_lock自旋锁。lru_cache_add(),如果页不在LRU链表中,将PG_lru标志置位,得到管理区的lru_lock自旋锁,调用add_page_to_inactive_list()把页插入管理区的非活动链表。lru_cache_add_active(),如果页不在LRU链表中,将PG_lru和PG_active标志置位,得到管理区的lru_lock自旋锁,调用add_page_to_active_list()把页插入管理区的活动链表。
事实上,最后两个函数,lru_cache_add()和lru_cache_add_active()稍有些复杂。这两个函数实际上并没有立刻把页移到LRU,而是在pagevec类型的临时数据结构中聚集这些页,每个结构可以存放多达14个页描述符指针。只有当一个pagevec结构写满了,页才真正被移到LRU链表中。这种机制可以改善系统性能,这是因为只当LRU链表实际修改后才获得LRU自旋锁。
在LRU链表之间移动页
PFRA把最近访问过的页集中放在活动链表中,以便当查找要回收的页框时不扫描这些页。相反,PFRA把很长时间没有访问的页集中放在非活动链表中。当然,应该根据页是否正被访问,把页从非活动链表移到活动链表或者退回。显然,两个状态(“活动”和“非活动”)是不足以描述所有可能的访问模式的。
页不应该在每次单独的访问中就改变自己的状态似乎是合理的。在页描述符中的PG_referenced标志用来把一个页从非活动链表移到活动链表所需的访问次数加倍;也把一个页从活动链表移到非活动链表所需的“丢失访问”次数加倍。
例如,假定在非活动链表中的一个页其PG_referenced标志为0。第一次访问把这个标志置为1,但是这一页仍然留在非活动链表中。第二次对该页访问时发现这一标志被设置,因此,把页移到活动链表。但是,如果第一次访问之后在给定的时间间隔内第二次访问没有发生,那么页框回收算法就可能重置PG_referenced标志。
从非活动变为活动,先是被引用,再是活动。被引用后一段时间内没有触发变为活动的访问,则取消被引用。如图17-4所示,PFRA使用mark page_accessed()、page_referenced()和refill_inactive_zane()函数在LRU链表之间移动页。在图中,包含有页的LRU链表由PG_active标志的状态表示。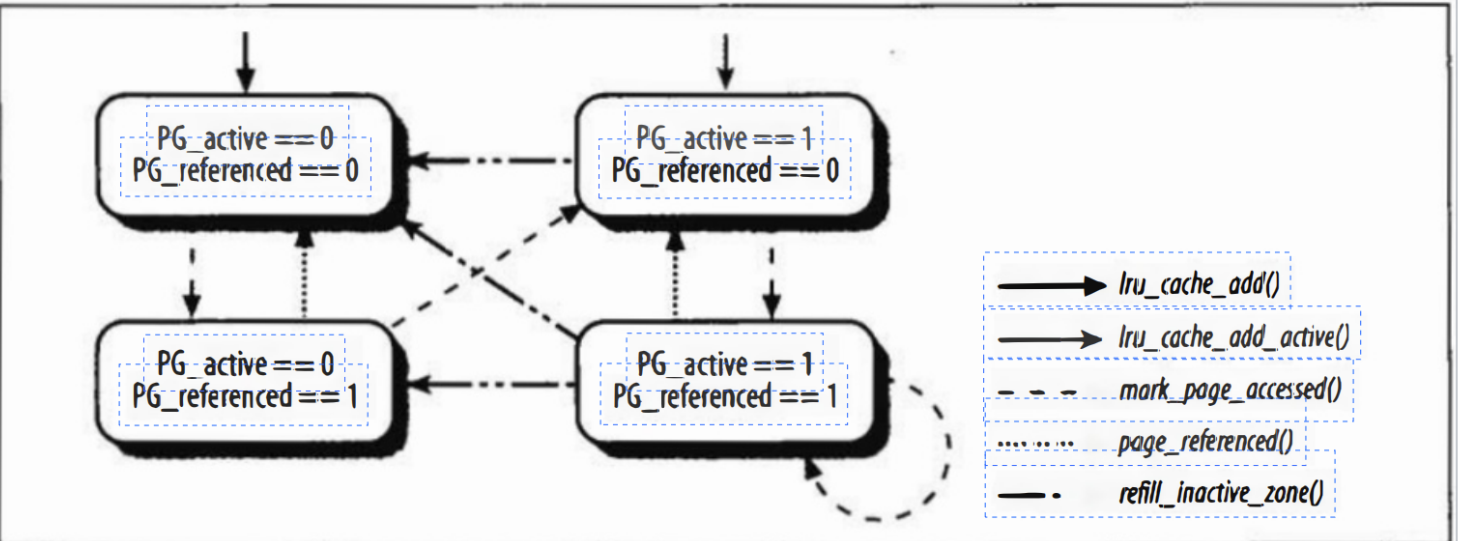
mark_page_accessed()函数
当内核必须把一个页标记为访问过时,就调用mark_page_accessed()函数。每当内核决定一个页是被用户态进程、文件系统层还是设备驱动程序引用时,这种情况就会发生。例如,在下列情况下调用mark_page_accessed():
- 当按需装入进程的一个匿名页(从磁盘交换区装入内存)时(由
do_anonymous_page()函数执行)。 - 当按需装入内存映射文件的一个页(磁盘文件内容装入内存)时(由
filemap_nopage()函数执行)。 - 当按需装入IPC共享内存区的一个页时(由
shmem_nopage()函数执行)。 - 当从文件读取数据页时(由
do_generic_file_read()函数执行)。 - 当换入一个页时(由
do_swap_page()函数执行)。 - 当在页高速缓存中搜索一个缓冲区页时。
mark_page_accessed()函数执行下列代码片段:
if(!PageActive(page)&& PageReferenced(page) && PageLRU(page)){
activate_page(page);
ClearPageReferenced(page);// 激活的同时取消引用
} else if(!PageReferenced(page〉)
SetPageReferenced(page);// 从非引用变为引用如图17-4所示,该函数调用前,只有当PG_referenced标志置位,它才把页从非活动链表移到活动链表。
page_referenced()函数
PFRA扫描一页调用一次page_referenced()函数,如果PG_referenced标志或页表项中的某些Accessed标志位置位,则该函数返回1;否则返回0。该函数首先检查页描述符的PG_referenced标志。如果标志置位则清0。然后使用面向对象的反向映射方法,对引用该页的所有用户态页表项中的Accessed标志位进行检查并清0。为此,函数用到三个辅助函数:page_referenced_anon()、page_referenced_file()和page_referenced_one(),从活动链表到非活动链表移动页由refill_inactive_zone()函数实施的。refill_inactive_zone()函数除此之外还有其他很多功能。
refill_inactive_zone()函数
如图17-3所示,refill_inactive_zone()函数由shrink_zone()调用,而shrink_zone()函数对页高速缓存和用户态地址空间进行页回收。此函数有两个参数:zone和sc。指针zone指向一个内存管理区描述符;指针sc指向一个scan_control结构。PFRA广泛使用scan_control这个数据结构,该结构存放着回收操作执行时的有关信息。
开始时,对每次调用,扫描非活动链表中少量的页,但是当PFRA很难回收内存时,refill_inactive_zone()在每次调用时就逐渐增加扫描的活动页数。scan_control数据结构中priority字段的值控制该函数的行为(低值表示更紧迫的优先级)。还有一个试探法可以调整refill_inactive_zone()函数行为。LRU链表中有两类页:属于用户态地址空间的页、不属于任何用户态进程且在页高速缓存中的页。
如前所述,PFRA倾向于压缩页高速缓存,而将用户态进程的页留在RAM中。refill_inactive_zone()函数使用交换倾向(swap tendency)经验值,由它确定函数是移动所有的页还是只移动不属于用户态地址空间的页。
函数按如下公式计算交换倾向值:交换倾向值=映射比率 / 2 + 负荷值 + 交换值。
映射比率(mapped ratio)是用户态地址空间所有内存管理区的页(sc->nr_mapped)占所有可分配页框数的百分比。mapped_ratio的值大表示动态内存大部分用于用户态进程,而值小则表示大部分用于页高速缓存。负荷值(distress)用于表示PFRA在管理区中回收页框的效率。其依据是前一次PFRA运行时管理区的扫描优先级,这个优先级存放在管理区描述符的prev_priority字段。
交换值(swappiness)是一个用户定义常数,通常为60。系统管理员可以在/proc/sys/vm/swappiness文件内修改这个值,或用相应的sysct1()系统调用调整这个值。只有当管理区交换倾向值大于等于100时,页才从进程地址空间回收。
那么当系统管理员将交换值设为0时,PFRA就不会从用户态地址空间回收页,除非管理区的前一次优先级为0(这不大可能发生)。如果系统管理员将交换值设为100,那么PFRA每次调用该函数时都会从用户态地址空间回收页。
下面是refill_inactive_zone()函数执行步骤的一个简要说明:
- 调用
1ru_add_drain(),把仍留在pagevec数据结构中的所有页移入活动与非活动链表。 - 获得
zone->lru_lock自旋锁。 - 对
zone->active_list中的页进行首次扫描,从链表的底部开始向上,一直执行下去,直到链表为空或sc->nr_to_scan的页扫描完毕。在这一次循环中每扫描一页,函数就将引用计数器加1,从zone->active_list中删除页描述符,把它放在临时局部链表l_hold中。但是如果页框引用计数器是0,则把该页放回活动链表。实际上,引用计数器为0的页框一定属于管理区的伙伴系统,但释放页框时,首先递减使用计数器,然后将页框从LRU链表删除并插入伙伴系统链表。因此在一个很小的时间段,PFRA可能会发现LRU链表中的空闲页。 - 把已扫描的活动页数追加到
zone->pages_scanned。 - 从
zone->nr_active中减去移入局部链表1_hold中的页数。 - 释放
zone->lru_lock自旋锁。 - 计算交换倾向值。
- 对局部链表
1_hold中的页运行第二次循环。这次循环的目的是:把其中的页分到两个子链表l_active和l_inactive中。属于某个进程用户态地址空间的页(即page->_mapcount为非负数的页)被加入l_active的条件是:
交换倾向值小于100,或者是匿名页但又没有激活的交换区,或者应用于该页的page_referenced()函数返回正数(正数表示该页最近被访问过)。而任何其他情形下,页被加入l_inactive链表。
获得zone->lru_lock自旋锁。 - 对局部链表
l_inactive中的页执行第三次循环。把页移入zone->inactive_list链表,更新zone->nr_inactive字段,同时递减被移页框的使用计数器,从而抵消第3步中增加的值。 - 对局部链表
l_active中的页执行第四次也是最后一次循环。把页移入zone->active_list链表,更新zone->nr_active字段,同时递减被移页框的使用计数器,从而抵消第3步中增加的值。 - 释放自旋锁
zone->lru_lock并返回。refill_inactive_zone()只检查用户态地址空间页的PG_referenced标志。相反的情况是,页在活动链表的底部,也就是较长时间以前被访问过,那么不大可能会在近期被访问。如果页属于某个用户态进程且最近被使用过,那么函数也不会将页从活动链表删除。
内存紧缺回收
当内存分配失败时激活内存紧缺回收。在图17-3中,在分配VFS缓冲区或缓冲区首部时,内核调用free_more_memory();而当从伙伴系统分配一个或多个页框时,调用try_to_free_pages()。
free_more_memory()函数
- 调用
wakeup_bdflush()唤醒一个pdflush内核线程,并触发页高速缓存中1024个脏页的写操作。写脏页到磁盘的操作将最终使包含缓冲区、缓冲区首部和其他VFS数据结构的页框成为可释放的。 - 调用
sched_yield()系统调用的服务例程,为pdflush内核线程提供执行机会。 - 对系统的所有内存节点,启动一个循环。
- 对每一个节点,调用
try_to_free_pages()函数,传给它的参数是一个“紧缺”内存管理区链表(在80x86体系结构中是ZONE_DMA和ZONE_NORMAL。
try_to_free_pages()函数
参数:
zones,要回收的页所在的内存管理区链表。gfp_mask,用于失败的内存分配的一组分配标志。order,没有使用。
该函数的目标就是通过重复调用shrink_caches()和shrink_slab()函数释放至少32 个页框,每次调用后优先级会比前一次提高。有关的辅助函数可以获得scan_control 类型描述符中的优先级,以及正在进行的扫描操作的其他参数。最低的、也是初始的优先级是12,而最高的、也是最终的优先级是0。如果try_to_free_pages()没能在某次(共13次)调用shrink_caches()和shrink_slab()函数时成功回收至少32个页框,PFRA就要黔驴技穷了。最后一招:删除一个进程,释放它的所有页框。
这一操作由out_of_memory()函数执行。该函数主要执行如下步骤:
分配和初始化一个
scan_control描述符,具体说就是把分配掩码gfp_mask存入gfp_mask字段。对
zones链表中的每个管理区,将管理区描述符的temp_priority字段设为初始优先级12,而且计算管理区LRU链表中的总页数。从优先级
12到0,执行最多13次的循环,每次迭代执行如下子步骤:- 更新
scan_control描述符的一些字段。具体地,把用户态进程的总页数存入nr_mapped字段,把本次迭代的当前优先级存人priority字段。而且将nr_scanned和nr_reclaimed字段设为0。 - 调用
shrink_caches(),传给它zones链表和scan_control描述符地址作为参数。这个函数扫描管理区的非活动页。 - 调用
shrink_slab()从可压缩内核高速缓存中回收页。 - 如果
current->reclaim_state非空,则将slab分配器高速缓存中回收的页数追加到scan_control描述符的nr_reclaimed字段。在调用try_to_free_pages()函数之前,__alloc_pages()函数建立current->reclaim_state字段,并在结束后马上清除该字段。 - 如果已达目标(
scan_control描述符的nr_reclaimed字段大于等于32),则跳出循环到第4步。 - 如果未达目标,但已扫描完成至少
49页,则调wakeup_bdflush()激活pdflush内核线程,并将页高速缓存中的一些脏页写入磁盘。
如果函数已完成4次迭代而又未达目标,则调用blk_congestion_wait()挂起进程,直到没拥塞的WRITE请求队列或100ms超时已过。
- 更新
把每个管理区描述符的
prev_priority字段设为上一次调用shrink_caches()使用的优先级,该值存放在管理区描述符的temp_priority字段。如果成功回收则返回
1,否则返回0。
shrink_caches()函数
shrink_caches()函数由try_to_free_pages()调用,它有两个参数:内存管理区链表zones和scan_control描述符地址sc。该函数的目的只是对zones链表中的每个管理区调用shrink_zone()函数。但对给定管理区调用shrink_zone()之前,shrink_caches()函数用sc->priority字段的值更新管理区描述符的temp_priority字段,这就是扫描操作的当前优先级。而且如果PFRA的上一次调用优先级高于当前优先级,即这个管理区进行页框回收变得更难了,那么shrink_caches()把当前优先级拷贝到管理区描述符的prev_priority。最后,如果管理区描述符中的all_unreclaimable标志置位,且当前优先级小于12,则shrink_caches()不调用shrink_zone(),也就是说,在try_to_free_pages()的第一迭代中不调用shrink_caches()。当PFRA确定一个管理区都是不可回收页,扫描该管理区的页纯粹是浪费时间时,则将all_unreclaimable标志置位。
shrink_zone()函数
shrink_zone()函数有两个参数:zone和sc。zone是指向struct_zone描述符的指针;sc是指向scan_control描述符的指针。该函数的目标是从管理区非活动链表回收32页。它每次在更大的一段管理区非活动链表上重复调用辅助函数shrink_cache(),以期达到目标。
而且shrink_zone()重复调用refill_inactive_zone()函数来补充管理区非活动链表。管理区描述符的nr_scan_active和nr_scan_inactive字段在这里起到很重要的作用。为提高效率,函数每批处理32页。因此如果函数在低优先级运行(对应sc->priority 的高值),且某个LRU链表中没有足够的页,函数就跳过对这个链表的扫描。但因此跳过的活动或不活动页数就分别存放在nr_scan_active或nr_scan_inactive中,这样函数下次执行时再处理这些跳过的页。
shrink_zone()函数的具体执行步骤如下:
- 递增
zone->nr_scan_active,增量是活动链表(zone->nr_active)的一小部分。实际增量取决于当前优先级,其范围是:zone->nr_active / 2 ^ 12到zone->nr_active / 2(即管理区内的总活动页数)。 递增
zone->nr_scan_inactive,增量是非活动链表(zone->nr_inactive)的一小部分。实际增量取决于当前优先级,其范围是:zone->nr_inactive / 2 ^ 12到zone->nr_inactive。如果
zone->nr_scan_active字段大于等于32,函数就把该值赋给局部变量nr_active,并把该字段设为0,否则把nr_active设为0。- 如果
zone->nr_scan_inactive字段大于等于32,函数就把该值赋给局部变量nr_inactive,并把该字段设为0,否则把nr_inactive设为0。 - 设定
scan_control描述符的sc->nr_to_reclaim字段为32。 - 如果
nr_active和nr_inactive都为0,则无事可做,函数结束。这不常见,用户态进程没有被分配到任何页时才可能出现这种情形。 - 如果
nr_active为正,则补充管理区非活动链表:
sc->nr_to_scan = min(nr_active,32);
nr_active -= sc->nr_to_scan;
refill_inactive_zone(zone,sc);- 如果
nr_inactive为正,则尝试从非活动链表回收最多32页:
sc->nr_to_scan = min(nr_inactive,32);
nr_inactive -= sc->nr_to_scan;
shrink_cache(zone,sc);- 如果
shrink_zone()成功回收32页(现在sc->nr_to_reclaim小于等于0),则结束;否则,跳回第6步。
shrink_cache()函数
shrink_cache()函数又是一个辅助函数,它的主要目的就是从管理区非活动链表取出一组页,把它们放入一个临时链表,然后调用shrink_list()函数对这个链表中的每一页进行有效的页框回收操作。
shrink_cache()函数的参数与shrink_zones()一样,都是zone和sc,执行的主要步骤如下:
- 调用
lru_add_drain(),把仍然在pagevec数据结构中的页移入活动与非活动链表。 - 获得
zone->lru_lock自旋锁。 - 处理非活动链表中的页(最多
32页),对于每一页,函数递增使用计数器;检查该页是否不会被释放到伙伴系统;把页从管理区非活动链表移入一个局部链表。 - 把
zone->nr_inactive计数器的值减去从非活动链表中删除的页数。 - 递增
zone->pages_scanned计数器的值,增量为在非活动链表中有效检查的页数。 - 释放
zone->lru_lock自旋锁。 - 调用
shrink_list()函数,传给它上面第3步中搜集的页。 - 把
sc->nr_to_reclaim字段的值减去由shrink_list()实际回收的页数。 - 再次获取
zone->lru_lock自旋锁。 - 把局部链表中
shrink_list()没有成功释放的页放回非活动或活动链表。注意,shrink_list()有可能置位PG_active标志,从而将某页标记为活动页。这一操作使用pagevec数据结构对一组页进行处理。 - 如果函数扫描的页数至少是
sc->nr_to_scan,且如果没有成功回收目标页数(即sc->nr_to_reclaim仍然大于0),则跳回第3步。 - 释放
zone->lru_lock自旋锁并结束。
shrink_list()函数
我们现在讨论页框回收算法的核心部分。从try_to_free_pages()到shrink_cache()函数,前面所述这些函数的目的就是找到一组适合回收的候选页。shrink_list()函数则从参数page_list链表中尝试回收这些页,该函数的第二个参数sc是指向scan_control 描述符的指针。当shrink_list()返回时,page_list链表中剩下的是无法回收的页。
函数执行步骤如下:
- 如果当前进程的
need_resched字段置位,则调用schedule()。 - 执行一个循环,处理
page_list链表中的每一页。对其中每个元素,从链表中删除页描述符并尝试回收该页框。如果由于某种原因页框不能释放,则把该页描述符插入一个局部链表。 - 现在
page_list已空,函数再把页描述符从局部链表移回page_list链表。 - 递增
sc->nr_reclaimed字段,增量为第2步中回收的页数,并返回这个数。当然,shrink_list()函数尝试回收页框的代码确实很有意思。图17-5是这段代码的流程图。
shrink_list()处理的每个页框只可能有三种结果:
- 调用
free_cold_page()函数,把页释放到管理区伙伴系统,因此被有效回收。 - 页没有被回收,因此被重新插入
page_list链表。但是shrink_list()假设不久还能回收该页。因此函数让页描述符的PG_active标志保持清0,这样页将被放回内存管理区的非活动链表。这种情况对应于图17-5中标为“INACTIVE”的小方框。 - 页没有被回收,因此被重新插入
page_list链表。但是,或是页正被使用,或是shrink_list()假设近期无法回收该页。函数将页描述符的PG_active标志置位,这样页将被放回内存管理区的活动链表。这种情况对应于图17-5中标为“ACTIVE”的小方框。
shrink_list()函数不会去回收锁定页(PG_locked置位)与写回页(PG_writeback 置位)。shrink_list()调用page_referenced()函数检查该页是否最近被引用过,要回收匿名页,就必须把它加入交换高速缓存,那么就必须在交换区为它保留一个新页槽(slot)。
如果页在某个进程的用户态地址空间(页描述符的_mapcount字段大于等于0),则shrink_list()调用try_to_unmap()寻找引用该页框的所有页表项。当然,只有当这个函数返回SWAP_SUCCESS时,回收才可继续。如果是脏页,则写回磁盘前不能回收、为此,shrink_list()使用pageout()。只有当pageout()不必进行写操作或写操作不久将结束时,回收才可继续。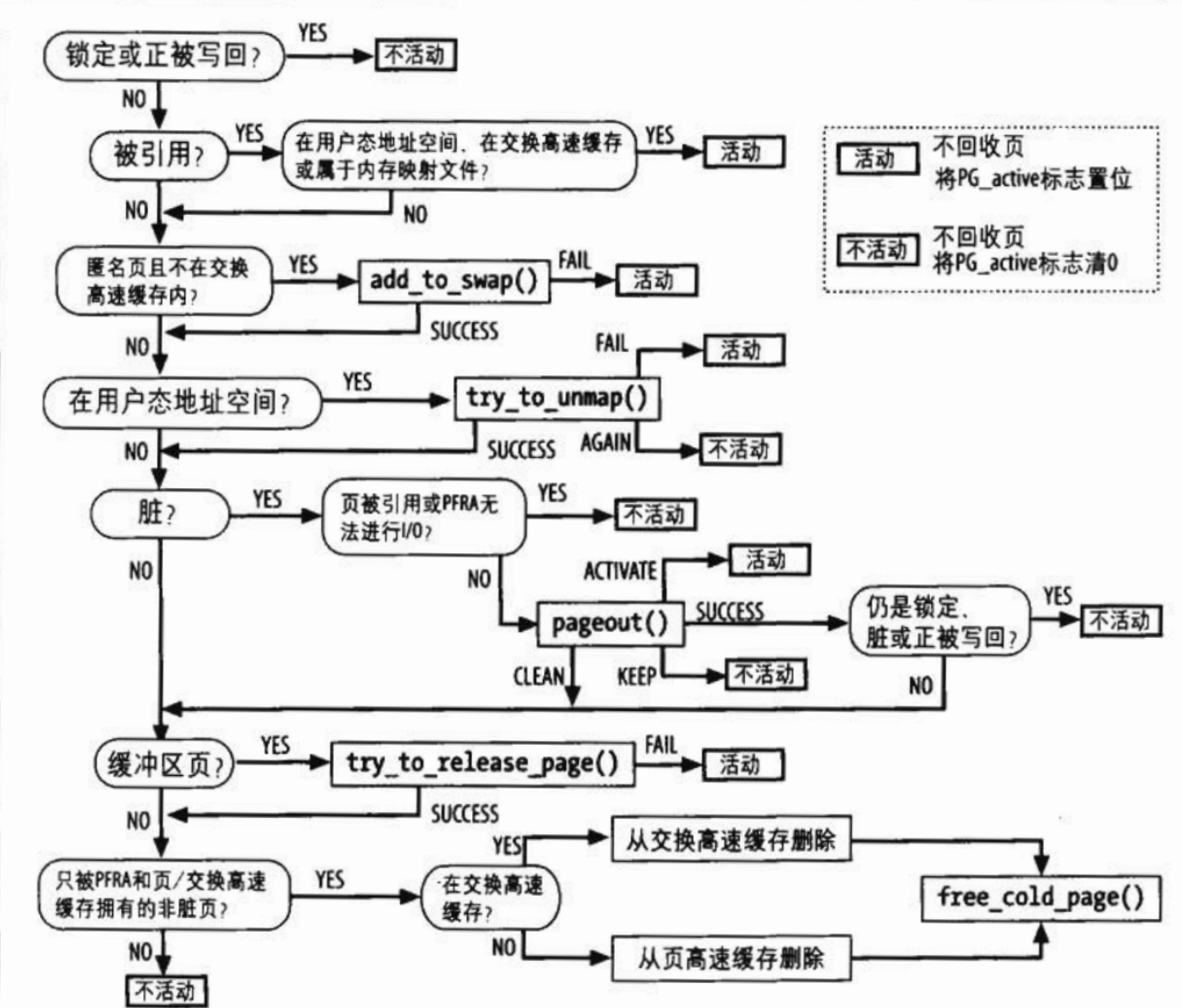
如果页包含VFS缓冲区,则shrink_list()调用try_to_release_page()释放关联的缓冲区首部。
最后,如果一切顺利,shrink_list()就检查页的引用计数器。
若等于2,那么这两个拥有者就是:页高速缓存(如果是匿名页,则为交换高速缓存)和PFRA自己(shrink_cache()函数中第3步中会递增引用计数器,参见前面)。这种情况下,如果页仍然不为脏,则页可以回收。为此,首先根据页描述符的PG_swapcache标志的值,从页高速缓存或交换高速缓存删除该页,然后,执行函数free_cold_page()。
pageout()函数
当一个脏页必须写回磁盘时,shrink_list()调用pageout()函数。函数执行的主要步骤如下:
- 检查页存放在页高速缓存还是交换高速缓存中。进一步检查该页是否由页高速缓存(或交换高速缓存)与
PFRA拥有。如果检查失败,则返回PAGE_KEEP。 - 检查
address_space对象的writepage方法是否已定义。如果没有,则返回PAGE_ACTIVATE。 - 检查当前进程是否可以向块设备(与
address_space对象对应)请求队列发出写请求。实际上,kswapd和pdflush内核线程总会发出写请求;而普通进程只有在请求队列不拥塞的情况下才能发出写请求,除非current->backing_dev_info字段指向块设备的backing_dev_info数据结构。 - 检查是否仍然是脏页。如果不是则返回
PAGE_CLEAN。 - 建立一个
writeback_control描述符,调用address_space对象的writepage方法以启动一个写回操作。 - 如果
writepage方法返回错误码,则函数返回PAGE_ACTIVATE。 - 返回
PAGE_SUCCESS。
回收可压缩磁盘高速缓存的页
内核在页高速缓存之外还使用其他磁盘高速缓存,例如,目录项高速缓存与索引节点高速缓存。
当要回收其中的页框时,PFRA就必须检查这些磁盘高速缓存是否可压缩。PFRA处理的每个磁盘高速缓存在初始化时必须注册一个shrinker函数。shrinker函数有两个参数:待回收页框数和一组GFP分配标志。函数按照要求从磁盘高速缓存回收页,然后返回仍然留在高速缓存内的可回收页数。
set_shrinker()函数向PFRA注册一个shrinker函数。该函数分配一个shrinker类型的描述符,在该描述符中存放shrinker函数的地址,然后把描述符插入一个全局链表,该链表存放在shrinker_list全局变量中,set_shrinker()函数还初始化shrinker 描述符的seeks字段,通俗地说,这个字段表示:在高速缓存中的元素一旦被删除,那么重建一个所需的代价。
在Linux2.6.11中,向PFRA注册的磁盘高速缓存很少。除了目录项高速缓存和索引节点高速缓存之外,注册shrinker函数的只有磁盘限额层、文件系统元信息块高速缓存(主要用于文件系统扩展属性)和XFS日志文件系统。从可压缩磁盘高速缓存回收页的PFRA函数叫作shrink_slab(),它由try_to_free_pages()和balance_pgdat()调用。(函数名有点误导,因为该函数与slab分配器高速缓存没什么关系)。
对于从可压缩磁盘高速缓存回收的代价与及从LRU链表回收的代价之间,shrink_slab()函数试图作出一种权衡。实际上,函数扫描shrinker描述符的链表,调用这些shrinker函数并得到磁盘高速缓存中总的可回收页数。然后,函数再一次扫描shrinker描述符的链表,对于每个可压缩磁盘高速缓存,函数推算出待回收页框数。推算考虑的因素有:磁盘高速缓存中总的可回收页数、在磁盘高速缓存中重建一页的相关代价、LRU链表中的页数。然后再调用shrinker函数尝试回收一组页(至少128页)。因篇幅所限,我们只简单讨论目录项高速缓存和索引节点高速缓存的shrinker函数。
从目录项高速缓存回收页框
shrink_dcache_memory()函数是目录项高速缓存的shrinker函数。它搜索高速缓存中的未用目录项对象,即没有被任何进程引用的目录项对象,然后将它们释放。由于目录项高速缓存对象是通过slab分配器分配的,因此shrink_dcache_memory()函数可能导致一些slab变成空闲的,这样有些页框就可以被cache_reap()回收。此外,目录项高速缓存起索引节点高速缓存控制器的作用,因此,当一个目录项对象被释放时,存放相应索引节点对象的页就可以变为未用,而最终被释放。
shrink_dcache_memory()函数接收两个参数:待回收页框数和GFP掩码。一开始,它检查GFP掩码中的__GFP_FS标志位是否清0。如果是则返回-1,因为释放目录项可能触发基于磁盘文件系统的操作。通过调用prune_dcache(),就可以有效地进行页框回收。该函数扫描未用目录项链表(该链表的头部存放在dentry_unused变量中),一直到获得请求数量的释放对象或整个链表扫描完毕。对每个最近未被引用的对象,函数执行如下步骤:
- 把目录项对象从目录项散列表、从其父目录中的目录项对象链表、从拥有者索引节点的目录项对象链表中删除。
- 调用d_iput目录项方法(如果定义)或者iput()函数减少目录项的索引节点的引用计数器。
- 调用目录项对象的d_release方法(如果定义)。
- 调用call_rcu()函数以注册一个会删除目录项对象的回调函数,该回调函数又调用kmem_cache_free()把对象释放给slab分配器。
- 减少父目录的引用计数器。
最后,依据仍然留在目录项高速缓存中的未用目录项数,shrink_dcache_memory()返回一个值。更准确地说,返回值是未用目录项数乘以100除以sysctl_vfs_cache_pressure全局变量的值。该变量的系统默认值是100,因此返回值实际就是未用目录项数。但是通过修改文件/proc/sys/vm/yfs_cache_pressure或通过有关的sysct1()系统调用,系统管理员可以改变这个变量值。把值改为小于100,则使shrink_slab()从目录项高速缓存回收的页少于从LRU链表中回收的页。反之,如把值改为大于100,则使shrink_slab()从目录项高速缓存回收的页多于从LRU链表中回收的页。
从索引节点高速缓存回收页框
shrink_icache_memory()函数被调用来从索引节点高速缓存删除未用索引节点对象。“未用”就是指索引节点不再有一个控制目录项对象。这个函数非常类似于刚描述的shrink_dcache_memory()。它检查gfp_mask参数的__GFP_FS位,然后调用prune_icache(),最后与前面一样,依据仍然留在索引节点高速缓存中的未用索引节点数和sysctl_vfs_cache_pressure变量的值,返回一个值。
prune_icache()函数又扫描inode_unused链表。要释放一个索引节点,函数必须释放与该索引节点关联的任何私有缓冲区,它使页高速缓存内(引用该索引节点的)不再使用的干净页框无效,然后通过调用clear_inode()和destroy_inode()函数来删除索引节点对象。
周期回收
PFRA用两种机制进行周期回收:kswapd内核线程和cache_reap函数。前者调用shrink_zone()和shrink_slab()从LRU链表中回收页;后者则被周期性地调用以便从slab分配器中回收未用的slab。
kswapd内核线程
kswapd内核线程是激活内存回收的另外一种机制。为什么还需要这个内核线程呢?当空闲内存变得紧缺并且发出另一个内存分配请求时,调用try_to_free_pages()还不足够吗?
有些内存分配请求是由中断和异常处理程序执行的,它们不会阻塞等待释放页框的当前进程;还有,有些内存分配请求是由已经获得对临界资源互斥访问权限,因此就不能激活I/O数据传送的内核控制路径实现的。在极少的情况下,所有的内存分配请求都是由这种内核控制路径完成的,因此内核将永远不能释放空闲内存。kswapd利用机器空闲的时间保持内存空闲也对系统性能有良好的影响,进程因此能很快获得自己的页。
每个内存节点对应各自的kswapd内核线程。每个这样的线程通常睡眠在等待队列中,该等待队列以节点描述符的kswapd_wait字段为头部。但是,如果__alloc_pages()发现所有适合内存分配的内存管理区包含的空闲页框数低于“警告”阈值(一个依据内存管理区描述符的pages_low 和protection字段推算出来的值)时,那么相应内存节点的kswapd内核线程被激活。
从本质上说,为了避免更多紧张的“内存紧缺”的情形,内核才开始回收页框。每个管理区描述符还包括字段pages_min和pages_high。前者表示必须保留的最小空闲页框数阈值;后者表示“安全”空闲页框数阈值,即空闲页框数大于该阈值时,应该停止页框回收。
kswapd内核线程执行kswapd()函数。内核线程被初始化的内容是:把线程绑定到访问内存节点的CPU;再把reclaim_state描述符地址存入进程描述符的current->reclaim_state字段;把current->flags字段的PF_MEMALLOC和PF_KSWAP标志置位,其含义是进程将回收内存,运行时允许使用全部可用空闲内存。每当kswapd内核线程被唤醒,kswapd ()函数执行下列主要操作:
- 调用
finish_wait()从节点的kswapd_wait等待队列删除内核线程。 - 调用
balance_pgdat()对kswapd的内存节点进行内存回收。 - 调用
prepare_to_wait()把进程设成TASK_INTERRUPTIBLE状态,并让它在节点的kswapd_wait等待队列中睡眠。 - 调用
schedule()让CPU处理一些其他可运行进程。
balance_pgdat()函数又执行下面的主要步骤:
- 建立
scan_control描述符。 - 把内存节点的每个管理区描述符中的
temp_priority字段设为12(最低优先级)。 - 执行一个循环,从
12到0最多13次迭代。每次迭代执行下列子步骤:
- 扫描内存管理区,寻找空闲页框数不足的最高管理区(从
ZONE_DMA到ZONE_HIGHMEM)。由zone_watermark_ok()函数进行每次的检测。如果所有管理区都有大量空闲页框,则跳到第4步。- 对一部分管理区再一次进行扫描,范围是从
ZONE_DMA到第3a步找到的管理区。对每个管理区,必要时用当前优先级更新管理区描述符的prev_priority字段,且连续调用shrink_zone()以回收管理区中的页。然后,调用shrink_slab()从可压缩磁盘高速缓存回收页。- 如果已有至少
32页被回收,则跳出循环至第4步。
用各自temp_priority字段的值更新每个管理区描述符的prev_priority字段。
如果仍有“内存紧缺”管理区存在,且如果进程的need_resched字段置位,则调用schedule()。当再一次执行时,跳到第1步。
- 返回回收的页数。
cache_reap()函数
PFRA还必须回收slab分配器高速缓存的页。为此,它使用cache_reap()函数,该函数周期性(差不多每两秒一次)地在预定事件工作队列中被调度。它的地址存放在每CPU变量reap_work 的func字段,该变量为work_struct类型。
cache_reap()函数主要执行如下步骤:
(1). 尝试获得cache_chain_sem信号量,该信号量保护slab高速缓存描述符链表。如果信号量已取得,就调用schedule_delayed_work()去调度该函数的下一次执行,然后结束。
(2). 否则,扫描存放在cache_chain链表中的kmem_cache_t描述符。对找到的每一个高速缓存描述符,函数执行以下步骤:
a. 如果高速缓存描述符的SLAB_NO_REAP标志置位,则页框回收被禁止,因此处理链表中的下一个高速缓存。
b. 清空局部slab高速缓存,则会有新的slab被释放。
c. 每个高速缓存都有“收割时间(reap time)”,该值存放在高速缓存描述符中kmem_list3结构的next_reap字段。如果jiffies值仍然小于next_reap,则继续处理链表中的下一个高速缓存。
d. 把存放在next_reap字段的下一次“收割时间”设为:从现时起的4s。
e. 在多处理器系统中,函数清空slab共享高速缓存,那么会有新的slab被释放。
f. 如有新的slab最近被加入高速缓存,即高速缓存描述符中kmem_list3结构的free_touched置位,那么跳过这个高速缓存,继续处理链表中的下一个高速缓存。
g. 根据经验公式计算要释放的slab数量。基本上,这个数取决于高速缓存中空闲对象数的上限和能装入单个slab的对象数。
h. 对高速缓存空闲slab链表中的每个slab,重复调用slab_destroy(),一直到链表为空或者已回收目标数量的空闲slab。
i. 调用cond_resched()检查当前进程的TIF_NEED_RESCHED标志,如果该标志置位,则调用schedule()。
(3). 释放cache_chain_sem信号量。
(4). 调用schedule_delayed_work()去调度该函数的下一次执行,然后结束。
内存不足删除程序
为满足一些紧迫请求,内核总试图释放内存,但是无法成功,这是因为交换区已满且所有磁盘高速缓存已被压缩。因此,没有进程可以继续执行,也就没有进程会释放它所拥有的页框。为应对这种突发情况,PFRA使用所谓的内存不足(out ofmemory,00M)删除程序,该程序选择系统中的一个进程,强行删除它并释放页框。当空闲内存十分紧缺且PFRA又无法成功回收任何页时,__alloc_pages()调用out_of_memory()函数。函数调用select_bad_process()在现有进程中选择一个“牺牲品”,然后调用oom_kill_process()删除该进程。
当然,select_bad_process()并不是随机挑选进程的。被选进程应满足下列条件:
- 它必须拥有大量页框,从而可以释放出大量内存。
- 删除它只损失少量工作成果(删除一个工作了几个小时或几天的批处理进程就不是个好主意)。
- 它应具有较低的静态优先级,用户通常给不太重要的进程赋予较低的优先级。
- 它不应是有root特权的进程,特权进程的工作通常比较重要。
- 它不应直接访问硬件块设备(如
XWindow服务器),因为硬件不能处在一个无法预知的状态。 - 它不能是
swapper(进程0)、init(进程1)和任何其他内核线程。
select_bad_process()函数扫描系统中的每一个进程,根据以上准则用经验公式计算一个值,这个值表示选择这个进程的有利程度,然后返回最有利的被选进程描述符的地址。out_of_memory()函数再调用oom_kill_process()并发出死亡信号,该信号发给该进程的一个子进程,或如果做不到,就发给该进程本身。oom_kill_process()同时也删除与被选进程共享内存描述符的所有克隆进程。
交换标记
当系统内存不足时,PFRA全力把页写入磁盘以释放内存并从一些进程窃取相应的页框;而同时,这些进程要继续执行,也全力访问它们的页。因此内核把PFRA刚释放的页框又分配给这些进程,并从磁盘读回其内容。
其结果就是页被无休止地写入磁盘并且再从磁盘读回。大部分的时间耗在访问磁盘上,从而没有进程能实质性地运行下去。为减少交换失效的发生,一种由Jiang和Zhang在2004年提出的技术在内核版本2.6.9 中得到实现。即把所谓的交换标记(swap token)赋给系统中的单个进程,该标记可以使该进程免子页框回收,所以进程可以实质性地运行,而且即使内存十分稀少,也有希望运行至结束。交换标记的具体实现形式是swap_token_mm内存描述符指针。当进程拥有交换标记时,swap_token_mm被设为进程内存描述符的地址。
页框回收算法的免除以如此简洁的方式实现了。我们在“最近最少使用(LRU)链表”一节看到,只当最近没有被引用时,一页才可从活动链表移入非活动链表。page_referenced()函数进行这一检查。如果该页属于一个线性区,该区域所在进程拥有交换标记,那么该函数认可这个交换标记并返回1(被引用)。实际上,交换标记在几种情况下不予考虑:PFRA代表一个拥有交换标记的进程运行,以及PFRA达到页框回收的最难优先级(0级)。
grab_swap_token()函数决定是否将交换标记赋给当前进程。对每个主缺页(major page fault)调用该函数,这只有两种情形:
(1). 当filemap_nopage()函数发现请求页不在页高速缓存中时。
(2). 当do_swap_page()函数从交换区读入一个新页时。
grab_swap_token()函数在分配交换标记之前要进行一些检查,具体地说,就是要满足下列条件才可赋予交换标记:
(1). 上次调用grab_swap_token()后,至少已过了2s。
(2). 在上一次调用grab_swap_token()后,当前拥有交换标记的进程没再提出主缺页,或该进程拥有交换标记的时间超出swap_token_default_timeout个节拍。
(3). 当前进程最近没有获得过交换标记。
交换标记的持有时间最好长一些,甚至以分钟为单位,因为其目标就是允许进程完成其执行。在Linux 2.6.11中,交换标记的持有时间默认值很小,即一个节拍。但是,通过编辑/proc/sys/vm/swap_token_default_timeout文件或发出相应的sysct1()系统调用,系统管理员可以修改swap_token_default_timeout变量的值。当删除一个进程时,内核检查该进程是否拥有交换标记。如果是则放开它。这由mmput()函数实现。
交换
交换(swapping)用来为非映射页在磁盘上提供备份。从前面的讨论我们知道有三类页必须由交换子系统处理:
(1). 属于进程(没有名字的线性区)匿名线性区(例如,用户态堆栈和堆)的页。—属于没有名字线性区的页
(2). 属于进程私有内存映射的脏页。—内存映射,映射所在的线性区也是匿名的
(3). 属于IPC共享内存区的页。—内存映射,映射所在的线性区也是匿名的。共享只限于父子进程间。
就像请求调页,交换对于程序必须是透明的。换句话说,不需要在代码中嵌入与交换有关的特别指令。我们知道每个页表项包含一个Present标志。内核利用这个标志来通知属于某个进程地址空间的页已被换出。在这个标志之外,Linux还利用页表项中的其他位存放换出页标识符(swapped-out page identifier)。该标识符用于编码换出页在磁盘上的位置。当缺页异常发生时,相应的异常处理程序可以检测到该页不在RAM中,然后调用函数从磁盘换入该缺页。
交换子系统的主要功能总结如下:
(1). 在磁盘上建立交换区(swap area),用于存放没有磁盘映像的页。
(2). 管理交换区空间。当需求发生时,分配与释放页槽(page slot)。
(3). 提供函数用于从RAM中把页换出(swap out)到交换区或从交换区换入(swap in)到RAM中。
(4). 利用页表项(现已被换出的换出页页表项)中的换出页标识符跟踪数据在交换区中的位置。
总之,交换是页框回收的一个最高级特性。
如果我们要确保进程的所有页框都能被PFRA 随意回收,而不仅仅是回收有磁盘映像的页,那么就必须使用交换。
当然,你可以用swapoff命令关闭交换,但此时随着磁盘系统负载增加,很快就会发生磁盘系统瘫痪。
我们还需指出,交换可以用来扩展内存地址空间,使之被用户态进程有效地使用。
事实上,一个大交换区可允许内核运行几个大需求量的应用,它们的内存总需求量超过系统中安装的物理内存量。
但是,就性能而言,RAM的仿真还是比不上RAM本身。
进程对当前换出页的每一次访问,与对RAM中页的访问比起来,要慢几个数量级。简而言之,如果性能重要,那么交换仅仅作为最后一个方案;为了解决不断增长的计算需求增加RAM芯片的容量仍然是一个最好的方法。
交换区
从内存中换出的页存放在交换区(swap area)中,交换区的实现可以使用自己的磁盘分区,也可以使用包含在大型分区中的文件。可以定义几种不同的交换区,最大个数由MAX_SWAPFILES宏(通常被设置成32)确定。如果有多个交换区,就允许系统管理员把大的交换空间分布在几个磁盘上,以使硬件可以并发操作这些交换区;这样处理还允许在系统运行时不用重新启动系统就可以扩大交换空间的大小。
每个交换区都由一组页槽(page slot)组成,也就是说,由一组4096字节大小的块组成,每块中包含一个换出的页。交换区的第一个页槽用来永久存放有关交换区的信息,其格式由swap_header联合体(由两个结构info和magic组成)来描述。
magic结构提供了一个字符串,用来把磁盘某部分明确地标记成交换区,它只含有一个字段magic。magic,这个字段含有一个10字符的“magic”字符串。magic结构从根本上允许内核明确地把一个文件或分区标记成交换区,这个字符串的内容就是“SWAPSPACE2“。该字段通常位于第一个页槽的末尾。
info结构包括以下字段:
bootbits,交换算法不使用该字段。该字段对应于交换区的第一个1024字节,可以存放分区数据、磁盘标签等等。version,交换算法的版本。last_page,可有效使用的最后一个页槽。nr_badpages,有缺陷的页槽的个数。padding[125],填充字节。badpages[1],一共637个数字,用来指定有缺陷页槽的位置。
创建与激活交换区
只要系统是打开的,存放在交换区中的数据就是有意义的。
当系统被关闭时,所有的进程都被杀死,因此,进程存放在交换区中的数据也被丢弃。
基于这个原因,交换区包含很少的控制信息,实际上包含交换区类型和有缺陷页槽的链表。
这种控制信息很容易存放在一个单独的4KB页中。
通常,系统管理员在创建Linux系统中的其他分区时都创建一个交换分区,然后使用mkswap命令把这个磁盘区设置成一个新的交换区。
该命令对刚才介绍的第一个页槽中的字段进行初始化。
由于磁盘中可能会有一些坏块,这个程序还可以对其他所有的页槽进行检查从而确定有缺陷页槽的位置。但是执行mkswap命令会把交换区设置成非激活的状态。
每个交换区都可以在系统启动时在脚本文件中被激活,也可以在系统运行之后动态激活。每个交换区由一个或多个交换子区(swap extent)组成,每个交换子区由一个swap_extent描述符表示,每个子区对应一组页(更准确地说,是一组页槽),它们在磁盘上是物理相邻的。
swap_extent描述符由下面这几部分组成:交换区的子区首页索引、子区的页数和子区的起始磁盘扇区号。
当激活交换区自身的同时,组成交换区的有序子区链表也被创建。存放在磁盘分区中的交换区只有一个子区;
但是,存放在普通文件中的交换区则可能有多个子区,这是因为文件系统有可能没把该文件全部分配在磁盘的一组连续块中。
如何在交换区中分布页
当换出时,内核尽力把换出的页存放在相邻的页槽中,从而减少在访问交换区时磁盘的寻道时间,这是高效交换算法的一个重要因素。
但是,如果系统使用了多个交换区,事情就变得更加复杂了。快速交换区(也就是存放在快速磁盘中的交换区)可以获得比较高的优先级。
当查找一个空闲页槽时,要从优先级最高的交换区中开始搜索。
如果优先级最高的交换区不止一个,为了避免超负荷地使用其中一个,应该循环选择相同优先级的交换区。
如果在优先级最高的交换区中没有找到空闲页槽,就在优先级次高的交换区中继续进行搜索,依此类推。
交换区描述符
每个活动的交换区在内存中都有自己的swap_info_struct描述符flags字段包括三个重叠的子字段:
SWP_USED,如果交换区是活动的,该值就是1;如果交换区不是活动的,该值就是0。SWP_WRITEOK,如果可以写入交换区,该值就是1;如果交换区只读,该值就是0(可以是活动的或不是活动的)。SWP_ACTIVE,这个两位的字段实际上是SWP_USED和SWP_WRITEOK的组合。如果前面两个标志置位,那么SWP_ACTIVE标志置位。
swap_map字段指向一个计数器数组,交换区的每个页槽对应一个元素。
如果计数器值等于0,那么这个页槽就是空闲的;如果计数器为正数,那么换出页就填充了这个页槽。
实际上,页槽计数器的值就表示共享换出页的进程数。
如果计数器的值为SWAP_MAP_MAX(等于32767),那么存放在这个页槽中的页就是“永久”的,并且不能从相应的页槽中删除。如果计数器的值是SWAP_MAP_BAD(等于32768),那么就认为这个页槽是有缺陷的,也就是不可用的。
prio字段是一个有符号的整数,表示交换子系统依据这个值考虑每个交换区的次序。sdev_lock字段是一个自旋锁,它防止SMP系统上对交换区数据结构(主要是交换描述符)的并发访问。swap_info数组包括MAX_SWAPFILES个交换区描述符。只有那些设置了SWP_USED 标志的交换区才被使用,因为它们是活动区域。
图17-6说明了swap_info数组、一个交换区和相应的计数器数组的情况。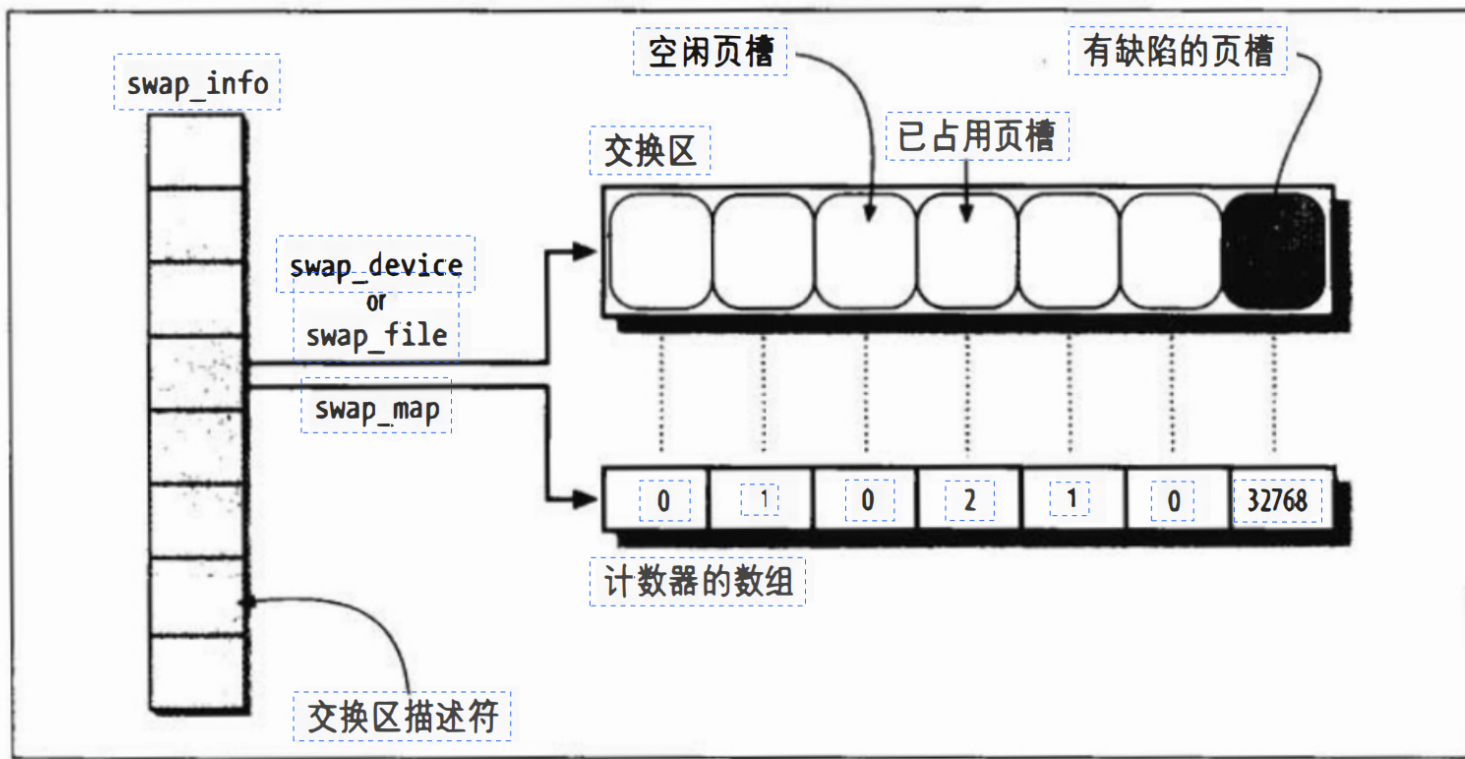
nr_swapfiles变量存放数组中包含或已包含所使用交换区描述符的最后一个元素的索引。- 这个变量有些名不符实,它并没有包含活动交换区的个数。
- 活动交换区描述符也被插入按交换区优先级排序的链表中。
- 该链表是通过交换区描述符的
next字段实现的,next字段存放的是swap_info数组中下一个描述符的索引。该字段作为索引的这种用法与我们已经见过的很多名为next字段的用法有所不同,后者通常都是指针。
swap_list_t类型的swap_list变量包括以下字段:
head,第一个链表元素在swap_info数组中的下标。next,为换出页所选中的下一个交换区的描述符在swap_info数组中的下标。该字段用于在具有空闲页槽的最大优先级的交换区之间实现轮询算法。
swaplock自旋锁防止在多处理器系统中对链表的并发访问。
交换区描述符的max字段存放以页为单位交换区的大小,而pages字段存放可用页槽的数目。
这两个数字之所以不同是因为pages字段并没有考虑第一个页槽和有缺陷的页槽。
最后,nr_swap_pages变量包含所有活动交换区中可用的(空闲并且无缺陷)页槽数目,而total_swap_pages变量包含无缺陷页槽的总数。
换出页标识符
可以很简单地而又唯一地标识一个换出页,这是通过在swap_info数组中指定交换区的索引和在交换区内指定页槽的索引实现的。由于交换区的第一个页(索引为0)留给swap_header联合体,第一个可用页槽的索引就为1。
swp_entry(type,offset)宏负责从交换区索引type和页槽索引offset中构造换出页标识符。swp_type和swp_offset宏,分别从换出页标识符中提取出交换区索引和页槽索引。
当页被换出时,其标识符就作为页的表项插入页表中,这样在需要时就可以再找到这个页。
要注意这种标识符的最低位与Present标志对应,通常被清除来说明该页目前不在RAM中。
但是,剩余31位中至少有一位被置位,因为没有页存放在交换区0的页槽0 中。
这样就可以从一个页表项中区分三种不同的情况:
- 空项,该页不属于进程的地址空间,或相应的页框还没有分配给进程(请求调页)。
- 前
31个最高位不全等于0,最后一位等于0,该页现在被换出。 - 最低位等于
1,该页包含在RAM中。
注意,交换区的最大值由表示页槽的可用位数决定。在80x86体系结构上,有24位可用,这就限制了交换区的大小为2^24个页槽(也就是64GB)。由于一个页可以属于几个进程的地址空间(参见前面的“反向映射”一节),所以它可能从一个进程的地址空间中被换出,但是仍旧保留在主存中;因此可能把同一个页换出多次。当然,一个页在物理上只被换出并存储一次,但是后来每次试图换出该页都会增加swap_map计数器的值。
在试图换出一个已经换出的页时就会调用swap_duplicate()函数。该函数只是验证以参数传递的换出页标识符是否有效,并增加相应的swap_map计数器的值。更确切地说,该函数执行以下操作:
- 使用
swp_type和swp_offset宏从参数中提取出交换区号type和页槽索引offset。 - 检查交换区是否被激活;如果不是,则返回
0(无效的标识符)。 - 检查页槽是否有效且是否不为空闲(
swap_map计数器大于0且小于SWAP_MAP_BAD);如果不是,则返回0(无效的标识符)。 - 否则,换出页的标识符确定出一个有效页的位置。如果页槽的
swap_map计数器还没有达到SWAP_MAP_MAX,则增加它的值。 - 返回
1(有效的标识符)。
激活和禁用交换区
一旦交换区被初始化,超级用户(或者更确切地说是任何具有CAP_SYS_ADMIN权能的用户)就可以分别使用swapon和swapoff程序激活和禁用交换区。这两个程序分别使用了swapon()和swapoff()系统调用,我们将简要介绍相应的服务例程。
sys_swapon()服务例程
sys_swapon()服务例程接收如下参数:specialfile,这个参数指向设备文件(或分区)的路径名(在用户态地址空间),或指向实现交换区的普通文件的路径名。swap_flags,这个参数由一个单独的SWAP_FLAG_PREFER位加上交换区优先级的3I位组成(只有在SWAP_FLAG_PREFER位置位时,优先级位才有意义)。
sys_swapon()函数对创建交换区时放入第一个页槽中的swap_header联合体字段进行检查。其执行的主要步骤有:
检查当前进程是否具有
CAP_SYS_ADMIN权能。在交换区描述符
swap_info数组的前nr_swapfiles个元素中查找SWP_USED标志为0(即对应的交换区不是活动的)的第一个描述符。如果找到一个不活动交换区,则跳到第4步。新交换区数组索引等于
nr_swapfiles:它检查保留给交换区索引的位数是否足够用于编码新索引。如果不够,则返回错误代码;如果足够,就将nr_swapfiles的值加找到未用交换区索引:它初始化这个描述符的字段,即把
flags置为SWP_USED,把lowest_bit和highest_bit置为0。如果
swap_flags参数为新交换区指定了优先级,则设置描述符的prio字段。否则,就把所有活动交换区中最低的优先级减1后赋给这个字段(这样就假设最后一个被激活的交换区在最慢的块设备上)。如果没有其他交换区是活动的,就把该字段设置成-1。从用户态地址空间复制由
specialfile参数所指向的字符串。调用
filp_open()打开由specialfile参数指定的文件。把
filp_open()返回的文件对象地址存放在交换区描述符的swap_file字段。检查
swap_info中其他的活动交换区,以确认该交换区还未被激活。具体就是,检查交换区描述符的swap_file->f_mapping字段中存放的address_space对象地址。如果交换区已被激活,则返回错误码。如果
specialfile参数标识一个块设备文件,则执行下列子步骤:- 调用
bd_claim()把交换子系统设置成块设备的占有者。如果块设备已有一个占有者,则返回错误码。 - 把
block_device描述符地址存入交换区描述符的bdev字段。 - 把设备的当前块大小存放在交换区描述符的
old_block_size字段,然后把设备的块大小设成4096字节(即页的大小)。
- 调用
如果
specialfile参数标识一个普通文件,则执行下列子步骤:检查文件索引节点
i_flags字段中的S_SWAPFILE字段。如果该标志置位,说明文件已被用作交换区,返回错误码。把该文件所在块设备的描述符地址存入交换区描述符的
bdev字段。
读入存放在交换区页槽
0中的swap_header描述符。为达到这个目的,它调用read_cache_page(),并传入参数:由swap_file->f_mapping指向的address_space对象、页索引0、文件readpage方法的地址(存放在swap_file->f_mapping->a_ops->readpage)指向文件对象swap_file的指针。然后等待直到页被读入内存。检查交换区中第一页的最后
10个字符中的魔术字符串是否等于“SWAPSPACE2”。如果不是,就返回一个错误码。根据存放在
swap_header联合体的info.last_page字段中的交换区的大小,初始化交换区描述符的lowest_bit和highest_bit字段。调用
vmalloc()来创建与新交换区相关的计数器数组,并把它的地址存放在交换描述符的swap_map字段中。还要根据swap_header联合体的info.bad_pages字段中存放的有缺陷的页槽链表把这个数组的对应元素初始化成0或SWAP_MAP_BAD。通过访问第一个页槽中的
info.last_page和info.nr_badpages字段计算可用页槽的个数,并把它存入交换区描述符的pages字段。而且把交换区中的总页数赋给max字段。为新交换区建立子区链表
extent_list(如果交换区建立在磁盘分区上,则只有一个子区),并相应地设定交换区描述符的nr_extents和curr_swap_extent字段。把交换区描述符的
flags字段设为SWP_ACTIVE。更新
nr_good_pages、nr_swap_pages和total_swap_pages三个全局变量。把新交换区描述符插入
swap_list变量所指向的链表中。返回
0(成功)。
sys_swapoff()服务例程
sys_swapoff()服务例程使specialfile参数所指定的交换区无效。sys_swapoff()比sys_swapon()复杂得多,也更加耗时,因为使之无效的这个分区现在可能仍然还包含几个进程的页。因此,强制该函数扫描交换区并把所有现有的页都换入。
由于每个换入操作都需要一个新的页框,因此如果现在没有空闲页框,这个操作就可能失败。在这种情况下,该函数就返回一个错误码。所有这些操作都是通过执行以下主要步骤实现的:
(1). 验证当前进程是否具有CAP_SYS_ADMIN权能。
(2). 拷贝内核空间中specialfile所指向的字符串。
(3). 调用filp_open(),打开specialfile参数确定的文件。与往常一样,该函数返回文件对象的地址。
(4). 扫描交换区描述符链表swap_list,比较由filp_open()返回的文件对象地址与活动交换区描述符的swap_file字段中的地址,如果不一致,说明传给函数的是一个无效参数,则返回一个错误码。
(5). 调用cap_vm_enough_memory(),检查是否有足够的空闲页框把交换区上存放的所有页换入。如果不够,交换区就不能禁用,然后释放文件对象,返回错误码。这只是个粗略的检查,但可使内核免于许多无用的磁盘操作。当执行这项检查时,cap_vm_enough_memory()要考虑由slab高速缓存分配且SLAB_RECLAIM_ACCOUNT标志置位的页框,这样的页(被认为是可回收的这些页)的数量存放在slab_reclaim pages变量中。
(6). 从swap_list链表中删除该交换区描述符。
(7). 从nr_swap_pages和total_swap_pages的值中减去存放在交换区描述符的pages字段中的值。
(8). 把交换区描述符flags字段中的SWP_WRITEOK标志清0。这可禁止PFRA向交换区换出更多的页。
(9). 调用try_to_unuse()函数强制把这个交换区中剩余的所有页都移到RAM中,并相应地修改使用这些页的进程的页表。当执行该函数时,当前进程(即运行swapoff的进程)的PF_SWAPOFF标志置位。该标志置位只有一个结果:如页框严重不足,select_bad_process()函数就会被强制选择并删除该进程。
(10). 一直等到交换区所在的块设备驱动器被卸载。这样在交换区被禁用之前,try_to_unuse()发出的读请求会被驱动器处理。
(11). 如果在分配所有请求的页框时try_to_unuse()函数失败,那么就不能禁用这个交换区。因此,sys_swapoff()执行下列子步骤:
a. 把这个交换区描述符重新插入swap_list链表,并把它的flags字段置为SWP_WRITEOK。
b. 把交换区描述符中pages字段的值加到nr_swap_pages和total_swap_pages变量以恢复其原值。
c. 调用filp_close()关闭在第3步中打开的文件,并返回错误码。
(12). 否则,所有已用的页槽都已经被成功传送到RAM中。因此,执行下列子步骤
a. 释放存有swap_map数组和子区描述符的内存区域。
b. 如果交换区存放在磁盘分区,则把块大小恢复到原值,该原值存放在交换区描述符的old_block_size字段。而且,调用bd_release()函数,使交换子系统不再占有该块设备。
c. 如果交换区存放在普通文件中,则把文件索引节点的S_SWAPFILE标志清0。
d. 调用filp_close()两次,第一次针对swap_file文件对象,第二次针对第3步中filp_open()返回的对象。
e. 返回0(成功)。
try_to_unuse()函数
try_to_unuse()函数使用一个索引参数,该参数标识待清空的交换区。该函数换入页并更新已换出页的进程的所有页表。因此,该函数从init_mm内存描述符(用作标记)开始,访问所有内核线程和进程的地址空间。这是一个相当耗时的函数,通常以开中断运行。因此,与其他进程的同步也是关键的。
try_to_unuse()函数扫描交换区的swap_map数组。当它找到一个“在用”页槽时,首先换入其中的页,然后开始查找引用该页的进程。这两个操作的顺序对避免竞争条件是至关重要的。当I/O数据传送正在进行时,页被加锁,因此没有进程可以访问它。一旦I/O数据传送完成,页又被try_to_unuse()加锁,以使它不会被另一个内核控制路径再次换出。
因为每个进程在开始进行换入或换出操作之前查找页高速缓存,所以这也可以避免竞争条件。最后,由try_to_unuse()所考虑的交换区被标记为不可写(SWP_WRITEOK标志被清0),因此,没有进程可以对这个交换区的页槽执行换出。但是,可能强迫try_to_unuse()对交换区引用计数器的swap_map数组扫描几次。这是因为对换出页引用的线性区可能在一次扫描中消失,而在随后又出现在进程链表中。
例如,回想do_munmap()函数的描述;只要进程释放一个线性地址区间,do_munmap()就从进程链表中删除所有受影响线性地址所在的线性区;随后,该函数把只是部分解除映射的那部分线性区重新插入进程链表中。
do_munmap()还要负责释放属于已释放线性地址区间的换出页;但是,如果换出的页属于重新插入进程链表的线性区,则最好不要释放它们。 因此,try_to_unuse()对引用给定页槽的进程进行查找时可能失败,因为相应的线性区暂时没有包含在进程的线性区链表中。为了处理这种情况,try_to_unuse()一直对swap_map 数组进行扫描,直到所有的引用计数器都变为空。引用了换出页的“神出鬼没”的线性区最终会重新出现在进程链表中,因此,try_to_unuse()终将会成功释放所有页槽。
让我们现在来描述try_to_unuse()所执行的主要操作。传递给它的参数为交换区swap_map数组的引用计数器,该函数在这个引用计数器上执行连续循环。如果当前进程接收到一个信号,则循环会中断,函数返回错误码。对于数组中的每个引用计数器,try_to_unuse()执行下列步骤:
- 如果计数器等于
0(没有页存放在这里)或者等于SWAP_MAP_BAD,则对下一个页槽继续处理。- 否则,调用
read_swap_cache_async()函数换入该页。这包括分配一个新页框(如果必要),用存放在页槽中的数据填充新页框并把这个页存放在交换高速缓存。- 等待,直到用磁盘中的数据适当地更新了这个新页,然后锁住它。
- 当正在执行前一步时,进程有可能被挂起。因此,还要检查这个页槽的引用计数器是否变为空,如果是,说明这个交换页可能被另一个内核控制路径释放,然后继续处理下一个页槽。
- 对于以
init_mm为头部的双向链表中的每个内存描述符,调用unuse_process()。这个耗时的函数扫描拥有内存描述符的进程的所有页表项,并用这个新页框的物理地址替换页表中每个出现的换出页标识符。为了反映这种移动,还要把swap_map数组中的页槽计数器减1(除非计数器等于SWAP_MAP_MAX),并增加这个页框的引用计数器。- 调用
shmem_unuse()检查换出的页是否用于IPC共享内存资源,并适当地处理那种情况。- 检查页的引用计数器。如果它的值等于
SWAP_MAP_MAX,则页槽是“永久的”。为了释放它,则把引用计数器强制置为1。- 交换高速缓存可能也拥有该页(它对引用计数器的值起作用)。如果页属于交换高速缓存,就调用
swap_writepage()函数把页的内容刷新到磁盘(如果页为脏),调用delete_from_swap_cache()从交换高速缓存删去页,并把页的引用计数减1。- 设置页描述符的
PG_dirty标志,并打开页框的锁,递减它的引用计数器(取消第5步的增量)。- 检查当前进程的
need_resched字段;如果它被设置,则调用schedule()放弃CPU。禁用交换区是一件冗长的工作,内核必须保证系统中的其他进程仍然继续执行。只要这个进程再次被调度程序选中,try_to_unuse()函数就从这一步继续执行。- 继续到下一个页槽,从第
1步开始。
try_to_unuse()继续执行,直到swap_map数组中的每个引用计数器都为空。回想一下,即使这个函数已经开始检查下一个页槽,但是前一个页槽的的引用计数器有可能仍然为正。事实上,一个“神出鬼没”的进程可能还在引用这个页,典型的原因是某些线性区已经被临时从第5步所扫描的进程链表中删除。try_to_unuse()最终会捕获到每个引用。但是,在此期间,页不再位于交换高速缓存,它的锁被打开,并且页的一个拷贝仍然包含在要禁用的交换区的页槽中。
一般会认为这种情形可能导致数据丢失。例如,假定某个“神出鬼没”的进程访问页槽,并开始换入其中的页。因为页不再位于交换高速缓存,因此,进程用从磁盘读取的数据填充一个新的页框。但是,这个页框可能不同于与“神出鬼没”进程共享页的那些进程曾经拥有的页框。当禁用交换区时这个问题不会发生,因为只有在换出的页属于私有匿名内存映射时,对“神出鬼没“进程的干涉才会发生。把不同的页框分配给引用了同一页的进程是完全合法的。但是,try_to_unuse()函数将页标记为“脏”。否则,shrink_list()函数可能随后从某个进程的页表中删除这一页,而并不把它保存在另一个交换区中。
分配和释放页槽
搜索空闲页槽的第一种方法可以选择下列两种既简单而又有些极端的策略之一:
- 总是从交换区的开头开始。这种方法在换出操作过程中可能会增加平均寻道时间,因为空闲页槽可能已经被弄得凌乱不堪。
- (2). 总是从最后一个已分配的页槽开始。如果交换区的大部分空间都是空闲的(这是最通常的情况),
Linux采用了一种混合的方法。除非发生以下这些条件之一,否则Linux总是从最后一个已分配的页槽开始查找。已经到达交换区的末尾。
(1). 上次从交换区的开头重新分配之后,已经分配了SWAPFILE_CLUSTER(通常是256)个空闲页槽。
(2). swap_info_struct描述符的cluster_nr字段存放已分配的空闲页槽数。当函数从交换区的开头重新分配时该字段被重置为0。
cluster_next字段存放在下一次分配时要检查的第一个页槽的索引。为了加速对空闲页槽的搜索,内核要保证每个交换区描述符的lowest_bit和highest_bit字段是最新的。这两个字段定义了第一个和最后一个可能为空的页槽,换言之,所有低于lowest_bit和高于highest_bit的页槽都被认为已经分配过。
scan_swap_map()函数
scan_swap_map()函数用来在给定的交换区中查找一个空闲页槽。该函数只作用于一个参数,该参数指向交换区描述符返回一个空闲页槽的索引。如果交换区不含有任何空闲页槽,就返回0。该函数执行以下步骤:
- 首先试图使用当前的簇。如果交换区描述符的
cluster_nr字段是正数,就从cluster_next索引处的元素开始对计数器的swap_map数组进行扫描,查找一个空项。如果找到一个空项,就减少cluster_nr字段的值并转到第4步。 - 如果执行到这儿,那么,或者
cluster_nr字段为空,或者从cluster_next开始搜索后没有在swap_map数组中找到空项。现在就应该开始第二阶段的混合查找。把cluster_nr重新初始化成SWAPFILE_CLUSTER,并从lowest_bit索引处开始重新扫描这个数组,以便试图找到有SWAPFILE_CLUSTER个空闲页槽的一个组。如果找到这样的一个组,就转到第4步。 - 不存在
SWAPFILE_CLUSTER个空闲页槽的组。从lowest_bit索引处开始重新开始扫描这个数组,以便试图找到一个单独的空闲页槽。如果没有找到空项,就把lowest_bit字段置为数组的最大索引,highest_bit字段置为0,并返回0(交换区已满)。 - 已经找到空项。把
1放在空项中,减少nr_swap_pages的值,如果需要就修改lowest_bit和highest_bit字段,把inuse_page字段的值加1,并把cluster_next字段设置成刚才分配的页槽的索引加1。 - 返回刚才分配的页槽的索引。
get_swap_page()函数
get_swap_page()函数通过搜索所有活动的交换区来查找一个空闲页槽。它返回一个新近分配页槽的换出页标识符,如果所有的交换区都填满,就返回0,该函数要考虑活动交换区的不同优先级。该函数需要经过两遍扫描,以便在容易发现页槽时节约运行时间。第一遍是部分的,只适用于只有相同优先级的交换区。该函数以轮询的方式在这种交换区中查找一个空闲页槽。如果没有找到空闲页槽,就从交换区链表的起始位置开始进行第二遍扫描。在第二遍扫描中,要对所有的交换区都进行检查。
swap_free()函数
当换入页时,调用swap_free()函数以对相应的swap_map计数器进行减1操作。当相应的计数器达到0时,由于页槽的标识符不再包含在任何页表项中,因此页槽就变成空闲。但是,我们将在后面“交换高速缓存”一节看到,交换高速缓存也记入页槽拥有者的个数。该函数只作用于一个参数entry,entry表示换出页标识符。
函数执行以下步骤:
- 从
entry参数导出交换区索引和页槽索引offset,并获得交换区描述符的地址。 - 检查交换区是否是活动的。如果不是,就立即返回。
- 如果正在释放的页槽对应的
swap_map计数器小于SWAP_MAP_MAX,就减少这个计数器的值。回想一下,值为SWAP_MAP_MAX的项都被认为是永久的(不可删除的)。 - 如果
swap_map计数器变成0,就增加nr_swap_pages的值,减少inuse_pages字段的值,如果需要就修改这个交换区描述符的lowest_bit和highest_bit字段。
交换高速缓存
向交换区来回传送页会引发很多竟争条件,具体地说,交换子系统必须仔细处理下面的情形:
- 多重换入,两个进程可能同时要换入同一个共享匿名页。
- 同时换入换出,一个进程可能换入正由
PFRA换出的页。
交换高速缓存(swap cache)的引入就是为了解决这类同步问题。
关键的原则是,没有检查交换高速缓存是否已包括了所涉及的页,就不能进行换入或换出操作。有了交换高速缓存,涉及同一页的并发交换操作总是作用于同一个页框的。因此,内核可以安全地依赖页描述符的PG_locked标志,以避免任何竞争条件。考虑一下共享同一换出页的两个进程这种情形。当第一个进程试图访问页时,内核开始换入页操作,第一步就是检查页框是否在交换高速缓存中,我们假定页框不在交换高速缓存中,那么内核就分配一个新页框并把它插入交换高速缓存,然后开始I/O操作,从交换区读入页的数据;同时,第二个进程访问该共享匿名页,与上面相同,内核开始换入操作,检查涉及的页框是否在交换高速缓存中。现在页框是在交换高速缓存,因此内核只是访问页框描述符,在PG_locked标志清0之前(即I/O数据传输完毕之前),让当前进程睡眠。
当换入换出操作同时出现时,交换高速缓存起着至关重要的作用。shrink_list()函数要开始换出一个匿名页,就必须当try_to_unmap()从进程(所有拥有该页的进程)的用户态页表中成功删除了该页后才可以。但是当换出的写操作还在执行的时候,这些进程中可能有某个进程要访问该页,而产生换入操作。在写入磁盘前,待换出页由shrink_list()存放在交换高速缓存。
考虑页P由两个进程(A和B)共享。最初,两个进程的页表项都引用该页框,该页有两个拥有者,如图17-8(a)所示。当PFRA选择回收页时,shrink_list()把页框插入交换高速缓存。如图17-8(b)所示,现在页框有三个拥有者,而交换区中的页槽只被交换高速缓存引用。然后PFRA调用try_to_unmap()从这两个进程的页表项中删除对该页框的引用。一旦这个函数结束,该页框就只有交换高速缓存引用它,而引用页槽的有这两个进程和交换高速缓存,如图17-8(c)所示。假定:当页中的数据写入磁盘时,进程B访问该页,即它要用该页内部的线性地址访问内存单元。那么,缺页异常处理程序发现页框在交换高速缓存,并把物理地址放回进程B的页表项,如图17-8(d)所示。
相反地,如果换出操作结束,而没有并发换入操作,shrink_list()函数则从交换高速缓存删除该页框并把它释放到伙伴系统,如图17-8(e)所示。你可以认为交换高速缓存是一个临时区域,该区域存有正在被换入或换出的匿名页描述符。当换入或换出结束时(对于共享匿名页,换入换出操作必须对共享该页的所有进程进行),匿名页描述符就可以从交换高速缓存删除。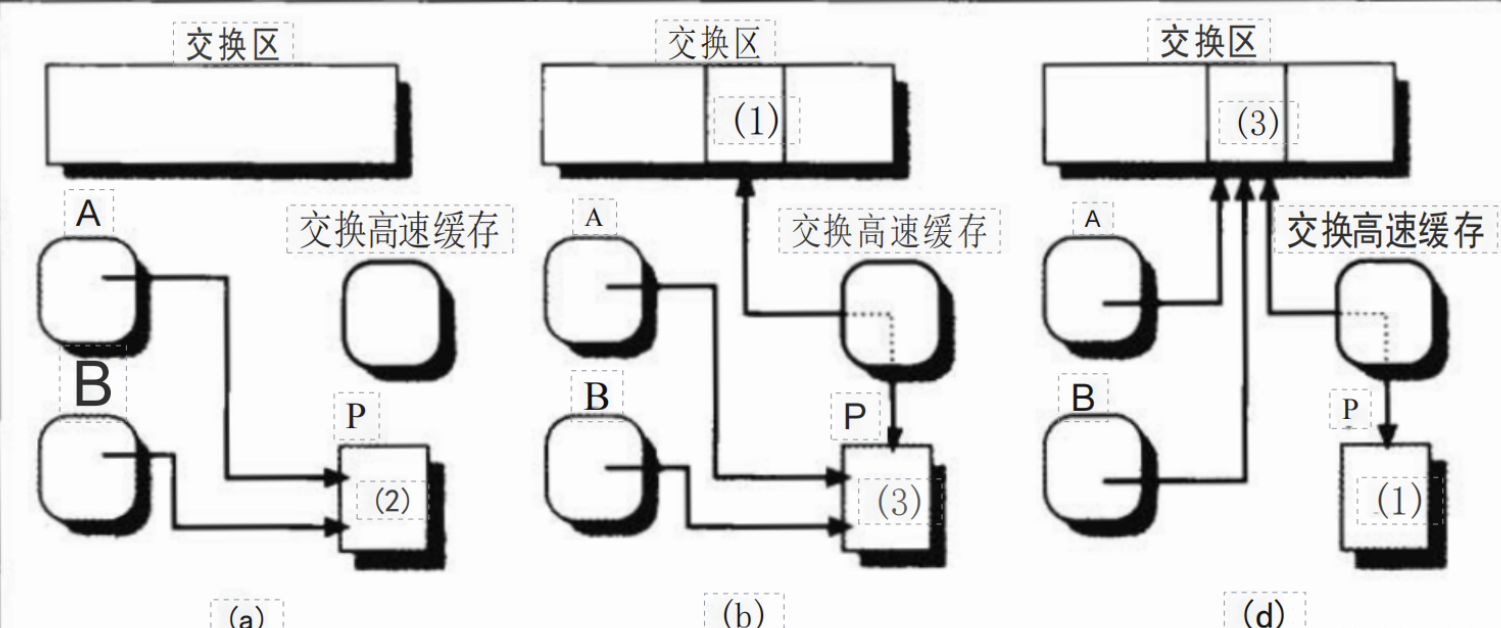
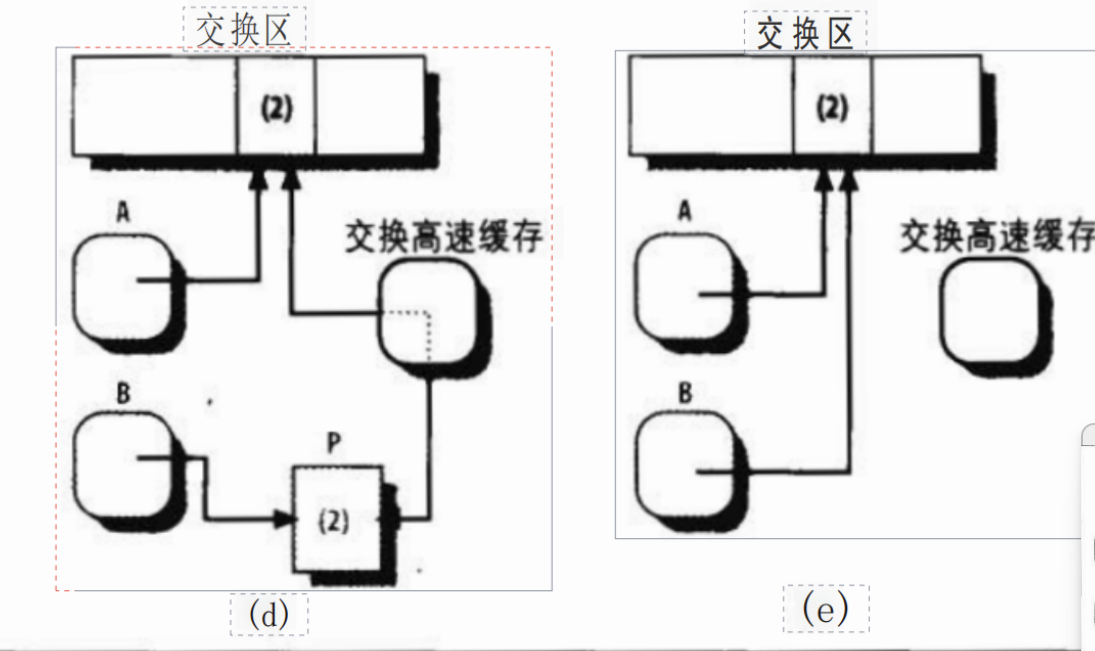
交换高速缓存的实现
交换高速缓存由页高速缓存数据结构和过程实现。回想一下,页高速缓存的核心就是一组基树,借助基树,算法就可以从address_space对象地址(即该页的拥有者)和偏移量值推算出页描述符的地址。在交换高速缓存中页的存放方式是隔页存放,并有下列特征:页描述符的mapping字段为NULL。页描述符的PG_swapcache标志置位。private字段存放与该页有关的换出页标识符。此外,当页被放入交换高速缓存时,则页描述符的count字段和页槽引用计数器的值都增加,因为交换高速缓存既要使用页框,也要使用页槽。最后,交换高速缓存中的所有页只使用一个swapper_space地址空间,因此只有一个基树(由swapper_space.page_tree指向)对交换高速缓存中的页进行寻址。swapper_space地址空间的nrpages字段存放交换高速缓存中的页数。
交换高速缓存的辅助函数
内核使用几个函数来处理交换高速缓存,稍后我们将说明这些相对低层的函数是如何被高层函数调用来按需换入和换出页的。处理交换高速缓存的函数主要有:
lookup_swap_cache(),通过传递来的参数(换出页标识符)在交换高速缓存中查找页并返回页描述符的地址。如果该页不在交换高速缓存中,就返回0。该函数调用radix_tree_lookup()函数,把指向swapper_space.page_tree的指针(用于交换高速缓存中页的基树)和换出页标识符作为参数传递,以查找所需要的页。add_to_swap_cache(),把页插入交换高速缓存中。它本质上调用swap_duplicate()检查作为参数传递来的页槽是否有效,并增加页槽引用计数器;然后调用radix_tree_insert()把页插入高速缓存;最后递增页引用计数器并将PG_swapcache和PG_locked标志置位。__add_to_swap_cache(),与add_to_swap_cache()类似,但是,在把页框插入交换高速缓存前,这个函数不调用swap_duplicate()。delete_from_swap_cache(),调用radix_tree_delete()从交换高速缓存中删除页,递减swap_map中相应的使用计数器,递减页引用计数器。free_page_and_swap_cache(),如果除了当前进程外,没有其它用户态进程正在引用相应的页槽,则从交换高速缓存中删除该页,并递减页使用计数器。free_pages_and_swap_cache(),与free_page_and_swap_cache()相似,但它是对一组页操作。free_swap_and_cache(),释放一个交换表项,并检查该表项引用的页是否在交换高速缓存。如果没有用户态进程(除了当前进程之外)引用该页,或者超过50%的交换表项在用,则从交换高速缓存中释放该页。
换出页
我们从本章前面“内存紧缺回收”一节可看到,PFRA是如何确定一个给定的匿名页是否该被换出。在这一节,我们描述内核如何执行换出操作。
向交换高速缓存插入页框
换出操作的第一步就是准备交换高速缓存。如果shrink_list()函数确认某页为匿名页(PageAnon()函数返回1)而且交换高速缓存中没有相应的页框(页描述符的PG_swapcache 标志清0),内核就调用add_to_swap()函数。add_to_swap()函数在交换区中分配一个新页槽,并把一个页框(其页描述符地址作为参数传递)插入交换高速缓存。
函数执行如下主要步骤:
- 调用
get_swap_page()函数分配一个新页槽。如果失败(例如没有发现空闲页槽),则返回0。 - 调用
__add_to_page_cache(),传给它页槽索引、页描述符地址和一些分配标志。 - 将页描述符中的
PG_uptodate和PG_dirty标志置位,从而强制shrink_list()函数把页写入磁盘。 - 返回
1(成功)。
更新页表项
一旦add_to_swap()结束,shrink_list()就调用try_to_unmap(),它确定引用匿名页的每个用户态页表项地址,然后将换出页标识符写入其中。
将页写入交换区
为完成换出操作需执行的下一个步骤是将页的数据写入交换区。这一I/O传输是由shrink_list()函数激活的,它检查页框的PG_dirty标志是否置位,然后执行pageout()函数。pageout()函数建立一个writeback_control描述符,且调用页address_space对象的writepage方法。而swapper_state 对象的writepage方法是由swap_writepage()函数实现的。
swap_writepage()函数所执行的主要步骤如下:
(1). 检查是否至少有一个用户态进程引用该页。如果没有,则从交换高速缓存删除该页,并返回0。这一检查之所以必须做,是因为一个进程可能会与PFRA发生竞争并在shrink_list()检查完后释放一页。
(2). 调用get_swap_bio()分配并初始化一个bio描述符。函数从换出页标识符算出交换区描述符地址。然后它搜索交换子区链表,以找到页槽的初始磁盘扇区。bio描述符将包含一个单页数据请求(页槽),其完成方法设为end_swap_bio_write()函数。
(3). 置位页描述符的PG_writeback标志和交换高速缓存基树的writeback标记。此外函数还清零PG_locked标志。
(4). 调用submit_bio(),传给它WRITE命令和bio描述符地址。
(5). 返回0。
一旦I/O数据传输结束,就执行end_swap_bio_write()函数。实际上,这个函数唤醒正等待页PG_writeback标志清零的所有进程,清除PG_writeback标志和基树中的相关标记,并释放用于I/O传输的bio描述符。
从交换高速缓存中删除页框
换出操作的最后一步还是由shrink_list()执行。如果它验证在I/O数据传输时没有进程试图访问该页框,它实际就调用delete_from_swap_cache()从交换高速缓存中删除该页框。因为交换高速缓存是该页的唯一拥有者,该页框被释放到伙伴系统。
换入页
当进程试图对一个已被换出到磁盘的页进行寻址时,必然会发生页的换入。
在以下条件发生时,缺页异常处理程序就会触发一个换入操作:
(1). 引起异常的地址所在的页是一个有效的页,也就是说,它属于当前进程的一个线性区。
(2). 页不在内存中,也就是说,页表项中的Present标志被清除。
(3). 与页有关的页表项不为空,但是Dirty位清0,这意味着页表项包含一个换出页标识符。如果上面的所有条件满足,则handle_pte_fault()调用相对简易的do_swap_page()函数换入所需页。
do_swap_page()函数
do_swap_page()函数作用于如下参数:
mm,引起缺页异常的进程的内存描述符地址vma,address所在的线性区描述符地址address,引起异常的线性地址page_table,映射address的页表项的地址Pmd,映射address的页中间目录的地址orig_pte,映射address的页表项的内容write_access,一个标志,表示试图执行的访问是读操作还是写操作
与其他函数相反,do_swap_page()从不返回0。如果页已经在交换高速缓存中就返回1 (次错误),如果页已经从交换区读入就返回2(主错误),如果在进行换入时发生错误就返回-1。
该函数本质上执行下列步骤:
- 从
orig_pte获得换出页标识符。- 调用
pte_unmap()释放任何页表的临时内核映射,该页表由handle_mm_fault()函数建立。访问高端内存页表需要进行内核映射。- 释放内存描述符的
page_table_lock自旋锁(它是由调用者函数handle_pte_fault()获取的)。- 调用
lookup_swap_cache()检查交换高速缓存是否已经含有换出页标识符对应的页;如果页已经在交换高速缓存中,就跳到第6步。- 调用
swapin_readahead()函数从交换区读取至多有2n个页的一组页,其中包括所请求的页。值n存放在page_cluster变量中,通常等于3。其中的每个页是通过调用read_swap_cache_async()函数读入的。- 再一次调用
read_swap_cache_async()换入由引起缺页异常的进程所访问的那一页。这一步可能看起来有点多余,但其实不然。swapin_readahead()函数可能在读取请求的页时失败——例如,因为page_cluster被置为0,或者该函数试图读取一组含有空闲或有缺陷页槽(SWAP_MAP_BAD)的页。另一方面,如果swapin_readahead()成功,这次对read_swap_cache_async()的调用就很快结束,因为它在交换高速缓存找到了页。- 尽管如此,如果请求的页还是没有被加到交换高速缓存,那么,另一个内核控制路径可能已经代表这个进程的一个子进程换入了所请求的页。这种情况的检查可以通过临时获取
page_table_lock自旋锁,并把page_table所指向的表项与orig_pte进行比较来实现。如果二者有差异,则说明这一页已经被某个其他的内核控制路径换入,因此,函数返回1(次错误);否则,返回-1(失败)。- 函数执行到此,我们知道页已经在高速缓存中。如果页已被换入(主错误),函数就调用
grab_swap_token()试图获得一个交换标记。- 调用
mark_page_accessed()并对页加锁。- 获取
page_table_lock自旋锁。- 检查另一个内核控制路径是否代表这个进程的一个子进程换入了所请求的页。如果是,就释放
page_table_lock自旋锁,打开页上的锁,并返回1(次错误)。- 调用
swap_free()减少entry对应的页槽的引用计数器。- 检查交换高速缓存是否至少占满
50%(nr_swap_pages小于total_swap_pages的一半)。如果是,则检查页是否仅被引起异常的进程(或其一个子进程)拥有;如果是这样,则从交换高速缓存中删去这一页。- 增加进程的内存描述符的
rss字段。- 更新页表项以便进程能找到这一页。这一操作的实现是通过把所请求页的物理地址和在线性区的
vm_page_prot字段所找到的保护位写入page_table所指向的页表项中来达到的。此外,如果引起缺页的访问是一个写访问,且造成缺页的进程是页的唯一拥有者,那么,函数还要设置Dirty和Read/Write标志以防止无用的写时复制错误。- 打开页上的锁。
- 调用
page_add_anon_rmap()把匿名页插入面向对象的反向映射数据结构。- 如果
write_access参数等于1,则函数调用do_wp_page()复制一份页框。- 释放
mm->page_table_lock自旋锁,并返回1(次错误)或2(主错误)。
read_swap_cache_async()函数
只要内核必须换入一个页,就调用read_swap_cache_async()函数,它接收的参数为:
entry,换出页标识符vma,指向该页所在线性区的指针addr,页的线性地址
我们知道,在访问交换分区之前,该函数必须检查交换高速缓存是否已经包含了所要的页框。因此,该函数本质上执行下列操作:
- 调用
radix_tree_lookup(),搜索swapper_space对象的基树,寻找由换出页标识符entry给出位置的页框。如果找到该页,递增它的引用计数器,返回它的描述符地址。 - 页不在交换高速缓存。调用
alloc_page()分配一个新的页框。如果没有空闲的页框可用,则返回0(表示系统没有足够的内存)。 - 调用
add_to_swap_cache()把新页框的页描述符插入交换高速缓存。这个函数也对页加锁。 - 如果
add_to_swap_cache()在交换高速缓存找到页的一个副本,则前一步可能失败。例如,进程可能在第2步阻塞,因此允许另一个进程在同一个页槽上开始换入操作。在这种情况下,该函数释放在第2步分配的页框,并从第1步重新开始。 - 调用
lru_cache_add_active()把页插入LRU的活动链表。 - 新页框的页描述符现已在交换高速缓存。调用
swap_readpage()从交换区读入该页数据。这个函数与前面“换出页”一节所描述的swap_writepage()函数很相似,它将页描述符的PG_uptodate标志清0,调用get_swap_bio()为I/O传输分配与初始化一个bio描述符,再调用’submit_bio()向块设备子系统层发出I/O请求。 - 返回页描述符的地址。
IPC
管道
管道(pipe)是所有Unix都愿意提供的一种进程间通信机制。管道是进程之间的一个单向数据流:一个进程写入管道的所有数据都由内核定向到另一个进程,另一个进程由此就可以从管道中读取数据。在Unix的命令shell中,可以使用“1”操作符来创建管道。例如,下面的语句通知shell 创建两个进程,并使用一个管道把这两个进程连接在一起:$ ls | more
第一个进程(执行ls程序)的标准输出被重定向到管道中;第二个进程(执行more程序)从这个管道中读取输入。注意,执行下面这两条命令也可以得到相同的结果:
$ ls > temp
$ more < temp第一个命令把ls的输出重定向到一个普通文件中;接下来,第二个命令强制more从这个普通文件中读取输入。
当然,通常使用管道比使用临时文件更方便,这是因为:
shell语句比较短,也比较简单。- 没有必要创建将来还必须删除的临时普通文件。
使用管道
管道被看作是打开的文件,但在已安装的文件系统中没有相应的映像。可以使用pipe()系统调用来创建一个新管道,这个系统调用返回一对文件描述符;然后进程通过fork()把这两个描述符传递给它的子进程,由此与子进程共享管道。进程可以在read()系统调用中使用第一个文件描述符从管道中读取数据,同样也可以在write()系统调用中使用第二个文件描述符向管道中写入数据。
POSIX只定义了半双工的管道,因此即使pipe()系统调用返回了两个描述符,每个进程在使用一个文件描述符之前仍得把另外一个文件描述符关闭。
如果所需要的是双向数据流,那么进程必须通过两次调用pipe()来使用两个不同的管道。有些Unix系统,例如System VReleas 4,实现了全双工的管道。在全双工管道中,允许两个文件描述符既可以被写入也可以被读取,这就有两个双向信息通道。
Linux采用了另外一种解决方法;每个管道的文件描述符仍然都是单向的,但是在使用一个描述符之前不必把另外一个描述符关闭。让我们回顾一下前面的那个例子。当shell命令对ls I more语句进行解释时,实际上要执行以下操作:
shell进程:
- 调用
pipe()系统调用;让我们假设pipe()返回文件描述符3(管道的读通道)和4(管道的写通道)。 - 两次调用
fork()系统调用。 - 两次调用
close()系统调用来释放文件描述符3和4。
第一个子进程必须执行ls程序,它执行以下操作:
- 调用
dup2(4,1)把文件描述符4拷贝到文件描述符1。从现在开始,文件描述符1就代表该管道的写通道。 - 两次调用
close()系统调用来释放文件描述符3和4。 - 调用
execve()系统调用来执行ls程序。缺省情况下,这个程序要把自己的输出写到文件描述符为1的那个文件(标准输出)中,也就是说,写入管道中。
第二个子进程必须执行more程序;因此,该进程执行以下操作:
- 调用
dup2(3,0)把文件描述符3拷贝到文件描述符0。从现在开始,文件描述符0就代表管道的读通道。 - 两次调用
close()系统调用来释放文件描述符3和4。 - 调用
execve()系统调用来执行more程序。缺省情况下,这个程序要从文件描述符为0的那个文件(标准输入)中读取输入,也就是说,从管道中读取输入。
在这个简单的例子中,管道完全被两个进程使用。但是,由于管道的这种实现方式,二个管道可以供任意个进程使用。显然,如果两个或者更多个进程对同一个管道进行读写,
那么这些进程必须使用文件加锁机制或者IPC信号量机制,对自己的访问进行显式的同步。除了pipe()系统调用之外,很多Unix系统都提供了两个名为popen()和pclose()的封装函数来处理在使用管道的过程中产生的所有脏工作。只要使用popen()函数创建二个管道,就可以使用包含在C函数座中的高级IO函数(fprintf(),fscanf()等等)对这个管道进行操作。在Linux中,popen()和pclose()都包含在C函数库中。popen()函数接收两个参数:可执行文件的路径名filename和定义数据传输方向的字符串type。该函数返回一个指向FILE数据结构的指针。
popen()函数实际上执行以下操作:
使用
pipe()系统调用创建一个新管道。创建一个新进程,该进程又执行以下操作:
- 如果
type是r,就把与管道的写通道相关的文件描述符拷贝到文件描述符1(标准输出);如果type是w,就把与管道的读通道相关的文件描述符拷贝到文件描述符0(标准输入)。 - 关闭
pipe()返回的文件描述符。 - 调用
execve()系统调用执行filename所指定的程序。
- 如果
如果
type是r,就关闭与管道的写通道相关的文件描述符;如果type是w,就关闭与管道的读通道相关的文件描述符。返回
FILE文件指针所指向的地址,这个指针指向仍然打开的管道所涉及的任一文件描述符。在popen()函数被调用之后,父进程和子进程就可以通过管道交换信息:
1,2,3,4说的是父进程。1, 2, 3说的是子进程。
父进程可以使用该函数所返回的FILE指针来读(如果type是r)写(如果type是w)数据。子进程所执行的程序分别把数据写入标准输出或从标准输入中读取数据。pclose()函数接收popen()所返回的文件指针作为参数,它会简单地调用wait4()系统调用并等待popen()所创建的进程结束。
管道数据结构
我们现在又一次在系统调用的层次考虑问题。只要管道一被创建,进程就可以使用read()和write()这两个VFS系统调用来访问管道。因此,对于每个管道来说,内核都要创建一个索引节点对象和两个文件对象,一个文件对象用于读,另外一个对象用于写。
当进程希望从管道中读取数据或向管道中写入数据时,必须使用适当的文件描述符。当索引节点指的是管道时,其i_pipe字段指向一个如表19-1所示的pipe_inode_info 结构。
除了一个索引节点对象和两个文件对象之外,每个管道都还有自己的管道缓冲区(pipe buffer)。实际上,它是一个单独的页,其中包含了已经写入管道等待读出的数据。
在Linux 2.6.10以前,每个管道一个管道缓冲区。而2.6.11内核中,管道(与FIFO)的数据缓冲区已有很大改变,每个管道可以使用16个管道缓冲区。这个改变大大增强了向管道写大量数据的用户态应用的性能。
pipe_inode_info数据结构的bufs字段存放一个具有16个pipe_buffer对象的数组,每个对象代表一个管道缓冲区。该对象的字段如表19-2所示。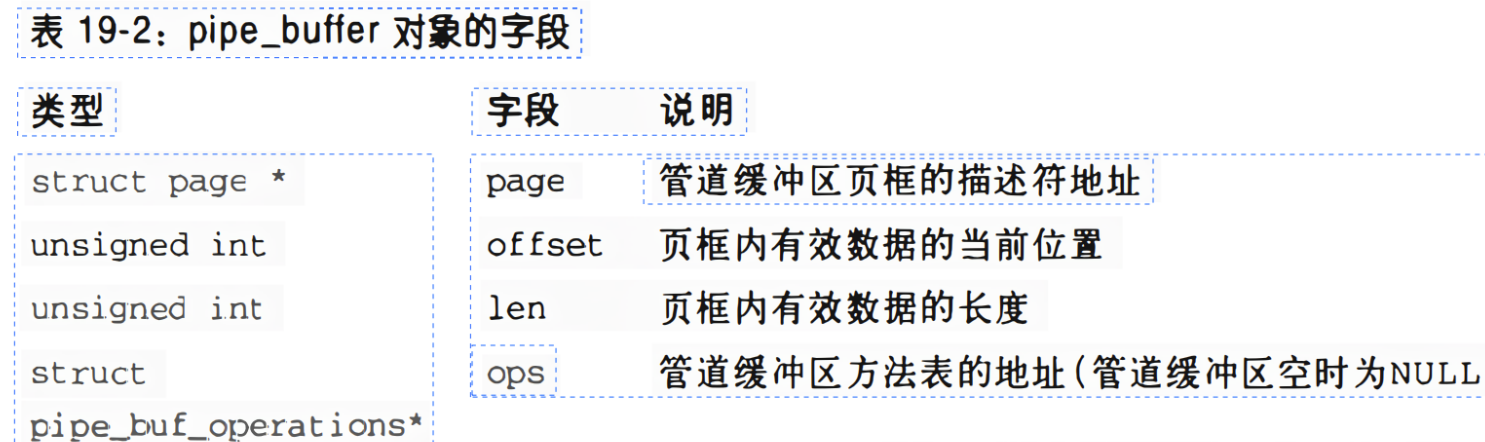
ops字段指向管道缓冲区方法表anon_pipe_buf_ops,它是一个类型为pipe_buf_operations 的数据结构。实际上,它有三个方法:
(1). map
在访问缓冲区数据之前调用。它只在管道缓冲区在高端内存时对管道缓冲区页框调用kmap()。
(2). unmap
不再访问缓冲区数据时调用。它对管道缓冲区页框调用kunmap()。
(3). release
当释放管道缓冲区时调用。
该方法实现了一个单页内存高速缓存:释放的不是存放缓冲区的那个页框,而是由pipe_inode_info数据结构(如果不是NULL)的tmp_page字段指向的高速缓存页框。
存放缓冲区的页框变成新的高速缓存页框。
16个缓冲区可以被看作一个整体环形缓冲区:写进程不断向这个大缓冲区追加数据,而读进程则不断移出数据。
所有管道缓冲区中当前写入而等待读出的字节数就是所谓的管道大小。为提高效率,仍然要读的数据可以分散在几个未填充满的管道缓冲区内:事实上,在上一个管道缓冲区没有足够空间存放新数据时,每个写操作都可能会把数据拷贝到一个新的空管道缓冲区。因此,内核必须记录:
(1). 下一个待读字节所在的管道缓冲区、页框中的对应偏移量。该管道缓冲区的索引存放在pipe_inode_info数据结构的curbuf字段,而偏移量在相应pipe_buffer对象的offset字段。
(2). 第一个空管道缓冲区。它可以通过增加当前管道缓冲区的索引得到(模为16),并存放在pipe_inode_info数据结构的curbuf字段,而存放有效数据的管道缓冲区号存放在nrbufs字段。为了避免对管道数据结构的竟争条件,内核使用包含在索引节点对象中的i_sem信号量。
pipefs特殊文件系统
管道是作为一组VFS对象来实现的,因此没有对应的磁盘映象。在Linux 2.6中,把这些VFS对象组织为pipefs特殊文件系统以加速它们的处理。因为这种文件系统在系统目录树中没有安装点,因此用户根本看不到它。
但是,有了pipefs,管道完全被整合到VFS层,内核就可以以命名管道或FIFO的方式处理它们,FIFO是以终端用户认可的文件而存在的。init_pipe_fs()函数(一般是在内核初始化期间执行)注册pipefs文件系统并安装它:
struct file_system_type pipe_fs_type;
pipe_fs_type.name ="pipefs";
pipe_fs_type.get_sb = pipefs_get_sb;
pipe_fs.kill_sb = kill_anon_super;
register_filesystem(&pipe_fs_type);
pipe_mnt = do_kern_mount("pipefs", 0, "pipefs", NULL);表示pipefs根目录的已安装文件系统对象存放在pipe_mnt变量中。
创建和撤消管道
pipe()系统调用由sys_pipe()函数处理,后者又会调用do_ pipe()函数。为了创建一个新的管道,do_ pipe()函数执行以下操作:
调用
get_pipe_inode()函数,该函数为pipefs文件系统中的管道分配一个索引节点对象并对其进行初始化。具体来说,该函数执行下列操作:- 在
pipefs文件系统中分配一个新的索引节点。 - 分配
pipe_inode_info数据结构,并把它的地址存放在索引节点的i_pipe字段。 - 设置
pipe_inode_info的curbuf和nrbufs字段为0,并将bufs数组中的管道缓冲区对象的所有字段都清0。 - 把
pipe_inode_info结构的r_counter和w_counter字段初始化为1。 - 把
pipe_inode_info结构的readers和writers字段初始化为1。
- 在
为管道的读通道分配一个文件对象和一个文件描述符,并把这个文件对象的f_flag字段设置成O_RDONLY,把f_op字段初始化成read pipe_fops表的地址。
为管道的写通道分配一个文件对象和一个文件描述符,并把这个文件对象的
flag字段设置成O_WRONLY,把f_op字段初始化成write_pipe_fops表的地址。分配一个目录项对象,并使用它把两个文件对象和索引节点对象连接在一起;然后,把新的索引节点插入
pipefs特殊文件系统中。把两个文件描述符返回给用户态进程。发出一个
pipe()系统调用的进程是最初唯一一个可以读写访问新管道的进程。为了表示该管道实际上既有一个读进程,又有一个写进程,就要把pipe_inode_info数据结构的readers和writers字段都初始化成1。通常,只要相应管道的文件对象仍然由某个进程打开,这两个字段中的每个字段就应该都被设置成1;如果相应的文件对象已经被释放,那么这个字段就被设置成0,因为不会再有任何进程访问这个管道。创建一个新进程并不增加readers和writers字段的值,因此这两个值从不超过1。但是,父进程仍然使用的所有文件对象的引用计数器的值都会增加。因此,即使父进程死亡时这个对象都不会被释放,管道仍会一直打开供子进程使用。只要进程对与管道相关的一个文件描述符调用close()系统调用,内核就对相应的文件对象执行fput()函数,这会减少它的引用计数器的值。如果这个计数器变成0,那么该函数就调用这个文件操作的release方法。
根据文件是与读通道还是与写通道关联,release方法或者由pipe_read_release()或者由pipe_write_release()函数来实现。这两个函数都调用pipe_release(),后者把pipe_inode_info结构的readers字段或writers字段设置成0。
pipe_release()还要检查readers和writers是否都等于0。如果是,就调用所有管道缓冲区的release 方法,向伙伴系统(buddy system)释放所有管道缓冲区页框;此外,函数还释放由tmp_page字段指向的高速缓存页框。否则,readers或者writers字段不为0,函数唤醒在管道的等待队列上睡眠的任一进程,以使它们可以识别管道状态的变化。
从管道中读取数据
希望从管道中读取数据的进程发出一个read()系统调用,为管道的读端指定一个文件描述符。内核最终调用与这个文件描述符相关的文件操作表中所找到的read方法。在管道的情况下,read 方法在read_pipe_fops表中的表项指向pipe_read()函数。pipe_read()相当复杂,因为POSIX标准定义了管道的读操作的一些要求。表19-3概述了所期望的read()系统调用的行为,该系统调用从一个管道大小(管道缓冲区中待读的字节数)为p的管道中读取n个字节。
这个系统调用可能以两种方式阻塞当前进程:
- 当系统调用开始时管道缓冲区为空。
- 管道缓冲区没有包含所有请求的字节,写进程在等待缓冲区的空间时曾被置为睡眠。
注意,读操作可以是非阻塞的。在这种情况下,只要所有可用的字节(即使是0个)一被拷贝到用户地址空间中,读操作就完成。还要注意,只有在管道为空而且当前没有进程正在使用与管道的写通道相关的文件对象时,read()系统调用才会返回0。
pipe_read()函数执行以下操作:
获取索引节点的
i_sem信号量。确定存放在
pipe_inode_info结构nrbufs字段中的管道大小是否为0。如果是,说明所有管道缓冲区为空。这时还要确定函数必须返回还是进程在等待时必须被阻塞,直到其他进程向管道中写入一些数据。I/O操作的类型(阻塞或非阻塞)是通过文件对象的f_flags字段中的O_NONBLOCK标志来表示的。如果当前进程必须被阻塞,则函数执行下列操作:- 调用
prepare_to_wait()把current加到管道的等待队列(pipe_inode_info结构的wait字段)。 - 释放索引节点的信号量。
- 调用
schedule()。 - 一旦
current被唤醒,就调用finish_wait()把它从等待队列中删除,再次获取i_sem索引节点信号量,然后跳回第2步。
- 调用
从
pipe_inode_info数据结构的curbuf字段得到当前管道缓冲区索引。执行管道缓冲区的
map方法。从管道缓冲区拷贝请求的字节数(如果较小,就是管道缓冲区可用字节数)到用户地址空间。
执行管道缓冲区的
unmap方法。更新相应
pipe_buffer对象的offset和len字段。如果管道缓冲区已空(
pipe_buffer对象的len字段现在等于0),则调用管道缓冲区的release方法释放对应的页框,把pipe_buffer对象的ops字段置为NULL,增加在pipe_inode_info数据结构的curbuf字段中存放的当前管道缓冲区索引,并减小nrbufs字段中非空管道缓冲区计数器的值。如果所有请求字节拷贝完毕,则跳至第
12步。目前,还没有把所有请求字节拷贝到用户态地址空间。如果管道大小大于
0(pipe_inode_info的nrbufs字段不是NULL),则跳到第3步。管道缓冲区内已没有剩余字节。如果至少有一个写进程正在睡眠(即
pipe_inode_info数据结构的waiting_writers字段大于0),且读操作是阻塞的,那么调用wake_up_interruptible_sync()唤醒在管道等待队列中所有睡眠的进程,然后跳至第2步。释放索引节点的
i_sem信号量。调用
wake_up_interruptible_sync()函数唤醒在管道的等待队列中所有睡眠的写者进程。返回拷贝到用户地址空间的字节数。
向管道中写入数据
希望向管道中写入数据的进程发出一个write()系统调用,为管道的写端指定一个文件描述符。内核通过调用适当文件对象的write方法来满足这个请求;write_pipe_fops 表中相应的项指向pipe_write()函数。
表19-4概述了由POSIX标准所定义的write()系统调用的行为,该系统调用请求把n 个字节写入一个管道中,而该管道在它的缓冲区中有u个未用的字节。
具体地说,该标准要求涉及少量字节数的写操作必须原子地执行。更确切地说,如果两个或者多个进程并发地在写入一个管道,那么任何少于4096个字节(管道缓冲区的大小)的写操作都必须单独完成,而不能与唯一进程对同一个管道的写操作交叉进行。但是,超过4096个字节的写操作是可分割的,也可以强制调用进程睡眠。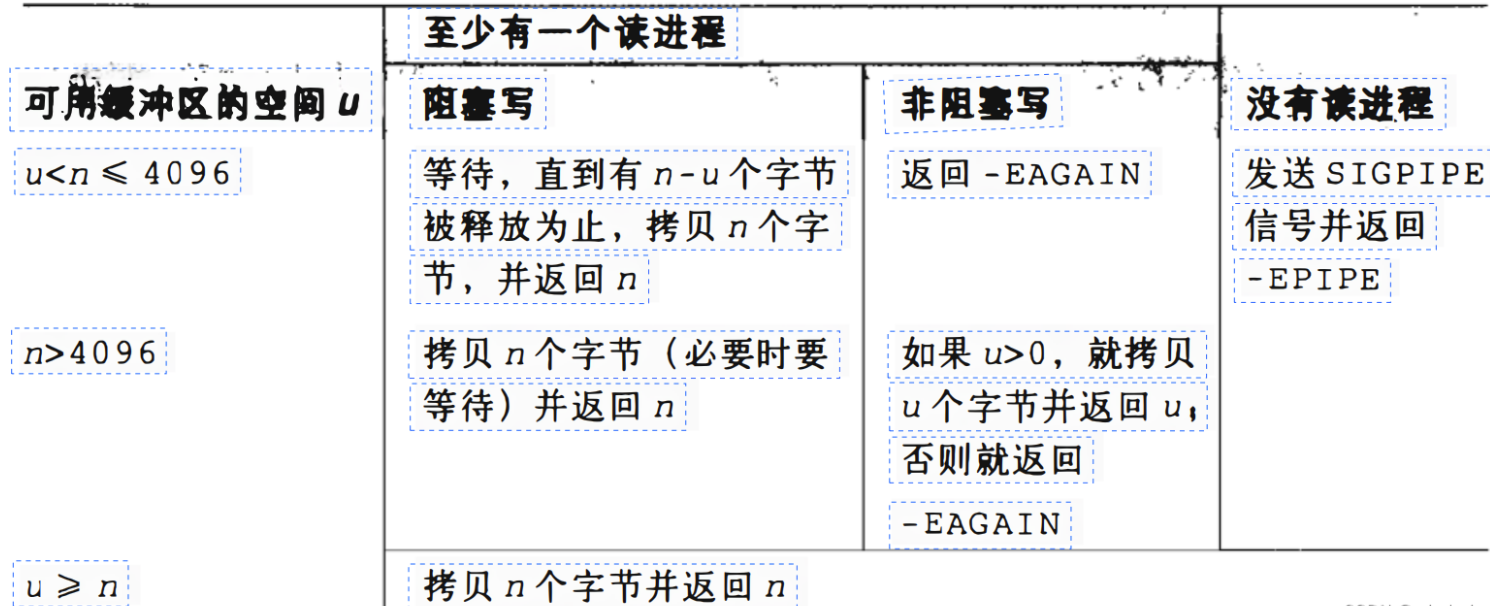
还有,如果管道没有读进程(也就是说,如果管道的索引节点对象的readers字段的值是0),那么任何对管道执行的写操作都会失败。在这种情况下,内核会向写进程发送一个SIGPIPE信号,并停止write()系统调用,使其返回一个-EPIPE错误码,这个错误码就表示我们熟悉的“Broken pipe(损坏的管道)”消息。
pipe_write()函数执行以下操作:
获取索引节点的
i_sem信号量。检查管道是否至少有一个读进程。如果不是,就向当前进程发送一个
SIGPIPE信号,释放索引节点信号量并返回-EPIPE值。将
pipe_inode_info数据结构curbuf和nrbufs字段相加并减一得到最后写入的管道缓冲区索引。如果该管道缓冲区有足够空间存放待写字节,就拷入这些数据:- 执行管道缓冲区的
map方法。 - 把所有字节拷贝到管道缓冲区。
- 执行管道缓冲区的
unmap方法。 - 更新相应
pipe_buffer对象的len字段。 - 跳至第
11步。
- 执行管道缓冲区的
如果
pipe_inode_info数据结构的nrbufs字段等于16,就表明没有空闲管道缓冲区来存放待写字节。这种情况下:- 如果写操作是非阻塞的,跳至第
11步,结束并返回错误码-EAGAIN - 如果写操作是阻塞的,将
pipe_inode_info结构的waiting_writers字段加1,调用prepare_to_wait()将当前操作加入管道等待队列(pipe_inode_info结构的wait字段),释放索引节点信号量,调用schedule()。一旦唤醒,则调用finish_wait()从等待队列中移出当前操作,重新获得索引节点信号量,递减waiting_writers字段,然后跳回第4步。
- 如果写操作是非阻塞的,跳至第
现在至少有一个空缓冲区,将
pipe_inode_info数据结构的curbuf和nrbufs字段相加得到第一个空管道缓冲区索引。除非
pipe_inode_info数据结构的tmp_page字段不是NULL,否则从伙伴系统中分配一个新页框。从用户态地址空间拷贝多达
4096个字节到页框(如果必要,在内核态线性地址空间作临时映射)。更新与管道缓冲区关联的
pipe_buffer对象的字段:将page字段设为页框描述符的地址,ops字段设为anon_pipe_buf_ops表的地址,offset字段设为0,len字段设为写入的字节数。增加非空管道缓冲区计数器的值,该缓冲区计数器存放在
pipe_inode_inf结构的nrbufs字段。如果所有请求的字节还没有写完,则跳至第
4步。释放索引节点信号量。
唤醒在管道等待队列上睡眠的所有读进程。
返回写入管道缓冲区的字节数(如果无法写入,则返回错误码)。
FIFO
虽然管道是一种十分简单、灵活、有效的通信机制,但它们有一个主要的缺点,也就是无法打开已经存在的管道。这就使得任意的两个进程不可能共享同一个管道,除非管道由一个共同的祖先进程创建。这个缺点在很多应用程序中都存在。
服务器和给定客户端之间的每次交互都可以使用一个管道进行处理。但是,当用户显式查询数据库时,通常由shell命令根据需要创建客户端进程;因此,服务器进程和客户端进程就不能方便地共享管道。
为了突破这种限制,Unix系统引入了一种称为命名管道(named pipe)或者FIFO[FIFO 代表“先进先出(first in,first out)”;最先写入文件的字节总是被最先读出]的特殊文件类型。
FIFO在这几个方面都非常类似于管道:在文件系统中不拥有磁盘块,打开的FIFO 总是与一个内核缓冲区相关联,这一缓冲区中临时存放两个或多个进程之间交换的数据。然而,有了磁盘索引节点,使得任何进程都可以访问FIFO,因为FIFO文件名包含在系统的目录树中。
因此,在前面那个数据库的例子中,服务器和客户端之间的通信可以很容易地使用FIFO而不是管道。服务器在启动时创建一个FIFO,由客户端程序用来发出自己的请求。每个客户端程序在建立连接之前都另外创建一个FIFO,并在自己对服务器发出的最初请求中包含这个FIFO的名字,服务器程序就可以把查询结果写入这个FIFO。在Linux 2.6中,FIFO和管道几乎是相同的,并使用相同的pipe_inode_info结构。
事实上,FIFO的read和write操作就是由前面“从管道中读取数据”和“向管道中写入数据”这两节描述的pipe_read()和pipe_write()函数实现的。事实上,只有两点主要的差别:
FIFO索引节点出现在系统目录树上而不是pipefs特殊文件系统中。FIFO是一种双向通信管道;
也就是说,可能以读/写模式打开一个FIFO。因此,为了完成我们的描述,我们仅说明如何创建和打开FIFO。
创建并打开FIFO
进程通过执行mknod()系统调用创建一个FIFO,传递的参数是新FIFO的路径名以及S_IFIFO(0x10000)与这个新文件的权限位掩码进行逻辑或的结果。POSIX引入了一个名为mkfifo()的系统调用专门用来创建FIFO。这个系统调用在Linux以及System VRelease 4中是作为调用mknod()的C库函数实现的。
FIFO一旦被创建,就可以使用普通的open()、read()、write()和close()系统调用访问FIFO,但是VFS对FIFO的处理方法比较特殊,因为FIFO的索引节点及文件操作都是专用的,并且不依赖于FIFO所在的文件系统。POSIX标准定义了open()系统调用对FIFO的操作;这种操作本质上与所请求的访问类型、I/O操作的种类(阻塞或非阻塞)以及其他正在访问FIFO的进程的存在状况有关。
进程可以为读操作、写操作或者读写操作打开一个FIFO。根据这三种情况,把与相应的文件对象相关的文件操作设置成特定的方法。
当进程打开一个FIFO时,VFS就执行一些与设备文件所执行的操作相同的操作。与打开的FIFO相关的索引节点对象是由依赖于文件系统的read_inode超级块方法进行初始化的。
这个方法总要检查磁盘上的索引节点是否表示一个特殊文件,并在必要时调用init_special_inode()函数。这个函数又把索引节点对象的i_fop字段设置为def_fifo_fops表的地址。
随后,内核把文件对象的文件操作表设置为def_fifo_fops,并执行它的open方法,这个方法由fifo_open()实现。fifo_open()函数初始化专用于FIFO的数据结构;具体来说,它执行下列操作:
- 取
i_sem索引节点信号量。 - 检查索引节点对象的
i_pipe字段;如果为NULL,则分配并初始化一个新的pipe_inode_info结构,这与本章前面“创建和撤销管道”一节的第1b~le步相同。 - 根据
open()系统调用的参数中指定的访问模式,用合适的文件操作表的地址初始化文件对象的f_op字段 - 如果访问模式或者为只读或者为读/写,则把
1加到pipe_inode_info结构的readers字段和r_counter字段。此外,如果访问模式是只读的,且没有其他的读进程,则唤醒等待队列上的任何写进程。 - 如果访问模式或者为只写或者为读/写,则把
1加到pipe_inode_info结构的writers字段和w_counter字段。此外,如果访问模式是只写的,且没有其他的写进程,则唤醒等待队列上的任何读进程。 - 如果没有读进程或没有写进程,则确定函数是应当阻塞还是返回一个错误码而终止(如表
19-6所示)。

- 释放索引节点信号量,并终止,返回
0(成功)。 FIFO的三个专用文件操作表的主要区别是read和write方法的实现不同。如果访问类型允许读操作,那么read方法是使用pipe_read()函数实现的;否则,read方法就是使用bad pipe_r()函数实现的,该函数只是返回一个错误码。如果访问类型允许写操作,那么write方法就是使用pipe_write()函数实现的;否则,write方法就是使用bad pipe_w()函数实现的,该函数也只是返回一个错误代码。
System V IPC
IPC是进程间通信(Interprocess Communication)的缩写,通常指允许用户态进程执行下列操作的一组机制:
(1). 通过信号量与其他进程进行同步
(2). 向其他进程发送消息或者从其他进程接收消息和其他进程共享一段内存,System VIPC最初是在一个名为“Columbus Unix”的开发版Unix变体中引入的,之后在AT&T的System II中采用。现在在大部分Unix系统(包括Linux)中都可以找到。
IPC数据结构是在进程请求IPC资源(信号量、消息队列或者共享内存区)时动态创建的。每个IPC资源都是持久的:除非被进程显式地释放,否则永远驻留在内存中(直到系统关闭)。IPC资源可以由任一进程使用,包括那些不共享祖先进程所创建的资源的进程。
由于一个进程可能需要同类型的多个IPC资源,因此每个新资源都是使用一个32位的IPC关键字来标识的,这和系统的目录树中的文件路径名类似。每个IPC资源都有一个32位的IPC标识符,这与和打开文件相关的文件描述符有些类似。IPC标识符由内核分配给IPC资源,在系统内部是唯一的,而IPC关键字可以由程序员自由地选择。
当两个或者更多的进程要通过一个IPC资源进行通信时,这些进程都要引用该资源的IPC标识符。
使用IPC资源
根据新资源是信号量、消息队列还是共享内存区,分别调用semget()、msgget()或者shmget()函数创建IPC资源。
这三个函数的主要目的都是从IPC关键字(作为第一个参数传递)中导出相应的IPC标识符,进程以后就可以使用这个标识符对资源进行访问。
如果还没有IPC资源和IPC关键字相关联,就创建一个新的资源。如果一切都顺利,那么函数就返回一个正的IPC标识符;否则,就返回一个如表19-7所示的错误码。
- EACCES:指定的消息队列已存在,但调用进程没有权限访问它
- EEXIST:key指定的消息队列已存在,而msgflg中同时指定IPC_CREAT和IPC_EXCL标志
- ENOENT:key指定的消息队列不存在同时msgflg中没有指定IPC_CREAT标志
- ENOMEM:需要建立消息队列,但内存不足
- ENOSPC:需要建立消息队列,但已达到系统的限制
假设两个独立的进程想共享一个公共的IPC资源。这可以使用两种方法来达到:
- 这两个进程统一使用固定的、预定义的
IPC关键字。这是最简单的情况,对于由很多进程实现的复杂的应用程序也工作得很好。然而,另外一个无关的程序也可能使用了相同的IPC关键字。在这种情况下,IPC函数可能被成功地调用,但返回错误资源的IPC标识符。 - 一个进程通过指定
IPC_PRIVATE作为自己的IPC关键字来调用semget()、msgget()或shmget()函数。一个新的IPC资源因此而被分配,这个进程或者可以与应用程序中的另一个进程共享自己的IPC标识符,或者自己创建另一个进程。这种方法确保IPC资源不会偶然被其他应用程序使用。
semget()、msgget()和shnget()函数的最后一个参数可以包括三个标志。
IPC_CREAT说明如果IPC资源不存在,就必须创建它;IPC_EXCL说明如果资源已经存在而且设置了IPC_CREAT标志,那么函数就必定失败;IPC_NOWAIT说明访问IPC资源时进程从不阻塞(典型的情况如取得消息或获取信号量)。
即使进程使用了IPC_CREAT和IPC_EXCL标志,也没有办法保证对一个IPC资源进行排它访问,因为其他进程也可能用自己的IPC标识符引用了这个资源。
为了把不正确地引用错误资源的风险降到最小,内核不会在IPC标识符一空闲时就再利用它。相反,分配给资源的IPC标识符总是大于给同类型的前一个资源所分配的标识符(唯一的例外发生在32位的IPC标识符溢出时)。
每个IPC标识符都是通过结合使用与资源类型相关的位置使用序号(slot usage sequence number)、已分配资源的任意位置索引(slot index)以及内核中为可分配资源所选定的的最大值而计算出来的。
如果我们使用s来代表位置使用序号,M来代表可分配资源的最大数目,i来代表位置索引,此处0 ≤ i < M,则每个IPC资源的ID都可以按如下公式来计算:IPC标识符 = s × M + i。在Linux 2.6中,M的值设为32768(IPCMNI宏)。位置使用序号s被初始化成0,每次分配资源时增加1。当s达到预定的阈值时(这取决于IPC资源类型),它从0重新开始。
IPC资源的每种类型(信号量、消息队列和共享内存区)都拥有ipc_ids数据结构ipc_id_ary数据结构有两个字段:p和size。p字段是一个指向kern_ipc_perm数据结构的指针数组,每个结构对应一个可分配资源。size字段是这个数组的大小。
最初,数组为共享内存区、消息队列与信号量分别存放1、16或128个指针。当太小时,内核动态地增大数组。但是每种资源都有个上限。系统管理员可以修改/proc/sys/kernel/sem、/proc/sys/kernel/msgmni和/proc/sys/kernel/shmmni这三个文件以改变这些上限。每个kern_ipc_perm数据结构与一个IPC资源相关联,并且包含如表19-9所示的字段。uid、gid、cuid和cgid分别存放资源的创建者的用户标识符和组标识符以及当前资源属主的用户标识符和组标识符。mode位掩码包括六个标志,分别存放资源的属主、组以及其他用户的读、写访问权限。
IPC访问许可权和第一章的“访问权限和文件模式”一节中介绍的文件访问许可权类似,唯一不同的是这里没有执行许可权标志。kern_ipc_perm数据结构也包括一个key字段和一个seq字段,前者指的是相应资源的IPC关键字,后者存放的是用来计算该资源的IPC标识符所使用的位置使用序号。
semctl()、msgctl()和shmctl()函数都可以用来处理IPC资源。IPC_SET子命令允许进程改变属主的用户标识符和组标识符以及ipc_perm数据结构中的许可权位掩码。IPC_STAT和IPC_INFO子命令取得和资源有关的信息。最后,IPC_RMID子命令释放IPC资源。
根据IPC资源的种类不同,还可以使用其他专用的子命令。一旦一个IPC资源被创建,进程就可以通过一些专用函数对这个资源进行操作。进程可以执行semop()函数获得或释放一个IPC信号量。当进程希望发送或接收一个IPC消息时,就分别使用msgsnd()和msgrcv()函数。最后,进程可以分别使用shmat()和shmdt()函数把一个共享内存区附加到自己的地址空间中或者取消这种附加关系。
ipc()系统调用
所有的IPC函数都必须通过适当的Linux系统调用实现。实际上,在80×86体系结构中,只有一个名为ipc()的IPC系统调用。当进程调用一个IPC函数时,比如说msgget(),该函数实际上调用C库中的一个封装函数,该函数又通过传递msgget()的所有参数加上一个适当的子命令代码(在本例中是MSGGET)来调用ipc()系统调用。sys_ipc()服务例程检查子命令代码,并调用内核函数实现所请求的服务。ipc()“多路复用”系统调用是从早期的Linux版本中继承而来的,早期Linux版本把IPC 代码包含在动态模块中。在system_call表中为可能未实现的内核部件保留几个系统调用入口并没有什么意义,因此内核设计者就采用了这种多路复用的方法。现在,System V IPC不再作为动态模块被编译,因此也就没有理由使用单个IPC系统调用。事实上,Linux在HP的Alpha体系结构和Intel的IA-64上为每个IPC函数都提供了一个系统调用。
IPC信号量
IPC信号量和在内核信号量非常类似:二者都是计数器,用来为多个进程共享的数据结构提供受控访问。如果受保护的资源是可用的,那么信号量的值就是正数;如果受保护的资源现不可用,那么信号量的值就是0。要访问资源的进程试图把信号量的值减1,但是,内核阻塞这个进程,直到在这个信号量上的操作产生一个正值。当进程释放受保护的资源时,就把信号量的值增加1;在这样处理的过程中,其他所有正在等待这个信号量的进程就都被唤醒。
实际上,IPC信号量比内核信号量的处理更复杂是由于两个主要的原因:
每个IPC信号量都是一个或者多个信号量值的集合,而不像内核信号量一样只有一个值。这意味着同一个IPC资源可以保护多个独立、共享的数据结构。在资源正在被分配的过程中,必须把每个IPC信号量中的信号量的个数指定为semget()函数的一个参数。
从现在开始,我们就把信号量内部的计数器作为原始信号量(primitive semaphore)来引用。IPC信号量资源的个数和单个IPC资源内原始信号量的个数都有界限,其缺省值前者为128,后者为250;
不过,系统管理员可以通过/proc/sys/kernel/sem文件很容易地修改这两个界限。
System V IPC信号量提供了一种失效安全机制,这是用于进程不能取消以前对信号量执行的操作就死亡的情况的。当进程选择使用这种机制时,由此引起的操作就是所谓的可取消的(undoable)信号量操作。当进程死亡时,所有IPC信号量都可以恢复成原来的值,就好像从来都没有开始它的操作。这有助于防止出现这种情况:由于正在结束的进程不能手工取消它的信号量操作,其他使用相同信号量的进程无限地停留在阻塞状态。
首先我们简要描绘一下,当进程想访问IPC信号量所保护的一个或者多个资源时所执行的典型步骤:
- 调用
semget()封装函数来获得IPC信号量标识符,作为参数指定对共享资源进行保护的IPC信号量的IPC关键字。如果进程希望创建一个新的IPC信号量,则还要指定IPC_CREATE或者IPC_PRIVATE标志以及所需要的原始信号量。 - 调用
semop()封装函数来测试并递减所有原始信号量所涉及的值。如果所有的测试全部成功,就执行递减操作,结束函数并允许这个进程访问受保护的资源。
如果有些信号量正在使用,那么进程通常都会被挂起,直到某个其他进程释放这个资源为止。函数接收的参数为IPC信号量标识符、用来指定对原始信号量所进行的原子操作的一组整数以及这种操作的个数。作为选项,进程也可以指定SEM_UNDO标志,这个标志通知内核:如果进程没有释放原始信号量就退出,那么撤消那些操作。
(4). 当放弃受保护的资源时,就再次调用semop()函数来原子地增加所有有关的原始信号量。
(5). 作为选择,调用semctl()封装函数,在参数中指定IPC_RMID命令把这个IPC信号量从系统中删除。
现在我们就可以讨论内核是如何实现IPC信号量的。有关的数据结构如图19-1所示。sem_ids变量存放IPC信号量资源类型的ipc_ids数据结构;对应的ipc_id_ary数据结构包含一个指针数组,它指向sem_array数据结构,每个元素对应一个IPC信号量资源。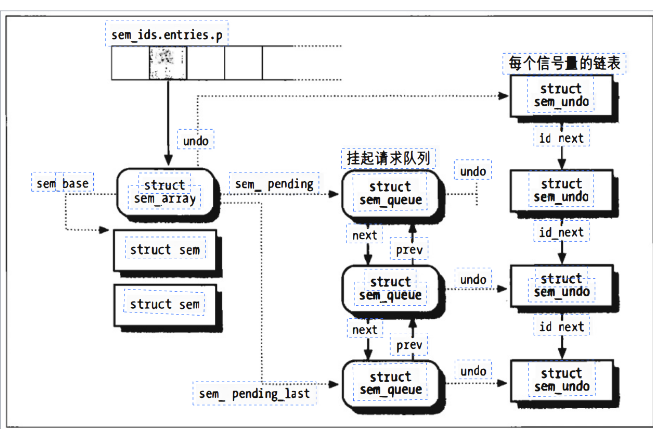
从形式上说,这个数组存放指向kern_ipc_perm数据结构的指针,但是每个结构只不过是sem_array数据结构的第一个字段。sem_base字段指向sem数据结构的数组,每个元素对应一个IPC原始信号量。sem数据结构只包括两个字段:
(1). semval
信号量的计数器的值。
(2). sempid
最后一个访问信号量的进程的PID。进程可以使用semctl()封装函数查询该值
可取消的信号量操作
如果一个进程突然放弃执行,那么它就不能取消已经开始执行的操作(例如,释放自己保留的信号量);因此通过把这些操作定义成可取消的,进程就可以让内核把信号量返回到一致状态并允许其他进程继续执行。进程可以在semop()函数中指定SEM_UNDO标志来请求可取消的操作。
为了有助于内核撤消给定进程对给定的IPC信号量资源所执行的可撤销操作,有关的信息存放在sem_undo数据结构中。这个结构实际上包含信号量的IPC标识符及一个整数数组,这个数组表示由进程执行的所有可取消操作对原始信号量值引起的修改。
有一个简单的例子可以说明如何使用这种sem_undo元素。考虑一个进程使用具有4个原始信号量的一个IPC信号量资源,并假设该进程调用semop()函数把第一个计数器的值增加1并把第二个计数器的值减2。如果该函数指定了SEM_UNDO标志,sem_undo数据结构中的第一个数组元素中的整数值就被减少1,而第二个元素就被增加2,其他两个整数都保持不变。
同一进程对这个IPC信号量执行的更多的可取消操作将相应地改变存放在sem_undo结构中的整数值。当进程退出时,该数组中的任何非零值就表示对相应原始信号量的一个或者多个错乱操作;
内核只简单地给相应的原始信号量计数器增加这个非零值来取消这些操作。换而言之,把异常中断的进程所做的修改退回,而其他进程所做的修改仍然能反映信号量的状态。
对于每个进程来说,内核都要记录以可取消操作处理的所有信号量资源,这样如果进程意外退出,就可以回滚这些操作。还有,内核还必须对每个信号量都记录它所有的sem_undo结构,这样只要进程使用semctl()来强行给一个原始信号量的计数器赋一个明确的值或者撤消一个IPC信号量资源时,内核就可以快速访问这些结构。
正是由于两个链表(我们称之为每个进程的链表和每个信号量的链表),使得内核可以有效地处理这些任务。第一个链表记录给定进程以可取消操作处理的所有信号量。第二个链表记录对以可取消操对给定信号量进行操作的所有进程。更确切地说:
- 每个进程链表包含所有的
sem_undo数据结构,该结构对应于进程执行了可取消操作的IPC信号量。进程描述符的sysvsem.undo_list字段指向一个sem_undo_list类型的数据结构,而该结构又包含了指针指向该链表的第一个元素。 - 每个
sem_undo数据结构的proc_next字段指向该链表的下一个元素,因为都共享一个sem_undo_list描述符,将CLONE_SYSVSEM标志传给clone()系统调用而克隆的进程都共享同一个可取消信号量操作链表。 - 每个信号量链表包含的所有
sem_undo数据结构对应于在该信号量上执行可取消操作的进程。sem_array数据结构的undo字段指向链表的第一个元素,而每个sem_undo数据结构的id_next字段指向链表的下一个元素。
当进程结束时,每个进程的链表才被使用。exit_sem()函数由do_exit()调用,后者会遍历这个链表,并为进程所涉及的每个IPC信号量平息错乱操作产生的影响。
与此相对照,当进程调用semctl()函数强行给一个原始信号量赋一个明确的值时,每个信号量的链表才被使用。内核把指向IPC信号量资源的所有sem_undo数据结构中的数组的相应元素都设置成0,因为撤消原始信号量的一个可取消操作不再有任何意义。此外,在IPC信号量被清除时,每个信号量链表也被使用。通过把semid字段设置成-1而使所有有关的sem_undo数据结构都变为无效。
挂起请求的队列
内核给每个IPC信号量都分配了一个挂起请求队列,用来标识正在等待数组中的一个(或多个)信号量的进程。
这个队列是一个sem_queue数据结构的双向链表,其字段如表19-11所示。队列中的第一个和最后一个挂起请求分别由sem_array结构中的sem pending和sem_pending_last字段所指向。
这最后一个字段允许把链表作为一个FIFO进行简单的处理。新的挂起请求都被追加到链表的末尾,这样就可以稍后得到服务。
挂起请求最重要的字段是nsops和sops,前者存放挂起操作所涉及的原始信号量的个数,后者指向描述每个信号量操作的整型数组。sleeper字段存放发出请求操作的睡眠进程的描述符地址。
有三个挂起请求的一个IPC信号量。第二个和第三个请求涉及可取消操作,因此sem_queue数据结构的undo字段指向相应的sem_undo结构;第一个挂起请求的undo字段为NULL,因为相应的操作是不可取消的。
IPC消息
进程彼此之间可以通过IPC消息进行通信。进程产生的每条消息都被发送到一个IPC消息队列中,这个消息一直存放在队列中直到另一个进程将其读走为止。
消息是由固定大小的首部和可变长度的正文组成的,可以使用一个整数值(消息类型)标识消息,这就允许进程有选择地从消息队列中获取消息。只要进程从IPC消息队列中读出一条消息,内核就把这个消息删除;因此,只能有一个进程接收一条给定的消息。
为了发送一条消息,进程要调用msgsnd()函数,传递给它以下参数:
- 目标消息队列的
IPC标识符 - 消息正文的大小
- 用户态缓冲区的地址,缓冲区中包含消息类型,之后紧跟消息正文
进程要获得一条消息就要调用msgrcv()函数,传递给它如下参数:
IPC消息队列资源的IPC标识符- 指向用户态缓冲区的指针,消息类型和消息正文应该到被拷贝这个缓冲区
- 缓冲区的大小
- 一个值
t,指定应该获得什么消息
如果t的值为0,就返回队列中的第一条消息。如果t为正数,就返回队列中类型等于t 的第一条消息。最后,如果1为负数,就返回消息类型小于等于t绝对值的最小的第一条消息。为了避免资源耗尽,IPC消息队列资源在这几个方面是有限制的:
IPC消息队列数(缺省为16),每个消息的大小(缺省为8192字节)及队列中全部信息的大小(缺省为16384 字节)。不过和前面类似,系统管理员可以分别修改/proc/sys/kernel/msgmni、/proc/sys/kernel/msgmnb和/proc/sys/kernel/msgmax文件调整这些值。与IPC消息队列有关的数据结构如图19-2所示。msg_ids变量存放IPC消息队列资源类型的ipc_ids数据结构;相应的ipc_id_ary数据结构包含一个指向shmid_kernel数据结构的指针数组–每个IPC消息资源对应一个元素。
从形式上看,数组中存放指向kern_ipc_perm数据结构的指针,但是,每个这样的结构只不过是msg_queue数据结构的第一个字段。msg_queue数据结构的所有字段如表19-12所示。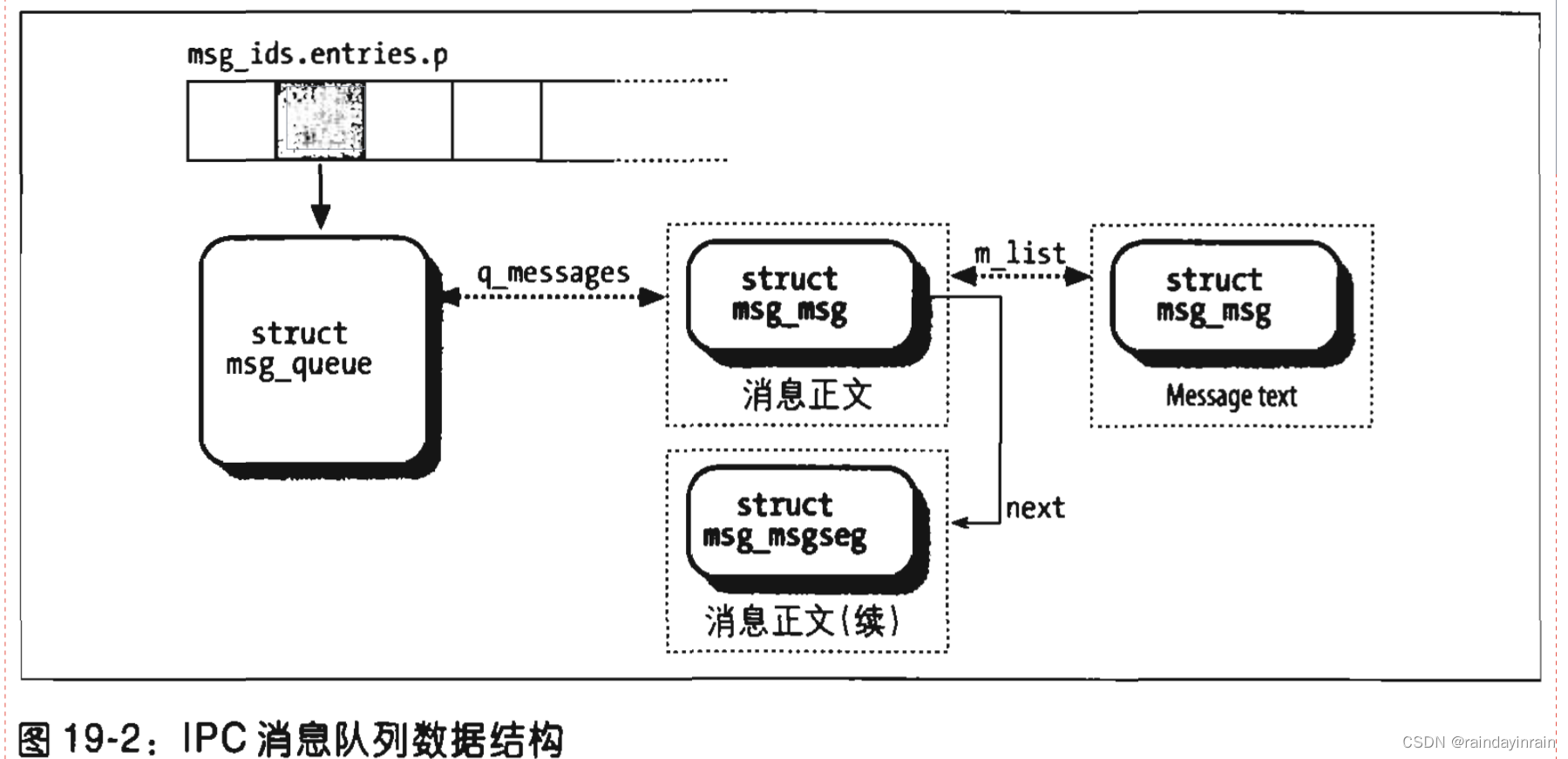
最重要的字段是qmessages,它表示包含队列中当前所有消息的双向循环链表的首部(也就是第一个哑元素)。每条消息分开存放在一个或多个动态分配的页中。
- 第一页的起始部分存放消息头,消息头是一个
msg_msg类型的数据结构;它的字段如表19-13所示。m_list字段指向队列中前一条和后一条消息的指针。消息的正文正好从msg_msg描述符之后开始;如果消息(页的大小减去msg_msg描述符的大小)大于4072字节,就继续放在另一页,它的地址存放在msg_msg描述符的next字段中。 - 第二个页框以
msg_msgseg类型的描述符开始,这个描述符只包含一个next指针,该指针存放可选的第三个页,以此类推。当消息队列满时(或者达到了最大消息数,或者达到了队列最大字节数),则试图让新消息入队的进程可能被阻塞。msg_queue数据结构的q_senders字段是所有阻塞的发送进程的描述符形成的链表的头。当消息队列为空时(或者当进程指定的一条消息类型不在队列中时),则接收进程也会被阻塞。
msg_queue数据结构的qreceivers字段是msg_receiver数据结构链表的头,每个阻塞的接收进程对应其中一个元素。其中的每个结构本质上都包含。一个指向进程描述的指针、一个指向消息的msg_msg结构的指针和所请求的消息类型。
IPC共享内存
最有用的IPC机制是共享内存,这种机制允许两个或多个进程通过把公共数据结构放入一个共享内存区(IPC shared memory region)来访问它们。
如果进程要访问这种存放在共享内存区的数据结构,就必须在自己的地址空间中增加一个新内存区,它将映射与这个共享内存区相关的页框。
这样的页框可以很容易地由内核通过请求调页进行处理。与信号量以及消息队列一样,调用shmget()函数来获得一个共享内存区的IPC标识符,如果这个共享内存区不存在,就创建它。
调用shmat()函数把一个共享内存区“附加(attach)”到一个进程上。该函数使用IPC 共享内存资源的标识符作为参数,并试图把一个共享内存区加入到调用进程的地址空间中。
调用进程可以获得这个内存区域的起始线性地址,但是这个地址通常并不重要,访问这个共享内存区域的每个进程都可以使用自己地址空间中的不同地址。
shmat()函数不修改进程的页表。我们稍后会介绍在进程试图访问属于新内存区域的页时内核究竟怎样进行处理。调用shmdt()函数来“分离”由IPC标识符所指定的共享内存区域,也就是说把相应的共享内存区域从进程的地址空间中删除。
回想一下,IPC共享内存资源是持久的;即使现在没有进程在使用它,相应的页也不能被丢弃,但是可以被换出。与IPC资源的其他类型一样,为了避免用户态进程过分使用内存,也有一些限制施加于所允许的,IPC共享内存区域数(缺省为4096)、每个共享段的大小(缺省为32MB)以及所有共享段的最大字节数(缺省为8GB)。
不过,系统管理员照样可以调整这些值,这是通过分别修改/proc/sys/kernel/shmmni、/proc/sys/kernel/shmmax和/proc/sys/kernel/shmall文件完成的。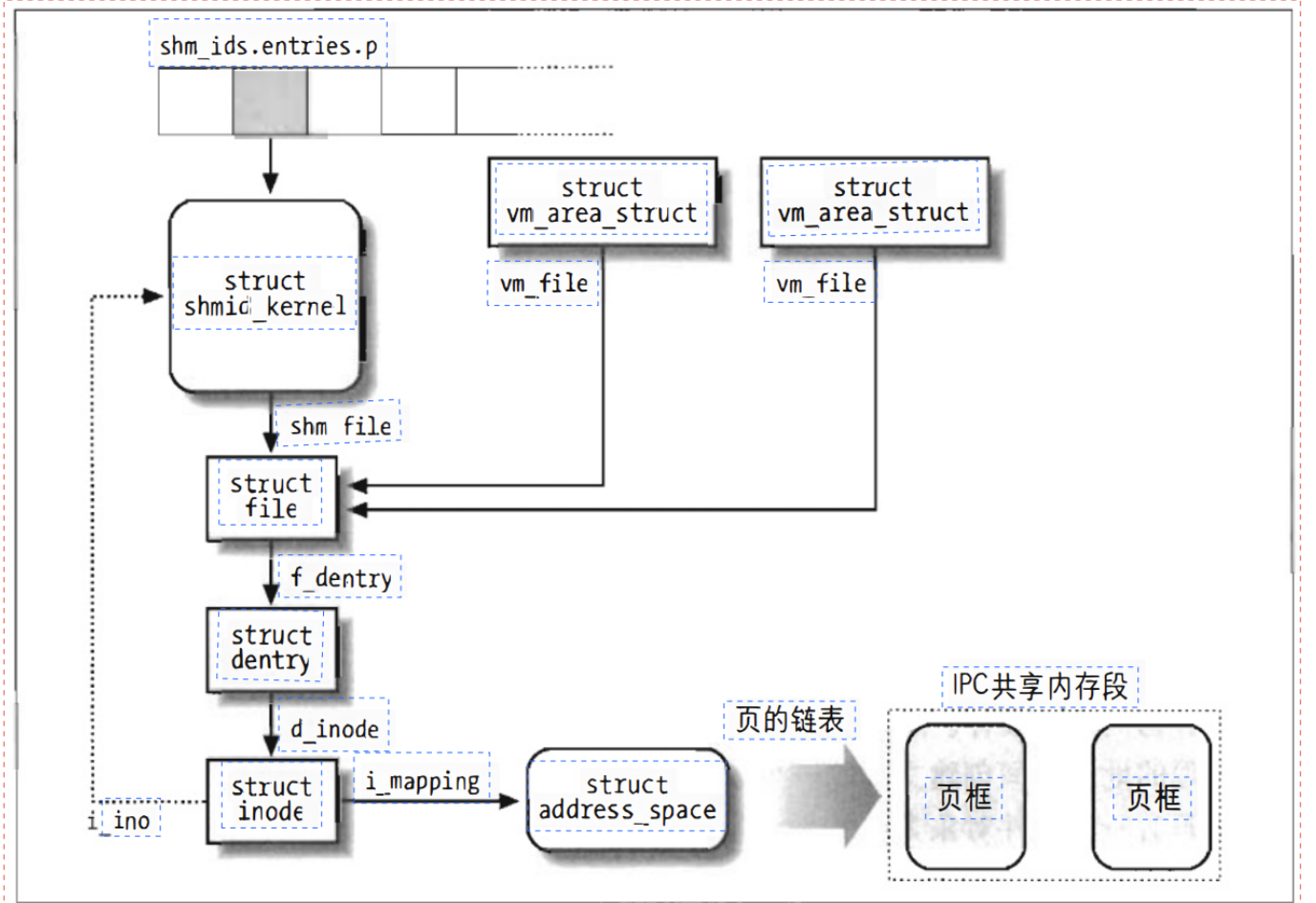
图19-3显示与IPC共享内存区相关的数据结构。shm_ids变量存放IPC共享内存资源类型ipc_ids的数据结构;相应的ipc_id_ary数据结构包含一个指向shmid_kernel数据结构的指针数组,每个IPC共享内存资源对应一个数组元素。
从形式上看,这个数组存放指向kern_ipc_perm数据结构指针,但是每个这样的结构只不过是shmid_kernel数据结构的第一个字段。shmid_kernel数据结构的所有字段如表19-14所示。
最重要的字段是shm_file,该字段存放文件对象的地址。这反映Linux 2.6中IPC共享内存与VFS的紧密结合。具体来说,每个IPC共享内存区与属于shm特殊文件系统的一个普通文件相关联。
因为shm文件系统在系统目录树中没有安装点,因此,用户不能通过普通的VFS系统调用打开并访问它的文件。
但是,只要进程“附加”一个内存段,内核就调用do_mmap(),并在进程的地址空间创建文件的一个新的共享内存映射。因此,属于shm特殊文件系统的文件只有一个文件对象方法mmap,该方法是由shm_mmap()函数实现的。
如图19-3所示,与IPC共享内存区对应的内存区是用vm_area_struct对象描述的;
它的vm_file字段指回特殊文件的文件对象,而特殊文件又依次引用目录项对象和索引节点对象。
存放在索引节点i_ino字段的索引节点号实际上是IPC共享内存区的位置索引,因此,索引节点对象间接引用shmid_kernel描述符。
同样,对于任何共享内存映射,通过address_space对象把页框包含在页高速缓存中,而address_space对象包含在索引节点中而且被索引节点的i_mapping字段引用。
万一页框属于IPC共享内存区,address_space对象的方法就存放在全局变量shmem_aops中。
换出IPC共享内存区的页
内核在把包含在共享内存区的页换出时一定要谨慎,并且交换高速缓存的作用是至关紧要的。
因为IPC共享内存区映射的是在磁盘上没有映像的特殊索引节点,因此其页是可交换的。因此为了回收IPC共享内存区的页,内核必须把它写入交换区。因为IPC共享内存区是持久的——也就是说即使内存段不附加到进程,也必须保留这些页。
因此即使这些页没有进程在使用,内核也不能简单地删除它们。让我们看看PFRA是如何回收IPC共享内存区页框的。一直到shrink_list()函数处理页之前,都与第十七章“内存紧缺回收”一节所描述的一样。因为这个函数并不为IPC 共享内存区域作任何检查,因此它会调用try_to_unmap()函数从用户态地址空间删除对页框的每个引用。正如第十七章“反向映射”一节描述的一样,相应的页表项就被删除。
然后,shrink_list()函数检查页的PG_dirty标志,调用pageout()(当IPC共享内存区域的页框在分配时总是被标记为脏,因此pageout()总是被调用)。而pageout()函数又调用所映射文件的address_space对象的writepage方法。
shmem_writepage()函数实现了IPC共享内存区页的writepage方法。它实际上给交换区域分配一个新页槽(page slot),然后将它从页高速缓存移到交换高速缓存(实际上就是改变页所有者的address_space对象)。
该函数还在shmem_inode_info结构中存放换出页页标识符,这个结构包含了IPC共享内存区的索引节点对象,它再次设置页的PG_dirty标志。
如第十七章的表17-5所示,shrink_list()函数检查PG_dirty标志,并通过把页留在非活动链表而中断回收过程。
迟早,PFRA还会处理该页框。shrink_list()又一次调用pageout()尝试将页刷新到磁盘。
但这一次,页已在交换高速缓存内,因而它的所有者是交换子系统的address_space对象,即swapper_space。相应的writepage方法swap_writepage()开始有效地向交换区进行写入操作。
一旦pageout()结束,shrink_list()确认该页已干净,于是从交换高速缓存删除页并释放给伙伴系统。
IPC共享内存区的请求调页
通过shmat()加入进程的页都是哑元页(dummy page);该函数把一个新内存区加入一个进程的地址空间中,但是它不修改该进程的页表。
此外,我们已经看到,IPC共享内存区的页可以被换出。因此,可以通过请求调页机制来处理这些页。
我们知道,当进程试图访问IPC共享内存区的一个单元,而其基本的页框还没有分配时则发生缺页异常。相应的异常处理程序确定引起缺页的地址是在进程的地址空间内,且相应的页表项为空;因此,它就调用do_no_page()函数。这个函数又检查是否为这个内存区定义了nopage方法。然后调用这个方法,并把页表项设置成所返回的地址。
IPC共享内存所使用的内存区通常都定义了nopage方法。这是通过shmem_nopage()函数实现的,该函数执行以下操作:
- 遍历
VFS对象的指针链表,并导出IPC共享内存资源的索引节点对象的地址(参见图19-3)。 - 从内存区域描述符的
vm_start字段和请求的地址计算共享段内的逻辑页号。 - 检查页是否已经在页高速缓存中,如果是,则结束并返回该描述符的地址。
- 检查页是否在交换高速缓存内且是否最新。如果是,则结束并返回该描述符的地址。
- 检查内嵌在索引节点对象的
shmem_inode_info是否存放着逻辑页号对应的换出页标识符。如果是,就调用read_swap_cache_async()执行换入操作,并一直等到数据传送完成,然后结束并返回页描述符的地址。 - 否则,页不在交换区中;因此就从伙伴系统分配一个新页框,把它插入页高速缓存,并返回它的地址。
do_no_page()函数对引起缺页的地址在进程的页表中所对应的表项进行设置,以使该函数指向nopage方法所返回的页框。
程序的执行
进程的信任状和权能
从传统上看,Unix系统与每个进程的一些信任状(credential)相关,信任状把进程与一个特定的用户或用户组捆绑在一起。
信任状在多用户系统上尤为重要,因为信任状可以决定每个进程能做什么,不能做什么,这样既保证了每个用户的个人数据的完整性,也保证了系统整体上的稳定性。信任状的使用既需要在进程的数据结构方面给予支持,也需要在被保护的资源方面给予支持。
文件就是一种显而易见的资源。因此,在Ext2文件系统中,每个文件都属于一个特定的用户,并被捆绑于某个用户组。
文件的拥有者可以决定对某个文件允许哪些操作,以在文件的拥有者、文件的用户组及其他所有用户之间做出区别。当某个进程试图访问一个文件时,VFS总是根据文件的拥有者和进程的信任状所建立的许可权检查访问的合法性。进程的信任状存放在进程描述符的几个字段中,如表20-1所示。这些字段包括系统中用户和用户组的标识符,与之可以相比较的通常是存放在所访问文件索引节点中的标识符。
| 名称 | 说明 |
|---|---|
| uid, gid | 用户与组的实际标识符 |
| euid, egid | 用户与组的有效标识符 |
| fsuid, fsgid | 文件访问的用户和组的有效标识符 |
| groups | 补充的组标识符 |
| suid, sgid | 用户和组保存的标识符 |
值为0的UID指定给root超级用户,而值为0的用户GID指定给root超级组。只要有关进程的信任状存放了一个零值,则内核将放弃权限检查,始终允许这个进程做任何事情,如涉及系统管理或硬件处理的那些操作,而这些操作对于非特权进程是不允许的。当一个进程被创建时,总是继承父进程的信任状。不过,这些信任状以后可以被修改,这发生在当进程开始执行一个新程序时,或者当进程发出合适的系统调用时。
通常情况下,进程的uid、euid、fsuid及suid字段具有相同的值。然而,当进程执行setuid 程序时,即可执行文件的setuid标志被设置时,euid和fsuid字段被置为这个文件拥有者的标识符。几乎所有的检查都涉及这两个字段中的一个: fsuid用于与文件相关的操作,而euid用于其他所有的操作。
这也同样适用于组标识符的gid、egid、fsgid及sgid字段。我们用一个例子来说明如何使用fsuid字段,考虑一下当用户想改变她的口令时的典型情况。所有的口令都存放在一个公共文件中,但用户不能直接编辑这样的文件,因为它是受保护的。因此,用户调用一个名为/usr/bin/passwd的系统程序,它可以设置setuid 标志,而且它的拥有者是超级用户。
当shell创建的进程执行这样一个程序时,进程的euid和fsuid字段被置为0,即超级用户的PID。现在,这个进程可以访问这个文件,因为当内核执行访问控制表时在fsuid字段发现了值0。当然,usr/bin/passwd程序除了让用户改变自己的口令外,并不允许做其他任何事情。
从Unix的历史发展可以得出一个教训,即setuid程序是相当危险的:恶意用户可以以这样的方式触发代码中的一些编程错误(bug),从而强迫setuid程序执行程序的最初设计者从未安排的操作。这可能常常危及整个系统的安全。为了减少这样的风险,Linux与所有现代Unix操作系统一样,让进程只有在必要时才获得setuid特权,并在不需要时取消它们。
可以证明,当以几个保护级别实现用户应用程序时,这种特点是很有用的。进程描述符包含一个suid字段,在setuid程序执行以后在该字段中正好存放有效标识符(euid和fsuid)的值。进程可以通过setuid()、setresuid()、setfsuid()和setreuid()系统调用改变有效标识符。
请注意,如果调用进程还没有超级用户特权,即它的euid字段不为0,那么,只能用这些系统调用来设置在这个进程的信任状字段已经有的值。例如,一个普通用户进程可以通过调用系统调用setfsuid()强迫它的fsuid值为500,但这只有在其他信任状字段中有一个字段已经有相同的值500时才行。
为了理解四个用户ID字段之间的复杂关系,让我们考虑一下setuid()系统调用的效果。这些操作是不同的,这取决于调用者进程的euid字段是否被置为0(即进程有超级用户特权)或被置为一个正常的UID。
如果euid字段为0,这个系统调用就把调用进程的所有信任状字段(uid、euid、fsuid 及suid)置为参数e的值。超级用户进程因此就可以删除自己的特权而变为由普通用户拥有的一个进程。例如,在用户登录时,系统以超级用户特权创建一个新进程,但这个进程通过调用setuid()系统调用删除自己的特权,然后开始执行用户的login shell程序。如果euid字段不为0,那么这个系统调用只修改存放在euid和fsuid中的值,让其他两个字段保持不变。当运行setuid程序来提高和降低进程有效权限时(这些权限存放在euid和fsuid字段),该系统调用的这种功能是非常有用的。
进程的权能
POSIX.le草案(现已撤销)用“权能(capability)”一词引入进程信任状的另一种模型。Linux内核支持POSIX权能,但是大部分Linux的发行版本不用它。一种权能仅仅是一个标志,它表明是否允许进程执行一个特定的操作或一组特定的操作。这个模型不同于传统的“超级用户VS普通用户”模型,在后一种模型中,一个进程要么能做任何事情,要么什么也不能做,这取决于它的有效UID。如表20-3所示,在Linux 内核中已包含了很多权能。
- CAP_CHOWN:修改文件属主的权限
- CAP_DAC_OVERRIDE:忽略文件的DAC访问限制
- CAP_DAC_READ_SEARCH:忽略文件读及目录搜索的DAC访问限制
- CAP_FOWNER:忽略文件属主ID必须和进程用户ID相匹配的限制
- CAP_FSETID:允许设置文件的setuid位
- CAP_KILL:允许对不属于自己的进程发送信号
- CAP_SETGID:允许改变进程的组ID
- CAP_SETUID:允许改变进程的用户ID
- CAP_SETPCAP:允许向其他进程转移能力以及删除其他进程的能力
- CAP_LINUX_IMMUTABLE:允许修改文件的IMMUTABLE和APPEND属性标志
- CAP_NET_BIND_SERVICE:允许绑定到小于1024的端口
- CAP_NET_BROADCAST:允许网络广播和多播访问
- CAP_NET_ADMIN:允许执行网络管理任务
- CAP_NET_RAW:允许使用原始套接字
- CAP_IPC_LOCK:允许锁定共享内存片段
- CAP_IPC_OWNER:忽略IPC所有权检查
- CAP_SYS_MODULE:允许插入和删除内核模块
- CAP_SYS_RAWIO:允许直接访问/devport,/dev/mem,/dev/kmem及原始块设备
- CAP_SYS_CHROOT:允许使用chroot()系统调用
- CAP_SYS_PTRACE:允许跟踪任何进程
- CAP_SYS_PACCT:允许执行进程的BSD式审计
- CAP_SYS_ADMIN:允许执行系统管理任务,如加载或卸载文件系统、设置磁盘配额等
- CAP_SYS_BOOT:允许重新启动系统
- CAP_SYS_NICE:允许提升优先级及设置其他进程的优先级
- CAP_SYS_RESOURCE:忽略资源限制
- CAP_SYS_TIME:允许改变系统时钟
- CAP_SYS_TTY_CONFIG:允许配置TTY设备
- CAP_MKNOD:允许使用mknod()系统调用
- CAP_LEASE:允许修改文件锁的FL_LEASE标志
补充:更加细致版本:
权能的主要优点是,任何时候每个进程只需要有限种权能。因此,即使有恶意的用户发现一种利用有潜在错误的程序的方法,他也只能非法地执行有限个操作类型。例如,假定一个有潜在错误的程序只有CAP_SYS_TIME权能。在这种情况下,利用其错误的恶意用户只能在非法地改变实时时钟和系统时钟方面获得成功。她并不能执行任何其他特权的操作。不管是VFS还是Ext2文件系统目前都不支持权能模型,所以,当进程执行一个可执行文件时,无法把这个文件与本该强加的一组权能联系起来。
然而,进程可以分别用capget()和capset()系统调用显式地获得和降低它的权能。例如,完全可以通过修改login程序只保留其权能的一个子集而删除其他权能。事实上,Linux内核已经考虑权能。例如,让我们考虑一下nice()系统调用,它允许用户改变进程的静态优先级。在传统的模型中,只有超级用户才能提升一个优先级,内核因此应该检查调用进程描述符的euid字段是否为0。然而,Linux内核定义了一个名为CAP_SYS_NICE的权能,就正好对应着这种操作。内核通过调用capable()函数并把CAP_SYS_NICE值传给这个函数来检查这个标志的值。正是由于一些“兼容性小巧程序”已被加入到内核代码中,这种方法才起作用。每当一个进程把euid和fsuid字段设置为0时(或者通过调用表20-2中的一个系统调用,或者通过执行超级用户所拥有的setuid程序),内核就设置进程的所有权能,以便使所有的检查成功。
类似地,当进程把euid和fsuid字段重新置为进程拥有者的实际UID时,内核检查进程描述符中的keep_capabilities标志,并在该标志设置时删除进程的所有权能。进程可以调用Linux专有的prctl()系统调用来设置和重新设置keep_capabilities标志。
Linux安全模块框架
在Linux 2.6中,权能是与Linux安全模块(LSM)框架紧密结合在一起的。
简单地说,LSM框架允许开发人员定义几种可以选择的内核安全模型。每个安全模型是由一组安全钩(security hook)实现的。安全钩是由内核调用的一个函数,用于执行与安全有关的重要操作。
钩函数决定一个操作是否可以执行。钩函数存放在security_operations类型的表中。当前使用的安全模型钩表地址存放在security_ops变量中。内核默认使用dummy_security_ops表实现最小安全模型。
表中的每个钩函数实际上去检查相应的权能(如果有)是否允许,否则无条件返回0(允许操作)。例如,stime()和settimeofday()函数的服务例程在改变系统日期时间之前调用settime安全钩。durmmy_security_ops表指向相应的函数,而该函数约束自己去检查当前进程是否有CAP_SYS_TIME的权能,并相应地返回0或者-EPERM。
命令行参数和shell环境
当用户键入一个命令时,为满足这个请求而装入的程序可以从shell接收一些命令行参数(command-line argument)。
例如,当用户键入命令:
$ ls -l /usr/bin 以获得在/usr/bin目录下的全部文件列表时,shell进程创建一个新进程执行这个命令。
这个新进程装入/bin/ls可执行文件。在这样做的过程中,从shell继承的大多数执行上下文被丢弃,但三个单独的参数ls、-l和/usr/bin依然保持。一般情况下,新进程可以接收任意多个参数。
传递命令行参数的约定依赖于所用的高级语言。在C语言中,程序的main()函数把传递给程序的参数个数和指向字符串指针数组的地址作为参数。下列原型形式化地表示了这种标准格式:int main(int argc,char *argv[])
在C语言中,传递给main()函数的第三个可选参数是包含环境变量的参数。环境变量用来定制进程的执行上下文,由此为用户或其他进程提供通用的信息,或者允许进程在执行execve()系统调用的过程中保持一些信息。为了使用环境变量,main()可以声明如下:int main(int argc, char *argv[], char *envp[])
envp参数指向环境串的指针数组,形式如下:VAR_NAME=something这里,VAR_NAME表示一个环境变量的名字,而“=”后面的子串表示赋给变量的实际值。envp数组的结尾用一个空指针标记,就像argv数组。envp数组的地址存放在C 库的environ全局变量中。命令行参数和环境串都存放在用户态堆栈中,正好位于返回地址之前。图20-1显示了用户态堆栈的底部单元。注意,环境变量位于栈底附近正好在一个0长整数之后。
库
每个高级语言的源码文件都是经过几个步骤才转化为目标文件的,目标文件中包含的是汇编语言指令的机器代码,它们和相应的高级语言指令对应。目标文件并不能被执行,因为它不包含源代码文件所用的全局外部符号名的线性地址(例如库函数或同一程序中的其他源代码文件)。这些地址的分配或解析是由链接程序完成的,链接程序把程序所有的目标文件收集起来并构造可执行文件。链接程序还分析程序所用的库函数,并以本章后面所描述的方式把它们粘合成可执行文件。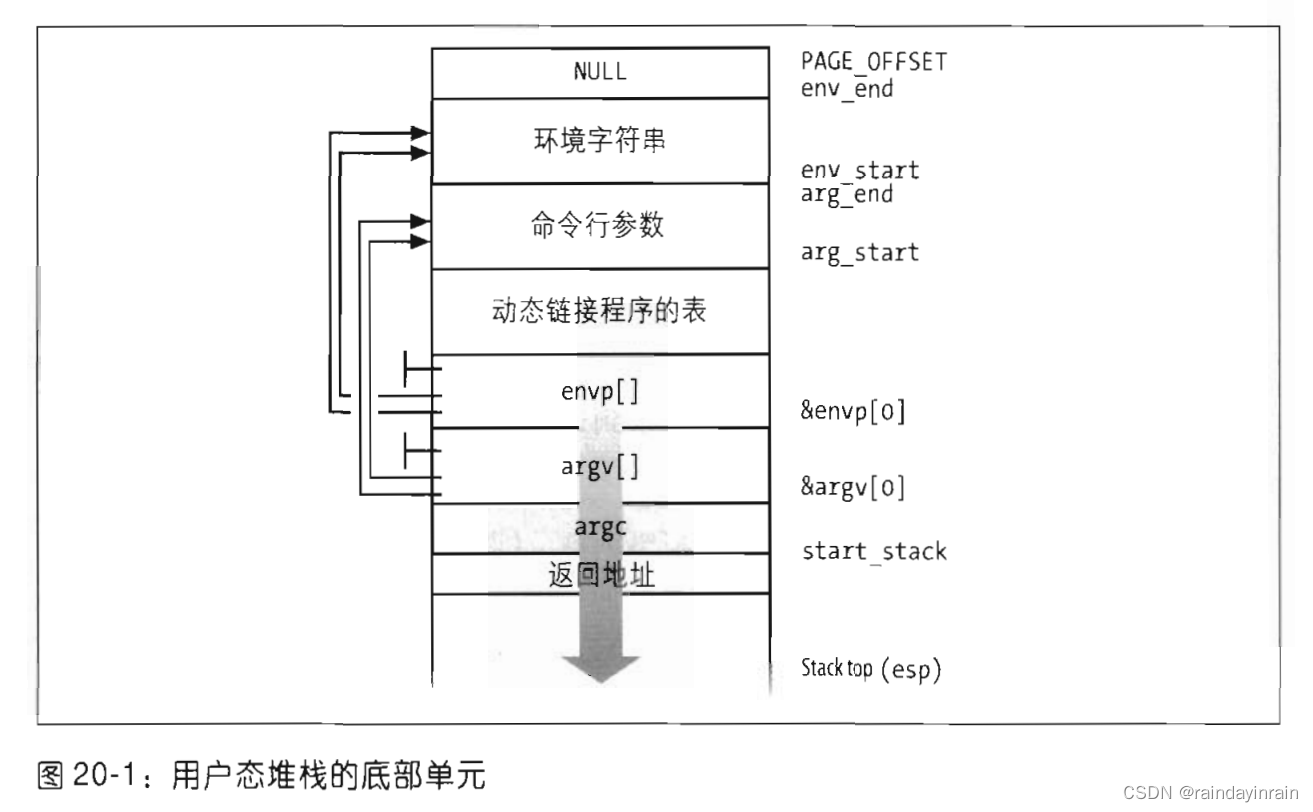
大多数程序,甚至是最小的程序都会利用C库。例如,请看下面只有一行的C程序:void main(void){}
尽管这个程序没有做任何事情,但还是需要做很多工作来建立执行环境,并在程序终止时杀死这个进程。尤其是当main()函数终止时,C编译程序把exit_group()函数插入到目标代码中。从第十章我们知道,程序通常通过C库中的封装例程调用系统调用。C编译器亦如此。任何可执行文件除了包括对程序的语句进行编译所直接产生的代码外,还包括一些“粘合”代码来处理用户态进程与内核之间的交互。这样的粘合代码有一部分存放在C库中。除了C库,Unix系统中还包含很多其他的函数库。一般的Linux系统通常就有几百个不同的库。这里仅仅列举其中的两个:数学库libm包含浮点操作的基本函数,而X11库libX1l收集了所有X11窗口系统图形接口的基本底层函数。
传统Unix系统中的所有可执行文件都是基于静态库(static library)的。这就意味着链接程序所产生的可执行文件不仅包括原程序的代码,还包括程序所引用的库函数的代码。静态库的一大缺点是:它们占用大量的磁盘空间。的确,每个静态链接的可执行文件都复制库代码的某些部分。
现代Unix系统利用共享库(shared library)。可执行文件不用再包含库的目标代码,而仅仅指向库名。当程序被装入内存执行时,一个名为动态链接器(dynamic linker,也叫ld.so)的程序就专注于分析可执行文件中的库名,确定所需库在系统目录树中的位置,并使执行进程可以使用所请求的代码。进程也可以使用dlopen()库函数在运行时装入额外的共享库。
共享库对提供文件内存映射的系统尤为方便,因为它们减少了执行一个程序所需的主内存量。当动态链接程序必须把某一共享库链接到进程时,并不拷贝目标代码,而是仅仅执行一个内存映射,把库文件的相关部分映射到进程的地址空间中。这就允许共享库机器代码所在的页框被使用同一代码的所有进程共享。显然,如果程序是静态链接的,那么共享是不可能的。共享库也有一些缺点。动态链接的程序启动时间通常比静态链接的程序长。此外,动态链接的程序的可移植性也不如静态链接的好,因为当系统中所包含的库版本发生变化时,动态链接的程序运行时就可能出现问题。用户可以始终请求一个程序被静态地链接。例如,GCC编译器提供-static选项,即告诉链接程序使用静态库而不是共享库。
程序段和进程的线性区
从逻辑上说,Unix程序的线性地址空间传统上被划分为几个叫做段(segment)的区间:
正文段,包含程序的可执行代码。
已初始化数据段,包含已初始化的数据,也就是初值存放在可执行文件中的所有静态变量和全局变量(因为程序在启动时必须知道它们的值)。
未初始化数据段(bss段),包含未初始化的数据,也就是初值没有存放在可执行文件中的所有全局变量(因为程序在引用它们之前才赋值);历史上把这个段叫做bss段。
堆栈段,包含程序的堆栈,堆栈中有返回地址、参数和被执行函数的局部变量。
每个mm_struct内存描述符都包含一些字段来标识相应进程特定线性区的作用:start_code, end_code,程序的源代码所在线性区的起始和终止线性地址,即可执行文件中的代码start_data, end_data,程序的初始化数据所在线性区的起始和终止线性地址,正如在可执行文件中所指定的那样。这两个字段指定的线性区大体上与数据段对应。start_brk, brk,存放线性区的起始和终止线性地址,该线性区包含动态分配给进程的内存区。有时把这部分线性区叫做堆(heap)。start_stack,正好在main()的返回地址之上的地址。如图20-1所示,更高的地址被保留(回想一下,栈是向低地址增长)。arg_start, arg_end,命令行参数所在的堆栈部分的起始地址和终止地址。env_start, env_end,环境串所在的堆栈部分的起始地址和终止地址。
灵活线性区布局
灵活线性区布局(flexible memory region lagout)在内核版本2.6.9中引入:实际上,每个进程是按照用户态堆栈预期的增长量来进行内存布局的。但是仍然可以使用老的经典布局(主要用于:当内核无法限制进程用户态堆栈的大小时)。
表20-4以80x86结构的默认用户态地址空间为例描述了这两种布局,地址空间最大可以到3GB。
正如你所看到的,布局之间只在文件内存映射与匿名映射时线性区的位置上有区别。在经典布局下,这些区域从整个用户态地址空间的1/3开始,通常在地址0x40000000。新的区域往更高线性地址追加,因此,这些区域往用户态堆栈方向扩展。
- 正文段(ELF):起自0X08048000
- 数据与BSS段:起自紧接正文段之后
- 堆:起自紧接数据与BSS之后
- 文件内存映射与匿名线性区:
- 经典布局为0X40000000该地址对应于整个用户态地址空间的1/3处!库连续往高地址追加;
- 灵活的布局是紧接用户态堆栈,库连续往低地址追加!
- 用户态堆栈起自:0XC00000000并向低地址增长
而相反的是,在灵活布局中,文件内存映射与匿名映射的线性区是紧接用户态堆栈尾的。新的区域往更低线性地址追加,因此,这些区域往堆的方向扩展。记住,堆栈也是连续往低地址追加的。当内核能通过RLIMIT_STACK资源限制来限定用户态堆栈的大小时,通常使用灵活布局。这个限制确定了为堆栈保留的线性地址空间大小。但是这个空间大小不能小于128MB或大于2.5GB。另外,如果RLIMIT_STACK资源限制设为无限(infinity),或者系统管理员将sysctl_legacy_va_layout变量设为1(通过修改/proc/sys/vm/legacy_va_layout 文件或调用相应的sysctl()系统调用实现),内核无法确定用户态堆栈的上限,就仍然使用经典线性区布局。
为什么引入灵活布局?
其主要优点是可以允许进程更好地使用用户态线性地址空间。在经典布局中,堆的限制是小于1GB,而其他线性区可以使用到约2GB(要减去堆栈大小)。在灵活布局中,这些限制没有了,堆和其他线性区可以自由扩展,可以使用除了用户态堆栈和程序用固定大小的段以外的所有线性地址空间。现在,一个实用的小试验很有启发意义。让我们录入和编译下面的C程序;
#include <stdio.h>
#include <stdlib.h>
include <unistd.h>
int main()
{
char cmd[32];
brk((void *)0x8051000);
sprintf(cmd, "cat /proc/self/maps");
system(cmd);
return 0;
}
1234567891011 实际上,程序将它的进程堆变大,然后在/proc特殊文件系统下读入maps文件,该文件产生进程自身的线性区清单。前两个十六进制数表示线性区的范围,后面是权限标志。最后面是线性区映射的文件的有关信息,如果有信息就是:文件内的开始偏移量、块设备号、索引节点号和文件名。请注意,列出的所有区域是由私有内存映射实现的(权限列的p字母)。这并不奇怪,因为这些线性区是只为进程提供数据而存在的。当执行指令时,进程可以修改这些线性区的内容,但是与它们相关的磁盘文件会保持不变。私有内存映射就具有如此作用。
从0x8048000开始的线性区是与/tmp/memorylayout文件的0~4095字节部分对应的内存映射。而相应的权限表示是可执行的(它包含了目标代码)、只读的(因为指令在执行期间是不改变的,因此不可写)和私有的。这很正确,这是程序正文段的映射区域。从0x8049000开始的线性区也是与/tmp/memorylayout文件的0~4095字节部分对应的另一个内存映射。这个程序太小,以至于程序的正文、数据和bss段都在同一个文件页里。因此,包含数据段和bss段的线性区与上一个线性区在线性地址空间是重叠的。
第三个线性区包含进程的堆。注意,它在线性地址0x8051000处终止,传递给brk()系统调用的就是该地址。接下来从0x40000000和0x40014000开始的两个线性区,分别对应这个系统ELF共享库(/lib/ld-2.3.2.so)动态链接程序的正文段和数据、bss段。动态链接程序决不单独执行,它总是以内存映射的方式映射到执行其他程序的进程地址空间内。
从0x40015000 开始的匿名线性区已由动态链接程序分配。
在这个系统上,C库正好存放在文件/lib/libc-2.3.2.so中。C库的正文段和数据、bss段被映射到从0x4002f000地址开始的两个线性区。还记得私有区域所在的页框,只要没被修改,就可以通过写时复制机制在几个进程间共享。因此,因为正文段是只读的,所示包含C库执行代码的页框几乎在所有当前运行进程间共享(除了静态链接程序)。
从0x4015b000开始的匿名线性区已由C库分配。
从0xbffeb000到0xc0000000的匿名内存区对应于用户态堆栈。我们在第九章“缺页异常处理程序”一节已讨论过堆栈是如何在必要时自动地向低地址方向扩展的。
最后,从0xffffe000开始的单页匿名线性区包含进程的vsyscall页,当发出系统调用和从信号处理程序返回时会访问该区域。
执行跟踪
执行跟踪(execution tracing)是一个程序监视另一个程序执行的一种技术。被跟踪的程序一步一步地执行,直到接收到一个信号或调用一个系统调用。执行跟踪由调试程序(debugger)广泛使用,当然还使用其他技术(包括在被调试程序中插入断点及运行时访问它的变量)。与往常一样,我们将集中讨论内核怎样支持执行跟踪,而不讨论调试程序怎样工作。在Linux中,通过ptrace()系统调用进行执行跟踪,这个系统调用能处理如表20-5所示的命令。设置了CAP_SYS_PTRACE权能的进程可以跟踪系统中的任何进程(除了init)。相反,没有CAP_SYS_PTRACE权能的进程P只能跟踪与P有相同属主的进程。此外,两个进程不能同时跟踪一个进程。
ptrace()系统调用修改被跟踪进程描述符的parent字段以使它指向跟踪进程,因此,跟踪进程变为被跟踪进程的有效父进程。当执行跟踪终止时,也就是当以PTRACE_DETACH命令调用ptrace()时,这个系统调用把p_pptr设置为real_parent 的值,恢复被跟踪进程原来的父进程。与被跟踪程序相关的几个监控事件为:
- 一条单独汇编指令执行的结束
- 进入系统调用
- 退出系统调用
- 接收到一个信号
当一个监控的事件发生时,被跟踪的程序停止,并且将SIGCHID信号发送给它的父进程。
当父进程希望恢复子进程的执行时,就使用PTRACE_CONT、PTRACE_SINGLESTEP 和PTRACE_SYSCALL命令中的一条命令,这取决于父进程要监控哪种事件。
PTRACE_CONT命令只继续执行,子进程将一直执行到收到另一个信号。这种跟踪是通过进程描述符的ptrace字段中的PF_PTRACED标志实现的,而这个标志的检查是由do_signal()函数进行的。PTRACE_SINGLESTEP命令强迫子进程执行下一条汇编语言指令,然后又停止它。这种跟踪是基于80×86机器的eflags寄存器的TF陷阱标志而实现的。当这个标志为1时,在任一条汇编语言指令之后正好产生一个“Debug”异常。相应的异常处理程序只是清掉这个标志,强迫当前进程停止,并发送SIGCHLD信号给父进程。注意,设置TF标志并不是特权操作,因此用户态进程即使在没有ptrace()系统调用的情况下,也能强迫单步执行。内核检查进程描述符中的PT_DTRACE标志,以跟踪子进程是否通过ptrace()进行单步执行。PTRACE_SYSCALL命令使被跟踪的进程重新恢复执行,直到一个系统调用被调用。进程停止两次,第一次是在系统调用开始时,第二次是在系统调用终止时。这种跟踪是利用进程描述符中的TIF_SYSCALL_TRACE标志实现的。这个标志是在进程thread_info结构的flags字段中,并在system_call()汇编语言的函数中被检查。
也可以利用Intel Pentium处理器的一些调试特点来跟踪进程。例如,父进程使用PTRACE_POKEUSR命令为子进程设置dr0,…,dr7调试寄存器的值。当由某调试寄存器监控的事情发生时,CPU产生“Debug”异常,异常处理程序然后挂起被调试的进程并给父进程发送SIGCHLD信号。
可执行格式
Linux标准的可执行格式是ELF(Executable and Linking Format)。
Linux支持很多其他不同格式的可执行文件。在这种方式下,Linux能运行为其他操作系统所编译的程序,如MS-DOS的EXE程序。有几种可执行格式,如Java或bash脚本,是与平台无关的。
由类型为linux_binfmt的对象所描述的可执行格式实质上提供以下三种方法:load_binary,通过读存放在可执行文件中的信息为当前进程建立一个新的执行环境。load_shlib,用于动态地把一个共享库捆绑到一个已经在运行的进程,这是由uselib()系统调用激活的。core_dump,在名为core的文件中存放当前进程的执行上下文。这个文件通常是在进程接收到一个缺省操作为“dump”的信号时被创建的,其格式取决于被执行程序的可执行类型。
所有的linux_binfmt对象都处于一个单向链表中,第一个元素的地址存放在formats 变量中。
在系统启动期间,为每个编译进内核的可执行格式都执行register_binfmt()函数。当实现了一个新的可执行格式的模块正被装载时,也执行这个函数,当模块被卸载时,执行unregister_binfmt()函数。
在formats链表中的最后一个元素总是对解释脚本(interpreted script)的可执行格式进行描述的一个对象。这种格式只定义了load_binary方法。其相应的load_script()函数检查这种可执行文件是否以两个#!字符开始。如果是,这个函数就把第一行的其余部分解释为另一个可执行文件的路径名,并把脚本文件名作为参数传递以执行它。
Linux`允许用户注册自己定义的可执行格式。对这种格式的识别或者通过存放在文件前`128`字节的魔数,或者通过表示文件类型的扩展名。当内核确定可执行文件是自定义格式时,它就启动相应的解释程序(`interpreterprogram`)。解释程序运行在用户态,读入可执行文件的路径名作为参数,并执行计算。例如,包含`Java`程序的可执行文件就由`Java`虚拟机(如`/usr/lib/java/bin/java`)来解释。这种机制与脚本格式类似,但功能更加强大,这是因为它对自定义格式不加任何限制。要注册一个新格式,就必须在`binfmt_misc`特殊文件系统(通常`/proc/sys/fs/binfmt_misc`)的注册文件内写入一个字符串,其格式如下:`:name:type:offset:string:mask:interpreter;flags执行域
Linux的一个巧妙的特点就是能执行其他操作系统所编译的程序。当然,只有内核运行的平台与可执行文件包含的机器代码对应的平台相同时这才是可能的。对这些“外来”程序提供两种支持:
- 模拟执行(
emulated execution):程序中包含的系统调用与POSIX不兼容时才有必要执行这种程序。 - 原样执行(
native execution):只有程序中所包含的系统调用完全与POSIX兼容时才有效。
Microsoft MS-DOS和Windows程序是被模拟执行的,因为它们包含的API不能被Linux 所认识,因此不能原样执行。像DOSemu或Wine这样的模拟程序被调用来把每个API调用转换为一个模拟的封装函数调用,而封装函数调用又使用现有的Linux系统调用。因为模拟程序主要是作为用户态的应用程序来执行,因此我们在此不做进一步的讨论。
另一方面,不用太费力就可以执行为其他操作系统编译的与POSIX兼容的程序,因为与POSIX兼容的操作系统都提供了类似的API(尽管实际上并不总是这种情况,但API应该相同)。内核必须消除的细微差别通常涉及如何调用系统调用或如何给各种信号编号。这种信息存放在类型为exec_domain的执行域描述符(execution domain descriptor)中。进程可以指定它的执行域,这是通过设置进程描述符的personality字段,以及把相应exec_domain数据结构的地址存放到thread_info结构的exec_domain字段来实现的。进程可以通过发布一个叫做personality()的系统调用来改变它的个性(personality);
exec函数
Unix系统提供了一系列函数,这些函数能用可执行文件所描述的新上下文代替进程的上下文。这样的函数名以前缀exec开始,后跟一个或两个字母,因此,家族中的一个普通函数被当作exec函数来引用。
| 函数 | 路径搜索 | 命令行参数 | 环境数组 |
|---|---|---|---|
| execl | 否 | 列表 | 否 |
| execlp | 是 | 列表 | 否 |
| execle | 否 | 列表 | 是 |
| execv | 否 | 数组 | 否 |
| execvp | 是 | 数组 | 否 |
| execve | 否 | 数组 | 是 |
每个函数的第一个参数表示被执行文件的路径名。路径名可以是绝对路径或是当前进程目录的相对路径。此外,如果路径名中不包含“/”字符,execlp()和execvp()函数就在PATH环境变量指定的所有目录中搜索这个可执行文件。除了第一个参数,execl()、execlp()和execle()函数包含的其他参数个数都是可变的。每个参数指向一个字符串,这个字符串是对新程序命令行参数的描述,正如函数名中“l”字符所隐含的一样,这些参数组织成一个列表(最后一个值为NULL)。
通常情况下,第一个命令行参数复制可执行文件名。相反,execv()、execvp()和execve()函数指定单个参数的命令行参数,正如函数名中的“v”字符所隐含的一样,这单个参数是指向命令行参数串的指针向量地址。数组的最后一个元素必须存放NULL值。
execle()和execve()函数的最后一个参数是指向环境串的指针数组的地址;数组的最后一个元素照样必须为NULL。其他函数对新程序环境参数的访问是通过C库定义的外部全局变量environ进行的。
所有的exec函数(除execve()外)都是C库定义的封装例程,并利用了execve()系统调用,这是Linux所提供的处理程序执行的唯一系统调用。
sys_execve()服务例程接收下列参数:
(1). 可执行文件路径名的地址(在用户态地址空间)。
(2). 以NULL结束的字符串指针数组的地址(在用户态地址空间)。每个字符串表示一个命令行参数。
(3). 以NULL结束的字符串指针数组的地址(也在用户态地址空间)。每个字符串以NAME=value形式表示一个环境变量。
sys_execve()把可执行文件路径名拷贝到一个新分配的页框。
然后调用do_execve()函数,传递给它的参数为指向这个页框的指针、指针数组的指针及把用户态寄存器内容保存到内核态堆栈的位置。
do_execve()依次执行下列操作:
动态地分配一个
linux_binprm数据结构,并用新的可执行文件的数据填充这个结构调用
path_lookup()、dentry_open()和path_release(),以获得与可执行文件相关的目录项对象、文件对象和索引节点对象。如果失败,则返回相应的错误码。检查是否可以由当前进程执行该文件,再检查索引节点的
i_writecount字段,以确定可执行文件没被写入;把-1存放在这个字段以禁止进一步的写访问。在多处理器系统中,调用
sched_exec()函数来确定最小负载CPU以执行新程序,并把当前进程转移过去。调用
init_new_context()检查当前进程是否使用自定义局部描述符表)。如果是,函数为新程序分配和准备一个新的LDT。调用
prepare_binprm()函数填充linux_binprm数据结构,这个函数又依次执行下列操作:- 再一次检查文件是否可执行(至少设置一个执行访问权限)。如果不可执行,则返回错误码(因为带有
CAP_DAC_OVERRIDE权能的进程总能通过检查,所以第3步中的检查还不够。)。 - 初始化
linux_binprm结构的e_uid和e_gid字段,考虑可执行文件的setuid和setgid标志的值。这些字段分别表示有效的用户ID和组ID。也要检查进程的权能。 - 用可执行文件的前
128字节填充linux_binprm结构的buf字段。这些字节包含的是适合于识别可执行文件格式的一个魔数和其他信息。
- 再一次检查文件是否可执行(至少设置一个执行访问权限)。如果不可执行,则返回错误码(因为带有
把文件路径名、命令行参数及环境串拷贝到一个或多个新分配的页框中(最终,它们会被分配给用户态地址空间)。
调用
search_binary_handler()函数对formats链表进行扫描,并尽力应用每个元素的load_binary方法,把linux_binprm数据结构传递给这个函数。只要load_binary方法成功应答了文件的可执行格式,对formats的扫描就终止。如果可执行文件格式不在
formats链表中,就释放所分配的所有页框并返回错误码-ENOEXEC,表示Linux不认识这个可执行文件格式。否则,函数释放
linux_binprm数据结构,返回从这个文件可执行格式的load_binary方法中所获得的代码。
可执行文件格式对应的load_binary方法执行下列操作(我们假定这个可执行文件所在的文件系统允许文件进行内存映射并需要一个或多个共享库):
检查存放在文件前
128字节中的一些魔数以确认可执行格式。如果魔数不匹配,则返回错误码-ENOEXEC。读可执行文件的首部。这个首部描述程序的段和所需的共享库。
从可执行文件获得动态链接程序的路径名,并用它来确定共享库的位置并把它们映射到内存。
获得动态链接程序的目录项对象(也就获得了索引节点对象和文件对象)。
检查动态链接程序的执行许可权。
把动态链接程序的前
128字节拷贝到缓冲区。对动态链接程序类型执行一些一致性检查。
调用
flush_old_exec()函数释放前一个计算所占用的几乎所有资源。这个函数又依次执行下列操作:- 如果信号处理程序的表为其他进程所共享,那么就分配一个新表并把旧表的引用计数器减
1;而且它将进程从旧的线程组脱离。这是通过调用de_thread()函数完成的。 - 如果与其他进程共享,就调用
unshare_files()函数拷贝一份包含进程已打开文件的files_struct结构。 - 调用
exec_mmap()函数释放分配给进程的内存描述符、所有线性区及所有页框,并清除进程的页表。 - 将可执行文件路径名赋给进程描述符的
comm字段。 - 调用
flush_thread()函数清除浮点寄存器的值和在TSS段保存的调试寄存器的值。 - 调用
flush_signal_handlers()函数,用于将每个信号恢复为默认操作,从而更新信号处理程序的表。 - 调用
flush_old_files()函数关闭所有打开的文件,这些打开的文件在进程描述符的files->close_on_exec字段设置了相应的标志。现在,我们已经不能返回了:如果真出了差错,这个函数再不能恢复前一个计算。
- 如果信号处理程序的表为其他进程所共享,那么就分配一个新表并把旧表的引用计数器减
清除进程描述符的
PF_FORKNOEXEC标志。这个标志用于在进程创建时设置进程记账,在执行一个新程序时清除进程记账。设立进程新的个性,即设置进程描述符的
personality字段调用
arch_pick_mmap_layout(),以选择进程线性区的布局。调用
setup_arg_pages()函数为进程的用户态堆栈分配一个新的线性区描述符,并把那个线性区插入到进程的地址空间。setup_arg_pages()还把命令行参数和环境变量串所在的页框分配给新的线性区。调用
do_mmap()函数创建一个新线性区来对可执行文件正文段(即代码)进行映射。这个线性区的起始线性地址依赖于可执行文件的格式,因为程序的可执行代码通常是不可重定位的。因此,这个函数假定从某一特定逻辑地址的偏移量开始(因此就从某一特定的线性地址开始)装入正文段。ELF程序被装入的起始线性地址为0x08048000。调用
do_mmap()函数创建一个新线性区来对可执行文件的数据段进行映射。这个线性区的起始线性地址也依赖于可执行文件的格式,因为可执行代码希望在特定的偏移量(即特定的线性地址)处找到它自己的变量。在ELF程序中,数据段正好被装在正文段之后。为可执行文件的其他专用段分配另外的线性区,通常是无。
调用一个装入动态链接程序的函数。如果动态链接程序是
ELF可执行的,这个函数就叫做load_elf_interp()。
一般情况下,这个函数执行第12~14步的操作,不过要用动态链接程序代替被执行的文件。动态链接程序的正文段和数据段在线性区的起始线性地址是由动态链接程序本身指定的;但它们处于高地址区(通常高于0x40000000),这是为了避免与被执行文件的正文段和数据段所映射的线性区发生冲突。把可执行格式的
linux_binfmt对象的地址存放在进程描述符的binfmt字段中。确定进程的新权能。
创建特定的动态链接程序表并把它们存放在用户态堆栈,如图
20-1所示,这些表处于命令行参数和指向环境串的指针数组之间。设置进程的内存描述符的
start_code、end_code、start_data 、end_data、start_brk、brk及start_stack字段。调用
do_brk()函数创建一个新的匿名线性区来映射程序的bss段(当进程写入一个变量时,就触发请求调页,进而分配一个页框)。这个线性区的大小是在可执行程序被链接时就计算出来的。因为程序的可执行代码通常是不可重新定位的,因此,必须指定这个线性区的起始线性地址。在ELF程序中,bss段正好装在数据段之后。调用
start_thread()宏修改保存在内核态堆栈但属于用户态寄存器的eip和esp的值,以使它们分别指向动态链接程序的入口点和新的用户态堆栈的栈顶。如果进程正被跟踪,就通知调试程序
execve()系统调用已完成。返回
0值(成功)。
当execve()系统调用终止且调用进程重新恢复它在用户态的执行时,执行上下文被大幅度改变,调用系统调用的代码不复存在。
从这个意义上看,我们可以说execve()从未成功返回。取而代之的是,要执行的新程序已被映射到进程的地址空间。但是,新程序还不能执行,因为动态链接程序还必须考虑共享库的装载。尽管动态链接程序运行在用户态,但我们还要在这里简要概述一下它是如何运作的。
它的第一个工作就是从内核保存在用户态堆栈的信息(处于环境串指针数组和arg_start 之间)开始,为自己建立一个基本的执行上下文。然后,动态链接程序必须检查被执行的程序,以识别哪个共享库必须装入及在每个共享库中哪个函数被有效地请求。接下来,解释器发出几个mmap()系统调用来创建线性区,以对将存放程序实际使用的库函数(正文和数据)的页进行映射。然后,解释器根据库的线性区的线性地址更新对共享库符号的所有引用。最后,动态链接程序通过跳转到被执行程序的主入口点而终止它的执行。从现在开始,进程将执行可执行文件的代码和共享库的代码。
你可能已注意到,执行程序是一个相当复杂的活动,它涉及内核设计的很多方面,如进程抽象、内存管理、系统调用及文件系统。这会使你认识到:Linux真是一个杰作!